Introduction
Machine learning is revolutionizing various industries by enabling computers to learn and make intelligent decisions without being explicitly programmed. One of the critical aspects of machine learning is data collection – the process of gathering and preparing relevant data that will be used to train and improve the machine learning models.
Data collection forms the foundation of any successful machine learning project, as the quality and quantity of the data directly impact the accuracy and performance of the models. By collecting the right data, businesses and researchers can gain valuable insights, make informed decisions, and drive innovation.
In this article, we will explore the importance of data collection in machine learning and provide practical tips for effectively collecting and preparing the data for model training. We will discuss various aspects such as determining the purpose and scope of the data collection, selecting the right data sources, handling missing data, cleaning and preprocessing the data, ensuring data quality and reliability, and much more.
By following the best practices outlined in this article, you can ensure that your machine learning models are built on accurate, representative, and robust data, leading to more reliable predictions and better overall performance.
Now, let’s delve into the details of data collection for machine learning and explore the crucial steps you need to take to set yourself up for success.
Understanding the Importance of Data Collection in Machine Learning
Data collection plays a crucial role in machine learning as it provides the raw material for training and fine-tuning models. The success of any machine learning project depends heavily on the quality and relevance of the collected data. Let’s explore why data collection is so important in the context of machine learning.
1. Training and Improving Models: Machine learning models learn patterns and make predictions based on the examples provided to them during training. The more diverse and representative the training data is, the better the models can generalize and make accurate predictions on new, unseen data. By collecting a wide range of data that covers different scenarios, edge cases, and variations, you can train models to be more robust and reliable.
2. Identifying Relationships and Insights: Data collection allows us to uncover relationships, correlations, and insights that may not be apparent at first. By analyzing a large dataset, we can identify hidden patterns and trends that can lead to valuable insights and help businesses make data-driven decisions. For example, in healthcare, analyzing patient data can reveal patterns that assist in early disease detection and personalized treatments.
3. Improving Decision Making: Collecting and analyzing relevant data enables organizations to make informed decisions. By understanding customer behaviors, preferences, and demographics, businesses can tailor their marketing strategies and product offerings to meet the specific needs of their target audience. This leads to more effective campaigns, increased customer satisfaction, and higher conversion rates.
4. Continuous Learning and Improvement: Data collection is an ongoing process that allows machine learning models to continuously learn and improve. By regularly updating and expanding the dataset, models can adapt to changing patterns and dynamics in the environment they operate in. This ensures that the models remain accurate and relevant over time, maximizing their true potential.
5. Quality Assurance and Risk Mitigation: Data collection helps identify potential risks or anomalies that may impact the performance of machine learning models. By analyzing the collected data, organizations can identify outliers, errors, or biases that might lead to inaccurate predictions or compromised decision-making. This allows for necessary corrective measures to be taken to improve the reliability and fairness of the models.
In summary, data collection is of utmost importance in machine learning. It provides the foundation for training models, gaining insights, making informed decisions, and ensuring continuous improvement. By collecting high-quality and relevant data, organizations can unlock the true potential of their machine learning initiatives and stay ahead in the competitive landscape.
Identifying the Purpose and Scope of Your Data Collection
Before diving into data collection for machine learning, it’s crucial to clearly define the purpose and scope of your data collection efforts. This involves understanding the specific goals you want to achieve and the type of data you need to collect to support those goals. Let’s explore the steps to identify the purpose and scope of your data collection.
1. Define Your Objectives: Start by clearly articulating the objectives of your machine learning project. Are you aiming to develop a predictive model, a recommendation system, or an anomaly detection algorithm? Understanding the desired outcome will help you determine what types of data you need to gather.
2. Identify the Key Variables: Determine the key variables or features that are essential for achieving your objectives. These variables depend on the specific problem you are trying to solve. For example, if you’re developing a model to predict customer churn, you may need variables such as customer demographics, purchase history, and interaction data.
3. Consider Ethical and Legal Considerations: Take into account any ethical or legal considerations when defining the scope of your data collection. Ensure that you collect data in a way that respects privacy regulations and maintain proper data security measures.
4. Evaluate Data Availability: Assess the availability of data sources that align with your objectives and variables of interest. Determine if you have access to internal data, third-party data, public data sets, or if you need to collect the data from scratch. This evaluation will help you plan the collection process effectively.
5. Consider Data Volume and Variability: Determine the expected volume and variability of the data you need to collect. Consider factors such as the required sample size, the frequency of data collection, and any seasonal or temporal variations that may influence the data.
6. Consider Data Diversity: Ensure that you collect a diverse range of data that covers various scenarios, demographics, and contexts relevant to your problem domain. This diversity will help improve the generalizability and performance of your machine learning models.
7. Set Data Collection Metrics: Establish metrics to measure the success of your data collection efforts. This could include measures such as data completeness, accuracy, reliability, and coverage. It’s important to continuously monitor these metrics throughout the data collection process.
By thoroughly identifying the purpose and scope of your data collection, you can ensure that you collect the right data that aligns with your objectives. This clarity will facilitate the subsequent steps of choosing the right data sources, handling missing data, and cleaning and preprocessing the collected data.
Choosing the Right Data Sources
When it comes to data collection for machine learning, choosing the right data sources is crucial for obtaining accurate, relevant, and reliable data. The quality of the data you collect directly impacts the performance and validity of your machine learning models. Here are some key considerations for selecting the right data sources.
1. Internal Data: Start by exploring the data available within your organization. This includes customer records, transactional data, user interactions, logs, and any other relevant data collected through your business operations. Internal data is often rich in quality and provides valuable insights specific to your organization.
