Introduction
A data pipeline plays a crucial role in managing the vast amounts of data generated in the world of big data. In today’s digital landscape, organizations are constantly collecting, processing, and analyzing data to gain valuable insights that can drive strategic decision-making. However, handling massive volumes of data can be a daunting task, which is where data pipelines come into play.
A data pipeline is a set of processes and tools that facilitate the seamless flow of data from various sources to its destination, such as a data warehouse or analytics platform. It involves ingesting, storing, processing, transforming, integrating, and analyzing data to ensure its quality, reliability, and accessibility.
Data pipelines are designed to handle the challenges associated with big data, including its velocity, variety, and volume. With the exponential growth of data, traditional approaches to data management are no longer sufficient. A well-architected data pipeline provides a scalable and efficient way to handle large datasets and enables organizations to leverage the full potential of their data.
While the specifics of data pipelines may vary depending on the organization and its specific requirements, they generally consist of several key components. These components work together to ensure the smooth flow of data throughout the pipeline, from ingestion to analysis.
In this article, we will explore the various components of a data pipeline and discuss the benefits they offer in the context of big data. Understanding these components will provide a foundation for building or optimizing data pipelines to handle the complexities of managing and processing large-scale data.
What is a Data Pipeline?
A data pipeline is a system or a set of processes that enables the flow of data from its source to its destination, typically involving data ingestion, storage, processing, transformation, integration, and analysis. It provides a structured and automated approach to handle the movement and manipulation of data through various stages.
Data pipelines are essential in the world of big data because they establish a framework for efficiently managing and processing large volumes of data. By orchestrating the flow of data, pipelines ensure that data is collected, organized, and transformed in a way that makes it accessible and usable for analysis and decision-making.
The primary goal of a data pipeline is to eliminate the need for manual intervention or ad-hoc processes when dealing with data. By automating the movement and transformation of data, organizations can reduce errors, improve efficiency, and ensure data consistency across different stages of the pipeline.
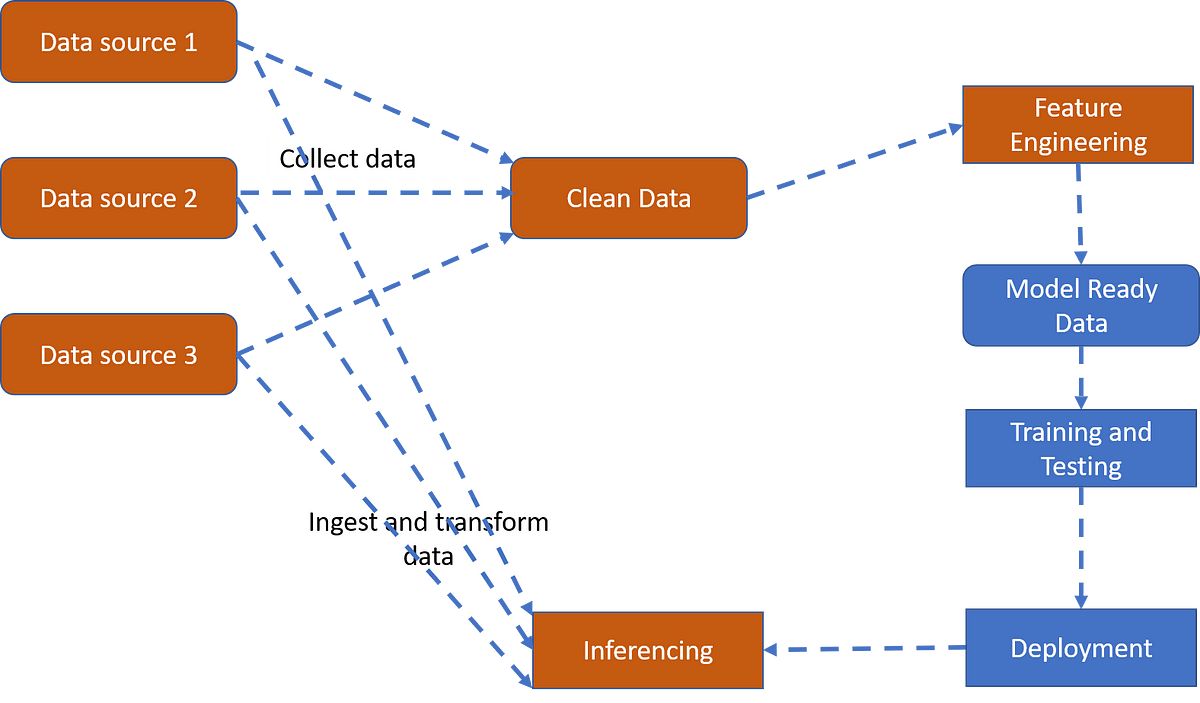
A data pipeline typically starts with data ingestion, where data is collected from various sources such as databases, APIs, or streaming platforms. Once the data is collected, it moves to the data storage phase, where it is stored in a scalable and reliable repository for further processing. Data processing involves performing operations on the data, such as filtering, aggregating, or cleaning, to prepare it for analysis.
