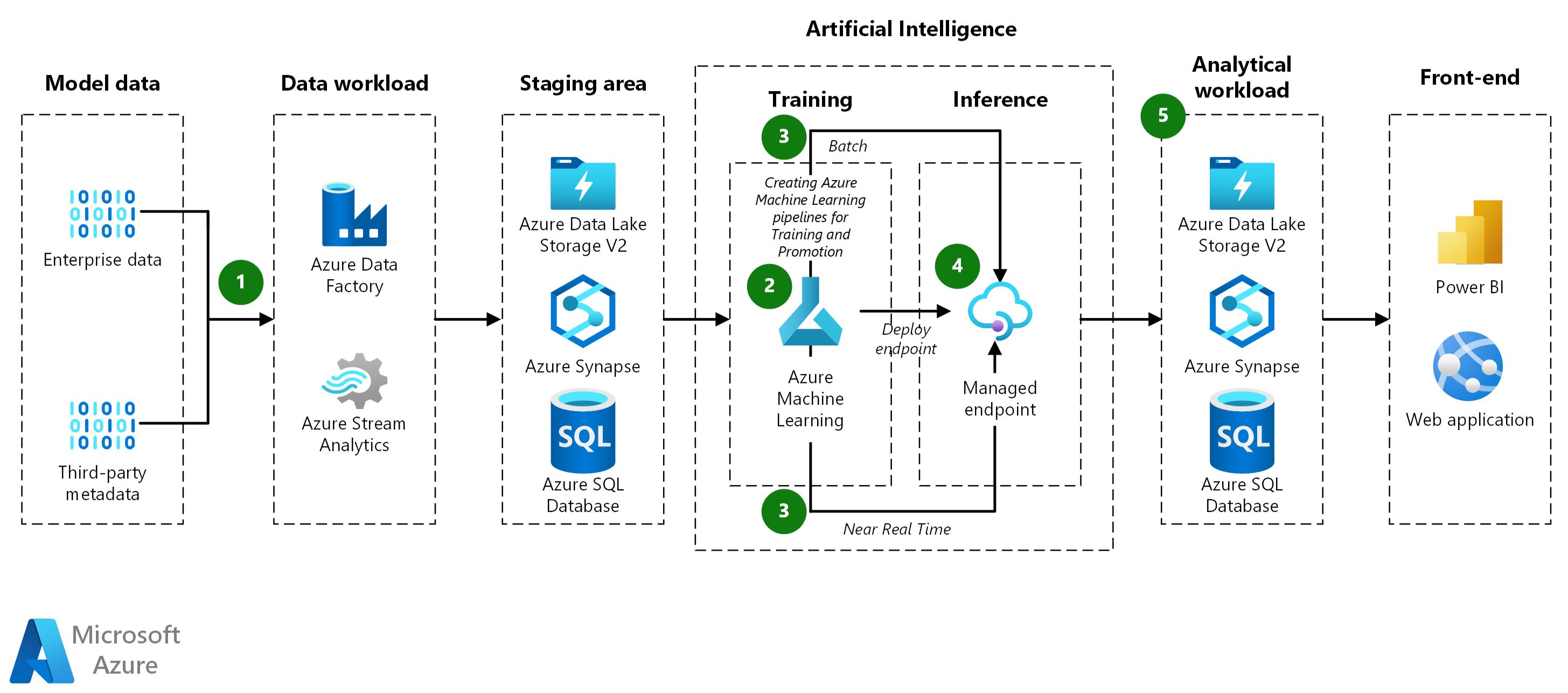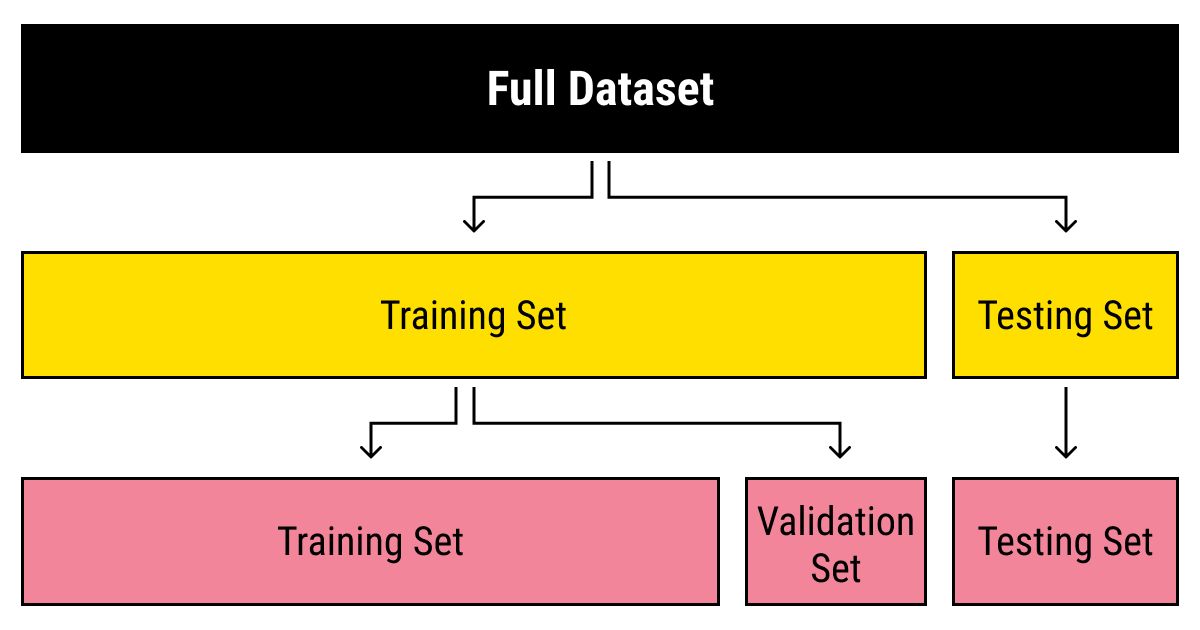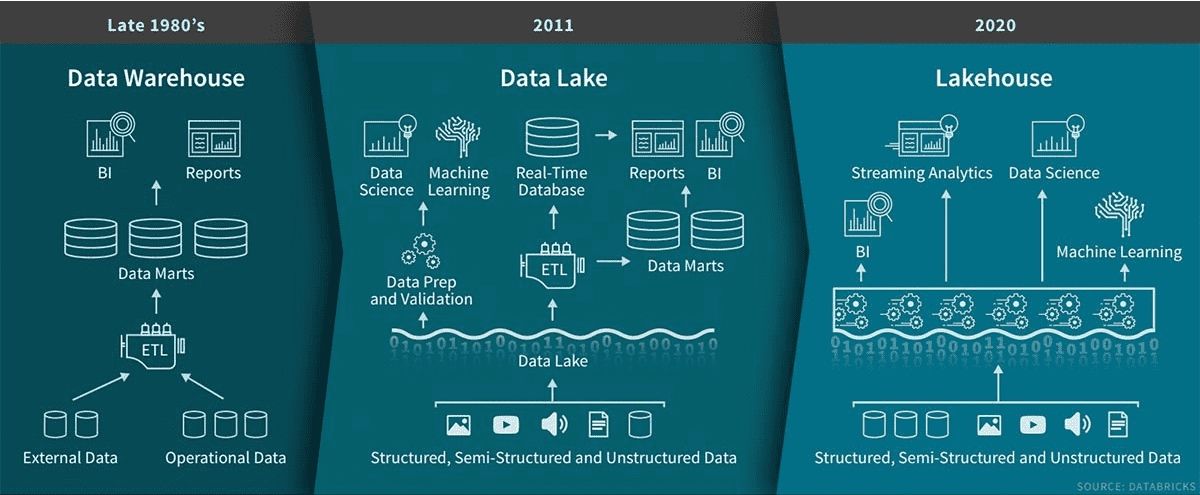
Introduction
Welcome to the Access Point to the Databricks Lakehouse Platform for Machine Learning Practitioners. In this article, we will explore the key concepts, features, and benefits of the Databricks Lakehouse Platform and discuss how machine learning practitioners can access and utilize this powerful platform for their projects.
The advent of big data has revolutionized the field of machine learning, allowing practitioners to work with massive datasets and extract valuable insights. However, managing and processing these large-scale datasets can be a daunting task. This is where the Databricks Lakehouse Platform comes in.
The Databricks Lakehouse Platform combines the best features of data lakes and data warehouses, providing a unified and scalable solution for managing and analyzing large volumes of data. It allows machine learning practitioners to seamlessly integrate data from various sources, perform advanced analytics, and develop machine learning models in a collaborative and efficient manner.
With the Databricks Lakehouse Platform, machine learning practitioners can take full advantage of its powerful features, such as real-time data processing, advanced analytics, and scalable computing resources. This platform is designed to simplify the end-to-end machine learning workflow, empowering practitioners to tackle complex challenges and drive meaningful insights from their data.
Throughout this article, we will delve into the different aspects of the Databricks Lakehouse Platform and guide machine learning practitioners on how to effectively access and leverage this platform for their projects. From the initial data ingestion to the model development and deployment, we will explore each step of the machine learning journey and provide practical tips and best practices.
