Introduction
Machine learning is a branch of artificial intelligence that focuses on developing algorithms and models that enable computers to learn and make predictions or decisions without explicit programming. One of the primary goals of machine learning is to improve the accuracy of predictions by constantly learning from data and adapting to new information.
In the context of machine learning, recall is an important metric used to evaluate the performance of a classifier or model. It measures the ability of a model to identify all relevant instances or records in a dataset. High recall indicates that the model is effective at capturing most of the positive instances, while low recall suggests that the model may be missing important records.
Recall is particularly crucial in scenarios where the identification of positive instances is paramount, such as detecting fraudulent transactions, identifying diseases in medical diagnoses, or flagging spam emails. While other performance metrics like accuracy and precision provide valuable insights, recall specifically focuses on minimizing false negatives.
When it comes to evaluating the effectiveness of a model, a single metric like accuracy can be misleading, especially in cases where the dataset is imbalanced. For example, if we’re developing a model to detect rare diseases that only occur in 1% of the population, a model that predicts all instances as negative (with 99% accuracy) would be practically useless. In such cases, recall becomes a more informative measure as it directly assesses the model’s ability to find the positive cases, minimizing the risk of false negatives.
In this article, we will delve deeper into the concept of recall, its importance in machine learning, how to calculate it, interpret the results, and explore various strategies to improve recall. Understanding these key aspects will enable data scientists and machine learning practitioners to build models that are not only accurate but also effective in capturing positive instances in real-world applications.
Definition of Recall
Recall, also known as sensitivity or true positive rate, is a performance metric used to evaluate the ability of a machine learning model to correctly identify all positive instances in a dataset. It measures the proportion of true positives (correctly identified positive instances) out of the total number of actual positive instances.
Mathematically, recall can be expressed as:
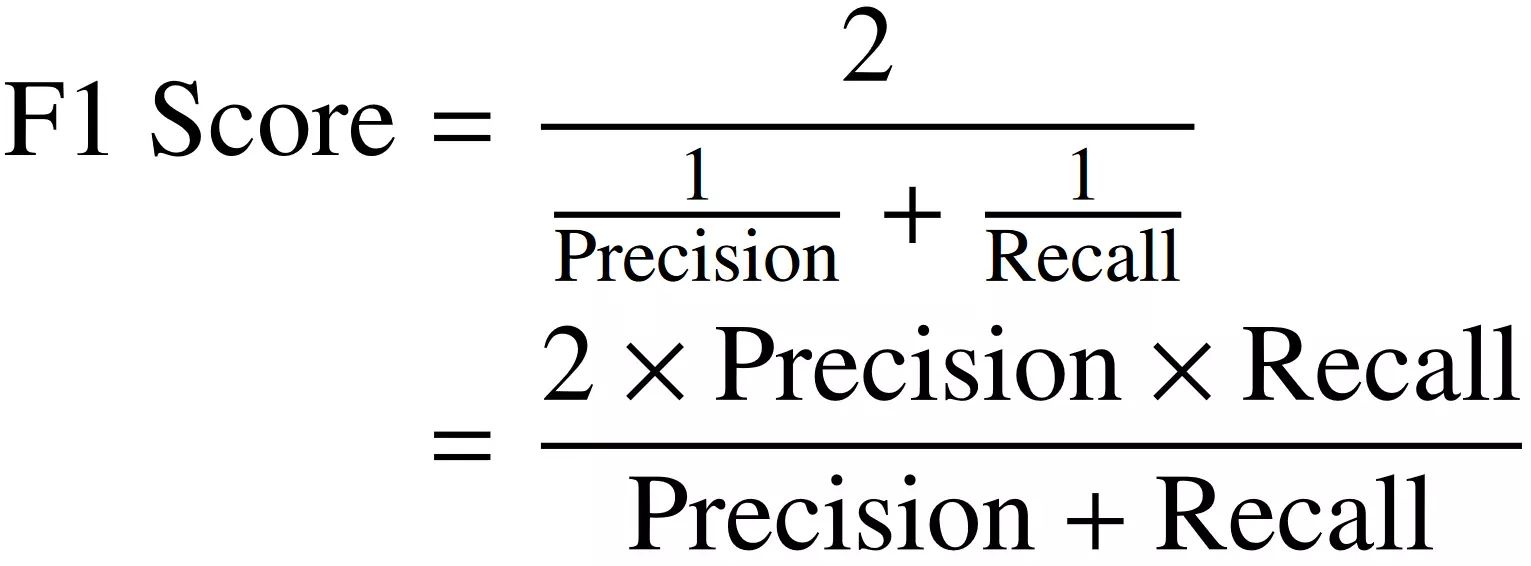
Recall = True Positives / (True Positives + False Negatives)
True positives represent the number of positive instances that the model correctly identified, while false negatives represent the number of positive instances that were mistakenly classified as negative by the model.