Data transformation is another critical component of a data pipeline. It involves converting the data into a desired format or structure that is suitable for downstream processes, such as data integration or analysis. Data integration combines data from different sources or systems to create a unified view of the data, enabling comprehensive analysis and insights.
The final stage of a data pipeline is data analysis, where the transformed and integrated data is used to extract valuable insights and drive decision-making. This stage may involve various analytical techniques, such as statistical analysis, machine learning algorithms, or visualization tools, to uncover patterns, trends, and correlations in the data.
Overall, a data pipeline serves as the backbone of data-driven organizations, enabling them to extract value from big data. It streamlines the data management process, ensures data quality and consistency, and empowers organizations to make informed decisions based on timely and accurate insights.
Components of a Data Pipeline
A data pipeline is composed of several key components that work together to ensure the seamless flow of data through different stages. These components are essential for processing, transforming, and integrating data effectively. Let’s explore each of these components:
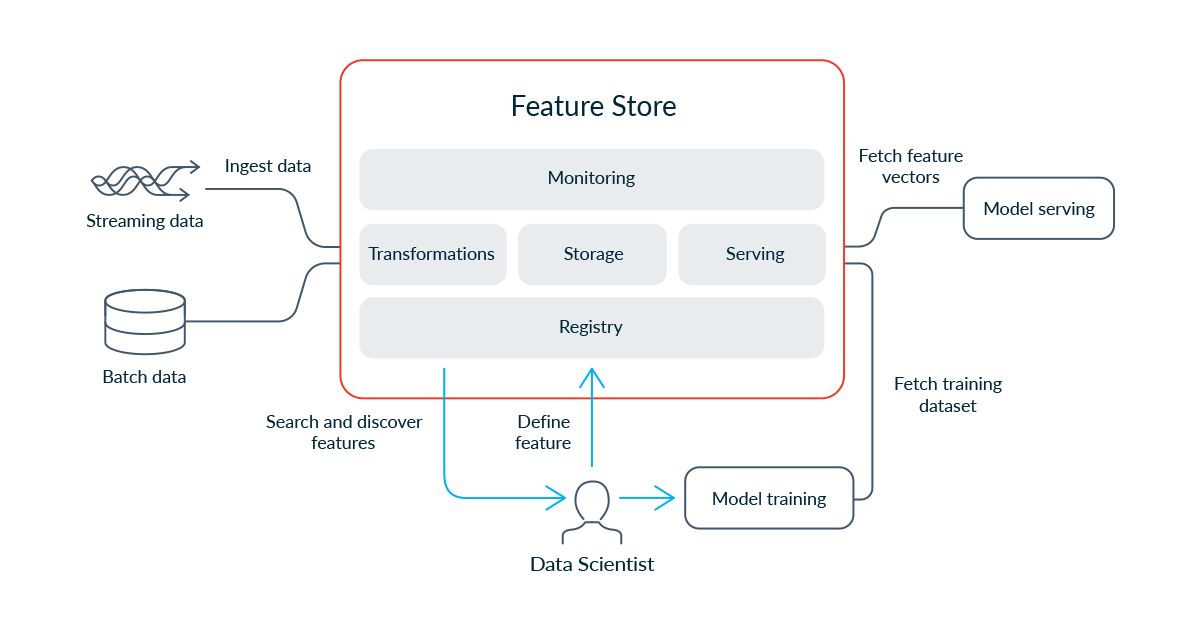
- Data Ingestion: This component involves the collection and ingestion of data from various sources. It can include extracting data from databases, APIs, log files, or streaming platforms. Data ingestion ensures that the pipeline receives data from diverse sources and prepares it for further processing.
