We live in an interesting era of technology where machine learning (ML) is at the height of evolution. Now, not only can an image processing software detect details within an image, but it can also analyze them. This is the gift of the Google Vision application programming interface (API). How does it work and who will benefit from such a service?
Take a look at its features below and learn how this amazing tool works.
Inside this article:
What Is Google Vision API?

As its name suggests, the Google Cloud Vision API—also called Vision AI—uses artificial intelligence (AI) to derive insights from an image. You can trust that the term “insights” here is not just a fancy word to make the service look cool. When Google says their software can derive insights from an image, you can expect the AI to give you advanced analytics such as what emotions are present in a photo, the exact location where it might have been taken, and other image properties. The software uses machine learning so that each time someone uploads an image to have it analyzed, it expands its knowledge so that it can provide more insights the next time.
Now, API or application programming interface is what makes it possible for two applications to exchange data with each other. Simply put, it’s what allows your device and the application to communicate. You use your device to use the application; the application uploads your image to the server to be analyzed, and then it goes back to you with the information. It’s important to have a basic understanding of what API means if you want to understand how the Google Vision API works. Google offers to provide this API to other developers so that they can incorporate this image analysis feature into their own apps or websites.
Image Analysis and Detection Features
How do you use the Google Vision API? Web and app developers can purchase either a monthly subscription for the AutoML product or pay per unit with the Vision API which allows them to use a set of features for multiple images. More about the pricing is explained below. But you can try it out for free by going to the Vision AI website. Upload an image in the box under Try the API and see what it does! Make sure to tick on the “I’m not a robot” box or else, the page will be stuck in uploading your image.
Here are some of the powerful image analysis and detection features of Vision AI.
Faces and Emotions
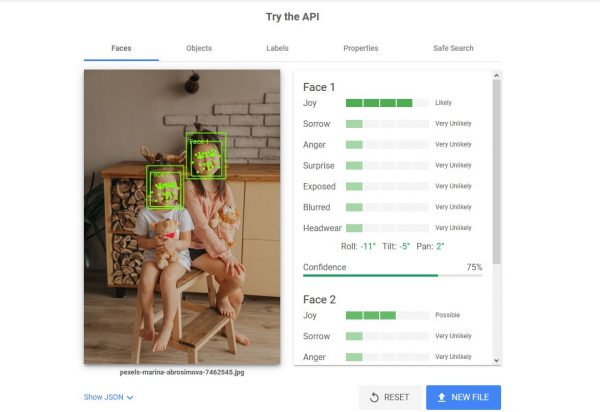
As you can see from the image above, the AI detected two faces. Note the two green boxes labeled Face 1 and Face 2. To the right, you can see the attributes or analyses for each of the faces. Under Face 1, you will see that the emotion “Joy” is “likely” as is also indicated by the green bar, and the emotion “Sorrow” is “very unlikely”. Under Face 2, it only says that the emotion “Joy” is “possible”.
It can detect other possible emotions in any photo with faces on it. Some of the emotions it can detect include anger, surprise, and so on. It will also tell you if the faces are blurred in the image and if there is any headwear.
Objects
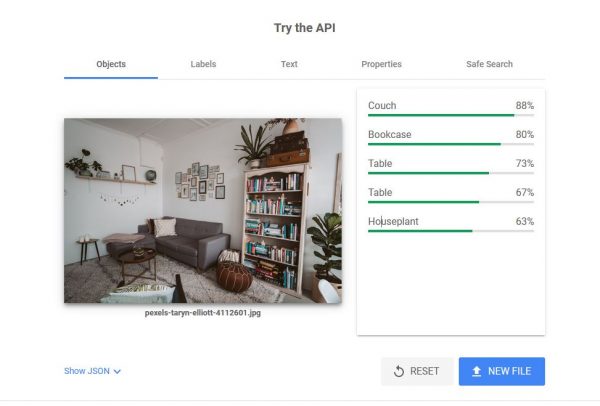
The example image here is that of a living room. On top of the image is a menu of the type of images that the software detected. The Faces tab is not present because it did not detect any. On the right is the analytics pane and as you can see, the AI detected a couch, a bookcase, two tables, and a houseplant. The green “strength bar” and the percentage show the accuracy (or the likelihood that these analyses are correct).
