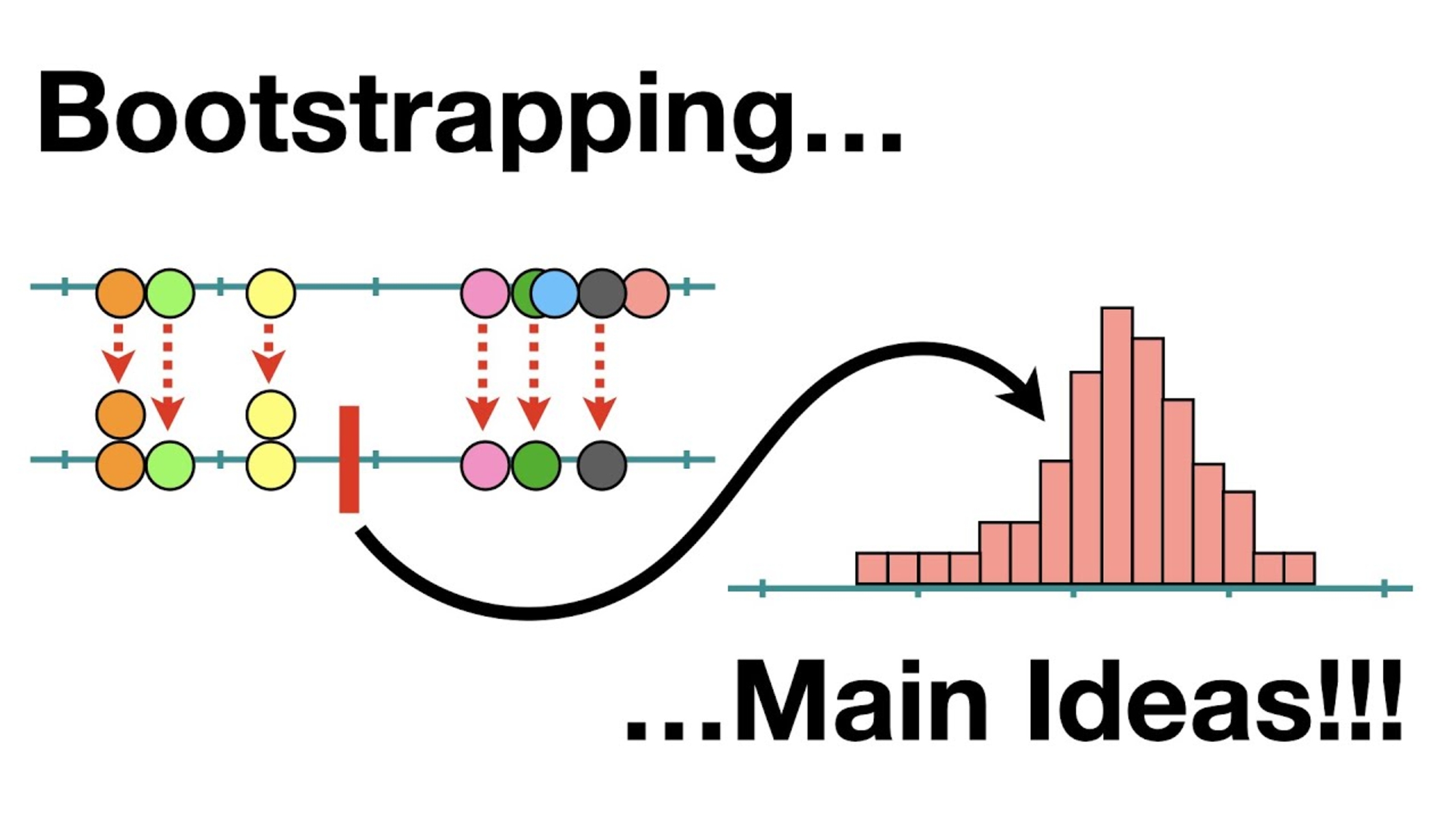
Introduction
Welcome to the world of machine learning! In this rapidly evolving field, where algorithms and models are used to analyze and make predictions from vast amounts of data, it is important to understand the concept of variance. Variance plays a crucial role in the accuracy and reliability of machine learning models, determining how much the predictions can vary or deviate from the expected outcome.