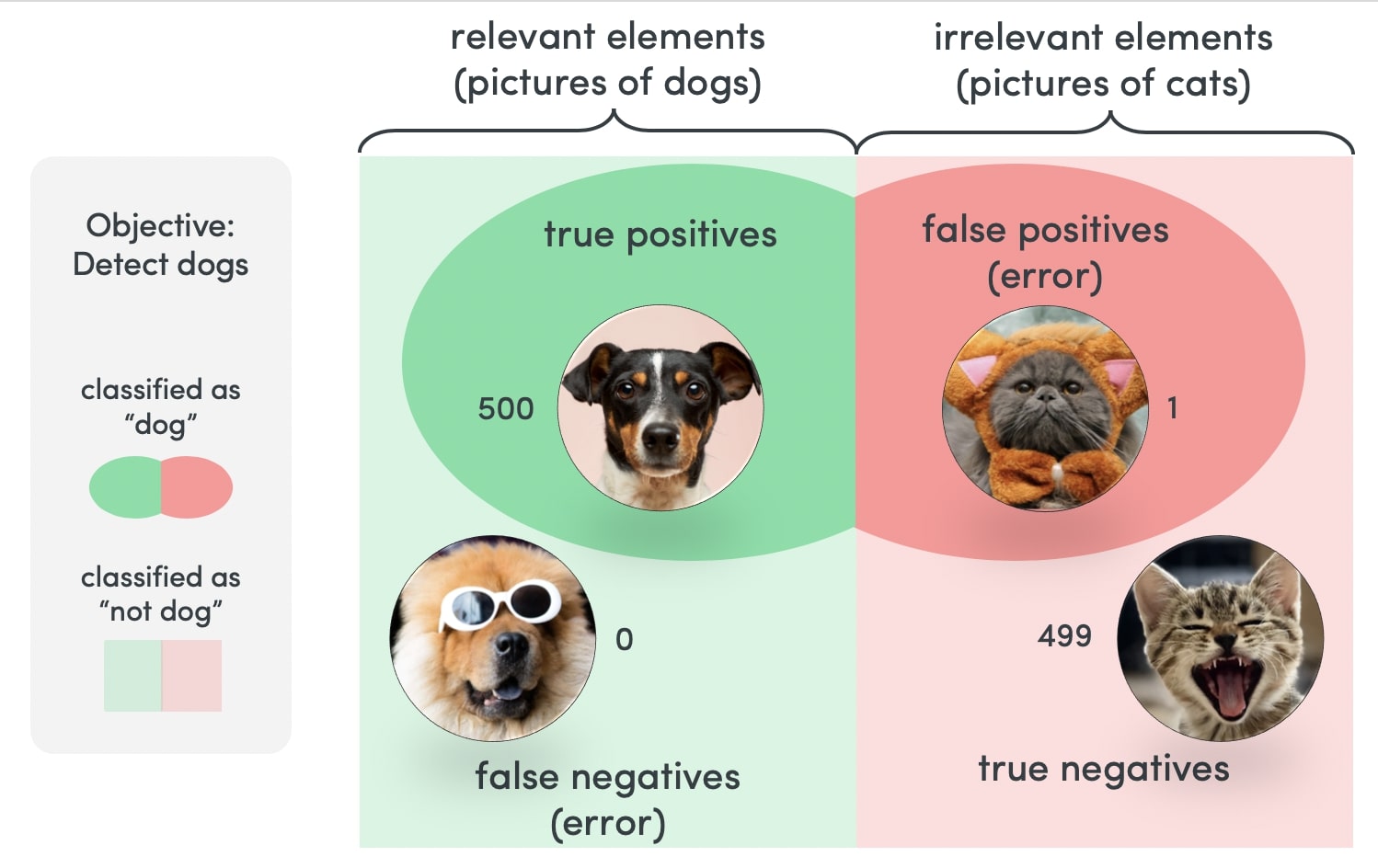
For instance, let’s consider a binary classification problem where our model predicts whether an email is spam or not:
- True Positive (TP): The model accurately predicts an email as spam, and indeed, it is spam.
