





Introduction
The central processing unit, or CPU, is a critical component of any computer system. It is responsible for executing instructions and performing calculations that enable the system to function. Naturally, one of the primary goals of CPU design is to increase processing speed, allowing for faster and more efficient operations.
However, there are limits to the number of instructions a CPU can execute within a given timeframe. Understanding these limitations can shed light on why processors have specific performance characteristics and how they can be optimized.
In this article, we will explore the factors that limit the number of instructions a CPU can execute and their impact on processing speed. We will delve into various aspects of CPU architecture, including clock speed, instruction set, number of cores, memory bandwidth, cache, and power requirements.
By gaining insight into these factors, we can better appreciate the challenges and trade-offs involved in optimizing CPU performance. Let’s dive in and explore the fascinating world of CPU limitations and their impact on processing speed.
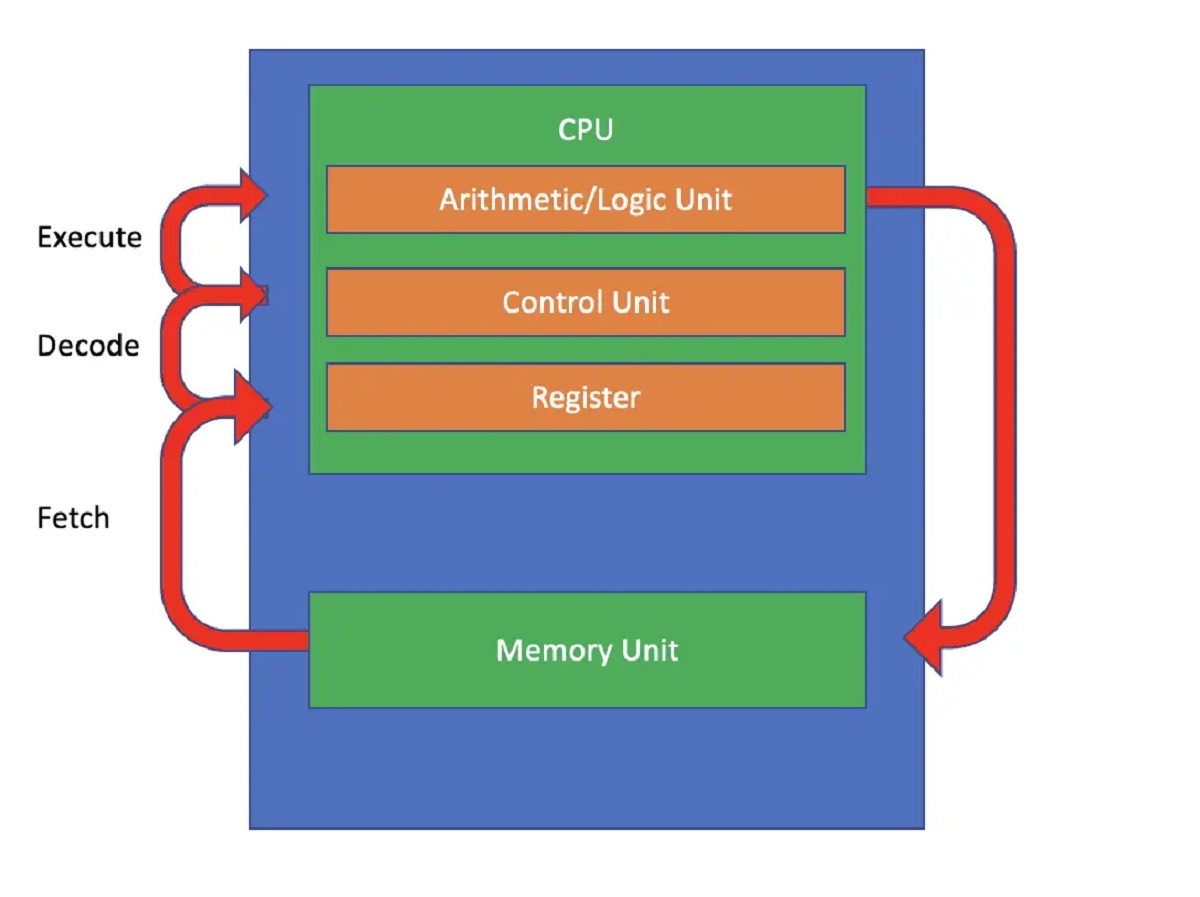
CPU Architecture
CPU architecture plays a crucial role in determining the processing speed of a computer system. The design and organization of the CPU impact its ability to execute instructions efficiently.
