Introduction
Machine Learning has revolutionized various industries by enabling computers to learn, adapt, and make intelligent decisions. One crucial component of machine learning is data representation, which involves converting raw data into a suitable format for analysis and model training. Encoders play a vital role in this process, providing a way to transform data into a numerical representation that algorithms can understand.
An encoder is a fundamental concept in machine learning that converts input data into a different, more suitable representation. It essentially maps data from a high-dimensional space to a lower-dimensional space, capturing essential features and patterns. By reducing the dimensionality of the data, encoders can simplify the learning process for machine learning algorithms and improve their performance.
The purpose of an encoder is to extract key features from the input data while minimizing information loss. It aims to represent the data in a more compact and meaningful way, making it easier for algorithms to process and derive meaningful insights. Encoders are widely used in various machine learning tasks, such as image recognition, natural language processing, anomaly detection, and recommendation systems.
To understand how an encoder works, let’s consider an example of image recognition. An image contains thousands or even millions of pixels, each representing a specific color value. The encoder takes this high-dimensional pixel data and maps it to a lower-dimensional space, where each dimension corresponds to a relevant feature of the image. This compressed representation retains the essential characteristics of the image while reducing its complexity.
There are different types of encoders used in machine learning, each with its specific approach and characteristics. Some common types include autoencoders, variational autoencoders, and convolutional encoders. These encoders differ in how they capture and represent data, making them suitable for different types of tasks and data types.
Definition of an Encoder
An encoder is a fundamental component in machine learning that converts input data into a different representation that is more suitable for analysis and modeling. It essentially maps data from a high-dimensional space to a lower-dimensional space, capturing essential features and patterns. By doing so, an encoder simplifies the learning process for machine learning algorithms and improves their performance.
The main purpose of an encoder is to extract relevant features from the input data while minimizing information loss. It achieves this by transforming the data into a compressed representation that retains the essential characteristics needed for analysis. By reducing the dimensionality of the data, an encoder reduces the complexity and computational requirements of the learning process.
