Introduction
Machine learning has become increasingly popular in recent years, revolutionizing various industries and improving our daily lives in countless ways. From virtual assistants to self-driving cars, machine learning algorithms are driving innovation and automation. But have you ever wondered how these algorithms work? One of the key ingredients that powers machine learning is data.
Data is the lifeblood of machine learning algorithms. It is the fuel that enables them to learn and make predictions or decisions. Without data, the algorithms would be like empty vessels, devoid of any knowledge or insights. The quality and quantity of data are crucial factors that determine the success of a machine learning model.
In this article, we will explore the role of data in machine learning and answer the question: How much data is needed for machine learning? We will delve into the factors that affect data requirements, discuss the concept of “big data,” and examine the relationship between sample size and training data. Additionally, we will touch upon the issues of overfitting and underfitting, and provide strategies for obtaining sufficient data for machine learning models.
It is important to note that while data plays a pivotal role in machine learning, it is not the only factor at play. Algorithm selection, feature engineering, and model tuning are equally critical. However, for the purpose of this article, our focus will primarily be on the data aspect of machine learning.
So, get ready to dive into the world of machine learning and unravel the mysteries behind the data requirements of these powerful algorithms. Let’s explore the fascinating relationship between data and machine learning and discover how much data is truly needed to achieve accurate and reliable results.
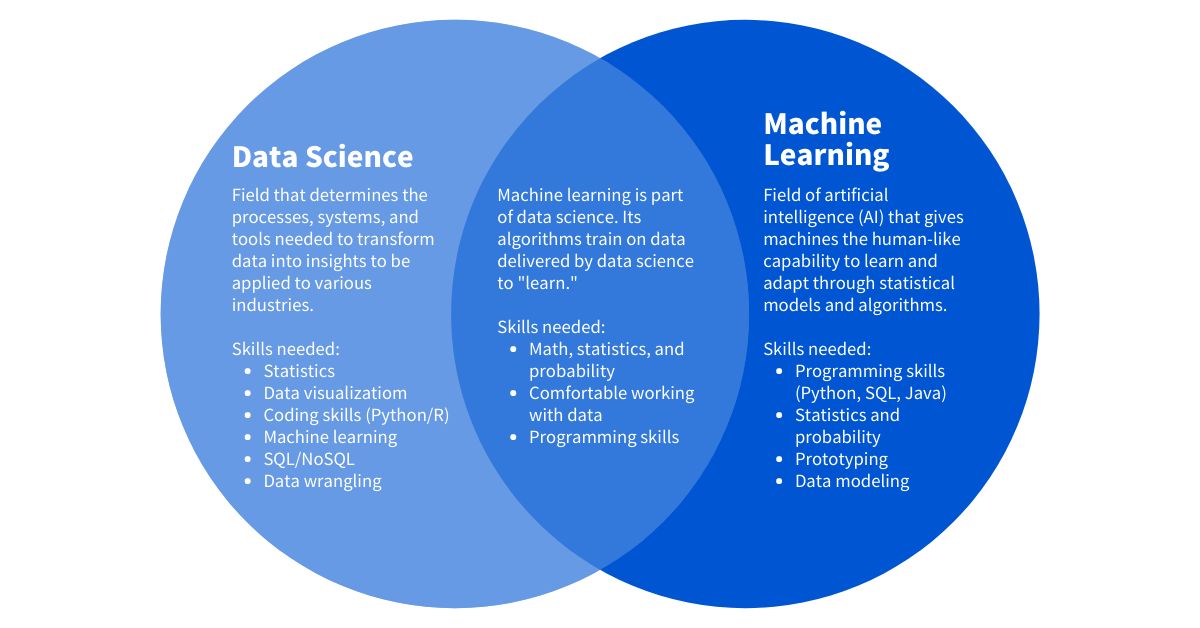
What is Machine Learning?
Machine learning is a subfield of artificial intelligence (AI) that focuses on the development of algorithms and models that enable computers to learn and make decisions without being explicitly programmed. In traditional programming, humans provide explicit instructions to computers to perform specific tasks. However, in machine learning, computers learn from data and use statistical techniques to make predictions or take actions.
At the core of machine learning is the ability of algorithms to identify patterns and relationships within data and make informed decisions based on those patterns. Machine learning algorithms can automatically adjust their performance and improve their accuracy over time as they are exposed to more data. This ability to learn from data is what sets machine learning apart from traditional programming.
