





Introduction
Data mining and machine learning are two terms that are often used interchangeably in the field of data analysis. While they are closely related, they actually refer to different concepts and techniques. Understanding the difference between data mining and machine learning is crucial for anyone involved in data analysis, as it can help guide the selection of the appropriate tools and methods for a given task.
Data mining is the process of discovering patterns and relationships in large datasets through various statistical and mathematical techniques. It involves extracting useful information from raw data in order to make informed decisions and predictions. Data mining can be applied to various domains such as business, finance, healthcare, and marketing, among others. The goal is to uncover hidden patterns, trends, and insights that may not be immediately apparent when examining the data manually.
On the other hand, machine learning is a subset of artificial intelligence that focuses on the development of algorithms and models that enable computers to learn from and make predictions or decisions based on data. Machine learning algorithms automatically learn from the data without being explicitly programmed. The algorithms are designed to improve their performance over time by continuously refining their models using feedback from the available data.
While both data mining and machine learning involve the analysis of data, there are fundamental differences between the two. Data mining is primarily concerned with the extraction of information from large datasets, while machine learning focuses on the development of models that can make predictions or decisions based on data.
In this article, we will explore the differences between data mining and machine learning in more detail. We will examine the variances in preprocessing and data collection, the goals and purposes of each, the techniques and algorithms involved, and the application areas where they are commonly used. Additionally, we will highlight the key similarities between these two fields, as they are closely intertwined and often used in conjunction with one another. By the end of this article, you will have a clearer understanding of the disparities and overlaps between data mining and machine learning, and be able to distinguish between the two with confidence.
Explanation of Data Mining
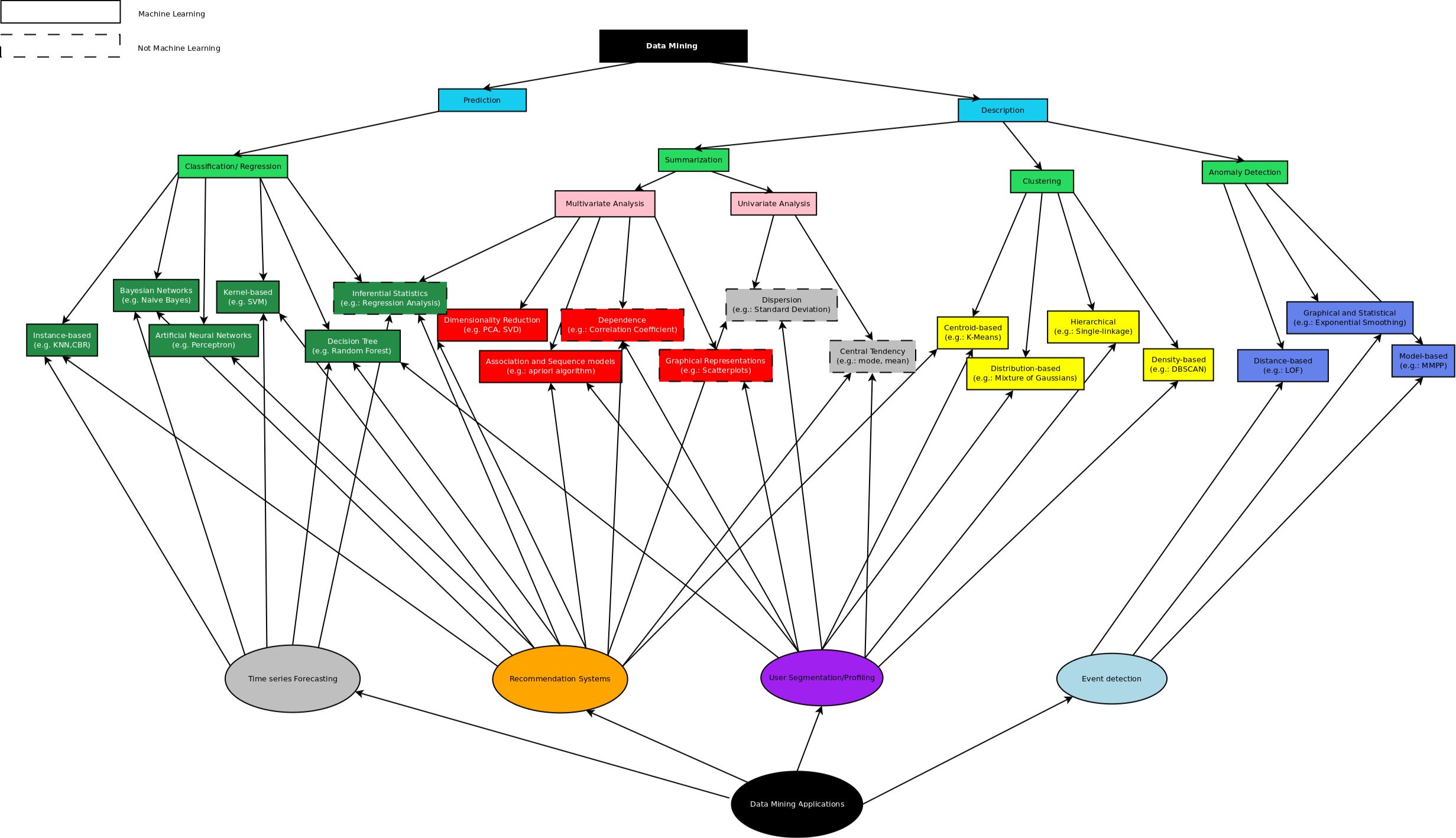
Data mining is a process that involves the extraction of meaningful patterns, relationships, and insights from large datasets. It utilizes a combination of statistical methods, machine learning techniques, and artificial intelligence algorithms to identify hidden patterns or trends that can be used for decision-making and forecasting. The primary goal of data mining is to transform raw data into valuable information that can be used for various purposes.
One of the key aspects of data mining is preprocessing. This involves cleaning and transforming the raw data to remove any inconsistencies, errors, or missing values. Preprocessing techniques may include data cleaning, normalization, integration, selection, and transformation. By ensuring the quality and reliability of the data, data mining algorithms can produce more accurate and meaningful results.
