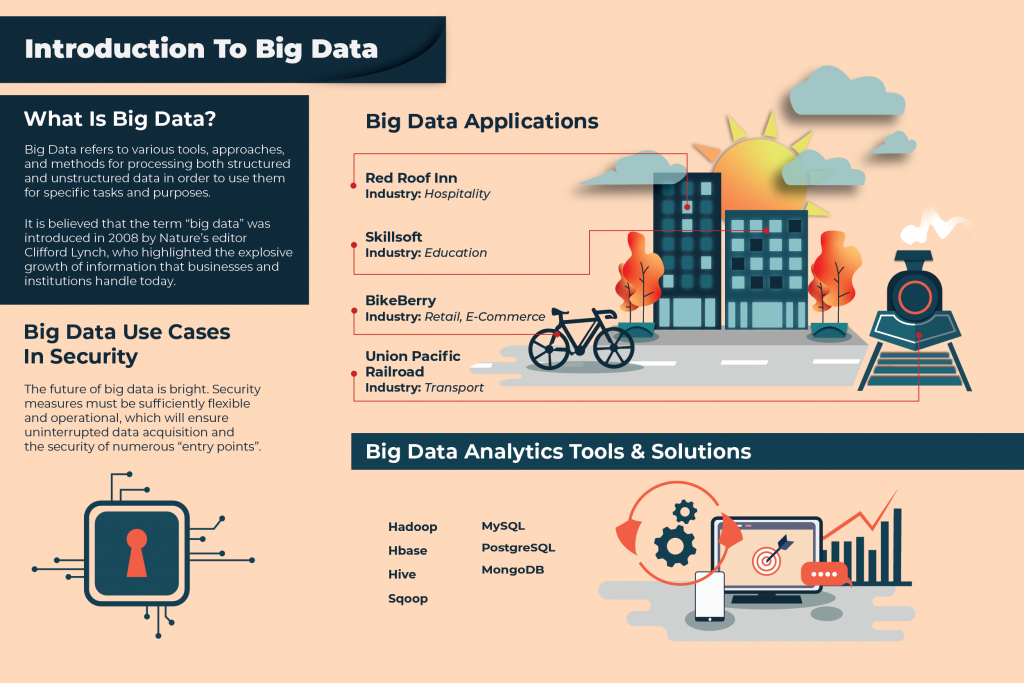
What Is Big Data?
Many have heard the trending tech buzzword that is big data. However, few of us truly understand what it is and how it works. There are many interpretations of what big data really means. But, all these concepts boil down to the central definition that big data refers to the interpretation of large amounts of data that an ordinary computer cannot handle.
On the one hand, big data refers to various tools, approaches, and methods for processing both structured and unstructured data in order to use them for specific tasks and purposes. It is believed that the term “big data” was introduced in 2008 by Nature’s editor Clifford Lynch, who highlighted the explosive growth of information that businesses and institutions handle today.
Some argue that big data is not strictly defined. What constitutes a large amount of data? The name itself is very subjective. But to date, according to experts, the majority of data streams over 100 GB per day can be categorized as Big data. In general, under the term “big data”, we are talking about data storage and processing.
An Industry Expert’s View On Big Data
However, there is a well-established view that big data is a combination of technologies that are designed to perform three functions. First, process large amounts of data compared to “standard” scenarios. Secondly, to be able to work with fast incoming data in very large volumes. That is, not just a lot of data but data that increases exponentially. Third, they should be able to work with structured and poorly structured data in parallel in different aspects. Big data suggests that the input algorithms receive a stream of not always structured information and that more than one idea can be extracted from it.
For ease of understanding, imagine a big shop in which all products are not in the usual manner. Milk near the vegetables, socks near the bread, liquid for ignition opposite the rack with napkins, which among other things is strawberry, meat, and shoes. Big data puts everything in its place and helps you find quail eggs, find out their cost and shelf life, and furthermore, has the ability to tell you who buys the same eggs as you.
Big Data Applications
All businesses rely on data for their day to day operations. Whether it be the automotive industry or advertising or education, data related to customer information, marketing plans and product specifications all play a part in generating revenue. Therefore, the application of big data is limitless given that all industries can benefit from it. To highlight some notable projects, here are companies that have begun to tap on big data for business.