- Data Storage: Once the data is ingested, it needs to be stored in a reliable and scalable data repository. Data storage can involve traditional databases, data warehouses, data lakes, or cloud-based storage systems. The choice of storage depends on factors such as data volume, velocity, and the required access pattern.
- Data Processing: The data processing component involves performing operations on the data to cleanse, transform, or enrich it. This step ensures that the data is in a consistent and usable format for downstream analysis. Data processing can include tasks like data validation, data deduplication, or data enrichment through aggregations or calculations.
- Data Transformation: Data transformation involves converting the data to a desired format or structure. It can include tasks like data normalization, data denormalization, data format conversion, or data schema changes. Data transformation ensures that the data is in a standardized format suitable for downstream processes.
- Data Integration: Data integration combines data from multiple sources or systems to create a unified view. It enables the seamless integration of different data sets, ensuring consistency and accuracy in the final data output. Data integration can involve tasks like data merging, data blending, or data synchronization.
- Data Analysis: The data analysis component focuses on extracting insights and meaningful information from the processed and integrated data. It involves using statistical techniques, machine learning algorithms, or visualization tools to discover patterns, trends, and correlations in the data. Data analysis helps organizations derive valuable insights to support decision-making.
By incorporating these components into a well-designed data pipeline, organizations can efficiently manage the flow of data, ensure data quality, and enable advanced analytics. Each component plays a crucial role in the overall data pipeline architecture, contributing to the success of data-driven initiatives.
Data Ingestion
Data ingestion is the first component of a data pipeline and involves the process of collecting and importing data from various sources into the pipeline. This component is crucial as it sets the foundation for data processing, transformation, and analysis.
Data can be ingested from a wide range of sources, including databases, web services, log files, sensors, social media platforms, and more. The data ingestion process can be either near real-time or batch-based, depending on the nature of the data and the requirements of the pipeline.
There are different methods for data ingestion, depending on the source and the requirements of the organization. Some common methods include:
- Direct Database Access: In this method, data is extracted directly from databases using specific connectors or APIs. This approach is beneficial when data is stored in structured databases and needs to be continuously synchronized with the data pipeline.
- File Upload: Data can be ingested by uploading files, such as CSV, JSON, or XML, into the pipeline. This is a common approach for importing data from external systems or legacy applications.
- API Integration: Many platforms and services provide APIs that allow data to be retrieved in real-time. By integrating these APIs into the data pipeline, organizations can stream data directly into the pipeline without the need for manual file uploads.
- Streaming Data: In scenarios where data needs to be processed in real-time, streaming frameworks like Apache Kafka or Apache Flink can be used for continuous ingestion. This approach is particularly useful for handling large volumes of data generated from sources like IoT devices or social media platforms.
Regardless of the method used for data ingestion, it is important to ensure the reliability, scalability, and security of the process. Techniques such as change data capture (CDC), data validation, and error handling mechanisms should be implemented to ensure the accuracy and integrity of the ingested data.
Data ingestion is a critical step in a data pipeline as it sets the stage for subsequent data processing and analysis. The success of downstream tasks relies heavily on the proper and efficient ingestion of data. Organizations must carefully plan and implement a robust data ingestion strategy to ensure a smooth and reliable flow of data into the pipeline.
Data Storage
The data storage component is a critical part of a data pipeline, responsible for securely and efficiently storing the ingested data. Effective data storage ensures that the data is readily available for processing, transformation, and analysis within the pipeline.
When considering data storage options for a data pipeline, several factors need to be taken into account, including scalability, performance, data integrity, and cost. Common data storage solutions used in data pipelines include:
- Relational Databases: Relational databases, such as MySQL, PostgreSQL, or Oracle, are commonly used for structured data storage. They offer ACID (Atomicity, Consistency, Isolation, Durability) properties and provide robust data management capabilities.
- Data Warehouses: Data warehouses, like Amazon Redshift or Snowflake, are specifically designed for storing and analyzing large amounts of structured data. They offer features such as columnar storage, compression, and optimized query performance.