- False Negative (FN): The model incorrectly predicts an email as not spam, but it is actually spam.
- False Positive (FP): The model incorrectly predicts an email as spam, but it is not spam.
- True Negative (TN): The model accurately predicts an email as not spam, and indeed, it is not spam.
Recall focuses specifically on the true positive and false negative rates, emphasizing the model’s ability to minimize false negatives. Essentially, recall quantifies the completeness of the model’s predictions regarding positive instances.
A high recall value indicates that the model successfully identifies a large proportion of positive instances, minimizing the number of false negatives. On the other hand, a low recall value suggests that the model may be missing important positive instances, leading to a high number of false negatives.
It is important to note that recall is only one of the performance metrics used to evaluate a machine learning model. It should be considered alongside other metrics such as accuracy, precision, and F1 score to gain a comprehensive understanding of the model’s overall performance.
Why Recall is Important in Machine Learning
Recall plays a crucial role in machine learning as it directly addresses the issue of false negatives. False negatives occur when a positive instance is mistakenly classified as negative by the model. In various real-world applications, the consequences of false negatives can be severe and highly undesirable.
Consider a medical diagnosis scenario where a machine learning model is developed to detect a life-threatening disease. A false negative in this case would mean that the model fails to identify an individual who actually has the disease. As a result, the individual would not receive the necessary medical intervention, potentially leading to delayed treatment or even loss of life.
In situations like fraud detection, a false negative can mean overlooking malicious activities and allowing potential financial losses for individuals or organizations. Similarly, in spam email filtering, false negatives may result in important emails being wrongly classified as spam, leading to missed opportunities or crucial information going unnoticed.
By focusing on recall, machine learning models prioritize sensitivity and the ability to capture positive instances. Maximizing recall helps minimize the occurrence of false negatives, thus reducing the risks and consequences associated with missing important positive cases.
Moreover, recall becomes especially vital when dealing with imbalanced datasets, where the number of positive instances is significantly smaller than that of negative instances. In such cases, if a model is optimized for accuracy alone, it might achieve high accuracy by simply predicting all instances as negative. However, this would lead to extremely low recall and compromise the model’s effectiveness in capturing positive instances.
It’s worth noting that recall should be considered alongside other performance metrics like precision and accuracy. While recall focuses on minimizing false negatives, precision measures the ability of the model to correctly identify positive instances out of the total predicted positives. Accuracy, on the other hand, provides an overall measure of the model’s correctness in classifying both positive and negative instances.
In summary, recall is important in machine learning as it helps minimize the risks and consequences of false negatives. By prioritizing sensitivity and the ability to capture positive instances, models can make accurate predictions in critical applications like disease diagnosis, fraud detection, spam filtering, and many others.
How to Calculate Recall
Calculating recall involves evaluating the true positive and false negative rates of a machine learning model. The formula for calculating recall is:
Recall = True Positives / (True Positives + False Negatives)
To calculate recall, follow these steps:
- Determine the number of true positives (TP): These are the instances correctly identified as positive by the model. For example, in a medical diagnosis scenario, TP would represent the number of patients correctly diagnosed with a disease.
- Determine the number of false negatives (FN): These are the instances that were incorrectly predicted as negative by the model, but are actually positive. In the medical diagnosis example, FN would represent the number of patients who have the disease but were falsely classified as disease-free by the model.
- Add the true positives and false negatives: Sum up the number of true positives and false negatives.
- Divide the number of true positives by the sum of true positives and false negatives: Use the formula mentioned above to calculate the recall.
