Introduction
Machine learning, a subfield of artificial intelligence, has gained significant attention and usage in various industries. It involves developing algorithms and models that enable computers to learn and improve from data without being explicitly programmed. One crucial aspect of machine learning is evaluating the performance of these models, which helps in making informed decisions about their effectiveness.
When it comes to evaluating the performance of classification models, metrics such as accuracy, precision, recall, and F1 score play a vital role. In this article, we will delve into the concept of F1 score, which is widely used to assess the effectiveness of classification models in machine learning.
Have you ever wondered how to measure the accuracy of a model, considering both precision and recall? The F1 score is a metric that combines these two measures into a single value, providing a comprehensive evaluation of the model’s performance. It is particularly useful when dealing with imbalanced datasets, where the number of instances in one class is significantly higher than the other.
The F1 score is widely favored in several applications, including text classification, sentiment analysis, fraud detection, and medical diagnosis. It provides a balanced view of a model’s ability to correctly classify instances, regardless of disproportionate class distribution.
In the next section, we will explore the calculation of F1 score, which will give us a clearer understanding of how it captures the trade-off between precision and recall. Let’s dive in!
What is F1 Score?
The F1 score is a statistical measure widely used in machine learning to evaluate the accuracy and performance of classification models. It is derived from the concepts of precision and recall, which are two fundamental metrics for evaluating a model’s ability to correctly classify instances.
Precision measures the proportion of correctly predicted positive instances out of all instances predicted as positive. It focuses on the accuracy of the positive predictions made by the model. Recall, on the other hand, measures the proportion of correctly predicted positive instances out of the actual positive instances in the dataset. It focuses on the model’s ability to correctly identify all positive instances.
The F1 score combines precision and recall into a single value to provide a balanced evaluation of a model’s performance. It is the harmonic mean of precision and recall, giving equal importance to both measures. The F1 score ranges from 0 to 1, with 1 being the best possible score representing perfect precision and recall.
The F1 score is particularly useful when dealing with imbalanced datasets, where one class is significantly more prevalent than the other. In such cases, a high accuracy score alone can be misleading, as the model might perform well on the majority class but poorly on the minority class. The F1 score, by considering both precision and recall, offers a more comprehensive evaluation of the model’s performance.
It is important to note that the F1 score is a valuable metric when the focus is on finding a balance between precision and recall. However, in some specific cases, precision or recall may be more critical depending on the problem at hand. Therefore, it is crucial to consider the specific requirements of the application when interpreting the F1 score.
In the next section, we will explore how the F1 score is calculated, which will shed light on how it combines precision and recall to provide a unified measure of a classification model’s performance.
How is F1 Score calculated?
The F1 score is calculated using the precision and recall values of a classification model. It combines these two measures to provide a single value that represents the overall performance of the model.
To calculate the F1 score, we first need to compute the precision and recall. Precision is calculated by dividing the number of true positive predictions by the sum of true positive and false positive predictions:
Precision = TP / (TP + FP)
where TP represents the number of true positive predictions and FP represents the number of false positive predictions.
Similarly, recall is calculated by dividing the number of true positive predictions by the sum of true positive and false negative predictions:
Recall = TP / (TP + FN)
where TP represents the number of true positive predictions and FN represents the number of false negative predictions.
