Introduction
Welcome to the fascinating world of Machine Learning! In today’s era of exponential technological growth, machine learning has emerged as a game-changing field that promises to revolutionize industries and reshape the way we live and work. From personalized recommendations on streaming platforms to fraud detection algorithms in the finance sector, machine learning algorithms are powering countless applications that make our lives easier and more efficient.
Machine learning, simply put, is a subset of artificial intelligence that focuses on the development of algorithms and models that allow computers to learn from data and make predictions or decisions without being explicitly programmed. It enables computers to automatically improve and optimize their performance through experience.
But how difficult is machine learning? The answer to this question is not straightforward, as it depends on various factors, including the complexity of the problem at hand, the availability and quality of data, the choice of algorithms, and the expertise of the data scientists involved.
Machine learning algorithms can be incredibly powerful, but they also have their challenges. For one, they require a significant amount of computational resources, such as processing power and memory, to train and deploy. The complexity of the algorithms used in machine learning can sometimes make the learning process time-consuming and resource-intensive.
Furthermore, machine learning requires a deep understanding of mathematical concepts and statistics. Data scientists need to have a solid grasp of linear algebra, calculus, and probability theory to effectively work with machine learning algorithms. The ability to identify relevant features, engineer them appropriately, and select the best algorithms for a given problem is crucial in achieving successful results.
Another challenge in machine learning is the availability and quality of data. Good quality and representative data is essential to train accurate models. Data collection and cleaning can be a tedious and time-consuming process, as data scientists need to ensure that the data is formatted correctly, missing values are handled appropriately, and there are no biases or inconsistencies in the dataset.
Despite these challenges, machine learning offers immense potential for businesses and organizations looking to gain insights from their data and make data-driven decisions. With advancements in technology and the availability of powerful tools and libraries, the barriers to entry in the field have been significantly lowered, making machine learning more accessible than ever before.
In the following sections, we will delve deeper into the intricacies of machine learning, exploring the complexity of algorithms, the role of data, challenges in model training, performance evaluation, and the limitations of this exciting field.
What is Machine Learning?
Machine learning is a branch of artificial intelligence (AI) that focuses on the development of algorithms and models that enable computers to learn and make predictions or decisions, without being explicitly programmed. It is based on the idea that computers can automatically analyze and learn from data to improve their performance on specific tasks.
At its core, machine learning revolves around the concept of creating algorithms that can automatically identify patterns and relationships within data, and use that knowledge to make predictions or take actions. These algorithms can be broadly categorized into three types: supervised learning, unsupervised learning, and reinforcement learning.
In supervised learning, the algorithm is trained on a labeled dataset, where each data point is associated with a corresponding label or outcome. The algorithm learns from these labeled examples and can subsequently make predictions on unseen data. Examples of supervised learning tasks include image classification, speech recognition, and sentiment analysis.
Unsupervised learning, on the other hand, involves training algorithms on unlabeled data. The goal is to identify hidden patterns or structures within the data without any prior knowledge or guidance. Clustering and dimensionality reduction are common examples of unsupervised learning tasks, which can be useful for tasks like customer segmentation or anomaly detection.
Reinforcement learning takes a different approach, where an agent learns to interact with an environment in order to achieve a specific goal. The agent receives feedback in the form of rewards or penalties based on its actions, allowing it to learn through trial and error. This type of learning is often used in areas such as robotics and game playing.
Machine learning algorithms rely heavily on data to learn and generalize from. The more diverse and representative the data, the better the algorithm can learn and make accurate predictions. Data scientists play a crucial role in preparing and curating the data, ensuring its quality and relevance for the specific task at hand.
Machine learning has found applications in a wide range of industries and domains. In healthcare, it is used for diagnosing diseases, predicting patient outcomes, and drug discovery. In finance, machine learning algorithms are used for fraud detection, algorithmic trading, and credit scoring. It is also widely used in marketing, customer analytics, natural language processing, and many other fields.
Machine learning algorithms are not fixed or static; they continuously adapt and improve over time as they are exposed to new data. This ability to learn and evolve without explicit programming is what sets machine learning apart and makes it such a powerful tool in today’s data-driven world.