Data mining utilizes various techniques and algorithms to analyze the data and uncover patterns. These techniques can be divided into two main categories: supervised learning and unsupervised learning. In supervised learning, the algorithm is provided with labeled data where each sample has a known outcome or class label. The algorithm learns from this labeled data and can make predictions or classify new data based on the learned patterns. On the other hand, unsupervised learning involves analyzing unlabeled data and finding patterns or structures without any predefined outcomes.
Common data mining techniques include clustering, classification, regression, association rule mining, and outlier detection. Clustering algorithms group similar data points together based on their characteristics or features. Classification algorithms train models to classify data into predefined categories or classes. Regression algorithms analyze the relationships between variables to make predictions about numerical values. Association rule mining identifies patterns or relationships between items in large datasets. Outlier detection algorithms identify rare or abnormal data points that deviate significantly from the normal patterns.
Data mining can be applied in various fields and industries. In business, it can be used for market analysis, customer segmentation, fraud detection, and churn prediction. In healthcare, data mining can assist in disease diagnosis, drug discovery, and personalized treatment plans. In finance, it can be used for credit scoring, fraud detection, and investment analysis. The applications of data mining are vast and continue to expand as data becomes more abundant and accessible.
Overall, data mining is a powerful tool for uncovering patterns and insights from large datasets. It enables businesses and organizations to make data-driven decisions, improve performance, and gain a competitive edge. By leveraging data mining techniques, valuable information can be extracted from raw data, leading to enhanced understanding and actionable insights.
Explanation of Machine Learning
Machine learning is a branch of artificial intelligence that focuses on the development of algorithms and models that can learn from and make predictions or decisions based on data. It involves the use of statistical techniques and computational algorithms to enable computers to improve their performance on a given task through experience. The primary goal of machine learning is to develop models that can automatically learn and adapt without being explicitly programmed.
Machine learning algorithms can be categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the algorithm is provided with training data that is labeled with known outcomes or target variables. The algorithm learns from this labeled data and can make predictions or classify new, unlabeled data based on the patterns it has learned. Unsupervised learning, on the other hand, involves analyzing unlabeled data to discover patterns, structures, or relationships without any predefined outcomes. Reinforcement learning takes a different approach, where the algorithm learns through a trial-and-error process, receiving feedback or rewards for its actions and continuously refining its decision-making strategies.
Machine learning involves preprocessing and feature engineering, similar to data mining. Preprocessing techniques may include data cleaning, normalization, feature selection, and dimensionality reduction. Feature engineering involves transforming and selecting the relevant features or variables that are most informative for the learning process. These preprocessing steps are crucial for improving the quality and efficiency of the learning algorithms.
