Introduction
When it comes to accessing and utilizing data from websites, there are various methods available for downloading it. Whether you are an analyst, a researcher, or simply interested in gathering information, understanding the process of downloading data from a website can be immensely helpful. In this article, we will explore some practical steps and options for downloading data from websites, ensuring that you can easily access the information you need.
With the immense amount of data available on the internet, it is crucial to have the right tools and techniques at your disposal. While some websites provide direct download options for their data, others might require additional steps, such as utilizing web scraping tools or accessing API endpoints. By familiarizing yourself with these methods, you can efficiently gather the desired information.
Before diving into the various approaches for downloading website data, it is essential to have a clear understanding of your specific data source. This involves identifying the type of data you need and the website that provides it. Whether it is financial data, product information, or statistical reports, each website may have a different structure and format for presenting their data. Understanding the layout and organization of the website will help you determine the most effective method for data extraction.
In the following sections, we will explore different techniques for downloading website data. This includes using web scraping tools like Python and BeautifulSoup, utilizing API endpoints for data extraction, and utilizing web browser extensions specifically designed for downloading purposes. By following these steps, you can save valuable time and effort in obtaining the data you require.
Step 1: Understand the data source
Before diving into the process of downloading data from a website, it is crucial to familiarize yourself with the data source. Understanding the structure and layout of the website will help you determine the most efficient method for extracting the desired information.
Start by identifying the type of data you need and the specific website that provides it. Is it a news website, an e-commerce platform, a government database, or a research portal? Each website may present its data in a different format, and knowing how the information is organized will make the extraction process much smoother.
Take some time to navigate through the website and explore the different sections or categories where the data might be located. Look for any search filters or advanced search options that can narrow down your results. Understanding how the website organizes its data can help you identify the best approach for extracting it.
Additionally, pay attention to the data format in which the information is presented. Is it in a structured format like tables, lists, or grids? Alternatively, is it embedded within paragraphs, images, or multimedia content? This knowledge will help you determine the appropriate method for extracting the data.
Furthermore, consider the frequency of data updates on the website. Is the data constantly changing in real-time, or is it updated on a regular basis? This information is important because it affects the approach you should take for downloading the data. Real-time data may require an API-based approach, while regularly updated data can be scraped periodically using web scraping tools.
By gaining a clear understanding of the data source, you will be better equipped to choose the most suitable method for downloading the data. This knowledge will save you time and effort by ensuring that you extract the information efficiently.
Step 2: Choose the right method for downloading
Once you have a good understanding of the data source, it’s time to choose the appropriate method for downloading the data. There are several options available, depending on the website’s structure and the nature of the data you are seeking.
One common method is to use a web scraping tool. Web scraping involves extracting data from websites by parsing through their HTML code. Tools like Python and BeautifulSoup provide powerful functionalities for scraping web pages and extracting the desired data. With web scraping, you can automate the data extraction process and save it in a structured format.
Another option is to utilize API endpoints. Many websites provide APIs (Application Programming Interfaces) that allow developers to access and retrieve specific data. APIs provide a streamlined way to extract data directly from the website’s server, often in a standardized format like JSON or XML. This method is particularly useful for real-time data or data that requires frequent updates.
