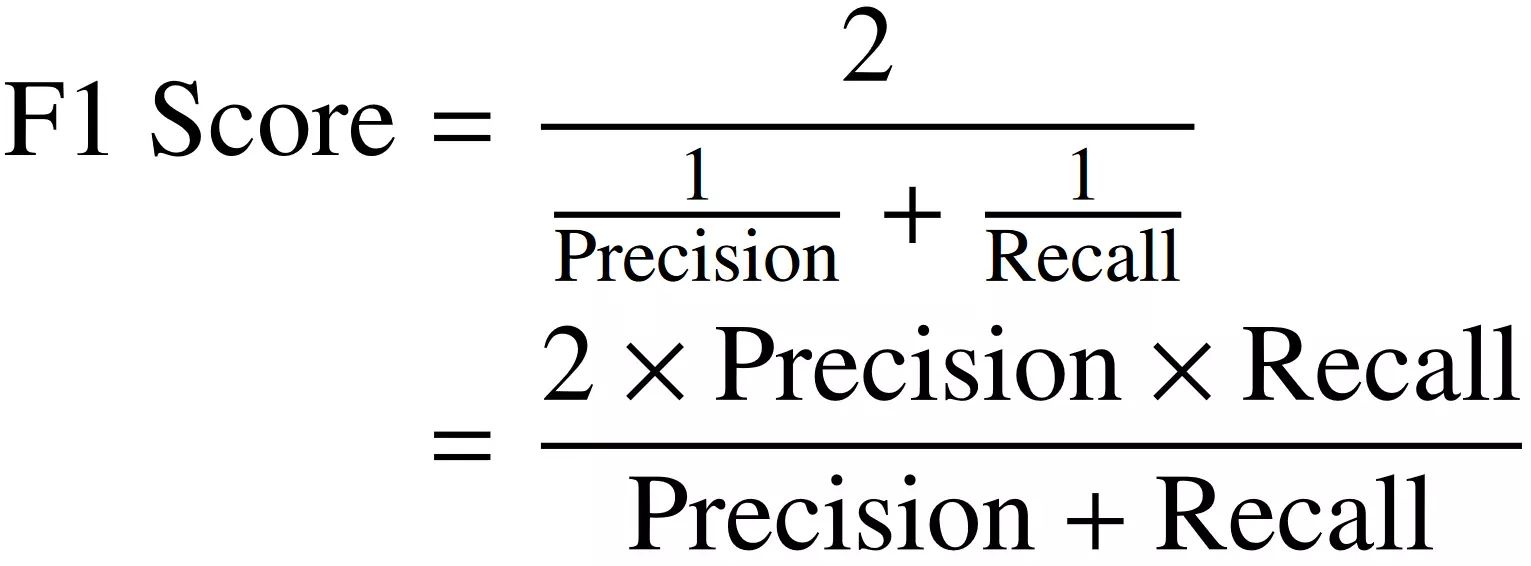
Introduction
Welcome to the fascinating world of machine learning! In this rapidly evolving field, where computers are programmed to learn from data and make intelligent decisions, one of the fundamental concepts is the notion of a class. Classes play a crucial role in organizing and categorizing data, enabling machines to recognize and differentiate various patterns and objects.
At its core, a class can be thought of as a category or a group of similar entities. It represents a distinct type or label that helps us understand and classify the data we encounter. In the context of machine learning, classes serve as the foundation upon which algorithms are trained to recognize and predict different types of information.
By leveraging the power of classes, machine learning algorithms can analyze vast amounts of data and identify meaningful patterns or relationships. This enables machines to make predictions or decisions based on new, previously unseen data.
Classes are crucial in both supervised and unsupervised learning algorithms. In supervised learning, the machine is trained using labeled data where each instance is associated with a specific class. The goal is for the machine to learn the relationship between the input data and its corresponding class, allowing it to classify future, unlabeled instances accurately.