BikeBerry
Industry: Retail, e-commerce
BikeBerry.com is an American online store of bicycles, motorcycles and accessories. With the help of RetentionScience, sophisticated machine learning algorithms and statistical models were introduced to track and predict customer behavior. The technologies used made it possible to identify and use behavioral patterns on the site in models, also used data on purchase history, demographic and behavioral information.
As a result, the store was able to recommend to customers the most relevant products for them and make personalized discount offers only to those customers who really needed them, which increased profitability, more than doubled sales and improved a number of other indicators.
Red Roof Inn
Industry: Hospitality
In the winter of 2014, the American hotel chain Red Roof Inn faced a decrease in the flow of tourists due to the harsh winter and adverse weather conditions. However, due to such weather conditions at airports, a large number of flights were canceled every day, passengers stayed at airports for a long time and needed a hotel. Using open data on weather conditions and flight cancellation, the company was able to send personalized offers to passengers of delayed flights with contact details of the nearest Red Roof Inn hotel to the airport when they were most in demand.
Skillsoft
Industry: Education
Skillsoft is an American company that develops educational software and content, one of the world leaders in the field of corporate educational programs. In partnership with IBM, the company used internal data about user interaction with the system, directly through the program and via e-mail distribution, to personalize their experience, increase engagement and improve learning outcomes. Data on user behavior in the program was used to monitor engagement, to determine the best time and communication channel with which you can attract the user’s attention. Also, on the basis of the preferences of this and other users, an educational content system was built to offer recommendations. 84% of users rated the recommendations as relevant and commented that the content presentation was optimal.
Union Pacific Railroad
Industry: Transport
Union Pacific Railroad is the largest US railway company, has more than 8,000 locomotives, and owns the largest US rail network. Thermometers, acoustic and visual sensors were installed at the bottom of each train. Data is transmitted to the processing center via fiber-optic cables stretched along the railway network. The processing center also receives data on weather conditions, data on the status of braking and other systems, GPS-coordinates of trains. The collected data and predictive models built on them allow you to track the condition of wheels and railroad tracks and predict the breakdown of trains from rails a few days or even weeks before a possible incident. This time is enough to quickly fix problems, avoid asset damage and delay to other trains.
Big Data Ecosystem

Any new product immediately attracts everyone’s attention. It happened with the rise of the Internet and blockchain technology. New companies immediately attracted the attention of investors who were eager to become early adopters and make a handsome profit. Even without understanding what it is about.
The same thing happened with startups associated with Big Data projects. Of the thousands (and maybe more) of startups, only the largest ones remained. They had found a way to make money and achieved progress in the big data space. However, it is a fact that the majority of big data start-ups failed to make the grade and investors lost money as a result.
The largest big data companies to date can be counted with both hands. They include HortonWorks, New Relic, Cloudera, MongoDB, among a few others. Also, it is important not to forget technology giants who use big data as the main tool of their earnings: Amazon, Google and IBM. Definitely, the number of big data companies is growing.
Big Data Security

The future of big data is bright. But, there is no guarantee that big data will be the next big thing. Today, quite often, it is possible to observe how serious gaps are formed in corporate databases. This suggests that the majority of large data collectors are not able to protect their main value – user data.
It is necessary to make serious changes to security protocols because large databases are prone to attack by malicious hackers.
Traditional security mechanisms, such as firewalls and anti-virus software installed on computers, are not enough to effectively protect big data. The problem is that all this was created to protect small amounts of static information – files stored on hard drives, rather than a large information flow coming from the cloud. Security measures must be sufficiently flexible and operational, which will ensure uninterrupted data acquisition and the security of numerous “entry points”.
At the moment there are already identified problems related to the security of big data:
Computing security in distributed software systems
Programs that perform several computational steps must have several levels of protection: at least one for the programs itself, the other to protect the data from these programs.
Security of non-relational databases
These databases, called in the language of professionals, NoSQL, are actively developing. Therefore, it is necessary to develop with them appropriate security measures.
Secure data storage
In the past, IT managers controlled the movement of data, but in the era of big data, manual control of these processes is untenable. Automatic data movement across tiers requires additional security mechanisms.
Authenticity verification
When the system, as it happens in the case of collecting large data, receives millions of inputs, you need to make sure that every bit of information is trustworthy and relevant.
Real-time security monitoring
While real-time security cannot boast of a high level of detection of real threats,, specialists, therefore, receive thousands of false positives on the system every day.