In the next sections, we will explore the complexity of machine learning algorithms, the role of data, challenges in model training, performance evaluation, and the limitations of this exciting field.
Understanding the Complexity of Machine Learning Algorithms
Machine learning algorithms can be incredibly complex, requiring a deep understanding of mathematical concepts, statistical analysis, and programming techniques. The complexity arises from the need to develop algorithms that can effectively learn from data, make accurate predictions, and adapt to changing environments.
One aspect of the complexity in machine learning algorithms is the underlying mathematical foundations. Many algorithms are based on statistical techniques, such as regression analysis, decision trees, and Bayesian inference. Understanding these mathematical concepts is essential to effectively apply and interpret the results of machine learning algorithms.
Moreover, the choice of algorithms can greatly impact the complexity of a machine learning task. There is a wide range of algorithms available, each with its own strengths and weaknesses. Selecting the most appropriate algorithm for a specific problem requires a deep understanding of the problem domain, the available data, and the desired outcomes.
Deep learning algorithms, a subset of machine learning, have gained considerable attention in recent years due to their ability to process and learn from complex, high-dimensional data. Deep learning architectures, such as neural networks, can have countless layers and millions of parameters, making them computationally intensive and requiring substantial computational resources for training.
Furthermore, the complexity of machine learning algorithms extends to the preprocessing and feature engineering steps. Preprocessing involves cleaning and transforming the raw data into a suitable format for analysis. Feature engineering involves selecting or creating relevant features that capture the essential information in the data. Both steps require careful consideration and domain expertise to ensure the best possible input for the learning algorithms.
Another factor contributing to the complexity of machine learning algorithms is the need to tune their hyperparameters. Hyperparameters are parameters that are not learned from the data but are set by the user before training the model. Selecting appropriate hyperparameter values can significantly impact the performance of the model. It requires experimentation and fine-tuning to strike the right balance and achieve optimal results.
Additionally, the complexity of machine learning algorithms also involves the iterative process of model training and evaluation. Training a machine learning model involves optimizing its parameters based on the available data. This iterative process involves running the algorithm multiple times, adjusting parameters, and evaluating the performance of the model on validation data. It can be time-consuming and computationally demanding.
Overall, the complexity of machine learning algorithms reflects the intricate nature of the problems they aim to solve. It requires a combination of mathematical expertise, programming skills, and domain knowledge to effectively utilize and interpret these algorithms. However, advancements in tools, frameworks, and libraries have made it more accessible for both researchers and practitioners to leverage the power of machine learning in various applications.
In the next sections, we will delve into the role of data in machine learning, the importance of feature selection and engineering, challenges in model training, and how to evaluate the performance of machine learning models.
The Role of Data in Machine Learning
Data plays a central role in the field of machine learning. It serves as the fuel that powers various algorithms, enabling them to learn, generalize, and make accurate predictions. The quality, quantity, and diversity of the data used for training machine learning models greatly impact their performance and reliability.
One of the primary requirements of machine learning is having a sufficient amount of representative and relevant data. The more data available for training, the better the algorithm can learn from it and make accurate predictions. However, it is important to note that having more data does not always guarantee better results, as the quality of data also matters.
High-quality data is crucial for training robust machine learning models. Data scientists must carefully curate and clean the data to ensure its accuracy, consistency, and completeness. This involves identifying and handling missing values, removing outliers, and dealing with potential biases in the data that could affect the model’s performance.
The diversity of the data used for training is also essential. Representing different variations and scenarios within the data helps the algorithm to generalize well and make predictions on unseen data. Incorporating diverse data can help address bias and prevent the model from making erroneous assumptions based on limited data samples.