On the other hand, unsupervised learning algorithms aim to discover inherent structures or patterns within the data without predefined class labels. These algorithms identify clusters, which are essentially groups of similar instances, providing insights into the underlying organization of the data.
To successfully classify data and assign instances to their respective classes, a variety of classification algorithms are employed in machine learning. These algorithms employ diverse techniques ranging from decision trees and support vector machines to neural networks and ensemble methods.
As you further delve into the exciting domain of machine learning, understanding the concept of classes and how they are utilized in different algorithms is essential. By harnessing the power of classes, machines can transform raw data into valuable information, aiding in decision-making and problem-solving across various domains.
What is a Class?
In the realm of machine learning, a class refers to a distinct category or label that is assigned to different instances of data. It represents a specific type or group that allows us to organize and categorize information effectively.
To better understand the concept of a class, let’s consider an example. Imagine you are working on a project to develop a system that can classify emails as either spam or legitimate. In this scenario, the two classes would be “spam” and “legitimate.” Each email instance would be labeled with the appropriate class based on its content and characteristics.
Classes provide a way to identify and differentiate different patterns or objects within a dataset. They act as the building blocks for machine learning algorithms, allowing the machine to learn and make predictions based on the provided labels.
When a machine learning algorithm is trained, it learns to recognize the relationship between the input data and the corresponding classes. By observing and analyzing multiple instances of data, the algorithm tries to identify common features or characteristics associated with each class.
For instance, in a speech recognition system, the classes might be “yes,” “no,” “up,” “down,” “left,” “right,” and “unknown.” The algorithm analyzes audio samples with associated labels, deriving patterns and features specific to each class, which enables it to recognize and interpret spoken words successfully.
Classes are not limited to binary distinctions. In many cases, there can be multiple classes or categories. For example, in an image classification task, there could be classes like “cat,” “dog,” “car,” “tree,” and so on.
It’s important to note that the definition and representation of classes may vary depending on the specific problem and the context in which it is being addressed. The choice of classes plays a crucial role in determining the objectives of the machine learning task and the accuracy of the predictions or classifications made by the algorithm.
Overall, classes provide a structured framework that allows machines to understand and categorize data effectively. By organizing information into distinct categories, machine learning algorithms can make sense of complex datasets and perform various tasks, ranging from classification and prediction to anomaly detection and clustering.
Classes in Machine Learning
In the realm of machine learning, classes play a vital role in organizing, categorizing, and making sense of data. They provide a framework for machines to understand and classify various patterns and objects, allowing them to make informed decisions and predictions.
In supervised learning, each instance of data is associated with a specific class label. The goal of the machine learning algorithm is to learn the relationship between the input features and their corresponding classes. By observing a significant number of labeled examples, the algorithm can make predictions on new, unseen instances and assign them to the appropriate class.
For example, in a medical diagnosis system, classes could represent different diseases or conditions. The algorithm is trained on data where each patient’s medical history and test results are labeled with the corresponding disease. By consistently examining and analyzing such data, the algorithm can effectively classify future patients and provide accurate diagnostic predictions.
In unsupervised learning, classes are not predetermined or labeled. Instead, the algorithm aims to uncover underlying structures or patterns within the data. It accomplishes this by grouping similar instances together into clusters, where each cluster represents a potential class or category.
By identifying clusters, unsupervised learning algorithms can reveal relationships and associations that might not be immediately apparent. This can lead to valuable insights and facilitate various tasks, such as market segmentation, anomaly detection, and recommendation systems.
One popular approach in unsupervised learning is k-means clustering, where the algorithm partitions the data into k clusters based on their similarities. Each instance is assigned to the cluster with the closest features or characteristics. Through this process, the algorithm effectively organizes the data into distinct groups, providing a foundation for further analysis and decision-making.
Another technique often used in unsupervised learning is dimensionality reduction, where the algorithm aims to reduce the number of features or dimensions in the data while preserving its essential structure. This can help in visualizing the data and uncovering meaningful relationships that may not be easily identifiable in high-dimensional spaces.
