Introduction
When it comes to information retrieval, the ability to efficiently process and analyze large volumes of data is crucial. This is where tokenization plays a vital role. Tokenization is a fundamental concept in the field of Natural Language Processing (NLP) that involves breaking down textual data into smaller units called tokens. These tokens can be individual words, phrases, or even sentences. By dividing the data into tokens, it becomes easier to perform various operations such as indexing, searching, and analyzing textual information.
Tokenization serves as a crucial step in many natural language processing applications, including search engines, text analysis, machine translation, and sentiment analysis, to name a few. By breaking down text into meaningful units, tokenization enables efficient data processing and retrieval, facilitating accurate analysis and extraction of valuable insights.
Tokenization plays a vital role in information retrieval by providing several benefits. Firstly, it helps in reducing the dimensionality of textual data, making it easier to handle and process. Additionally, tokenization allows for improved search and retrieval accuracy by enabling more precise matching of search queries with indexed tokens. Furthermore, tokenization facilitates the extraction of crucial information from unstructured text, enabling better insights and decision-making.
The tokenization process involves several steps. It begins with text segmentation, where the input data is divided into sentences or paragraphs. The next step involves breaking down these sentences or paragraphs into individual words, known as word tokenization. Additionally, tokenization may involve other techniques such as stemming, which reduces words to their base or root form, and stop-word removal, which eliminates commonly used words that do not carry significant meaning.
Various tokenization techniques are used depending on the specific requirements of the application. Some common techniques include whitespace tokenization, which separates words based on spaces or punctuation marks, and regular expression-based tokenization, which allows for more complex pattern matching. Another technique is dictionary-based tokenization, which uses pre-defined dictionaries to identify and process tokens.