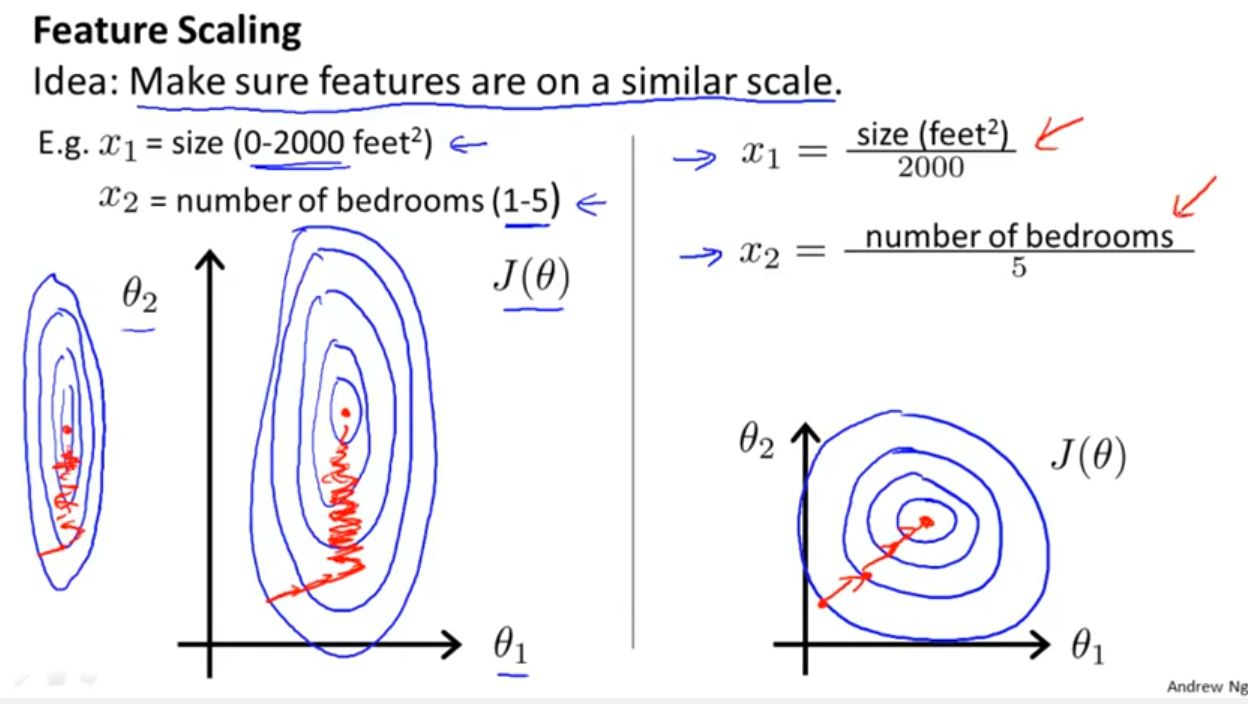
Another important consideration when working with data in machine learning is its appropriate representation and format. Data needs to be encoded properly to make it usable by the learning algorithms. Features may require scaling or normalization to ensure that they contribute equally to the model’s learning process and avoid biases towards certain features.
While labeled data is commonly used in supervised learning, where each data point is associated with a corresponding label, obtaining labeled data is not always feasible or readily available. In such cases, techniques like semi-supervised learning can be employed, where a combination of labeled and unlabeled data is used to train the model.
The availability and access to data can also present challenges. In some cases, data may be scarce or limited, especially in niche domains or emerging fields. Data collection processes may incur costs or require special permissions and agreements. Overcoming these challenges often involves collaboration, data sharing, and the development of strategies to collect or generate sufficient training data.
Furthermore, the privacy and ethical considerations associated with data cannot be overlooked. As machine learning heavily relies on data, it is essential to ensure that data usage aligns with legal and ethical guidelines. Data anonymization techniques, secure storage, and compliance with privacy regulations are aspects to be considered when working with sensitive or personal data.
In summary, data is the lifeblood of machine learning. The quality, quantity, diversity, and appropriateness of the data used for training greatly impact the performance and reliability of machine learning models. Data curation, cleaning, and representation are crucial steps in preparing data for training, while considering privacy and ethical considerations is essential to ensure responsible use of data in the machine learning process.
