Introduction
Welcome to the world of machine learning! As technology continues to advance, machine learning has become a powerful tool that is revolutionizing various industries. One of the crucial steps in the machine learning process is model evaluation, where we assess the performance and generalization ability of our models. This evaluation process plays a vital role in determining the effectiveness of a model in solving real-world problems.
One popular technique for model evaluation is cross-validation. Cross-validation is a statistical procedure used to assess how well a machine learning model will generalize to new and unseen data. It is a fundamental tool for estimating the accuracy of a model and selecting the best model architecture or hyperparameters.
In simple terms, cross-validation helps us avoid overfitting, where a model performs exceptionally well on the training data but fails to generalize to new data. In essence, it gives us confidence that our model is not just memorizing the training examples but is actually learning the underlying patterns and relationships in the data.
As an SEO writer, it’s important to understand cross-validation and its significance in machine learning. By delving into cross-validation, we can gain insights into how models are evaluated and make more informed decisions when it comes to selecting the best model for a given problem.
In this article, we will explore cross-validation in detail. We will look at its definition, why it is important, different variations of cross-validation techniques, how it works, and the pros and cons associated with it. Additionally, we will discuss how to choose the right cross-validation technique based on the dataset and model characteristics. To make the concepts more tangible, we will also provide examples of cross-validation implementation in machine learning algorithms.
So, whether you are a beginner venturing into the world of machine learning or an experienced practitioner looking to brush up on your cross-validation knowledge, this article will provide the necessary foundation to grasp the concept and its practical applications.
Definition of Cross-Validation
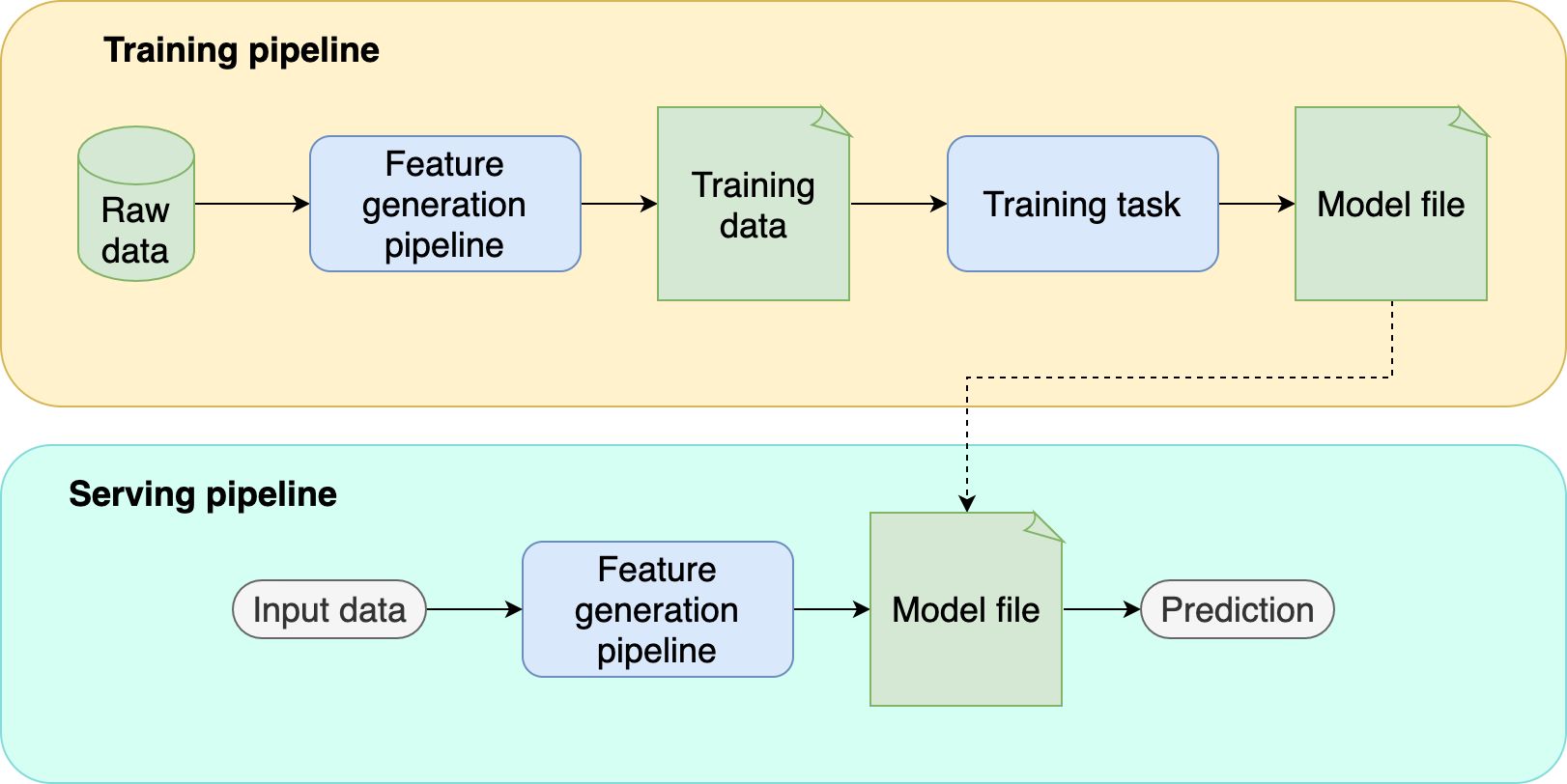
Cross-validation is a statistical technique used in machine learning to evaluate how well a predictive model will perform on unseen data. It involves splitting the available dataset into multiple subsets or folds, training the model on some folds, and then testing its performance on the remaining fold(s). This process is repeated multiple times, with different subsets serving as the test set and training set, allowing for a more comprehensive assessment of the model’s performance.
The main goal of cross-validation is to provide an unbiased estimate of a model’s performance on unseen data. By using different subsets of data for training and testing, we can evaluate how well the model generalizes to new and unseen samples. This helps us assess the model’s ability to accurately predict outcomes in real-world situations.
There are various types of cross-validation techniques, such as k-fold cross-validation, stratified k-fold cross-validation, leave-one-out cross-validation (LOOCV), and hold-out validation. In k-fold cross-validation, the dataset is divided into k equal-sized folds, where k-1 folds are used for training the model, and the remaining fold is used for testing. This process is repeated k times, with each fold serving as the test set. The performance results are then averaged to obtain an overall performance metric.