Overall, classes form the backbone of machine learning algorithms. They provide the necessary structure and organization for machines to make sense of data and perform various tasks, such as classification, clustering, and dimensionality reduction. By harnessing the power of classes, machines can accurately identify patterns, make predictions, and gain valuable insights from complex datasets.
Supervised Learning and Classes
In the realm of machine learning, supervised learning is a powerful approach that relies on the use of labeled data to train algorithms. It involves associating each instance of data with a specific class label, allowing the algorithm to learn the relationship between the input features and their corresponding classes.
Supervised learning is particularly effective when the objective is to classify or predict outcomes based on the provided data. By observing numerous instances with known class labels, the algorithm can generalize and make accurate predictions on new, unseen instances.
The use of classes is integral to supervised learning algorithms. It allows the algorithm to categorize and differentiate different types of information, enabling accurate classification or prediction. The machine learning model learns the patterns or features associated with each class, enabling it to assign new instances to the appropriate class based on their similarities to the training data.
For instance, in a spam detection system, the classes would be “spam” and “not spam.” The algorithm is trained on a labeled dataset containing examples of both spam and legitimate emails. By examining the features of these emails, such as the presence of certain keywords or patterns, the algorithm can learn to distinguish between spam and legitimate emails. Subsequently, when presented with a new, unlabeled email, the algorithm can confidently classify it as either spam or not spam based on the learned patterns.
Supervised learning algorithms can employ various classification techniques to classify instances into classes. Decision trees, support vector machines, logistic regression, and neural networks are among the popular algorithms used in supervised learning. These algorithms differ in their underlying principles and mathematical models but all aim for accurate classification based on the provided class labels.
Furthermore, supervised learning is not limited to binary classifications. It can handle multi-class scenarios where more than two distinct classes exist. For example, in image recognition, the objective could be to classify images into categories like “cat,” “dog,” “bird,” “car,” and so on. In such cases, the algorithm learns the features and patterns specific to each class, allowing it to accurately classify new images into the appropriate category.
Supervised learning with classes fuels a wide range of applications, including medical diagnosis, fraud detection, sentiment analysis, and customer churn prediction. By leveraging the power of labeled data and classes, supervised learning algorithms can make informed predictions and drive decision-making processes in various domains.
Unsupervised Learning and Clusters
In the field of machine learning, unsupervised learning is an approach that aims to uncover hidden patterns or structures within data without the use of labeled examples. Unlike supervised learning, unsupervised learning algorithms do not rely on predefined classes but instead focus on grouping similar instances into clusters.
Clusters are sets or collections of instances that share common characteristics or properties. They represent potential classes or categories that emerge naturally from the data itself, without any prior information or labels. By identifying these clusters, unsupervised learning algorithms provide insights into the underlying structure and organization of the data.
One popular technique used in unsupervised learning is k-means clustering. This algorithm partitions the data into a specified number of clusters, where each instance is assigned to the cluster that has the closest features or characteristics. The goal is to minimize the sum of distances between instances and the centroid of the cluster they belong to.
For example, imagine a dataset containing information about different customers, such as age, income, and purchase history. By applying k-means clustering, the algorithm can group customers who exhibit similar characteristics into distinct clusters. This can inform marketing strategies, as it helps identify target customer segments and tailor campaigns based on the specific needs and preferences of each cluster.
Another powerful unsupervised learning technique is hierarchical clustering, which organizes instances into a hierarchical structure based on their similarities. This tree-like structure, known as a dendrogram, provides a visual representation of how instances cluster together at different levels of granularity.
Unsupervised learning and the identification of clusters can also play a vital role in anomaly detection. By understanding the normal behavior or patterns within a dataset, unsupervised learning algorithms can identify instances that deviate significantly from the norm. These instances, known as anomalies or outliers, can be indicative of potential fraud, system malfunctions, or other abnormal events that warrant further investigation.