2. Publicly Available Data Sets: Utilize publicly available data sets that align with your objectives. Various organizations and institutions provide access to data repositories covering a wide range of domains such as healthcare, finance, climate, social media, and more. These data sets can supplement your own data and enrich the diversity of your machine learning models.
3. Third-Party Data Providers: Consider partnering with third-party data providers who specialize in collecting and curating data. These providers can offer access to data sets that would otherwise be challenging to obtain or require significant resources to collect. Ensure that the data provider complies with privacy regulations and practices reliable data collection methods.
4. Surveys and Questionnaires: If the information you require is not readily available, you can conduct surveys or collect data through questionnaires. This approach allows you to gather specific data directly from your target audience or specific demographics. Ensure you design unbiased and well-structured surveys to obtain reliable insights.
5. Web Scraping: Extract relevant data from websites and online sources using web scraping techniques. This method can be useful for collecting real-time data, industry-specific information, or user-generated content. However, ensure that the web scraping process complies with legal and ethical guidelines and respects the terms of service of the websites being scraped.
6. Sensor Data: In certain domains, such as Internet of Things (IoT) applications, sensor data can provide valuable insights. Utilize sensors and connected devices to collect data on various environmental parameters, physical activities, or health metrics. Ensure that the sensors are calibrated and provide accurate measurements.
7. Partnerships and Collaborations: Consider collaborating with other organizations or research institutions that possess relevant data for your machine learning project. Pooling resources and data from multiple sources can enhance the quality and diversity of the collected data, leading to more robust models.
Remember to evaluate each data source for its relevance, quality, and ethical considerations. Ensure that the data you collect aligns with your objectives, complies with privacy regulations, and maintains the necessary security measures to protect sensitive information. By selecting the right data sources, you lay the foundation for collecting high-quality and reliable data to fuel your machine learning efforts.
Determining the Data Variables and Features
When collecting data for machine learning, it’s important to determine the data variables and features that will be used to train and analyze your models. Variables represent the characteristics or attributes of your data, while features are the specific variables you select to represent your data in the context of your machine learning problem. Here’s how you can determine the data variables and features:
1. Domain Knowledge: Start by gaining a solid understanding of the problem domain and the factors that may influence the outcome you are trying to predict. This will help you identify the relevant variables that are important for your machine learning models.
2. Data Exploration: Analyze and explore your data to identify potential variables and features. Use summary statistics, visualization techniques, and exploratory data analysis to uncover patterns, relationships, and correlations among different variables. This process will help you understand the potential value and relevance of each variable.
3. Feature Selection: Select the most informative and relevant features from your dataset. Consider using techniques such as statistical tests, correlation analysis, or machine learning algorithms like lasso regression or random forests to identify the features that have the most predictive power. By selecting the right features, you can improve the efficiency and performance of your machine learning models.
4. Feature Engineering: Create new features from existing variables if they provide additional insights or increase the predictive power of your models. This can involve performing mathematical transformations, extracting meaningful information from raw data, or deriving new variables based on domain knowledge. Feature engineering can enhance the representation and predictive capabilities of your models.
5. Handling Categorical Data: Determine how to handle categorical variables in your dataset. Categorical variables express qualitative attributes and can be either nominal (unordered) or ordinal (ordered). Decide whether to represent them as numeric values, use one-hot encoding, or apply other encoding techniques based on the nature of the variable and the specific requirements of your machine learning algorithm.
6. Dealing with Missing Data: Assess and address missing data in your dataset. Determine the best strategy to handle missing values, such as imputation methods (mean, median, mode), deletion of missing data, or advanced techniques like multiple imputation. Ensure that the chosen approach does not introduce bias or compromise the integrity of your data.
7. Consider Feature Scaling: Evaluate whether feature scaling is necessary for your selected variables. Feature scaling can bring variables to a similar scale, preventing the dominance of certain variables in distance-based algorithms. Techniques like standardization or normalization can help ensure that all variables contribute equally to the model training process.
By carefully determining the data variables and features, you can effectively represent and leverage the information within your dataset. This step is crucial for building accurate and efficient machine learning models that can make meaningful predictions and generate valuable insights.
Dealing with Missing Data
The presence of missing data is a common challenge when working with real-world datasets for machine learning. Missing data can occur for various reasons, such as data entry errors, sensor malfunction, non-response in surveys, or data corruption. It’s important to effectively handle missing data to ensure the integrity and accuracy of your machine learning models. Here are some strategies for dealing with missing data:
1. Identify Missing Patterns: Start by identifying and understanding the patterns of missing data in your dataset. Determine if the missingness is completely random, missing at random, or missing not at random. Analyzing the missing patterns can help you decide on the most appropriate technique for handling the missing data.
2. Deletion of Missing Data: If the amount of missing data is relatively small and the missingness is random, you can choose to delete the observations with missing values. However, this approach should be used cautiously as it may lead to loss of valuable information and potential bias if the missing data are not missing completely at random.
3. Imputation Techniques: Imputation involves filling in missing values with estimated values. There are several imputation techniques available, including mean imputation, median imputation, mode imputation, and regression imputation. The choice of imputation technique depends on the nature of the data and the underlying assumptions of your machine learning algorithm.
4. Multiple Imputation: Multiple imputation is a more advanced technique which involves creating multiple imputed datasets and performing analysis on each dataset. This technique takes into account the uncertainty associated with imputation and incorporates it into the subsequent analyses. Multiple imputation can produce more accurate and reliable results compared to single imputation techniques.