- Data Lakes: Data lakes, such as Hadoop Distributed File System (HDFS) or cloud-based solutions like Amazon S3 or Google Cloud Storage, are repositories that store vast amounts of unstructured or semi-structured data. Data lakes are highly scalable and allow flexible schema evolution.
- NoSQL Databases: NoSQL databases, such as MongoDB or Cassandra, are suitable for storing unstructured or semi-structured data. They provide high scalability, fast write and read operations, and flexible data modeling.
- In-Memory Databases: In-memory databases, like Redis or Apache Ignite, store data in memory, providing extremely fast data access. They are often used for caching frequently accessed data or real-time analytics.
Organizations must choose the appropriate storage solution based on their data requirements, data volume, and performance needs. Hybrid storage solutions, combining different storage technologies, are also becoming increasingly popular to leverage the strengths of each storage system.
It is important to ensure data security and data governance while storing data in a data pipeline. Data encryption, access control mechanisms, and compliance with data protection regulations are essential considerations when designing the data storage component.
The data storage component of a data pipeline should be designed to handle the volume, velocity, and variety of data efficiently. Additionally, it should provide mechanisms for data replication, backup, and disaster recovery to ensure data availability and integrity.
By selecting the appropriate data storage solution and implementing sound data management practices, organizations can ensure that the ingested data is securely stored and readily available for further processing and analysis within the data pipeline.
Data Processing
The data processing component of a data pipeline focuses on performing operations and transformations on the ingested data to prepare it for analysis and other downstream tasks. Data processing plays a crucial role in ensuring data quality, consistency, and usability within the pipeline.
Data processing involves a variety of tasks, including data cleaning, filtering, aggregating, and joining. These tasks help in organizing and refining the data to make it suitable for analysis and further processing.
Some common techniques and tools used for data processing in a data pipeline are:
- Data Cleaning: Data cleaning involves identifying and fixing errors, inconsistencies, and missing values in the data. This can include tasks like removing duplicates, correcting formatting issues, or imputing missing values to ensure data integrity.
- Data Filtering: Data filtering allows the extraction of specific subsets of data based on predefined criteria. Filtering can be done to exclude irrelevant or redundant data, ensuring that only relevant data is processed further.
- Data Aggregation: Data aggregation involves combining multiple data records into larger units, such as calculating average values, sums, or counts. Aggregation can help in reducing the volume of the data while preserving key information for analysis.
- Data Joining: Data joining is the process of combining data from multiple sources by matching common fields or keys. Joining allows the enrichment of data by merging information from different datasets into a single cohesive unit.
- Data Validation: Data validation ensures the integrity and accuracy of the data by performing checks and validations against predefined rules or constraints. This helps in identifying and handling data that does not meet specific quality standards.
Data processing techniques can be implemented using various tools and frameworks, such as SQL for relational databases, Apache Spark for distributed processing, or Python libraries like pandas for data manipulation. These tools provide robust capabilities for efficient data processing at scale.
The aim of data processing in a data pipeline is to transform raw data into a format that is actionable, meaningful, and ready for analysis. It sets the stage for downstream tasks such as data transformation, integration, and analysis.
By implementing effective data processing techniques, organizations can ensure that their data is clean, accurate, and properly structured, enabling them to derive valuable insights and make informed decisions based on reliable data.
Data Transformation
The data transformation component of a data pipeline focuses on converting and reshaping the data into a desired format or structure. Data transformation plays a vital role in preparing the data for downstream processes such as data integration or analysis.
Data transformation involves various operations such as data normalization, denormalization, format conversion, or schema changes. These operations help ensure that the data is in a standardized and consistent format that can be easily processed and analyzed.
Some common data transformation tasks performed in a data pipeline include:
- Data Normalization: Data normalization involves restructuring the data to eliminate redundancy and eliminate data anomalies. This process ensures that data is organized efficiently and reduces the chances of inconsistent or duplicate data.
- Data Denormalization: Denormalization is the process of combining data from multiple tables or sources to create a single, flattened dataset. This simplifies data access and improves query performance, especially for analytical operations.
- Data Format Conversion: Data format conversion may be necessary to transform data from one format to another. For example, converting data from CSV to JSON or XML to JSON, or vice versa, allows for easier integration with different systems or tools.
- Data Schema Changes: Data schema changes involve modifying the structure or layout of the data. This could include adding or removing columns, renaming fields, or altering the data types to better align with the needs of downstream processes.