However, tokenization also poses certain challenges. Ambiguous words, special characters, abbreviations, and domain-specific terms can complicate the tokenization process. Additionally, different languages and writing systems may require specific tokenization techniques tailored to their unique characteristics.
Overall, tokenization is a critical component of information retrieval systems, allowing for efficient and accurate processing of textual data. Through its various techniques and processes, tokenization enables improved search and retrieval, enhanced data analysis, and better insights from unstructured text. In the following sections, we will explore the different tokenization techniques, common challenges faced, and the benefits of tokenization in information retrieval.
Definition of Tokenization
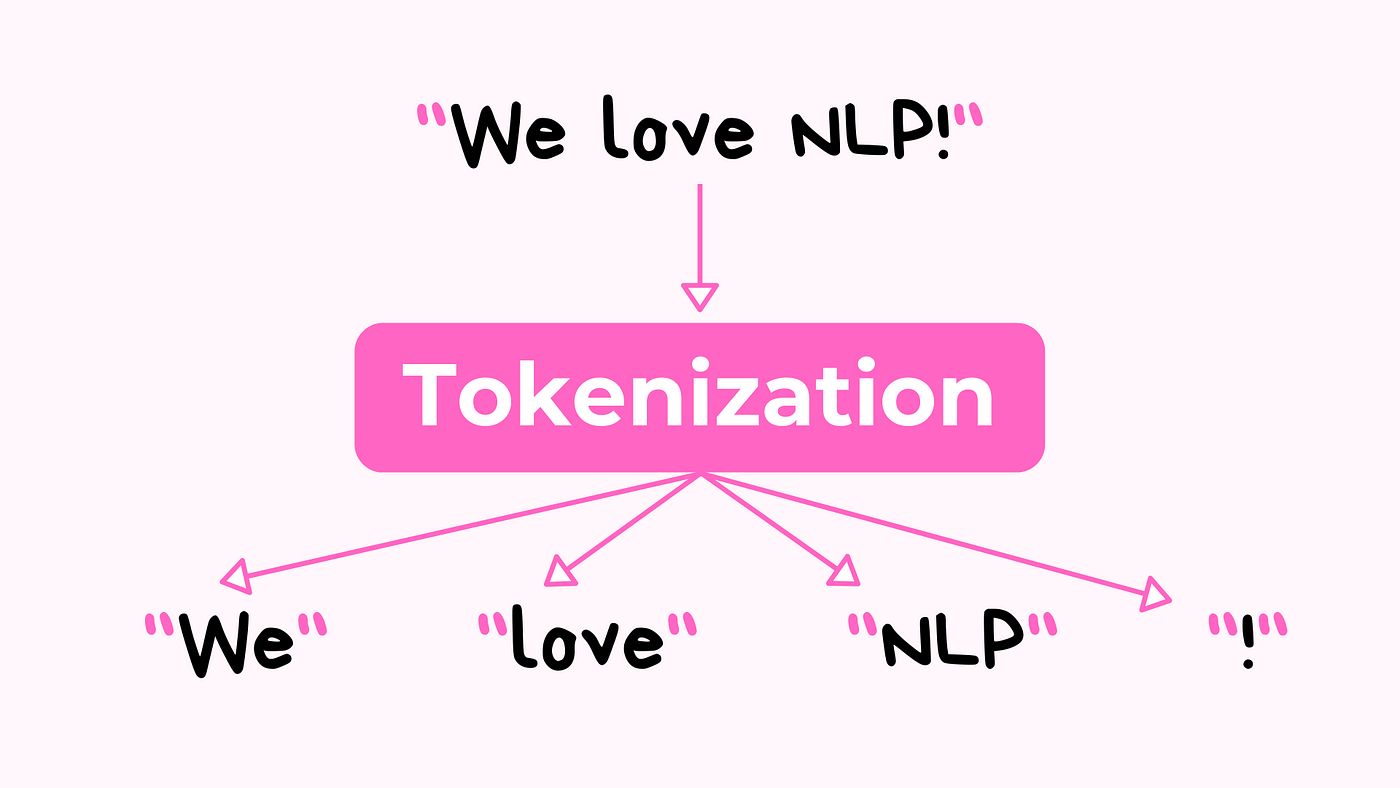
Tokenization is the process of dividing textual data into smaller units called tokens. These tokens can be individual words, phrases, or even sentences. These units serve as the building blocks for further analysis and processing of textual information.
Tokenization is a fundamental concept in Natural Language Processing (NLP) and information retrieval. It plays a crucial role in breaking down unstructured text into meaningful units that can be easily processed, indexed, and searched. By segmenting text into tokens, tokenization enables efficient analysis, retrieval, and analysis of textual data.
The objective of tokenization is to decompose text into smaller, more manageable units that carry semantic and contextual significance. Breaking down text into tokens allows for the application of various linguistic and computational techniques to derive meaningful insights from the data. Tokens can be used for indexing, matching search queries, language modeling, sentiment analysis, and many other text-processing tasks.
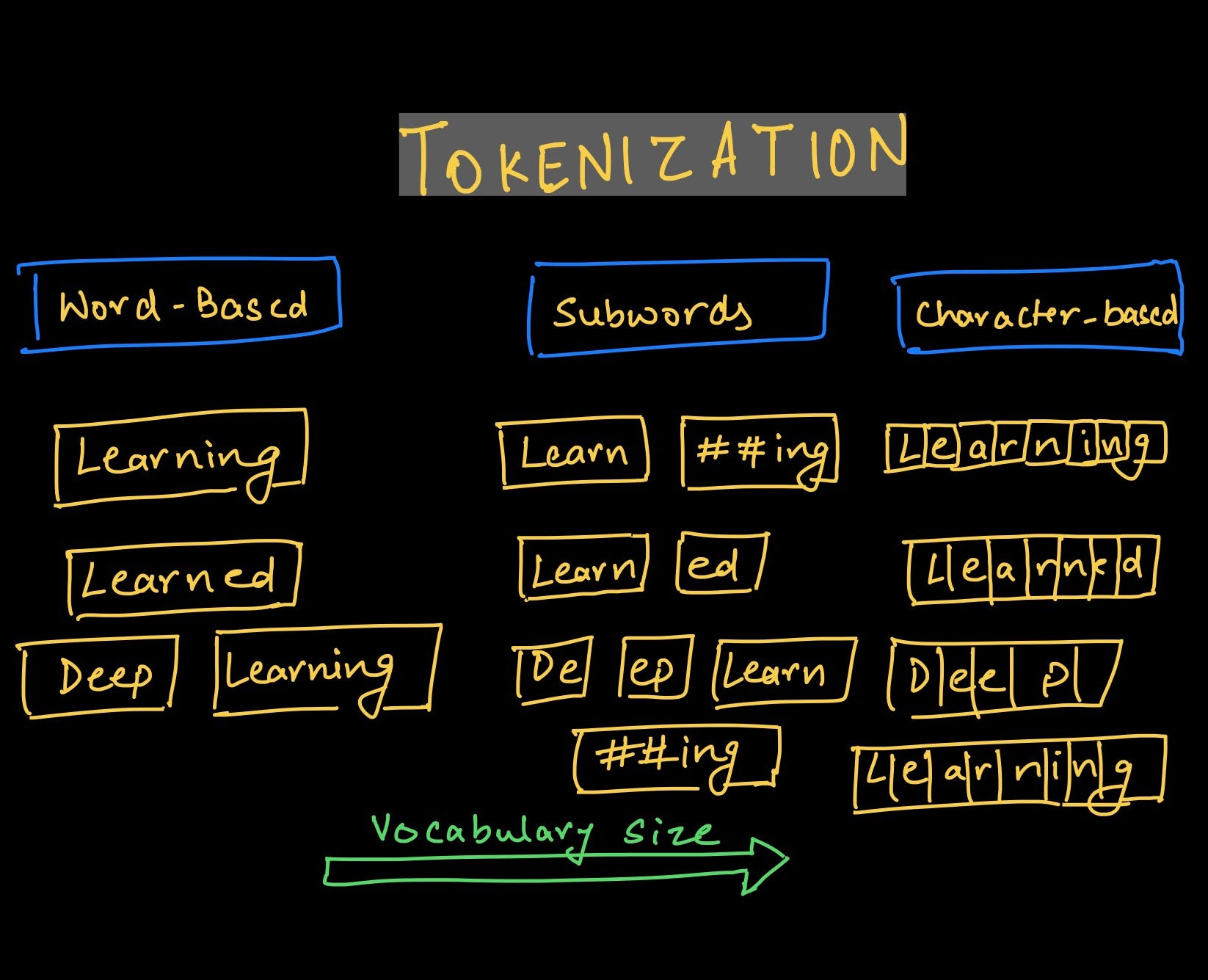
There are different levels of tokenization depending on the granularity desired. Word tokenization is the most common form, where the text is split into individual words. However, tokenization can also involve the splitting of text into phrases or sentences, depending on the specific requirements of the application.
