Introduction
The field of machine learning has gained significant attention and popularity in recent years. With the ability to process large amounts of data using algorithms, machine learning models are capable of making accurate predictions and intelligent decisions. However, despite the advancements in this domain, building and debugging a machine learning model can still be a challenging task.
In this article, we will delve into the process of debugging a machine learning model, exploring the various steps and techniques involved. Debugging a model essentially means identifying and rectifying errors or issues that may arise during the development and deployment of the model. These errors can range from data preprocessing problems to algorithmic weaknesses and overfitting.
Understanding the importance of debugging is crucial as it not only improves the performance of the model but also enhances its reliability and credibility. A well-debugged model is more likely to provide accurate predictions and better insights.
This article aims to provide an overview of the debugging process and equip you with valuable tools and strategies to effectively debug your machine learning model. Whether you are a seasoned data scientist or a beginner exploring the world of machine learning, the techniques discussed here will help you troubleshoot common issues and optimize the performance of your models.
Without further ado, let’s dive into the world of machine learning debugging and explore the steps involved in ensuring the reliability and accuracy of your models.
Understanding the Problem
Before diving into the process of debugging a machine learning model, it is essential to have a comprehensive understanding of the problem at hand. This involves gaining clarity on the goals, constraints, and requirements of the model.
Start by clearly defining the problem you are trying to solve. Is it a classification problem, where you need to predict categories or classes? Or is it a regression problem, where you aim to predict continuous values? Understanding the nature of the problem will help you choose the appropriate modeling techniques and evaluation metrics.
Next, consider the specific constraints and requirements of the problem. Are there any limitations on the data you can collect or the resources available? This information will influence your modeling decisions and help you choose the right algorithms and techniques to maximize performance within the given constraints.
Additionally, it is crucial to identify any inherent biases or imbalances in the data. Biases can lead to skewed model predictions and impact the overall performance. Carefully analyze your data to ensure it is representative and unbiased. Data preprocessing techniques such as sampling, feature engineering, and balancing can be employed to address these issues.
During this stage, it is also important to consider the scalability and generalizability of the model. Will the model be deployed in a real-world production scenario? If so, it should be robust enough to handle unseen data and maintain its performance over time. Consider techniques such as cross-validation and model evaluation on test datasets to assess the model’s generalization.
By thoroughly understanding the problem, its constraints, and biases, you lay a strong foundation for building and debugging your machine learning model. This clarity will guide your decision-making throughout the process and help you identify and address potential issues effectively.
Gathering and Preparing Data
Gathering and preparing data is a critical step in the machine learning process. Good quality data is essential for training accurate and reliable models. In this section of the article, we will explore the steps involved in gathering and preparing data for your machine learning project.
The first step is to identify and collect the relevant data for your problem. Depending on the nature of your problem, you may need to gather data from a variety of sources, such as databases, APIs, or web scraping. It is important to ensure that the data you collect is representative of the problem and covers a wide range of scenarios.
Once you have collected the data, the next step is to clean and preprocess it. This involves handling missing values, dealing with outliers, and performing feature engineering. Missing values can be imputed using techniques such as mean imputation, regression imputation, or using advanced imputation models. Outliers can be identified and treated by either removing them or transforming them to minimize their impact on the model.
Feature engineering plays a crucial role in preparing the data for modeling. This involves transforming and manipulating the existing features or creating new features that capture important information. Techniques such as one-hot encoding, feature scaling, and creating interaction variables can help improve the performance of the model.
In addition to preprocessing the data, it is important to split it into training and testing datasets. The training dataset is used to build and train the model, while the testing dataset is used to evaluate the performance of the model. This separation helps in assessing the generalization ability of the model and prevents overfitting.
Lastly, it is essential to perform exploratory data analysis (EDA) to gain insights into the data and understand its distribution and relationships. Visualizations and statistical analyses can help in identifying patterns, correlations, and potential issues in the data.
By thoroughly gathering and preparing the data, you set the foundation for building a reliable and accurate machine learning model. This step is crucial in identifying any data-related issues and ensuring that the model is trained on a high-quality dataset.