- Data Enrichment: Data enrichment involves enhancing the existing data with additional information from external sources. This can include appending geolocation data, demographic data, or other relevant attributes to enrich the dataset and enable more comprehensive analysis.
Data transformation tasks can be performed using various techniques and tools. This can range from using SQL queries for simple transformations to employing ETL (Extract, Transform, Load) tools or data integration platforms for complex and large-scale transformations.
The ultimate goal of data transformation is to ensure that the data is in a uniform and usable state, enabling downstream processes like data integration and analysis to be more efficient and accurate. By transforming the data into a desired format, organizations can improve data quality, enhance data interoperability, and gain deeper insights from the data.
Effective data transformation techniques and tools empower organizations to unlock the full potential of their data assets and enable data-driven decision-making.
Data Integration
Data integration is a crucial component of a data pipeline that involves combining and consolidating data from multiple sources into a unified view. The goal of data integration is to create a comprehensive and cohesive dataset that can be utilized for analysis, reporting, and decision-making.
Organizations often have data stored in various systems, databases, or formats, making it challenging to derive meaningful insights. Data integration bridges these gaps by merging data from disparate sources, enabling a holistic view of the data.
Data integration can be achieved through various techniques and strategies:
- Data Consolidation: Data consolidation involves the aggregation of data from multiple sources into a single location or repository. This allows for a centralized and unified dataset for analysis and reporting purposes.
- Data Harmonization: Data harmonization is the process of mapping and aligning data from different sources to ensure consistency and interoperability. It involves resolving differences in data formats, structures, and semantics to create a standardized view of the data.
- Data Synchronization: Data synchronization ensures that data across different systems or databases is kept consistent and up-to-date. This can involve real-time or near real-time updates to ensure that all instances of the data reflect the latest changes.
- Data Federation: Data federation allows for virtual integration, where data remains in its original source but appears to be unified through a logical view. This approach provides a federated view of the data, eliminating the need to physically move or replicate data.
- Data Mastering: Data mastering involves identifying and merging duplicate or overlapping data records to create a single, accurate representation. This helps in reducing data redundancy and increasing data quality.
Data integration can be performed using various tools and technologies, including ETL (Extract, Transform, Load) processes, data integration platforms, or data virtualization tools. These tools streamline the process of integrating data from different sources and provide mechanisms for data cleansing, transformation, and reconciliation.
It is essential to ensure data consistency, reliability, and security during the integration process. Validating and verifying the integrity of the integrated data, implementing data governance policies, and addressing data quality issues are crucial aspects of successful data integration.
By integrating data from various sources into a unified view, organizations can uncover valuable insights, identify trends, and make informed decisions. Data integration maximizes the value of data assets and enables organizations to derive meaningful and actionable information from their data pipelines.
Data Analysis
Data analysis is a critical component of a data pipeline that focuses on extracting valuable insights and meaningful information from the processed and integrated data. It involves applying various techniques, tools, and methodologies to uncover patterns, trends, and correlations within the data.
Data analysis can be performed at different levels, ranging from simple descriptive statistics to advanced predictive modeling and machine learning algorithms. The goal is to transform raw data into actionable insights that can drive decision-making and strategic planning.
Data analysis involves several key tasks:
- Descriptive Analysis: Descriptive analysis provides a summary and visualization of the data, such as mean, median, mode, frequency distributions, or charts. Descriptive analysis helps in understanding the basic characteristics and patterns within the data.
- Diagnostic Analysis: Diagnostic analysis aims to identify the causes or factors contributing to specific outcomes or observations in the data. It involves analyzing relationships, dependencies, or anomalies within the data to uncover underlying patterns or issues.
- Predictive Analysis: Predictive analysis utilizes statistical and machine learning techniques to make predictions or forecasts based on historical data. It involves building models that can predict future trends or outcomes and enable proactive decision-making.
- Prescriptive Analysis: Prescriptive analysis goes beyond predictive analysis by prescribing actions or recommendations based on the insights derived from the data. It helps in optimizing processes, identifying opportunities, and guiding decision-making towards the most optimal course of actions.
Data analysis can be performed using a range of tools, programming languages, and technologies. Popular options include statistical software like R or Python’s data analysis libraries (e.g., pandas, numpy), as well as advanced analytics platforms like Microsoft Power BI or Tableau.