There are different types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the algorithm is trained on labeled data, where each data point is associated with a known outcome or label. The algorithm learns to generalize from the labeled data and make predictions on new, unseen data. Supervised learning is commonly used for tasks such as classification or regression.
In unsupervised learning, the algorithm is given unlabeled data and is tasked with finding meaningful patterns or structures within the data. The goal is often to discover the underlying relationships between data points or group similar data points together. Unsupervised learning is widely used for tasks such as clustering or anomaly detection.
Reinforcement learning is a type of machine learning where an agent learns to interact with an environment and take actions to maximize a reward signal. The agent receives feedback on the quality of its actions and adjusts its behavior accordingly. Reinforcement learning is commonly used in applications such as game playing, robotics, and optimization problems.
Machine learning has numerous applications across various industries. It is used in image and speech recognition, natural language processing, recommendation systems, fraud detection, autonomous vehicles, and many other domains. The ability of machine learning algorithms to analyze large amounts of data and make predictions or decisions based on patterns has provided tremendous opportunities for innovation and efficiency.
In the next section, we will explore the importance of data in machine learning and understand why data is crucial for the success of machine learning models.
Importance of Data in Machine Learning
Data is the foundation of machine learning. It serves as the raw material from which algorithms learn, make predictions, and generate insights. The quality and quantity of data directly impact the performance and accuracy of machine learning models. Without relevant and reliable data, machine learning algorithms would be unable to effectively generalize and make accurate predictions on new, unseen data.
High-quality data is essential for training machine learning models. The data used for training should be representative of the real-world scenarios in which the model will be deployed. It should include a diverse range of examples and cover all possible outcomes or labels. By exposing the algorithm to various data patterns, it can learn to recognize and generalize from those patterns when faced with new, unknown data.
In addition to quality, the quantity of data also plays a significant role in machine learning. Generally, more data tends to lead to better model performance. Larger datasets provide a wider range of examples, increasing the chances of capturing complex relationships and avoiding biases that may be present in smaller datasets. However, the relationship between data quantity and model performance is not always linear, and there can be diminishing returns as the dataset grows beyond a certain point.
Data also helps in addressing the issue of overfitting in machine learning. Overfitting occurs when a model learns the training data too well, to the point that it fails to generalize to new data. By having sufficient and diverse data, machine learning models can better understand the underlying patterns and avoid becoming overly reliant on noise or outliers in the training data.
Another aspect to consider is the data quality and cleanliness. Poor quality data, such as missing values, inconsistent formats, or outliers, can significantly impact model performance. It is crucial to preprocess and clean the data before training the models to ensure accurate and reliable results. Data preprocessing techniques, such as normalization, feature engineering, and outlier detection, are essential steps in improving the quality of the training data.
It’s worth noting that data is not a one-time requirement in machine learning. Models need to be constantly updated and retrained with new data to adapt to changing patterns and improve performance. This process is known as continual learning or online learning. Additionally, machine learning models often require ongoing monitoring to ensure that they continue to perform well and remain unbiased as new data comes in.
In the next section, we will delve into the question of how much data is needed for machine learning and explore the factors that influence data requirements in machine learning models.
How Much Data is Needed for Machine Learning?
The amount of data required for machine learning depends on various factors, including the complexity of the problem, the diversity of the data, and the performance goals. Generally, having more data can lead to better model performance, but there is no definitive answer to how much data is needed for every machine learning task.
For simple classification or regression problems with well-defined features and patterns, a relatively small dataset might be sufficient. In such cases, a few hundred or thousand labeled examples can be enough to train a model that generalizes well to unseen data. As the complexity of the problem increases, however, more data is generally required to capture the intricacies of the underlying patterns.
Complex tasks such as natural language processing, computer vision, or speech recognition often demand much larger datasets. These tasks involve a wide range of input features and intricate relationships. Gathering and labeling a vast amount of data becomes necessary to train models that can accurately capture these complex patterns and make accurate predictions.
Furthermore, the concept of “big data” has gained significant attention in the field of machine learning. Big data refers to exceptionally large and complex datasets that cannot be easily managed or processed using traditional database systems. Big data often includes unstructured or semi-structured data from multiple sources, such as social media, sensor data, or customer interactions. Handling and processing big data require specialized techniques and technologies, such as distributed computing and parallel processing.
It’s important to note that the quantity of data alone is not the sole determining factor for model performance. The quality and representativeness of the data are equally important. Having a massive dataset that is noisy, biased, or unrepresentative of real-world scenarios can lead to poor model performance. Therefore, it is crucial to strike a balance between data quantity and data quality.