There are various machine learning algorithms used, depending on the type of problem and data at hand. Some common algorithms include linear regression, logistic regression, decision trees, random forests, support vector machines, neural networks, and deep learning algorithms. Each algorithm has its own strengths and weaknesses and is suited for different types of data and tasks. The choice of algorithm depends on factors such as the complexity of the problem, the amount and quality of available data, and the interpretability of the model.
Machine learning has a wide range of applications in different industries. In healthcare, it can be used for disease diagnosis, patient monitoring, and personalized medicine. In finance, machine learning algorithms can assist with credit scoring, fraud detection, and stock market prediction. In marketing, it can be used for customer segmentation, recommendation systems, and targeted advertising. Machine learning is also employed in natural language processing, image and speech recognition, autonomous vehicles, and many other domains.
Overall, machine learning is a powerful tool that enables computers to learn from data and make intelligent decisions or predictions. Its ability to automatically discover patterns and relationships in data has revolutionized various industries and continues to drive innovation. As the field of machine learning continues to advance, we can expect even more sophisticated algorithms and applications to emerge, further transforming the way we analyze and utilize data.
Comparison of Data Mining and Machine Learning
Data mining and machine learning are closely related fields that share some similarities but also have distinct differences. In this section, we will compare and contrast data mining and machine learning based on several key factors.
Preprocessing and Data Collection: Both data mining and machine learning involve preprocessing and cleaning of data as a necessary step before analysis. However, data mining tends to focus more on data cleaning and transformation, as it aims to extract meaningful patterns from large datasets. In contrast, machine learning focuses on feature engineering, which involves selecting and transforming relevant features for training the models.
Goal and Purpose: The primary goal of data mining is to discover patterns, trends, and insights from data without necessarily predicting future outcomes. On the other hand, the main objective of machine learning is usually to develop models that can make accurate predictions or decisions based on the available data. While data mining focuses on extracting information from data, machine learning emphasizes the ability to generalize and make predictions on new, unseen data.
Techniques and Algorithms: Data mining employs a variety of statistical and mathematical techniques such as clustering, classification, regression, and association rule mining. Machine learning, on the other hand, uses algorithms like decision trees, support vector machines, neural networks, and deep learning models. While there is overlap in some techniques, the emphasis and focus of the algorithms differ between data mining and machine learning.
Application Areas: Both data mining and machine learning find applications in many domains and industries. Data mining is commonly used in business, marketing, healthcare, finance, and science for tasks such as market analysis, customer segmentation, fraud detection, and drug discovery. Machine learning, on the other hand, is widely applied in areas like image and speech recognition, natural language processing, autonomous vehicles, recommendation systems, and personalized medicine.
Methodology: Data mining often follows a more exploratory and descriptive approach, where the goal is to uncover interesting patterns and insights from data. In contrast, machine learning typically employs a more predictive and inferential approach, focusing on building models that can make accurate predictions on unseen data.
Data Requirements: Data mining can handle both structured and unstructured data and can work with large datasets. It often involves mining data from databases, transactional data, text documents, and other diverse sources. In machine learning, structured data is more commonly used, although techniques like natural language processing enable the analysis of unstructured text data.
Despite these differences, it’s important to note that data mining and machine learning are not mutually exclusive. In fact, they often work hand in hand, with data mining providing the foundation for machine learning models and algorithms. Data mining helps uncover patterns and insights that can be used to inform the feature selection and model development process in machine learning.
In summary, data mining and machine learning have similarities but also distinct differences in terms of their goals, techniques, and applications. While data mining focuses on extracting knowledge and patterns from data, machine learning focuses on developing models that can make predictions or decisions. Understanding the nuances between these two fields is essential for selecting the appropriate approach and tools for a given data analysis task.
Differences in Preprocessing and Data Collection
Data preprocessing is a crucial step in both data mining and machine learning. It involves cleaning, transforming, and preparing the data before analysis. Although the overall goal of preprocessing is similar in both fields, there are some noteworthy differences in how data is collected and processed.
Data Collection: Data mining often deals with large, complex datasets from various sources like databases, logs, and transactional data. These datasets may contain noise, missing values, or inconsistencies that need to be addressed during preprocessing. In contrast, machine learning often works with structured datasets, where the features and labels are clearly defined. The data collection process for machine learning may involve careful selection and extraction of relevant features, as well as the collection of labeled data for supervised learning tasks.