By conducting thorough data analysis, organizations gain valuable insights into customer behavior, market trends, operational efficiency, and various other aspects of their business. These insights serve as a foundation for evidence-based decision-making, helping organizations improve performance, identify opportunities, and mitigate risks.
Ultimately, data analysis empowers organizations to make data-driven decisions, uncover hidden insights, and gain a competitive advantage in today’s data-driven landscape.
Benefits of Data Pipelines in Big Data
Data pipelines play a crucial role in managing and harnessing the power of big data. They offer numerous benefits that enable organizations to efficiently process, analyze, and derive insights from vast volumes of data. Here are some key advantages of data pipelines in the context of big data:
- Scalability: Data pipelines provide a scalable solution for handling large-scale data processing. They allow organizations to ingest, store, and process massive volumes of data without compromising performance or data integrity. With the ability to scale horizontally, data pipelines can accommodate growing datasets and increasing data velocity efficiently.
- Efficiency: By automating the data flow and incorporating streamlined processes, data pipelines optimize the efficiency of data operations. They eliminate manual intervention, reduce the risk of human errors, and ensure that data processing tasks are performed consistently and reliably. This results in faster data processing and analysis, enabling organizations to make timely decisions based on real-time or near-real-time insights.
- Data Quality: Data pipelines enforce data quality standards throughout the pipeline. From data ingestion to data transformation and integration, data pipelines implement data validation, cleansing, and enrichment techniques to ensure that data is accurate, complete, and consistent. This promotes better data reliability, allowing organizations to make informed decisions based on trustworthy and high-quality data.
- Data Integration: Data pipelines provide a framework for integrating data from various sources, whether structured, unstructured, or semi-structured. By consolidating data into a single unified view, data pipelines enable organizations to gain a comprehensive understanding of their data assets. This integration facilitates cross-functional analysis, enables data-driven decision-making, and improves collaboration within the organization.
- Flexibility: Data pipelines offer flexibility in terms of data processing and analysis. They allow organizations to adapt and evolve their data pipelines to accommodate changing business needs, data sources, or analytical requirements. This flexibility enables organizations to stay agile and responsive in the face of evolving data landscapes and business demands.
- Cost-effectiveness: By automating data operations and leveraging scalable cloud-based storage and computing resources, data pipelines provide a cost-effective solution for managing big data. They eliminate the need for manual and resource-intensive data processes, reduce infrastructure costs, and allow organizations to leverage cloud-based services to scale their data pipelines as needed.
Overall, data pipelines significantly enhance the value and utility of big data. They streamline data processing, ensure data quality, promote data integration, and offer scalability and cost-efficiency. With these benefits, organizations can leverage the full potential of big data to gain valuable insights, make data-driven decisions, and achieve a competitive edge in the digital age.
Conclusion
Data pipelines play a critical role in managing and leveraging the vast amounts of data generated in the world of big data. They provide a structured and efficient framework for ingesting, storing, processing, transforming, integrating, and analyzing data. By automating these processes, data pipelines enable organizations to extract valuable insights, make informed decisions, and derive competitive advantages.
Throughout this article, we explored the essential components of a data pipeline, including data ingestion, storage, processing, transformation, integration, and analysis. Each component serves a specific purpose in ensuring the seamless flow of data and maximizing its value within the pipeline.
Data pipelines offer numerous benefits for organizations dealing with big data. They provide scalability, allowing organizations to handle massive volumes of data and accommodate growing datasets. They enhance efficiency by automating data processes, reducing human errors, and enabling faster data processing and analysis. Data pipelines also promote data quality, integration, and flexibility, ensuring that organizations can make data-driven decisions based on reliable, comprehensive, and up-to-date insights.
Moreover, data pipelines bring cost-effectiveness by leveraging cloud-based services and eliminating the need for manual and resource-intensive data operations. This enables organizations to optimize their data infrastructure and efficiently scale their data processing capabilities.
In conclusion, data pipelines play a pivotal role in harnessing the power of big data. They empower organizations to unlock the true potential of their data assets, derive meaningful insights, and gain a competitive edge in today’s data-driven business landscape. By implementing well-designed and optimized data pipelines, organizations can navigate the complexities of big data, make informed decisions, and propel their growth and success in the digital era.