Modern CPUs are typically based on complex instruction set computing (CISC) or reduced instruction set computing (RISC) architectures. CISC CPUs have a larger and more diverse instruction set, allowing for more complex operations to be performed with a single instruction. On the other hand, RISC CPUs have a simplified instruction set, which enables faster instruction execution.
Another critical aspect of CPU architecture is the pipeline design. Pipelining allows the CPU to execute multiple instructions simultaneously, overlapping different stages of the instruction execution process. This parallelism improves processing speed; however, it also introduces challenges, such as the potential for instruction dependencies and pipeline stalls.
Furthermore, the width of the CPU’s data bus and the number of registers can impact processing speed. A wider data bus allows for faster data transfer between the CPU and memory, while more registers enable the CPU to store and access data quickly.
Cache memory is another vital component of the CPU architecture. It acts as a high-speed storage area that holds frequently accessed instructions and data, reducing the need to fetch them from slower main memory. The size and organization of the cache can significantly impact the CPU’s performance.
Overall, the architecture of the CPU determines its capability to execute instructions efficiently. A well-designed architecture can enhance processing speed by optimizing instruction execution, minimizing bottlenecks, and maximizing resource utilization.
Clock Speed
One of the primary factors that determine the speed at which a CPU can execute instructions is its clock speed. The clock speed refers to the rate at which the CPU’s internal clock generates electrical pulses that synchronize the operation of its various components. It is typically measured in frequency units called gigahertz (GHz).
A higher clock speed means that the CPU can execute more instructions per second, resulting in faster processing. This is because each instruction is processed within a specific number of clock cycles, known as the instruction cycle. The shorter the duration of each clock cycle, the faster instructions can be executed.
Advancements in manufacturing technologies have enabled CPUs to achieve higher clock speeds over time. However, there are limits to how fast a CPU can operate. As clock speeds increase, several technical challenges arise, including power consumption, heat dissipation, and signal integrity.
Increased power consumption is a significant concern as higher clock speeds require more electrical energy to drive the CPU’s circuits. This leads to more heat being generated, which can cause thermal throttling and reduce performance if not managed properly.
Heat dissipation becomes a critical aspect of CPU design, as excessive heat can damage the CPU and other components in the system. Manufacturers mitigate this by incorporating efficient cooling mechanisms, such as heat sinks and fans, to maintain optimal operating temperatures.
Signal integrity is another concern at higher clock speeds. As the frequency of the clock signal increases, the potential for signal degradation and interference grows. This requires careful design considerations to ensure that the CPU’s internal signals remain stable and reliable.
It’s important to note that clock speed alone does not determine the overall performance of a CPU. Other factors, such as the number of cores, cache size, and instruction set, also play significant roles. Nonetheless, clock speed remains a fundamental aspect of CPU performance and is an essential consideration when comparing different processors.
Instruction Set
The instruction set of a CPU defines the repertoire of machine instructions it can execute. It specifies the operations that the CPU can perform, such as arithmetic calculations, logical operations, data movement, and control flow instructions.
The design and complexity of the instruction set impact the CPU’s ability to execute instructions efficiently. There are two main types of instruction sets: complex instruction set computing (CISC) and reduced instruction set computing (RISC).
CISC CPUs have a large and diverse set of instructions. Each instruction can perform multiple operations, allowing for complex tasks to be executed with a single instruction. This allows for more efficient code development and potentially reduces the number of instructions required to perform a task. However, the increased complexity of the instruction set can result in longer execution times and higher power consumption.
RISC CPUs, on the other hand, have a simplified instruction set. Each instruction performs a single operation, resulting in a smaller and more streamlined set of instructions. This simplicity allows for faster instruction decoding and execution, leading to improved processing speed. However, it may require more instructions to accomplish complex tasks.
Modern CPU architectures often incorporate a combination of CISC and RISC elements, known as complex instruction set architecture (ISA). This hybrid approach aims to leverage the advantages of both instruction set types, providing a balance between instruction complexity and execution efficiency.
Instruction set extensions, such as SIMD (single instruction, multiple data) and VLIW (very long instruction word), can further enhance the CPU’s capabilities. SIMD instructions allow for parallel processing of data elements, enabling accelerated multimedia and scientific computations. VLIW instructions allow the CPU to execute multiple instructions simultaneously, increasing throughput and performance.
The choice of instruction set impacts software development, as different programming languages and compilers may be optimized for specific instruction sets. It is important for developers to consider the target CPU architecture to ensure optimal software performance.
In summary, the instruction set of a CPU defines its capabilities and impacts its performance. The design philosophy, complexity, and extensions of the instruction set influence the efficiency and versatility of instruction execution.