Variance, in the context of machine learning, refers to the variability or spread of predictions made by a model when presented with different training datasets. It measures how sensitive the model is to changes in the training data and indicates the model’s ability to generalize and make accurate predictions on unseen data.
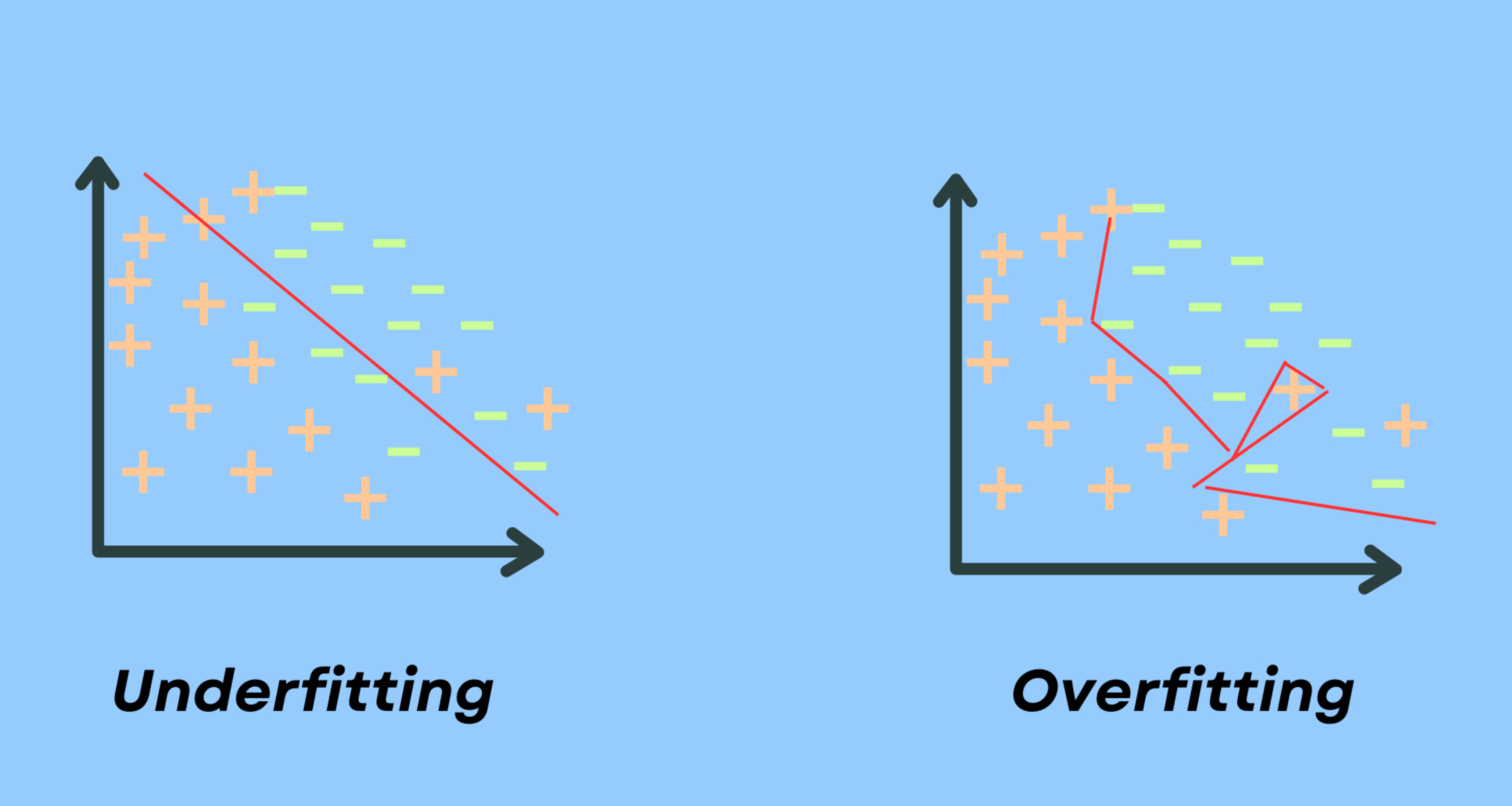
Why is variance important in machine learning? Well, high variance can lead to overfitting, while low variance can result in underfitting. Overfitting occurs when the model is too complex and learns the noise or random fluctuations in the training data, leading to poor performance on new data. Underfitting, on the other hand, happens when the model is not complex enough and fails to capture the underlying patterns and relationships in the data.