In the following sections, we will explore the importance of feature selection and engineering, the challenges in model training, and how to evaluate the performance of machine learning models.
The Importance of Feature Selection and Engineering
Feature selection and engineering play a critical role in machine learning. The choice and creation of relevant features greatly influence the performance and interpretability of machine learning models. Effective feature selection and engineering can enhance model accuracy, improve computational efficiency, and provide valuable insights into the underlying data.
Feature selection involves identifying and selecting a subset of features from the available data that are most informative and relevant for the learning task. Having too many irrelevant or redundant features can lead to overfitting, where the model performs well on the training data but fails to generalize to new, unseen data. On the other hand, selecting too few relevant features might result in underfitting, where the model does not capture the complexity of the underlying data.
To perform feature selection, domain knowledge and statistical techniques are often employed. Domain experts can provide valuable insights into the important factors that influence the outcome of the problem being solved. Statistical methods, such as correlation analysis or mutual information, can quantify the relationship between features and the target variable. These techniques help identify the most influential features and discard those that have little impact on the predictive power of the model.
In addition to feature selection, feature engineering is the process of creating new features or transforming existing ones to improve the model’s performance. This involves deriving new representations or combinations of the original features that capture relevant patterns or relationships in the data. Feature engineering can enhance the predictive power of the model by providing it with more meaningful and discriminative information.
Feature engineering techniques vary depending on the nature of the data and the problem at hand. It may involve scaling or normalizing features to ensure they are on a similar scale and contribute equally to the learning process. Transformations such as logarithmic or polynomial transformations can help capture nonlinear relationships between features and the target variable. Domain-specific knowledge can also guide the creation of new features that capture specific patterns or domain expertise.
Effective feature selection and engineering can lead to several benefits in the machine learning process. Firstly, it can enhance the model’s predictive accuracy by focusing on the most informative features and eliminating noise or irrelevant information. This can result in more accurate and reliable predictions on unseen data.
Secondly, proper feature selection and engineering can improve computational efficiency. By reducing the number of features, the model’s training and inference times can be significantly decreased, allowing for quicker model development and deployment in real-world applications.
Moreover, feature selection and engineering can also provide valuable insights and interpretability. By understanding which features are most relevant for the model’s predictions, domain experts can gain a deeper understanding of the underlying factors driving the problem at hand. This knowledge can help make informed decisions, identify potential biases, and guide further data collection or preprocessing efforts.
In summary, feature selection and engineering are critical steps in the machine learning process. They enable the identification of the most informative features, reduce computational complexity, improve model accuracy, and provide insights into the underlying data. With careful consideration and domain expertise, feature selection and engineering can greatly enhance the performance and interpretability of machine learning models.
In the following sections, we will explore the challenges in model training, the evaluation of machine learning model performance, and the limitations of this exciting field.
Challenges in Model Training
Model training is a crucial step in the machine learning pipeline, where the learning algorithm learns from the available data to make accurate predictions or decisions. However, model training can be a challenging process that requires careful consideration of various factors to ensure optimal model performance.
One of the main challenges in model training is the availability and quality of training data. Machine learning algorithms rely on representative and diverse data to learn patterns and make predictions. However, obtaining high-quality labeled data can be expensive, time-consuming, or even impractical in some cases. Insufficient or biased training data can lead to poor model performance and limited generalization to unseen data.
Another challenge is the curse of dimensionality, which refers to the increase in complexity and computation requirements as the number of features or dimensions in the data increases. As the dimensionality of the data grows, the model may struggle to learn effectively, resulting in overfitting or decreased performance. Techniques such as feature selection and dimensionality reduction can help mitigate this challenge but require careful implementation.
The choice of model architecture and hyperparameters also poses challenges in model training. Different machine learning algorithms have different assumptions, strengths, and limitations. Selecting the most appropriate algorithm for a given task requires a solid understanding of the problem domain and the characteristics of the data. Tuning the hyperparameters of the selected model is also crucial to optimize its performance. This process can be time-consuming and requires experimentation and expertise.