Stratified k-fold cross-validation is similar to k-fold cross-validation, but it ensures that the proportion of samples from different classes is maintained in each fold. This technique is particularly useful when dealing with imbalanced datasets.
Leave-one-out cross-validation (LOOCV) is a special case of k-fold cross-validation, where k is equal to the total number of instances in the dataset. In each iteration, one instance is held out as the test set, and the remaining instances are used for training the model. This process is repeated for all instances, and the performance results are averaged.
Hold-out validation, also known as simple validation, involves splitting the dataset into a training set and a validation set. The model is trained on the training set and evaluated on the validation set. This technique is commonly used when the dataset is large and time or resource constraints prevent performing k-fold cross-validation.
Overall, cross-validation is a crucial technique in machine learning as it provides an accurate estimate of a model’s performance on unseen data. It helps in selecting the best model and avoiding overfitting, ensuring that our models can generalize well to new scenarios.
Why is Cross-Validation Important?
Cross-validation plays a significant role in machine learning for several reasons. Let’s explore why it is important:
1. Performance Evaluation: Cross-validation provides an unbiased estimate of a model’s performance on unseen data. By using different subsets of the data for training and testing, it enables us to assess how well the model generalizes to new and unseen samples. This helps us understand the model’s capability in making accurate predictions in real-world scenarios.
2. Model Selection: Cross-validation allows us to compare the performance of different models or different variations of the same model. By evaluating multiple models using the same cross-validation procedure, we can select the best-performing model that is likely to generalize well to unseen data. This aids in choosing the most suitable algorithm, model architecture, or hyperparameters for our specific problem.
3. Preventing Overfitting: Overfitting occurs when a model performs exceptionally well on the training data but fails to generalize to new data. Cross-validation helps us identify overfitting by evaluating the model’s performance on unseen data. If a model consistently performs well on the training data but poorly on the validation data, it indicates overfitting. Cross-validation aids in selecting models that are less prone to overfitting, leading to better generalization.
4. Understanding Data Variability: By repeating the cross-validation process multiple times, we obtain performance measures from different subsets of the data. This provides insights into the variability of the model’s performance. It helps us understand the stability and robustness of the model and assess how the model’s performance may vary when exposed to different sample distributions or random variations in the data.