5. Domain Knowledge: Leverage your domain knowledge to make informed decisions regarding missing data. For example, if certain variables have a high proportion of missing values and are not critical for your analysis, you may choose to exclude them from your modeling process.
6. Model-Based Imputation: Model-based imputation involves using machine learning or statistical models to estimate missing values based on the available data. This approach leverages the relationships between variables and can provide more accurate imputations compared to simple imputation techniques.
7. Establish a Missing Data Indicator: Create a binary variable to indicate whether a certain variable has missing data or not. This allows your machine learning algorithms to treat missingness as a separate category, capturing any potential patterns or associations related to missing data.
Remember to evaluate the impact of your chosen approach on the performance and validity of your machine learning models. It’s important to document and report the methods used for dealing with missing data to ensure transparency and reproducibility of your results.
By employing suitable techniques for handling missing data, you can mitigate the impact of missingness and maintain the accuracy and reliability of your machine learning models.
Cleaning and Preprocessing the Data
Cleaning and preprocessing the data is a critical step in preparing your dataset for machine learning. It involves identifying and resolving issues such as inconsistencies, errors, outliers, and noise to ensure the quality and usability of your data. By performing effective cleaning and preprocessing techniques, you can improve the accuracy and reliability of your machine learning models. Here are some key steps to consider when cleaning and preprocessing your data:
1. Removing Duplicate Data: Check for and remove any duplicate entries in your dataset. Duplicate data can introduce bias and impact the performance of your models, so it’s essential to eliminate these redundancies.
2. Handling Outliers: Identify and handle outliers, which are values that deviate significantly from the rest of your data. Outliers can impact the statistical analysis and modeling process, so you can choose to remove them or apply appropriate techniques such as winsorization or transformation to mitigate their effect.
3. Dealing with Inconsistent Data: Clean up inconsistencies in your data by standardizing formats, resolving discrepancies, and addressing data entry errors. This may involve correcting misspelled words, normalizing data to a consistent unit of measurement, or fixing inconsistent date or time formats.
4. Dealing with Irrelevant Variables: Determine if any variables in your dataset are irrelevant or redundant for your machine learning task. Removing irrelevant variables can improve the efficiency and interpretability of your models.
5. Encoding Categorical Variables: Convert categorical variables into a numerical representation that can be processed by machine learning algorithms. This can be done through techniques such as one-hot encoding, ordinal encoding, or label encoding, depending on the nature of the data and the requirements of your models.
6. Rescaling and Normalizing Data: Rescale numeric variables to a similar scale to prevent certain variables from dominating the analysis. Common techniques for rescaling include standardization (mean centering and scaling to unit variance) and normalization (scaling values between 0 and 1).
7. Handling Missing Values: Apply the appropriate technique for handling missing values as discussed in the previous section. This ensures that missing data does not compromise the accuracy and integrity of your models.
8. Feature Engineering: Engineer new features from existing variables or incorporate domain knowledge to extract meaningful and informative features. Feature engineering can enhance the representation power of your models and improve their performance.
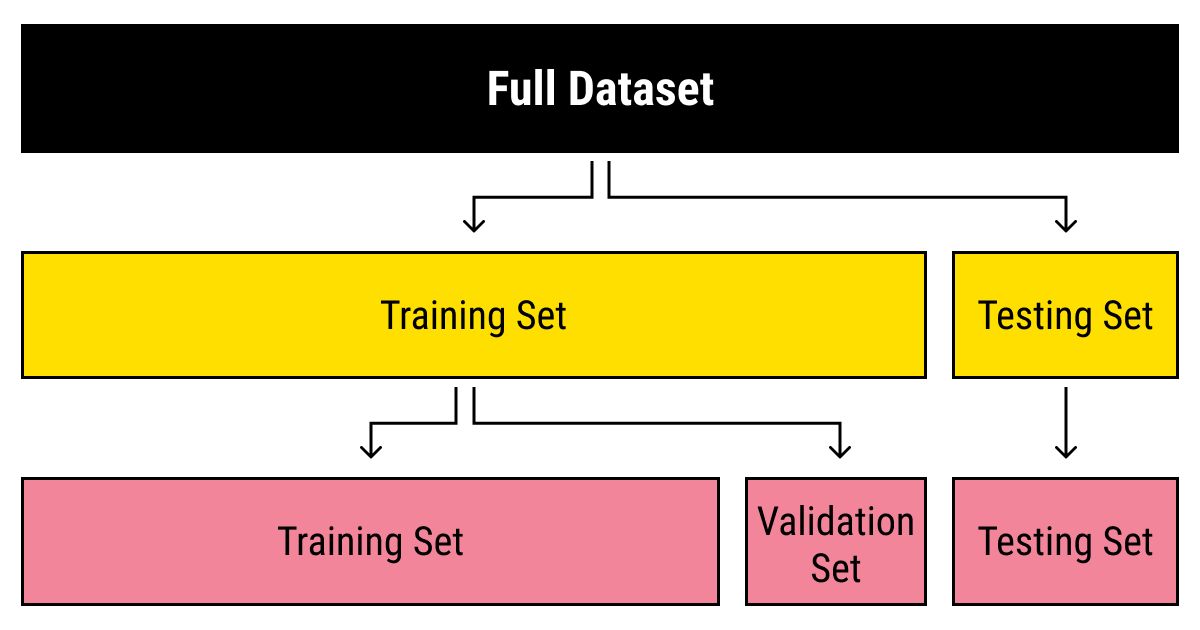
9. Splitting the Dataset: Split your dataset into training, validation, and testing sets to assess model performance and prevent overfitting. The training set is used to train the model, the validation set helps tune hyperparameters, and the testing set evaluates the final model’s performance.