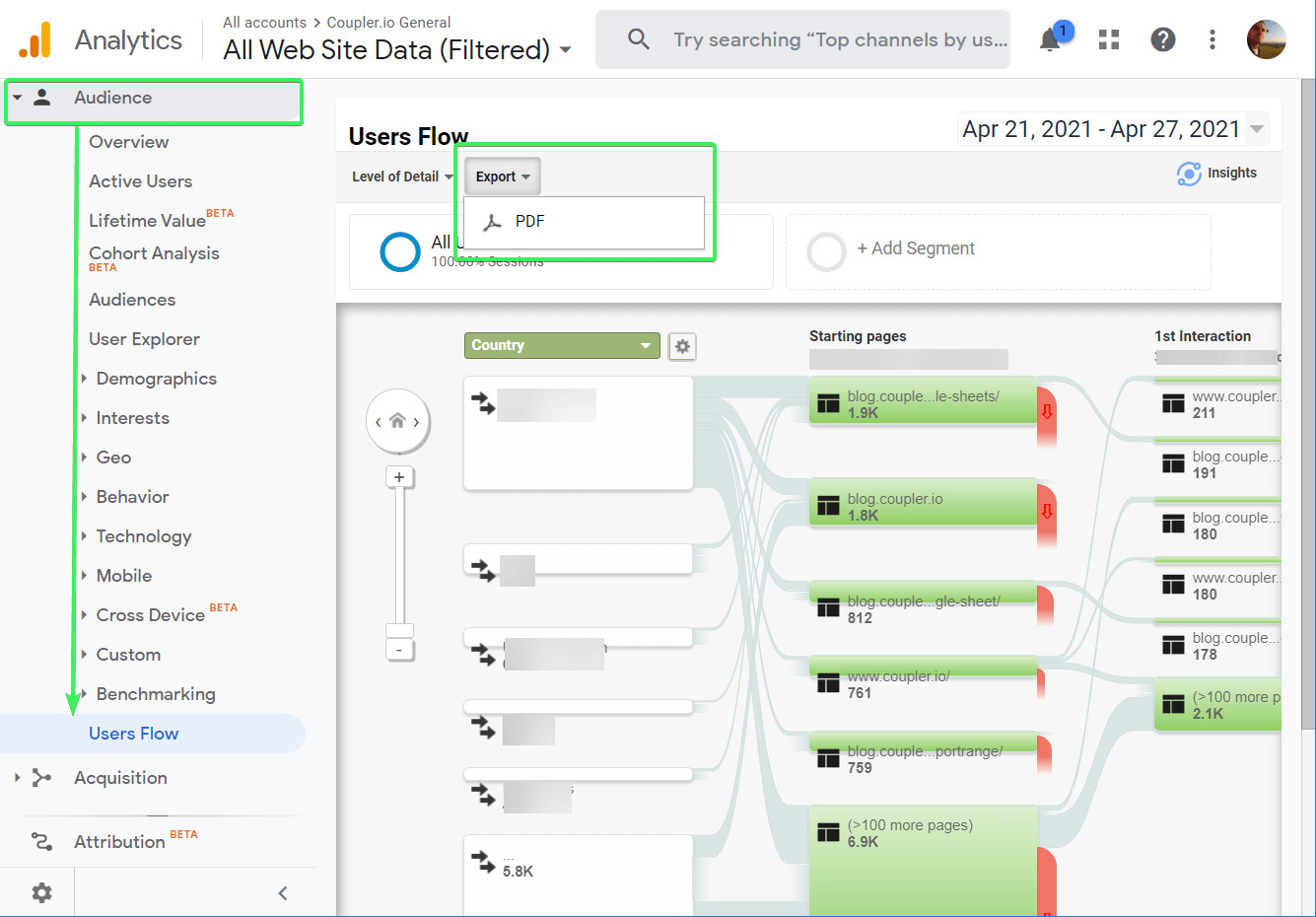
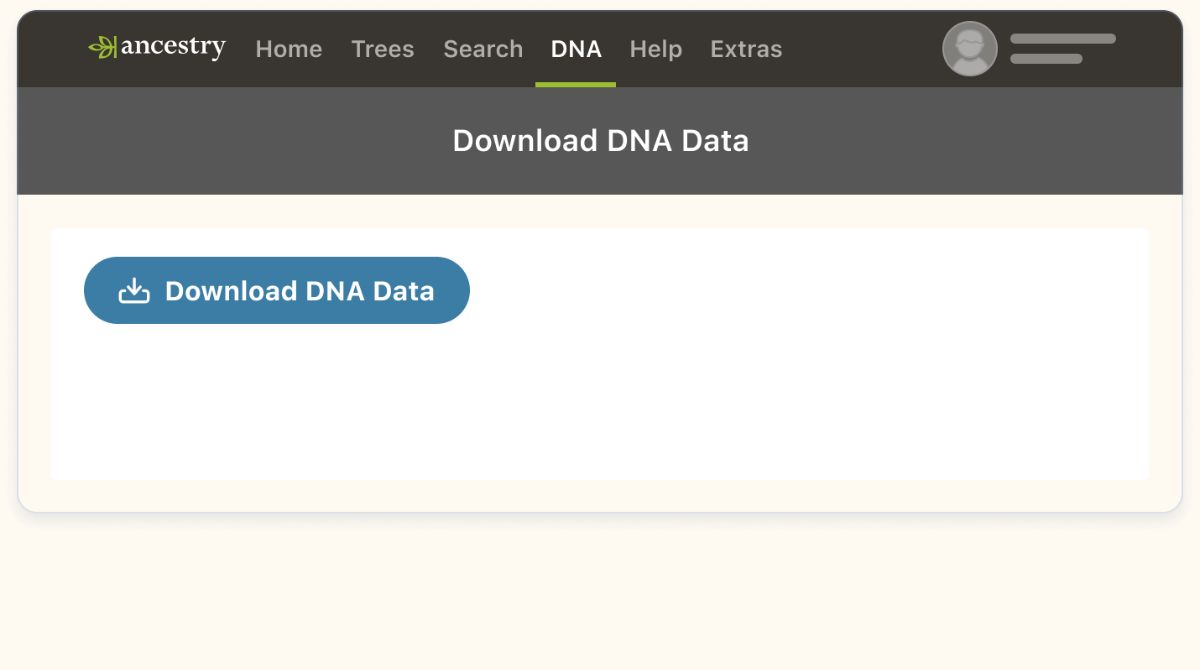
In some cases, websites offer direct download options for their data. Look for buttons or links that allow you to download the files in a suitable format, such as CSV, Excel, or PDF. This method is straightforward and eliminates the need for additional extraction steps.