Encoders play a crucial role in various machine learning tasks, such as image recognition, natural language processing, anomaly detection, and recommendation systems. Depending on the specific task and data type, different types of encoders are utilized.
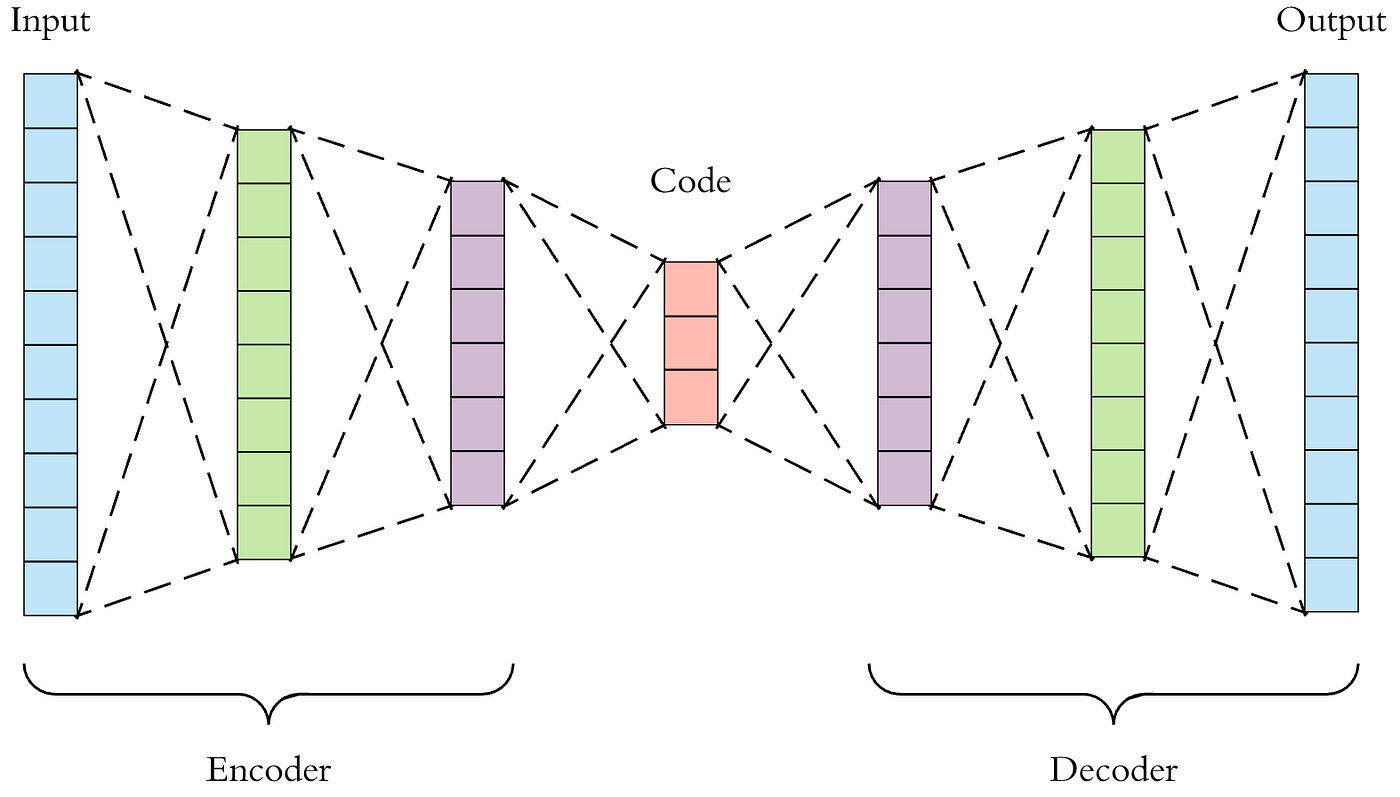
Autoencoders are one of the most commonly used types of encoders in machine learning. They are neural network-based models that consist of an encoder and a decoder. The encoder compresses the input data into a lower-dimensional representation, while the decoder reconstructs the original data from this representation. Autoencoders are often used for dimensionality reduction, anomaly detection, and generative modeling.
Variational autoencoders (VAEs) are another popular type of encoder. They not only learn a compressed representation but also model the underlying distribution of the data. VAEs enable generating new data points with similar characteristics to the training data, making them suitable for tasks such as image synthesis and data generation.
Convolutional encoders, on the other hand, are specifically designed for processing image data. They utilize convolutional neural networks (CNNs) to capture spatial relationships and local features in images. Convolutional encoders are commonly used in computer vision tasks, such as image classification and object detection.
In summary, an encoder is a crucial component in machine learning that transforms input data into a more suitable representation. By extracting relevant features and reducing the dimensionality of the data, encoders simplify the learning process and enhance the performance of machine learning algorithms.
Purpose of an Encoder
The primary purpose of an encoder in machine learning is to transform input data into a more suitable representation for analysis and modeling. It plays a critical role in simplifying the learning process for machine learning algorithms and improving their performance.
One of the main purposes of an encoder is to extract essential features from the input data. By reducing the dimensionality of the data, encoders capture the most relevant characteristics while eliminating noise and redundant information. This feature extraction process makes the data more meaningful and easier to understand for machine learning algorithms.
Another purpose of an encoder is to compress the input data. By mapping the data from a high-dimensional space to a lower-dimensional space, encoders reduce the complexity and computational requirements of the learning process. This compression not only speeds up the training process but also allows for efficient storage and retrieval of the data.
Encoders also facilitate data normalization and standardization. In many cases, input data may have varying scales or distributions, which can negatively impact the performance of machine learning algorithms. Encoders can transform the data into a standardized format, ensuring that it is in a consistent range or distribution suitable for analysis.
