What is Machine Learning?
Machine Learning is a subfield of artificial intelligence that focuses on the development of algorithms and models that enable computers to learn and make predictions or decisions without being explicitly programmed. It is based on the idea that machines can analyze and interpret data, identify patterns, and automatically learn from them.
Traditionally, computers were programmed to perform specific tasks based on a defined set of rules. However, this approach limits their ability to handle complex and evolving scenarios. Machine Learning, on the other hand, empowers computers to learn and adapt by using algorithms that automatically improve their performance over time.
Machine Learning algorithms can be categorized into three broad types: supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the algorithm is trained on labeled data, meaning it is provided with input data along with the correct output. The model then learns to make predictions or classify new, unseen data based on the patterns it observes in the labeled examples.
In unsupervised learning, the algorithm processes unlabeled data and finds patterns or structures within it. This type of learning is often used for tasks like clustering, where the goal is to group similar data points together based on their properties or characteristics.
Reinforcement learning involves training an agent to make decisions and take actions in an environment to maximize a cumulative reward. The algorithm learns through trial and error, receiving feedback in the form of rewards or penalties based on its actions and adjusting its behavior to achieve better outcomes.
By leveraging the power of Machine Learning, organizations and individuals can automate tasks, gain insights from vast amounts of data, and make informed decisions. Machine Learning is used in various fields, including finance, healthcare, robotics, marketing, and more. It enables applications like fraud detection, recommendation systems, natural language processing, image recognition, and autonomous vehicles.
As Machine Learning continues to advance, the possibilities for its application expand. Researchers and practitioners are constantly developing new algorithms, techniques, and frameworks to improve the accuracy, efficiency, and scalability of Machine Learning models.
In the next sections, we will explore the fundamentals of Machine Learning, the steps involved in building and deploying a Machine Learning model, common challenges, and best practices for successful Machine Learning projects.
Understanding the Basics of Machine Learning
Before delving into the intricacies of machine learning algorithms and models, it is essential to grasp the foundational concepts and terminology that underpin this field.
At its core, machine learning is centered around the concept of using data to make predictions or decisions. The first step in this process is to identify the problem or task at hand. This could range from predicting sales figures to recognizing handwriting or classifying emails as spam or not. Defining a clear objective is crucial in order to select the appropriate machine learning technique.
Data plays a central role in machine learning. It serves as the raw material from which models are built and trained. Typically, datasets are divided into two subsets: the training set and the test set. The training set is used to teach the model, while the test set is used to evaluate its performance. The idea is to provide the model with enough diverse examples to learn patterns and generalize its understanding to unseen data.
Features or attributes are the characteristics of the data that the model uses to make predictions. For example, in a spam detection problem, features could include the length of the email, the presence of certain words or phrases, and the sender’s address. Feature engineering is the process of selecting and transforming the relevant features from the data to provide the model with meaningful information.
The model itself is the algorithm or mathematical function that takes in input data and produces an output or prediction. There are various types of machine learning algorithms, each with its own strengths and limitations. Some commonly used algorithms include linear regression, decision trees, support vector machines, and neural networks.
When training a machine learning model, the objective is to find the best parameters or coefficients that minimize the error between the predicted output and the actual output. This is done through an optimization process called learning. The model learns from the data by adjusting its internal parameters, based on a specified objective function and a chosen optimization algorithm.
Once the training is complete, it is crucial to evaluate the performance of the model on the test set. This provides an indication of how well the model can generalize to unseen data. Common evaluation metrics include accuracy, precision, recall, and F1-score, depending on the nature of the problem being solved.
Understanding the basics of machine learning sets the foundation for diving deeper into the technical aspects of algorithms, data preparation, model building, and evaluation. In the next sections, we will explore these topics in detail and provide practical insights for successfully applying machine learning techniques.
Choosing the Right Machine Learning Algorithm
One of the critical decisions in machine learning is selecting the most appropriate algorithm for a given task. There is a wide array of machine learning algorithms available, each designed to tackle different types of problems and data characteristics.
The first step in choosing the right algorithm is to understand the nature of the problem you are trying to solve. Is it a classification problem where you want to predict which category or class a sample belongs to? Or is it a regression problem where you aim to predict a continuous value? Alternatively, it could be an unsupervised learning problem where you want to discover patterns or clusters within the data.
For classification tasks, popular algorithms include logistic regression, support vector machines, decision trees, and random forests. These algorithms work well when the data is labeled and there is a clear distinction between different classes.