Whether you are a seasoned machine learning practitioner or just starting your journey in this field, the Databricks Lakehouse Platform can help you streamline your workflow and unleash the full potential of your data. So, let’s begin our exploration of the platform and discover how it can revolutionize your machine learning projects.
Key Concepts
Before diving into the details of the Databricks Lakehouse Platform, let’s familiarize ourselves with some key concepts that form the foundation of this powerful tool.
1. Data Lake: A data lake is a central repository that stores raw, unprocessed data in its original format. Unlike traditional data warehouses, which require data to be structured before ingestion, data lakes accept any kind of data. This flexibility allows for the storage and analysis of diverse data types, from structured to semi-structured and unstructured data.
2. Data Warehouse: A data warehouse is a relational database optimized for query and analysis. It organizes data in a structured manner and provides a schema that defines how the data is stored and indexed. Data warehouses are designed for fast retrieval, making them ideal for business intelligence and reporting purposes.
3. Lakehouse Architecture: The Lakehouse architecture consolidates the benefits of both data lakes and data warehouses into a unified approach. It combines the scalability and flexibility of data lakes with the query performance and reliability of data warehouses. The goal is to provide a solution that can handle both analytical and operational workloads seamlessly.
4. Unified Analytics: Unified Analytics is a concept that emphasizes the integration of data engineering, data science, and business intelligence on a single platform. By bringing together these disciplines, machine learning practitioners can efficiently collaborate and leverage the same data and tools throughout the entire data lifecycle.
5. Delta Lake: Delta Lake is an open-source storage layer built on top of data lakes. It adds reliability, performance, and ACID transaction capabilities to data lakes, making them more suitable for analytical workloads. Delta Lake ensures data quality and consistency, enabling machine learning practitioners to work with high-quality, reliable data.
6. Machine Learning: Machine learning is a subset of artificial intelligence that focuses on developing algorithms and models that can learn from data and make predictions or decisions without explicit programming instructions. Machine learning techniques, such as supervised learning, unsupervised learning, and reinforcement learning, enable computers to discover patterns and insights from data.
7. Collaborative Environment: The Databricks Lakehouse Platform provides a collaborative environment where machine learning practitioners can work together on projects. It allows teams to easily share notebooks, collaborate on code, and track changes. This collaborative aspect fosters knowledge sharing and accelerates innovation.
These key concepts lay the groundwork for understanding the Databricks Lakehouse Platform and its capabilities. With an understanding of these concepts, we can now delve into the platform’s features and how machine learning practitioners can leverage them to drive impactful insights.
Platform Overview
The Databricks Lakehouse Platform is a comprehensive solution that empowers machine learning practitioners to efficiently manage and analyze their data. It provides a unified interface for data engineering, data science, and business intelligence, enabling practitioners to seamlessly collaborate and execute their machine learning projects.
At its core, the platform offers a collaborative workspace where teams can work together on projects. This workspace provides a central hub for data ingestion, exploration, model development, deployment, and monitoring. By bringing all these components into a single platform, the Databricks Lakehouse Platform streamlines the end-to-end machine learning workflow and eliminates the need for multiple tools and interfaces.
One of the key advantages of the Databricks Lakehouse Platform is its scalability. It leverages distributed computing technologies to handle massive datasets and complex analytics workloads. Machine learning practitioners can tap into the platform’s powerful cluster management capabilities to allocate computing resources based on their project needs, ensuring optimal performance and scalability.
Another standout feature of the Databricks Lakehouse Platform is its support for multiple programming languages and frameworks. Whether you prefer Python, R, SQL, or Scala, the platform allows you to leverage your preferred tools and libraries to develop machine learning models. It also supports popular frameworks like TensorFlow, PyTorch, and scikit-learn, enabling you to leverage the latest advancements in the field.
With the Databricks Lakehouse Platform, practitioners can easily connect to various data sources and ingest data into their projects. The platform provides integrations with popular data lakes, databases, and streaming systems, allowing seamless data integration and ingestion. This ensures that machine learning practitioners can work with a wide range of data types and sources, enhancing the versatility and applicability of their projects.
Furthermore, the platform offers robust data exploration and visualization capabilities. Machine learning practitioners can leverage interactive notebooks to explore and analyze their datasets, visually inspecting the data and gaining insights. The platform also supports advanced visualizations and data exploration libraries, enabling practitioners to create impactful visual representations of their findings.
Overall, the Databricks Lakehouse Platform provides a comprehensive and scalable solution for machine learning practitioners. It combines powerful features like collaborative workspaces, scalable computing resources, support for multiple programming languages, and integrations with various data sources. With these capabilities at their disposal, machine learning practitioners can streamline their workflows, tackle complex challenges, and unlock the potential of their data.
