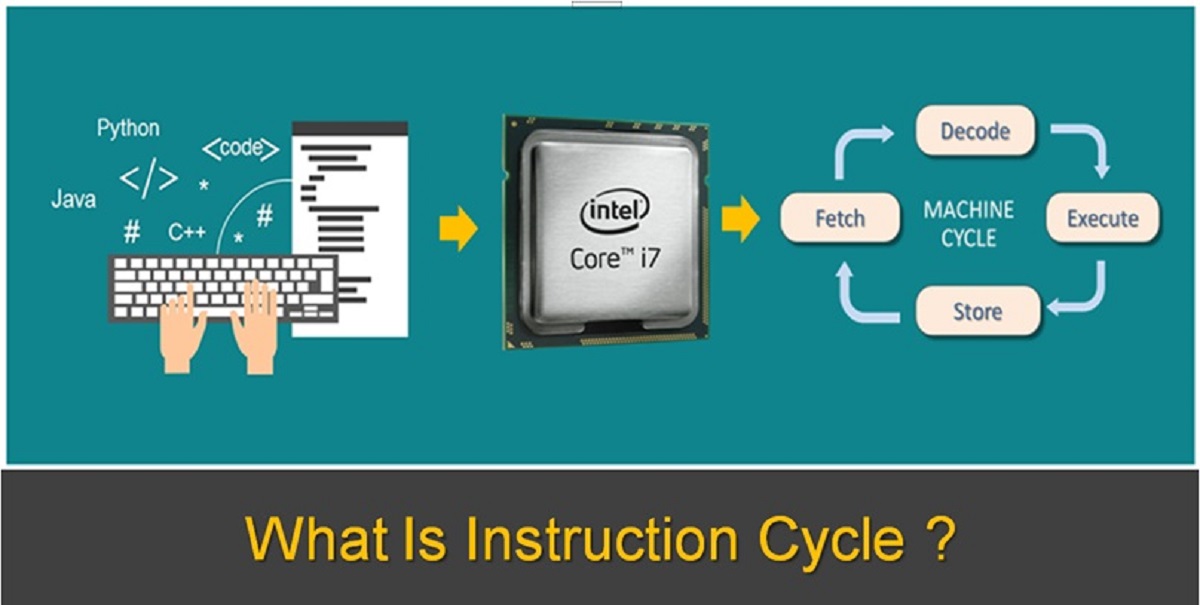
Introduction
Welcome to the world of cache memory! In the realm of computer systems, where speed and efficiency reign supreme, cache memory plays a crucial role in enhancing the performance of the Central Processing Unit (CPU). It acts as a bridge between the blazing-fast CPU and the relatively slower main memory, enabling the CPU to access frequently used instructions or data swiftly.
Imagine you are working on a complex task, and you need to retrieve information from the main memory repeatedly. Accessing the main memory is relatively slower compared to the CPU’s processing speed. This is where cache memory comes into play, serving as a high-speed buffer between the CPU and the main memory. It stores copies of frequently accessed instructions or data, allowing the CPU to retrieve them quickly and reduce the time needed for processing.
Cache memory is like a well-organized library, where the heavily used books are placed on the shelves nearest to the reading area. Similarly, cache memory keeps the most frequently accessed instructions or data close to the CPU, eliminating the need for the CPU to retrieve them from the main memory every time.
By utilizing cache memory, the CPU can significantly reduce the time spent waiting for data from the main memory. It’s like having all your essential tools within arm’s reach, rather than having to walk to a distant storage area to fetch them every time you need them.
In this article, we will explore the different types of cache memory, delve into how cache memory works, examine the various caching algorithms employed, and discuss the many benefits and limitations of this invaluable component in modern computer systems.
So, fasten your seatbelts as we embark on an exciting journey through the inner workings of cache memory!