Furthermore, the number of classes or outcomes being predicted also plays a role in data requirements. Predicting binary outcomes (e.g., Yes/No) typically requires less data compared to multi-class classification problems with numerous distinct categories.
In practice, it is recommended to start with a reasonable amount of data and gradually increase the dataset size based on the model’s performance. This iterative process allows for better understanding of the data requirements and helps optimize the trade-off between data quantity and model performance.
In the next section, we will explore the factors that influence data requirements in machine learning models and discuss how the sample size and training data impact model performance.
Factors Affecting Data Requirements in Machine Learning
Several factors influence the data requirements of machine learning models. Understanding these factors is crucial for determining the amount and quality of data needed to train a model effectively. Let’s explore some of the key factors that play a role in data requirements:
- Complexity of the Problem: The complexity of the problem being addressed directly impacts the data requirements. Complex problems, such as natural language processing or computer vision, often require larger and more diverse datasets to capture the intricate relationships and patterns involved. Simpler problems with well-defined features may require smaller datasets.
- Data Diversity: Having diverse data is essential for building robust machine learning models. Diverse data helps the model generalize well and make accurate predictions on unseen examples. Data diversity can be achieved by including a wide range of examples that cover different variations, scenarios, or demographics related to the problem at hand.
- Performance Goals: The performance goals set for the machine learning model influence the data requirements. Models aimed at achieving high accuracy, precision, or recall may require larger datasets to capture the subtle nuances of the problem. On the other hand, models that prioritize speed or efficiency might require less data.
- Available Resources: The resources available for data collection and labeling also impact the data requirements. If there are limitations on time, budget, or human resources, it may not be feasible to collect or label a massive amount of data.
- Data Quality: The quality of data significantly affects the performance of machine learning models. Poor quality data, such as missing values, mislabeled examples, or inconsistent formats, can introduce noise and biases, which can lead to inaccurate predictions. Ensuring data quality through data cleaning, preprocessing, and validation is essential for reliable model performance.
- Data Balance: The distribution of data across different classes or outcomes can impact model performance. Imbalanced datasets, where one class dominates the data, can lead to biased models that perform poorly on underrepresented classes. Balancing the data by oversampling minority classes or undersampling majority classes can help address this issue.
- Domain Knowledge: The prior knowledge or domain expertise available about the problem can guide the data requirements. Understanding the intricacies of the problem and its underlying structure can inform decisions regarding the types of data to collect and the level of detail needed.
These factors highlight the complexity involved in determining the exact amount of data required for machine learning. It often requires a thorough analysis of the problem, the resources available, and the desired performance goals. Striking the right balance between data quantity, quality, and diversity is crucial for training robust and reliable models.
Next, we will explore the concept of “big data” in machine learning and its implications for data requirements.
The Concept of “Big Data” in Machine Learning
“Big data” refers to exceptionally large and complex datasets that traditional data processing techniques and systems struggle to handle effectively. The term is often associated with the three Vs: volume, velocity, and variety. Volume refers to the massive amount of data generated and collected from various sources, including social media, sensors, and transaction records. Velocity refers to the speed at which the data is generated, often in real-time, requiring quick processing. Variety refers to the diversity of the data, including structured, unstructured, and semi-structured data formats.
Big data has significant implications for machine learning, as it enables the discovery of valuable insights, patterns, and trends that would otherwise be challenging or impossible to uncover. By leveraging big data, machine learning models can make more accurate predictions and decisions, leading to improved outcomes in various domains, such as healthcare, finance, and marketing.
Big data provides opportunities for machine learning models to learn from a vast array of examples and capture complex relationships that may not be apparent in smaller datasets. With more diverse data, models can be trained to recognize subtle patterns and generalize better to new, unseen data.
However, big data also presents several challenges in terms of data requirements. The sheer volume of data can make it difficult to store, process, and analyze using traditional computing systems. Handling big data often requires specialized infrastructure and techniques, such as distributed computing, parallel processing, and cloud platforms, which can significantly impact the cost and resources needed for data processing.
Another challenge is the quality of big data. Large datasets may include noisy, incomplete, or inconsistent data, which can introduce biases or errors into the machine learning models. It is crucial to preprocess and clean the big data to ensure reliable and accurate results.
Privacy and ethical considerations are also important when dealing with big data. The massive amount of personal and sensitive information contained in big data requires careful handling to protect individuals’ privacy and comply with regulations and ethics guidelines.
In addition to the technical and ethical challenges, utilizing big data in machine learning requires expertise in data management, data analysis, and domain knowledge. The ability to extract meaningful information from big data and apply it effectively to machine learning models is a valuable skill in today’s data-driven world.