Data Cleaning: In both data mining and machine learning, data cleaning is essential for ensuring the accuracy and reliability of the analysis. However, the focus and extent of data cleaning may differ. In data mining, the emphasis is on identifying and handling missing values, outliers, and inconsistencies in large datasets. Data mining algorithms may utilize techniques such as imputation or outlier detection to address these issues. In machine learning, on the other hand, the focus is on preparing the data for training the models. This involves techniques like removing duplicate records, handling missing values, and scaling or normalizing the data to ensure proper model training and performance.
Data Transformation: Data transformation is an important step in both data mining and machine learning. In data mining, transformation techniques such as normalization, discretization, or feature extraction may be applied to improve the quality of the data and facilitate more effective analysis. For example, normalization can scale numerical features to a common range, while discretization can convert continuous variables into categorical variables. In machine learning, feature engineering plays a critical role in transforming the data into a format suitable for the models. This may involve techniques such as one-hot encoding, feature scaling, or creating new derived features through mathematical operations.
Dimensionality Reduction: Another difference in preprocessing between data mining and machine learning is the focus on dimensionality reduction. In data mining, handling high-dimensional datasets and reducing the number of irrelevant or redundant features is a common challenge. Techniques such as principal component analysis (PCA) or feature selection methods are used to reduce the dimensionality and improve the efficiency of the analysis. In machine learning, dimensionality reduction may also be employed, but the focus is more on selecting the most informative features rather than reducing the dimensionality of the entire dataset.
In summary, while both data mining and machine learning involve preprocessing and data cleaning, there are differences in the types of datasets they handle, the extent of data cleaning and transformation, and the focus on dimensionality reduction. Data mining typically deals with large, complex datasets and focuses on addressing noise, missing values, and inconsistencies. In contrast, machine learning often works with structured datasets and focuses on feature engineering and preparing the data for model training. Understanding these differences is essential for effectively preprocessing data and ensuring accurate and reliable analysis in both data mining and machine learning tasks.
Differences in Goal and Purpose
Data mining and machine learning have distinct differences in terms of their goals and purposes. While both fields involve the analysis of data, the primary objectives they aim to achieve are different.
Data Mining: The goal of data mining is to discover valuable patterns, trends, and insights from large datasets. Data mining techniques aim to extract knowledge and information that may not be immediately apparent when examining the data manually. It is often used for exploratory data analysis and to uncover hidden patterns or relationships between variables. The purpose of data mining is to gain a better understanding of the data and to extract actionable knowledge that can be used for making informed decisions, improving processes, and optimizing business strategies.
Machine Learning: In contrast, the main objective of machine learning is to develop models or algorithms that can learn from data and make accurate predictions or decisions. Machine learning algorithms seek to automatically learn patterns and relationships in the data, allowing the models to generalize and make predictions on unseen data. The purpose of machine learning is to create intelligent systems that can adapt and improve their performance over time through experience. It is used for tasks such as classification, regression, clustering, and recommendation systems.
Data mining focuses on extracting information from data, while machine learning emphasizes the ability of models to generalize and make predictions. Data mining is more concerned with descriptive analysis and uncovering insights, while machine learning is more focused on predictive analysis and developing models that can make accurate predictions or decisions.
The difference in their goals and purposes leads to different approaches in their applications. Data mining is often used for tasks such as market analysis, customer segmentation, fraud detection, and anomaly detection. It helps businesses gain a deeper understanding of their customers, identify trends, and identify patterns that can drive strategic decision-making. On the other hand, machine learning is deployed in various domains such as healthcare, finance, marketing, and technology. Its applications include disease diagnosis, credit scoring, personalized medicine, recommendation systems, and image recognition, among others.
While data mining and machine learning have different objectives, they are not mutually exclusive. In fact, data mining can serve as a foundation for machine learning models by uncovering patterns and insights that inform the feature selection and model development process. The knowledge gained from data mining can enhance the accuracy and effectiveness of machine learning algorithms.
Understanding the differences in the goals and purposes of data mining and machine learning is crucial for selecting the appropriate approach for a given task. Whether the objective is to gain insights and knowledge from data or to develop predictive models, both fields provide valuable tools and techniques for analyzing and utilizing data effectively.
Differences in Techniques and Algorithms
Data mining and machine learning employ different techniques and algorithms to analyze and extract patterns from data. While there may be some overlap in terms of the methods used, there are distinct differences between the techniques and algorithms used in these two fields.
Data Mining Techniques: Data mining techniques focus on exploring and discovering patterns, relationships, and insights from large datasets. Clustering is a commonly used technique in data mining, where data points are grouped into clusters based on their similarities or patterns. Classification is another technique that assigns data points to predefined classes or categories based on their features. Regression is used to establish relationships between variables and make predictions about numeric values. Association rule mining identifies relationships and associations between items in a dataset, enabling the discovery of patterns or events that frequently occur together. Outlier detection is employed to identify data points that deviate significantly from the normal patterns.
