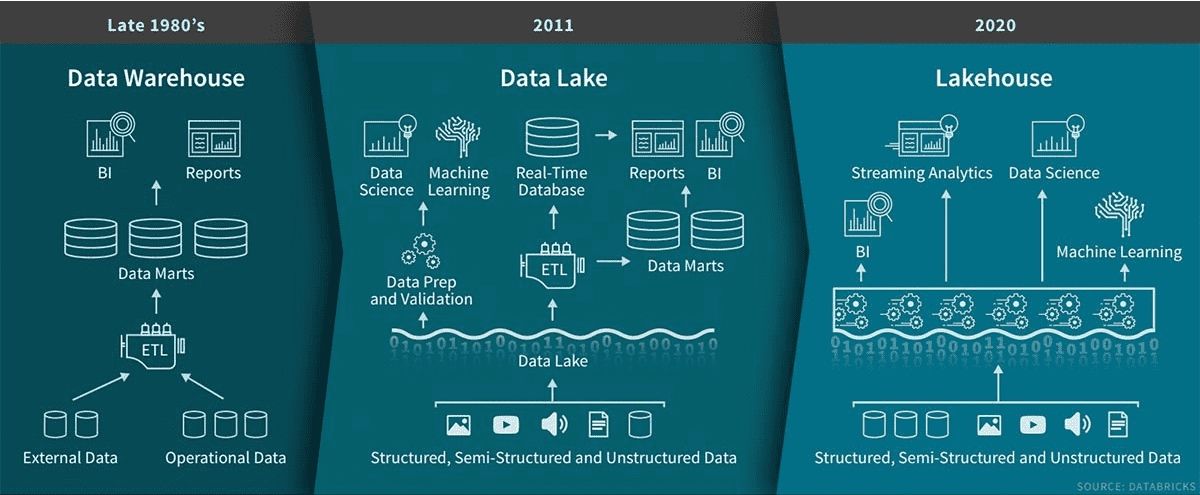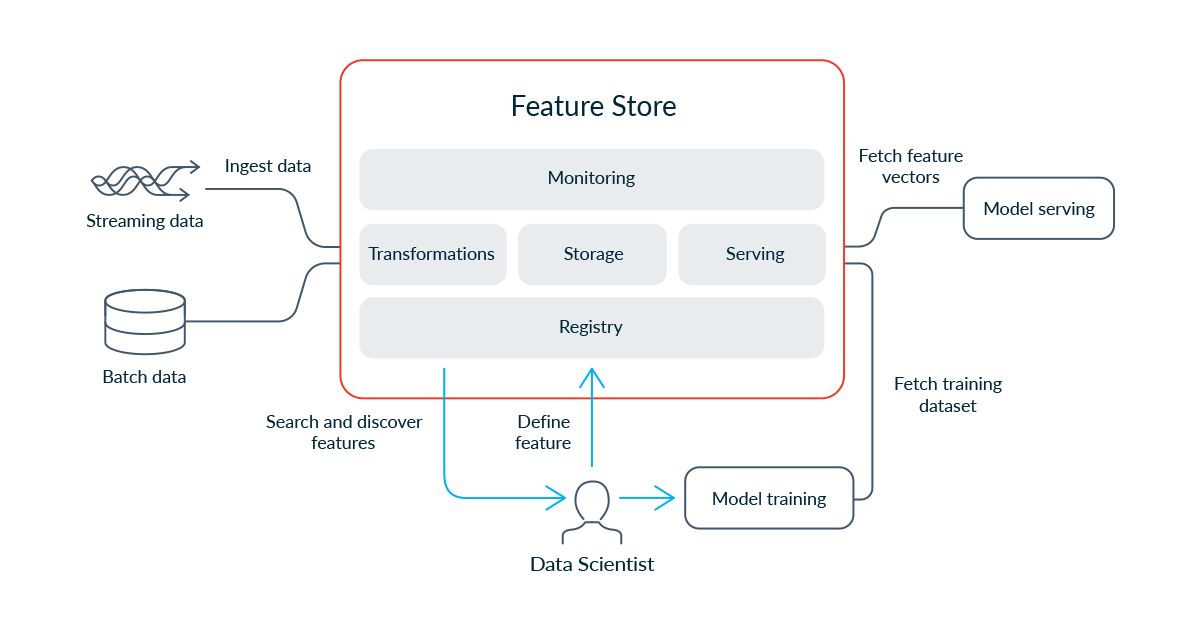
What Is a Feature Store?