Databricks Lakehouse Platform
The Databricks Lakehouse Platform is designed to address the challenges faced by machine learning practitioners in managing and analyzing big data. It provides a unified and scalable solution that combines the best features of data lakes and data warehouses, enabling practitioners to seamlessly integrate, process, and analyze their data.
One of the key components of the Databricks Lakehouse Platform is Delta Lake. Built on top of data lakes, Delta Lake adds reliability, performance, and ACID transaction capabilities to data lakes. It ensures data quality by enforcing schema consistency and providing features like schema evolution and data versioning. With Delta Lake, machine learning practitioners can trust the integrity and reliability of their data, allowing for more accurate and meaningful insights.
The platform also offers advanced analytics capabilities, allowing practitioners to perform complex calculations, aggregations, and transformations on their data. It supports distributed SQL queries, enabling practitioners to leverage familiar SQL syntax to extract insights from large-scale datasets. This empowers machine learning practitioners to easily manipulate and transform their data, making it ready for modeling and analysis.
Another essential feature of the Databricks Lakehouse Platform is its support for machine learning model development and training. The platform provides a rich set of tools and libraries for building and training machine learning models. TensorFlow, PyTorch, and scikit-learn are some of the popular frameworks supported, allowing practitioners to leverage their preferred tools and algorithms. Moreover, powerful distributed computing capabilities enable efficient model training on large datasets.
The Databricks Lakehouse Platform also simplifies the deployment and monitoring of machine learning models. It provides seamless integration with popular deployment platforms like Amazon SageMaker and Azure Machine Learning, allowing for easy deployment of trained models into production environments. Additionally, the platform offers monitoring and logging capabilities to track the performance and behavior of deployed models, ensuring their ongoing accuracy and effectiveness.
Collaboration is a core aspect of the Databricks Lakehouse Platform. It provides a collaboration workspace where machine learning practitioners can share notebooks, collaborate on code, and track changes. This facilitates teamwork and knowledge sharing, enhancing productivity and innovation within machine learning projects.
Overall, the Databricks Lakehouse Platform offers a powerful and comprehensive solution for machine learning practitioners. It consolidates data management, analytics, model development, and deployment into a unified platform, simplifying the end-to-end machine learning workflow. With its robust features and scalable infrastructure, the platform empowers practitioners to extract valuable insights, develop cutting-edge models, and drive transformative impact with their data-driven projects.
Accessing the Platform
Accessing the Databricks Lakehouse Platform is a straightforward process that allows machine learning practitioners to start utilizing its powerful capabilities.
To access the platform, practitioners need to have a Databricks account. They can sign up for an account on the Databricks website or through their organization’s Databricks deployment. Once the account is created, practitioners can log in to the platform’s web-based interface using their credentials.
Once logged in, machine learning practitioners are greeted with the Databricks workspace, which serves as the central point for accessing and managing their projects. The workspace provides an intuitive user interface where practitioners can create new projects, open existing ones, and organize their work.
Within the workspace, the key component for machine learning practitioners is the Notebooks feature. Notebooks are interactive documents that combine the code, visualizations, and narrative explanations to enable the development and documentation of machine learning workflows. Practitioners can create new notebooks, import existing ones, and collaborate with team members on notebook development.
Collaboration is a vital aspect of the Databricks Lakehouse Platform. Practitioners can easily share notebooks with colleagues, allowing for seamless collaboration and knowledge sharing. They can also track changes made to notebooks, providing a version control system to manage the iterative development process.
Machine learning practitioners can access their data within the Databricks platform by connecting to various data sources. The platform supports integrations with data lakes, databases, and streaming systems, allowing practitioners to ingest data from diverse sources. This enables them to work with a wide range of data types and sources, enhancing the versatility and applicability of their projects.
Furthermore, the Databricks platform provides powerful computing resources essential for running machine learning workloads. Practitioners can take advantage of the platform’s scalable cluster management capabilities to allocate computing resources based on their project needs. This ensures optimal performance and facilitates the efficient processing of large datasets.
To enhance the accessibility and convenience of the Databricks platform, it also offers integrations with popular development tools and languages. Practitioners can connect their preferred programming environments, such as Jupyter or RStudio, to the platform, allowing them to leverage their existing workflows seamlessly.
In summary, accessing the Databricks Lakehouse Platform involves signing up for a Databricks account and logging in to the platform’s web-based interface. From there, machine learning practitioners can utilize the workspace and its Notebooks feature to develop and collaborate on their projects. They can connect to various data sources, leverage scalable computing resources, and integrate with their preferred development tools. With these capabilities, practitioners can easily access and harness the power of the Databricks platform for their machine learning endeavors.