The tokenization process typically involves several steps. It begins by segmenting the text into sentences or paragraphs. From there, the sentences are further divided into individual tokens, usually words, by separating them based on spaces or punctuation marks. The tokens can then undergo additional processing steps such as stemming, where words are reduced to their base or root form, or stop-word removal, which eliminates commonly used words that do not carry significant meaning.
Tokenization techniques can vary depending on the language, writing system, and specific requirements of the task at hand. There are rule-based techniques, such as whitespace tokenization and regular expression-based tokenization, which allow for more complex pattern matching. Dictionary-based tokenization uses pre-defined dictionaries to identify and process tokens, making it suitable for domain-specific tokenization.
Overall, tokenization is a vital step in information retrieval and NLP applications. By breaking down text into meaningful units, tokenization enables efficient processing, analysis, and retrieval of textual data. It forms the foundation for various text-processing tasks and plays a significant role in extracting insights and facilitating decision-making from unstructured text.
Importance of Tokenization in Information Retrieval
Tokenization plays a crucial role in information retrieval, providing several key benefits and enabling efficient handling and analysis of textual data. Let’s explore why tokenization is important in the context of information retrieval:
1. Improved search and retrieval accuracy: Tokenization allows for more precise matching of search queries with indexed tokens. By breaking down text into individual tokens, tokenization enables more accurate and relevant search results. This is particularly useful in search engines, where efficient retrieval of relevant information is paramount.
2. Efficient indexing and storage: Tokenization reduces the dimensionality of textual data by breaking it down into smaller units. This makes it easier to index and store the data, improving the performance of information retrieval systems. By indexing tokens instead of entire documents, search engines can retrieve relevant results faster, leading to a better user experience.