Choosing the Right Model
Choosing the right machine learning model is crucial for the success of your project. With a plethora of algorithms and techniques available, it is important to understand the strengths and limitations of different models and select the one that best suits your problem. In this section of the article, we will explore the process of choosing the right model for your machine learning project.
The first step in the model selection process is to have a clear understanding of the problem you are trying to solve. Is it a classification problem, a regression problem, or something else? Based on the problem type, you can narrow down the list of suitable models.
Next, consider the size and complexity of your dataset. Some models work well with small datasets, while others require larger amounts of data to perform effectively. If you have a limited dataset, simpler models like logistic regression or decision trees may be more appropriate. On the other hand, if you have a large dataset, more complex models like deep learning algorithms or gradient boosting can be considered.
Consider the interpretability of the models as well. Some models, such as linear regression or decision trees, provide transparent and easily interpretable results, which can be beneficial when explaining the model to stakeholders or regulatory bodies. Other models, like neural networks or support vector machines, may have more complex internal structures and lack interpretability.
Another important factor to consider is the time and computational resources required to train and deploy the model. Some models are computationally expensive and may require high-performance hardware to train efficiently. If you have limited resources, you may need to select a model that is computationally efficient or can be trained on a subset of data.
Additionally, take into account the robustness of the model. How well does it handle noisy or missing data? How sensitive is it to outliers? Robust models are capable of handling data imperfections and are less likely to be influenced by outliers.
Lastly, consider the availability of libraries and frameworks for implementing the chosen model. Popular machine learning libraries like scikit-learn, TensorFlow, or PyTorch provide extensive support for various models and can streamline the development process.
By carefully considering these factors, you can choose the right model that aligns with the problem requirements and constraints. Remember that the model selection process may involve trial and error, and it is important to iterate and experiment to find the best fit for your specific problem.
Training the Model
Once you have chosen the right model for your machine learning project, the next step is to train the model using your prepared dataset. Training a model involves fitting the algorithm to the data, allowing it to learn the patterns and relationships within the dataset. In this section of the article, we will explore the process of training a machine learning model.
The first step in training a model is to split your prepared dataset into two parts: the training dataset and the validation dataset. The training dataset is used to train the model, while the validation dataset is used to assess the performance of the model during training and tune its hyperparameters.
During the training process, the model iteratively updates its internal parameters to minimize the difference between the predicted outputs and the actual outputs in the training dataset. This is achieved by using optimization algorithms such as gradient descent or stochastic gradient descent.
It is important to monitor the performance of the model during training to prevent overfitting. Overfitting occurs when the model becomes too complex and perfectly fits the training data but fails to generalize to unseen data. Regularization techniques such as L1 and L2 regularization can be employed to prevent overfitting.
Additionally, tuning the hyperparameters of the model can significantly impact its performance. Hyperparameters are the settings that define the behavior of the model, such as the learning rate, the number of hidden layers in a neural network, or the kernel type in a support vector machine. Grid search or random search techniques can be used to find the optimal combination of hyperparameters.
Training a model can be an iterative process. It is important to experiment with different configurations, hyperparameters, and optimization techniques to find the best performance. Regularly monitoring the training process and assessing the validation performance helps in identifying potential issues or areas of improvement.
Once the model has been trained and tuned, it can be evaluated on the test dataset to assess its performance on unseen data. This provides a realistic measure of the model’s generalization ability and helps in quantifying its accuracy and reliability.
By following the proper training procedures and monitoring the model’s performance, you can build a well-trained machine learning model that is capable of making accurate predictions and decisions.
Evaluating Model Performance
Evaluating the performance of a machine learning model is a crucial step in the model development process. It allows us to assess how well the model is able to generalize and make accurate predictions on unseen data. In this section of the article, we will explore various techniques for evaluating the performance of a machine learning model.
One common evaluation metric for classification tasks is accuracy, which measures the percentage of correctly classified instances. However, accuracy alone may not be sufficient in scenarios where the classes are imbalanced or when different misclassifications have varying costs. In such cases, metrics like precision, recall, and F1-score can provide a more nuanced assessment of the model’s performance.
In regression tasks, common evaluation metrics include mean squared error (MSE), root mean squared error (RMSE), mean absolute error (MAE), and R-squared. These metrics help quantify the difference between the predicted and actual values, providing insights into the accuracy and precision of the model’s predictions.
