Introduction
Welcome to the world of machine learning in data science! In today’s data-driven society, machine learning has emerged as a powerful tool that can uncover valuable insights hidden within massive amounts of data. By utilizing sophisticated algorithms and statistical techniques, machine learning enables computers to learn from data and make predictions or decisions without being explicitly programmed.
The concept of machine learning may sound complex, but its applications are prevalent in various industries, from finance and healthcare to marketing and entertainment. This technology has revolutionized the way businesses operate, enabling them to leverage the power of data to drive informed decisions, optimize processes, and ultimately achieve competitive advantages.
At its core, machine learning focuses on developing computer models that can learn and improve from experience. These models are trained to identify patterns or relationships within a dataset, allowing them to make accurate predictions or provide valuable insights. This iterative learning process enables machines to adapt and improve their performance over time, leading to more accurate and efficient results.
Machine learning encompasses a wide range of algorithms and techniques, each tailored to specific types of problems and data scenarios. Some algorithms fall under supervised learning, where the machine is trained with labeled examples and guided by a target variable. Others belong to unsupervised learning, which explores patterns and structures within the data without any predefined targets. Additionally, reinforcement learning focuses on training agents to interact with an environment and learn from feedback.
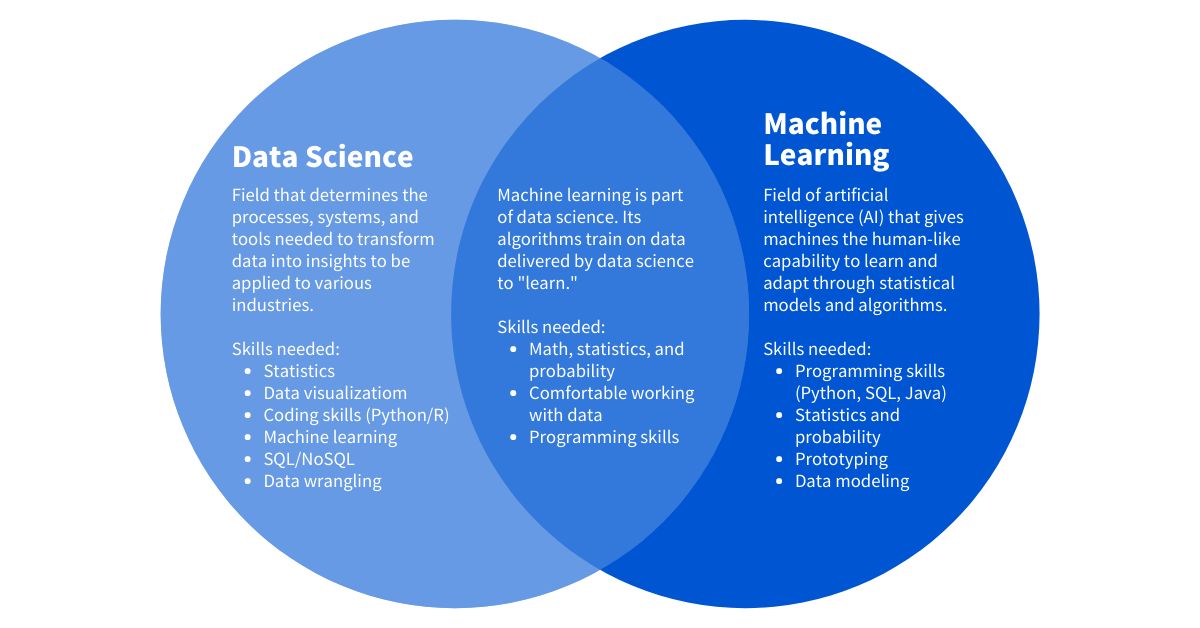
It is important to note that machine learning is not the same as artificial intelligence (AI), although they are closely related. AI refers to the broader concept of creating intelligent machines that can mimic human behavior, while machine learning is a subset of AI that focuses on enabling machines to learn and improve from data.