Machine Learning Algorithms: Machine learning algorithms focus on developing models that can learn from data and make predictions or decisions. Some common machine learning algorithms include decision trees, which use a hierarchical structure to make decisions based on features of the data. Support vector machines are used for classification tasks by finding the optimal separation between classes. Neural networks, including deep learning algorithms, imitate the workings of the human brain to learn patterns and relationships in data. Ensemble methods, such as random forests and gradient boosting, combine multiple models to improve predictions. Reinforcement learning algorithms involve an agent learning through a trial-and-error process, receiving rewards or feedback for its actions.
Data mining techniques and algorithms are often used to explore and uncover insights from data without necessarily focusing on prediction or decision-making. In contrast, machine learning algorithms aim to develop models that can generalize patterns and make accurate predictions on unseen data. While some techniques, such as clustering and classification, may be common to both data mining and machine learning, the emphasis and application of these techniques differ.
In data mining, the focus is on descriptive analysis and discovering patterns that may be useful for decision-making. Data mining techniques often involve exploratory and descriptive statistics, data visualization, and statistical analysis to identify significant patterns. In machine learning, there is a greater emphasis on predictive analysis and developing models that can generalize patterns and make accurate predictions. Machine learning algorithms learn from data through an iterative process and adjust their models to optimize their performance.
It’s worth noting that machine learning can leverage data mining techniques as a preprocessing step. Data mining techniques can help uncover valuable patterns and features that can enhance the performance of machine learning models. The insights gained from data mining can inform feature selection, data preprocessing, and the overall model development process in machine learning.
Overall, while data mining and machine learning may utilize some similar techniques and algorithms, the focus and application of these techniques differ. Data mining techniques are used to explore, uncover patterns, and gain insights from data, while machine learning algorithms are focused on developing models that can make predictions or decisions based on the data. Understanding these differences is important for determining the appropriate approach and techniques for a given data analysis task.
Differences in Application Areas
Data mining and machine learning find applications in various domains and industries, but there are differences in terms of the specific areas where they are commonly used. While there may be overlap, each field has its own distinct application areas and use cases.
Data Mining Applications: Data mining is widely used in business, marketing, healthcare, finance, and science, among other domains. In business and marketing, data mining is employed for market segmentation, customer profiling, and behavioral analysis to gain insights into consumer preferences and behaviors. It helps businesses understand their customers better and optimize their marketing strategies. In healthcare, data mining aids in disease diagnosis, patient monitoring, and identification of risk factors or patterns in medical data. It assists healthcare professionals in making informed decisions and improving patient outcomes. In finance, data mining techniques are used for credit scoring, fraud detection, investment analysis, and market forecasting. Data mining can uncover patterns and anomalies that can help reduce risks and improve financial decision-making. In science, data mining is utilized for scientific exploration, pattern discovery, and hypothesis testing. It helps researchers in fields like genomics, astronomy, and environmental science to analyze large datasets and uncover insights.
Machine Learning Applications: Machine learning has a wide range of applications across many industries. In healthcare, machine learning algorithms are used for disease detection, personalized medicine, drug discovery, and medical image analysis. Machine learning models can be trained to analyze patient data and make accurate predictions, assist in diagnosis, and recommend treatment plans. In finance, machine learning assists in credit scoring, fraud detection, algorithmic trading, and risk management. It learns from historical data to identify patterns and predict financial outcomes. Machine learning is also extensively used in recommendation systems, such as those in e-commerce and entertainment platforms, to personalize user experiences and suggest relevant products or content. In natural language processing, machine learning algorithms enable language understanding, sentiment analysis, and speech recognition. Machine learning is also vital in image and video analysis, autonomous vehicles, and predictive maintenance in manufacturing and transportation industries.
While there may be overlap in some application areas, data mining and machine learning often have different focuses within these domains. Data mining is often used for exploratory analysis and uncovering insights from large datasets, while machine learning is focused on developing models that can make accurate predictions or decisions based on the data. The specific techniques and algorithms used in each field further differentiate their applications.
It’s important to note that data mining often serves as a foundation for machine learning models. The insights gained from data mining can inform the feature selection, data preprocessing, and model development processes in machine learning. The patterns and relationships discovered through data mining can enhance the accuracy and effectiveness of machine learning algorithms.