Understanding the sources of variance in machine learning models can help us identify and mitigate potential issues. One common source of variance is the choice of algorithm and model complexity. Complex models have a higher tendency to overfit, while simpler models may struggle to capture the complexities in the data.
Data quality and quantity also contribute to variance. Insufficient or noisy data can lead to high variance, as the model may not have enough information to make accurate predictions. Additionally, the randomness in the data can introduce variance, especially in situations where data points are sparse or the relationships between variables are weak.
Now that we have a basic understanding of variance in machine learning, let’s explore some examples to illustrate its impact. We will also discuss techniques to reduce variance and improve the performance of machine learning models. So, fasten your seatbelts as we embark on this exciting journey!
Definition of Variance
Before we delve deeper into variance in the context of machine learning, let’s start by understanding the definition of variance itself. In statistics, variance is a measure of how spread out a set of data points is from their mean or average value. It quantifies the dispersion of the data and provides insights into the variability or deviation from the expected outcomes.
Variance is calculated by taking the average of the squared differences between each data point and the mean of the dataset. Mathematically, it can be expressed as:
Variance = Σ(x – μ)² / N
Where:
x represents the individual data points,
μ denotes the mean of the dataset, and
N denotes the total number of data points.
A high variance indicates that the data points are spread out over a wider range, while a low variance suggests that the data points are closely clustered around the mean. Variance is often used as a measure of uncertainty, indicating the degree of fluctuation or noise in the data.
Now, when we apply the concept of variance to machine learning, it takes on a slightly different meaning. In this context, variance refers to the variability or spread of predictions made by a machine learning model when exposed to different training datasets. It assesses how sensitive the model is to changes in the training data and how well it can generalize to new, unseen data.
In simpler terms, variance in machine learning measures how much the predictions from a model can vary or deviate from the expected outcome. A high variance can lead to overfitting, where the model becomes too complex and captures noise or random fluctuations in the training data. On the other hand, a low variance can result in underfitting, where the model is unable to capture the underlying patterns and relationships in the data.
Understanding the concept of variance is essential in the field of machine learning as it helps us assess the performance and reliability of our models. By reducing variance, we can enhance the accuracy and robustness of our predictions, ensuring that our models generalize well to new data and provide meaningful insights.
Variance in Machine Learning
In the realm of machine learning, variance plays a pivotal role in determining the performance and reliability of predictive models. It refers to the variability or spread of predictions made by a model when presented with different training datasets. Understanding variance is essential for assessing the model’s ability to generalize and make accurate predictions on unseen data.
When a machine learning model is trained on a specific dataset, it learns the underlying patterns and relationships within that data. However, the model’s success in generalizing to new, unseen data depends on its ability to avoid overfitting, a situation where it learns the noise or random fluctuations in the training data rather than the true underlying patterns.
In the context of variance, high variance is synonymous with overfitting. A model with high variance is overly complex, capturing the noise in the training data rather than the true underlying patterns. As a result, when this model encounters new data, it may make predictions that are highly sensitive to small changes in the input, leading to less reliable or accurate results.
On the other hand, low variance is associated with underfitting. An underfit model is too simplistic and fails to capture the complexity in the training data. It oversimplifies the relationships and thus struggles to make accurate predictions on both the training data and new data. Underfitting often occurs when the model lacks the necessary complexity or is trained on inadequate amounts of data.
To strike a balance between overfitting and underfitting, it is crucial to manage the variance in machine learning models. The goal is to create models that can generalize well to new data by reducing variance without sacrificing the model’s ability to capture the true underlying patterns. This can be achieved through various techniques, such as regularization, cross-validation, and ensemble learning.
Regularization is a method used to control the complexity of a model by adding a penalty term to the loss function. By penalizing excessive complexity, regularization helps prevent overfitting and reduces variance. One popular form of regularization is L1 or L2 regularization, which adds a constraint to the model’s coefficients or weights.
Cross-validation is another technique that helps manage variance in machine learning models. It involves dividing the training data into multiple subsets to train and evaluate the model on different combinations of these subsets. Cross-validation can provide insights into the model’s performance on different variations of the training data, helping identify potential issues with high variance.