A feature store is a centralized repository that stores and manages the features used in machine learning projects. Features refer to the input variables or attributes that are used to train machine learning models and make predictions.
In a machine learning context, features can include a wide range of data points, such as user demographics, transaction history, sensor measurements, or text embeddings. These features can come from various sources, including databases, data lakes, APIs, or external services.
A feature store acts as a reliable and scalable solution to organize, store, and retrieve features for machine learning applications. It offers a unified interface for data scientists and machine learning engineers to access and utilize features efficiently.
The primary purpose of a feature store is to promote consistency and reusability of features across different projects and teams. By providing a centralized location for managing features, it prevents duplication of effort and ensures that features are consistently processed and transformed for model training and inference.
Additionally, a feature store facilitates collaboration among teams working on machine learning projects. It acts as a shared repository where multiple teams can contribute their feature definitions and access the features needed for their specific use cases.
A feature store also plays a crucial role in the feature engineering process. Feature engineering refers to the process of selecting, transforming, and creating new features from the raw data to improve the performance of machine learning models. With a feature store, data scientists can easily iterate and experiment with different feature combinations and transformations.
Furthermore, a feature store enables versioning and lineage tracking of features. This means that data scientists can keep track of the changes made to features over time, understand the lineage of features, and ensure the reproducibility of machine learning experiments.
Overall, a feature store acts as a central hub for managing and delivering features in machine learning projects. It promotes collaboration, consistency, and reusability while streamlining the feature engineering process and ensuring the quality and reliability of features used in machine learning models.
Why Use a Feature Store in Machine Learning?
Using a feature store in machine learning projects offers several benefits and advantages. Here are some key reasons why organizations choose to incorporate a feature store into their machine learning workflows:
1. Centralized and Scalable Storage: A feature store provides a centralized repository to store and manage features from various sources. This eliminates the need for scattered storage solutions and makes it easier to access and retrieve features for machine learning tasks. Additionally, feature stores are designed to handle large volumes of data, ensuring scalability as data volumes grow.
2. Consistency and Reusability: By using a feature store, organizations can maintain consistency in feature definitions and transformations across different projects and teams. This promotes reusability, as data scientists can leverage existing features for new models or experiments, saving time and effort.
3. Efficient Feature Engineering: Feature stores streamline the feature engineering process by providing a unified interface for data scientists to explore, preprocess, and experiment with features. Data scientists can quickly iterate on feature combinations, transformations, and feature engineering pipelines, fostering faster model development.
4. Improved Collaboration: With a feature store, multiple teams can collaborate seamlessly on machine learning projects. They can share feature definitions, access curated features, and avoid duplicating work. This encourages knowledge sharing, accelerates development, and reduces redundancies.
5. Versioning and Lineage Tracking: Feature stores enable versioning, tracking, and auditing of features. Data scientists can easily track changes made to features over time, compare different feature versions, and understand the lineage of features. This promotes reproducibility, traceability, and transparent model development.
6. Better Model Monitoring and Debugging: With a feature store, it becomes easier to monitor and debug models in production. Data scientists can keep track of the features that were used during model training and compare them with the features used during inference. This helps in identifying data inconsistencies and debugging model performance issues.
7. Enhanced Data Governance: Feature stores provide a framework for enforcing data governance policies and compliance requirements. They allow organizations to define access control and data privacy rules, ensuring that only authorized users can access and modify features. This is especially crucial when dealing with sensitive or regulated data.