In the following sections, we will delve deeper into the various types of machine learning algorithms, the steps involved in the machine learning process, as well as the challenges and benefits of implementing machine learning in data science. So, let’s embark on this exciting journey into the world of machine learning!
Definition of Machine Learning
Machine learning is a subset of artificial intelligence that focuses on developing computer systems capable of learning and making predictions or decisions without being explicitly programmed. It involves the development of algorithms and statistical models that allow computers to analyze and interpret large volumes of data, identify patterns or relationships, and use this knowledge to make accurate predictions or take appropriate actions.
At its core, machine learning revolves around the idea that computers can learn and improve from experience. Instead of relying on explicit instructions, the machine learns by discovering patterns or insights from historical data, and then applies this knowledge to new, unseen data to make predictions or decisions. This ability to automatically learn and adapt is what sets machine learning apart from traditional programming approaches.
Machine learning algorithms can be broadly classified into three main types: supervised learning, unsupervised learning, and reinforcement learning.
Supervised Learning: In supervised learning, the machine is provided with a labeled dataset, where each data instance is associated with a target variable or outcome. The goal is to learn a function that can predict the target variable for future, unseen data. Common examples of supervised learning algorithms include regression and classification.
Unsupervised Learning: Unsupervised learning focuses on finding patterns or structures in a dataset without any predefined target variable. The machine is tasked with identifying inherent relationships or clusters within the data. Unsupervised learning algorithms include clustering and dimensionality reduction techniques.
Reinforcement Learning: Reinforcement learning involves training an agent to interact with an environment and learn from the feedback received. The agent learns by trial and error, receiving rewards or punishments based on its actions, and aims to maximize the cumulative reward over time. Reinforcement learning is often used in robotics and gaming applications.
In practice, machine learning algorithms utilize various mathematical and statistical techniques, such as linear regression, decision trees, support vector machines, neural networks, and deep learning, among others. These algorithms are implemented using programming languages such as Python or R, along with specialized libraries and frameworks designed for machine learning tasks.
Machine learning has the potential to revolutionize industries by providing data-driven insights, automating processes, and enabling intelligent decision-making. By leveraging the power of machine learning, businesses can gain a competitive edge, optimize operations, detect anomalies, personalize user experiences, and much more.
In the following sections, we will explore the different types of machine learning algorithms in more detail and discuss the steps involved in the machine learning process. So let’s dive deeper and uncover the inner workings of this fascinating field.
Applications of Machine Learning
Machine learning has emerged as a powerful tool with a wide range of applications across various industries. Its ability to analyze large volumes of data, identify patterns, and make accurate predictions or decisions has revolutionized numerous sectors. Let’s explore some of the key applications of machine learning:
1. Healthcare: Machine learning is transforming the healthcare industry by helping diagnose diseases, predict patient outcomes, and optimize treatment plans. Algorithms can analyze medical images and identify abnormalities, assist in drug discovery, and provide personalized medicine based on patient data and genetic profiles.
2. Finance: Machine learning is used in finance for fraud detection, credit scoring, algorithmic trading, and risk assessment. Algorithms can analyze large volumes of financial data to detect anomalies or suspicious activities, predict creditworthiness, and generate investment strategies based on market trends.
3. Marketing and Advertising: Machine learning enables targeted advertising by analyzing customer behavior, preferences, and demographics. Algorithms can segment customers based on their characteristics, predict their purchasing patterns, and optimize advertising campaigns to maximize conversions and ROI.
4. Natural Language Processing: Machine learning techniques, such as natural language processing (NLP), enable computers to understand and process human language. Applications include chatbots, virtual assistants, sentiment analysis, and language translation.
5. Recommendation Systems: Machine learning is used to build recommendation systems that suggest personalized products, movies, or content based on user preferences and behavior. These systems analyze historical data to predict user preferences and provide relevant recommendations.
6. Image and Speech Recognition: Machine learning algorithms can analyze patterns in images or audio to perform tasks such as image recognition, object detection, facial recognition, speech recognition, and transcription. These applications find use in areas like security, autonomous vehicles, and voice assistants.
