Introduction
Hugging Face has become one of the leading platforms for working with state-of-the-art machine learning models in natural language processing (NLP). This open-source library, known as Transformers, provides a wide range of pre-trained models that can be easily downloaded and used for various NLP tasks. Whether you are working on text classification, sentiment analysis, or text generation, Hugging Face Transformers offers a rich collection of models that can save you time and effort in model development.
In this article, we will explore how to download Hugging Face models and utilize them in your own projects. We will also discuss the Hugging Face Model Hub, where you can discover and access an extensive selection of pre-trained models and other resources.
Before we dive into the specifics of downloading models, it is important to ensure that you have the necessary dependencies installed. The Hugging Face Transformers library can be installed using pip, the Python package manager. This library requires Python 3.6 or later versions, along with PyTorch or TensorFlow.
Once you have the Hugging Face Transformers library installed, you can start downloading and loading pre-trained models. These models have been trained on large datasets and possess powerful capabilities for various NLP tasks. With just a few lines of code, you can use these models to perform tasks like text classification, named entity recognition, and text generation.
The Hugging Face Model Hub is the central repository where you can find and access a wide range of pre-trained models. It provides a convenient interface to explore models based on different architectures, tasks, and languages. Additionally, the Model Hub allows you to contribute your own models and share them with the community. It is a collaborative platform that fosters innovation and knowledge exchange in the field of NLP.
In the next sections, we will walk you through the process of downloading and loading pre-trained models from the Hugging Face Model Hub. We will also provide examples of downloading popular models such as BERT, GPT-2, BART, and DistilBERT. Furthermore, we will touch upon the concept of fine-tuning models, which allows you to adapt pre-trained models to specific tasks or domains.
Installing Hugging Face Transformers
Before you can start downloading and using Hugging Face models, you need to install the Hugging Face Transformers library. This library simplifies the process of working with pre-trained models and provides a unified API for a wide range of NLP tasks.
To install Hugging Face Transformers, you can use pip, the Python package manager. Open your preferred terminal or command prompt and enter the following command:
pip install transformers
This will download and install the latest version of the library along with its dependencies. Make sure you have an active internet connection to successfully complete the installation process.
It is recommended to use Python 3.6 or later versions, as earlier versions might not be compatible with the library. Additionally, Hugging Face Transformers supports both PyTorch and TensorFlow as backend frameworks, so make sure you have one of them installed before proceeding.
If you prefer using PyTorch as the backend, you can install it using the following command:
pip install torch
For TensorFlow, you can use the following command:
pip install tensorflow
Once you have installed the necessary libraries, you are ready to start harnessing the power of Hugging Face Transformers and its pre-trained models. In the next section, we will explore how to download and load these models for your NLP tasks.
Downloading and Loading Pretrained Models
With the Hugging Face Transformers library installed, you can easily download and load various pre-trained models for your NLP tasks. These models have been trained on massive amounts of text data and possess impressive capabilities to understand and generate natural language.