Workspace
The Workspace is a central component of the Databricks Lakehouse Platform that provides machine learning practitioners with a collaborative and organized environment for their projects. It serves as a hub where practitioners can create, manage, and access all their machine learning assets, including notebooks, data, and libraries.
The Workspace offers a user-friendly interface that practitioners can navigate to perform various tasks. Upon accessing the Workspace, practitioners are presented with a directory structure that allows them to organize their projects and files efficiently. They can create folders, subfolders, and notebooks to keep their work organized and easily accessible.
One of the key features of the Workspace is the ability to create notebooks. Notebooks are interactive documents that combine code, visualizations, and narrative explanations. They allow practitioners to develop machine learning workflows, experiment with code, and document their findings and insights. Notebooks support multiple programming languages, including Python, R, SQL, and Scala, providing flexibility for practitioners to use their preferred language.
Within the Workspace, machine learning practitioners can collaborate with team members on notebook development. They can share notebooks, allowing others to view, edit, and provide feedback. Collaborators can work simultaneously on the same notebook, enabling real-time collaboration and fostering teamwork. Version control is also available, allowing practitioners to track changes made to notebooks and roll back to previous versions if needed.
In addition to notebooks, the Workspace provides a space for practitioners to manage their data. They can upload datasets, create tables, and store data in different formats, such as Parquet, CSV, and JSON. The Workspace also allows practitioners to connect to external data sources, such as data lakes or databases, to access and analyze data directly within their projects.
Furthermore, the Workspace offers a library management system, where practitioners can manage their dependencies and install additional libraries and packages. This allows practitioners to easily access and utilize popular machine learning libraries like TensorFlow, PyTorch, and scikit-learn, enhancing the capabilities and flexibility of their projects.
Overall, the Workspace is a crucial component of the Databricks Lakehouse Platform, providing a collaborative and organized environment for machine learning practitioners. With its support for notebooks, data management, collaboration, and library integration, the Workspace empowers practitioners to efficiently develop, collaborate on, and organize their machine learning projects.
Notebooks
Notebooks are a core feature of the Databricks Lakehouse Platform that empower machine learning practitioners to develop, experiment, and collaborate on their projects. They provide an interactive and versatile environment where practitioners can combine code, visualizations, and explanatory text to document their workflows.
Within the Databricks platform, notebooks support multiple programming languages, including Python, R, SQL, and Scala. This flexibility allows practitioners to use their preferred language and leverage their existing knowledge and skills. They can write and execute code directly within the notebook cells, making it easy to experiment and iterate on their machine learning algorithms.
Notebooks provide a sequential and modular structure, with code cells that can be executed individually or as a group. This modularity allows for better organization and understanding of the workflows. Practitioners can assign variables, define functions, and import libraries at the beginning of the notebook, ensuring a clear and reproducible workflow.
Another advantage of notebooks is the ability to include visualizations and narrative explanations alongside code. Practitioners can generate insightful visualizations to better understand and analyze their data. They can also provide explanatory text to document their thought process, insights, and observations. This combination of code, visualization, and narrative makes notebooks highly effective for communicating and sharing insights with team members and stakeholders.
Collaboration is a key aspect of notebooks within the Databricks platform. Multiple users can work together on the same notebook, either in parallel or at different times. Collaborators can view, edit, and provide feedback on the code and documentation. This fosters teamwork and knowledge sharing, allowing practitioners to learn from each other and collaborate effectively on machine learning projects.
Notebooks also support version control, allowing practitioners to track changes made to the code and documentation. This feature provides a history of modifications and enables practitioners to revert back to previous versions if needed. It ensures the integrity and reproducibility of the project as it evolves over time.
Finally, notebooks within the Databricks platform offer seamless integration with other platform features. Practitioners can connect to various data sources, such as data lakes or databases, directly within the notebook. They can also leverage powerful distributed computing capabilities to process large datasets and train machine learning models efficiently.
In summary, notebooks are a powerful tool within the Databricks Lakehouse Platform that enable machine learning practitioners to develop, experiment, and collaborate on their projects. They support multiple programming languages, facilitate visualization and narrative documentation, foster collaboration, and offer integration with other platform features. With the versatility and collaborative features of notebooks, practitioners can enhance their productivity and effectively communicate their findings and insights.
Collaborating with Others
Collaboration is a vital aspect of the Databricks Lakehouse Platform, enabling machine learning practitioners to work together effectively on projects. The platform offers robust features and capabilities that facilitate collaboration and foster teamwork among practitioners.