7. Manufacturing and Industrial Processes: Machine learning is utilized in optimizing manufacturing processes and predicting equipment failures. By analyzing sensor data from machinery, algorithms can detect anomalies, predict maintenance needs, and improve overall efficiency and productivity.
8. Social Media and Customer Sentiment Analysis: Machine learning algorithms analyze social media data to understand trends, sentiments, and public opinions. This information can help businesses gain insights about their brand reputation, customer feedback, and market trends.
These are just a few examples of the wide-ranging applications of machine learning. As technology continues to advance, machine learning is expected to play an increasingly significant role in various industries, driving innovation, efficiency, and decision-making.
In the next sections, we will explore the different types of machine learning algorithms, the machine learning process, and the challenges and benefits of implementing machine learning in data science.
Types of Machine Learning Algorithms
Machine learning algorithms are categorized into several distinct types, each designed to handle specific types of problems and data scenarios. Understanding these types can provide insights into the capabilities and applications of machine learning. Let’s explore the three main types of machine learning algorithms:
1. Supervised Learning: This type of machine learning algorithm is based on labeled training data. It involves training the machine using input features and corresponding output labels, allowing it to learn the relationship between the two. Supervised learning algorithms are used for regression tasks when the output is continuous, and for classification tasks when the output is categorical. Examples of supervised learning algorithms include linear regression, decision trees, support vector machines (SVM), and random forests.
2. Unsupervised Learning: Unsupervised learning algorithms are used when the training data is unlabeled or lacks specific output labels. These algorithms seek to identify hidden patterns or structures within the data, such as clusters of similar data points. Unsupervised learning can be used for tasks such as data clustering, dimensionality reduction, and anomaly detection. Examples of unsupervised learning algorithms include k-means clustering, hierarchical clustering, principal component analysis (PCA), and Gaussian mixture models.
3. Reinforcement Learning: Reinforcement learning algorithms are based on the concept of learning through interaction with an environment. An agent interacts with the environment, takes actions, and receives feedback or rewards based on those actions. The goal of the agent is to learn a policy that maximizes the cumulative reward over time. Reinforcement learning is commonly used in robotics, game playing, and control systems. Examples of reinforcement learning algorithms include Q-learning, deep Q-networks (DQN), and policy gradient methods.
It’s important to note that these types of algorithms are not mutually exclusive, and often, a combination of supervised, unsupervised, and reinforcement learning techniques may be used in real-world machine learning applications.
Additionally, within each type of algorithm, there are various variations and specialized techniques that cater to specific data scenarios. For example, within supervised learning, there are algorithms like logistic regression for binary classification, support vector machines for classification with complex decision boundaries, and ensemble methods that combine multiple models for better predictions.
Understanding the different types of machine learning algorithms allows developers and data scientists to choose the most appropriate technique for their specific problem and datasets. By leveraging the power of these algorithms, businesses can solve complex problems, gain insights from data, and make accurate predictions or decisions.
In the following sections, we will explore the machine learning process, including the steps involved and the challenges and benefits associated with implementing machine learning in data science.
Supervised Learning
Supervised learning is a type of machine learning where the algorithm is trained on labeled data, meaning the input data is accompanied by corresponding output labels. The goal of supervised learning is to build a model that can accurately predict the output labels for new, unseen data. This type of machine learning is commonly used for regression tasks, where the output is continuous, and classification tasks, where the output is categorical.
In supervised learning, the training data consists of input features and their known output labels. The algorithm analyzes the relationship between the input features and output labels, and constructs a model that generalizes this relationship. When presented with new data, the trained model can make predictions or classifications based on its learned knowledge.
Regression is a form of supervised learning where the goal is to predict a continuous output variable. For example, predicting housing prices based on features like square footage, number of rooms, and location. Regression algorithms, such as linear regression and decision trees, learn a function that maps the input features to the output variable.
In classification, the goal is to predict a categorical output variable. For instance, classifying emails as spam or not spam based on their content or classifying images as a dog, cat, or bird. Classification algorithms, like logistic regression, decision trees, support vector machines (SVM), and random forests, learn to separate the input features into distinct classes.