An important aspect of encoders is their ability to capture latent representations of the input data. These latent representations are compressed, lower-dimensional versions of the original data that retain essential information. By learning these representations, encoders enable the generation of new data points with similar characteristics, allowing for tasks such as data synthesis and data augmentation.
Furthermore, encoders support dimensionality reduction, where they transform high-dimensional data into a lower-dimensional space while preserving as much relevant information as possible. This reduction in dimensionality not only simplifies the learning process but can also help in visualizing and understanding the data, especially in complex multidimensional datasets.
Overall, the purpose of an encoder is to enhance the efficiency and effectiveness of machine learning algorithms by transforming input data into a more suitable representation. By extracting essential features, compressing the data, facilitating normalization, capturing latent representations, and supporting dimensionality reduction, encoders play a vital role in data preprocessing and feature engineering, ultimately improving the accuracy and performance of machine learning models.
How an Encoder Works
An encoder works by taking input data and transforming it into a different, more suitable representation that captures essential features and patterns. This process involves several steps that enable the encoder to convert high-dimensional data into a compressed, lower-dimensional space.
The first step in the encoding process is to define the architecture of the encoder. This typically involves selecting the type of encoder, such as autoencoder or variational autoencoder, and configuring the layers and parameters of the neural network. The architecture is crucial as it determines how the input data will be transformed and what features will be extracted.
Once the architecture is defined, the encoder starts the process by feeding the input data into the neural network. The neural network consists of multiple layers, each performing specific computations on the data. These computations involve a combination of linear transformations and non-linear activation functions, such as ReLU (Rectified Linear Unit), sigmoid, or tanh.
As the data flows through the layers, the encoder progressively extracts essential features and reduces the dimensionality. This feature extraction is achieved by applying weight matrices to the data and applying activation functions that introduce non-linearities. The layers closer to the output of the encoder typically have fewer neurons, resulting in a compressed representation of the input data.
During the encoding process, the encoder aims to map the input data to a lower-dimensional space that preserves as much relevant information as possible. The encoder learns to identify the most important features and patterns in the data and represents them in a compact form. This compressed representation serves as a more efficient and informative version of the original data.
After the encoding process is complete, the encoder outputs the compressed representation of the input data. This representation typically consists of numerical values that capture the essential characteristics of the data. The encoder’s output can then be used for further analysis or as input to other machine learning algorithms for tasks such as classification, clustering, or data generation.
It’s important to note that the encoding process is usually accompanied by a decoding process. In autoencoders, for example, there is a corresponding decoder that tries to reconstruct the original data from the compressed representation. This reconstruction is useful for tasks such as data generation, anomaly detection, or denoising.
In summary, an encoder works by taking input data, applying a series of transformations, and mapping it to a lower-dimensional space that captures essential features and patterns. Through the process of feature extraction, dimensionality reduction, and non-linear transformations, encoders enable the representation of data in a more compact and meaningful manner, facilitating efficient analysis and modeling in machine learning tasks.
Types of Encoders
In machine learning, various types of encoders are utilized to transform data into more suitable representations for analysis and modeling. Each type of encoder has distinct characteristics and is designed to handle specific types of data and tasks. Here are some common types of encoders:
1. Autoencoders: Autoencoders are neural network-based models consisting of an encoder and a decoder. The encoder compresses the input data into a lower-dimensional representation, while the decoder reconstructs the original data from this representation. Autoencoders are widely used for dimensionality reduction, data denoising, and anomaly detection.
2. Variational Autoencoders (VAEs): VAEs, similar to autoencoders, learn compressed representations of input data. However, they also model the underlying distribution of the data, enabling generation of new data points with similar characteristics. VAEs are particularly useful for tasks such as image synthesis, data generation, and unsupervised learning.
3. Convolutional Encoders: Convolutional encoders are specifically designed for processing image data. They utilize convolutional neural networks (CNNs) to capture spatial relationships and local features in images. Convolutional encoders are commonly used in computer vision tasks, such as image classification, object detection, and image generation.