One of the primary collaboration features within the platform is the ability to share notebooks. Machine learning practitioners can easily share their notebooks with colleagues, allowing others to view, edit, and provide feedback. This promotes seamless collaboration and knowledge sharing, facilitating teamwork and accelerating project progress.
Collaboration on notebooks can happen in real-time, enabling multiple team members to work simultaneously on the same notebook. This real-time collaboration feature allows for immediate feedback and reduces the need for version control complexities. Team members can work together, experiment with code, and discuss ideas, enhancing the quality and efficiency of the project.
In addition to real-time collaboration, the platform provides version control for notebooks. Machine learning practitioners can track changes made to the code, documentation, and visualizations, ensuring a clear history of modifications. Version control allows practitioners to compare different versions, roll back to previous versions if needed, and easily identify who made specific changes. This promotes transparency and ensures the integrity and reproducibility of the project.
The collaboration capabilities of the platform extend beyond notebooks. Practitioners can collaborate on other project assets, such as datasets, libraries, and visualizations. They can share and collaborate on data exploration and analysis, collectively work on data preprocessing and feature engineering tasks, and collaborate on developing and fine-tuning machine learning models.
Within the collaboration workspace of the platform, communication channels are available for team members to discuss and exchange ideas. Practitioners can use messaging features, comments, and discussion threads to communicate within the platform. This eliminates the need to rely on external communication tools and streamlines communication within the project environment.
The collaboration features within the Databricks Lakehouse Platform promote not only effective teamwork but also knowledge sharing and continuous learning. By collaborating on projects, team members can learn from each other’s expertise, explore different approaches, and discover innovative solutions. This collaborative environment fosters a culture of learning and innovation within machine learning projects.
Collaboration is a key factor in achieving successful machine learning outcomes. The Databricks Lakehouse Platform provides the necessary tools and features to facilitate collaboration, including real-time collaboration on notebooks, version control, shared datasets, libraries, and communication channels. By embracing collaboration, machine learning practitioners can leverage the collective knowledge and expertise of the team, leading to enhanced project outcomes and driving meaningful impact with data-driven solutions.
Data Ingestion
Data ingestion is a critical step in the machine learning workflow, and the Databricks Lakehouse Platform provides robust capabilities for efficiently and effectively ingesting data from various sources.
The platform offers seamless integration with popular data sources, including data lakes, databases, and streaming systems. This integration enables machine learning practitioners to easily connect to their data sources and ingest data directly into their projects. Data can be fetched from structured, semi-structured, or unstructured sources, allowing practitioners to work with diverse data types.
The Databricks Lakehouse Platform supports various data ingestion methods, ensuring flexibility and versatility based on the specific requirements of the project. Machine learning practitioners can use batch ingestion to import large collections of data at once or opt for real-time ingestion methods such as streaming to ingest data continuously as it becomes available. This flexibility allows practitioners to choose the ingestion method that suits their project’s needs.
To ensure data quality and reliability, the Databricks platform provides integration with Delta Lake, which adds robustness and transaction capabilities to the data lake environment. Delta Lake ensures data consistency and reliability by enforcing schema consistency, supporting schema evolution, and providing features like ACID transactions and data versioning. These features guarantee that the ingested data is of high quality and can be efficiently utilized in machine learning workflows.
Furthermore, the platform allows for data transformations and preprocessing during the ingestion process. Machine learning practitioners can apply transformations, filters, and aggregations to the ingested data, ensuring that it aligns with their project objectives and requirements. This eliminates the need for separate preprocessing steps and enables practitioners to work with prepared and refined data from the beginning of their machine learning projects.
Another significant advantage of the Databricks Lakehouse Platform is its scalability in handling large-scale data ingestion. Leveraging distributed computing technologies, the platform can efficiently process and ingest massive volumes of data. By dynamically allocating computing resources based on project needs, the platform ensures optimal performance and reduces the time required for data ingestion.
Lastly, the platform offers data source connectors, allowing practitioners to leverage specialized data connectors to import data from specific sources more efficiently. Whether it’s a data lake in Amazon S3, a database in Azure SQL, or a streaming system in Apache Kafka, machine learning practitioners can utilize the appropriate data connectors provided by the Databricks Lakehouse Platform to simplify and enhance their data ingestion process.
In summary, the Databricks Lakehouse Platform provides machine learning practitioners with a comprehensive and efficient data ingestion process. With support for diverse data sources, flexibility in ingestion methods, integration with Delta Lake for data quality assurance, scalability in handling large-scale data, and specialized data connectors, the platform streamlines the data ingestion step and empowers practitioners to work with high-quality and reliable data from the start of their machine learning projects.