Supervised learning algorithms learn from the training data by minimizing a predefined error metric, such as mean squared error for regression or cross-entropy loss for classification. They iteratively adjust their internal parameters to minimize the error between the predicted outputs and the actual labels. This training process ensures that the model can make accurate predictions on new, unseen data.
The success of supervised learning depends heavily on the quality and representativeness of the labeled training data. It is crucial to have a diverse and well-labeled dataset to train the model effectively. Feature engineering, which involves selecting and transforming relevant input features, also plays a vital role in improving the performance of supervised learning models.
Supervised learning finds applications in various domains, including but not limited to finance, healthcare, marketing, and image recognition. Its ability to make predictions based on labeled data enables businesses to automate tasks, make data-driven decisions, and gain valuable insights.
In the subsequent sections, we will explore other types of machine learning algorithms, including unsupervised learning and reinforcement learning. By understanding the different types of machine learning, we can expand our toolkit for solving complex problems and extracting valuable information from data.
Unsupervised Learning
Unsupervised learning is a type of machine learning where the algorithm is trained on unlabeled data. Unlike supervised learning, there are no predefined output labels associated with the input data. The objective of unsupervised learning is to discover patterns, structures, or relationships in the data without any prior knowledge or guidance.
In unsupervised learning, the algorithm analyzes the input data and identifies inherent patterns or similarities. This can involve discovering clusters of similar data points, identifying hidden structures, or reducing the dimensionality of the data. Unsupervised learning is commonly used in exploratory data analysis and for tasks where the goal is to gain insights from unstructured or unlabeled data.
Clustering is a popular application of unsupervised learning. Clustering algorithms group similar data points together based on their feature similarity. This helps in discovering meaningful segments or clusters within the data. Examples of clustering algorithms include k-means clustering, hierarchical clustering, and DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
Dimensionality reduction is another important aspect of unsupervised learning. When dealing with high-dimensional data, it can be challenging to visualize or analyze the data. Dimensionality reduction techniques aim to reduce the number of features while preserving as much information as possible. Principal Component Analysis (PCA) and t-SNE (t-Distributed Stochastic Neighbor Embedding) are commonly used algorithms for dimensionality reduction.
Anomaly detection is also a typical application of unsupervised learning. By learning patterns from normal instances, the algorithm can identify data points that deviate significantly from the norm. This is useful for detecting fraud in financial transactions, identifying faulty equipment in manufacturing processes, or detecting anomalies in network traffic.
Unsupervised learning algorithms learn by finding intrinsic patterns or structures within the data. This can be done through iterative processes that aim to minimize a certain metric, such as minimizing the distance between data points within the same cluster or maximizing the separation between clusters. The specific algorithm used depends on the characteristics of the dataset and the objective of the analysis.
Unsupervised learning has wide applications in diverse fields, including customer segmentation, recommender systems, image recognition, and anomaly detection. By exploring and understanding the patterns within the data, businesses can gain valuable insights, make informed decisions, and optimize processes.
In the next section, we will delve into reinforcement learning, another type of machine learning that involves training agents to interact with environments and learn from feedback. Understanding the different types of machine learning algorithms expands our toolkit for solving real-world problems and extracting knowledge from data.
Reinforcement Learning
Reinforcement learning is a type of machine learning where an agent learns to interact with an environment and improve its performance through trial and error. It involves training the agent to take certain actions in a given state based on feedback received in the form of rewards or punishments. Reinforcement learning is inspired by the principles of behavioral psychology and aims to develop intelligent decision-making agents.
In reinforcement learning, the agent takes actions in an environment to maximize a cumulative reward signal over time. The agent interacts with the environment by observing the current state, taking an action, and receiving feedback in the form of a reward or punishment. The agent’s objective is to learn a policy, which is a mapping of states to actions, that maximizes the expected long-term reward.
The process of reinforcement learning involves several elements:
- Agent: The decision-making entity that observes the environment, takes actions, and learns from feedback.