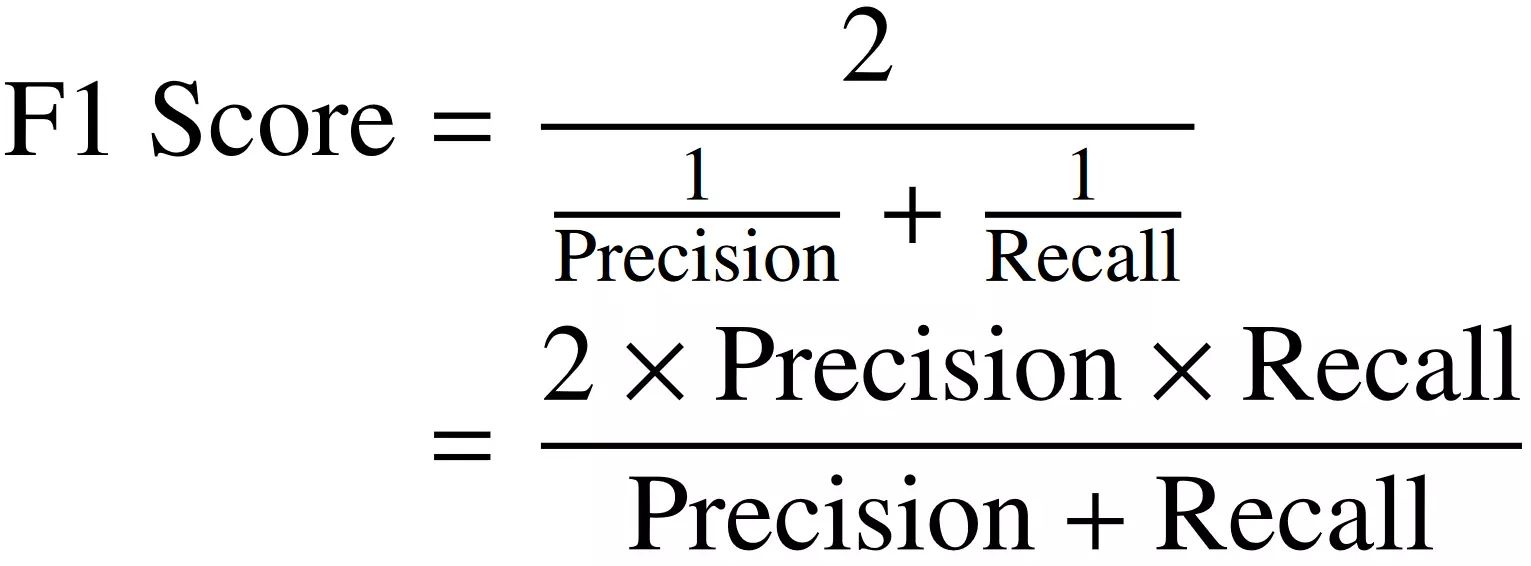
Once we have the precision and recall values, we can calculate the F1 score using the formula:
F1 Score = 2 * ((Precision * Recall) / (Precision + Recall))
The F1 score is the harmonic mean of precision and recall, which ensures that the score gives equal weightage to both measures. The harmonic mean gives more importance to lower values, which means that if either precision or recall is low, the F1 score will be significantly affected. This makes the F1 score a useful metric for evaluating models in scenarios where both precision and recall are crucial.
Once the precision, recall, and F1 score are calculated, these metrics can be used to analyze and compare the performance of different classification models. The higher the F1 score, the better the model’s ability to correctly classify instances while maintaining a balance between precision and recall.
Now that we understand how the F1 score is calculated, let’s explore why it is an important metric in machine learning.
Why is F1 Score important in machine learning?
The F1 score is a crucial metric in machine learning for several reasons. It provides a balanced evaluation of a classification model’s performance by considering both precision and recall. Here are a few reasons why the F1 score is important:
1. Evaluating model performance: The F1 score offers a comprehensive assessment of a model’s accuracy. Accuracy alone may not be sufficient, especially when dealing with imbalanced datasets or when both precision and recall are critical. The F1 score considers both measures, providing a more reliable evaluation of the model’s effectiveness.
2. Dealing with class imbalance: In classification problems where one class is significantly more prevalent than the other, accuracy can be misleading. A model that predicts the majority class with high accuracy may perform poorly on the minority class. The F1 score mitigates this issue by considering both precision and recall, allowing for a fair assessment of the model’s performance on both classes.
3. Identifying trade-offs: The F1 score helps to identify the trade-off between precision and recall. Depending on the specific application, either precision or recall may be more critical. For example, in medical diagnosis, recall is crucial to minimize false negatives, while in spam detection, precision is important to reduce false positives. The F1 score helps strike a balance between these two measures.
4. Model selection and comparison: When evaluating multiple classification models, the F1 score provides a standardized metric to compare their performance. By considering both precision and recall, the F1 score enables researchers and practitioners to make informed decisions about the most suitable model for their specific use case.