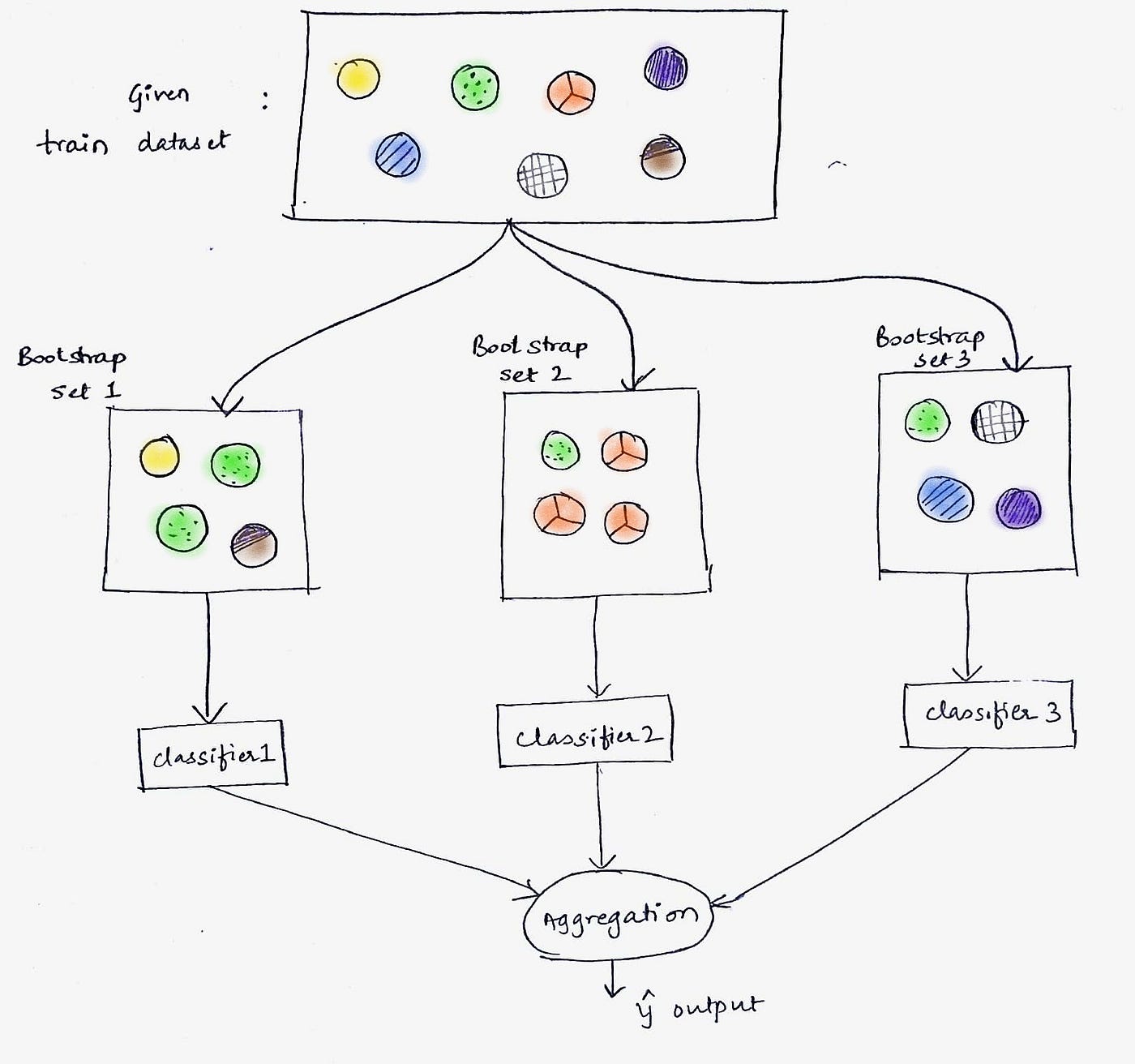
Ensemble learning is a powerful technique that combines predictions from multiple models to obtain a more accurate and robust prediction. By aggregating the predictions from diverse models, ensemble learning can help reduce variance and improve the overall performance of the model.
In summary, variance in machine learning refers to the variability or spread of predictions made by a model when presented with different training datasets. Managing variance is essential for developing robust and reliable machine learning models that can generalize well to new, unseen data. Techniques such as regularization, cross-validation, and ensemble learning can be employed to reduce variance and strike a balance between oversimplification and overfitting in the models.