10. Data Normalization: Normalize the features in your dataset to ensure that they have similar scales and ranges. This process can help algorithms to converge faster and make the models less sensitive to different scales of features.
By thoroughly cleaning and preprocessing your data, you can ensure that your machine learning models are built on high-quality, reliable, and meaningful data. This step is essential for maximizing the performance and interpretability of your models and obtaining accurate predictions and valuable insights from your machine learning endeavors.
Ensuring Data Quality and Reliability
Ensuring data quality and reliability is crucial to obtain accurate and trustworthy results from your machine learning models. Poor-quality data can lead to biased or unreliable predictions, hampering the effectiveness of your models. Here are some key considerations to ensure data quality and reliability:
1. Data Validation: Perform data validation checks to identify any inconsistencies or errors. This can involve verifying data formats, ranges, and logical relationships between variables. Ensuring that your data adheres to predefined rules and constraints helps maintain its integrity.
2. Data Sampling: When working with large datasets, consider taking a representative sample of the data for analysis. This helps ensure that the sample accurately reflects the characteristics of the entire dataset while reducing computation time and resource requirements.
3. Data Normalization: Normalize the features in your dataset to ensure that they have similar scales and ranges. This process can help algorithms converge faster and make the models less sensitive to different scales of features, leading to more reliable predictions.
4. Data Cleansing: Cleanse the data by removing duplicate entries, handling missing values, and addressing outliers. Removing inconsistencies and errors enhances the quality and reliability of your dataset, helping to improve the performance of your models.
5. Data Documentation: Document all steps and processes related to data collection, preprocessing, and cleaning. Keep track of any modifications, transformations, or exclusions made to the data to ensure transparency and enable reproducibility of results. Proper documentation also helps in understanding and interpreting the data correctly.
6. Data Quality Metrics: Define and monitor data quality metrics to assess the reliability of your dataset. These metrics could include measures such as accuracy, completeness, consistency, and timeliness. Regularly measuring these metrics helps identify any data quality issues and enables timely corrective actions.
7. Data Backups: Establish regular data backups to prevent data loss or corruption. Implement robust data storage and backup mechanisms to ensure that your data is secure and can be retrieved in case of any unforeseen incidents or technical failures.
8. Data Governance: Implement data governance practices to establish clear roles, responsibilities, and processes for data management. This includes assigning data ownership, ensuring data access controls, and complying with regulatory and privacy requirements.
9. Data Versioning: Maintain a version control system for your dataset to track changes over time. This allows you to easily revert to previous versions and facilitates collaboration among team members working on the same dataset.
10. Data Privacy and Security: Ensure compliance with privacy regulations and adopt robust data security measures to safeguard sensitive information. Implement access controls, encryption, and authentication mechanisms to protect your data from unauthorized access or breaches.
By implementing strategies for data quality and reliability, you can enhance the accuracy, credibility, and usefulness of your machine learning models. High-quality data serves as a solid foundation for making informed decisions, gaining valuable insights, and driving successful outcomes in your machine learning projects.
Selecting an Appropriate Data Collection Method
The data collection method you choose for your machine learning project significantly impacts the quality and relevance of the data you gather. Selecting the right data collection method ensures that you collect data efficiently and effectively. Here are some key considerations to help you select an appropriate data collection method:
1. Research Objective: Understand your research objective and the specific information you need to collect. Determine if you require qualitative or quantitative data, or a combination of both. This will help you decide on the most suitable data collection method.
2. Scope and Scale: Consider the scope and scale of your data collection. Determine if you need to collect data from a small sample or a large population. This will influence the choice of data collection method, whether it’s conducting surveys, interviews, or analyzing existing datasets.
3. Time and Resources: Assess the available time and resources for data collection. Some collection methods, such as web scraping or using existing datasets, may save time and resources compared to methods that involve direct data collection from participants.
4. Data Accessibility: Evaluate the accessibility of the data you require. Determine if the data is readily available from public sources, such as open data repositories, or if you need to collect it directly. Assess the feasibility and practicality of accessing the data you need.
5. Data Quality: Consider the data quality implications of the chosen data collection method. Ensure that the method captures the required level of detail and accuracy to meet your objectives. Assess potential biases or limitations associated with the method and mitigate them where possible.
6. Participant Engagement: Depending on your research objectives, consider the level of participant engagement required. Some methods, such as in-person interviews or focus groups, allow for direct interaction and in-depth exploration of the research topic, while other methods, such as analyzing social media data, provide insights without direct participant engagement.
7. Ethical Considerations: Pay attention to ethical considerations related to data collection, particularly when dealing with sensitive or personal information. Ensure that you comply with privacy regulations, obtain informed consent from participants, and protect the confidentiality and anonymity of the collected data.
8. Iterative Feedback: Determine if your research requires iterative feedback or continuous collection of data over time. In such cases, consider methods that allow for ongoing data collection, such as mobile surveys or data streaming, to capture dynamic changes and trends.
9. Mixed-Methods Approach: Consider using a mixed-methods approach that combines multiple data collection methods. This approach can provide a more comprehensive and nuanced understanding of your research topic by blending quantitative and qualitative data from various sources.
10. Pilot Testing: Before implementing a data collection method on a large scale, pilot test the method to identify potential challenges, refine procedures, and ensure the validity and reliability of the collected data.