When dealing with regression problems, algorithms such as linear regression, polynomial regression, and support vector regression are commonly used. These algorithms aim to predict a continuous value based on input features.
For unsupervised learning tasks, algorithms like k-means clustering, hierarchical clustering, and principal component analysis (PCA) are employed. These algorithms help identify patterns within unlabeled data and group similar instances together.
In addition to the problem type, it is crucial to consider the size of the dataset and its characteristics. Some algorithms are better suited for small datasets, while others excel with large datasets. For example, support vector machines and random forests can handle large volumes of data efficiently, while other algorithms may struggle with scalability.
The complexity of the problem and the interpretability of the model are also factors to consider. For simpler problems, linear regression or logistic regression may be sufficient, as they provide a straightforward interpretation of the relationship between features and the target variable. On the other hand, for more complex problems, neural networks or deep learning algorithms may offer better performance but may come at the cost of interpretability.
Additionally, it is important to evaluate the performance and limitations of different algorithms. This can be done through empirical testing, benchmarking, or studying research papers and community feedback. Understanding the strengths and weaknesses of various algorithms will help guide your decision-making process.
Lastly, remember that there are no one-size-fits-all solutions in machine learning. It often requires experimentation and iteration to find the best algorithm for your specific task. It is recommended to try multiple algorithms and compare their performance before settling on one.
Choosing the right machine learning algorithm is a crucial step in building a successful model. In the next sections, we will explore the process of gathering and preparing data for machine learning, followed by the steps involved in building, evaluating, and deploying a machine learning model.
Gathering and Preparing Data for Machine Learning
Data is the foundation of any machine learning project and plays a vital role in the success of the model. Gathering and preparing the right data is crucial to ensure accurate predictions and reliable insights.
The first step in data gathering is to clearly define the problem you are trying to solve and identify the type of data needed. Depending on the problem, you may require structured data, such as tabular data in a database, or unstructured data, such as text, images, or audio. It is essential to have a clear understanding of the data requirements and ensure that you have access to the relevant data sources.
Once you have identified the data sources, the next step is to collect the data. This can involve extracting data from databases, scraping websites, accessing APIs, or even conducting surveys or experiments to generate the required data. It is important to ensure the data collection process is reliable, accurate, and representative of the problem you are trying to solve.
After gathering the data, it is crucial to clean and preprocess it. Data cleaning involves dealing with missing values, outliers, duplicates, and other inconsistencies that may exist in the dataset. This process ensures the data is of high quality and suitable for analysis.
Data preprocessing includes transforming the data into a format that can be processed by machine learning algorithms. This involves tasks such as normalization, feature scaling, feature extraction, and encoding categorical variables. By preprocessing the data, you enable the machine learning algorithm to effectively learn patterns and make accurate predictions.
Feature engineering is another important step in preparing the data. This involves selecting the relevant features or attributes that will be used as input for the model. It may also involve creating new features by combining or transforming existing ones. Feature engineering is a crucial step as it determines the information available to the model and can significantly impact its performance.
It is important to also consider the size of the dataset. In some cases, the dataset may be small, requiring techniques such as data augmentation to artificially increase the number of samples. In other cases, the dataset may be large and require techniques like sampling or mini-batch processing to handle it efficiently.
Furthermore, data should be split into training and testing sets. The training set is used to teach the model, while the testing set is used to evaluate its performance on unseen data. This helps estimate how well the model will generalize to new, real-world scenarios.
As part of data preparation, it is essential to address any potential biases or ethical considerations that may arise from the data. Care should be taken to ensure the data used for training the model is representative and unbiased, avoiding any potential discrimination or unfairness.
Gathering and preparing data for machine learning is a critical step that requires careful consideration and attention to detail. In the next sections, we will delve into the process of building and training a machine learning model, followed by evaluating and testing its performance.
Building and Training a Machine Learning Model
Once the data has been gathered and prepared, the next step in the machine learning workflow is building and training a model. This step involves selecting an appropriate algorithm and leveraging the prepared data to teach the model to make predictions or decisions accurately.
The first consideration in model building is choosing the most suitable algorithm for your problem and data. This decision depends on the problem type (classification, regression, or clustering), the nature of the data, the size of the dataset, and the desired performance metrics. Popular algorithms include linear regression, decision trees, support vector machines, and neural networks, among others.