5. Assessing Model Stability: Cross-validation provides a way to evaluate the stability of the model’s performance by analyzing the variation in the performance metrics across different folds. If the model consistently performs well across all folds, it indicates that the model is stable and less sensitive to the specific arrangement of the training and test data. On the other hand, if the performance varies significantly, it indicates that the model’s performance might be highly dependent on the particular data split.
In summary, cross-validation serves as a critical technique for evaluating the performance, selecting the best model, preventing overfitting, understanding data variability, and assessing model stability. By using cross-validation, we can make more informed decisions in building and selecting models that are more likely to generalize well to new and unseen data.
Variations of Cross-Validation
When it comes to cross-validation, there are various techniques that can be employed depending on the characteristics of the dataset and the specific requirements of the machine learning problem. Let’s explore some of the common variations of cross-validation:
1. K-Fold Cross-Validation: K-fold cross-validation is one of the most widely used variations. It involves dividing the dataset into k equal-sized folds. The model is trained on k-1 folds and evaluated on the remaining fold. This process is repeated k times, with each fold serving as the test set. The performance results are then averaged to obtain an overall performance metric. K-fold cross-validation provides a good balance between computation time and reliability in estimating the model’s performance.
2. Stratified K-Fold Cross-Validation: Stratified k-fold cross-validation is particularly useful when dealing with imbalanced datasets, where the distribution of classes is uneven. It ensures that each fold’s proportion of samples from different classes remains the same as the original dataset. This helps prevent bias towards the majority class and provides a more representative evaluation of the model’s performance across different classes.
3. Leave-One-Out Cross-Validation (LOOCV): LOOCV is a special case of k-fold cross-validation where k is equal to the total number of instances in the dataset. In each iteration, one instance is held out as the test set, and the remaining instances are used for training the model. This process is repeated for all instances, resulting in n separate model evaluations, where n is the number of instances in the dataset. LOOCV provides an unbiased estimate of the model’s performance but can be computationally expensive for large datasets.
4. Hold-Out Validation: Hold-out validation, also known as simple validation, is a straightforward approach where the dataset is divided into a training set and a validation set. The model is trained on the training set and evaluated on the validation set. Hold-out validation is commonly used when the dataset is large and time or resource constraints prevent performing k-fold cross-validation. However, it may not provide as reliable estimates as k-fold cross-validation, especially with limited data.
5. Repeated Cross-Validation: Repeated cross-validation involves repeating the cross-validation process multiple times with different random splits of the data. This helps to further reduce the impact of data variability and provides more robust performance estimates. Repeated cross-validation is useful when dealing with small datasets or when additional reassurance is needed regarding the stability of the model’s performance.
It is essential to choose the appropriate cross-validation technique based on the specific characteristics of the dataset and the machine learning problem at hand. Each variation has its advantages and considerations, and the choice should be made carefully to ensure reliable performance evaluation and model selection.
How does Cross-Validation Work?
Cross-validation is a systematic process that involves splitting the dataset into subsets, training a model on some subsets, and evaluating its performance on the remaining subset(s). This allows us to estimate a model’s performance on unseen data. Let’s explore the step-by-step process of how cross-validation works:
1. Data Preparation: Initially, the available dataset is prepared for cross-validation. This involves cleaning the data, handling missing values, encoding categorical variables, and performing any necessary preprocessing steps to ensure the data is in a suitable format for modeling.
2. Subset Creation: The dataset is divided into multiple subsets or folds. The most common approach is k-fold cross-validation, where the dataset is divided into k equal-sized folds. Alternatively, other cross-validation techniques, such as stratified k-fold or leave-one-out cross-validation, may be used depending on the specific requirements of the problem.
3. Model Training and Evaluation: The model training and evaluation process is performed iteratively. In each iteration, one fold serves as the test set, while the remaining folds are used for training the model. The model is trained on the training data and then evaluated on the test fold. The performance metrics, such as accuracy, precision, recall, or F1 score, are recorded for each iteration.
4. Averaging Performance Metrics: After all iterations are completed, the performance metrics obtained from each fold are averaged to obtain an overall performance estimate. This average helps provide a more reliable measure of the model’s performance compared to using a single performance value from a single train-test split.