3. Facilitates language processing techniques: Tokenization provides the foundation for various language processing techniques such as stemming, part-of-speech tagging, and sentiment analysis. These techniques rely on the accurate identification and processing of individual tokens to derive meaningful insights from the text. For example, stemming reduces words to their base form, allowing for better analysis of word frequency and relationship.
4. Enables better data analysis and insights: Tokenization paves the way for deeper analysis of textual data. By breaking down text into smaller units, it becomes easier to extract valuable information, identify patterns, and derive insights. Tokenization allows for various analytical techniques such as keyword extraction, topic modeling, and text classification, enabling better understanding and interpretation of unstructured text.
5. Supports multilingual and domain-specific processing: Tokenization techniques can be tailored to handle different languages and writing systems. This is particularly important in multilingual environments where information retrieval systems need to handle diverse textual data. Tokenization can also be customized for specific domains, allowing for more accurate and relevant analysis of industry-specific text.
6. Enhanced text preprocessing: Tokenization is a crucial step in text preprocessing, where unstructured text data is cleaned and transformed into a more manageable format. By breaking down text into tokens, it becomes easier to remove irrelevant elements such as stop words or punctuation marks. This results in cleaner and more meaningful data, improving the quality of subsequent analysis and retrieval processes.
In summary, tokenization is of utmost importance in information retrieval. From improving search and retrieval accuracy to enabling advanced language processing techniques, tokenization plays a vital role in handling textual data effectively. It allows for efficient indexing, storage, and analysis of text, ultimately leading to better insights and decision-making from unstructured information.
Tokenization Process
The tokenization process involves transforming textual data into smaller units called tokens. These tokens serve as the building blocks for further analysis and processing of the text. The tokenization process typically follows these steps:
1. Text Segmentation: The first step in the tokenization process is segmenting the input text into smaller units, such as sentences or paragraphs. This segmentation step helps in organizing the text and setting boundaries for subsequent tokenization.
2. Word Tokenization: Once the text is segmented, the next step is to break down the sentences or paragraphs into individual words. This process is known as word tokenization or word boundary detection. The text is divided based on spaces or punctuation marks between words. For example, the sentence “Tokenization is important in information retrieval” would be tokenized into the tokens: “Tokenization”, “is”, “important”, “in”, “information”, “retrieval”.
3. Stemming and Lemmatization: In some cases, stemming and lemmatization techniques can be applied to further process the tokens. Stemming reduces words to their base or root form, such as converting “running” to “run”. Lemmatization, on the other hand, converts words to their dictionary or base form, such as converting “went” to “go”. These techniques help to reduce word variations and consolidate the token set.
4. Stop-word Removal: Stop words are commonly used words without much significance in the analysis process, such as “a,” “and,” or “the”. Removing stop words can improve the accuracy and efficiency of the tokenization process by eliminating irrelevant tokens.
5. Special Character Handling: Tokenization also involves special character handling. For example, handling contractions like “can’t” by either splitting it into “can” and “not” or preserving it as a single token depends on the specific requirements of the application. Similarly, handling punctuation marks like hyphens, apostrophes, or periods can vary depending on the context.
6. Token Normalization: Token normalization is the process of standardizing tokens to ensure consistent representation. This can involve converting tokens to lowercase, removing diacritics or accents, or transforming numbers into a common format.
7. Token Encoding: Once the tokens are prepared, they need to be encoded to a suitable format for storage, indexing, and further retrieval. This encoding can involve converting the tokens into a numerical representation or specific encoding schemes like UTF-8 for compatibility.
It is important to note that the tokenization process may vary depending on the specific requirements of the application, language, or writing system being analyzed. Different tokenization techniques and steps may be employed accordingly to handle the complexities of the text.
In summary, the tokenization process involves segmenting text, breaking it down into individual words, applying techniques like stemming and stop-word removal, handling special characters, normalizing tokens, and encoding them for further analysis. The goal of tokenization is to transform text into meaningful units that can be processed, indexed, and retrieved efficiently for various information retrieval and natural language processing tasks.
Tokenization Techniques
Tokenization techniques vary depending on the specific requirements of the application, language, and text being analyzed. Here are some commonly used tokenization techniques:
1. Whitespace Tokenization: This technique involves breaking text into tokens based on whitespace or punctuation marks. Words are separated by spaces or specific characters, such as commas or periods. For example, the sentence “Tokenization is important in information retrieval” would be tokenized into the tokens “Tokenization,” “is,” “important,” “in,” “information,” and “retrieval.”