- Environment: The external system or problem that the agent interacts with.
- State: The current representation of the environment, which is used by the agent to make decisions.
- Action: The action taken by the agent in response to a given state.
- Reward: The feedback signal received by the agent after taking an action in a given state. The goal is to maximize the cumulative reward.
Reinforcement learning algorithms use the concept of exploration and exploitation to learn the optimal policy. Initially, the agent explores different actions to gather information about the environment. As it learns and gathers feedback, the agent starts exploiting the knowledge it has gained to make informed decisions and maximize the expected reward.
Key reinforcement learning algorithms include Q-learning, where the agent learns action values based on the expected cumulative rewards, and policy gradient methods, where the agent directly learns a policy that maximizes the expected reward. Deep reinforcement learning combines reinforcement learning with deep neural networks, enabling agents to handle high-dimensional data, such as images, and learn complex strategies.
Reinforcement learning finds applications in various domains, including robotics, game playing, autonomous vehicles, and control systems. It allows agents to learn from experience, adapt to changing environments, and make intelligent decisions even in complex and dynamic scenarios.
By simulating environments and allowing agents to learn through trial and error, reinforcement learning provides a powerful framework for developing autonomous systems capable of continuous learning and improvement.
In the subsequent sections, we will explore the differences between machine learning and artificial intelligence, as well as the steps involved in the machine learning process. Understanding these concepts broadens our understanding of the field of machine learning and its practical applications.
Difference Between Machine Learning and Artificial Intelligence
Machine learning and artificial intelligence (AI) are closely related concepts often used interchangeably. However, they represent distinct but interconnected fields within computer science. Let’s explore the difference between machine learning and artificial intelligence:
Machine Learning: Machine learning is a subset of artificial intelligence that focuses on the development of algorithms and techniques that enable computers to learn and improve from experience, without being explicitly programmed. It revolves around the idea that machines can automatically learn from data, identify patterns, and make predictions or decisions based on that knowledge. Machine learning algorithms are designed to analyze and interpret data, discover insights, and improve their performance over time. It encompasses supervised learning, unsupervised learning, and reinforcement learning.
Artificial Intelligence: Artificial Intelligence, on the other hand, is a broader concept that encompasses the development of intelligent systems that can perform tasks that typically require human intelligence. AI aims to create machines that can mimic human cognitive abilities, such as understanding language, solving problems, and making decisions. It includes various subfields, including machine learning, natural language processing, computer vision, robotics, and expert systems. AI systems can exhibit “intelligence” by analyzing data, reasoning, learning from experience, and adapting to new situations.
While machine learning is a fundamental part of AI, not all AI systems rely on machine learning. AI can incorporate techniques such as rule-based systems, expert systems, and symbolic reasoning, which do not involve learning from data. Machine learning, on the other hand, focuses specifically on algorithms and models that learn from data and improve their performance through experience.
In essence, machine learning is a subset of AI that provides the tools and techniques to enable computers to learn and make predictions or decisions from data. AI, on the other hand, encompasses a broader range of concepts and methodologies to create intelligent systems capable of performing human-like tasks.
Both machine learning and AI have significant real-world applications. Machine learning algorithms have revolutionized various industries, from healthcare and finance to marketing and autonomous vehicles. AI systems have transformed areas such as natural language processing, robotics, virtual assistants, and computer vision.
Understanding the difference between machine learning and artificial intelligence provides clarity on the specific goals and techniques employed in each field. By combining the strengths of machine learning and AI, researchers and practitioners can develop intelligent systems that solve complex problems, learn from data, and interact with the world in a human-like manner.
The Machine Learning Process
The machine learning process is a systematic approach that involves several steps to develop, train, evaluate, and deploy machine learning models. This process guides researchers and data scientists in building effective and accurate models that can make predictions or decisions based on data. Let’s explore the key steps involved in the machine learning process:
1. Define the Problem: The first step is to clearly define the problem you want to solve with machine learning. This involves determining the task at hand, the desired outcome, and the input data needed to train the model.