Cache Memory
Cache memory, often referred to simply as “cache,” is a small, high-speed memory component that stores frequently used instructions or data needed by the CPU. It acts as a temporary storage space, bridging the speed gap between the CPU and the main memory. The primary purpose of cache memory is to improve the overall performance of the computer system by reducing the time required for data access.
Cache memory operates on the principle of locality of reference. This principle states that programs tend to access a relatively small portion of instructions or data repeatedly, and cache memory exploits this behavior by storing these frequently accessed items. Whenever the CPU requires data, it first checks the cache to see if the data is already present. If it is, the CPU can retrieve the data much faster from the cache compared to the main memory. This results in reduced latency and improved overall system performance.
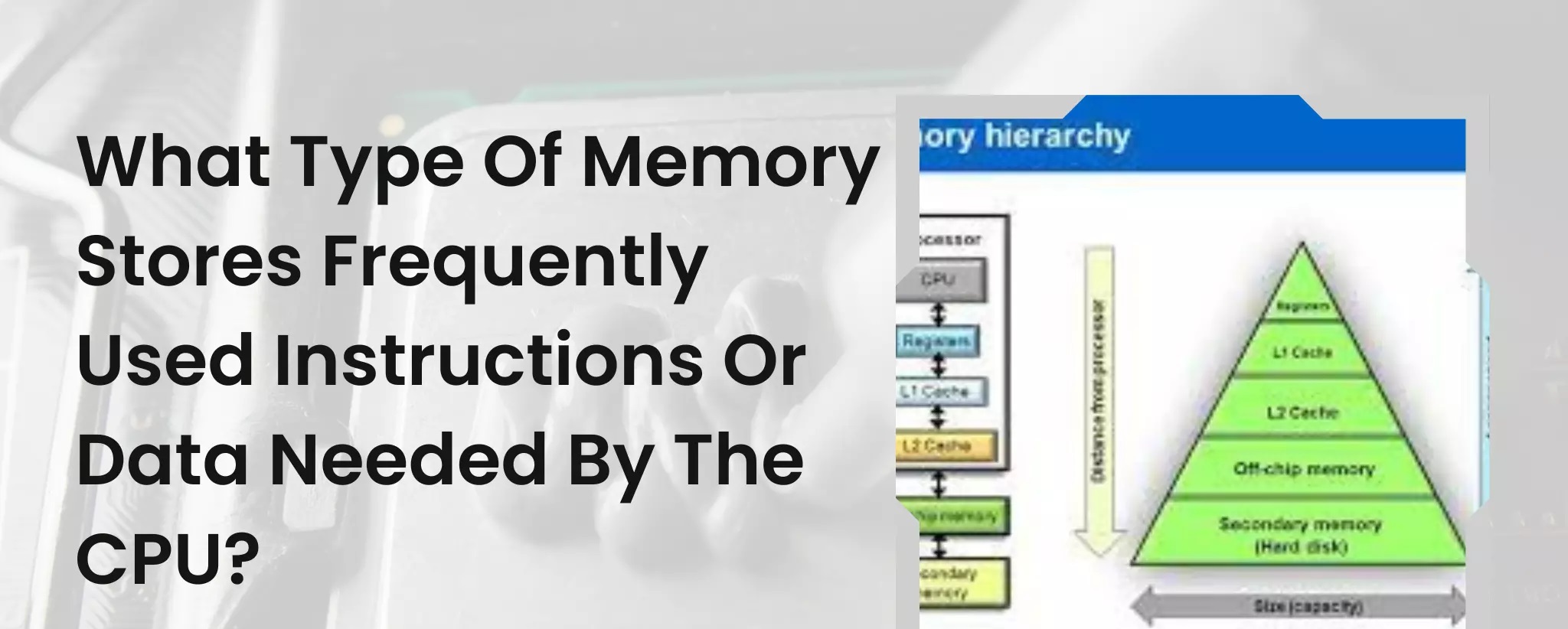
Cache memory is organized into different levels, typically denoted as L1, L2, and L3. These levels form a hierarchy, with L1 being the closest and fastest to the CPU and L3 being the farthest and relatively slower.