Furthermore, training large-scale models can be computationally demanding. Deep learning models with numerous layers and millions of parameters often require significant computational resources, such as powerful GPUs or distributed computing systems. Training such models may also consume a substantial amount of time and energy, making it a challenge for researchers and practitioners with limited resources.
Model evaluation and validation present their own set of challenges in the training process. Splitting the available data into training and validation sets is necessary to assess the model’s performance and ensure its generalization. However, this process can introduce bias or overestimate the model’s performance if not done carefully. Techniques such as cross-validation and bootstrapping can help mitigate these challenges, but they require additional computational resources and careful implementation.
Addressing overfitting or underfitting is another challenge in model training. Overfitting occurs when a model learns the training data too well but fails to generalize to new data. Underfitting refers to a model’s inability to capture the underlying patterns in the data. Both scenarios can impair a model’s performance. Regularization techniques, such as L1 or L2 regularization, and early stopping can help mitigate these challenges and improve model generalization.
Lastly, model training in real-world applications often requires consideration of ethical and privacy concerns. The use of sensitive or personal data needs to comply with legal regulations and privacy policies. Implementing techniques like differential privacy or federated learning can help protect the privacy of individuals while still training effective models.
In summary, model training in machine learning comes with its own set of challenges. These challenges include data availability and quality, the curse of dimensionality, model selection and hyperparameter tuning, computational requirements, model evaluation, addressing overfitting or underfitting, and ethical considerations. Overcoming these challenges requires expertise, careful experimental design, and consideration of the specific context in which the models are being trained.
In the following sections, we will explore how to evaluate the performance of machine learning models and discuss the limitations of machine learning.
Evaluating the Performance of Machine Learning Models
Evaluating the performance of machine learning models is critical to assess their effectiveness and determine their suitability for specific tasks. Proper evaluation provides insights into the model’s predictive capabilities and helps identify areas for improvement. However, evaluating machine learning models comes with its own challenges, and various metrics and techniques are used to measure performance.
One commonly used metric for evaluating classification models is accuracy, which measures the proportion of correct predictions over the total number of predictions. While accuracy is a straightforward measure, it may not be suitable for imbalanced datasets where the classes are unequally represented. In such cases, metrics like precision, recall, and F1 score provide a more nuanced evaluation by considering true positives, true negatives, false positives, and false negatives.
For regression problems, metrics such as mean squared error (MSE) or mean absolute error (MAE) are often used to assess the model’s ability to predict continuous variables. Lower values of these metrics indicate a better-performing model. Additionally, metrics like R-squared (R²) measure the proportion of the variance in the target variable that can be explained by the model’s predictions.
Cross-validation is a technique commonly used to evaluate the performance of machine learning models. By partitioning the available data into multiple subsets, a model can be trained and tested on different combinations of the data. This helps provide a more robust estimate of the model’s performance, as it reduces the dependency on a single train-test split. However, performing cross-validation can be computationally expensive, especially for large datasets or complex models.
Receiver Operating Characteristic (ROC) curves and Area Under the Curve (AUC) are widely used to evaluate binary classification models. ROC curves illustrate the trade-off between true positive rate and false positive rate at various threshold settings, while AUC represents the overall performance of the model. Higher AUC values indicate better discrimination power and prediction quality.
When evaluating machine learning models, it is important to consider the specific requirements and objectives of the task at hand. Different applications may prioritize different metrics and evaluation techniques. For instance, in medical diagnosis, the emphasis might be on maximizing sensitivity to reduce false negatives, whereas in financial fraud detection, precision might be a more critical metric to minimize false positives.
The evaluation of machine learning models should also take into account potential biases in the data or evaluation process. Bias can occur if the training data is not representative of the population or if certain groups are underrepresented. It is essential to ensure fairness and equality in model evaluation by carefully considering and addressing potential biases in the evaluation process.
Interpreting the results of model evaluation is equally important. Understanding not only the numerical scores but also the underlying patterns and predictions made by the model can help identify strengths, weaknesses, and potential areas for improvement. Visualization techniques, such as confusion matrices or scatter plots, can aid in comprehending the model’s performance and identifying potential disparities or outliers.