5. Model Selection and Fine-tuning: The performance estimates obtained from cross-validation can be used for model selection. Different models or variations of the same model can be evaluated using the same cross-validation procedure. This helps in comparing their performance and selecting the model that performs best on unseen data. Additionally, cross-validation can be utilized to fine-tune model hyperparameters by evaluating different parameter combinations and selecting the ones that yield the best performance.
The number of iterations and the choice of cross-validation technique depend on factors like the dataset size, computational resources available, and the desired level of model evaluation. The performance estimates obtained from cross-validation provide insights into the model’s ability to generalize to new data and aid in making informed decisions during model selection and fine-tuning.
Overall, cross-validation works by repeatedly training and evaluating the model on different subsets of the data, allowing for a comprehensive assessment of the model’s performance on unseen data.
Pros and Cons of Cross-Validation
Cross-validation is a widely used technique in machine learning for model evaluation and selection. Like any approach, it has its advantages and disadvantages. Let’s explore the pros and cons of using cross-validation:
Pros:
- Unbiased Performance Estimation: Cross-validation provides an unbiased estimate of a model’s performance on unseen data. It ensures that the model’s performance is evaluated on multiple subsets of the data, which helps in obtaining a more reliable measure of its generalization ability.
- Efficient Use of Data: Cross-validation allows us to utilize the entire dataset effectively. By using different subsets for training and testing, we can make the most of the available data and reduce the risk of overfitting.
- Model Selection: Cross-validation enables us to compare the performance of different models or variations of the same model using the same evaluation procedure. This helps in selecting the best-performing model or determining the optimal hyperparameters for a given problem.
- Understanding Data Variability: Through cross-validation, we can gain insights into the variability of the model’s performance across different subsets of the data. This helps us understand the stability and robustness of the model and assess its performance in various scenarios.
Cons:
- Computational Cost: Cross-validation can be computationally expensive, especially when dealing with large datasets or complex models. Running multiple iterations of training and evaluation can increase the overall computational time, requiring more resources.
- Data Dependency: The performance estimates obtained from cross-validation can be influenced by the specific arrangement of the data splits. The choice of random seed or the order of data instances can impact the results, potentially leading to slightly different performance metrics.
- Limited Data for Training: In k-fold cross-validation, the model is trained on k-1 folds, leaving a limited amount of data for training. This might be a concern when the dataset is small, and every instance of data is crucial for model training.
- Unrealistic Assumption: Cross-validation assumes that the data samples are independently and identically distributed (i.i.d). However, in some real-world scenarios, this assumption may not hold, leading to biased performance estimates.
Despite the drawbacks, cross-validation remains a valuable technique for evaluating models and making informed decisions in machine learning. By weighing the pros and cons, developers and researchers can determine whether cross-validation is suitable for their specific tasks and adjust their analytical strategies accordingly.
Choosing the Right Cross-Validation Technique
Choosing the appropriate cross-validation technique is crucial for obtaining reliable performance estimates and making informed decisions in machine learning. The choice depends on various factors, including the dataset size, computational resources available, and the specific requirements of the problem. Let’s explore some considerations when selecting the right cross-validation technique:
1. Data Size: For large datasets, k-fold cross-validation is often suitable. It strikes a balance between reliable performance estimation and computational efficiency. On the other hand, if the dataset is small, leave-one-out cross-validation or hold-out validation can be used to maximize the use of available data.
2. Imbalanced Data: When dealing with imbalanced datasets, where the classes are not equally represented, stratified k-fold cross-validation is recommended. It ensures that each fold maintains the same class distribution as the original dataset. This helps in obtaining more representative performance estimates across different classes.
3. Computational Resources: If computational resources are limited, hold-out validation or a single fold of k-fold cross-validation can be used. Although this may provide a less reliable estimation compared to multiple folds, it offers a time-efficient alternative when running extensive cross-validation is not feasible.
4. Model Stability Assessment: When assessing the stability of the model’s performance, repeated cross-validation is a suitable option. By repeating the cross-validation process with different random splits, it provides insights into the consistency of the model’s performance across different subsets of the data.
5. High Variance or Limited Data: In situations where the dataset is limited or the model has high variance, leave-one-out cross-validation can be effective. It uses all but one instance for training, maximizing the use of available data and providing a reliable estimate of the model’s generalization ability.