The L1 cache, also known as the primary cache, is the smallest but fastest cache level. It is usually directly integrated into the CPU and provides the quickest data access. L1 cache stores frequently used instructions and data that the CPU needs immediately.
The L2 cache, also referred to as the secondary cache, is larger than L1 cache and is located between the CPU and the main memory. It retains a greater amount of frequently accessed data and instructions, allowing for improved performance compared to accessing the main memory.
The L3 cache, or the last-level cache, is the largest cache level and is shared among multiple processor cores. It acts as a shared resource, enabling efficient data sharing between the cores and reducing the need to access the main memory.
The size, speed, and organization of cache memory can vary based on the architecture and design of a computer system. The goal is to strike a balance between cost, power consumption, and performance.
In the next sections, we will dive deeper into how cache memory works, explore different caching algorithms, and discuss the various benefits and limitations associated with cache memory.
Types of Cache Memory
Cache memory can be classified into different types based on its placement and accessibility within a computer system. Let’s take a closer look at the three main types of cache memory: L1 cache, L2 cache, and L3 cache.
L1 Cache: The L1 cache, also known as the primary cache, is the closest and fastest cache level to the CPU. It is integrated directly into the CPU chip and operates at the same clock speed. L1 cache is further divided into two subcategories: instruction cache (L1i) and data cache (L1d). The instruction cache stores frequently used instructions, while the data cache stores frequently accessed data. Due to its close proximity to the CPU, L1 cache offers extremely low latency, enabling rapid data retrieval.
L2 Cache: The L2 cache, also referred to as the secondary cache, is located between the L1 cache and the main memory. It is typically larger in size compared to the L1 cache and operates at a slightly slower speed. The L2 cache stores additional copies of frequently accessed instructions and data, providing a larger storage capacity compared to the L1 cache. In multi-core processors, each core may have its dedicated L1 and L2 caches, while a shared L3 cache is employed for efficient data sharing.
L3 Cache: The L3 cache, also known as the last-level cache, is the largest cache level and is shared among multiple processor cores in a multi-core system. It acts as a shared resource, facilitating data sharing between different cores and reducing the need to access the main memory. Since the L3 cache is shared across multiple cores, it offers higher storage capacity but may have slightly higher latency compared to the L1 and L2 caches.
The configuration and size of cache memory can vary based on the specific computer architecture and the intended application. Some computer systems may have multiple levels of cache memory, while others may have only one or two levels.
It’s important to note that cache memory is implemented using Static Random Access Memory (SRAM) technology, which allows for faster access times compared to the dynamic random access memory (DRAM) used in main memory. SRAM retains data without refreshing, which contributes to its higher performance but also makes it more expensive to produce.
Now that we have a better understanding of the types of cache memory, let’s delve into how cache memory works and the algorithms involved in optimizing its performance.
L1 Cache
The L1 cache, also known as the primary cache, is the first level of cache memory within a computer system. It is directly integrated into the CPU chip, making it the closest and fastest cache level to the CPU. L1 cache is further divided into two subcategories: instruction cache (L1i) and data cache (L1d).
The primary function of the L1 cache is to store frequently used instructions and data that the CPU needs immediately. By keeping these frequently accessed items in a cache that is located near the CPU, the latency of accessing the instructions and data is significantly reduced, resulting in accelerated processing times.
The L1 instruction cache (L1i) stores copies of instructions that the CPU fetches from the main memory. When the CPU needs to execute a particular instruction, it first checks the L1 instruction cache. If the required instruction is found in the cache, the CPU can retrieve it quickly, avoiding the slower process of accessing the main memory. This reduces the processing time and improves overall system performance.