After selecting the algorithm, the next step is feeding the prepared data to the model. This involves assigning the input features to the appropriate model variables. The algorithm learns the relationships between the input variables and the target variable through an optimization process that adjusts the internal parameters.
The model training process involves providing the algorithm with the labeled training data and having it iteratively refine its internal parameters to minimize the difference between predicted and actual outputs. This optimization step is typically done using an algorithm-specific technique such as gradient descent or stochastic gradient descent, which adjusts the model’s parameters in the direction that reduces the training error.
During training, it is essential to monitor the model’s performance and adjust the hyperparameters to optimize its accuracy. Hyperparameters are configuration settings that are not learned directly from the data but affect the performance of the model. Examples of hyperparameters include learning rate, regularization parameter, and number of hidden layers in a neural network.
Once the model training is complete, it is essential to evaluate its performance. This involves measuring how well the model generalizes to unseen data, using the test dataset that was set aside during the data preparation phase. Common evaluation metrics include accuracy, precision, recall, and F1-score, depending on the problem type.
If the model does not perform well, there are several approaches to improve its performance. This may involve revisiting the data preprocessing steps, adjusting the model’s hyperparameters, or even trying different algorithms. It is an iterative process that requires experimentation and fine-tuning to achieve the desired level of accuracy.
Once the model has been trained and evaluated, it is ready to make predictions on new, unseen data. It is important to note that the model’s performance may vary on real-world data compared to the test set. Regular monitoring and updating of the model, as new data becomes available, is crucial to maintain its accuracy and relevance.
Building and training a machine learning model involves careful algorithm selection, data feeding, and iterative optimization. In the next sections, we will explore the process of evaluating and testing the model’s performance, as well as deploying and scaling the model for practical applications.
Evaluating and Testing the Machine Learning Model
Once a machine learning model has been built and trained, it is crucial to evaluate its performance and test its capabilities on unseen data. Evaluating and testing the model allows us to assess its accuracy, generalization ability, and reliability in real-world scenarios.
The evaluation process begins by feeding the test dataset, which was set aside during the data preparation phase, to the trained model. The model makes predictions on this data, and the predicted outputs are compared against the true outputs to measure the model’s performance.
Various evaluation metrics can be used, depending on the type of problem being solved. For classification tasks, common metrics include accuracy, precision, recall, and F1-score. These metrics provide insights into the model’s ability to correctly classify instances into their respective classes.
In regression tasks, evaluation metrics such as mean squared error (MSE), root mean squared error (RMSE), and coefficient of determination (R-squared) are commonly used. These metrics quantify the deviation between the predicted values and the actual values, measuring the accuracy of the model’s predictions.
In addition to evaluation metrics, it is important to understand the model’s limitations and potential sources of errors. Analyzing the model’s performance on specific subsets of the data, such as different classes or regions, can provide valuable insights into its strengths and weaknesses.
It is also crucial to assess the model’s ability to generalize to unseen data. This can be done through techniques such as cross-validation, where the dataset is divided into multiple subsets, and the model is trained and evaluated on different combinations of these subsets. Cross-validation helps estimate how well the model performs on new, unseen data and is particularly useful when the dataset is limited.
In addition to evaluating the model’s performance, it is important to consider the potential ethical implications associated with its predictions. Bias, discrimination, or unfairness can arise if the model is trained on biased or unrepresentative data. Evaluating and mitigating these biases is crucial to ensure fair and ethical machine learning practices.
If the model’s performance is not satisfactory, several steps can be taken to improve its accuracy. This may involve fine-tuning the model’s hyperparameters, revisiting the feature engineering process, or even considering a different algorithm or approach altogether. Model performance should be continuously monitored and optimized as new data becomes available.
Evaluating and testing the machine learning model is a critical step in the machine learning workflow. It provides insights into the model’s accuracy, generalization ability, and limitations. In the next sections, we will explore the process of deploying and scaling the model for practical applications, as well as common challenges and best practices in machine learning projects.