If the website does not provide a direct download option or an accessible API, you can consider using web browser extensions specifically designed for downloading purposes. These extensions can help you capture and save web pages or specific sections of a website with ease. Keep in mind that this method may not be suitable for extracting large amounts of data or data that requires regular updates.
When choosing the method for downloading data, consider factors such as the website’s structure, data format, and frequency of updates. Select the approach that provides the most efficient and accurate extraction of the desired information.
In the following steps, we will explore specific techniques and tools for downloading data from websites, including web scraping with Python and BeautifulSoup, utilizing API endpoints, and using web browser extensions. Each method has its own advantages and should be chosen based on the unique requirements of the data source.
Step 3: Inspect the website for download options
Before resorting to more complex methods like web scraping or utilizing APIs, it’s important to thoroughly inspect the website for any existing download options. Many websites provide direct download links or buttons for users to access and save the desired data without the need for additional tools or techniques.
Start by exploring the website’s user interface and navigation. Look for any sections or pages that might indicate the availability of downloadable content. Common areas to check include “Downloads,” “Data,” or “Resources” sections. Additionally, keep an eye out for icons or graphics that suggest the presence of download options.
Once you find potential download areas, carefully review the provided information. Some websites may offer data downloads in different formats, such as CSV, Excel, PDF, or ZIP files. Consider which format suits your needs and click on the appropriate download link or button.
If the website has a search or filtering feature, use it to narrow down your results. This can help you locate specific datasets or files that you’re interested in downloading. Try using relevant keywords or tags to facilitate the search process.
In cases where the website doesn’t explicitly provide download options, look for alternative actions that might allow you to save the data. For example, some websites offer a print function that enables you to save the content as a PDF file. While this method may not preserve the data in a structured format, it can still be a valuable option depending on your requirements.
Remember to document any discovered download options, including the file formats available and the paths to access them. This information will be helpful in determining the best course of action for downloading the data, especially if you encounter any difficulties or limitations with other methods.
By inspecting the website for download options, you may discover a straightforward and efficient way to obtain the desired data directly from the source. This can save you time and effort compared to more intricate methods such as web scraping or API utilization.
Step 4: Use a web scraping tool
If the website does not provide a direct download option or the data you need is not easily accessible through other means, web scraping can be a powerful method for extracting the desired information. Web scraping involves automatically parsing through the HTML code of a website to extract specific data.
One popular and versatile tool for web scraping is Python combined with BeautifulSoup. Python, a widely-used programming language, provides a rich ecosystem of libraries and packages that make web scraping relatively straightforward. BeautifulSoup is a Python library specifically designed for parsing HTML and XML documents.
The first step in using a web scraping tool is to install Python and BeautifulSoup on your computer. Once you have these set up, you can start writing code to scrape the website. Begin by inspecting the HTML code of the webpage you want to scrape. Identify the elements that contain the data you need, such as HTML tags, classes, or IDs.
Using BeautifulSoup, you can programmatically navigate the HTML structure of the webpage and extract the desired data. BeautifulSoup provides functions and methods that simplify the process of searching for and extracting specific elements or attributes from the HTML code.
When scraping a website, it’s important to respect the website’s terms and conditions and not overwhelm their servers with excessive requests. Use appropriate delays between requests and ensure that you are not putting any unnecessary strain on the website’s resources.
Once you have extracted the data using web scraping, you can save it in a suitable format such as CSV, Excel, or JSON. Python provides various libraries for data manipulation and storage, allowing you to analyze and work with the scraped data efficiently.