6. Specific Requirements: Some machine learning problems may have specific requirements that necessitate the use of a particular cross-validation technique. It is essential to consider any specific constraints or guidelines in the problem domain when selecting the appropriate technique.
It’s important to note that there is no one-size-fits-all approach to cross-validation. The choice of technique depends on the specific characteristics of the dataset and the goals of the machine learning project. Careful consideration of these factors helps ensure accurate performance estimation and reliable model selection.
Examples of Cross-Validation in Machine Learning
Cross-validation is widely used in various machine learning algorithms and tasks. Let’s explore a few examples of how cross-validation is implemented in different scenarios:
1. Regression: In regression tasks, where the goal is to predict a continuous value, cross-validation is commonly employed to assess the model’s performance. The dataset is divided into k folds, and the model is trained on k-1 folds and evaluated on the remaining fold. The process is repeated for all folds, and the performance metrics, such as mean squared error or mean absolute error, are averaged to obtain the overall performance estimate.
2. Classification: Cross-validation is extensively used in classification tasks. For example, in binary classification, where the goal is to classify instances into two classes, stratified k-fold cross-validation is commonly used. It ensures that each fold maintains the same class distribution as the original dataset. The model is trained on k-1 folds and evaluated on the remaining fold, with performance measures such as accuracy, precision, recall, or F1 score computed for each fold.
3. Hyperparameter Tuning: Cross-validation is essential in hyperparameter tuning, where different combinations of hyperparameters are explored. A grid or random search approach is typically used in combination with cross-validation. Each hyperparameter combination is evaluated using cross-validation, and the combination that yields the best performance across the folds is selected as the optimal set of hyperparameters.
4. Feature Selection: Cross-validation can aid in feature selection by ranking the importance of different features. Features are iteratively excluded or included, and cross-validation is used to assess the model’s performance. This helps identify the subset of features that contribute the most to the model’s predictive capability.
5. Model Comparison: Cross-validation is useful for comparing different models or variations of the same model. By evaluating multiple models or model architectures using the same cross-validation procedure, we can determine the best-performing model that generalizes well to new and unseen data.
6. Ensemble Methods: Cross-validation is utilized in ensemble methods such as bagging and boosting. In bagging, multiple models are trained on different subsets of the data obtained through sampling with replacement. Cross-validation is used to estimate the ensemble model’s performance on unseen data. In boosting, where models are sequentially trained on different weighted samples of the data, cross-validation guides the selection of the optimal number of iterations or learning rate.
These are just a few examples of how cross-validation is commonly applied in machine learning. It showcases the versatility and significance of cross-validation in various aspects of model evaluation, selection, and tuning.
Conclusion
Cross-validation is a fundamental technique in machine learning that enables accurate model evaluation and selection. By dividing the dataset into subsets, training models on some subsets, and evaluating their performance on the remaining subsets, cross-validation provides insights into a model’s ability to generalize to unseen data. It helps in preventing overfitting, understanding data variability, and selecting the best-performing model or hyperparameters.
Throughout this article, we have explored the definition of cross-validation and its importance in the machine learning process. We have discussed various variations of cross-validation, including k-fold cross-validation, stratified k-fold, leave-one-out cross-validation, and hold-out validation. Each technique has its strengths and considerations, allowing flexibility in choosing the most appropriate approach for a given scenario.
We have also discussed the pros and cons of cross-validation, highlighting the benefits of unbiased performance estimation, efficient use of data, model selection, understanding data variability, as well as potential challenges related to computational cost and data dependency.
Furthermore, understanding the process of cross-validation has been emphasized. By following a step-by-step methodology of data preparation, subset creation, model training, evaluation, and averaging of performance metrics, practitioners can effectively leverage cross-validation to assess model performance and make informed decisions in their machine learning projects.
Lastly, we have examined examples of cross-validation in different machine learning tasks, including regression, classification, hyperparameter tuning, feature selection, model comparison, and ensemble methods. These examples demonstrate the versatility and applicability of cross-validation across a wide range of scenarios.
In conclusion, cross-validation serves as an indispensable tool for evaluating and selecting machine learning models. It offers a robust framework for estimating model performance, avoiding overfitting, and guiding decision-making processes. By leveraging cross-validation, practitioners can build more reliable and effective machine learning models that are capable of accurate predictions on unseen data.