2. Regular Expression-Based Tokenization: Regular expression-based tokenization allows for more complex pattern matching. It involves specifying regular expressions that define the desired token boundaries. This technique provides more flexibility in handling specific tokenization requirements, such as handling complex compound words or extracting specific patterns from the text.
3. Dictionary-Based Tokenization: Dictionary-based tokenization relies on pre-defined dictionaries to identify and process tokens. The dictionaries contain a list of known words or phrases that should be considered as single tokens. This technique is useful for domain-specific tokenization or when dealing with specialized terminology. It ensures that domain-specific terms are recognized as individual units, even if they consist of multiple words.
4. Rule-Based Tokenization: Rule-based tokenization involves applying a set of predefined rules to determine token boundaries. These rules can be based on grammatical patterns, language-specific conventions, or specific requirements of the application. For example, rule-based tokenization may involve splitting text at certain punctuation marks or combining specific abbreviations into single tokens.
5. N-gram Tokenization: N-gram tokenization involves breaking text into consecutive sequences of n items. This technique creates tokens that consist of n words, characters, or phonemes. N-gram tokenization is commonly used in language modeling, where the model predicts the probability of the next word given the preceding n-1 words.
6. Statistical Tokenization: Statistical tokenization utilizes statistical models to determine token boundaries. These models analyze the frequency and patterns of words in a corpus to estimate the optimal tokenization boundaries. Statistical tokenization takes into account the context and distribution of words to make informed decisions about tokenization boundaries.
7. Customized Tokenization: In certain cases, customized tokenization techniques may be developed to handle specific requirements of the application or language. This can involve combining multiple techniques or adapting existing techniques to suit the unique characteristics of the text being analyzed.
It’s important to note that tokenization techniques may be combined or modified depending on the specific needs of the application. The choice of tokenization technique depends on factors such as language, text complexity, domain-specific considerations, and the desired granularity of the tokens.
In summary, tokenization techniques play a crucial role in breaking down text into meaningful units. Techniques like whitespace tokenization, regular expression-based tokenization, dictionary-based tokenization, rule-based tokenization, N-gram tokenization, statistical tokenization, and customized tokenization provide flexibility and accuracy in handling different types of text and languages.
Common Challenges of Tokenization
Tokenization is a fundamental process in information retrieval, but it also poses certain challenges. Here are some common challenges that can arise during the tokenization process:
1. Ambiguous Words: Words with multiple meanings can create ambiguity during tokenization. For example, the word “run” can be a noun or a verb, and it may carry different semantic implications depending on the context. Tokenizing such words accurately requires considering the surrounding context or employing advanced language processing techniques.
2. Special Characters: Special characters like hyphens, apostrophes, or periods pose challenges in tokenization. These characters can have different meanings or functions in different contexts. Tokenization techniques need to be flexible enough to handle variations such as hyphenated words or contractions.
3. Abbreviations: Abbreviations and acronyms can complicate tokenization. They may be represented both with and without periods, or they may have inconsistent casing or spacing. Tokenization techniques need to be capable of identifying and handling different forms of abbreviations to ensure accurate representation of the intended tokens.
4. Domain-Specific Terms: In specialized domains, unique terminology or domain-specific jargon can pose challenges in tokenization. These terms may not adhere to conventional tokenization rules and may require customized techniques or specialized dictionaries to ensure that they are recognized as individual tokens.
5. Nonstandard Spelling or Variations: Texts with nonstandard spellings, dialects, or variations can make tokenization more challenging. Different regional variations or informal language may require specific tokenization rules to capture the intended meaning and preserve the authenticity of the text.
6. Different Languages and Writing Systems: Tokenization becomes more complex when dealing with multilingual or multialphabet texts. Different languages and writing systems may have unique tokenization rules, such as character-based tokenization in some Asian languages or morpheme-based tokenization in agglutinative languages, making it necessary to employ language-specific tokenization techniques.
7. Negation and Sentiment: Tokenization can impact the interpretation of negations and sentiment in text. Words like “not” or “never” can change the meaning of the following word, and accurate tokenization is crucial in capturing this relationship. Tokenization techniques need to handle such cases to ensure accurate sentiment analysis or language understanding.