4. Recurrent Neural Network (RNN) Encoders: RNN encoders are employed for sequential data, such as natural language processing and time series analysis. They process the input data sequentially, capturing dependencies and patterns over time. RNN encoders are effective in tasks like sentiment analysis, machine translation, and speech recognition.
5. Hashing Encoders: Hashing encoders transform high-dimensional data into fixed-length binary codes. These codes are designed to preserve the similarity between data points, making them suitable for tasks like similarity search, recommendation systems, and clustering. Hashing encoders offer efficient storage and retrieval of large datasets.
6. Sparse Encoders: Sparse encoders aim to learn sparse representations, where only a subset of features in the input data is activated. These encoders find applications in areas like feature selection, anomaly detection, and visualization of high-dimensional data. They help in reducing computational complexity and improving interpretability.
Each type of encoder comes with its advantages and limitations, making it important to choose the appropriate encoder based on the specific task and data characteristics. Combining different types of encoders or leveraging ensemble methods can further enhance the representation and performance of machine learning models.
Application of Encoders in Machine Learning
Encoders have diverse applications in machine learning across various domains. They play a crucial role in transforming data into suitable representations for analysis, modeling, and decision-making. Here are some common applications where encoders are widely utilized:
1. Image Recognition: Encoders, especially convolutional encoders, are extensively used in image recognition tasks. They capture important features and patterns in images, enabling machines to classify objects, detect objects in images, and even generate new images. Encoders help in transforming pixel-based data into a meaningful and compact representation that machine learning models can interpret.
2. Natural Language Processing (NLP): Encoders are highly valuable in NLP tasks such as text classification, sentiment analysis, machine translation, and named entity recognition. By encoding textual data, encoders provide a numerical representation that captures the semantic meaning and contextual information of text. Recurrent neural network (RNN) encoders, along with techniques like word embeddings and attention mechanisms, are commonly used in NLP applications.
3. Anomaly Detection: Encoders are effective in identifying outliers and anomalies in data. By learning the normal patterns and representations of data, encoders can detect and flag unusual instances. This is particularly valuable in fraud detection, network intrusion detection, and system monitoring. Autoencoders and variational autoencoders are commonly utilized for detecting anomalies by reconstructing the input data and comparing it to the original.
4. Recommendation Systems: Encoders are used to create user and item profiles in recommendation systems. By encoding user behavior and item characteristics, encoders enable the generation of personalized recommendations. Collaborative filtering, content-based filtering, and hybrid approaches employ encoders to represent users and items in a lower-dimensional space, facilitating efficient recommendation generation.
5. Data Generation and Augmentation: Encoders, particularly variational autoencoders, are employed for data generation and augmentation tasks. By learning the underlying distribution of the training data, encoders can generate new data points with similar characteristics. This is useful in tasks such as image synthesis, data augmentation for training machine learning models, and overcoming data scarcity issues.
6. Dimensionality Reduction: Encoders are extensively used for dimensionality reduction, where high-dimensional data is transformed into a lower-dimensional space. This process helps in feature extraction, data visualization, and reducing computational complexity. Techniques like autoencoders and sparse encoders enable efficient representation of data, allowing for better understanding and analysis.
7. Unsupervised Learning: Encoders play a crucial role in unsupervised learning tasks, where there is no labeled data available for training. Encoders aid in learning meaningful representations of input data, allowing for clustering, denoising, and generative modeling. Unsupervised pre-training using encoders can help in initializing neural networks for subsequent supervised learning tasks.
These are just a few examples of how encoders are applied in machine learning. The flexibility and versatility of encoders make them essential tools for various applications, enabling machines to effectively process, understand, and make valuable insights from different types of data.
Challenges and Limitations of Encoders
While encoders are powerful tools in machine learning, they also come with certain challenges and limitations that should be taken into consideration. Understanding these challenges can help practitioners make informed decisions when using encoders in their projects. Here are some common challenges and limitations:
1. Loss of Information: Although encoders aim to minimize information loss, there is always a possibility of losing some important details during the encoding process. High-dimensional data may contain fine-grained information that could be crucial for certain tasks. Balancing between dimensionality reduction and preserving relevant information is a challenge when designing and training encoders.
