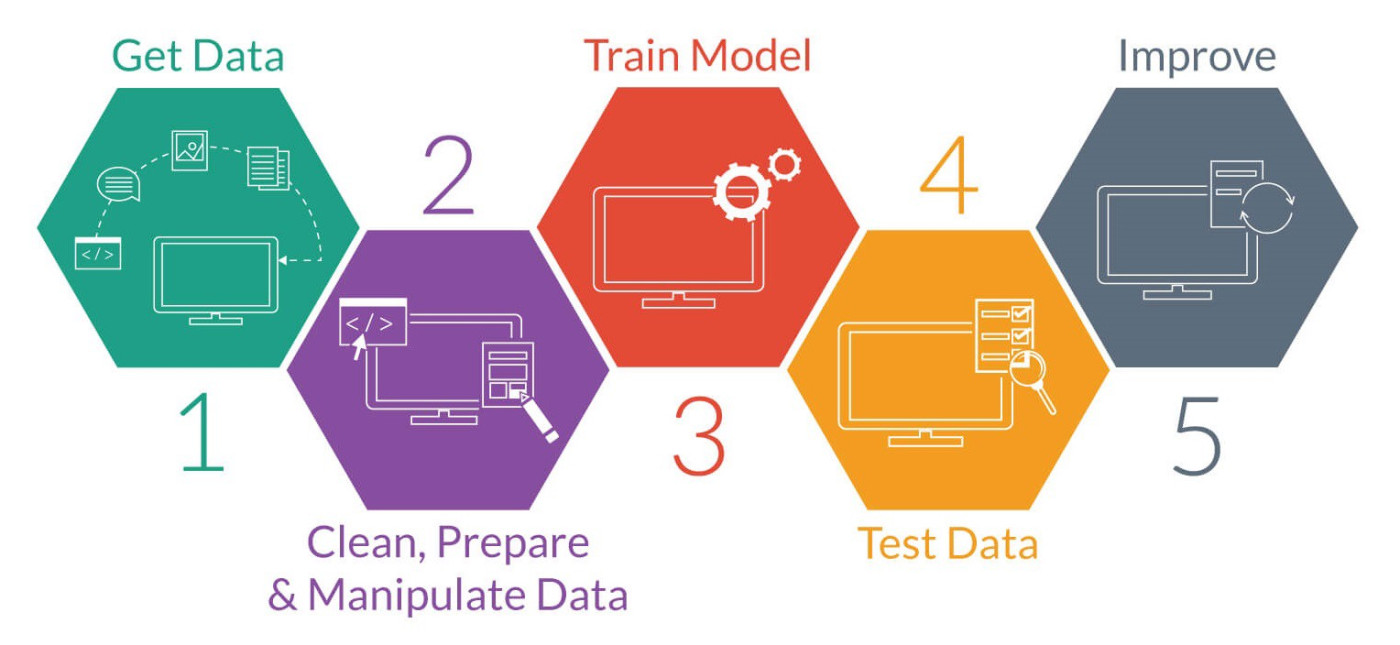
Introduction
Machine learning has become a popular and powerful field in the realm of technology. It enables computers to learn from data and make predictions or decisions without being explicitly programmed. One of the key components of machine learning is training a model, which involves feeding it with relevant data so that it can learn and generalize patterns.
Training a machine learning model is a crucial step in the development of an intelligent system. It enables the model to make accurate predictions based on the given input. Whether you’re building an image recognition system, a recommendation engine, or a language translator, training the model is essential to achieve high performance.
In this article, we will explore the step-by-step process of training a machine learning model. We’ll cover everything from gathering and preparing the data to evaluating the model’s performance and fine-tuning it for optimal results.
Before we dive into the specifics, it’s important to highlight that training a machine learning model requires not only a solid understanding of algorithms but also a good grasp of the data you are working with. The quality and quantity of the data can greatly impact the performance of the model, so careful consideration and preparation are necessary.
Throughout this article, we will discuss various techniques and best practices for training a machine learning model. Let’s get started with the first step: gathering and preparing the data.