Lastly, it is crucial to remember that evaluating the performance of machine learning models is an iterative process. Models may need to be continuously refined, retrained, and reassessed as new data becomes available or as the problem domain evolves. Regular monitoring and evaluation of model performance ensure that models remain reliable, accurate, and relevant over time.
In summary, evaluating the performance of machine learning models involves selecting appropriate metrics, utilizing techniques such as cross-validation and ROC curves, considering task-specific requirements, addressing biases, and interpreting results effectively. Proper evaluation allows data scientists and practitioners to make informed judgments about model performance and make necessary adjustments to improve their models.
In the following sections, we will discuss the limitations and drawbacks of machine learning, highlighting the factors that can impact its effectiveness.
Overcoming Bias and Overfitting in Machine Learning
Bias and overfitting are common challenges in machine learning that can impact the accuracy and reliability of models. These issues arise when models are unable to generalize well to new, unseen data, leading to poor performance and potentially biased predictions. Overcoming bias and overfitting is crucial to ensure the effectiveness and fairness of machine learning models.
Bias in machine learning refers to the systematic errors or prejudices present in a model’s predictions. Bias can be introduced at various stages of the machine learning process, including data collection, preprocessing, feature selection, and algorithm design. Biased data can lead to biased models that discriminate against certain groups or exhibit skewed predictions.
One way to overcome bias is to ensure the training data is representative and balanced. This involves careful sampling and data collection techniques to include a diverse range of samples that adequately represent the population. It is essential to address biases related to demographic factors, such as age, gender, or race, as well as biases related to specific subgroups or underrepresented classes in the data.
Another step towards mitigating bias is by performing bias audits and assessments of trained models. This involves analyzing the model’s predictions and evaluating whether there is any unfair or discriminatory bias present. Techniques like fairness metrics, such as equalized odds or demographic parity, can help identify and quantify biases in model predictions.
Overfitting occurs when a model performs extremely well on the training data but fails to generalize to new, unseen data. Overfitting happens when a model is too complex or when it is “memorizing” the noise or random variations in the training data instead of learning the true underlying patterns. Regularization techniques, such as L1 or L2 regularization, can help overcome overfitting by introducing penalties on model complexity and reducing the impact of unnecessary features.
Data augmentation and cross-validation techniques can also help combat overfitting. Data augmentation involves creating additional synthetic samples to increase the size and diversity of the training data. This helps the model to learn more robust and generalized patterns. Cross-validation ensures that the evaluation of model performance is not biased towards a specific train-test split and provides a more reliable estimate of the model’s generalizability.
Furthermore, early stopping is a technique that can be used to prevent overfitting. By monitoring the model’s performance on a validation dataset during the training process, early stopping allows for the termination of training when the model’s performance starts to deteriorate. This prevents the model from excessively fitting the training data and helps it generalize better to new data.
Regular monitoring and evaluation of models, even after they are deployed, are important for detecting and addressing bias and overfitting. Continuous data collection, analysis of model predictions, and user feedback can help identify potential biases or overfitting issues that may arise in real-world scenarios. Regular model retraining and updates can ensure that the models remain fair, accurate, and robust over time.
In summary, overcoming bias and overfitting is critical in machine learning to ensure fair and reliable predictions. Mitigating bias requires representative and balanced training data, along with rigorous bias audits and assessments. Overfitting can be minimized through regularization techniques, data augmentation, cross-validation, and early stopping. Regular monitoring and evaluation of models are essential for detecting and addressing biases and overfitting in real-world applications.
In the next sections, we will discuss the limitations and drawbacks of machine learning, highlighting the factors that can impact its effectiveness and applicability.
The Limitations and Drawbacks of Machine Learning
While machine learning has revolutionized various industries and enabled impressive advancements, it is important to acknowledge its limitations and potential drawbacks. Understanding these limitations can help practitioners and researchers make informed decisions and set realistic expectations when applying machine learning techniques.