In summary, incorporating a feature store into machine learning workflows brings efficiency, consistency, and collaboration to the feature engineering process. It empowers data scientists to leverage existing features, accelerate model development, and improve the overall quality and reliability of machine learning models.
Key Features of a Feature Store
A feature store is designed to provide specific functionalities and capabilities that enhance the management and utilization of features in machine learning projects. Here are some key features that are typically found in a feature store:
1. Centralized Storage: A feature store acts as a centralized repository for storing and managing features. It provides a unified location where features from various sources can be stored, organized, and accessed by data scientists and machine learning engineers.
2. Versioning and Lineage Tracking: Feature stores allow for versioning and lineage tracking of features. This means that data scientists can keep track of the changes made to features over time and understand the lineage of features. It enables reproducibility and enhances traceability in machine learning experiments.
3. Metadata Management: A feature store enables the management of metadata associated with features. This includes information such as feature descriptions, data types, transformations applied, and any other relevant contextual information. Metadata management facilitates understanding and documentation of features.
4. Feature Validation and Quality Assurance: Feature stores often include mechanisms for validating and ensuring the quality of features. This can involve checks for missing values, outliers, data distribution, and other data quality aspects. By validating features, it helps maintain the integrity and reliability of the features used in machine learning models.
5. Data Transformation and Feature Engineering: Feature stores may provide tools or functionalities to perform data transformations and feature engineering tasks. This includes operations such as data cleansing, feature scaling, encoding, and creation of new features. These capabilities enhance the feature engineering process and enable data scientists to preprocess features efficiently.
6. Access Control and Security: Security and access control mechanisms are crucial in a feature store. It ensures that only authorized individuals can access and modify features based on defined permissions and roles. This helps protect sensitive data and maintain data governance standards.
7. Scalability and Performance: A feature store should be designed to handle large volumes of data and provide efficient storage and retrieval mechanisms. It should be able to support the scalability requirements of growing machine learning projects and ensure high performance during feature access and retrieval operations.
8. Integration with ML Workflow: Seamless integration with the machine learning workflow is a key feature of a feature store. It should be able to integrate with popular machine learning frameworks, libraries, and tools, making it easy for data scientists to incorporate features into their models and experiments.
In summary, a feature store encompasses features and functionalities that promote effective storage, management, and utilization of features in machine learning projects. It provides versioning, lineage tracking, metadata management, feature validation, data transformations, access control, scalability, and integration capabilities to enhance the feature engineering process and support collaborative machine learning workflows.
Common Features in Feature Stores
Feature stores offer a variety of features and functionalities that enable efficient management and utilization of features in machine learning projects. While specific feature stores may have unique capabilities, there are several common features that are typically found across different feature store implementations. Here are some of the common features:
1. Centralized Storage: A feature store provides a centralized repository to store and organize features from different sources. It ensures easy access and retrieval of features for machine learning tasks.
2. Versioning and Lineage Tracking: Feature stores allow for versioning and lineage tracking of features. This feature helps data scientists keep track of changes made to features over time and understand the lineage of features, ensuring reproducibility and traceability.
3. Metadata Management: Feature stores enable the management of metadata associated with features. This includes information such as feature descriptions, data types, transformations applied, and other relevant contextual information, facilitating understanding and documentation of features.
4. Feature Validation and Quality Assurance: Feature stores often provide mechanisms for validating the quality of features. This can involve checks for missing values, outliers, and data distribution, ensuring consistency and reliability of features used in machine learning models.
5. Data Transformation and Feature Engineering: Feature stores may offer tools or functionalities to perform data transformations and feature engineering tasks. This includes operations such as data cleansing, feature scaling, encoding, and creation of new features, supporting efficient feature engineering processes.
6. Access Control and Security: Security and access control mechanisms are essential in feature stores. They ensure that only authorized individuals can access and modify features, maintaining data privacy and meeting data governance requirements.
7. Scalability and Performance: Feature stores are designed to handle large volumes of data and provide efficient storage and retrieval mechanisms. They ensure scalability and high performance during feature access and retrieval operations.