Importance of Variance in Machine Learning
Variance plays a critical role in machine learning because it directly impacts the performance and reliability of predictive models. Understanding the importance of variance is essential for building accurate, robust models that can effectively handle new, unseen data.
High variance in machine learning models can lead to overfitting, where the model learns the noise or random fluctuations in the training data instead of the true underlying patterns. This can result in poor performance when the model encounters new data because it is too sensitive to minor changes in the input. Overfitting can cause the model to make unreliable or inaccurate predictions.
On the other hand, low variance can result in underfitting. Underfitting occurs when the model is too simplistic and fails to capture the complexity in the training data. It struggles to make accurate predictions both on the training data and new, unseen data. Low variance can be an indication that the model is not capable of learning and generalizing well.
The importance of managing variance lies in finding the right balance between overfitting and underfitting. By reducing variance, we can ensure that our models generalize well to new data and produce accurate predictions. This is particularly crucial when the models are deployed in real-world scenarios where the performance and reliability are of utmost importance.
Reducing variance is especially relevant in applications such as disease detection, financial forecasting, and customer churn prediction, where accurate predictions can have significant implications. In these scenarios, having a model with low variance ensures that the predictions are reliable and can be used to make informed decisions.
Moreover, managing variance is crucial to prevent models from becoming too dependent on the specific characteristics of the training data. By reducing variance, we can ensure that the models are able to capture the underlying patterns and relationships in the data, rather than simply memorizing the training examples.
Ultimately, the importance of variance in machine learning lies in its impact on the model’s ability to make accurate and reliable predictions on unseen data. By managing variance and finding the right balance between overfitting and underfitting, we can develop models that generalize well, improve decision-making, and provide valuable insights in various fields and industries.
Sources of Variance in Machine Learning Models
There are several factors that contribute to the presence of variance in machine learning models. Understanding the sources of variance is crucial for identifying potential issues and effectively managing variance to improve the performance and reliability of the models.
One of the primary sources of variance is the complexity of the model itself. More complex models, such as deep neural networks or models with a large number of features, often have a higher risk of overfitting and thus exhibit higher variance. These models have a greater capacity to capture the noise or random fluctuations in the training data, leading to less reliable predictions on new, unseen data.
The choice of algorithm also plays a significant role in variance. Different algorithms have varying degrees of complexity and inherent biases, which can contribute to variance in the models. For example, decision tree algorithms have a tendency to overfit if they are not properly regularized, which can introduce high variance in the predictions. On the other hand, linear models like linear regression or logistic regression tend to have lower variance when the number of features is small.
Data quality and quantity are also key sources of variance. Insufficient or noisy data can lead to high variance in the models because there may not be enough information to accurately capture the underlying patterns. Noise or outliers in the training data can introduce randomness and contribute to higher variability in the predictions. It is important to ensure that the training data is clean, representative, and sufficient to reduce variance in the models.
The randomness in the data itself can introduce variance, especially in situations where data points are sparse or the relationships between variables are weak. In such cases, the models may struggle to identify the true underlying patterns and tend to rely on random variations, leading to higher variance in the predictions.
The distribution of the training data compared to the distribution of the real-world data can also introduce variance. If the training data does not accurately represent the real-world distribution, the model may not generalize well to unseen data and exhibit high variance. This is particularly relevant in cases where the distribution of the data changes over time or across different domains.
Another source of variance is the randomness introduced during the training process itself. Machine learning models often involve a certain level of randomness, such as random initialization of model parameters or random shuffling of the training data. This can lead to slightly different outcomes and predictions when the model is trained multiple times on the same data, resulting in variance in the models.
By understanding the sources of variance in machine learning models, we can take steps to mitigate their effects and improve the reliability and accuracy of the predictions. Techniques such as regularization, cross-validation, and ensemble learning can be employed to reduce variance and improve the overall performance of the models.
Examples of Variance in Machine Learning
Understanding the concept of variance in machine learning is best illustrated through real-life examples. These examples demonstrate how variance can impact the performance and reliability of machine learning models in various domains and applications.
Example 1: Image Classification
In image classification tasks, high variance can lead to overfitting and inaccurate predictions. For instance, consider training a model to classify images of cats and dogs. If the model is overly complex, it may learn specific characteristics of the training images rather than generalizing the features that distinguish cats from dogs. Consequently, when new images are presented, the model may struggle to correctly classify them, resulting in high variance.