For example, suppose we have a dataset of 100 spam emails, and our machine learning model predicts 80 of them correctly as spam (true positives) while mistakenly classifying 10 as not spam (false negatives). The calculation of recall would be as follows:
Recall = 80 / (80 + 10) = 0.888 (or 88.8%)
This means that our model has a recall of 0.888 or 88.8%, implying that it is able to successfully capture 88.8% of the actual positive instances in the dataset.
It is important to note that recall alone may not provide a complete understanding of the model’s performance. Therefore, it is often analyzed in conjunction with other performance metrics like precision, accuracy, and the F1 score to gain a comprehensive evaluation. These metrics collectively provide insights into the model’s ability to correctly identify positive instances while minimizing false positives and false negatives.
Interpretation of Recall Results
Understanding the interpretation of recall results is crucial for evaluating the performance of a machine learning model. The recall value provides insights into how effectively the model captures positive instances in a dataset. Here are some key points to consider when interpreting recall results:
- A high recall value (close to 1.0 or 100%) indicates that the model is effectively capturing most of the positive instances in the dataset. This suggests that the model has a low number of false negatives and is performing well in identifying the positive cases.
- A low recall value (close to 0.0 or 0%) suggests that the model may be missing a significant number of positive instances, leading to a high number of false negatives. This indicates that the model’s performance in capturing positive cases is suboptimal.
- Interpreting recall results in relation to the specific application is crucial. A high recall value might be more important in certain scenarios where minimizing false negatives is of utmost importance, such as in medical diagnoses or fraud detection. However, in other contexts, a slightly lower recall value might be acceptable if the focus is on precision or reducing false positives.
- Recall alone does not provide a complete picture of the model’s performance. It is recommended to consider other performance metrics like precision, accuracy, and the F1 score alongside recall to obtain a comprehensive evaluation. These metrics provide additional insights into the model’s ability to correctly identify positive instances while minimizing false positives and false negatives.
- It is crucial to compare the recall value with the baseline or desired performance level. This could be determined by benchmarking the model against industry standards or evaluating its performance against the requirements of the specific application. This helps determine the adequacy of the model’s recall results in the given context.
Interpreting recall results goes beyond numerical values; it requires understanding the context of the problem and the potential consequences of false negatives. Effective interpretation of recall results enables data scientists and decision-makers to assess the model’s strengths, weaknesses, and overall performance in capturing positive instances.
Factors Affecting Recall
Several factors can influence the recall performance of a machine learning model. Understanding these factors is crucial for improving and optimizing the recall results. Here are some key factors that can affect the recall of a model:
- Data Quality: The quality and reliability of the training data can greatly impact recall. If the training data contains errors, inconsistencies, or mislabeled instances, it can lead to a decrease in recall performance. It is important to ensure that the dataset is clean, properly labeled, and representative of the real-world instances that the model will encounter.
- Imbalanced Datasets: Imbalanced datasets, where the number of positive instances is significantly smaller than the negative instances, can pose challenges for recall. Models trained on imbalanced datasets tend to prioritize accuracy by classifying most instances as negative, resulting in low recall. Techniques such as oversampling the minority class or using techniques like SMOTE (Synthetic Minority Over-sampling Technique) can help address this issue.
- Feature Selection and Engineering: The choice and quality of features used in the model can impact recall. Relevant features that capture the distinguishing characteristics of the positive instances are essential for improving recall. Additionally, feature engineering techniques, such as creating new features or transforming existing features, can help enhance the model’s ability to capture positive instances.
- Model Complexity: The complexity of the machine learning model can also affect recall. Overly complex models may overfit the training data, resulting in poor generalization and lower recall performance. It is important to strike a balance between model complexity and interpretability to ensure optimal recall results.
- Threshold Setting: The threshold used to classify instances can impact recall. A higher threshold will lead to a more conservative classification, potentially increasing recall but potentially at the expense of precision. Conversely, a lower threshold may increase precision but could lead to a decrease in recall. Fine-tuning the threshold based on the specific requirements of the application can help optimize recall performance.