Number of Cores
The number of cores in a CPU is a significant factor in determining its processing speed and multitasking capabilities. A core is an independent processing unit within the CPU that can execute instructions and perform calculations.
Traditionally, CPUs were designed with a single core, which meant that they could only handle one instruction stream at a time. However, as the demand for multitasking and parallel processing increased, CPUs evolved to include multiple cores.
A multi-core CPU allows for concurrent execution of multiple tasks. Each core can handle a separate instruction stream, enabling parallel processing and improved overall performance. For example, while one core is performing a complex calculation, another core can handle background processes or user interface tasks.
The benefits of multiple cores are particularly noticeable in tasks that can be effectively parallelized, such as video editing, rendering, scientific simulations, or running multiple applications simultaneously. With more cores, each task can be allocated to a separate core, resulting in faster processing times and enhanced system responsiveness.
It is important to note that the effectiveness of multiple cores depends on various factors, including the nature of the tasks being performed and the available software. Some applications are not optimized for multi-threading and cannot fully leverage the advantages of multiple cores, potentially resulting in limited performance gains.
Additionally, the overall performance improvement achieved with each additional core may diminish. This is because the tasks assigned to each core must be divided efficiently, and the overhead of coordinating between cores increases as the number of cores grows.
Manufacturers have developed different configurations of multi-core CPUs, such as dual-core, quad-core, and even octa-core processors. Each configuration offers a different balance between processing power and cost. The choice of the number of cores depends on the specific requirements of the user.
In recent years, CPUs with a higher number of cores have become more common, particularly in high-end desktop and server systems. However, for typical day-to-day computing tasks, a dual-core or quad-core CPU is often sufficient.
In summary, the number of cores in a CPU impacts its multitasking capabilities and overall processing speed. Multiple cores enable parallel processing, leading to improved performance in tasks that can be parallelized. However, the benefits may vary depending on the nature of the tasks and software optimization.
Memory Bandwidth
Memory bandwidth refers to the rate at which data can be read from or written to the computer’s memory. It plays a crucial role in determining the overall performance of a CPU, as it affects how quickly the CPU can access instructions and data.
When a CPU needs to execute an instruction or access data from memory, it uses the memory bus, which is the pathway that connects the CPU and the memory modules. The memory bus has a limited capacity, known as its bandwidth, which determines the amount of data that can be transferred in a given time.
The higher the memory bandwidth, the faster the CPU can retrieve instructions and data, resulting in improved processing speed. A limited memory bandwidth can cause a bottleneck, where the CPU has to wait for the data to be transferred, slowing down the execution of instructions.
Several factors can affect memory bandwidth, including the memory type, bus width, and memory clock speed. Different generations of memory, such as DDR4 or DDR5, offer varying bandwidth capabilities. Likewise, a wider memory bus and higher memory clock speed can increase the amount of data that can be transferred simultaneously.
Memory bandwidth is particularly important in tasks that require frequent access to large amounts of data, such as video editing, gaming, or scientific simulations. In these scenarios, a higher memory bandwidth allows for faster loading times, smoother gameplay, and quicker data processing.
It’s worth noting that the CPU’s cache memory can also impact memory access times. Cache acts as a buffer between the CPU and the main memory, storing frequently accessed instructions and data. When the cache is able to satisfy the CPU’s memory requests, it reduces the need to access the main memory, improving overall performance. However, if the cache is too small or cannot effectively predict the CPU’s memory access patterns, it may result in cache misses, leading to slower performance.
In summary, memory bandwidth is a crucial factor in CPU performance. A higher memory bandwidth allows for faster access to instructions and data, improving overall processing speed. The memory type, bus width, memory clock speed, and cache performance all contribute to the effective utilization of memory bandwidth.
Cache
Cache memory is a critical component in modern CPU architectures that helps improve overall performance by reducing memory access times. It acts as a temporary storage area for frequently accessed instructions and data, providing faster access compared to the main memory.
The cache operates on the principle of locality of reference, which states that data that has been recently accessed or is likely to be accessed in the near future is more likely to be accessed again. By storing this data in a small but fast cache, the CPU can retrieve it quickly, avoiding the latency associated with accessing the main memory.
Cache memory is typically organized into multiple levels, including Level 1 (L1), Level 2 (L2), and sometimes Level 3 (L3). Each level has different sizes and proximity to the CPU. L1 cache is the closest and fastest, while L3 cache is usually larger but slightly slower.