Example 2: Financial Predictions
In financial forecasting, variance can have significant consequences. For instance, a model trained to predict stock prices may exhibit high variance if it learns noise or random fluctuations in the historical stock data, leading to unreliable predictions. Similarly, in predicting currency exchange rates, a model with high variance may fail to capture the underlying economic factors, causing inaccurate forecasts that can negatively impact investment decisions.
Example 3: Natural Language Processing
In natural language processing (NLP), variance can affect sentiment analysis and text classification tasks. A model trained to identify sentiment in customer reviews may overfit to specific phrases or words in the training data, resulting in high variance. Consequently, when faced with new reviews that have different sentence structures or vocabulary, the model may struggle to accurately classify the sentiment, leading to inconsistent predictions.
Example 4: Fraud Detection
In fraud detection, variance is crucial to ensure accurate identification of fraudulent transactions. A model with high variance may wrongly classify legitimate transactions as fraudulent or fail to detect actual fraud cases. This occurs when the model overfits to the specific patterns of known fraud instances, rather than capturing the general characteristics of fraudulent activity. As a result, the model becomes sensitive to minor variations in features and exhibits high variance in its predictions.
These examples highlight the importance of managing variance in machine learning models across various domains. By understanding and reducing variance, we can develop models that generalize well to new data, make accurate predictions, and provide reliable insights in tasks ranging from image classification and financial forecasting to natural language processing and fraud detection.
Techniques to Reduce Variance in Machine Learning Models
Reducing variance in machine learning models helps improve their performance and generalization ability. There are several effective techniques that can be employed to mitigate the impact of variance and ensure more reliable and accurate predictions.
1. Regularization: Regularization is a widely used technique to control the complexity of a model and reduce variance. By adding a penalty term to the loss function, regularization discourages the model from excessively fitting the training data. Common regularization techniques include L1 and L2 regularization, which add constraints on the magnitude of the model’s coefficients or weights. Regularization helps prevent overfitting and encourages better generalization to new, unseen data.
2. Cross-Validation: Cross-validation is a valuable technique for estimating the performance and managing variance in machine learning models. It involves dividing the training data into subsets, performing multiple iterations of training and evaluation, and computing the average performance metrics. Cross-validation provides a more robust estimate of the model’s performance on different variations of the training data, helping to identify and mitigate issues related to high variance.
3. Ensemble Learning: Ensemble learning combines the predictions of multiple models to obtain a more accurate and robust prediction. By aggregating the predictions from diverse models, ensemble learning helps reduce variance and improve overall model performance. Techniques such as bagging (Bootstrap Aggregating) and boosting (AdaBoost, Gradient Boosting) are popular approaches for implementing ensemble learning. Bagging creates multiple subsets of the training data and trains different models on each subset, while boosting combines weak models sequentially to create a strong model.