On the other hand, the L1 data cache (L1d) is responsible for storing frequently accessed data. Whenever the CPU requires data for processing, it checks the L1 data cache to see if the data is already present. If the data is found in the cache, it can be retrieved swiftly. If the data is not present in the L1 data cache, the CPU then seeks it from the main memory. The L1 data cache works hand in hand with the L1 instruction cache to provide speedy data access for efficient processing.
The size of the L1 cache is relatively smaller compared to higher-level caches, but its proximity to the CPU allows for extremely low latency. L1 cache is implemented using Static Random Access Memory (SRAM) technology, which offers faster access times compared to the Dynamic Random Access Memory (DRAM) used in main memory.
It’s important to note that each core in a multi-core processor has its dedicated L1 cache. This means that if a processor has multiple cores, each core has its separate L1 instruction cache and L1 data cache. This design enhances parallel processing capabilities and minimizes the need for data sharing between cores at the L1 cache level.
The L1 cache plays a vital role in improving the overall performance of the CPU by reducing the time required for data access. Its proximity and fast access times make it an efficient storage component, ensuring that frequently used instructions and data are readily available for the CPU’s processing needs.
In the next section, we will explore the L2 cache, the second level of cache memory, and its significance in the computer system’s performance.
L2 Cache
The L2 cache, also known as the secondary cache, is the second level of cache memory in a computer system. It is situated between the L1 cache and the main memory, acting as a bridge between the two. The L2 cache is designed to store additional copies of frequently accessed instructions and data, providing a larger storage capacity compared to the L1 cache.
As the L1 cache may not have enough storage capacity to hold all the frequently accessed instructions and data, the L2 cache comes into play to further enhance performance. It allows the CPU to access a greater pool of frequently used information without having to rely solely on the main memory, which can be slower to access.
One key difference between the L2 cache and the L1 cache is that the L2 cache operates at a slightly slower speed than the L1 cache. This difference in speed is primarily due to the increased size of the L2 cache, making it more challenging to maintain the same level of speed as the smaller and more localized L1 cache.
Multi-core processors usually have a shared L2 cache among the cores. In this configuration, all the processor cores in the system have access to the same L2 cache. This shared nature allows for efficient data sharing between the processor cores, reducing the dependency on accessing the main memory. It also promotes faster communication and synchronization between the cores, resulting in improved performance in multi-threaded applications.
Similar to the L1 cache, the L2 cache is implemented with Static Random Access Memory (SRAM) technology. While it may have slightly higher access times compared to the L1 cache, the L2 cache still offers considerably lower latency compared to the main memory.
The size of the L2 cache can vary depending on the specific computer system and architecture. Generally, L2 caches are larger than L1 caches, providing more storage capacity to accommodate a greater volume of frequently accessed instructions and data. The size of the L2 cache, along with its latency and speed considerations, are carefully balanced to achieve optimal performance without significantly increasing manufacturing costs.
By utilizing the L2 cache, the CPU can minimize the need to access the main memory for frequently used instructions and data. This results in reduced latency and improved overall system performance. The L2 cache acts as a crucial intermediary between the fast L1 cache and the slower main memory, bridging the speed gap and facilitating swift data access for the CPU.
In the following section, we will explore the L3 cache, the last level of cache memory, and its role in further optimizing system performance.
L3 Cache
The L3 cache, also known as the last-level cache, is the final level of cache memory in modern computer systems. It is typically larger in size compared to the L1 and L2 caches and is shared among multiple processor cores in a multi-core system. The L3 cache serves as a shared resource, enabling efficient data sharing and reducing the need to access the main memory.
The primary purpose of the L3 cache is to facilitate faster data access and communication between the processor cores in a multi-core system. As each core has its dedicated L1 and L2 caches, the L3 cache acts as a centralized cache that allows for inter-core data sharing. It stores copies of frequently accessed instructions and data that multiple cores may need, promoting data coherence and reducing the frequency of accessing the main memory.