Take note that the app still has its limitations. There are about three houseplants in this image but it only shows 63% accuracy. This may be because one or two of them are not that easily recognizable. It also did not detect some of the smaller objects such as the globe, the photos on the wall, and the suitcases.
Landmarks with Google Maps
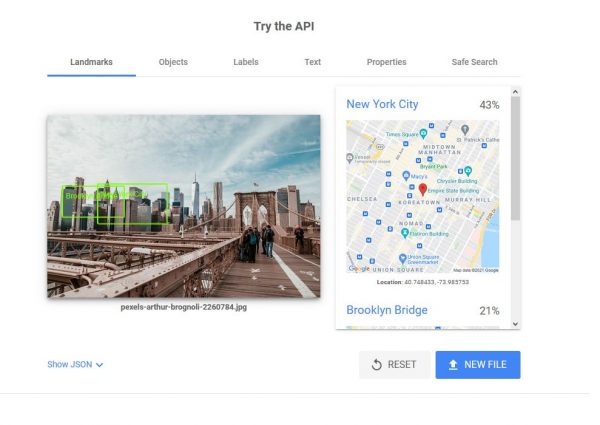
When the Google Cloud Vision API detects places, it also detects the landmarks that may be present in the photo. When applicable, it will also show the location on Google Maps. On the image above, you see the Brooklyn Bridge and on the right pane, it says New York City with 43% likelihood. If you have been to or have walked the length of Brooklyn Bridge, this image will be easily recognizable to you.
You may be wondering why it only says 43%. This could be due to the angle of the image and the fact that it only shows a part of it. Nevertheless, it was still able to correctly detect the location. You will also see two green boxes: one says Brooklyn Bridge and one says New York City—right on the NYC Skyline.
Labels and Logos
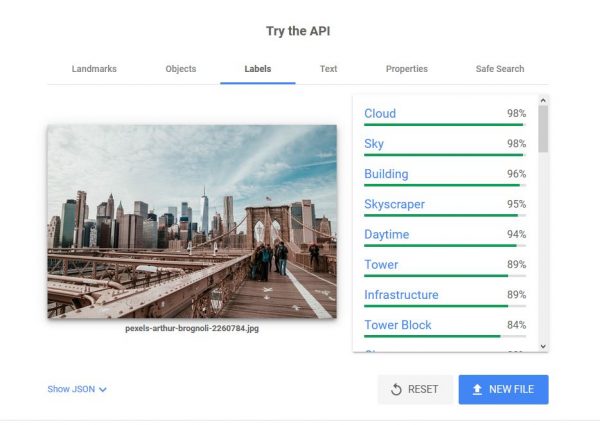
Using the same sample image, you will see more image attributes under the Labels tab. This does not mean that the software will look for labels within the photo. Rather, it provides labels for other things that might be present in the photo. On the right pane, you can see it detected clouds, sky, buildings, and skyscrapers. It also detected that the photo was taken during the daytime. Scroll down and you will see a lot more than that. It can tell you if it’s a possible tourist attraction—in this case, it says 56%; if it is within a metropolitan area and there is a crowd in the photo, Vision AI will list it down.
If there are logos present in the image, you will also see them listed on this same pane.