Cross-validation is a technique used to evaluate a model’s performance on multiple subsets of the data. It helps assess the model’s stability and generalization ability by training and testing the model on different partitions of the dataset. k-fold cross-validation and stratified k-fold cross-validation are commonly used techniques for this purpose.
Receiver Operating Characteristic (ROC) curves and Area Under the Curve (AUC) are evaluation techniques commonly used in binary classification tasks. The ROC curve plots the true positive rate against the false positive rate at various classification thresholds, and the AUC represents the overall performance of the model in differentiating between the positive and negative instances.
It is important to thoroughly evaluate the performance of the model using multiple evaluation metrics and techniques to gain a comprehensive understanding of its strengths and weaknesses. Additionally, it is recommended to compare the model’s performance against baseline models or previous versions to assess the improvements achieved.
Visualizations can also aid in the evaluation process by providing insights into the model’s predictions and decision boundaries. Visualizing the predicted versus actual values, confusion matrices, and precision-recall curves can help identify patterns, biases, and potential areas for improvement.
Ultimately, the evaluation of model performance is an ongoing process. As new data becomes available or the problem evolves, it is important to re-evaluate and continuously improve the model’s performance.
Identifying and Fixing Errors
Identifying and fixing errors is a critical part of the machine learning development process. As models are trained and deployed, it is common to encounter errors or issues that adversely affect their performance. In this section of the article, we will explore techniques for identifying and fixing errors in machine learning models.
One common type of error is caused by issues in the data. It is important to carefully examine the data for missing values, outliers, or corrupted samples. Missing values can be imputed using appropriate techniques, while outliers can be treated through techniques such as removing them or transforming them to minimize their impact. Cleaning the data and ensuring its quality is crucial for the model’s accuracy and reliability.
Another type of error is overfitting, where the model has memorized the training data instead of learning generalizable patterns. To address this, techniques such as regularization or early stopping can be used to prevent the model from becoming too complex or training for too long. Cross-validation can also help in detecting and mitigating overfitting.
Underfitting is another error that occurs when the model is too simple to capture the complexity of the data. This can be addressed by increasing the model’s complexity, adding more features, or trying different algorithms that are better suited for the problem. Ensuring proper feature engineering and selecting appropriate model architecture can help avoid underfitting.
Identifying errors can also involve analyzing the model’s predictions. By carefully examining the predicted versus actual values, you can observe patterns or discrepancies that may indicate issues with the model. Visualizations, such as scatter plots or residual plots, can provide insights into the model’s performance and error distribution.
Additionally, assessing the performance of the model using evaluation metrics can help pinpoint areas of improvement. If the model’s performance falls below desired thresholds, adjustments can be made to features, hyperparameters, or training strategies. Experimenting with different combinations and iteratively refining the model can lead to improved performance.
In cases where the errors persist despite attempts to fix them, it may be necessary to revisit the problem formulation, reanalyze the data, or consider alternative approaches. Sometimes, errors can stem from inherent limitations in the data or the modeling techniques being used. In such cases, adapting the problem formulation or exploring different algorithms can be beneficial.
Machine learning is an iterative process, and errors are a natural part of the development cycle. By identifing and fixing errors proactively, you can improve the model’s performance and ensure that it meets the desired objectives.