Having a shared L3 cache provides several advantages. First, it allows for faster communication and synchronization between cores, which is essential for multi-threaded applications that require efficient sharing of data and resources. Second, it minimizes the potential for cache thrashing, where multiple cores constantly compete for limited cache resources. With a larger shared cache, the likelihood of cache thrashing is reduced, resulting in more efficient utilization of cache resources.
Similar to the L1 and L2 caches, the L3 cache is constructed using Static Random Access Memory (SRAM) technology. While its access times may be slightly higher compared to the smaller and faster L1/L2 caches, the L3 cache still offers significantly lower latency compared to the main memory. This makes it a valuable component for improving overall system performance.
The size of the L3 cache varies depending on the specific computer system architecture and design. It is typically larger than both the L1 and L2 caches to accommodate the data sharing needs of multiple cores. The size of the L3 cache, along with the associated latency and speed considerations, are carefully balanced to optimize performance and cost-effectiveness.
Overall, the L3 cache plays a crucial role in enhancing the performance of multi-core systems. It acts as a shared resource, facilitating data sharing and reducing the need to access the main memory. By reducing data access latency and promoting efficient inter-core communication, the L3 cache contributes to improved system performance in a multi-core environment.
In the next section, we will uncover how cache memory works and the various caching algorithms employed to optimize its performance.
How Cache Memory Works
To understand how cache memory works, let’s consider a scenario where a computer system needs to retrieve data for processing. When the CPU requires data or instructions, it first checks the cache memory before accessing the main memory. This process involves two possible outcomes: cache hit and cache miss.
In a cache hit scenario, the CPU finds the required data or instructions in the cache memory. This means that the data is already present in the cache, and the CPU can quickly retrieve it without the need to access the slower main memory. A cache hit results in significantly reduced latency, allowing for faster processing and improved performance.
On the other hand, in a cache miss scenario, the CPU cannot find the required data or instructions in the cache memory. This indicates that the data is not currently stored in the cache, and the CPU must retrieve it from the main memory. A cache miss has higher latency compared to a cache hit since it involves accessing the slower main memory. However, when the data is fetched from the main memory, it is also stored in the cache for future use. This ensures that subsequent requests for the same data can be satisfied with a cache hit.
Cache memory works based on the principle of locality of reference. This principle states that programs tend to access a relatively small portion of instructions or data repeatedly. Cache memory takes advantage of this behavior by storing frequently accessed items in the cache, keeping them readily available for the CPU. By having a copy of frequently used data or instructions in the cache, cache memory minimizes the need to access the main memory and reduces latency.
Cache memory utilizes caching algorithms to determine which data or instructions to store in the cache and when to evict older entries. One popular algorithm is the Least Recently Used (LRU) algorithm, which evicts the least recently accessed items from the cache when space is limited. Other algorithms, such as Random Replacement or First-in-First-Out (FIFO), may also be employed depending on the specific cache design and requirements.
The effectiveness of cache memory depends on its organization and the utilization of caching algorithms. The cache hierarchy, with different levels such as L1, L2, and L3 caches, ensures that frequently accessed items are stored in closer proximity to the CPU, reducing latency even further.
In summary, cache memory works by storing frequently accessed data or instructions near the CPU to reduce the need for accessing the slower main memory. By utilizing caching algorithms and taking advantage of the principle of locality of reference, cache memory enhances system performance by reducing latency and increasing the overall efficiency of data access.
Caching Algorithms
Caching algorithms in cache memory management play a critical role in determining which data or instructions should be stored in the cache and when to evict older entries to make room for new ones. These algorithms are designed to optimize cache utilization and ensure that frequently accessed items are available for fast retrieval.
One commonly used caching algorithm is the Least Recently Used (LRU) algorithm. It operates on the principle that the items that have been accessed least recently are the least likely to be accessed in the near future. According to the LRU algorithm, when there is a cache miss and the cache is full, the least recently accessed item is evicted from the cache to make space for the new item. By evicting the least recently used item, the LRU algorithm aims to maximize the cache hit rate and improve cache performance.