Gathering and Preparing Data
When it comes to training a machine learning model, the quality and relevance of the data you use are critical. Gathering and preparing the data is the first crucial step in the process.
Before you start gathering data, it’s important to have a clear understanding of the problem you are trying to solve. Identify the specific variables and attributes that are relevant to your target outcome. This will help you determine the type of data you need and where to find it.
There are several methods you can use to gather data. You can collect data from existing databases, scrape websites, utilize APIs, or even crowdsource data from users. The key is to ensure that the data you collect is representative of the problem you’re tackling and is of sufficient quantity.
Once you have collected the data, the next step is to prepare it for training. This involves cleaning and preprocessing the data to ensure its quality and consistency. Here are some essential steps in data preparation:
- Data Cleaning: Remove any duplicate or irrelevant data, handle missing values, and correct any inconsistencies in the data.
- Data Transformation: Convert categorical variables into numerical values or apply scaling to normalize the data. This step ensures that the data is in a suitable format for the machine learning algorithms.
- Feature Selection: Identify the most relevant features that will contribute to the model’s performance and remove any unnecessary or redundant variables.
It’s important to note that data preparation may require considerable time and effort, as the quality of the data directly affects the accuracy and performance of the trained model. Invest sufficient time in this step to ensure your data is clean, consistent, and ready for training.
Once you have gathered and prepared the data, you’re ready to move on to the next step: choosing the right algorithm for your machine learning model.
Choosing the Right Algorithm
Selecting the right algorithm is critical to the success of your machine learning model. The algorithm you choose will determine how the model learns from the data and makes predictions or decisions. There are several factors to consider when deciding on the most suitable algorithm:
- Problem Type: Determine whether your problem is a classification, regression, clustering, or anomaly detection problem. Different algorithms are designed to tackle specific types of problems. For example, if you’re working on a classification problem, algorithms like Logistic Regression, Decision Trees, or Support Vector Machines may be suitable.
- Data Size: Take into account the size of your dataset. Some algorithms perform better on large datasets, while others are more suited for smaller or more complex datasets. For instance, if you have a large dataset, algorithms like Random Forests or Gradient Boosting Machines may be more effective.
- Model Complexity: Consider the complexity of the patterns in your data. If your data exhibits complex relationships, you may need to choose algorithms that are capable of capturing and learning these intricate patterns, such as Neural Networks or Deep Learning models.
- Interpretability: Evaluate whether interpretability is an important factor in your application. Some algorithms, like Decision Trees or Logistic Regression, provide interpretable models that can be easily understood and explained. In contrast, complex models like Neural Networks may offer higher accuracy but are harder to interpret.
It’s important to note that there is no one-size-fits-all algorithm. Different algorithms have different strengths and weaknesses, and the suitability of an algorithm depends on the specific characteristics of your problem and data.
One effective approach is to start with a simpler algorithm that aligns with your problem type, such as Logistic Regression or Decision Trees. This allows you to establish a baseline and understand the fundamental relationships in your data. From there, you can explore more sophisticated algorithms and compare their performance to the baseline model.
Additionally, it’s essential to experiment with different algorithms and tune their hyperparameters to find the optimal configuration for your data. This process may involve trial and error, but it’s necessary to achieve the best possible performance for your machine learning model.
Once you have chosen the appropriate algorithm, the next step is to split the data for training and testing, which we will explore in the next section.
Splitting the Data
Splitting the data is a crucial step in training a machine learning model. It involves dividing the available data into separate sets for training and testing. The purpose of this split is to assess the model’s performance on unseen data and to evaluate its ability to generalize well.
Typically, the data is divided into two sets: a training set and a testing set. The training set is used to train the model by feeding it with labeled data, where the input features are known and the corresponding output or target values are provided. The testing set, on the other hand, is used to evaluate the model’s performance after training.