By considering these factors, you can select an appropriate data collection method that aligns with your research objectives, resources, and ethical requirements. Choosing the right method sets the stage for successful data collection, resulting in high-quality data for training and improving your machine learning models.
Collecting and Storing the Data
Collecting and storing data properly is essential to ensure the integrity, security, and accessibility of your data for machine learning purposes. A well-executed data collection and storage process facilitates efficient data management and retrieval, enabling you to build accurate and reliable machine learning models. Here are some key considerations for collecting and storing data:
1. Data Collection Tools: Select appropriate tools for your data collection method. This may include survey platforms, data entry systems, web scraping tools, or data logging devices. Choose tools that align with your data collection objectives, taking into account factors such as ease of use, compatibility with your data sources, and data format requirements.
2. Data Collection Procedures: Implement standardized procedures for data collection to ensure consistency and minimize errors. Clearly define the data collection process, specify roles and responsibilities, and provide training to individuals involved in the data collection process. Regularly monitor the data collection process to identify and address any issues that may arise.
3. Data Validation and Quality Assurance: Validate the collected data to ensure its accuracy, completeness, and consistency. Implement validation checks, automated scripts, or manual review processes to identify any data anomalies, outliers, or inconsistencies. This step is crucial for maintaining data quality and reliability in your dataset.
4. Metadata Documentation: Document metadata, which provides information about the structure, meaning, and context of your data. Include details such as variable definitions, data source information, data collection timestamps, and any other relevant information that helps understand and interpret the data accurately.
5. Data Storage Infrastructure: Set up a robust data storage infrastructure that caters to the size and requirements of your dataset. Consider using cloud-based storage solutions or dedicated servers that offer scalability, reliability, and data redundancy. Ensure that the storage infrastructure aligns with privacy and security protocols to protect sensitive information.
6. Data Privacy and Security: Safeguard the privacy and security of your data by implementing access controls, encryption, and user authentication mechanisms. Comply with data protection regulations and institute measures to prevent unauthorized access, loss, or theft of data.
7. Data Backup and Recovery: Establish regular data backup and recovery procedures to protect against data loss or system failures. Automate the backup process and store backups in separate locations to ensure redundancy and quick recovery in case of emergencies.
8. Data Governance: Implement data governance practices to ensure the responsible and compliant management of your data. Define policies, roles, and responsibilities for data management, enforce data quality standards, and establish protocols for data sharing and access.
9. Data Retention: Define the retention period for your data based on legal, regulatory, and operational requirements. Establish procedures for timely data deletion to ensure compliance with applicable data privacy regulations.
10. Data Sharing: If applicable, determine data sharing protocols and obtain necessary permissions or approvals if you plan to share your data with external parties. Ensure that data sharing is done securely and in accordance with any data use agreements or privacy considerations.
By following these best practices for collecting and storing data, you can ensure that your dataset is reliable, secure, and readily usable for machine learning purposes. Effective data management sets the foundation for building robust machine learning models and extracting meaningful insights from your data.
Ensuring Data Privacy and Security
Data privacy and security are paramount when collecting and storing data for machine learning. Protecting sensitive information and maintaining the confidentiality, integrity, and availability of your data is crucial for compliance, ethical considerations, and maintaining the trust of individuals whose data you handle. Here are key aspects to consider when ensuring data privacy and security:
1. Data Minimization: Collect and retain only the data necessary for your machine learning purposes. Minimize the collection of personally identifiable information (PII) and sensitive data to reduce privacy risks and limit the potential impact of a data breach.
2. Data Anonymization: Anonymize or pseudonymize data whenever possible to protect the privacy of individuals. Removing or encrypting personally identifiable information helps prevent individuals from being directly or indirectly identified from the data.
3. Consent and Transparency: Obtain informed consent from individuals whose data you collect, clearly communicating the purpose and use of the data. Provide transparent information about data processing and sharing practices, and give individuals the option to withdraw their consent at any time.
4. Data Encryption: Encrypt data during transmission and at rest to prevent unauthorized access. Utilize secure protocols such as HTTPS or VPNs when transferring data. Encrypt sensitive data stored in databases, cloud storage, or any other data repositories.
5. Access Controls: Implement access controls to restrict data access to authorized individuals only. Use role-based access controls (RBAC) and implement strong user authentication mechanisms such as two-factor authentication (2FA) to ensure that only authorized users can access sensitive data.
6. Data Breach Prevention and Response: Implement measures to prevent data breaches, such as regular security audits, vulnerability assessments, and penetration testing. Prepare a robust incident response plan to mitigate the impact of a potential data breach and ensure timely reporting and communication if a breach occurs.
7. Data Retention and Disposal: Establish data retention policies that align with legal requirements and business needs. Regularly review and dispose of data that is no longer necessary, reducing the risk of unauthorized access or misuse of unnecessary data.
8. Staff Training and Awareness: Provide training and awareness programs to employees regarding data privacy and security best practices. Educate staff on the importance of protecting sensitive data and equip them with the knowledge to identify and mitigate potential risks.
9. Third-Party Risk Management: Evaluate the privacy and security practices of third-party vendors or partners who have access to your data. Ensure that they comply with relevant privacy regulations and have appropriate security measures in place to protect the data they handle.
10. Regular Audits and Compliance: Conduct regular audits to assess your data privacy and security practices. Stay updated with data protection regulations, such as the General Data Protection Regulation (GDPR) or California Consumer Privacy Act (CCPA), and ensure compliance with these regulations to avoid legal and reputational repercussions.