Deploying and Scaling the Machine Learning Model
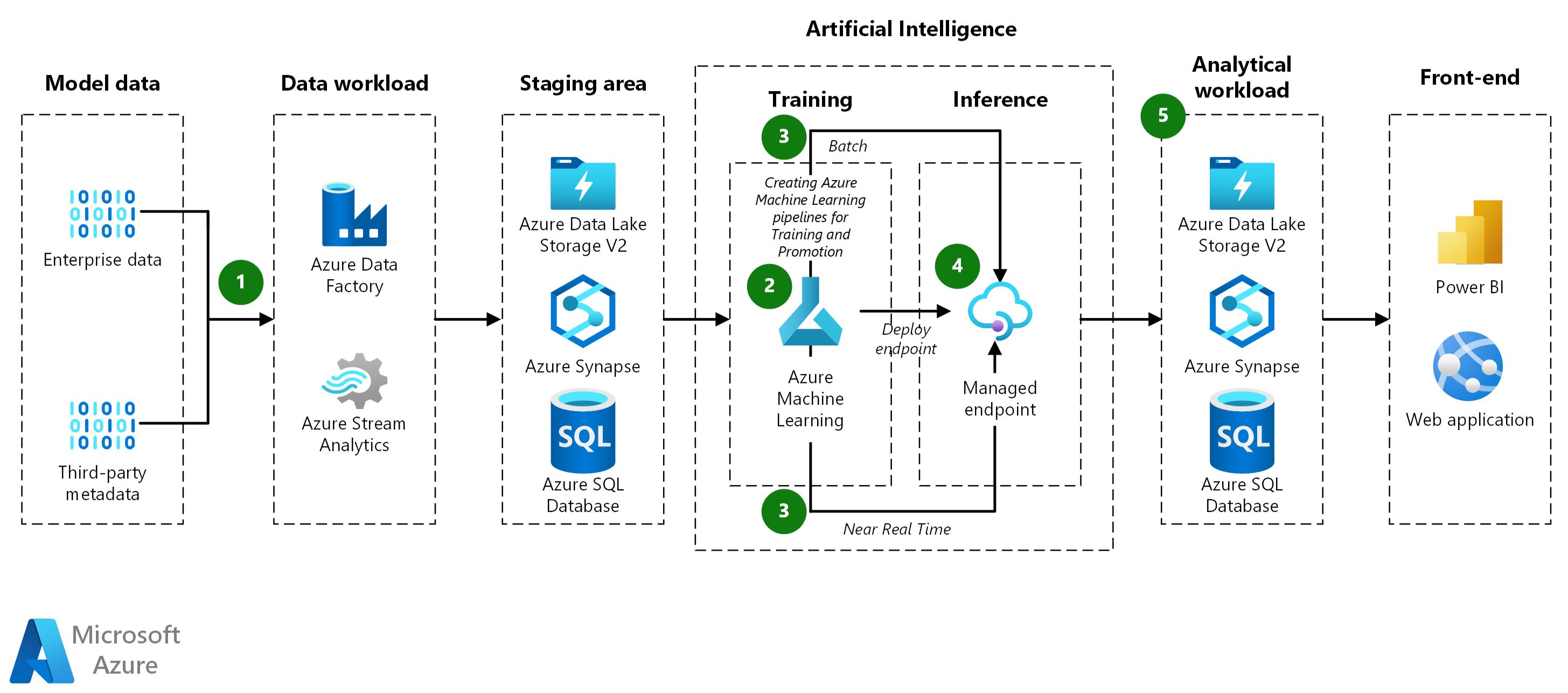
Deploying and scaling a machine learning model is the process of making it available for practical use and ensuring its performance and reliability in real-world scenarios. This step involves transitioning the model from a development environment to a production environment, where it can handle large volumes of data and make predictions in real-time.
One common approach to deploying a machine learning model is to package it as a service or API (Application Programming Interface) that can be accessed by other applications. This allows developers to integrate the model seamlessly into existing systems or build new applications around it. The model can be hosted on a server or cloud platform, making it accessible to users or other software components through well-defined endpoints.
When deploying a machine learning model, it is crucial to consider scalability. As the usage and demand for the model increase, it should be able to handle a growing number of requests efficiently. This may involve optimizing the code, utilizing parallel computing techniques, or scaling the infrastructure to handle higher volumes of data and user traffic.
Monitoring the deployed model’s performance is essential to ensure its reliability and detect any issues or anomalies. Monitoring can involve tracking various metrics, such as prediction accuracy, response time, and resource utilization. This information can be used to optimize the model and infrastructure, detect potential errors, and make informed decisions for improvements.
A well-designed deployment pipeline includes mechanisms for versioning and updating the model. As new data becomes available or the model’s performance needs enhancement, it can be retrained with the latest data and deployed as an updated version. Versioning ensures that different iterations of the model can coexist and allows for easy rollback if necessary.
Another important consideration in deploying a machine learning model is ensuring data privacy and security. Depending on the nature of the data being processed, measures such as encryption, access controls, and anonymization techniques may need to be implemented to protect sensitive information.