8. Integration with ML Workflow: Seamless integration with machine learning workflows is a crucial feature of feature stores. They should be able to integrate with popular machine learning frameworks, libraries, and tools, simplifying the process of incorporating features into models and experiments.
9. Collaboration and Teamwork: Feature stores facilitate collaboration among teams working on machine learning projects. They provide a shared repository for sharing and reusing features, avoiding duplication of effort, and promoting knowledge sharing and teamwork.
10. Monitoring and Debugging: Some feature stores offer features for monitoring and debugging machine learning models. This includes tracking the features used during model training and comparing them with the features used during inference, aiding in the identification and resolution of performance issues.
In summary, common features in feature stores include centralized storage, versioning and lineage tracking, metadata management, feature validation, data transformation, access control, scalability, integration with ML workflows, collaboration capabilities, and monitoring and debugging functionalities. These features collectively enhance the management and utilization of features in machine learning projects.
Benefits of Using a Feature Store in Machine Learning
Using a feature store in machine learning projects offers numerous benefits and advantages that improve the efficiency and effectiveness of the overall process. Here are some key benefits of incorporating a feature store into your machine learning workflows:
1. Consistency and Reusability: A feature store provides a centralized repository for storing and managing features, ensuring consistent definitions and transformations across projects and teams. This promotes reusability, as data scientists can leverage existing features for new models or experiments, saving time and effort.
2. Efficient Feature Engineering: Feature stores streamline the feature engineering process by providing a unified interface and tools for data scientists to explore, preprocess, and experiment with features. They enable rapid iteration on feature combinations, transformations, and feature engineering pipelines, accelerating model development.
3. Collaboration and Knowledge Sharing: With a feature store, multiple teams can collaborate seamlessly on machine learning projects. They can share feature definitions, access curated features, and avoid duplicating work. This encourages knowledge sharing, accelerates development, and reduces redundancies.
4. Versioning and Lineage Tracking: Feature stores enable versioning and lineage tracking of features, ensuring reproducibility and traceability. Data scientists can track changes made to features over time, compare different versions, and understand the lineage of features, facilitating transparency and reproducibility in machine learning experiments.
5. Improved Model Monitoring and Debugging: Feature stores make it easier to monitor and debug models in production. Data scientists can keep track of the features used during model training and compare them with the features used during inference. This helps identify data inconsistencies and debug model performance issues.
6. Scalability and Performance: Feature stores are designed to handle large volumes of data and provide efficient storage and retrieval mechanisms. They ensure scalability as data volumes grow and deliver high-performance access to features for machine learning tasks.
7. Enhanced Data Governance: Feature stores provide a framework for enforcing data governance policies and compliance requirements. They enable organizations to define access control and data privacy rules, securing sensitive data and ensuring compliance with relevant regulations.
8. Acceleration of ML Workflows: The use of a feature store accelerates machine learning workflows by reducing the time and effort spent on data preparation and feature management. It allows data scientists to focus more on model development and experimentation, leading to faster time-to-market for machine learning solutions.
In summary, the benefits of using a feature store in machine learning include consistency and reusability of features, efficient feature engineering, collaboration and knowledge sharing, versioning and lineage tracking, improved model monitoring and debugging, scalability and performance, enhanced data governance, and acceleration of machine learning workflows. Incorporating a feature store into your machine learning projects can significantly improve productivity, collaboration, and the overall quality of your machine learning models.
Challenges and Considerations in Implementing a Feature Store
While implementing a feature store in machine learning projects can offer numerous benefits, there are several challenges and considerations that organizations need to be aware of. Here are some key challenges and considerations in implementing a feature store:
1. Data Governance and Privacy: Implementing a feature store requires careful consideration of data governance policies and privacy regulations. Organizations need to ensure that the feature store aligns with their data governance framework and complies with relevant privacy regulations to protect sensitive data and maintain data privacy.
2. Data Quality and Consistency: The quality and consistency of features stored in a feature store are crucial for accurate and reliable machine learning models. Ensuring data quality and consistency is an ongoing challenge and requires regular monitoring, validation, and cleansing of features.
