Introduction
Machine learning is a rapidly evolving field that focuses on developing algorithms and models that can learn and make predictions or decisions without explicit programming. It has gained significant attention and has been successfully applied in various industries, including healthcare, finance, marketing, and more.
At the heart of machine learning lie the parameters, which play a vital role in defining the behavior and performance of machine learning models. These parameters control the learning process and can significantly impact the accuracy and effectiveness of the model’s predictions.
In this article, we will delve into the world of machine learning parameters and explore their importance in building robust and accurate models. We will discuss the different types of machine learning parameters, the distinction between hyperparameters and model parameters, common examples of these parameters, and best practices for setting and tuning them. By understanding the role of parameters in machine learning, you will be better equipped to fine-tune your models and achieve optimal results.
So, let’s dive into the fascinating world of machine learning parameters and discover how they shape the performance of machine learning models.
What is Machine Learning?
Machine learning is a subset of artificial intelligence that focuses on developing algorithms and models that can learn from data and make predictions or decisions without being explicitly programmed. It enables computers to analyze large amounts of data, recognize patterns, and make accurate predictions or decisions based on that data.
There are various approaches to machine learning, but the most common one is supervised learning. In supervised learning, the algorithm is trained on a labeled dataset, where the inputs are paired with the corresponding correct outputs. The algorithm learns from these labeled examples and uses them to make predictions or decisions on new, unseen data.
One of the key concepts in machine learning is the idea of generalization. A well-trained machine learning model should not only perform well on the data it was trained on but also generalize well to new, unseen data. This ability to generalize is what allows machine learning models to make accurate predictions or decisions on real-world data.
Machine learning is commonly used in a wide range of applications, including image and speech recognition, natural language processing, recommendation systems, fraud detection, and autonomous vehicles, to name just a few. It has the potential to revolutionize various industries by automating processes and making intelligent decisions based on data.
Overall, machine learning is a powerful tool that allows computers to learn from data and make accurate predictions or decisions. It is a key driver of many technological advancements and has the potential to transform our daily lives.
What are Machine Learning Parameters?
Machine learning parameters are the knobs and settings that are used to tune and configure machine learning models. These parameters possess values that influence the behavior and performance of the algorithms used by the models. In other words, parameters act as the internal settings that can be adjusted to optimize the learning process and enhance the model’s predictive accuracy.
Each machine learning algorithm has its own set of parameters, which may control factors such as the learning rate, regularization strength, number of layers in a neural network, or the number of neighbors to consider in a k-nearest neighbors algorithm. These parameters are crucial because they determine the capacity and flexibility of the model and can have a significant impact on its performance.
Machine learning parameters can broadly be divided into two categories: hyperparameters and model parameters. Hyperparameters are set before the learning process begins and remain constant throughout training. They control aspects of the learning algorithm and model architecture, such as the number of hidden units in a neural network or the maximum depth of a decision tree. On the other hand, model parameters are learned during the training process and are specific to a particular model instance. They represent the internal weights and biases of the model that are adjusted to minimize the error between the predicted and actual outputs.
The process of setting and tuning machine learning parameters is known as parameter optimization or hyperparameter tuning. It involves selecting the right combination of parameter values to maximize the model’s performance while avoiding overfitting or underfitting. This process is typically iterative, wherein various parameter values are tested and evaluated using appropriate validation techniques.
Machine learning parameters are critical because they allow the model to adapt and learn from the data it is given. By fine-tuning these parameters, model performance can be improved, making accurate predictions or decisions on unseen data.
Why are Machine Learning Parameters Important?
Machine learning parameters play a crucial role in the performance and effectiveness of machine learning models. They directly influence the learning process and the model’s ability to make accurate predictions or decisions. Here are a few reasons why machine learning parameters are so important:
1. Model Optimization: Machine learning algorithms have default parameter values, but these may not be optimal for every dataset or problem. By tuning the parameters, we can optimize the model’s performance and improve its accuracy on the specific task at hand.
2. Generalization: Machine learning models aim to generalize well to unseen data. Properly tuned parameters can help the model achieve this generalization by finding the right balance between overfitting (where the model becomes too complex and fits the training data too closely) and underfitting (where the model is too simple and fails to capture the underlying patterns in the data).