The proportion of the data allocated to each set can vary depending on the size of the dataset and the specific problem. A common approach is to allocate around 70-80% of the data to the training set and the remaining 20-30% to the testing set. This ensures an adequate amount of data for the model to learn from, while still leaving enough data for testing and evaluation.
It is important to ensure that the data splitting process is random and unbiased. This means that the split should maintain the distribution of the data, preserving the proportions of different classes or categories if applicable. Randomizing the data before the split helps to prevent any unintentional biases that might occur if the data is ordered in a specific way.
Splitting the data into training and testing sets allows you to assess how well your model performs on unseen data. This is crucial to ensure that your model is not overfitting, which happens when it learns the training data too well but fails to generalize to new, unseen data. Evaluating your model on the testing set helps you gauge its performance and make improvements if necessary.
It’s worth noting that in some cases, a third set called a validation set may be used. The validation set is used for hyperparameter tuning and model selection. It helps to optimize the model by adjusting the hyperparameters and selecting the best-performing model based on its performance on the validation set.
Once the data is split into appropriate sets, you can move on to the next step of training your machine learning model: feature engineering.
Feature Engineering
Feature engineering is a crucial step in training a machine learning model. It involves transforming the raw input data into a format that the algorithm can effectively learn from. By extracting, selecting, and creating meaningful features, you can enhance the predictive power of your model and improve its performance.
Here are some common techniques and considerations for feature engineering:
- Feature Extraction: Extract valuable information from the raw data by transforming it into a more compact representation. This can involve techniques such as dimensionality reduction using methods like Principal Component Analysis (PCA) or extracting statistical features like mean, median, or standard deviation.
- Feature Selection: Choose the most relevant features that contribute significantly to the target variable. This can involve methods like correlation analysis, where you measure the relationship between features and the target variable, or using algorithms like LASSO regression or Recursive Feature Elimination (RFE) to select the most important features.
- Feature Creation: Create new features by combining existing ones or applying mathematical operations. For example, you can create interaction terms, polynomial features, or time-based features to capture additional patterns or relationships in the data.
- Handling Categorical Variables: If your dataset contains categorical variables, you’ll need to transform them into a numerical form that the algorithm can handle. This can be done through one-hot encoding, label encoding, or target encoding, depending on the specific characteristics of the data.
Feature engineering requires a good understanding of the data and domain knowledge. It involves careful analysis of the data to identify meaningful patterns and relationships that can be effectively captured by the model. It’s important to strike a balance between simplicity and complexity in feature engineering, as overly complex features may lead to overfitting, while too simple features may result in underfitting.
It’s also important to note that feature engineering is an iterative process. You may need to revisit and refine your feature engineering techniques based on the performance of your model. Continuous experimentation, evaluation, and refinement of features can lead to better model performance and improved predictions.
Once your features are engineered, you can proceed to the next step: training the model.
Training the Model
Training the model is the core step in the machine learning pipeline. It involves feeding the prepared data to the chosen algorithm and iteratively updating the model’s parameters to minimize the error or maximize the performance metric.
When training the model, you will typically use the training set that was created during the data splitting process. The model learns from the input features and the corresponding target values or labels provided in the training set. The algorithm uses various optimization techniques, such as gradient descent, to adjust the model’s parameters and minimize the difference between the predicted outputs and the actual outputs.
The training process entails the following steps:
- Initialization: Initialize the model with initial values for its parameters. The chosen algorithm determines the model’s architecture and the specific parameters to be learned.
- Forward Propagation: Calculate the predicted outputs or probabilities by propagating the input features through the model’s layers or nodes. This step involves applying activation functions and performing matrix computations as defined by the algorithm.
- Loss Calculation: Measure the discrepancy between the predicted outputs and the actual target values using a loss or cost function. The choice of the loss function depends on the problem type, such as mean squared error for regression or cross-entropy for classification.
- Backpropagation: Propagate the calculated loss backwards through the model to adjust the parameters and update their values. This step involves computing the gradients of the loss with respect to each parameter and applying the optimization technique to update the parameters.