In summary, data mining and machine learning have different application areas, with data mining commonly used in business, marketing, healthcare, finance, and scientific research. Machine learning finds applications in healthcare, finance, recommendation systems, natural language processing, image analysis, and many other domains. Understanding the specific application areas of each field is crucial for determining the appropriate techniques and methods to employ in a given data analysis task.
Key Similarities between Data Mining and Machine Learning
While data mining and machine learning have distinct differences, there are also key similarities between these two fields. These similarities highlight the interconnectedness and complementary nature of data mining and machine learning in the analysis and utilization of data.
Data Analysis: Both data mining and machine learning are focused on analyzing data to extract meaningful patterns and insights. They both involve exploring and understanding the underlying patterns and relationships within a given dataset. Whether it is through data mining techniques or machine learning algorithms, the ultimate goal is to gain knowledge and make informed decisions based on the data.
Pattern Discovery: Data mining and machine learning are both concerned with discovering patterns and relationships in data. Data mining techniques, such as clustering, classification, regression, and association rule mining, aim to uncover hidden patterns and structures within datasets. Similarly, machine learning algorithms strive to learn patterns and relationships in data, leading to the ability to make predictions or decisions based on the learned patterns.
Data Preprocessing: Preprocessing is a critical step in both data mining and machine learning. Both fields involve cleaning, transforming, and preparing the data to improve its quality and compatibility with the analysis techniques used. Data preprocessing techniques, such as handling missing values, dealing with outliers, and normalizing data, are commonly employed in both data mining and machine learning tasks to ensure accurate and reliable results.
Data Selection and Feature Engineering: Both data mining and machine learning require careful consideration of the relevant data attributes or features. In data mining, selecting the appropriate attributes or variables is crucial to extract meaningful patterns. Similarly, in machine learning, feature engineering plays an important role in selecting or transforming features to construct effective models. Both fields recognize the importance of feature selection and engineering in the analysis process.
Model Validation and Evaluation: Both data mining and machine learning involve the validation and evaluation of models. In data mining, models are evaluated based on their ability to uncover patterns and insights that align with the goals of the analysis. In machine learning, models are validated and evaluated based on their predictive accuracy and performance on unseen data. Both fields emphasize the importance of evaluating and validating models to ensure their effectiveness and reliability.
Iterative Process: Both data mining and machine learning involve an iterative process. In data mining, the process often starts with exploratory analysis to gain an initial understanding of the data, followed by data preprocessing, model building, and evaluation. This process is iterated, allowing the analyst to refine the analysis and extract deeper insights. Similarly, in machine learning, models are trained, evaluated, and refined in an iterative manner, aiming to improve their accuracy and predictive power over time.
By recognizing these key similarities between data mining and machine learning, it becomes clear that these two fields are closely interconnected. Data mining provides the foundation for uncovering patterns and insights, while machine learning builds on this foundation to develop models that can make predictions or decisions. Understanding and leveraging these similarities can lead to more holistic and effective data analysis and utilization.
Conclusion
In conclusion, data mining and machine learning are two interconnected fields that play crucial roles in the analysis and utilization of data. While they have distinct differences, they also share similarities in terms of their goals, techniques, and applications.
Data mining focuses on extracting patterns, trends, and insights from large datasets through exploratory analysis and descriptive techniques. It aims to uncover valuable information that can be used for decision-making and driving business strategies. On the other hand, machine learning is centered around developing models that can learn from data and make accurate predictions or decisions. It emphasizes predictive analysis and the ability to generalize patterns to new, unseen data.
Despite their differences, data mining and machine learning are not mutually exclusive. In fact, they often work hand in hand, with data mining providing the foundation for feature selection, data preprocessing, and model development in machine learning. The insights gained from data mining can enhance the accuracy and effectiveness of machine learning algorithms.
Both data mining and machine learning involve data preprocessing, feature engineering, and model evaluation. They both strive to extract valuable information from data and uncover patterns and relationships. They also share the iterative nature of the analysis process, refining and improving models over time.
Understanding the differences and similarities between data mining and machine learning is essential for selecting the appropriate approach and methods for a given data analysis task. The specific application areas of each field, such as business, healthcare, finance, and marketing, further differentiate their uses.
In today’s data-driven world, data mining and machine learning are valuable tools that enable businesses and organizations to gain insights from data, make informed decisions, and drive innovation. By leveraging the techniques and algorithms of both data mining and machine learning, we can unlock the power of data and transform it into actionable knowledge.
