One of the primary limitations of machine learning is its reliance on data. Machine learning models require large amounts of high-quality, labeled data to learn and generalize effectively. However, acquiring such data can be challenging, particularly in niche domains or emerging fields where labeled data may be scarce or costly to obtain. Limited or biased training data can lead to models that are not representative of the desired population and may produce inaccurate or biased predictions.
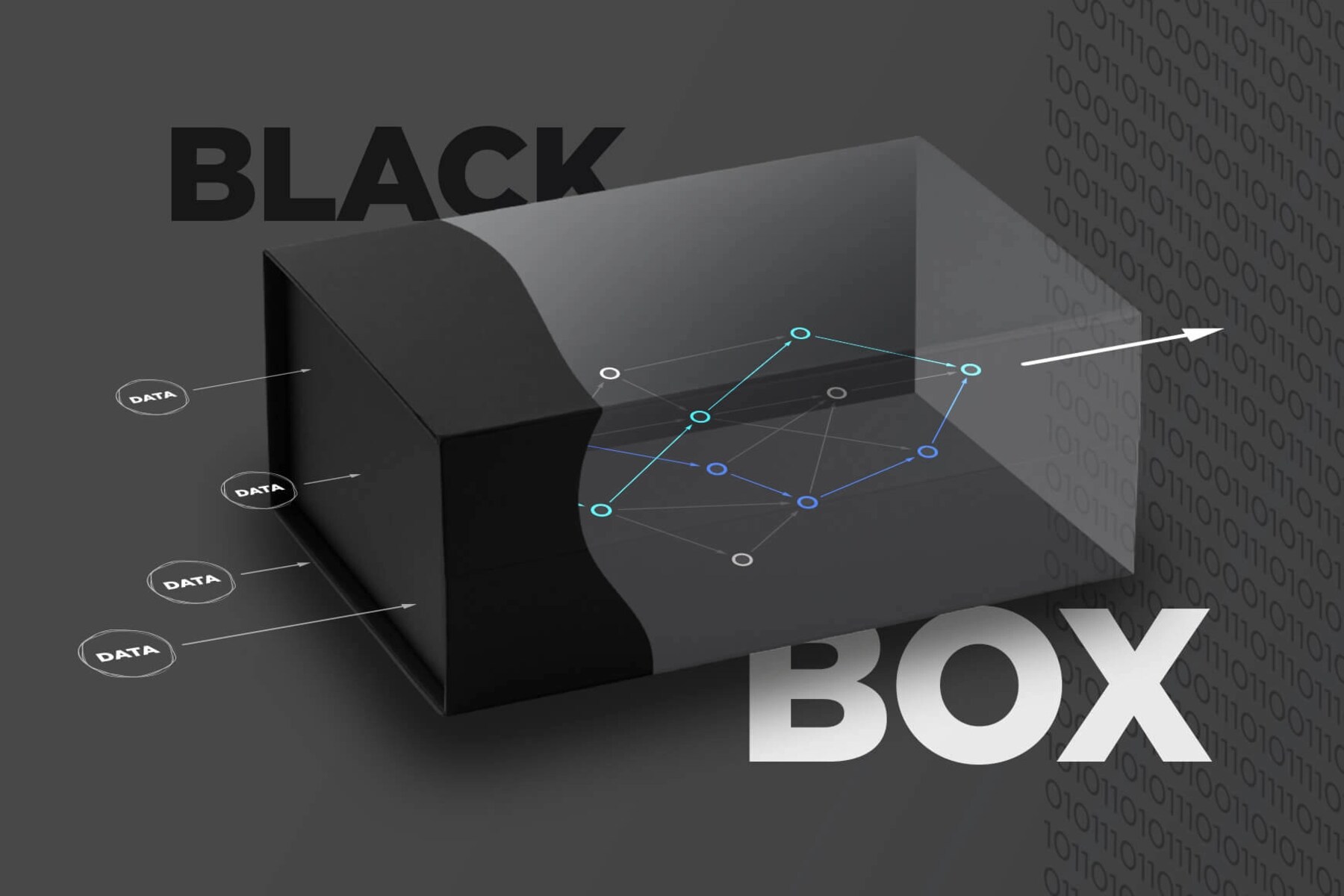
Another limitation is the interpretability of machine learning models. Deep learning, in particular, has gained significant popularity but is often regarded as a “black box” because it can be challenging to explain how and why the model makes its predictions. Lack of interpretability can be a drawback, especially in critical domains like healthcare or legal systems, where the ability to explain the model’s decision-making process is essential.