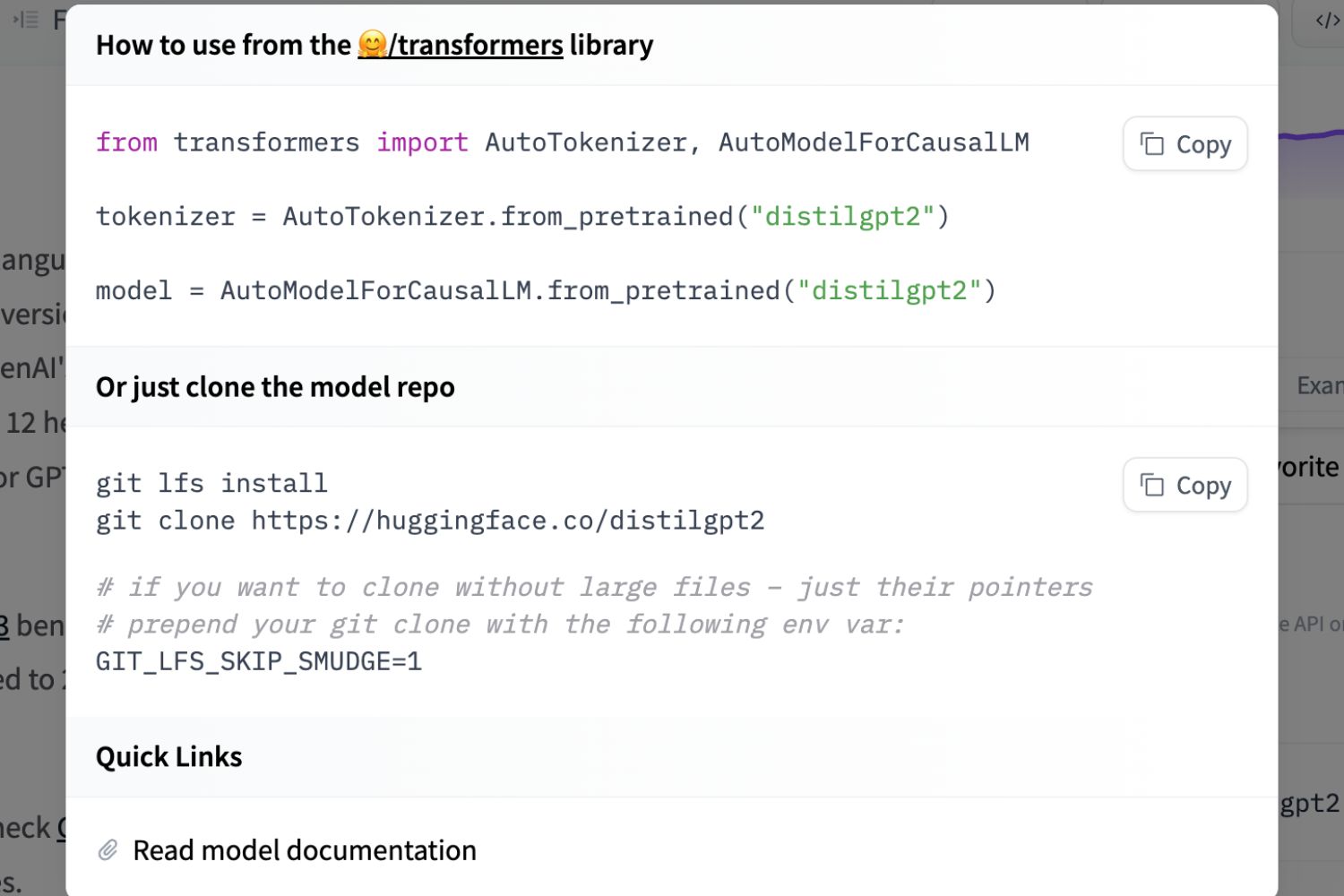
The process of downloading a pre-trained model involves specifying the model’s name or identifier and using the library’s `from_pretrained` function. Let’s take a look at the basic steps:
- Identify the model you want to download. You can find a wide range of models on the Hugging Face Model Hub, categorized by architecture, task, and language.
- Specify the model’s name or identifier as a parameter to the `from_pretrained` function. This function will automatically download the model if it is not already present in your local cache.
- Once the model is downloaded, it will be stored on your local system. You can then load the model using the appropriate model class from the Transformers library.
Here is an example of how to download and load a pre-trained BERT (Bidirectional Encoder Representations from Transformers) model:
python
from transformers import BertModel
model_name = “bert-base-uncased”
model = BertModel.from_pretrained(model_name)
In this example, we are using the `BertModel` class from the Transformers library, and we specify the model name as `”bert-base-uncased”`. If the model is not already downloaded, the library will automatically fetch it from the Model Hub and store it on your local system.