Texts
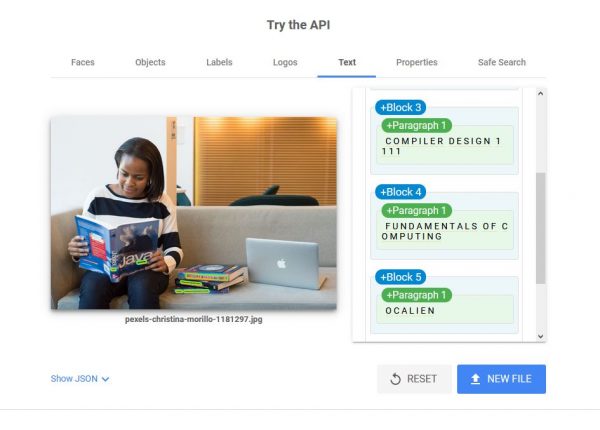
The app can also detect texts within an image although it is in no way perfect. On the image above, you can see a woman reading a book on Java and a pile of books beside her on the couch. Interestingly enough, it did not detect the word Java which is the largest text on the image but it detected the smaller texts—the titles of the books on the couch. You can see on the right pane, it listed the titles Compiler Design and Fundamentals of Computing.
Image Properties
On the Properties tab, you can see other details on the image such as the dominant colors, crop hints, and aspect ratio.
Safe Search
If you click the Safe Search tab, you will see the likelihood of an image containing adult content or violence. You may not need an AI to tell you about these things but this feature is very useful for developers who want to filter out specific content in their apps. This feature also detects if a medical procedure is likely depicted on the image since some people may find such images upsetting.
Types of Google Cloud Vision Products
There are two computer visions that developers and business owners can use. These are also great for students who want to start doing their own machine learning projects.
AutoML Vision
Google’s AutoML Vision or Cloud AutoML is a great tool for new developers who want to train their custom ML models to learn the image analysis feature. It’s perfect for those who are still trying to learn how machine learning works because you don’t need to have the expertise to incorporate it into your apps or projects. It has an intuitive graphical interface so you don’t have to worry about memorizing the right codes. You can easily use the platform to teach your ML models to analyze not only images but also videos and tables. You will have access to a robust set of tools so you can maximize all the features.
Part of the beta features of AutoML is the Video Intelligence—which lets you automatically input subtitles or annotations using custom labels. It can analyze videos as they stream and even detect changes in shots. It also detects and tracks objects. You can also make use of machine learning translation. It automatically detects and translates different languages.
Vision API
Vision API, on the other hand, already has powerful pre-trained ML models. It allows you to quickly analyze image details and put them into different pre-set categories. Aside from detecting objects and faces, it can also read both digital and handwritten texts. Since this package doesn’t come with a graphical user interface, it may be more suitable for more experienced developers.
However, it does come with an integrated ML Kit which you can use to build apps for both Android and iOS devices. It features text recognition, barcode scanning, landmark recognition, smart replies, and so much more.
Pricing Explained
Though both Google Vision API products are available via monthly subscriptions, the pricing can be a bit confusing. Here is how it works, explained in the simplest way possible.
First of all, you would only pay for the features that you need. This applies to both. Your bill will also depend on your usage—how many images you’ve run through the software.
AutoML
- Each feature has a different price per “node hour” (this is approximately an hour on the clock) of training your ML model
- For example, Image Classification is $3.15 per node hour.
- Many developers reported that eight node hours is enough to build an experimental model.
- You can do a Free Trial which includes 40 free node hours and you can keep them up to a year.
Vision API
- You pay for “units” or the features that you need per image, billed per month.
- For example, you use the facial analysis and the landmark detection features—those are two units total for one image.
- You will get free 1,000 units per month.
Who Will Benefit from the Vision AI Service?
You may think that only web and mobile app developers can benefit from the Google Vision API. However, a lot of its features can also be useful to online store owners, schools, and pretty much anyone who wants to incorporate Google’s image processing software into their online platform.
Take a look at the companies and organizations that are currently using the Vision AI service.
Current Customers of the Google Cloud Vision Service
NY Times

The New York Times magazine uses the Google Vision API to filter through their image archives hoping to find stories worth sharing in their platform, and it has worked significantly well. The team has digitized their image collection and used the software to derive insights from the images. From those, they were able to identify images that are associated with relevant events worth reporting.