By implementing robust data privacy and security measures, you demonstrate a commitment to protecting individuals’ privacy and safeguarding your data assets. This builds trust with data subjects and stakeholders, ensuring the ethical use of data and the longevity of your machine learning projects.
Data Labeling and Annotation
Data labeling and annotation are crucial steps in preparing data for machine learning. Labeling involves assigning meaningful tags or categories to data, while annotation involves adding additional information or context to the data. This process enables supervised learning, where machine learning algorithms learn from labeled examples to make accurate predictions. Here are some considerations for data labeling and annotation:
1. Define Labeling Guidelines: Establish clear guidelines and criteria for labeling and annotation. Provide instructions to labelers or annotators, specifying the desired tags, formats, or labeling conventions. Clear guidelines ensure consistency and reliability in the labeled data and prevent variations in interpretations.
2. Quality Assurance: Implement quality control measures to ensure accurate and reliable labeling. This can involve double-checking labeled data, conducting inter-rater reliability tests, or performing periodic audits. Consistently monitor the quality of labeled data and provide feedback and support to labelers or annotators.
3. Iterative Refinement: Incorporate an iterative process where feedback from model performance is used to refine and improve the labeling guidelines. This helps address any ambiguities or challenges and ensures alignment between the labeled data and the desired model outcomes.
4. Domain Expertise: Involve domain experts in the labeling process to ensure accurate labeling and annotation. Subject matter experts can provide insights, resolve ambiguities, and help identify relevant features to enhance the quality and relevance of the labeled data.
5. Active Learning: Consider using active learning techniques to optimize the labeling process. Active learning involves selecting and prioritizing the most informative samples for labeling, leveraging techniques such as uncertainty sampling, query-by-committee, or density-based approaches. This ensures efficient utilization of labeling resources.
6. Handling Ambiguity: Address cases where the data is ambiguous or falls into multiple categories. Define guidelines on how to handle ambiguous instances and ensure consistent labeling decisions. Collaboration and discussions among labelers or annotators can help resolve ambiguity and improve the quality of the labeled data.
7. Consensus Building: When multiple labelers or annotators are involved, establish processes to resolve disagreements and achieve consensus on labeling decisions. Techniques like majority voting or conducting annotation meetings can help reconcile differences and ensure consistent labeling outcomes.
8. Data Augmentation: Consider data augmentation techniques to supplement labeled data with additional examples. Data augmentation artificially increases the diversity and size of the labeled dataset by applying transformations such as rotation, scaling, or adding noise. This can help improve model generalization and robustness.
9. Continuous Training: Provide ongoing training and guidance to labelers or annotators to enhance their skills and maintain consistency in labeling practices. Regular communication and feedback loops can help improve the efficiency and effectiveness of the labeling process.
10. Privacy Considerations: Ensure that data labeling and annotation processes comply with privacy regulations and protect sensitive information. Anonymize or pseudonymize data as necessary and implement measures to secure the labeled data from unauthorized access or breaches.
By following effective data labeling and annotation practices, you can create high-quality labeled datasets that serve as a foundation for training accurate machine learning models. Properly labeled and annotated data leads to more reliable predictions and improves the overall performance of your machine learning projects.
Data Augmentation Techniques
Data augmentation is a technique used to artificially increase the size and diversity of a dataset by applying various transformations or modifications to existing data examples. By augmenting the dataset, machine learning models can learn from a broader range of variations and improve their performance. Here are some common data augmentation techniques:
1. Geometric Transformations: Apply geometric transformations to images, such as rotation, scaling, translation, or flipping. These transformations create new variations of the original images and help models learn to be invariant to different orientations or positions.
2. Image Distortion: Distort images by applying deformations, warping, or stretching. This can help models become more robust to image distortions encountered in real-world scenarios or improve their ability to generalize to different image variations.
3. Noise Injection: Add random noise or perturbations to the data examples. This can simulate variations or uncertainties in the real-world data and increase the model’s ability to handle noisy or imperfect inputs.
4. Texture or Pattern Alteration: Modify the texture or patterns in the data, such as changing the color, brightness, contrast, or saturation. This can enhance the model’s ability to recognize objects or features under different lighting conditions or color variations.
5. Data Mixing: Combine multiple data examples to create new data points. For example, in natural language processing, sentences from different documents can be combined to create new training examples. Data mixing encourages models to learn from diverse contexts and improves their ability to handle unseen combinations of features.
6. Subset Extraction: Extract subsets or segments from existing data examples. This can help models focus on specific regions of interest or learn from more fine-grained details within the data.
7. Feature Manipulation: Modify or add features to the data examples. This can involve changing the dimensions, attributes, or representation of the data to increase its diversity and provide more context or discriminative information for the models.
8. Semantic Transformation: Perform semantic transformations that preserve the underlying meaning but introduce variations to the data. This can include paraphrasing, synonym substitution, or paraphrase generation in natural language processing tasks.
9. Temporal Translation: Translate or shift the temporal dimension of time-series data. This can help models learn from different time intervals or shifts and improve their ability to capture temporal relationships.
10. Domain-Specific Techniques: Utilize domain-specific techniques tailored to the characteristics of your data. For example, in audio processing, techniques like pitch shifting, time stretching, or adding background noise can be used to augment speech or sound datasets.
By applying data augmentation techniques, you can generate a larger and more diverse dataset, which offers several benefits. It helps mitigate overfitting by preventing models from memorizing the training data, enhances model generalization to different variations, improves model robustness, and can lead to better performance on unseen or real-world examples.