8. Handling Unstructured Text: Tokenization often deals with unstructured text, such as social media posts or user-generated content, which can have noisy and unpredictable patterns. Tokenization techniques need to be adaptable to handle the unique challenges of processing unstructured text while maintaining reasonable accuracy.
It is important to address these challenges with appropriate techniques and considerations to ensure accurate and meaningful tokenization. Language-specific rules, advanced natural language processing techniques, and domain-specific knowledge can all help overcome these challenges and improve the effectiveness of the tokenization process.
In summary, tokenization can face common challenges related to ambiguous words, special characters, domain-specific terms, nonstandard spelling, different languages and writing systems, sentiment analysis, and handling unstructured text. Overcoming these challenges through the use of suitable techniques and linguistic knowledge is crucial to ensure accurate tokenization and effective information retrieval.
Benefits of Tokenization in Information Retrieval
Tokenization plays a vital role in information retrieval, offering several key benefits that enhance the efficiency and effectiveness of the retrieval process. Here are some of the benefits of tokenization:
1. Improved Search Accuracy: By breaking down text into tokens, tokenization enables more precise matching of search queries with indexed tokens. This improves the accuracy and relevance of search results, allowing users to find the most relevant information quickly and efficiently. Tokenization minimizes the chances of mismatches and enhances the overall search experience.
2. Efficient Indexing and Retrieval: Tokenization reduces the dimensionality of textual data by breaking it down into smaller units. This significantly improves the efficiency of indexing and retrieval processes in information retrieval systems. Indexing tokens instead of entire documents enables faster and more optimized retrieval of relevant information, resulting in reduced response times and improved system performance.
3. Facilitates Language Processing Techniques: Tokenization serves as the foundation for various language processing techniques such as stemming, part-of-speech tagging, and named entity recognition. These techniques rely on the accurate identification and processing of individual tokens to derive meaningful insights from the text. Tokenization enables efficient application of these techniques, helping to extract valuable information and enhance language understanding in the information retrieval process.
4. Extraction of Key Information: Tokenization facilitates the extraction of crucial information from unstructured text. By breaking down text into tokens, information retrieval systems can better identify and extract important entities, keywords, or phrases. Tokenization enables better analysis of word frequency, document relevance, and the relationship between tokens, leading to better insights and more informed decision-making based on the retrieved information.
5. Customized Text Processing: Tokenization allows for customized text processing according to specific requirements. Different tokenization techniques can be employed based on the language, domain, or application requirements. Customization enables better handling of domain-specific terms, specialized jargon, and unique linguistic patterns, resulting in more accurate and meaningful information retrieval.
6. Handling Multilingual Data: Tokenization techniques can be adapted to handle multilingual data effectively. By employing language-specific tokenization rules, information retrieval systems can tokenize and process text in different languages, improving the retrieval accuracy and catering to diverse user needs in multilingual environments.
7. Scalability and Flexibility: Tokenization provides scalability and flexibility to information retrieval systems. By tokenizing text into smaller units, the system becomes more adaptable to different types of text. This allows for more efficient processing of large volumes of data from various sources and supports the scalability requirements of modern information retrieval applications.
In summary, tokenization brings numerous benefits to information retrieval systems. By improving search accuracy, enabling efficient indexing and retrieval, facilitating language processing techniques, extracting key information, allowing for customized text processing, handling multilingual data, and providing scalability and flexibility, tokenization enhances the overall effectiveness and efficiency of information retrieval processes.
Use Cases of Tokenization
Tokenization is a versatile process that finds application in various domains and information retrieval systems. Let’s explore some of the common use cases of tokenization:
1. Search Engines: Tokenization is essential for search engines as it enables efficient and accurate retrieval of relevant information. By breaking down documents and search queries into tokens, search engines can match and compare the tokens to deliver precise search results. Tokenization helps to eliminate noise and improve the accuracy of search engine rankings.
2. Text Analysis and Mining: Tokenization plays a crucial role in text analysis and mining tasks. By dividing text into tokens, it becomes possible to perform keyword extraction, sentiment analysis, topic modeling, and text classification. Tokenization serves as a foundation for these techniques, allowing for deeper understanding and extraction of insights from textual data.