- Model Selection and Tuning: The choice of machine learning algorithm and hyperparameter tuning can impact recall. Different algorithms have varying capabilities in capturing positive instances. Additionally, hyperparameters like regularization strength, learning rate, or tree depth can influence recall performance. It is essential to explore and compare different algorithms and tune hyperparameters to find the best combination for improving recall.
By considering these factors and implementing appropriate strategies, it is possible to enhance the recall performance of a machine learning model. Careful attention to data quality, dataset balance, feature selection, model complexity, threshold setting, and model selection and tuning can lead to significant improvements in recall performance and overall model effectiveness.
Strategies to Improve Recall
Improving recall in a machine learning model requires careful consideration of various strategies and techniques. By employing these strategies, data scientists and practitioners can enhance the model’s ability to capture positive instances. Here are some effective strategies to improve recall:
- Data Augmentation: Augmenting the dataset with additional samples can help address the issue of imbalanced datasets. Techniques like oversampling the minority class or using synthetic data generation methods, such as SMOTE (Synthetic Minority Over-sampling Technique), can effectively balance the dataset and improve recall for positive instances.
- Feature Engineering: Carefully selecting and engineering relevant features can significantly impact recall. Feature engineering techniques, such as creating new features, transforming existing ones, or applying domain-specific knowledge, can help capture the distinguishing characteristics of the positive instances and improve the model’s ability to identify them.
- Threshold Adjustment: Adjusting the classification threshold can be a powerful strategy to improve recall. By setting a lower threshold, the model becomes more sensitive, capturing more positive instances. However, this may come at the expense of precision. Fine-tuning the threshold based on the desired trade-off between recall and precision is crucial for optimizing the model’s performance.
- Ensemble Methods: Leveraging ensemble methods, such as bagging or boosting, can improve recall performance. Ensemble methods combine multiple models or predictions to obtain a more robust and accurate prediction. By combining the strengths of multiple models, ensembles can effectively capture positive instances and enhance recall.
- Model Selection: Choosing a suitable machine learning algorithm can also impact recall performance. Different algorithms have varying capabilities in capturing positive instances. For example, decision trees tend to have higher recall but may suffer from overfitting. It is important to explore and compare different algorithms to identify the one that best suits the specific requirements and goals of the application.
- Model Tuning: Hyperparameter tuning plays a crucial role in improving recall. Fine-tuning parameters such as regularization strength, learning rate, or tree depth can fine-tune the model’s ability to capture positive instances. Techniques like grid search or Bayesian optimization can help systematically search for the optimal hyperparameters and improve recall performance.
Implementing a combination of these strategies, tailored to the specific problem and dataset, can significantly enhance recall performance. However, it is important to note that improving recall often comes with a trade-off. Increasing recall may lead to a decrease in precision or other performance metrics. Therefore, it is essential to strike a balance between recall and other metrics based on the specific requirements of the application.
By applying these strategies and continually iterating and evaluating the model’s performance, data scientists can enhance recall and build powerful machine learning models that effectively identify positive instances in real-world scenarios.
Conclusion
Recall is a crucial performance metric in machine learning that measures the ability of a model to correctly identify positive instances. It focuses on minimizing false negatives, which can have significant consequences in various real-world applications. By understanding and optimizing recall, data scientists and machine learning practitioners can develop models that effectively capture positive instances and minimize the risks associated with false negatives.
In this article, we explored the definition of recall and why it holds importance in machine learning. We learned how to calculate recall using true positives and false negatives and discussed the interpretation of recall results. Additionally, we identified key factors that can influence recall and strategies to improve its performance.
Factors such as data quality, imbalanced datasets, feature selection, model complexity, threshold setting, and model selection play instrumental roles in recall performance. Employing strategies like data augmentation, feature engineering, threshold adjustment, ensemble methods, and model tuning can significantly enhance recall.
It is essential to consider recall alongside other performance metrics like precision, accuracy, and the F1 score to gain a comprehensive understanding of a model’s performance. Therefore, a balanced evaluation of multiple metrics is crucial to assess the effectiveness and suitability of a machine learning model for a specific application.
By continually exploring techniques to improve recall and iterating on model development, data scientists can build robust and reliable models that accurately capture positive instances, making them invaluable assets in various domains such as healthcare, finance, and security.