For example, they took an old photo of one of New York’s subway stations. The photo was black and white, and you can’t tell much by looking at it. They run the photo through the software and it was able to detect some texts which indicated some important events in history. It’s a great way to bring the past into the future!
Zoological Society of London
This wildlife reserve has been using the AutoML Vision product to identify animals and help save endangered ones. Before using the software, it took their team months to identify species from images. Now, it only takes them days after running a thousand images through the app. They set up camera traps in different wildlife areas and used the AutoML software to automate the identification process.
Now that it’s quicker for them to identify endangered species, they can take faster action and save more animals. It is a revolutionary change for conservation work.
Chevron
Chevron also uses the AutoML Vision to explore land areas where they might have business opportunities. They ran image locations through the software and it provided them with geologic labels. This enabled them to simplify their documentation. They are now able to filter through their documents in seconds instead of weeks, giving them the freedom to make timely business decisions.
Aspiring Programmers and App Developers
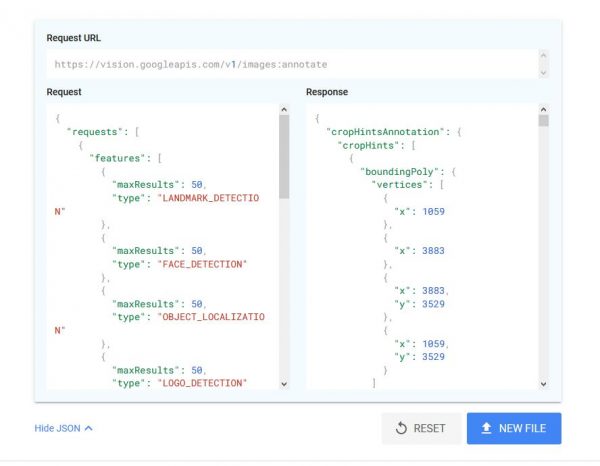
Aside from the functions available by purchasing either of the two products mentioned above, programmers and developers can simply go to the site and make use of the free service if they only intend to use it casually.
You will notice that when you upload an image on the site, you will see an expandable link that says Show JSON. This is a programming term and it’s a syntax derived from JavaScript, and when you click this option, you can copy and paste the code. As you can see from the image above, it provides you with both the request and response codes. Hover your mouse to the top-right of the box and you can click on the Copy icon to copy the code to your clipboard. You don’t even have to highlight anything!
Online Store Owners
Here is a scenario where the Google Vision API can be useful to online store owners. Suppose you have a website where you sell your products. A customer visits your site to browse through your online catalog. They can click on any product image that catches their attention. The software can then automatically analyze that image and when they exit the view, your site will display a ranked list of products similar to the one they viewed!
This way, you are helping your customers and your business at the same time. They find what they are looking for and you get more sales.
Magazines
You’ve seen how the New York Times made use of the Vision AI to help them find images that have stories waiting to be told. The same could work for other magazines, both eZines and those that are still making print issues.
Universities
There are so many ways that the Google Cloud Vision API service can help universities automate their processes. From online security to providing better services to students, the Vision AI could help immensely. Texas A&M University, for one, uses the service so that their scientists can better study the effects of climate change.
Using Google’s image analysis, they are now able to easily predict the Environmental Sensitivity Index (SEI) of shorelines. They do this by feeding images with aerial shots of coastlines to the AI and it provides them with the data that they need.
Free Resources to Learn About the API
The Vision AI site provides resources for developers to better understand how the API works. You can find documentation about the AutoML Vision as well as examples for Machine Learning APIs that you can use for your own projects. If you are a store owner, you can also access the Google Cloud Solutions for Retail document.
Final Word
The Google Cloud Vision API is truly an incredible tool for detecting and analyzing details on images, and it now has far wider use. As you can see from the examples above, its image analysis features can benefit not only those who are studying machine learning but also different types of companies and organizations. Try it for free and witness this technological wonder for yourself.