Similarly, you can download and load models for other architectures such as GPT-2, BART, DistilBERT, and many more. Just make sure to use the appropriate class and specify the correct model name or identifier.
Downloading and loading a pre-trained model is the first step towards leveraging its power for your NLP tasks. Once the model is loaded, you can use its various methods and properties to perform tasks like text generation, sentiment analysis, and named entity recognition. We will dive deeper into these tasks and provide examples in the upcoming sections.
Model Hub
The Hugging Face Model Hub is a centralized platform where you can discover, access, and share a wide range of pre-trained models for natural language processing (NLP). It serves as a repository of cutting-edge NLP models and resources contributed by the community.
The Model Hub provides a user-friendly interface to explore models based on different architectures, tasks, and languages. It allows you to filter models based on specific criteria and provides detailed documentation for each model, including its capabilities, usage examples, and performance benchmarks.
One of the key features of the Model Hub is its collaborative and open-source nature. It encourages researchers, developers, and NLP enthusiasts to contribute their own models to the community. This fosters innovation and knowledge exchange within the NLP community, making the Model Hub a dynamic and evolving platform.
When you want to download a pre-trained model from the Model Hub, you can specify the model’s name or identifier in your code. The Hugging Face Transformers library will automatically fetch the model from the Model Hub if it is not already available in your local cache. This seamless integration between the library and the Model Hub simplifies the process of accessing and utilizing pre-trained models.
Furthermore, the Model Hub not only provides access to pre-trained models but also offers various other resources. These include tokenizers, pipelines, example scripts, and notebooks that demonstrate the usage of different models for specific tasks. These resources act as valuable references to guide you in effectively leveraging the power of pre-trained models for your NLP projects.
Through the Model Hub, you can also contribute your own models to the community. By sharing your models, you can contribute to the advancement of NLP research and help others in their projects. This collaborative aspect of the Model Hub fosters a vibrant and supportive community of NLP practitioners.
In summary, the Hugging Face Model Hub is a comprehensive platform for accessing, exploring, and sharing pre-trained models in the field of natural language processing. It offers a diverse collection of models, documentation, and resources, enabling you to leverage state-of-the-art NLP capabilities in your own projects.
Example: Downloading BERT Model
To illustrate the process of downloading a pre-trained model from the Hugging Face Model Hub, let’s take a look at an example using BERT (Bidirectional Encoder Representations from Transformers) – one of the most popular models for NLP tasks.
In this example, we will download the ‘bert-base-uncased’ model. This particular BERT model has been pretrained on a large corpus of uncased English text and is suitable for a wide range of NLP tasks.
First, make sure you have the Hugging Face Transformers library installed. If not, you can install it using the following command:
pip install transformers
Once the library is installed, you can use the following code to download and load the pre-trained BERT model:
python
from transformers import BertModel
model_name = “bert-base-uncased”
model = BertModel.from_pretrained(model_name)
In the code snippet above, we import the `BertModel` class from the Transformers library. Then, we specify the model name as “bert-base-uncased” and use the `from_pretrained` function to download and load the model.
If the specified BERT model is not already present in your local cache, the library will automatically download it from the Model Hub. Once downloaded, the model will be stored on your local system, allowing you to use it for various NLP tasks.
By downloading the BERT model, you gain access to its powerful pre-trained representations, which can be used for tasks like text classification, sentiment analysis, and named entity recognition.
Remember that BERT is just one example of the many pre-trained models available on the Hugging Face Model Hub. You can explore the Model Hub to discover and download models that are more suited to your specific task or domain.
Now that we have seen an example of downloading the BERT model, let’s explore how to download other popular models like GPT-2, BART, and DistilBERT in the upcoming sections.
Example: Downloading GPT-2 Model
Another widely used pre-trained model available on the Hugging Face Model Hub is GPT-2 (Generative Pretrained Transformer 2). GPT-2 is known for its impressive language generation capabilities and has been trained on a massive corpus of internet text.