However, keep in mind that the legality and ethical implications of web scraping vary depending on the website and the purpose of scraping. It is essential to understand the website’s terms of service and obtain permission if necessary. Additionally, be aware of any legal restrictions or copyright issues that may apply to the data you are scraping.
Web scraping can be a powerful method for gathering data from websites that do not offer direct download options. However, it’s important to approach web scraping responsibly and ethically.
Step 5: Download using Python and BeautifulSoup
Python and BeautifulSoup can be a powerful combination for downloading data from websites that do not offer direct download options. With Python’s versatility and the scraping capabilities of BeautifulSoup, you can automate the process of extracting and saving the desired data.
To begin, make sure you have Python and BeautifulSoup installed on your computer. Once installed, you can create a Python script to perform the web scraping. Start by importing the necessary libraries, including `requests` to retrieve the HTML content and `BeautifulSoup` to parse the HTML code.
Next, use the `requests` library to send a GET request to the URL of the webpage you want to scrape. This will retrieve the HTML content of the webpage, which you can then pass to BeautifulSoup for parsing.
Once you have obtained the HTML content, use BeautifulSoup to navigate through the HTML structure and locate the data you need. This can be accomplished by identifying the specific HTML elements, classes, or IDs that contain the desired information. Use BeautifulSoup’s various methods and functions, such as `.find()`, `.find_all()`, and `.select()`, to locate and extract the relevant data.
After extracting the data, you can save it in a suitable format, such as CSV, Excel, or JSON. Python provides several libraries for data manipulation and storage, such as `csv`, `pandas`, or `json`. Choose the appropriate library based on your preferred file format and save the extracted data accordingly.
Remember to handle any exceptions or errors that may occur during the scraping process. Websites may change their structure or block scraping attempts, so it’s important to include error handling mechanisms in your script to handle such situations gracefully.
Additionally, ensure that your web scraping activities comply with the website’s terms of service and follow ethical guidelines. Avoid overloading the website’s servers with excessive requests and be respectful of their resources.
By using Python and BeautifulSoup, you can automate the process of downloading data from websites in a structured and efficient manner. This method is particularly useful when dealing with websites that do not provide direct download options or when you need to extract specific data elements from the webpage.
Step 6: Utilize API endpoints for data extraction
When it comes to extracting data from websites, one of the most efficient and reliable methods is to utilize API endpoints. Many websites provide APIs (Application Programming Interfaces) that allow developers to access and retrieve specific data in a structured format.
The first step in utilizing API endpoints is to identify if the website you’re interested in has an available API. Look for any documentation or developer resources on the website that provide information about their API offerings. You may need to register for an API key or authentication to access the data.
Once you have access to the API, familiarize yourself with its documentation. The documentation will provide details on the different endpoints available, the parameters you can use to filter or refine the data, and the format in which the data will be returned (typically JSON or XML).
Start by understanding the structure and syntax of the API endpoints. This includes the base URL, the path to the specific endpoint, and any additional query parameters that can be passed to refine the data extraction. The documentation will often provide examples and sample requests to guide you.
Using a programming language of your choice, you can then make HTTP requests to the API endpoints and receive the desired data in response. Most programming languages provide libraries or modules that make it easy to send HTTP requests and handle the responses.
After receiving the data from the API, you can process and manipulate it according to your requirements. This may involve extracting specific fields, filtering the data, or transforming it into a different format. Utilize the documentation to understand the structure of the response and access the relevant data fields.
Ensure that you comply with the API provider’s terms of service and any usage limits or restrictions. Respect the rate limits set by the API to avoid overwhelming the server and getting your requests blocked.
Utilizing API endpoints for data extraction is a powerful method that provides direct access to structured data. It eliminates the need for parsing HTML code or dealing with website-specific nuances. By leveraging APIs, you can access the data you need in a more efficient and standardized way.
Step 7: Use web browser extensions for downloading
If you’re looking for a simple and convenient method for downloading data from websites, utilizing web browser extensions can be a valuable option. These extensions are specifically designed to enhance your browsing experience and provide additional functionality, including the ability to download content from web pages.
The first step in using web browser extensions for downloading is to identify and install the appropriate extension for your preferred browser. Popular browsers such as Google Chrome, Mozilla Firefox, and Microsoft Edge have extensive extension libraries that offer a range of options.
Once installed, these extensions typically add a button or icon to your browser’s toolbar, which you can click to activate their functionality. Look for extensions with features related to downloading, data extraction, or web page capture.