3. Natural Language Processing (NLP): Tokenization is a fundamental step in NLP applications. It enables various language processing techniques like part-of-speech tagging, named entity recognition, and syntactic parsing. Tokenization breaks down text into meaningful units, making it possible to identify and analyze language structures, relationships, and semantic features.
4. Machine Translation: Tokenization is crucial in machine translation systems. It helps to segment source texts into tokens, enabling translation algorithms to process and transform the text more accurately. By tokenizing both the source and target languages, machine translation systems can align corresponding tokens and generate more effective translations.
5. Information Extraction: Tokenization is used in information extraction systems to identify important entities and relationships from unstructured text. By tokenizing text, these systems can isolate relevant terms and phrases, allowing for the extraction of specific information such as names, dates, locations, and other structured data.
6. Content Analysis: Tokenization is valuable in content analysis applications, such as social media monitoring or customer feedback analysis. By tokenizing text, it becomes possible to categorize or analyze user-generated content, identify trends, sentiments, or specific keywords, and gain insights into customer preferences or sentiment towards products or services.
7. Voice Recognition and Speech Processing: Tokenization is used in voice recognition and speech processing systems to convert spoken language into written text. By tokenizing the transcribed speech, it becomes easier to perform subsequent language processing tasks, such as sentiment analysis, keyword extraction, or dialogue management.
8. Information Retrieval on Web Pages: Tokenization is critical for web crawling and indexing. By tokenizing the contents of web pages, search engines can extract valuable information, index the data, and provide more accurate search results to users. Tokenization allows for improved analysis of keywords, HTML tags, and other structural elements in web pages.
9. Sentiment Analysis: Tokenization is essential in sentiment analysis systems. By breaking down text into tokens, sentiment analysis algorithms can identify and analyze subjective words or expressions, allowing for the classification of text into positive, negative, or neutral sentiment categories. Tokenization assists in accurately detecting sentiment-related features within the text.
10. Named Entity Recognition (NER): Tokenization is a critical component of NER systems that identify and classify named entities in text, such as person names, organization names, locations, or dates. By tokenizing the text, NER algorithms can target specific tokens and apply entity classification, enabling accurate extraction of important information.
These are just some of the many use cases of tokenization across different domains and applications. Tokenization serves as a foundational process that enables efficient information retrieval, language understanding, analysis, and extraction of insights from textual data.
Conclusion
Tokenization plays a fundamental role in information retrieval, enabling the efficient processing, analysis, and retrieval of textual data. By breaking down text into meaningful units called tokens, tokenization allows for improved search accuracy, efficient indexing and retrieval, and facilitates various language processing techniques. Tokenization provides several benefits, including better search results, enhanced data analysis, and better insights from unstructured text.
Throughout this article, we explored the definition and importance of tokenization in information retrieval. We discussed the tokenization process and the techniques used to divide text into tokens. Additionally, we explored the common challenges faced during tokenization and how they can be overcome. We also highlighted the diverse use cases of tokenization, ranging from search engines and text analysis to machine translation and sentiment analysis.
Tokenization is a versatile and essential step in information retrieval systems and natural language processing applications. Whether it’s improving search accuracy, enabling customized text processing, supporting multilingual data, or facilitating advanced language analysis techniques, tokenization plays a crucial role in enhancing the effectiveness and efficiency of information retrieval processes.
As technology continues to advance, the importance of tokenization will only increase. With the growing volume of text data and the need for better insights, accurate tokenization will play a crucial role in extracting valuable information and supporting decision-making processes.
Understanding the significance of tokenization and leveraging appropriate tokenization techniques is crucial for researchers, developers, and businesses working with textual data. By implementing effective tokenization processes, information retrieval systems can deliver more accurate and relevant results, improving user experiences and providing valuable insights from unstructured text.
In conclusion, tokenization is a fundamental process that transforms unstructured text into meaningful units for information retrieval. By breaking down text into tokens, tokenization enables improved search accuracy, efficient indexing and retrieval, and supports various advanced text analysis techniques. Tokenization is an indispensable tool in the field of information retrieval and plays a crucial role in extracting valuable insights from textual data.