2. Gather and Preprocess Data: Next, you need to collect and preprocess the data required for training the machine learning model. This involves gathering relevant data from various sources, cleaning the data by handling missing values and outliers, and transforming the data into a suitable format for machine learning algorithms.
3. Data Exploration and Feature Engineering: Once the data is preprocessed, it’s essential to explore the data to gain insights and perform feature engineering. This includes analyzing the data’s statistical properties, visualizing relationships between variables, and engineering new features that may improve the model’s performance.
4. Split the Data: The next step is to split the dataset into training and testing subsets. The training set is used to train the model, while the testing set is used to evaluate the model’s performance on unseen data. This helps assess how well the model generalizes to new data.
5. Select a Machine Learning Algorithm: Based on the problem, data, and desired outcome, you need to select an appropriate machine learning algorithm. This could be a supervised learning algorithm for regression or classification, an unsupervised learning algorithm for clustering or dimensionality reduction, or a reinforcement learning algorithm for sequential decision-making tasks.
6. Train the Model: In this step, the selected machine learning algorithm is applied to the training data to learn patterns and make predictions or decisions. The model’s parameters are adjusted iteratively to minimize the error or maximize a specified performance metric using optimization techniques.
7. Evaluate and Fine-tune the Model: Once the model is trained, it needs to be evaluated on the testing data to assess its performance. Metrics such as accuracy, precision, recall, and F1 score are used to evaluate the model’s predictions. If the model’s performance is unsatisfactory, it may be necessary to fine-tune the model by adjusting hyperparameters or exploring different algorithms.
8. Deploy and Monitor the Model: After fine-tuning the model, it can be deployed in real-world applications to make predictions or decisions. It is crucial to monitor the model’s performance and update it periodically to ensure its accuracy and reliability. Ongoing monitoring helps identify any degradation in performance or changes in the data distribution that may require model retraining.
The machine learning process is iterative, and steps like feature engineering, model selection, and hyperparameter tuning may need to be revisited multiple times to improve the model’s performance. Continuous learning, refinement, and adaptation are key to developing effective machine learning models.
By following a standardized and well-defined machine learning process, organizations can harness the power of data to build accurate and reliable models that can provide valuable insights and drive informed decision-making.
Steps in Machine Learning
Machine learning involves a series of steps that guide the development and deployment of machine learning models. These steps provide a systematic approach to solving problems using data and implementing predictive or decision-making systems. Let’s explore the key steps in the machine learning process:
1. Define the Problem: The first step is to clearly define the problem or task that you want to solve using machine learning. This includes identifying the objective, specifying the desired outcome, and understanding the requirements and constraints of the problem.
2. Gather and Preprocess Data: The next step is to collect and preprocess the data needed for training the machine learning model. This involves gathering relevant data from various sources, handling missing values, outliers, and noisy data, and transforming the data into a suitable format for analysis.
3. Explore and Analyze the Data: Once the data is preprocessed, it’s important to explore and analyze the data to gain insights and understand its characteristics. This includes performing descriptive statistics, data visualization, and identifying patterns, trends, or relationships within the data.
4. Feature Engineering: Feature engineering involves selecting or creating relevant features from the available data to improve the model’s performance. This includes transforming variables, creating new features, or encoding categorical variables to represent the data effectively for the machine learning algorithms.
5. Split the Data: After feature engineering, the next step is to split the data into training and testing sets. The training set is used to train the model, while the testing set is used to evaluate its performance on unseen data. Typically, the data is split into a training set (70-80%) and a testing/validation set (20-30%).
6. Select and Train the Model: Based on the problem and data, select an appropriate machine learning algorithm or ensemble of algorithms. This involves training the model using the training data and adjusting the algorithm’s parameters to fit the data. The model learns patterns, relationships, or rules from the training data to make predictions or decisions.
7. Evaluate the Model: Once the model is trained, it is important to evaluate its performance on the testing/validation data. This is done by calculating various metrics such as accuracy, precision, recall, or mean squared error, depending on the problem type. Evaluating the model helps assess its generalization ability and identify potential overfitting or underfitting issues.