3. Flexible Model Behavior: Different parameter values can lead to different model behaviors. By adjusting the parameters, we can make the model more or less flexible, allowing it to capture complex patterns or simplify its predictions based on the data characteristics.
4. Performance Improvements: Fine-tuning parameters can lead to significant improvements in model performance. By optimizing the parameters, we can reduce prediction errors, increase accuracy, and enhance the overall effectiveness of the model.
5. Adaptation to Specific Datasets: Each dataset has its own characteristics and nuances. By adjusting the parameters, we can make the model adapt to the specific dataset, ensuring that it captures the unique patterns and relationships present in the data.
6. Efficiency: Setting appropriate parameter values can have an impact on the efficiency and computational cost of the training process. By tuning the parameters, we can improve the training time and resource requirements, making the machine learning process more efficient.
Overall, machine learning parameters are important because they allow us to optimize the model’s performance, achieve generalization, and tailor the behavior of the model to specific datasets. By carefully selecting and tuning the parameters, we can create models that better capture the underlying patterns in the data and make more accurate predictions or decisions on new, unseen instances.
Types of Machine Learning Parameters
Machine learning models have different types of parameters that control their behavior and performance. Understanding these parameter types is crucial for effectively tuning and optimizing machine learning models. Here are the main types of machine learning parameters:
1. Hyperparameters: Hyperparameters are parameters that are set before the learning process begins and remain constant throughout training. They control the behavior and architecture of the learning algorithm and model. Examples of hyperparameters include the learning rate, regularization strength, number of hidden layers in a neural network, and the number of trees in a random forest. Hyperparameters significantly influence the model’s performance but are not learned from the data.
2. Model Parameters: Model parameters are the internal weights and biases of the model that are learned during the training process. They represent the knowledge acquired by the model from the training data. Model parameters are specific to each instance of the model and can vary between different model architectures or algorithms. Examples of model parameters include the weights in a neural network or the coefficients in a linear regression model.
3. Input-Dependent Parameters: Some models have input-dependent parameters that are determined by the characteristics of the input data. These parameters enable the model to adapt its behavior to different data instances. For example, in a k-nearest neighbors algorithm, the number of neighbors considered for prediction can be an input-dependent parameter that varies for each data point.
4. Output-Dependent Parameters: Output-dependent parameters are parameters that are influenced by the desired output or the loss function. These parameters can be used to fine-tune the model’s predictions based on the specific task or objective. For instance, in a classification model, the decision threshold for classifying a data point can be an output-dependent parameter that affects the classification outcome.
5. Global vs. Local Parameters: Machine learning models can have global parameters that influence the global behavior of the model, as well as local parameters that impact specific regions or sub-components of the model. Global parameters tend to have a broader impact on the overall model, while local parameters are more specific to certain parts of the model or specific instances.
Understanding the types of machine learning parameters is essential for effective parameter tuning and optimization. By properly adjusting these parameters, we can achieve optimal model performance, improve accuracy, and ensure that the model captures the underlying patterns in the data effectively.
Hyperparameters vs Model Parameters
When working with machine learning models, it is important to distinguish between hyperparameters and model parameters. Understanding the difference between these two types of parameters is crucial for effectively tuning and optimizing machine learning models. Here’s how hyperparameters and model parameters differ:
Hyperparameters: Hyperparameters are parameters that are set before the learning process begins and remain constant throughout training. They control the behavior and architecture of the learning algorithm and model. Hyperparameters are not learned from the data but are adjustable settings that need to be specified by the user. Examples of hyperparameters include the learning rate, regularization strength, number of hidden layers in a neural network, and the number of trees in a random forest. These parameters significantly impact the model’s performance but are independent of the training process itself.
Model Parameters: Model parameters, on the other hand, are the internal weights and biases of the model that are learned during the training process. They represent the knowledge acquired by the model from the training data. Model parameters are specific to each instance of the model and may vary between different model architectures or algorithms. Examples of model parameters include the weights in a neural network or the coefficients in a linear regression model. These parameters are adjusted iteratively during the training process to minimize the difference between the predicted outputs and the actual outputs.