Validating and Verifying the Data
Validating and verifying the data is a crucial step in the data preparation process for machine learning. It involves ensuring the accuracy, consistency, and reliability of the collected and preprocessed data. Proper validation and verification help identify and address potential issues and enhance the quality and trustworthiness of the dataset. Here are some key considerations for validating and verifying the data:
1. Data Consistency: Ensure that the data is consistent across different sources and variables. Check for any discrepancies or contradictions between data points or entries. Inconsistencies may arise due to data entry errors, data merging processes, or incompatible data formats.
2. Data Completeness: Confirm that the data is complete, with no missing values or important information omitted. Assess missing data patterns and determine if the missingness is random or systematic. Address missing data by applying appropriate imputation techniques or establishing mechanisms to handle missingness during model training and evaluation.
3. Data Accuracy: Evaluate the accuracy of the data by comparing it with known ground truth or expert-verified sources. Identify potential sources of errors or biases in the data collection process and take measures to address or mitigate them. Validate the data against external sources, references, or existing datasets to ensure accuracy.
4. Data Integrity: Verify the integrity of the data by performing data integrity checks. This involves validating data against predefined rules, constraints, or domain-specific validation criteria. Detect and resolve any integrity issues that may compromise the overall quality and reliability of the dataset.
5. Data Drift and Shift: Monitor data for any shifts or drifts over time. Data may change its statistical properties, distribution, or relationship to other variables. Continuously evaluate the validity and relevance of the dataset as new data becomes available to ensure that the model remains up to date and performs optimally.
6. Feature Engineering Validation: Validate the feature engineering process by assessing the effectiveness of generated features. Evaluate the impact of feature engineering on model performance and assess the relevance and information gain of each feature. Continuously refine and improve feature engineering techniques based on validation results.
7. Data Bias and Fairness: Examine the dataset for potential biases and unfairness. Assess whether the data represents a diverse range of demographic, geographic, or sociocultural characteristics. Identify any underrepresented or overrepresented groups and take steps to account for and mitigate biases during model training and decision-making processes.
8. Model Validation: Validate the dataset by evaluating model performance using appropriate validation techniques such as cross-validation, holdout validation, or k-fold validation. Assess the predictive power, generalization capabilities, and robustness of the model using relevant evaluation metrics. Validate the model against an independent test set to ensure its reliability and performance in real-world scenarios.
9. Data Version Control: Implement data version control mechanisms to track changes and updates to the dataset over time. Maintain a record of data modifications, preprocessing steps, and any transformations applied to ensure reproducibility and traceability of the data preparation process.
10. Peer Review and External Validation: Seek external validation or peer review of the dataset and the associated preprocessing steps. Engage domain experts, researchers, or data practitioners who can provide additional insights, feedback, or validation of the data quality and suitability for the intended machine learning task.
By diligently validating and verifying the data, you can identify and rectify any data-related issues early on, ensuring the accuracy, consistency, and reliability of the dataset. This contributes to the robustness and effectiveness of your machine learning models and encourages confidence in the results and subsequent decision-making processes.
Documentation and Version Control of the Data
Documentation and version control are essential components of effective data management in machine learning projects. Proper documentation allows for transparency, reproducibility, and collaboration, while version control enables tracking and management of changes made to the data. Here are key considerations for documenting and implementing version control for your data:
1. Data Description: Document a comprehensive description of the data, including its source, collection methods, and any relevant metadata. This description should capture details about the variables, their definitions, units, and any transformations or preprocessing steps applied.
2. Data Dictionary: Create a data dictionary that provides a comprehensive and standardized explanation of the variables, their meanings, and allowed values. This dictionary serves as a reference for anyone working with the data, ensuring clarity and consistency in the interpretation of the variables.
3. Data Provenance: Document the lineage and provenance of the data, recording the steps taken from data collection to preprocessing. This includes information about data sources, any modifications or filtering, and the rationale behind the decisions made during the data preparation process.
4. Code Documentation: Document any code or scripts used for data preprocessing, transformation, or feature engineering. Include comments that describe the purpose of each code block, the functions used, and any assumptions made during the process.
5. Data Versioning: Implement version control mechanisms to track changes to the data over time. Use a version control system such as Git to manage different versions of the dataset. This allows for easy identification of changes, reverting to previous versions, and collaboration among team members working on the data.
6. Data Auditing: Regularly audit and review the data documentation and version control records to ensure accuracy and completeness. Conduct sanity checks to identify any inconsistencies, missing information, or untracked changes to the data. Make necessary updates or corrections to the documentation and version control system as needed.
7. Data Access Control: Implement access controls to manage data access and prevent unauthorized modification or deletion of the data. Restrict write access to only authorized personnel and maintain a log of data modifications made by each user. This ensures data integrity and accountability.
8. Data Sharing and Collaboration: Utilize the documentation and version control system to facilitate data sharing and collaboration. Provide access to the data documentation and version history to team members or external collaborators, enabling them to understand and reproduce the data preparation process.
9. Reproducibility: Through comprehensive documentation and version control, aim to achieve reproducibility of the data preparation process. With clear documentation and version control records, other researchers or team members can replicate the data preprocessing steps accurately, enabling validation and building upon the work.
10. Data Privacy and Security: Ensure that documentation and version control systems adhere to privacy and security measures. Protect sensitive information and consider anonymization or pseudonymization techniques to maintain confidentiality while documenting and versioning the data.