3. Feature Engineering Complexity: Feature engineering involves selecting, transforming, and creating new features from raw data. Implementing a feature store does not eliminate the complexity of feature engineering but provides a platform to streamline and manage the process efficiently. Organizations need to have skilled data scientists who can effectively leverage the feature store and perform advanced feature engineering.
4. Integration with Existing Systems: Integrating a feature store with existing data sources, data pipelines, and machine learning workflows can be a challenge. Organizations need to consider the compatibility and integration capabilities of the feature store with their existing systems to ensure seamless and efficient data flow.
5. Scalability and Performance: As machine learning projects grow in size and complexity, ensuring the scalability and performance of the feature store becomes crucial. Organizations need to consider the ability of the feature store to handle increased data volumes and provide efficient storage and retrieval mechanisms to avoid performance bottlenecks.
6. Change Management and Adoption: Implementing a feature store often requires changes in the organization’s workflows and processes. Ensuring smooth adoption of the feature store across teams and promoting a culture of collaboration and knowledge sharing can be a challenge. Proper change management practices and training programs are essential for successful implementation.
7. Vendor Lock-in: Choosing a feature store vendor or implementation strategy may result in vendor lock-in. Organizations need to carefully evaluate the long-term implications of vendor lock-in and consider the portability and extensibility of the feature store to avoid dependency on a single vendor.
8. Cost Considerations: Implementing and maintaining a feature store incurs costs, including infrastructure, storage, and operational expenses. Organizations need to assess the cost-benefit ratio and consider the value derived from using a feature store compared to the investment required.
In summary, implementing a feature store presents challenges and considerations related to data governance, data quality, feature engineering complexity, integration with existing systems, scalability and performance, change management, vendor lock-in, and cost. Addressing these challenges requires careful planning, skilled resources, and consideration of the organizational needs and strategic goals for using a feature store in machine learning projects.
Examples of Feature Stores in Machine Learning
Several companies and open-source projects have developed feature store solutions that are widely used in machine learning workflows. Here are a few examples of feature stores:
1. Feast: Feast is an open-source feature store that is gaining popularity in the machine learning community. It provides a platform-agnostic solution for storing, managing, and serving features in real-time. Feast supports integration with various data sources, feature engineering tools, and machine learning frameworks, making it a flexible choice for diverse machine learning workflows.
2. Uber Ludwig: Ludwig, developed by Uber, offers a feature store module as part of its machine learning platform. The feature store enables data scientists to share, manage, and reuse features, enhancing collaboration and productivity. Ludwig’s feature store integrates seamlessly with its deep learning framework, simplifying the process of incorporating features into models.
3. Tecton: Tecton is a feature store platform designed to simplify the development and deployment of machine learning features. It provides a scalable and centralized repository for managing features, and it offers tools for feature generation, transformation, and serving. Tecton integrates with popular data storage systems and machine learning frameworks, enabling seamless integration with existing workflows.
4. Google BigQuery ML: BigQuery ML, a part of the Google Cloud Platform, integrates a feature store directly into its machine learning capabilities. It allows users to create and manage feature sets within BigQuery, leveraging its powerful data storage and query capabilities. With BigQuery ML, users can define, reuse, and share features across machine learning models.
5. Hopsworks Feature Store: Hopsworks is an open-source platform for the development and operation of machine learning pipelines. It includes a feature store component that allows data scientists to create, manage, and serve features. Hopsworks Feature Store integrates with popular machine learning frameworks and supports feature versioning and lineage tracking.
6. Amazon SageMaker Feature Store: SageMaker Feature Store is a fully managed feature store service provided by Amazon Web Services. It allows developers to create and manage reusable features, making them available for training and inference in machine learning models. The feature store integrates seamlessly with Amazon SageMaker, simplifying the process of incorporating features into models built on the platform.