As technologies and techniques continue to evolve, big data will continue to play a significant role in advancing machine learning capabilities and unlocking new opportunities for innovation and insights. Harnessing the power of big data in machine learning requires a multidisciplinary approach that combines data science, domain expertise, and advanced computing techniques.
In the next section, we will explore the relationship between the sample size and training data and its impact on machine learning model performance.
Sample Size and Training Data
The sample size, or the amount of training data, is a critical factor that affects the performance of machine learning models. It refers to the number of examples or instances available for model training. The sample size plays a significant role in determining how well a machine learning model can learn and generalize from the data.
Generally, larger sample sizes tend to lead to better model performance. With more data, machine learning models can capture a wider range of patterns, relationships, and variations in the data, improving their ability to make accurate predictions on new, unseen examples. This is especially true for complex tasks that require a deep understanding of the underlying patterns.
However, the relationship between sample size and model performance is not always linear. The benefits of increasing the sample size may diminish beyond a certain point. This is known as the law of diminishing returns. Once the model has learned the core patterns and structures present in the data, additional data may not significantly improve the model’s performance.
The sample size also needs to be balanced with data quality. It is more important to have a smaller but high-quality dataset than a larger but noisy or biased dataset. A smaller dataset that is representative and clean can often yield better results than a larger dataset with data of lower quality.
Another important consideration is the distribution of the data. It is crucial to have a representative sample that covers all possible outcomes or labels in the data. Imbalanced datasets, where one class or outcome dominates, can lead to biased models with poor performance on minority classes. Techniques such as oversampling or undersampling can help address this issue and improve model performance.
Moreover, the sample size needs to be sufficient to cover the complexity of the problem at hand. Complex tasks that involve a wide range of features, classes, or variations may require larger sample sizes to capture the intricacies of the problem.
It’s important to note that the sample size alone is not the sole determinant of model performance. Other factors, such as the choice of algorithm, feature engineering, and model tuning, also play a crucial role. These factors interact with the sample size to collectively impact the overall model performance.
To determine the optimal sample size, it is often recommended to start with a reasonably sized dataset and iteratively evaluate model performance as more data is collected or sampled. This iterative process helps to understand the trade-off between data quantity and model performance, ensuring that the model is trained on a sufficient but manageable amount of data.
In the next section, we will discuss the issues of overfitting and underfitting in machine learning and their relationship with the sample size and training data.
Overfitting and Underfitting in Machine Learning
Overfitting and underfitting are common challenges in machine learning that arise when the model’s performance does not generalize well to new, unseen data. Understanding the concepts of overfitting and underfitting is crucial for optimizing model performance and avoiding inaccurate predictions or decisions.
Overfitting: Overfitting occurs when a machine learning model learns the training data too well, to the point that it fails to generalize to new data. It happens when the model fits the training data too closely, capturing not only the underlying patterns but also the noise or random fluctuations present in that data. As a result, the model may not perform well on unseen examples, as it overly relies on the specific details of the training data.
One of the main causes of overfitting is a small or biased training dataset. When the sample size is insufficient, the model may not be exposed to enough diverse examples to capture the true underlying patterns in the data. Consequently, it may memorize noise or outliers present in the training data, leading to poor performance on new data.
Another cause of overfitting can be the complexity of the model. Models with a large number of parameters or high flexibility have a higher tendency to overfit, as they can memorize the training data with greater fidelity. This is especially true when the model is more complex than necessary for the given task or when there is limited regularization or constraint on model complexity.
Underfitting: On the other hand, underfitting occurs when a machine learning model is too simple or lacks the capacity to capture the underlying patterns in the data. Underfitting commonly arises when the model is not complex enough or when the data is not representative of the problem’s variability. In underfitting, the model fails to capture the essence of the data and performs poorly on both the training data and new, unseen examples.
The key to achieving optimal model performance is to strike a balance between overfitting and underfitting. Both extreme situations lead to poor generalization and inaccurate predictions. The aim is to find the “sweet spot” where the model generalizes well to new examples but also captures the essential patterns present in the training data.
The sample size and diversity of the training data play crucial roles in mitigating overfitting and underfitting. Having a larger and more diverse dataset helps the model learn the underlying patterns of the problem while avoiding over-reliance on noise or incomplete information. It provides a broader and more representative view of the problem and improves generalization performance.
Regularization techniques, such as adding penalty terms to the model’s objective function or constraining the model complexity, can also help prevent overfitting. These techniques discourage the model from fitting the data too closely and encourage it to capture the essential patterns.