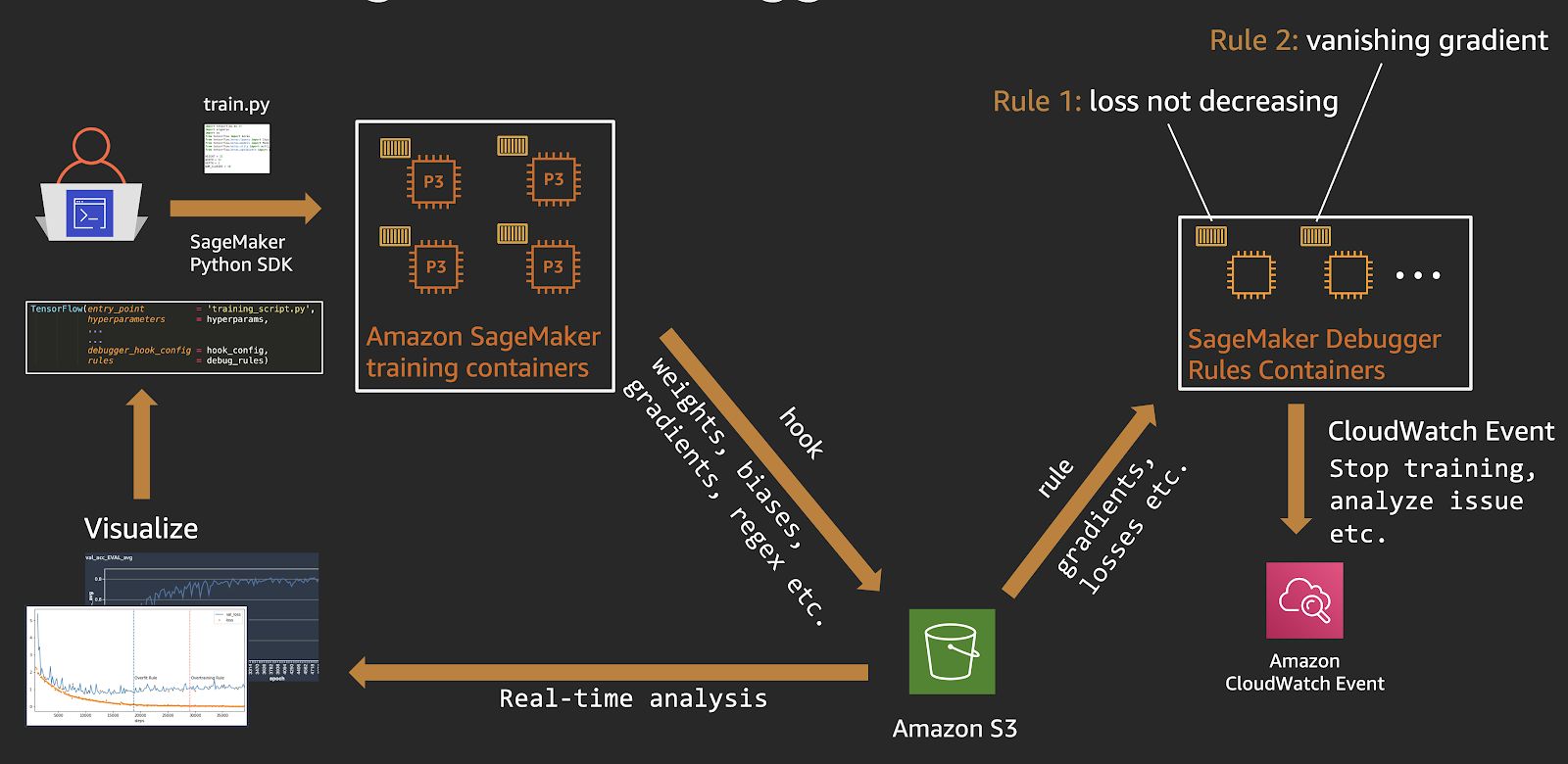
Utilizing Debugging Tools
Debugging tools play a vital role in identifying and resolving issues in machine learning models. These tools provide valuable insights into the inner workings of the model, allowing developers to diagnose and fix errors efficiently. In this section of the article, we will explore the importance of utilizing debugging tools in the machine learning development process.
One commonly used debugging tool is the ability to visualize and interpret the model’s internal representations. Techniques such as activation maps, feature visualization, and saliency maps can help understand which parts of the input data the model is paying attention to and which features are most influential in the decision-making process. These visualizations can reveal potential biases, erroneous patterns, or feature interactions that may be causing errors.
Another helpful debugging tool is the use of learning curves and training statistics. By monitoring training and validation metrics, such as loss and accuracy, over the course of training, developers can identify issues such as overfitting, underfitting, or convergence problems. Learning curves can indicate whether the model is learning and improving with additional data or if it has reached a plateau, assisting in making informed decisions regarding model modifications.
Interpretable machine learning models, such as decision trees or linear regression, provide explicit rules or coefficients that can be examined and analyzed for potential errors. By scrutinizing these models, developers can identify incorrect splitting criteria, irrelevant features, or inconsistency in coefficients, helping to rectify issues and improve performance.