It’s important to note that the number of clusters or the optimal partitioning of the data into clusters is not always known in advance. This can be determined through validation techniques, such as silhouette analysis or the elbow method, which help assess the quality and coherence of the clusters.
Unsupervised learning and clustering provide valuable insights into the structure and organization of data. They can be applied in various domains, including customer segmentation, image recognition, pattern discovery, and anomaly detection. By leveraging the power of unsupervised learning, machine learning algorithms can uncover hidden knowledge and facilitate decision-making processes in complex and unlabelled data scenarios.
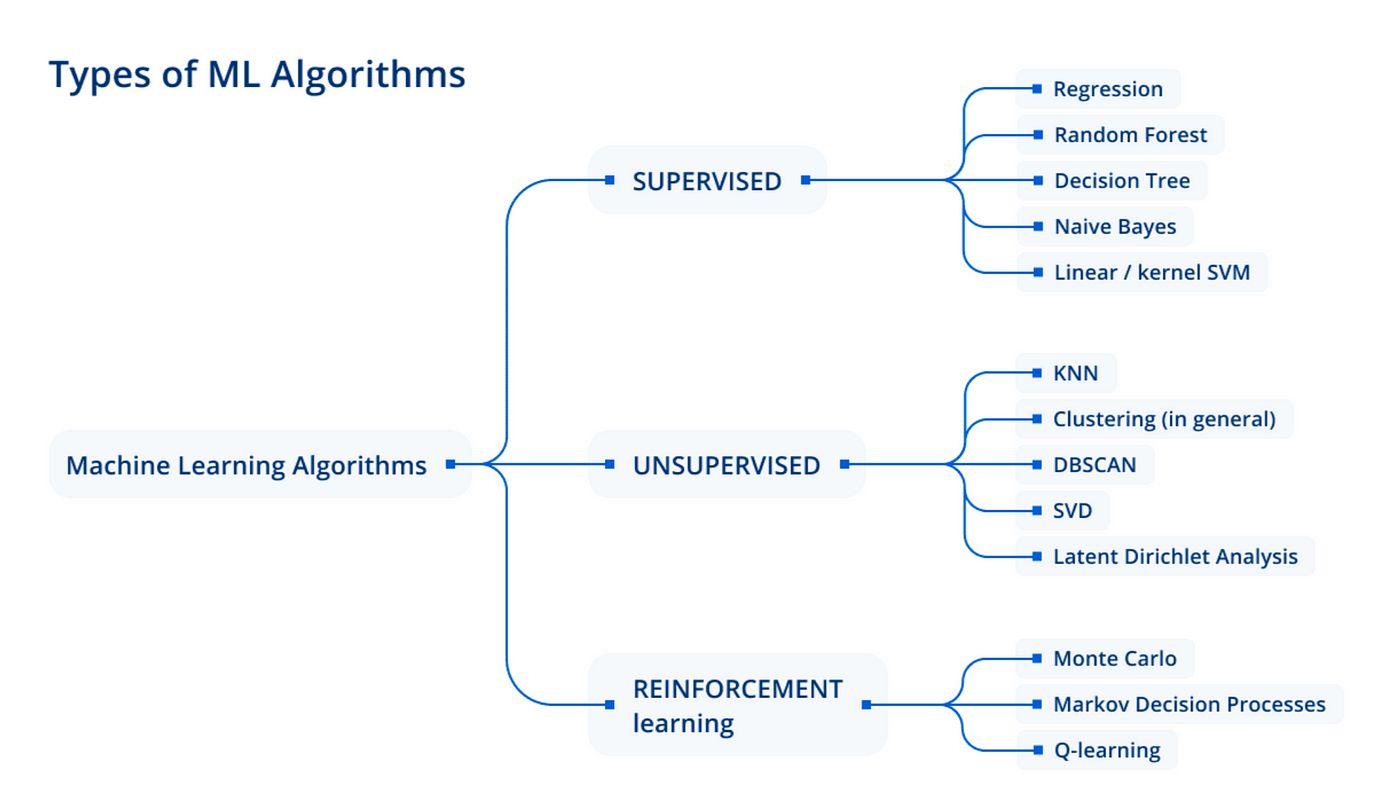
Classification Algorithms
In the field of machine learning, classification algorithms are used to train models that can assign instances of data to different predefined classes or categories. These algorithms are an essential component of supervised learning, where the machine learns from labeled examples to make accurate predictions.