Data Exploration and Visualization
Data exploration and visualization are crucial steps in the machine learning process, allowing practitioners to gain insights and understand the underlying patterns and relationships within the data. The Databricks Lakehouse Platform offers robust capabilities for data exploration and powerful visualization tools to facilitate this crucial stage.
Within the platform, machine learning practitioners can leverage interactive notebooks to explore and analyze their datasets. Notebooks provide an interactive environment where practitioners can write and execute code, visualize results, and document their findings. This enables practitioners to iteratively explore the data, execute queries, perform data preprocessing, and gain a deeper understanding of their datasets.
The platform provides support for distributed SQL queries, allowing practitioners to leverage familiar SQL syntax to extract valuable insights from large-scale datasets. SQL queries can be executed directly within the notebooks, enabling practitioners to manipulate and transform the data efficiently. This capability empowers practitioners to perform complex calculations, aggregations, and filtering operations across massive datasets, uncovering valuable insights effectively.
To enhance the data exploration process, the Databricks platform offers powerful visualization libraries and tools. Machine learning practitioners can leverage these libraries to create insightful and informative visualizations, enabling them to communicate patterns and relationships visually. These visualizations can include scatter plots, line charts, bar graphs, heatmaps, and more, depending on the nature of the data and the insights sought. Visualizations offer a powerful way to explore and communicate complex data, facilitating better decision-making throughout the machine learning process.
Interactive visualizations are particularly useful within the platform, enabling practitioners to customize and interact with the visualizations in real-time. Practitioners can zoom in, pan, filter, and highlight specific data points, enabling a deeper understanding and exploration of the data. These interactive capabilities allow for a more dynamic and engaging data exploration process.
The Databricks platform also supports advanced visualization libraries like Matplotlib, ggplot, and Seaborn, providing a wide range of options for creating professional and impactful visualizations. These libraries offer additional customization and advanced features to meet specific analysis and visualization requirements.
Moreover, the platform’s visualizations can be enriched with narrative explanations, allowing practitioners to provide context and insights alongside the visual representations. Practitioners can annotate charts, add descriptive text, and explain their data exploration process, facilitating communication and documentation within the project.
Overall, the Databricks Lakehouse Platform provides machine learning practitioners with powerful tools and libraries for data exploration and visualization. By leveraging interactive notebooks, SQL queries, and a variety of visualization libraries, practitioners can effectively analyze their data, uncover valuable insights, and communicate their findings visually. These capabilities enhance the data exploration process, enabling practitioners to make informed decisions and drive impactful results in their machine learning projects.
Model Development and Training
Model development and training are critical stages in the machine learning lifecycle, and the Databricks Lakehouse Platform offers robust capabilities to support practitioners throughout this process.
Within the platform, machine learning practitioners can leverage the power of distributed computing to develop and train their models at scale. The platform provides scalable computing resources, allowing practitioners to allocate resources based on their project needs. Whether training models on a small dataset or leveraging the parallel processing capabilities for large-scale datasets, the platform ensures optimal performance and reduces training time.
The Databricks platform supports popular machine learning frameworks such as TensorFlow, PyTorch, and scikit-learn, providing a wide range of algorithms and models for practitioners to choose from. Practitioners can utilize these frameworks and their corresponding libraries within their notebooks to develop and experiment with different machine learning models.
Machine learning practitioners can take advantage of the interactive nature of notebooks to develop and fine-tune their models. They can iteratively experiment with different hyperparameters, conduct feature engineering, and debug their code within the same environment. The ability to execute code cells in a notebook allows practitioners to immediately see the impact of changes on the model’s performance, making the model development and experimentation process more efficient.
Furthermore, the platform integrates seamlessly with other components of the machine learning workflow. Practitioners can access and retrieve datasets from the data lake and preprocess the data within the same notebook environment. This allows for a seamless transition between the data exploration, preprocessing, and model development stages.
The collaborative workspace of the Databricks platform also enhances the model development process. Multiple practitioners can work together on the same notebook, enabling real-time collaboration and knowledge sharing. This fosters teamwork and allows practitioners to leverage each other’s expertise and insights, resulting in more robust and effective models.
During the model training process, practitioners can leverage the parallel computing capabilities of the platform to distribute the workload across multiple nodes. This distributed training accelerates the training process, especially when dealing with large-scale datasets. Practitioners can leverage optimized algorithms and distributed computing techniques to scale their models efficiently.
The platform also provides monitoring and logging capabilities to track the progress and performance of the training process. Practitioners can monitor key metrics such as loss, accuracy, and convergence over time, enabling them to evaluate model performance and make necessary adjustments.