Furthermore, gradient-based debugging tools can aid in identifying and troubleshooting errors. By inspecting and analyzing gradients during training, developers can uncover issues related to vanishing or exploding gradients, improper parameter initialization, or inappropriate learning rates. These insights can guide adjustments to the model’s architecture, optimization strategy, or hyperparameters for better optimization performance.
The use of error analysis and confusion matrices can be insightful for identifying specific types of misclassifications or errors made by the model. By categorizing and analyzing these errors, developers can gain a deeper understanding of the underlying causes and design targeted fixes or improvements. This approach is especially beneficial in situations where misclassifications come with severe consequences, such as medical diagnosis or financial fraud detection.
Lastly, leveraging automated debugging tools and libraries can simplify the debugging process. Tools such as TensorFlow Debugger (tfdbg) or PyTorch’s torch.nn.utils.clip_grad_norm provide built-in functionality to diagnose and resolve issues during model training. These tools can help identify problems like gradient vanishing, NaN (Not-a-Number) values, or improper weight initialization.
By utilizing a combination of these debugging tools and techniques, developers can efficiently identify, diagnose, and fix errors in machine learning models. These tools provide valuable insights, facilitate experimentation, and streamline the debugging process, ultimately leading to more reliable and accurate models.
Analyzing Model Outputs
Analyzing the outputs of a machine learning model is a crucial step in understanding its behavior, performance, and potential issues. By examining the model’s predictions and outputs, developers can gain valuable insights into its strengths, weaknesses, and areas for improvement. In this section of the article, we will explore the importance of analyzing model outputs and techniques for conducting this analysis.
One aspect of analyzing model outputs is examining the distribution of predicted values. By visualizing the predicted values against the actual values, developers can identify patterns, biases, or discrepancies. Histograms, scatter plots, or density plots can provide a visual representation of the relationship between predictions and ground truth, helping identify potential issues such as under- or over-predictions.
Understanding the model’s confidence or uncertainty is another essential aspect of output analysis. Some models provide a measure of confidence in their predictions, such as probabilities or confidence intervals. By examining these measures, developers can identify instances where the model might be uncertain or overly confident. This information can guide further investigations into potential sources of uncertainty and areas of improvement.
Visualizing the model’s decision boundaries can also provide insights into its behavior. Decision boundaries represent the regions in the input space where the model assigns different class labels. By visualizing these boundaries, developers can detect regions of misclassifications or areas where the model might struggle. This information can be used to guide feature engineering or model modifications to improve performance.
Another technique for analyzing model outputs is analyzing the importance or contribution of different features to the predictions. Feature importance analysis can help identify which features are most influential in the model’s decision-making process. Techniques such as permutation importance, feature contribution plots, or partial dependence plots can provide insights into the relationships between input features and predictions.
Exploring misclassified instances or challenging samples is valuable for understanding the limitations of the model. By analyzing instances where the model made incorrect predictions, developers can identify specific patterns or classes that are prone to errors. This analysis can lead to further investigations, data augmentation, or application of specialized techniques to improve the model’s performance on challenging samples.
Interpretability methods, such as feature attribution, can also aid in the analysis of model outputs. These methods help explain how the model arrived at a particular decision by attributing importance to different input features. By understanding the reasoning behind the model’s predictions, developers can identify biases, errors, or potential pitfalls and take appropriate corrective actions.
Lastly, analyzing model outputs can involve comparing the model’s performance across different subgroups or demographic groups. This analysis helps identify potential bias or fairness issues in the model’s predictions. By evaluating the performance metrics across different groups, developers can identify disparities and biases in the model’s decision-making process and work towards building more equitable and unbiased models.
By conducting a thorough analysis of the model’s outputs, developers gain valuable insights into its behavior and performance. This analysis helps in identifying potential issues, areas for improvement, and future research directions, ultimately leading to more reliable, accurate, and robust machine learning models.
Troubleshooting Common Issues
Troubleshooting is an essential part of the machine learning development process. As models are built, trained, and deployed, it is common to encounter various issues that can affect the model’s performance and reliability. In this section of the article, we will explore common issues that arise in machine learning and techniques for troubleshooting them.