By documenting the data and implementing version control mechanisms, you establish a reliable and transparent data management process. This enables reproducibility, enhances collaboration, and maintains the integrity and consistency of the data for machine learning projects.
Data Exploration and Visualization
Data exploration and visualization are fundamental steps in understanding the characteristics, patterns, and relationships within your dataset. Exploring and visualizing the data can provide valuable insights, uncover trends, detect outliers, and guide the subsequent steps of data analysis and modeling. Here are key considerations for data exploration and visualization:
1. Summary Statistics: Calculate summary statistics such as mean, median, standard deviation, and quartiles for numerical variables. Explore the distribution, central tendency, and spread of the data to gain a high-level understanding of its characteristics.
2. Data Visualization: Visualize the data using a variety of charts, graphs, and plots. Visual representations help reveal patterns, trends, and correlations that may not be apparent in tabular form. Common visualizations include scatter plots, histograms, bar charts, line charts, heatmaps, and box plots.
3. Feature Relationships: Explore the relationships between variables by creating scatter plots or correlation matrices. Visualize the relationships between pairs of variables to identify correlations, dependencies, or possible interactions. This helps in feature selection, identifying redundant variables, or formulating hypotheses.
4. Data Distribution: Examine the distribution of variables to understand the data’s underlying pattern. Use histograms, kernel density plots, or probability plots to assess whether the data follows a particular distribution (e.g., normal, skewed, or multimodal).
5. Outlier Detection: Identify outliers that deviate significantly from the majority of the data. Box plots or scatter plots can help visualize outliers. Investigate the nature and potential causes of outliers to determine if they should be discarded, treated, or considered as important data points.
6. Data Segmentation: Segment the data by different categories or groups to uncover patterns or differences. Use bar charts, stacked plots, or grouped box plots to compare subgroups and understand variations across different dimensions.
7. Temporal Analysis: Analyze temporal or time-series data to identify trends, seasonality, or event-driven patterns. Use line charts or heatmaps to observe changes in data over time and study patterns at different time intervals.
8. Interactive Visualizations: Utilize interactive visualizations to enable user exploration and manipulation of the data. Interactive tools, such as zooming, filtering, or highlighting, allow for deeper analysis and uncovering more nuanced insights.
9. Dimensionality Reduction: Apply dimensionality reduction techniques to visualize high-dimensional data in lower-dimensional spaces. Methods such as principal component analysis (PCA) or t-distributed stochastic neighbor embedding (t-SNE) can help identify clusters or patterns in complex datasets.
10. Communication and Reporting: Use data visualizations to effectively communicate findings and insights to stakeholders or non-technical audiences. Create clear and visually appealing visualizations that convey important messages and support data-driven decision-making processes.
Data exploration and visualization provide a deeper understanding of the data, enabling better decision-making, identifying areas for improvement, and informing subsequent data analysis and modeling steps. Visual representations facilitate the interpretation and dissemination of findings, enhancing the overall impact of your machine learning projects.
Final Thoughts on Data Collection for Machine Learning
Data collection is a critical component of any successful machine learning project. The quality, relevance, and diversity of the collected data directly influence the accuracy, robustness, and generalization capabilities of machine learning models. As you wrap up your data collection efforts, here are some final thoughts to consider:
1. Domain Expertise: Engage domain experts throughout the data collection process to ensure the data captures the necessary domain-specific knowledge and nuances. Their insights can help identify relevant variables, guide the data collection approach, and enhance the overall quality of the dataset.
2. Iterative Approach: Embrace an iterative approach to data collection. Continuously evaluate the collected data, assess its quality, and incorporate feedback to refine and improve your data collection strategies. Iteration allows for course corrections and enhances the relevance and effectiveness of subsequent machine learning tasks.
3. Data Documentation: Document every step of your data collection process. Maintain comprehensive records of data sources, preprocessing steps, transformations, and any considerations made during the collection process. Well-documented data serves as a valuable asset for future reference, reproducibility, and collaboration.
4. Data Ethics: Prioritize ethical considerations throughout the data collection process. Ensure compliance with privacy regulations, obtain informed consent when necessary, and protect the confidentiality and privacy of individuals whose data you collect. Ethical data practices are crucial for fostering trust and maintaining the integrity of machine learning initiatives.
5. Continued Learning: Stay updated with advancements in data collection techniques, tools, and best practices. Machine learning is a rapidly evolving field, and new methods for data collection may emerge over time. Continually educate yourself and adapt your data collection processes to leverage the latest advancements.
6. Data Sharing and Collaboration: Consider the potential benefits of data sharing and collaboration with other researchers, practitioners, or organizations. Sharing data can foster knowledge exchange, enable benchmarking, and lead to new insights or advancements in the field. However, ensure that data sharing is done in a responsible and secure manner, following applicable legal and privacy regulations.
7. Bias Mitigation: Pay attention to potential biases in the data collection process. Strive for a representative and diverse dataset and be mindful of systematic biases that can perpetuate unfairness or discrimination in machine learning algorithms. Continuously evaluate and address biases to promote fairness and equity in your models and applications.
8. Data Lifecycle Management: Implement robust data lifecycle management practices encompassing data collection, storage, processing, sharing, and disposal. Adhere to data governance principles, establish clear data management protocols, and leverage technologies and methodologies for secure data handling throughout its lifecycle.
As you reflect on your data collection journey, remember that data quality, relevance, and diversity are instrumental in building effective machine learning models. By following best practices, adhering to ethical principles, and maintaining a continuous improvement mindset, you can lay a solid foundation for successful machine learning endeavors.