- Iteration: Repeat the forward propagation, loss calculation, and backpropagation steps for multiple iterations or epochs. This allows the model to learn from the data and refine its parameters iteratively.
The number of iterations or epochs required for training can vary depending on the complexity of the problem and the convergence of the model. It’s important to monitor the model’s performance during training using evaluation metrics and validation sets to prevent overfitting or underfitting.
Training a model can be computationally intensive, especially for complex algorithms or large datasets. It may require access to powerful hardware or cloud computing resources to speed up the process. However, with advancements in hardware and frameworks, training models has become more accessible and efficient.
Once the model has been trained, you can evaluate its performance using the testing set, which we will discuss in the next section.
Evaluating the Model
Evaluating the performance of your trained machine learning model is an essential step in assessing its accuracy and generalization capabilities. By evaluating the model, you can determine how well it performs on unseen data and understand its strengths and weaknesses.
There are several evaluation metrics that can be used depending on the nature of the problem you are solving. Here are some commonly used evaluation metrics:
- Accuracy: Accuracy measures the proportion of correctly classified instances out of the total number of instances. It is a commonly used metric for classification problems with balanced classes.
- Precision, Recall, and F1-score: These metrics are useful for imbalanced class problems and provide insights into the model’s performance in terms of false positives (precision) and false negatives (recall). The F1-score is the harmonic mean of precision and recall.
- Mean Squared Error (MSE) or Root Mean Squared Error (RMSE): These metrics are commonly used for regression problems and quantify the average squared difference between the predicted and actual values.
- R^2 Score: The R-squared score measures the proportion of the variance in the target variable that can be explained by the model. It provides an indication of how well the model fits the data.
In addition to these metrics, it’s important to visualize and analyze the model’s performance through techniques such as confusion matrices, precision-recall curves, or ROC curves. These visualizations can provide deeper insights into the model’s performance and help in understanding the trade-offs between different evaluation metrics.
When evaluating the model, it’s crucial to use data that the model hasn’t seen during training or hyperparameter tuning. This allows for a fair assessment of its generalization capabilities. The testing set, which was set aside during the data splitting step, is usually used for this purpose.
Remember that the evaluation process should go beyond just looking at numerical metrics. It’s important to consider the context of your problem and the specific requirements of your application when interpreting the results. Understanding the limitations of the model and potential sources of errors can help guide further improvements or iterations.
Evaluation is an iterative process. It may involve fine-tuning the model, adjusting hyperparameters, or exploring different algorithms or techniques to improve the model’s performance. Continuous evaluation and refinement of the model are essential to ensure its effectiveness in real-world scenarios.
Once you have evaluated your model and are satisfied with its performance, you can proceed to the next step: fine-tuning the model to optimize its performance.
Fine-tuning the Model
After evaluating the performance of your machine learning model, you may identify areas where it can be further improved. Fine-tuning the model involves making adjustments to enhance its performance, optimize its hyperparameters, and address any shortcomings observed during the evaluation.
Here are some key steps to consider when fine-tuning your model:
- Hyperparameter Optimization: Adjust the hyperparameters of your model to find the optimal configuration that yields the best performance. Hyperparameters are parameters that are not learned during training and have to be set prior to training. Examples include learning rate, regularization strength, and the number of hidden layers in a neural network. Techniques like grid search or random search can be employed to systematically explore different combinations of hyperparameters.
- Regularization Techniques: Implement regularization techniques to prevent overfitting and improve the generalization capabilities of the model. Techniques like L1 or L2 regularization, dropout, or early stopping can be applied to control the model’s complexity and prevent it from memorizing the training data.
- Data Augmentation: Expand your training dataset by applying data augmentation techniques. This involves introducing variations in the existing data to increase its diversity and improve the model’s ability to generalize. For example, in image classification, applying random rotations, translations, or color transformations can enhance the model’s robustness.
- Ensemble Methods: Implement ensemble methods to combine multiple models and improve predictive performance. Techniques like bagging, boosting, or stacking can be employed to leverage the diversity of individual models and achieve better results. This can be particularly effective when the models have different strengths or weaknesses.