The key distinction between hyperparameters and model parameters lies in their role and learning process. Hyperparameters are external to the model and influence the model’s behavior and characteristics. They are set prior to training and cannot be learned from the data. Model parameters, on the other hand, are internal to the model and are learned during the training process based on the provided labeled data. They capture the patterns and relationships in the data and are responsible for making accurate predictions on unseen instances.
It is important to optimize both hyperparameters and model parameters for achieving optimal model performance. Hyperparameter optimization involves finding the best combination of hyperparameter values that maximize the model’s performance. This typically requires thorough experimentation and evaluation of different parameter configurations. Model parameter optimization, on the other hand, involves adjusting the internal weights and biases of the model to minimize the training error on the given dataset.
By understanding and appropriately adjusting hyperparameters and model parameters, it is possible to fine-tune machine learning models and improve their accuracy and generalization capabilities. Finding the right balance and combination of these parameters is crucial for building robust and effective models that can make accurate predictions or decisions in real-world scenarios.
Common Examples of Machine Learning Parameters
Machine learning models have various parameters that control their behavior and performance. Here are some common examples of machine learning parameters:
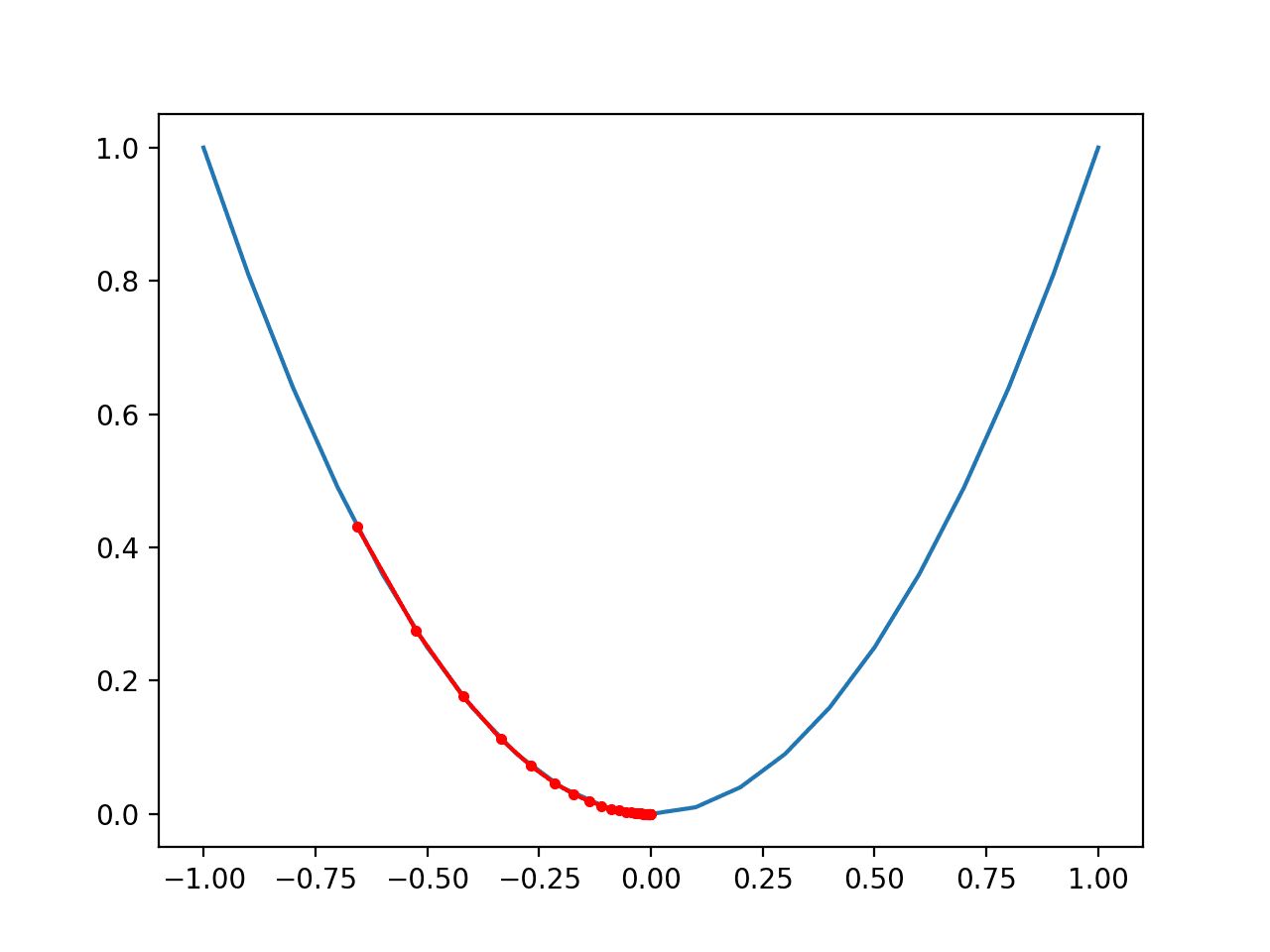
1. Learning Rate: The learning rate is a hyperparameter that determines how quickly or slowly a machine learning model adapts to the data. A higher learning rate can lead to faster convergence, but it may also increase the risk of overshooting the optimal solution. Conversely, a lower learning rate may result in slower convergence but can lead to better accuracy.