2. Data Dependency: Encoders heavily rely on the patterns and distribution of the training data. If the data used for training is not representative of the target population or is biased, the encoded representations may not generalize well to unseen data. Care must be taken to ensure that the training data is diverse and the encoder is not overfitting to specific patterns or biases.
3. Curse of Dimensionality: While encoders can effectively reduce the dimensionality of data, high-dimensional input spaces can still pose challenges. The curse of dimensionality refers to the sparsity and increased computational complexity that arises as the number of dimensions increases. It becomes harder to capture meaningful patterns and relationships in high-dimensional spaces, and encoders may struggle to extract useful features in extremely high-dimensional data.
4. Hyperparameter Tuning: Encoders often have several hyperparameters that need to be tuned during the design and training process. Selecting the appropriate architecture, layer configurations, activation functions, and regularization techniques can significantly impact the performance and capabilities of the encoder. Finding the optimal combination of hyperparameters can be time-consuming and require expertise.
5. Robustness to Noise and Outliers: Encoders may be sensitive to noisy or outlier data points, especially during the reconstruction phase in autoencoders. Anomalies or noisy instances in the training data can negatively affect the learning process, potentially leading to inaccurate reconstructions or distorted representations. Techniques such as data cleaning and robust optimization should be applied to mitigate the impact of outliers and noise.
6. Interpretability of Representations: While encoders generate compact and meaningful representations, interpreting these representations may be challenging. The encoded features may not have direct human-readable interpretations, making it difficult to understand the underlying reasons for certain predictions or decisions made by the machine learning model. Interpretable models or additional techniques, such as attention mechanisms, may be necessary to gain insights into the encoded representations.
7. Computational Resource Requirements: Some types of encoders, such as deep neural network-based architectures, can be computationally expensive to train and deploy. They may require significant computational resources and time for training, especially when dealing with large-scale datasets or complex architectures. The availability of sufficient computational power and memory is crucial for efficient and effective encoder training.
8. Domain Dependency: Encoders, like other machine learning models, may perform differently depending on the specific domain or application. The choice of encoder architecture and hyperparameters may need to be adapted or fine-tuned for each specific domain, and the effectiveness of encoders may vary across different types of data, such as images, text, or time series.
Awareness of these challenges and limitations will help practitioners effectively address them and make informed decisions when utilizing encoders in their machine learning projects. By understanding these limitations, practitioners can better assess the performance, applicability, and potential drawbacks associated with different types of encoders.
Conclusion
Encoders are indispensable tools in machine learning that play a vital role in transforming data into meaningful representations. They facilitate the extraction of essential features, compression of data, and dimensionality reduction, all of which enhance the efficiency and effectiveness of machine learning algorithms.
Through the various types of encoders, such as autoencoders, variational autoencoders, and convolutional encoders, different data types and tasks can be addressed effectively. Encoders find application in image recognition, natural language processing, anomaly detection, recommendation systems, and more.
While encoders offer numerous benefits, they also come with challenges and limitations. These include the potential loss of information, dependence on training data, curse of dimensionality, hyperparameter tuning, robustness to noise and outliers, interpretability of representations, and computational resource requirements. Being aware of these challenges is crucial to make informed decisions and mitigate their impact on the performance and applicability of encoders.
Despite these challenges, the application of encoders in machine learning continues to drive advancements in various fields by enabling machines to understand and interpret complex data. Encoders empower algorithms to effectively process images, text, and other forms of data, improving decision-making, accuracy, and efficiency.
In conclusion, encoders are powerful tools that transform raw data into meaningful representations, enabling machines to learn and make intelligent decisions. As machine learning continues to evolve, encoders will remain essential for effective data representation and analysis, empowering machines to unlock valuable insights and drive progress in diverse domains.