Cache size and organization play a crucial role in determining its effectiveness. A larger cache can hold more instructions and data, increasing the likelihood of a cache hit. A cache hit occurs when the CPU finds the required data in the cache, resulting in faster data retrieval. On the other hand, a cache miss occurs when the desired data is not found in the cache, requiring the CPU to access the main memory, resulting in increased latency.
Cache behavior is also influenced by cache associativity. Associativity refers to the way cache lines are mapped to specific memory locations. Direct-mapped cache, for example, maps each memory location to a specific cache location, which can cause cache conflicts if multiple memory locations are mapped to the same cache location. Set-associative or fully associative cache designs overcome this limitation by allowing multiple memory locations to be mapped to the same cache set or cache line.
The effectiveness of the cache is highly dependent on the CPU’s ability to predict which data to store in the cache. This is known as cache prefetching and involves algorithms that analyze the program’s memory access patterns to pre-fetch frequently accessed data into the cache before it is needed. Efficient prefetching can result in fewer cache misses and improved performance.
Overall, cache memory plays a crucial role in CPU performance by reducing memory access times and improving overall efficiency. Its size, organization, and prefetching mechanisms directly impact the effectiveness of the cache in accelerating instruction execution and data access.
Power and Cooling
Power consumption and heat generation are critical considerations in CPU design and can significantly impact performance and reliability. As CPUs continue to increase in complexity and processing power, managing power consumption and ensuring proper cooling becomes more important than ever.
Modern CPUs require a substantial amount of electrical power to operate. Higher clock speeds, multiple cores, and advanced architectural features increase power demands. As a result, power management techniques, such as dynamic voltage and frequency scaling (DVFS), are employed to adjust the CPU’s power consumption based on workload requirements. DVFS allows the CPU to operate at lower power levels during periods of low activity, conserving energy and reducing heat dissipation.
However, even with efficient power management, CPUs still generate significant amounts of heat during operation. Excessive heat can degrade performance, cause thermal throttling, and lead to premature component failure. Therefore, effective cooling mechanisms are crucial to maintain optimal operating temperatures.
The most common cooling method for CPUs is a combination of heat sinks and fans. Heat sinks are metallic components that absorb and dissipate heat, while fans help circulate air, increasing the rate of heat transfer. A properly designed cooling solution ensures that the CPU remains within the safe temperature range for optimal performance.
In high-performance systems, liquid cooling solutions are becoming increasingly popular. These systems use coolants flowing through tubes connected to the CPU to directly absorb and dissipate heat. Liquid cooling offers improved thermal efficiency and can handle higher heat loads compared to traditional air cooling methods.
Efficient cooling is not only necessary for maintaining performance but also important for extending the lifespan of the CPU. Excessive heat can cause thermal stress on the CPU and other components, potentially leading to early failure and system instability.
Manufacturers often provide thermal specifications and guidelines for each CPU model, including maximum operating temperatures and recommended cooling solutions. It is crucial to adhere to these guidelines to ensure reliable and efficient operation.
In summary, power consumption and heat generation are critical considerations in CPU design. Efficient power management and cooling mechanisms are necessary to optimize performance, prevent thermal throttling, and ensure the longevity of the CPU.
Conclusion
The speed at which a CPU can execute instructions is influenced by several key factors. CPU architecture, including factors such as the instruction set, number of cores, and cache design, plays a vital role in determining the CPU’s efficiency and processing speed.
The clock speed of a CPU, measured in gigahertz (GHz), determines the rate at which instructions can be executed. However, other factors such as memory bandwidth, cache performance, and power consumption also impact the overall performance of the CPU.
Multi-core CPUs allow for parallel processing, enabling faster execution of multiple tasks simultaneously. The number of cores and the effective utilization of cache memory influence the CPU’s multitasking capabilities and overall performance in handling parallel workloads.
Efficient memory access is crucial for CPU performance. Memory bandwidth determines the rate at which data can be read from or written to memory, directly impacting instruction execution. The cache memory, acting as a temporary storage area for frequently accessed data, reduces memory access times and improves performance by leveraging the principle of locality of reference.
Power consumption and cooling are also important considerations in CPU design. CPUs require significant power to operate, and efficient power management techniques help optimize energy consumption. Maintaining optimal operating temperatures through effective cooling mechanisms, such as heat sinks and fans or liquid cooling, prevents thermal throttling and ensures the longevity of the CPU.
In conclusion, achieving optimal processing speed relies on a combination of CPU architecture, clock speed, memory bandwidth, cache efficiency, and power management. By understanding the factors that limit instruction execution and how they interact, computer systems can be designed and optimized for faster and more efficient performance.
