These examples demonstrate the variety of feature store solutions available, ranging from open-source offerings to managed services provided by cloud providers. Each of these feature stores is designed to address the challenges of managing and serving features in machine learning projects, providing flexibility, scalability, and integration capabilities to enhance the overall machine learning workflow. Organizations can choose a feature store that best fits their specific needs and integrates smoothly with their existing systems and workflows.
How to Choose the Right Feature Store for Your Machine Learning Projects
Choosing the right feature store for your machine learning projects is a crucial decision that can significantly impact the efficiency and effectiveness of your workflows. Here are some key factors to consider when selecting a feature store:
1. Integration with Existing Systems: Evaluate how well the feature store integrates with your existing data sources, data pipelines, and machine learning frameworks. The feature store should seamlessly fit into your current workflows and tools, ensuring smooth data flow and minimal disruptions.
2. Scalability and Performance: Consider the scalability and performance capabilities of the feature store, especially if you anticipate handling large volumes of data. Ensure that the feature store can handle the scale of your machine learning projects and provide efficient storage and retrieval mechanisms to avoid performance bottlenecks.
3. Data Governance and Security: Ensure that the feature store aligns with your organization’s data governance policies and privacy regulations. Assess the data security and access control mechanisms of the feature store to safeguard sensitive data and comply with relevant regulations.
4. Feature Engineering Capabilities: Evaluate the feature engineering capabilities of the feature store. Look for tools and functionalities that support efficient feature engineering processes, such as data transformation, feature creation, and feature validation. The feature store should empower data scientists to easily preprocess and engineer features for their machine learning models.
5. Ease of Use: Consider the user-friendliness and ease of use of the feature store. It should have a user-friendly interface and provide intuitive workflows for data scientists and machine learning engineers to manage and serve features. An intuitive feature store reduces the learning curve and promotes productivity.
6. Community and Support: Assess the size and activity of the community around the feature store. A strong community indicates active development, regular updates, and good support. A vibrant community can provide valuable resources, documentation, and help troubleshoot any issues that may arise.
7. Cost Considerations: Evaluate the cost implications of the feature store. Consider factors such as licensing fees, infrastructure costs, and ongoing maintenance expenses. Assess the cost-benefit ratio of the feature store and ensure that it aligns with your budget and the value it provides to your machine learning projects.
8. Vendor Lock-in: Consider the potential vendor lock-in when choosing a feature store. Evaluate the portability and extensibility of the feature store in case you need to migrate or integrate with other systems in the future. Avoid vendor lock-in by selecting a feature store that supports open standards and offers flexibility in deployment options.
By carefully evaluating these factors and considering your specific requirements and goals, you can choose a feature store that best fits your machine learning projects. It’s important to select a feature store that not only meets your immediate needs but also aligns with your long-term vision for scalable and efficient machine learning workflows.
Conclusion
A feature store is a valuable tool in machine learning projects, offering a centralized repository for organizing, managing, and serving features. It promotes consistency, reusability, and collaboration among teams, streamlines the feature engineering process, and enhances the overall efficiency of machine learning workflows.
By using a feature store, organizations can ensure the quality and reliability of features by validating them, tracking their lineage, and facilitating versioning. This promotes reproducibility and traceability in machine learning experiments.
Several feature store solutions are available, ranging from open-source options like Feast and Hopsworks to managed services like Amazon SageMaker Feature Store. Each feature store offers a range of functionalities and capabilities, so organizations need to consider factors such as integration with existing systems, scalability, data governance requirements, and ease of use when choosing the right feature store for their projects.
Implementing a feature store does come with challenges, including data governance considerations, ensuring data quality and consistency, managing the complexity of feature engineering, integrating with existing systems, scalability, and change management. It is important to address these challenges by carefully planning, appropriately training resources, and ensuring alignment with organizational goals.
In conclusion, a feature store is a powerful tool that enables efficient management, sharing, and utilization of features in machine learning projects. By selecting the right feature store and implementing it effectively, organizations can enhance their feature engineering workflows, promote collaboration among teams, and ultimately improve the quality and effectiveness of their machine learning models.