In this example, we will guide you through the process of downloading the ‘gpt2’ model and loading it into your project.
Ensure that you have the Hugging Face Transformers library installed. If not, you can install it using the following command:
pip install transformers
Once the library is installed, you can use the following code to download and load the pre-trained GPT-2 model:
python
from transformers import GPT2Model
model_name = “gpt2”
model = GPT2Model.from_pretrained(model_name)
In the code snippet above, we import the `GPT2Model` class from the Transformers library. Then, we specify the model name as “gpt2” and utilize the `from_pretrained` function to download and load the model.
If the specified GPT-2 model is not already present in your local cache, the library will automatically download it from the Model Hub. Once downloaded, the model will be stored on your local system, allowing you to make use of its powerful language generation capabilities.
By downloading the GPT-2 model, you have access to its pre-trained representation, which can be utilized for various text generation tasks. With just a few additional steps, you can generate creative and coherent paragraphs of text.
Remember that GPT-2 is just one example of the many pre-trained models available on the Hugging Face Model Hub. You can explore the Model Hub to discover and download models that are better suited to your specific task or language.
Now that we have seen an example of downloading the GPT-2 model, let’s explore how to download other popular models like BART and DistilBERT in the upcoming sections.
Example: Downloading BART Model
BART (Bidirectional and Auto-Regressive Transformers) is a pre-trained model available on the Hugging Face Model Hub that excels in various natural language processing (NLP) tasks such as text summarization and language translation.
In this example, we will demonstrate how to download the ‘facebook/bart-base’ model and load it into your project for further use.
First, make sure you have the Hugging Face Transformers library installed. If not, you can install it using the following command:
pip install transformers
Once the library is installed, you can use the following code to download and load the pre-trained BART model:
python
from transformers import BartModel
model_name = “facebook/bart-base”
model = BartModel.from_pretrained(model_name)
In the code snippet above, we import the `BartModel` class from the Transformers library. Then, we specify the model name as “facebook/bart-base” and utilize the `from_pretrained` function to download and load the model.
If the specified BART model is not already present in your local cache, the library will automatically download it from the Model Hub. Once downloaded, the model will be stored on your local system, ready to be used for tasks like text summarization or language translation.
By downloading the BART model, you gain access to its pre-trained representations, enabling you to generate high-quality summaries or translate text between languages with ease.
It is worth noting that BART is just one example of the numerous pre-trained models available on the Hugging Face Model Hub. In the Model Hub, you can explore and discover models that are more specifically tailored to your particular task or domain.
Now that we have seen an example of downloading the BART model, let’s explore how to download another popular pre-trained model: DistilBERT.
Example: Downloading DistilBERT Model
DistilBERT is a compact version of the original BERT model, designed to deliver fast and efficient performance while maintaining comparable accuracy in natural language processing (NLP) tasks. It is widely used for various NLP tasks such as text classification and named entity recognition.
In this example, we will guide you through the process of downloading the ‘distilbert-base-uncased’ model from the Hugging Face Model Hub and loading it into your project.
Before proceeding, ensure that you have the Hugging Face Transformers library installed. If not, you can install it using the following command:
pip install transformers
Once the library is installed, you can use the following code to download and load the pre-trained DistilBERT model:
python
from transformers import DistilBertModel
model_name = “distilbert-base-uncased”
model = DistilBertModel.from_pretrained(model_name)
In the code snippet above, we import the `DistilBertModel` class from the Transformers library. We specify the model name as “distilbert-base-uncased” and leverage the `from_pretrained` function to download and load the model.
If the specified DistilBERT model is not already present in your local cache, the library will automatically download it from the Model Hub. Once downloaded, the model will be stored locally, ready to be utilized for various NLP tasks.
By downloading the DistilBERT model, you gain access to its powerful pre-trained representations, which can be used for tasks like text classification, named entity recognition, and more.