Machine learning models are also sensitive to changes in the input data. They might produce different results or exhibit reduced performance when exposed to data that differ from the training distribution. This limitation, known as distribution shift, can occur due to changes in the environment, user behavior, or technology. Models need to be continuously monitored and updated to accommodate such shifts and maintain their effectiveness.
Furthermore, machine learning models are only as good as the data they are trained on. Models can inadvertently pick up biases or discriminatory patterns present in the training data, leading to biased predictions or unfair outcomes. Special care must be taken to ensure fairness and avoid perpetuating existing biases or discriminations through machine learning systems.
The computational requirements of machine learning models can also be a limitation. Complex models, such as deep learning architectures, often require substantial computational resources and high-performance hardware to train and deploy. This can pose challenges for individuals or organizations with limited access to computing power or financial resources.
The ethical implications of using machine learning also cannot be disregarded. Machine learning algorithms can impact individuals’ lives, influence decision-making processes, and have wide-ranging societal impacts. Concerns regarding privacy, security, and accountability arise when machine learning is employed in sensitive domains like healthcare, finance, or criminal justice. Understandably, ensuring ethical use and addressing potential biases and discriminatory outcomes are critical in the development and deployment of machine learning systems.
Lastly, machine learning models are not a one-size-fits-all solution. Each model has its own strengths, limitations, and assumptions. Their performance can vary depending on the specific problem domain and the characteristics of the data. It is important to carefully consider the suitability and applicability of machine learning models for specific tasks, as they may not always be the best approach or the most effective solution.
In summary, machine learning has its limitations and potential drawbacks, including data reliance, interpretability challenges, sensitivity to distribution shifts, potential biases, computational requirements, ethical considerations, and limited applicability. Understanding and addressing these limitations is essential for responsible and effective use of machine learning in various domains.
In the next section, we will wrap up the article by summarizing the key points discussed and providing a final perspective on machine learning.
Conclusion
Machine learning is a powerful field that has the potential to transform industries and impact our daily lives. It enables computers to learn from data and make predictions or decisions without being explicitly programmed. However, it is essential to understand the complexities, limitations, and challenges that come with utilizing machine learning techniques.
We explored the intricacies of machine learning algorithms, the role of data in training models, the importance of feature selection and engineering, challenges in model training, evaluating model performance, and the potential biases and drawbacks of machine learning.
Machine learning algorithms can be complex, requiring an understanding of mathematical concepts, statistics, and programming. Proper data collection, preprocessing, and feature engineering are crucial to ensure accurate and meaningful predictions. Challenges such as bias, overfitting, and computation requirements must be addressed to develop robust and reliable models.
Evaluating the performance of machine learning models involves selecting appropriate metrics, employing techniques like cross-validation, and considering task-specific requirements. Overcoming bias and overfitting are critical for fair and accurate predictions. Continual monitoring, updating, and addressing ethical concerns are necessary to ensure responsible use of machine learning in real-world applications.
Despite its limitations, machine learning has made significant advancements and continues to enhance various industries. The ability to process vast amounts of data, identify patterns, and make predictions has led to improvements in healthcare, finance, marketing, and many other domains.
As technology advances and more data becomes available, machine learning will likely play an even more prominent role in shaping our future. It is crucial for researchers, practitioners, and policymakers to collaborate and address the challenges and ethical implications associated with machine learning.
Applying machine learning in a responsible and conscientious manner can lead to innovative solutions, informed decision-making, and substantial societal benefits. With ongoing efforts to improve algorithms, address biases, and develop ethical frameworks, machine learning has the potential to transform our lives in profound ways.