Another caching algorithm is the Random Replacement algorithm. This algorithm randomly selects an item from the cache to be evicted when a cache miss occurs and the cache is full. Since the eviction decision is random, the Random Replacement algorithm does not consider the history of item usage. While this algorithm may not provide optimal cache performance in all cases, it has the advantage of simplicity and does not require additional bookkeeping data structures.
The First-in-First-Out (FIFO) algorithm is another commonly used caching algorithm. According to FIFO, the first item that was brought into the cache is the first one to be evicted in the case of a cache miss and a full cache. This algorithm follows a strict “first in, first out” ordering, regardless of how frequently an item may be accessed. FIFO is relatively simple to implement but may not always result in the best cache performance, as recently accessed frequently used items may be evicted prematurely.
Other caching algorithms, such as the Random Replacement algorithm, consider a combination of factors, including the history of item usage, frequency of access, and temporal locality. These algorithms aim to strike a balance between maintaining frequently used items in the cache and allowing for new items to enter.
It’s important to note that the choice of caching algorithm depends on the specific requirements of the computer system and the characteristics of the workload. Different algorithms may be more suitable for certain types of applications or usage patterns. Cache management systems may even employ a hybrid approach, combining multiple algorithms to maximize cache performance efficiently.
The selection and implementation of caching algorithms are essential to ensure that cache memory optimally utilizes its limited capacity, improving system performance by minimizing cache misses and maximizing cache hits. These algorithms enable cache memory to efficiently store and manage frequently accessed data or instructions, reducing the need for accessing the slower main memory and enhancing overall processing speed.
Benefits of Cache Memory
Cache memory brings a multitude of benefits to computer systems, ranging from improved performance to reduced latency. Let’s explore some of the key advantages of cache memory:
1. Faster Data Access: Cache memory significantly reduces the time taken to access frequently used instructions or data. By storing copies of these frequently accessed items in the cache, the CPU can retrieve them quickly, avoiding the need to access the slower main memory. This results in faster data access and accelerated processing times.
2. Reduced Latency: Cache memory operates at a much faster speed compared to the main memory. It is designed to be closer to the CPU, minimizing latency and enabling rapid data retrieval. By reducing the time required to access data, cache memory enhances overall system performance and responsiveness.
3. Improved System Performance: With its ability to provide faster data access and reduced latency, cache memory plays a vital role in improving system performance. By keeping frequently accessed instructions and data readily available, the CPU can execute instructions more efficiently and process data more quickly. This leads to enhanced overall system productivity and a smoother user experience.
4. Efficient Resource Utilization: Cache memory helps in efficiently utilizing system resources, particularly the CPU’s processing power. By minimizing the time spent waiting for data from the main memory, cache memory optimizes the CPU’s utilization and ensures that valuable processing capabilities are not idle due to data transfer delays. This maximizes the efficiency of the entire system.
5. Lower Power Consumption: Cache memory contributes to reducing power consumption in computer systems. By accessing frequently used instructions or data from the cache instead of the main memory, the CPU can avoid the power-intensive process of accessing the slower main memory. This results in energy savings and improved system efficiency, making cache memory an essential component in power-conscious computing environments.
6. Improved Multi-Core Performance: In multi-core systems, cache memory facilitates efficient data sharing between processor cores. With shared caches, multiple cores can access the same cache, leading to faster communication and synchronization. This enhances the performance of multi-threaded applications and enables better utilization of resources in a multi-core environment.
7. Versatility and Scalability: Cache memory is a versatile component that can adapt to different system configurations and requirements. It can be implemented at different cache levels (L1, L2, L3) to accommodate various computing architectures. Moreover, cache memory can be scaled up or down, depending on the specific needs of the system, allowing for flexibility and future expansion.