8. Fine-tune and Optimize the Model: If the model’s performance is not satisfactory, it may be necessary to fine-tune and optimize the model. This involves adjusting hyperparameters, such as learning rate, regularization, or number of hidden layers, and exploring different algorithms or techniques to improve the model’s performance.
9. Deploy and Monitor the Model: Once the model has been fine-tuned, it can be deployed in real-world applications to make predictions or decisions. It is important to monitor the model’s performance over time, gather feedback from users or stakeholders, and update the model if necessary to ensure it remains accurate and reliable.
Machine learning is an iterative process, with steps like data preprocessing, feature engineering, and model optimization often requiring repeated iterations to achieve the desired outcomes. Continuous learning and improvement are essential to developing robust and effective machine learning models.
By following these steps, organizations can leverage the power of machine learning to extract valuable insights from data, automate processes, and make informed decisions.
Challenges in Machine Learning
Machine learning offers tremendous potential for solving complex problems and gaining insights from data. However, it also comes with several challenges that data scientists, researchers, and practitioners must address. Let’s explore some of the key challenges in machine learning:
1. Data Quality and Quantity: Machine learning models heavily rely on high-quality and representative data. Often, data may be incomplete, contain errors or outliers, or be biased, leading to inaccurate or biased models. Insufficient or unbalanced data can also hinder model performance and generalization.
2. Feature Selection and Engineering: Identifying the most relevant features from the available data and engineering informative features can be a challenging task. Choosing the right features and ensuring they adequately represent the underlying patterns in the data can greatly impact the model’s performance.
3. Overfitting and Underfitting: Overfitting occurs when a model learns too much from the training data and fails to generalize well to unseen data. Underfitting, on the other hand, happens when a model is too simple to capture the underlying patterns in the data. Balancing the complexity of the model and preventing overfitting or underfitting is a challenge in machine learning.
4. Model Selection and Hyperparameter Tuning: Choosing the most appropriate model and its associated hyperparameters can be a daunting task. Different models have distinct strengths and weaknesses for different types of data and problems. Additionally, tuning hyperparameters to achieve the optimal model performance is a time-consuming and iterative process.
5. Computational Resources: Training and deploying machine learning models often require significant computational resources, such as high-performance processors or GPUs. Handling large datasets and complex models can be computationally intensive and may require efficient infrastructure to achieve acceptable training times.
6. Interpretability and Explainability: Many machine learning models, such as deep neural networks, are considered black boxes, making it difficult to interpret or understand their decision-making process. Ensuring transparency and interpretability is crucial, especially in sensitive applications such as healthcare or finance.
7. Ethical and Bias Issues: Machine learning models can inadvertently perpetuate biases present in the data used for training. Careful consideration must be given to address ethical concerns and ensure fairness, transparency, and accountability in machine learning algorithms and their applications.
8. Continuous Learning and Adaptation: As new data becomes available or new scenarios arise, machine learning models may need to adapt and improve their performance over time. Implementing systems that can continuously update and retrain models to incorporate new information is a challenge.
Overcoming these challenges requires a combination of expertise in data preprocessing, feature engineering, model selection, and optimization. It is important for data scientists and practitioners to stay up-to-date with the latest advancements in machine learning techniques and adopt best practices to mitigate these challenges.
By addressing these challenges, the full potential of machine learning can be harnessed to drive innovation, enhance decision-making, and solve complex problems in various domains.
Benefits of Machine Learning
Machine learning has revolutionized industries and transformed the way businesses operate. It offers a range of benefits that empower organizations to leverage the power of data and make informed decisions. Let’s explore some of the key benefits of machine learning:
1. Accurate Predictions and Decisions: Machine learning algorithms can analyze vast amounts of data, detect patterns, and make accurate predictions or decisions. By leveraging historical data, machine learning models can identify trends, recognize anomalies, and provide insights that aid in making informed decisions.