Fine-tuning the model requires an iterative process of experimentation and evaluation. Each adjustment made to the model or its hyperparameters should be followed by reevaluation to assess its impact. This iterative approach helps identify the most effective strategies for improving the model’s performance.
It’s important to note that fine-tuning the model should not be done on the testing set, as it could lead to overfitting. Instead, it’s recommended to have a separate validation set or use techniques like cross-validation to evaluate the model’s performance during the fine-tuning process.
During the fine-tuning phase, it’s important to keep track of the changes made and document the improvements observed. This helps in understanding the model’s behavior and provides insights for future model iterations or similar problem domains.
Once you have fine-tuned your model and achieved the desired level of performance, you can proceed to the final step: finalizing the model for deployment or further use.
Finalizing the Model
Finalizing the model is the last step in the machine learning pipeline before deploying it for practical use. This step involves conducting a final evaluation, saving the trained model, and preparing it for integration into a production environment.
Here are the key actions to take when finalizing the model:
- Final Evaluation: Perform a comprehensive evaluation of the model’s performance using the testing set or a dedicated validation set. This evaluation ensures that the model meets the desired metrics, achieves the expected accuracy, and performs well on unseen data.
- Save the Model: Save the trained model in a format that can be easily reloaded or reused. This allows you to deploy the model in a production environment or share it with others for further testing or analysis. Common formats for saving models include pickle, JSON, or even more specialized formats such as ONNX for interoperability with other frameworks or platforms.
- Documentation and Reporting: Document key details about the model, including the algorithm used, hyperparameters, feature engineering techniques, and any insights gained during the training and evaluation process. This documentation preserves the knowledge and understanding of the model, making it easier for future maintenance, troubleshooting, or model replication.
- Integration and Deployment: Integrate the finalized model into the intended application or system. This may involve creating an API or library that allows other software components to interact with the model seamlessly. Ensure that the necessary dependencies and resources are available for the model to function correctly in its deployed environment.
- Monitoring and Maintenance: Continuously monitor the performance of the deployed model in the real-world setting. Monitor key metrics, collect feedback, and update the model as needed to account for changing data patterns or evolving business needs. Regular maintenance and updates are essential to ensure that the model remains accurate and reliable over time.
Finalizing the model marks the completion of the training and deployment process. It is important to ensure clear communication between the data science team, software engineers, and stakeholders to facilitate a smooth transition from development to deployment.
Remember that machine learning models are not static entities. They require ongoing monitoring, evaluation, and improvement as new data becomes available or the problem landscape evolves. Regular updates and maintenance are crucial to keep the model up-to-date and preserve its effectiveness in solving real-world problems.
Conclusion
Training a machine learning model is a complex but rewarding process that allows computers to learn from data and make accurate predictions or decisions. Through the various steps discussed in this article, you can effectively train a model and improve its performance.
Gathering and preparing data is the crucial first step, as the quality and relevance of the data greatly impact the model’s accuracy. Choosing the right algorithm based on problem type, data size, and interpretability is essential. Splitting the data into training and testing sets enables evaluation of the model’s generalization capabilities.
Feature engineering plays a significant role in enhancing the model’s predictive power, incorporating relevant features and removing noise. Training the model involves adjusting parameters and minimizing the error between predicted and actual values. Evaluating the model through appropriate metrics helps assess its performance and detect areas for improvement.
Fine-tuning the model through hyperparameter optimization, regularization, data augmentation, or ensemble methods can further enhance its accuracy and robustness. Finally, finalizing the model involves saving, documenting, integrating, and monitoring it to ensure its effectiveness in real-world scenarios.
Training a machine learning model is an iterative process that requires continuous evaluation, refinement, and adaptation. As technology advances and new methodologies emerge, it is essential to stay updated and adopt best practices for optimal results.
By following the steps outlined in this article and staying committed to continuous learning and improvement, you can train machine learning models that make a significant impact in various domains, from healthcare and finance to marketing and beyond.