Data mining and analytics that protects privacy
Big data is the ability to intensively collect information of a private nature without notification or consent of consumers.
Secure connections through encryption
For complete security, data must be encrypted from start to end, but it must remain effective and accessible to those who need it.
Fragmentary access control
Not all data is equally confidential, and companies should be able to segment them by their level of secrecy. This will make it possible to share the maximum amount of information, keeping only the most important information secret.
Detailed audits
To learn about security breaches, detailed audits are needed. However, due to the huge amount of big data, such reporting must be consistent with the scale of an incident.
Data source
Solutions must be aimed at monitoring and tracking the sources from which data comes.
Big Data Analytics Tools & Solutions

Hadoop
Hadoop is used to process more data and fast-growing data. It is intended for processing unstructured data. When using it, it is necessary to take into account that by itself it does not give access to real-time data while forming queries, the entire data array is processed.
Hadoop is used to build global analytics, machine learning systems, correlation analysis of various data, statistical systems.
Hbase
Hbase is a non-relational distributed open-source database; written in Java. It is an analog of Google BigTable, developed through the Hadoop project.
The data access model in HBase has the following limitations: searching a series by a single key; transactions are not supported; only single-line operations are available.
Hive
Hive, an add-on to Hadoop to make it easier to perform tasks such as summarizing data, non-programmable queries, and analyzing large data sets – can be used by those who know the SQL language; creates MapReduce jobs that run on a Hadoop cluster; table definitions in Hive are built over data in HDFS.
Sqoop
Sqoop has become a key solution for transferring data between SQL and Hadoop. The project provides connectors for popular MySQL, PostgreSQL, Oracle, SQL Server, and DB2 systems. It is also possible to develop high-speed connectors for specialized systems, such as corporate data warehouses.
Mysql
MySQL is a free relational database management system. The system is developed and maintained by Oracle Corporation. The product is distributed under the GNU General Public License.
The maximum size of tables in MySQL is limited by the maximum file size that the operating system allows you to create.
MySQL is a solution for small and medium applications. Typically, MySQL is used as a server that is accessed by local or remote clients, but the distribution package includes an internal server library that allows you to include MySQL in stand-alone programs.
PostgreSQL
PostgreSQL is a free object-relational database management system (DBMS). The system is based on the SQL language and supports many of the features of the SQL: 2003 standard. The strengths of PostgreSQL are support for the database of almost unlimited size (the maximum size of the table is 32Tbytes); powerful and reliable transaction and replication mechanisms; extensible built-in programming language system.
PostgreSQL has a more advanced query and index building functionality compared to MySQL. Practically used as an operational database in highly loaded projects.
MongoDB
MongoDB is an open-source document-oriented database management system (DBMS) that does not require a description of the table schema. Key features: document-oriented storage (JSON-like data schema); quite flexible language for forming queries; dynamic queries; index support; query profiling; efficient storage of high-volume binary data, such as photos and videos logging operations that modify data in the database; support for fault tolerance and scalability, asynchronous replication, a set of replicas and database distribution on nodes; can work in accordance with the MapReduce paradigm; full-text search, including in Russian, with morphology support.
Big Data Trends

If we talk about global trends, then, first of all, we can talk about the trend of transferring the infrastructure of big data to the cloud.
This makes sense for many companies since the server power for big data is very expensive, and not always needed. For example, some companies conduct most of their big data experiments on Amazon Cloud. In addition, cloud-based big data products often greatly facilitate the work of engineers the entry threshold for most big data software products in terms of deployment is very high, and in the cloud, you can immediately get an already configured cluster.
The next trend can be considered stream analytics, which allows analyzing the incoming data in real-time. This feature is especially important for applications built on top of data collected from sensors (IoT, IIoT).
Also, some experts argue that the global market is characterized by the division of the direction of big data, which in some countries is still understood in general terms, into many independent directions that solve narrower specific tasks.
For example, there are software and hardware tools for storing large data, tools for parallel data processing, tools for filtering data and building models, tools for visualizing data and their interconnection, tools for working with images, machine learning, intelligent interfaces, automation of mental labor.
This division is also associated with the emergence of ready-made industry solutions for small and medium-sized businesses, working as stand-alone applications, and on models of SaaS or BDaS (Big Data as Service).