Finally, the Databricks platform seamlessly integrates with popular model deployment platforms such as Amazon SageMaker and Azure Machine Learning. This integration allows practitioners to easily deploy and operationalize their trained models into production environments for real-world use.
In summary, the Databricks Lakehouse Platform provides a comprehensive set of tools and features to support machine learning practitioners in model development and training. Whether it is leveraging scalable computing resources, supporting popular machine learning frameworks, facilitating collaboration, or integrating with deployment platforms, the platform empowers practitioners to develop and train models efficiently and effectively, ultimately driving impactful results in their machine learning projects.
Model Deployment and Monitoring
Model deployment and monitoring are critical stages in the machine learning lifecycle, and the Databricks Lakehouse Platform offers robust capabilities to support practitioners in these areas.
The platform seamlessly integrates with popular deployment platforms like Amazon SageMaker and Azure Machine Learning, enabling practitioners to easily deploy their trained models into production environments. This integration simplifies the deployment process, ensuring that models can be seamlessly transitioned from development to deployment without the need for extensive rework or modification.
Machine learning practitioners can leverage the deployment capabilities of the Databricks platform to expose their models as APIs for real-world use. By creating APIs, practitioners can enable seamless integration of their models with other applications or systems, allowing for automated predictions and decision-making.
Once models are deployed, the platform provides monitoring and logging capabilities to track model performance and behavior. Practitioners can monitor key metrics such as accuracy, latency, and resource utilization, enabling them to identify any issues or performance bottlenecks. Monitoring models in real-time ensures that practitioners have visibility into their models’ performance and can address any concerns promptly.
The platform also facilitates model versioning and management, allowing practitioners to keep track of different model versions and easily switch between them. This capability is valuable when practitioners need to roll back to a previously deployed model or compare the performance of different versions. With versioning and management capabilities, practitioners have greater control and flexibility over their deployed models.
The Databricks platform also supports integration with common logging and visualization tools, enabling practitioners to visualize and analyze the monitoring data efficiently. Insights gained from monitoring can inform decisions about further model updates or improvements, ensuring continuous refinement and optimization of the deployed models.
An essential aspect of model deployment and monitoring is ensuring security and compliance. The platform provides robust data security features, including encryption at rest and in transit, role-based access controls, and compliance certifications such as SOC 2 and GDPR. These security measures provide practitioners peace of mind when deploying models and ensure that sensitive data is protected during the deployment and monitoring phases.
Finally, the collaboration capabilities of the platform extend to the model deployment and monitoring stages. Practitioners can collaborate with other team members and stakeholders on monitoring and tracking model performance, sharing insights, and discussing improvements. This collaborative environment promotes cross-functional collaboration and allows for efficient knowledge-sharing and decision-making.
In summary, the Databricks Lakehouse Platform offers comprehensive capabilities for model deployment and monitoring. With integrations with popular deployment platforms, monitoring and logging features, versioning and management capabilities, support for security and compliance, and collaboration tools, the platform empowers machine learning practitioners to successfully deploy their models into production environments and ensures the ongoing performance and effectiveness of the deployed models.
Conclusion
The Databricks Lakehouse Platform provides machine learning practitioners with a comprehensive and powerful solution for managing and analyzing data. With its unique combination of data lakes and data warehouses, the platform offers scalability, reliability, and advanced analytics capabilities.
Throughout this article, we explored various key concepts and features of the Databricks Lakehouse Platform. We learned how the platform streamlines the end-to-end machine learning workflow, from data ingestion and exploration to model development, deployment, and monitoring.
The platform’s collaborative workspace fosters teamwork and knowledge sharing, allowing practitioners to work together seamlessly on projects. They can leverage the platform’s powerful computing resources, support for multiple programming languages, and integrations with popular machine learning frameworks to develop and train models efficiently.
With its seamless integration with deployment platforms, the Databricks platform simplifies the model deployment process, enabling practitioners to expose their models as APIs and make them available for real-world use. The monitoring and logging capabilities ensure that practitioners can track model performance, make necessary adjustments, and maintain the effectiveness of the deployed models.
Furthermore, the platform’s focus on data quality and security ensures that practitioners can trust the integrity and reliability of their data. The integration with Delta Lake adds robustness and transaction capabilities to the data lake environment, guaranteeing data quality throughout the machine learning workflow. The platform’s strong data security features provide practitioners with peace of mind when working with sensitive data.
In conclusion, the Databricks Lakehouse Platform offers machine learning practitioners a powerful and unified solution for managing, analyzing, and utilizing their data. With its collaborative workspace, scalability, advanced analytics capabilities, and integration with deployment platforms, the platform empowers practitioners to drive meaningful insights and make informed decisions from their data-driven projects.