There are numerous classification algorithms available, each with its own set of strengths and weaknesses, and they differ in terms of their underlying mathematical models and principles. Some popular classification algorithms include:
1. Decision Trees
Decision trees are intuitive and easy-to-interpret algorithms that use a tree-like structure to make decisions. They split the data into branches based on specific features and their thresholds, ultimately leading to leaf nodes representing the predicted classes.
2. Support Vector Machines (SVM)
SVM is a powerful algorithm that separates data points using a hyperplane in a high-dimensional space. It aims to maximize the margin between different classes, allowing for effective classification in both linearly separable and non-linearly separable datasets.
3. Logistic Regression
Logistic regression is a widely used algorithm for binary classification. It models the relationship between the input features and the probability of belonging to a particular class by applying a logistic function.
4. Naive Bayes
Naive Bayes is a probabilistic algorithm based on Bayes’ theorem. It assumes that features are conditionally independent, given the class labels. It uses prior probabilities and likelihoods to calculate the posterior probability of a class for a given instance.
5. Random Forest
Random Forest is an ensemble algorithm that combines multiple decision trees. Each tree in the forest is trained on a subset of the data and features, and the final prediction is made through a voting mechanism. It improves accuracy and reduces overfitting compared to a single decision tree.
6. Neural Networks
Neural networks are complex algorithms inspired by the structure and function of the human brain. They consist of interconnected artificial neurons organized into layers. Neural networks can learn complex relationships between features and produce accurate predictions in various types of data.
These are just a few examples of classification algorithms, and there are many others available depending on the specific requirements of the problem at hand. Each algorithm has its own set of assumptions, strengths, and limitations, and the choice of algorithm depends on factors such as dataset characteristics, interpretability requirements, and computational resources.
Classification algorithms continue to evolve with advancements in machine learning, and researchers and practitioners are constantly exploring new techniques to improve accuracy, efficiency, and interpretability. By leveraging the right classification algorithm for a given problem, machine learning models can make accurate predictions, assist in decision-making processes, and unlock valuable insights from data.
Conclusion
Classes are a fundamental concept in machine learning, providing a way to organize and categorize data. They play a crucial role in both supervised and unsupervised learning algorithms, enabling machines to make accurate predictions, classify instances, and uncover hidden patterns within the data.
In supervised learning, classes are used to train algorithms by associating labeled data with specific class labels. This allows the algorithm to learn the patterns and features associated with each class, enabling it to classify new, unlabeled instances accurately.
On the other hand, unsupervised learning algorithms do not rely on predefined classes but rather aim to uncover clusters or groups of similar instances within the data. Clusters form natural categories or classes that emerge from the data, providing insights into its underlying structure and organization.
A plethora of classification algorithms are available, each with its own strengths and applications. Decision trees, support vector machines, logistic regression, naive Bayes, random forest, and neural networks are just a few examples of these algorithms. The choice of algorithm depends on factors such as the nature of the problem, the characteristics of the dataset, and interpretability requirements.
By leveraging classes and classification algorithms, machines can make accurate predictions, identify patterns, understand complex datasets, and drive decision-making processes in various domains. From medical diagnoses and fraud detection to customer segmentation and sentiment analysis, machine learning approaches that utilize classes have immense practical value.
As the field of machine learning continues to advance, it is crucial to stay updated with the latest algorithms and techniques. By embracing the power of classes and continuously exploring new methodologies, we can harness the full potential of machine learning and unlock its transformative capabilities.