It’s important to note that DistilBERT is just one example of the many pre-trained models available on the Hugging Face Model Hub. You can explore the Model Hub to discover and download models that are better suited to your specific task, language, or computational constraints.
Now that we have seen examples of downloading popular pre-trained models like BERT, GPT-2, BART, and DistilBERT, we can explore further topics such as fine-tuning these models for specific tasks.
Fine-tuning Models
Although pre-trained models from the Hugging Face Model Hub offer powerful capabilities for various natural language processing (NLP) tasks out of the box, sometimes it may be necessary to fine-tune these models on specific datasets or domains. Fine-tuning allows the model to adapt and specialize further for a particular task, thereby improving its performance.
The process of fine-tuning involves taking a pre-trained model and training it on a custom dataset that is specific to your task at hand. By fine-tuning, you can leverage the knowledge learned by the pre-trained model and refine it to make more accurate predictions on your specific task.
To fine-tune a pre-trained model, you need to follow these general steps:
- Load the pre-trained model from the Hugging Face Model Hub.
- Prepare your custom dataset by tokenizing and encoding the text appropriately.
- Configure the fine-tuning task, including the loss function, evaluation metrics, and optimizer.
- Train the model on your custom dataset, using the fine-tuning configuration and hyperparameters.
- Evaluate the fine-tuned model’s performance on a separate validation or test dataset.
When fine-tuning, it is important to strike a balance between using a sufficient amount of training data and preventing overfitting. Additionally, fine-tuning is often computationally expensive, so it is recommended to use powerful hardware or cloud-based resources for efficient model training.
The Hugging Face Transformers library provides easy-to-use APIs and utilities for fine-tuning pre-trained models across a variety of NLP tasks. It offers pre-configured fine-tuning scripts and examples that you can adapt to your specific task requirements.
By fine-tuning pre-trained models, you can achieve improved performance and accuracy on your target NLP tasks. It allows you to leverage the rich knowledge and representations learned by these models and tailor them to the specifics of your data and domain.
Now that you have an understanding of fine-tuning models, you can explore additional resources and documentation provided by Hugging Face to dive deeper into the fine-tuning process and effectively apply it to your own NLP projects.
Conclusion
In this article, we have explored the process of downloading and utilizing pre-trained models from the Hugging Face Model Hub. The Hugging Face Transformers library provides a seamless way to access and leverage state-of-the-art models for various natural language processing (NLP) tasks.
We started by installing the Hugging Face Transformers library, ensuring that we have the required dependencies. Once installed, we learned how to download and load pre-trained models by specifying their names or identifiers. The models are automatically fetched from the Model Hub and stored locally for efficient usage.
We then delved into examples of downloading popular pre-trained models like BERT, GPT-2, BART, and DistilBERT. These models offer powerful capabilities for tasks such as text classification, language generation, summarization, and more.
Additionally, we explored the Hugging Face Model Hub—a centralized repository that allows users to discover, access, and share pre-trained models and other NLP resources. The Model Hub encourages collaboration and community engagement, enabling researchers and practitioners to contribute their own models and benefit from the work of others.
We also briefly discussed the concept of fine-tuning models, which involves adapting pre-trained models to specific datasets or domains. Fine-tuning allows us to enhance the model’s performance on our specific NLP tasks.
The Hugging Face Transformers library, along with the extensive collection of models and resources available on the Model Hub, provides a powerful toolkit for NLP practitioners and researchers. By leveraging pre-trained models and fine-tuning them to specific tasks, we can achieve state-of-the-art performance with less effort and time compared to training models from scratch.
As you continue to explore the Hugging Face Transformers library and the Model Hub, you will discover new models, techniques, and advancements that can further enhance your NLP projects. The field of NLP is ever-evolving, and Hugging Face is at the forefront, providing tools and resources to drive innovation and progress.
So, embark on your NLP journey with Hugging Face Transformers, and unlock the potential of pre-trained models for your NLP tasks. Happy coding and model exploration!