Furthermore, it is important to have a robust monitoring and error handling system in place. This includes mechanisms to detect and handle data quality issues, model failures, and any potential bias or unfairness in the predictions. Regular monitoring, performance testing, and feedback from users or stakeholders are vital for maintaining the model’s accuracy and reliability over time.
Deploying and scaling a machine learning model involves carefully considering factors like performance, reliability, scalability, and security. By planning and implementing a well-designed deployment strategy, organizations and individuals can leverage the power of machine learning to make accurate predictions and informed decisions in various domains.
In the next sections, we will explore common challenges and pitfalls in machine learning projects, as well as best practices for successful implementation and management of machine learning applications.
Common Challenges and Pitfalls in Machine Learning
While machine learning offers exciting opportunities, it also presents its fair share of challenges and potential pitfalls. Understanding and addressing these challenges is crucial for successful implementation and utilization of machine learning models.
One common challenge in machine learning is obtaining high-quality and representative data. Data collection can be time-consuming, expensive, or prone to biases. Additionally, unbalanced data distributions or missing data can affect the performance and fairness of the models. It is essential to carefully curate and preprocess the data to ensure its reliability, relevance, and fairness.
Another challenge is choosing the right algorithm and model architecture. With numerous algorithms and techniques available, it is often difficult to determine the most suitable approach for a specific problem. Misalignment between the problem requirements and the algorithm’s capabilities can lead to suboptimal results. Proper experimentation and evaluation are necessary to find the best algorithm and architecture for a given task.
One pitfall in machine learning is overfitting, which occurs when a model becomes overly complex and captures noise or idiosyncrasies in the training data, leading to poor generalization to unseen data. Regularization techniques and cross-validation can help overcome overfitting and ensure models have the ability to generalize well.
Deploying and scaling machine learning models can also present challenges. Ensuring reliable performance, handling large volumes of data, and managing infrastructure resources are crucial aspects. Scaling models to handle increased user traffic or data volume requires careful optimization and consideration of hardware or cloud resource allocation.
Interpreting and explaining machine learning models can be challenging, especially for complex models like neural networks. Models that lack interpretability may hinder transparency, accountability, and trust, which are essential in certain domains such as healthcare or finance. Techniques like feature importance analysis and model-agnostic explanations can help provide insights into model predictions.
Continuous monitoring and maintenance of machine learning models are necessary to ensure ongoing accuracy and performance. Models may degrade over time due to changing data distributions or evolving problem requirements. Regular retraining of models with updated data and periodic evaluation of their performance are essential to maintain their effectiveness.
Ethical considerations are paramount in machine learning projects. Biased or discriminatory outcomes can arise from biased data or algorithmic biases. Addressing potential biases, ensuring fairness, and building diverse, inclusive training datasets are crucial to avoid unintended societal impacts and legal repercussions.
Finally, a significant challenge is the scarcity of skilled professionals with expertise in machine learning. Developing and implementing machine learning projects require a multidisciplinary skillset encompassing data science, mathematics, programming, and domain knowledge. Organizations must invest in attracting and retaining talent or develop strong internal capabilities to ensure successful adoption of machine learning.
Understanding and mitigating these challenges and pitfalls is essential to navigate the complexities of machine learning effectively. In the next section, we will discuss best practices that can help maximize the chances of success and ensure efficient and ethical implementation of machine learning projects.
Best Practices for Successful Machine Learning Projects
Implementing a successful machine learning project requires careful planning, attention to detail, and adherence to best practices. By following these practices, organizations can increase the chances of achieving accurate and impactful outcomes from their machine learning projects.
1. Clearly Define the Problem: Start by clearly defining the problem you are trying to solve or the goal you want to achieve with machine learning. Articulate the specific objectives and expected outcomes, as this will guide the entire project and ensure focus.
2. Collect and Prepare High-Quality Data: Gather relevant and representative data, ensuring it is of high quality and free from biases. Clean and preprocess the data, handling missing values, outliers, and inconsistencies. Validate the data to ensure its accuracy and reliability.
3. Choose the Right Algorithm and Model: Select the most appropriate algorithm and model architecture based on the problem type and data characteristics. Experiment with different algorithms if needed and evaluate their performance using appropriate metrics. Choose models that offer a balance between accuracy, interpretability, and scalability.