Overfitting is a common issue that occurs when a model becomes too complex and performs well on the training data but fails to generalize to new, unseen data. To address overfitting, techniques such as regularization, early stopping, or using more data can be applied. Regularization techniques like L1 and L2 regularization can prevent the model from becoming overly complex, while early stopping can halt the training process when the model starts to overfit.
Underfitting is another issue where the model fails to capture the complexity of the data and has poor performance. This can occur when the model is too simple or lacks the necessary complexity to capture the patterns and relationships in the data. To address underfitting, increasing the model’s complexity, adding more features, or trying different algorithms can be attempted. Feature engineering and selecting appropriate model architectures can also improve the model’s performance.
Imbalanced datasets can pose a challenge in machine learning, as the model can be biased towards the majority class and struggle to accurately predict the minority class. Techniques such as oversampling the minority class, undersampling the majority class, or using algorithms specifically designed for imbalanced data can help address this issue. Another approach is to use evaluation metrics that consider the class imbalance, such as precision, recall, and F1-score.
Data quality issues, such as missing values or outliers, can also impact model performance. Missing values can be addressed through imputation techniques, such as mean imputation, regression imputation, or using advanced imputation models. Outliers can be handled by removing them, transforming them, or using outlier detection algorithms. Careful and thorough data preprocessing can significantly improve the quality of the data and the subsequent performance of the model.
Selection of inappropriate features or inadequate feature engineering can lead to poor model performance. It is important to carefully analyze the relevance and importance of features in relation to the problem at hand. Feature selection techniques, such as backward or forward selection, can be used to identify the most important features. Additionally, domain knowledge and creative feature engineering can greatly enhance the model’s ability to capture the underlying patterns in the data.
Insufficient or inappropriate model evaluation can also lead to issues. It is crucial to evaluate the model using appropriate evaluation metrics, such as accuracy, precision, recall, or F1-score, depending on the problem type. Cross-validation can be employed to assess the model’s performance more reliably. Regularly monitoring the model during training and performing extensive evaluation help in identifying and addressing potential issues in a timely manner.
Finally, computational limitations can impact the model development process, especially with resource-intensive algorithms or large datasets. It may be necessary to optimize the code, leverage parallel computing, or use cloud-based or distributed computing services to address this issue. Partitioning large datasets or reducing the dimensionality of features through techniques like Principal Component Analysis (PCA) can also help mitigate computational challenges.
By understanding and being aware of these common issues in machine learning, developers can effectively troubleshoot and resolve them. Applying appropriate techniques for each issue can significantly improve model performance, reliability, and overall success.
Conclusion
Debugging and troubleshooting are integral parts of the machine learning development process. Building and fine-tuning machine learning models requires careful analysis, iterative testing, and problem-solving. In this article, we have explored various steps and techniques involved in debugging machine learning models.
We began by emphasizing the importance of understanding the problem and gathering high-quality data. The process of choosing the right model based on the problem’s characteristics and available resources was also discussed. We then delved into the crucial steps of training the model, evaluating its performance, and identifying and fixing errors. Utilizing debugging tools, analyzing model outputs, and troubleshooting common issues were examined as essential components of the debugging process.
Throughout this article, it is evident that debugging machine learning models requires a combination of technical skills, domain knowledge, and creativity. It involves thoroughly analyzing data, evaluating model performance, and iteratively refining the model to overcome challenges and improve accuracy.
It is important to remember that debugging is not a linear process—it requires an iterative and adaptable approach. Being open to experimenting with different techniques, exploring new ideas, and continuously monitoring and evaluating the model’s performance are crucial for successful debugging and optimization.
By effectively debugging machine learning models, we can build more reliable, accurate, and robust systems that yield meaningful insights and predictions. Debugging enables us to identify and resolve errors, improve performance, and enhance the overall usability and effectiveness of machine learning applications in various domains.
While mastering the art of debugging can be challenging and requires expertise, with practice and experience, developers can become more efficient at identifying and resolving issues. By incorporating the techniques and principles discussed in this article, developers can enhance their ability to create highly performant and reliable machine learning models.