2. Regularization Strength: Regularization is a technique used to prevent overfitting in machine learning models. The regularization strength parameter controls the amount of regularization applied to the model. Higher values of the regularization strength can reduce overfitting but may also increase underfitting.
3. Number of Hidden Layers: In neural networks, the number of hidden layers is a hyperparameter that determines the depth and complexity of the model. Adding more hidden layers can allow the model to learn more complex representations but may also increase the risk of overfitting if not appropriately regularized.
4. Number of Neighbors: In k-nearest neighbors (KNN) algorithms, the number of neighbors to consider for making predictions is a hyperparameter. Choosing the right number of neighbors is crucial for balancing bias and variance in the model and has a direct impact on its performance.
5. Number of Trees: In ensemble learning algorithms like random forest, the number of trees is a hyperparameter that determines the size and complexity of the forest. Increasing the number of trees can improve model performance but may also increase computational resources and training time.
6. Activation Function: In neural networks, the activation function determines the output of a neuron. Choosing the right activation function is critical for allowing the model to learn complex non-linear relationships. Common activation functions include sigmoid, tanh, and ReLU.
7. Batch Size: For models trained using stochastic gradient descent, the batch size is a hyperparameter that controls the number of training examples seen by the model in each iteration. A larger batch size can lead to faster convergence, but it may also require more memory and computational resources.
8. Dropout Rate: Dropout is a regularization technique used in neural networks to prevent overfitting. The dropout rate is a hyperparameter that determines the probability of dropping out a neuron during training. Higher dropout rates can increase model robustness but may also lead to increased training time.
These are just a few examples of machine learning parameters. Each machine learning algorithm and model may have its own specific parameters that influence its behavior and performance. It is crucial to understand these parameters and their impact to effectively fine-tune and optimize machine learning models.
How to Set Machine Learning Parameters
Setting machine learning parameters is a crucial step in building effective models. The process involves finding the right combination of parameter values that optimize the model’s performance and accuracy. Here are some strategies for setting machine learning parameters:
1. Default Values: Many machine learning algorithms have default parameter values that are a good starting point for model training. These default values are often based on common practices and can provide reasonable results for many cases. However, it’s important to remember that default values may not always be optimal for every dataset or problem.
2. Grid Search: Grid search is a systematic approach to parameter tuning. It involves specifying a range of values for each parameter and exhaustively evaluating the model’s performance with these combinations. This method can be time-consuming but provides a comprehensive evaluation of different parameter configurations.
3. Random Search: Random search is an alternative approach to parameter tuning that involves randomly sampling parameter combinations within specified ranges. This approach can be more efficient than grid search when the parameter space is large and the impact of individual parameters is not well-known.
4. Model-Specific Techniques: Some machine learning models have specific techniques or algorithms for parameter tuning. For example, in gradient boosting machines, parameters can be optimized using techniques like gradient-based optimization or Bayesian optimization. Model-specific techniques leverage the knowledge about the model’s internal workings to find optimal parameter values efficiently.
5. Cross-Validation: Cross-validation is a technique used to estimate the performance of a model on unseen data. It can also help in selecting the best parameter values. By splitting the training data into multiple subsets and evaluating the model’s performance, we can identify parameter values that lead to better generalization.