In the next section, we will discuss strategies for obtaining sufficient data to train machine learning models and improve their performance.
Strategies for Obtaining Sufficient Data
Obtaining sufficient data is crucial for training machine learning models effectively. Having a diverse and representative dataset improves model performance and generalization. However, collecting or accessing enough data can be a challenging task. Here are some strategies for obtaining sufficient data:
- Data Collection: One of the most straightforward approaches is to collect data specifically for the machine learning task at hand. This can involve designing surveys, conducting experiments, or implementing data collection systems. The data collection process should prioritize diversity and coverage to ensure that the dataset encompasses the various aspects of the problem.
- Data Augmentation: Data augmentation techniques can be employed to increase the size and diversity of the dataset. Augmentation involves creating new examples by applying transformations, modifications, or perturbations to the existing data. For example, in image classification, this could involve flipping, rotating, or zooming the images. Data augmentation helps to introduce variability into the dataset and can be particularly useful when the collection of new data is limited or time-consuming.
- Data Sharing: Collaboration and data-sharing initiatives can help overcome data limitations by pooling data from multiple sources. This approach allows access to a larger and more diverse dataset, enabling models to learn from a broader range of examples. However, privacy and ethical considerations must be taken into account when sharing data, ensuring secure and anonymized data sharing practices.
- Transfer Learning: Transfer learning is a technique where a pretrained model trained on a large, generic dataset is utilized as a starting point for a specific task. By leveraging the knowledge and features learned from the pretrained model, the amount of task-specific data required can be reduced. This is especially useful when the task at hand has limited data but shares similarities with a well-performing pretrained model.
- Active Learning: Active learning is an iterative approach that involves iteratively selecting and labeling the most informative and uncertain data points for annotation. By actively selecting the most relevant and informative examples to label, active learning maximizes the value of each labeled data point and reduces the amount of labeled data required. This strategy is particularly helpful when labeling data is expensive or time-consuming.
- Data Synthesis: In certain cases, where obtaining real-world data is difficult or expensive, synthetic or artificially generated data can be used to supplement the training dataset. Synthetic data is created based on modeling assumptions or algorithms, simulating the patterns and characteristics of the real data. While synthetic data can help increase the dataset size, it is crucial to ensure that it accurately represents the problem domain.
- Data Preprocessing: Often, the available data may contain noise, outliers, or irrelevant features. Data preprocessing techniques, such as cleaning, feature selection, and dimensionality reduction, can be applied to enhance the quality and relevance of the dataset. Removing noisy or irrelevant data points can effectively reduce the dataset without sacrificing model performance.
These strategies can help overcome data limitations and ensure that machine learning models are trained on sufficient and diverse datasets. The choice of strategy depends on the specific problem, available resources, and ethical considerations. It is essential to carefully consider the trade-offs between data quantity, quality, and representativeness to achieve optimal model performance.
In the next section, we will conclude our discussion and summarize the key points covered in this article.
Conclusion
Data plays a pivotal role in machine learning, serving as the foundation upon which models learn, make predictions, and generate insights. The amount and quality of data directly impact the performance and accuracy of machine learning models. While there is no definitive answer to how much data is needed for every machine learning task, several factors come into play.
The complexity of the problem, data diversity, performance goals, available resources, data quality, data balance, and domain knowledge all influence the data requirements of machine learning models. Striking the right balance between data quantity and quality is essential for training robust and accurate models.
Problems such as overfitting and underfitting highlight the importance of having an optimal sample size. Having a sample size that is too small can lead to underfitting, where the model fails to capture the underlying patterns. Conversely, having a sample size that is too large may result in overfitting, where the model memorizes noise in the data and fails to generalize well.
To obtain sufficient data, various strategies can be employed, such as data collection, data augmentation, data sharing, transfer learning, active learning, data synthesis, and data preprocessing. These strategies help overcome data limitations and enhance the diversity and representativeness of the dataset.
Ultimately, finding the right balance between data requirements and model performance is a continuous and iterative process. It requires careful consideration of the problem, available resources, and ethical considerations. By leveraging the power of data and employing effective strategies, machine learning models can achieve higher accuracy, make better predictions, and drive innovation across various industries.
As technology advances and new approaches to data collection, data management, and modeling techniques emerge, the field of machine learning continues to evolve. The insights gained from big data, the development of innovative algorithms, and the utilization of diverse and representative datasets pave the way for new discoveries and applications in the realm of machine learning.