4. Feature Engineering: Invest time and effort in feature engineering to select and transform the most relevant features. This process can significantly impact the model’s performance. Use domain knowledge to identify meaningful features and consider techniques like feature scaling, one-hot encoding, or dimensionality reduction.
5. Validate and Monitor Model Performance: Continuously validate and monitor the performance of the model. Use proper evaluation techniques, such as cross-validation, to assess the model’s generalization ability. Continuously monitor the model in the production environment to ensure ongoing accuracy and performance.
6. Ensure Ethical and Fair Practices: Be aware of biases and potential ethical implications in the data, algorithms, and predictions. Take steps to address biases in data, monitor for algorithmic biases, and ensure fairness in the model’s predictions. Consider the legal and moral implications of the model’s impact on individuals and society.
7. Build a Robust Infrastructure: Set up a scalable and reliable infrastructure to deploy and serve the machine learning model. Consider factors like performance, availability, and security. Use cloud-based services or distributed computing frameworks to handle large volumes of data efficiently.
8. Continual Learning and Improvement: Machine learning is an iterative process. Continually collect new data, retrain the model, and refine the algorithms. Learn from user feedback and adapt the model as needed. Stay updated with the latest research and advancements in machine learning to incorporate new techniques or algorithms as they emerge.
9. Foster Collaboration and Communication: Cultivate a collaborative environment where data scientists, domain experts, and other stakeholders can work together effectively. Encourage open communication and knowledge sharing to leverage diverse perspectives and domain expertise.
10. Document and Share Insights: Document the entire machine learning project, including the data sources, preprocessing steps, model selection, and evaluation results. Share the insights and learnings with the wider organization to foster a culture of knowledge sharing and enable replication or improvement of the project in the future.
By following these best practices, organizations can set themselves up for success in their machine learning projects. It is important to recognize that machine learning is an evolving field, and continually adapting to new challenges and advancements is crucial for maintaining a competitive edge and achieving meaningful results.
Additional Resources and Further Learning in Machine Learning
Machine learning is a rapidly evolving field, and there are abundant resources available for further learning and exploration. Whether you are a beginner looking to dive into the basics or an experienced practitioner seeking advanced techniques, the following resources can help you expand your knowledge and skills in machine learning:
1. Online Courses: Platforms like Coursera, edX, and Udacity offer comprehensive online courses on machine learning from top universities and industry professionals. These courses cover a wide range of topics, from introductory to advanced concepts, and often include hands-on projects to apply your knowledge.
2. Books: There are many popular books on machine learning that can serve as valuable references and learning guides. Some recommended titles include “Pattern Recognition and Machine Learning” by Christopher Bishop, “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron, and “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville.
3. Online Tutorials and Blogs: Various blogs and tutorial websites provide step-by-step guides and practical examples of implementing machine learning algorithms. Websites like Towards Data Science, Medium, and Kaggle’s blog feature a wealth of tutorials, case studies, and insights shared by experts in the field.
4. Open-Source Libraries and Frameworks: Libraries such as scikit-learn, TensorFlow, and PyTorch are widely used for machine learning and offer extensive documentation, tutorials, and example code to help you get started. These libraries provide ample resources to learn and implement various machine learning algorithms and techniques.
5. Research Papers and Conferences: Stay updated with the latest advancements in machine learning by exploring research papers and attending conferences. ArXiv and Google Scholar are popular platforms for accessing research papers in the field. Additionally, conferences like NeurIPS (Conference on Neural Information Processing Systems) and ICML (International Conference on Machine Learning) feature cutting-edge research and networking opportunities.
6. Online Communities and Forums: Engage with the machine learning community through online forums such as Stack Overflow and Reddit. These platforms offer a space to ask questions, seek advice, and participate in discussions with fellow enthusiasts and experts.
7. Kaggle Competitions: Participate in Kaggle competitions to apply your machine learning skills to real-world problems and learn from experienced practitioners. Kaggle provides datasets, code notebooks, and an opportunity to collaborate with others in the community.
8. Online Documentation and Forums for Specific Tools: Explore the official documentation and community forums for specific tools, libraries, and frameworks that you use or are interested in. These resources often provide detailed documentation, tutorials, and examples specific to the tool, enabling you to gain a deeper understanding of its functionalities.
Remember, machine learning is a hands-on field, and practical experience is key to mastering the concepts. As you explore these resources, don’t hesitate to apply your knowledge to real-world problems, experiment with different algorithms, and continuously seek opportunities to learn and grow as a machine learning practitioner.