When you come across a web page from which you wish to download data, click on the extension’s button or icon to activate it. The extension will then analyze the content of the page and provide options for downloading or saving specific elements or the entire page.
Some web browser extensions offer the ability to download specific types of data, such as images, videos, or documents. For example, you can find extensions that allow you to download all the images on a page with a single click.
Other extensions provide more advanced functionality, such as the ability to scrape data from tables or extract specific information from web pages. These extensions often require customization and configuration to set up the desired data extraction or download process.
Web browser extensions are especially handy when you need to download a small amount of data or extract specific elements quickly. However, they may not be as efficient for downloading large amounts of data or automating the process across multiple pages.
Since web browser extensions are developed by third-party developers, it is important to choose reputable extensions from trusted sources. Read user reviews and check the extension’s permissions to ensure you are getting a reliable and safe tool for downloading data.
By utilizing web browser extensions for downloading, you can simplify the process of obtaining data from websites without the need for complex coding or specialized tools. These extensions provide a user-friendly interface and are readily accessible within your web browser.
Step 8: Save the downloaded data in a suitable format
Once you have successfully downloaded the data from the website using your preferred method, it’s important to save it in a suitable format that can be easily accessed and manipulated for further analysis or usage.
The specific format in which you save the downloaded data depends on the nature of the data and your intended purpose. Here are some common formats to consider:
- CSV (Comma-Separated Values): This format is widely supported and can be easily opened in spreadsheet software like Microsoft Excel or Google Sheets. CSV files store tabular data with each value separated by a comma, making it easy to work with and analyze.
- JSON (JavaScript Object Notation): JSON is commonly used for structuring and storing data. It offers a simple and readable format that is often used for data interchange between applications. JSON is particularly useful when dealing with complex and nested data structures.
- Excel: Microsoft Excel’s .xlsx or .xls formats are convenient for storing data in a highly organized manner, with the ability to have multiple sheets and rich formatting options. This format is ideal for data that includes different data types and requires advanced calculations or analysis.
- Database: If you have a large amount of data or plan to work with it extensively, consider saving it in a database format such as MySQL, PostgreSQL, or SQLite. Databases provide more structured storage and offer features like querying, indexing, and data manipulation.
When selecting a format, consider the software and tools you will be using to work with the data. Ensure that you choose a format that is compatible with your analysis or processing requirements.
Additionally, it’s good practice to organize the downloaded data in a logical and structured manner. Consider creating folders or directories to categorize and store different datasets. This will make it easier to locate and access specific data in the future.
Remember to add appropriate file naming conventions to ensure clarity and ease of reference. Use descriptive names that indicate the content and context of the data, making it easier to understand its purpose and relevance.
Saving the downloaded data in a suitable format ensures that it remains accessible and usable for your intended purposes. Whether it’s for further analysis, reporting, or sharing with others, choosing the right format is crucial for effective data management.
Conclusion
Downloading data from websites can be a valuable skill for researchers, analysts, and anyone seeking information from online sources. By following the steps outlined in this article, you can efficiently extract and save the data you need.
Understanding the data source is crucial to determine the most effective method for data extraction. Take the time to explore the website and familiarize yourself with its structure, layout, and data format.
Choosing the right method for downloading depends on the website’s characteristics and the specific data you require. Options include using web scraping tools like Python and BeautifulSoup, utilizing API endpoints, or utilizing browser extensions specifically designed for downloading.
Inspecting the website for download options can save time and effort if the website provides direct download options for the data you need. Look for dedicated download sections or buttons that offer the desired files or data formats.
Using a web scraping tool like Python and BeautifulSoup allows you to extract data from websites that do not provide direct download options. Be mindful of the website’s terms of service and legal restrictions while web scraping.
Utilizing API endpoints provides a structured and efficient method for data extraction, especially for websites that offer APIs. Familiarize yourself with the available endpoints and parameters to retrieve the desired data.
Using web browser extensions can provide a simple and convenient way to download data from websites. Look for reputable extensions that offer features like data extraction, web page capture, or specific file downloads.
Saving the downloaded data in a suitable format ensures its accessibility and usability. Formats like CSV, JSON, Excel, or databases offer different advantages depending on the data and analysis requirements.
By following these steps and selecting the appropriate method for downloading data, you can efficiently gather the information you need for analysis, research, or any other purpose. Stay mindful of the legal and ethical considerations surrounding data extraction and respect the website’s terms of service. Armed with these techniques, you can enhance your data gathering capabilities and unlock valuable insights from the vast world of online information.