6. Domain Knowledge: Domain knowledge and understanding of the problem at hand can provide valuable insights for setting parameters. Prior knowledge about the data or problem characteristics can guide the selection of appropriate parameter values. This can involve considering factors such as data distribution, feature importance, or task-specific constraints.
7. Iterative Refinement: Parameter tuning is an iterative process. It involves trying different parameter values, evaluating performance, and fine-tuning based on the results. This iterative refinement can be performed in conjunction with techniques like grid search or random search to narrow down the parameter space effectively.
While these strategies provide a starting point for parameter tuning, it’s important to remember that the optimal parameter values may vary depending on the specific dataset and problem. Experimentation and evaluation are key to finding the best parameter values that result in accurate, well-performing models.
Best Practices for Tuning Machine Learning Parameters
Tuning machine learning parameters can be a complex and iterative process. Here are some best practices to follow when tuning machine learning parameters:
1. Start with Default Values: Begin by using the default parameter values provided by the machine learning algorithm. These values are often set based on common practices and can provide a reasonable starting point for model training.
2. Understand the Impact of Parameters: Gain an understanding of how each parameter affects the model’s behavior and performance. Consider the trade-offs between bias and variance, computational resources, and model complexity. This understanding will guide you in selecting the parameters to tune and their potential values.
3. Define a Parameter Search Space: Define a parameter search space, specifying the acceptable ranges or values for each parameter. This helps to systematically explore different parameter combinations during the tuning process.
4. Use Evaluation Metrics: Select appropriate evaluation metrics to quantify the model’s performance. This will provide a quantitative measure to compare different parameter configurations and choose the optimal ones.
5. Implement Cross-Validation: Utilize cross-validation to estimate the model’s performance and reduce the risk of overfitting. Split the data into multiple subsets and evaluate the model on each fold. This enables a more robust assessment of the model’s generalization capability.
6. Utilize Grid Search or Random Search: Employ systematic search strategies such as grid search or random search to explore the parameter space. Grid search exhaustively evaluates all possible parameter combinations, while random search randomly samples parameter values. Both approaches help identify promising parameter configurations.
7. Consider Computation Time: Take into account the computational resources required to train the model with different parameter configurations. Certain parameter settings may require more time or memory, so strike a balance between computational constraints and performance improvements.
8. Experiment Iteratively: Treat parameter tuning as an iterative process. Begin with a broad search to identify a set of promising parameter configurations. Based on the initial results, narrow down the search space and perform fine-grained optimization to refine the parameter values.
9. Keep Track of Results: Maintain a record of the parameter combinations and the corresponding evaluation metrics. This record helps gain insights into the relationship between the parameters and the model’s performance, guiding future iterations of parameter tuning.
10. Consider Domain Knowledge: Leverage domain knowledge and expertise to guide parameter tuning. Understand the data, the problem being solved, and potential constraints that can inform the selection of parameter values.
By following these best practices, you can ensure a systematic and effective process for tuning machine learning parameters, leading to optimized models with improved performance on real-world tasks.
Conclusion
Machine learning parameters are a fundamental component of building effective and accurate models. They influence the behavior and performance of machine learning algorithms, allowing them to adapt and make accurate predictions or decisions. By understanding the different types of parameters, such as hyperparameters and model parameters, we can navigate the process of parameter tuning and optimization more effectively.
Setting machine learning parameters requires a systematic approach, taking into account best practices such as starting with default values, understanding parameter impact, and defining a parameter search space. Evaluating model performance using appropriate metrics and employing strategies like cross-validation, grid search, or random search can help identify optimal parameter configurations.
It’s important to remember that there isn’t a one-size-fits-all solution when it comes to parameter tuning. The optimal parameter values often depend on the specific dataset, problem, and domain knowledge. The tuning process requires iteration, experimentation, and fine-tuning to achieve the best possible model performance.
Ultimately, by effectively setting and tuning machine learning parameters, we can improve the accuracy, generalization, and efficiency of our models. The ability to fine-tune parameters not only leads to better predictions or decisions but also enables machine learning models to adapt to various datasets and real-world scenarios.
As the field of machine learning continues to evolve, advances in algorithms, optimization techniques, and parameter tuning strategies will further enhance model performance and our ability to effectively utilize machine learning in various applications.