In summary, cache memory offers numerous benefits, including faster data access, reduced latency, improved system performance, efficient resource utilization, lower power consumption, improved multi-core performance, and versatility. These advantages make cache memory an integral part of modern computer systems, allowing for faster and more efficient processing of instructions and data.
Limitations of Cache Memory
While cache memory offers significant benefits and contributes to improved system performance, it is not without its limitations. Let’s explore some of the key limitations of cache memory:
1. Limited Capacity: Cache memory has a limited capacity compared to the main memory. The smaller size of cache memory means that not all data or instructions can be stored in the cache simultaneously. As a result, cache memory can become overwhelmed when dealing with large and complex workloads that require access to a vast amount of data. Cache misses occur when the cache does not contain the required information, leading to higher latency as the CPU accesses the slower main memory.
2. Cost: Cache memory, especially higher-level caches, can be more expensive to produce compared to the main memory. Cache memory utilizes Static Random Access Memory (SRAM) technology, which is faster but costlier than Dynamic Random Access Memory (DRAM) used in the main memory. As a result, increasing the size or incorporating additional cache levels can significantly impact the overall cost of the computer system.
3. Cache Coherency: In multi-core systems, cache coherency becomes a challenge. When multiple cores share a cache, it is crucial to ensure that all cores have consistent and up-to-date data. Maintaining cache coherency requires complex protocols and mechanisms, which can introduce additional overhead and impact system performance.
4. Unsuitability for Non-locality: Cache memory thrives on the principle of locality of reference, which assumes that programs access a relatively small portion of instructions or data repeatedly. However, certain workloads, such as scientific simulations or database queries, may exhibit poor locality and have unpredictable access patterns. In such cases, cache memory may not provide significant performance improvements
5. Energy Consumption: While cache memory contributes to overall system efficiency by reducing the need to access the main memory, it still consumes energy. The constant querying and updating of cache entries require power consumption, especially in larger cache configurations. As a result, cache memory can contribute to increased energy consumption, which may be a concern in battery-powered devices or energy-efficient computing environments.
6. Complexity: The management and optimization of cache memory involve complex algorithms and mechanisms. Caching algorithms need to make efficient decisions on which data to store in the cache and when to evict older entries. These algorithms require additional bookkeeping and control mechanisms, adding complexity to the cache memory management system. The increased complexity can sometimes lead to performance degradation or higher implementation costs.
In spite of these limitations, cache memory remains a crucial component in modern computer systems. While cache memory may not be able to eliminate all performance issues, it nonetheless provides significant improvements in data access speed, overall system efficiency, and latency reduction.
Conclusion
Cache memory plays a vital role in enhancing the performance and efficiency of modern computer systems. By storing copies of frequently accessed instructions and data, cache memory significantly reduces the time required for data access, improves overall system responsiveness, and accelerates processing times. The various levels of cache memory, including L1, L2, and L3 caches, make it possible to minimize latency and bridge the speed gap between the CPU and the main memory.
Caching algorithms, such as the Least Recently Used (LRU) algorithm, Random Replacement algorithm, and First-in-First-Out (FIFO) algorithm, optimize the utilization of cache memory, ensuring that the most frequently used items are readily available. These algorithms, combined with the cache memory hierarchy and shared cache designs in multi-core systems, improve resource utilization, facilitate data sharing between cores, and enhance the performance of multi-threaded applications.
While cache memory offers numerous benefits, it does have limitations, such as limited capacity, cost, cache coherency challenges, unsuitability for non-locality, potential energy consumption, and increased complexity. These limitations should be carefully considered during system design to strike a balance between performance improvements and cost-effectiveness.
In conclusion, cache memory is a fundamental component in modern computer systems, providing faster data access, reduced latency, improved system performance, efficient resource utilization, and enhanced multi-core capabilities. Despite its limitations, cache memory has revolutionized the way data is stored and accessed, enabling faster and more efficient processing. As computer systems continue to evolve, cache memory will remain an invaluable tool for achieving optimal performance and delivering a seamless user experience.