5. Performance optimization: Maximizing the F1 score can guide model optimization efforts. By analyzing the impact of different algorithms, techniques, or hyperparameter settings on the F1 score, machine learning practitioners can fine-tune their models to achieve the best overall performance.
Overall, the F1 score plays a crucial role in machine learning by providing a balanced and informative evaluation of a classification model’s performance. It helps to overcome the limitations of accuracy, especially in scenarios with imbalanced datasets or when considering both precision and recall. By leveraging the F1 score, practitioners can make more effective decisions, optimize models, and improve the overall accuracy of classification tasks.
Now that we understand the importance of the F1 score, let’s discuss some limitations associated with its usage.
Limitations of F1 Score
While the F1 score is a valuable metric for evaluating classification models, it is essential to be aware of its limitations. Understanding these limitations can help researchers and practitioners interpret the results effectively and make informed decisions. Here are some of the key limitations of the F1 score:
1. Equal weighting of precision and recall: The F1 score gives equal importance to precision and recall by taking their harmonic mean. However, in some cases, precision or recall may be more critical than the other. For example, in medical diagnoses, recall (to minimize false negatives) might be more important than precision. Therefore, relying solely on the F1 score may not provide a complete picture of a model’s performance, and it is crucial to consider the specific requirements of the application.
2. Imbalanced datasets: The F1 score can be influenced by class imbalance, where one class has significantly more instances than the other. In such cases, the F1 score may not accurately reflect the performance on the minority class. It is important to consider additional metrics and techniques, such as stratified sampling or resampling methods, to effectively evaluate model performance in imbalanced datasets.
3. Threshold dependency: The F1 score is calculated based on a specific classification threshold. However, different threshold values can yield different F1 scores. The optimal threshold depends on the specific task, and finding the right balance between precision and recall is often problem-dependent. Therefore, it is crucial to consider the F1 score alongside precision-recall curves or other threshold-dependent metrics to make informed decisions.
4. Insensitivity to true negatives: The F1 score does not take into account the number of true negatives (TN) in the classification task. This can be problematic when evaluating models on datasets with a high proportion of true negatives. In such cases, the F1 score may overemphasize classification performance without considering the correct rejection of negative instances.
5. Context-specific evaluation: The F1 score provides a general evaluation of model performance, but it may not capture the specific requirements of the application or domain. Different tasks may prioritize precision, recall, or a specific trade-off differently. Therefore, it is essential to consider the specific context and requirements when interpreting and using the F1 score.
Despite these limitations, the F1 score remains a valuable metric for evaluating classification models. Acknowledging these limitations and considering them in conjunction with other metrics can help researchers and practitioners gain a more comprehensive understanding of a model’s performance.
Now that we have explored the limitations of the F1 score, let’s wrap up our discussion.
Conclusion
The F1 score is an important metric in machine learning for evaluating the performance of classification models. It combines precision and recall, providing a balanced measure of a model’s ability to correctly classify instances. By taking their harmonic mean, the F1 score offers a comprehensive evaluation that is particularly useful in scenarios with imbalanced datasets or when both precision and recall are crucial.
Throughout this article, we learned that the F1 score plays a vital role in machine learning by enabling researchers and practitioners to assess model performance, make informed decisions, and optimize classification tasks. It helps overcome the limitations of accuracy and provides a standardized metric for comparing different models.
However, it’s crucial to be mindful of the limitations of the F1 score. Its equal weighting of precision and recall may not always align with specific requirements, and it may be influenced by class imbalance and threshold dependency. Additionally, it does not consider true negatives and may not capture the context-specific evaluation of a task.
Despite these limitations, the F1 score remains a valuable tool in evaluating classification models. By understanding its strengths and weaknesses, we can use it effectively alongside other metrics and considerations to make robust decisions.
In conclusion, the F1 score provides a balanced and informative evaluation of a classification model’s performance. It serves as a valuable guide in optimizing models, addressing class imbalance, and making informed decisions in machine learning applications.