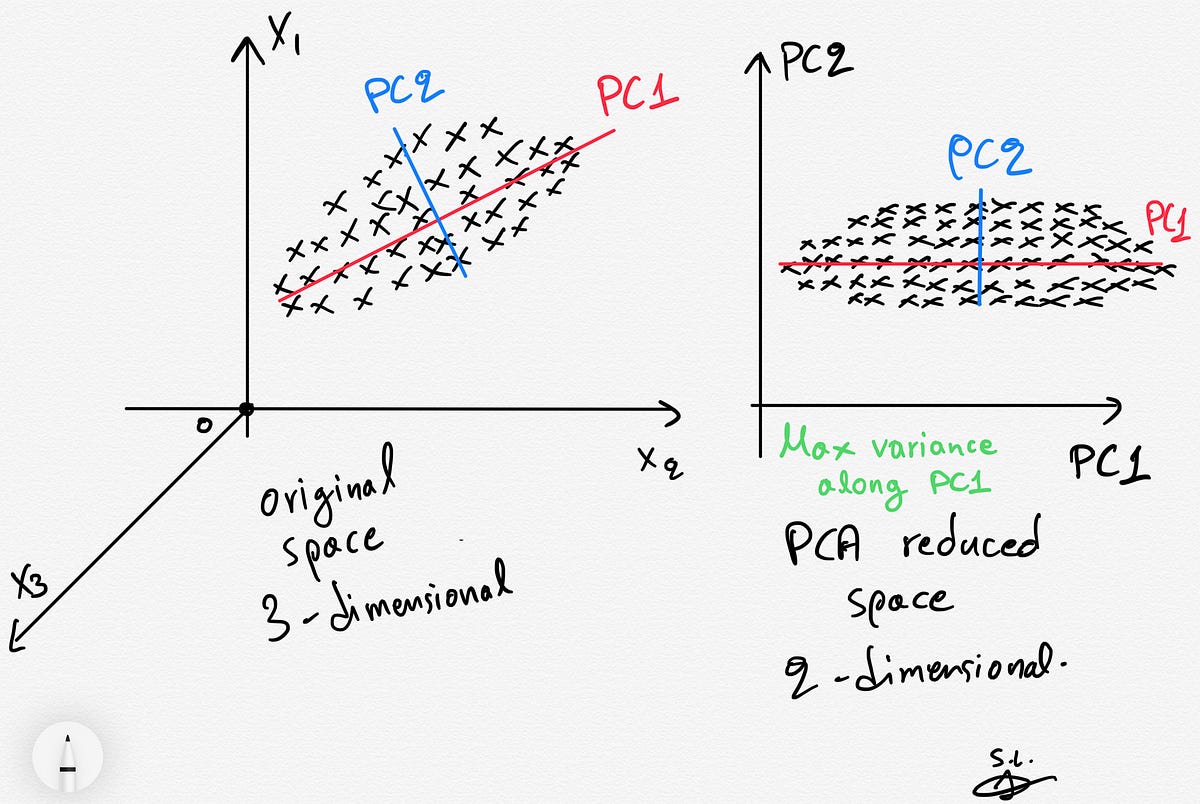
4. Feature Selection and Extraction: Carefully selecting relevant features and extracting meaningful information from the data can help reduce variance. Feature selection techniques identify the most informative features that contribute to the model’s performance, discarding irrelevant or redundant features that may introduce noise or fluctuations. Dimensionality reduction techniques such as Principal Component Analysis (PCA) or Singular Value Decomposition (SVD) can also be used to extract essential information from high-dimensional data, reducing the complexity and potential for variance.
5. Increasing Training Data: Insufficient data can contribute to high variance, as the model may struggle to generalize well. Adding more diverse and representative data points to the training set can help reduce variance by providing the model with a broader range of examples to learn from. Collecting additional data or using techniques such as data augmentation can help ensure sufficient representation and reduce the influence of random variations in the predictions.
6. Early Stopping: Early stopping is a technique used during the training process to prevent overfitting and reduce variance. It involves monitoring the model’s performance on a separate validation dataset during training and stopping the training process when the model performance on the validation set starts to deteriorate. By stopping the training at an optimal point, early stopping helps prevent the model from becoming overly complex and capturing noise in the training data.
These techniques provide effective strategies for reducing variance in machine learning models. By employing regularization, cross-validation, ensemble learning, feature selection, increasing training data, and utilizing early stopping, we can improve the model’s ability to generalize, make more accurate predictions, and produce reliable results in a variety of machine learning tasks.
Conclusion
Variance is a crucial concept in machine learning that directly impacts the performance and reliability of predictive models. By understanding and managing variance, we can develop models that generalize well to new, unseen data and make accurate predictions. High variance, often associated with overfitting, can lead to unreliable and inconsistent predictions, while low variance, related to underfitting, may result in models that cannot capture the complexity of the data.
Throughout this article, we have explored the definition of variance, its importance in machine learning, and the sources of variance in models. We have seen examples of how variance can affect image classification, financial predictions, natural language processing, and fraud detection. Additionally, we have discussed various techniques to reduce variance, including regularization, cross-validation, ensemble learning, feature selection, increasing training data, and early stopping.
Reducing variance is crucial for improving the generalization ability and accuracy of machine learning models. By employing these techniques, we can strike a balance between overfitting and underfitting, enabling the models to capture the true underlying patterns of the data without being overly reliant on noise or random fluctuations. This, in turn, leads to more reliable predictions and more effective decision-making in a wide range of domains.
As researchers and practitioners continue to advance the field of machine learning, managing variance will remain a critical aspect of model development. By staying vigilant and employing appropriate techniques to reduce variance, we can continue to push the boundaries of what is possible with machine learning and harness its power to drive innovation and solve complex problems.