2. Automation and Efficiency: Machine learning helps streamline processes by automating complex tasks. From data preprocessing to model training, machine learning algorithms reduce the manual effort required, saving time and resources. Automation leads to increased efficiency, enabling businesses to focus on higher-value tasks and improve productivity.
3. Personalization and Improved Customer Experience: Machine learning enables personalized experiences by analyzing customer data and behavior patterns. By understanding individual preferences and needs, businesses can provide tailored recommendations, personalized marketing offers, and customized user experiences. This enhances customer satisfaction and loyalty.
4. Fraud Detection and Risk Management: Machine learning algorithms aid in detecting fraudulent activities, such as credit card fraud, identity theft, or abnormal financial transactions. By analyzing historical data and detecting patterns of fraudulent behavior, machine learning models can identify potential risks proactively and help mitigate them.
5. Improved Healthcare Outcomes: Machine learning has the potential to revolutionize healthcare by enabling early diagnosis, predicting disease progression, and personalizing treatment plans. By analyzing medical records, genetic data, and patient information, machine learning algorithms can assist in diagnosing diseases, predicting patient outcomes, and improving healthcare delivery.
6. Cost Reduction and Resource Optimization: Machine learning can help businesses optimize resource allocation and reduce costs. For example, predictive maintenance algorithms can identify equipment failures before they occur, preventing costly breakdowns. Supply chain optimization models can minimize costs and improve inventory management.
7. Enhanced Decision-Making Speed: Machine learning enables faster decision-making by automating data analysis and providing real-time insights. This allows businesses to respond quickly to market changes, customer demands, and emerging opportunities, gaining a competitive edge in fast-paced environments.
8. Exploration of Complex Data Relationships: Machine learning algorithms can uncover complex relationships and patterns within large and high-dimensional datasets. This helps businesses gain deeper insights into customer behavior, market trends, and other intricate data associations that may not be apparent using traditional analysis methods.
These are just a few of the many benefits that machine learning offers. From improved decision-making and enhanced customer experiences to cost reduction and resource optimization, machine learning empowers businesses to unlock valuable insights, capitalize on opportunities, and drive innovation in a data-driven world.
By harnessing the power of machine learning techniques, organizations can gain a competitive advantage and stay at the forefront of their respective industries.
Conclusion
Machine learning has truly revolutionized the way we approach problem-solving and decision-making in various industries. Its ability to analyze data, uncover patterns, and make accurate predictions or decisions has opened up new possibilities and opportunities for businesses and individuals alike.
Throughout this article, we explored the fundamentals of machine learning, including its definition, applications, types of algorithms, and the process involved in building and deploying machine learning models. From supervised learning to unsupervised learning and reinforcement learning, each type of algorithm offers unique capabilities for solving different types of problems and gaining insights from data.
We discussed the challenges that come with machine learning, such as data quality, feature engineering, model selection, and interpretability. These challenges require thoughtful consideration and continuous learning to overcome and ensure the development of robust and reliable models.
Despite the challenges, the benefits of machine learning are significant. Accurate predictions and decisions, automation and efficiency, personalized experiences, fraud detection, healthcare improvements, cost reduction, and enhanced decision-making speed are just a few examples of the transformative potential of machine learning.
As technology continues to advance and more data becomes available, the field of machine learning will undoubtedly continue to evolve and shape our present and future. It is an exciting time to be a part of this journey and harness the power of machine learning to drive innovation, solve complex problems, and uncover valuable insights.
Whether in healthcare, finance, marketing, or any other domain, machine learning has the power to create a positive impact, improve processes, and empower decision-makers with data-driven insights. By embracing machine learning techniques and approaches, organizations can gain a competitive edge and make significant strides towards success.
In conclusion, machine learning is a transformative field that holds vast potential for solving complex problems, making accurate predictions, and driving decision-making. By understanding the fundamentals, embracing the challenges, and leveraging the benefits of machine learning, we can unlock a world of possibilities and pave the way for a future where intelligent systems help us navigate and thrive in an increasingly data-driven world.