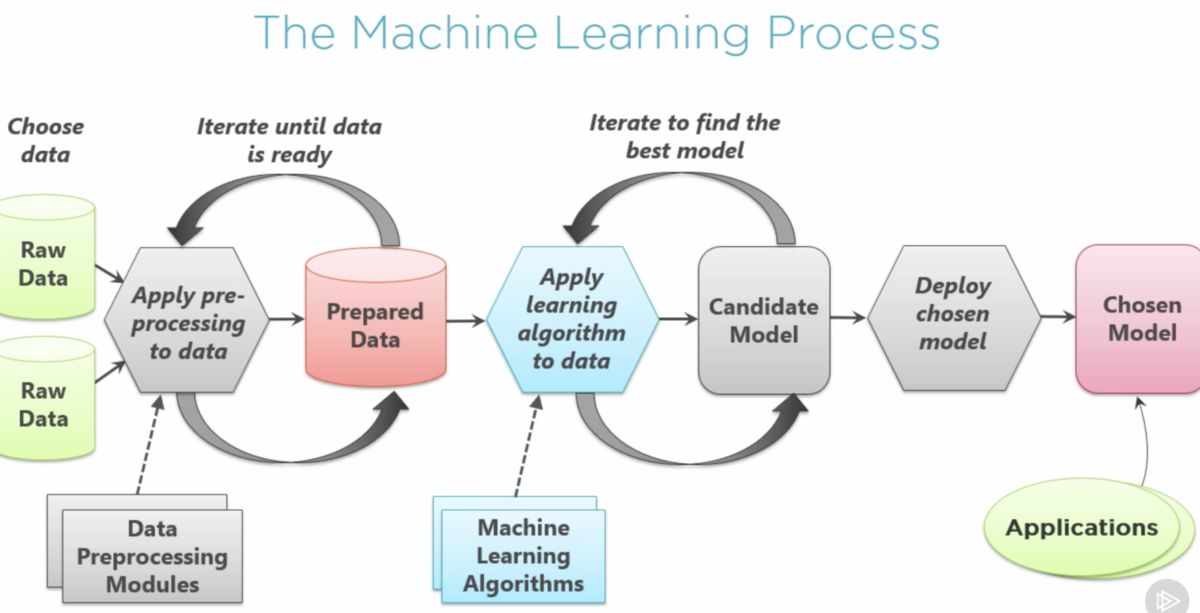
Introduction
Machine Learning (ML) has revolutionized various industries by enabling computers to learn from data and make predictions or decisions without being explicitly programmed. Machine learning models are the backbone of these applications, as they are trained on large datasets to identify patterns, make accurate predictions, or classify new data. However, building an effective machine learning model is only the first step. Testing these models is crucial to ensure their performance, reliability, and generalizability in real-world scenarios.
Testing machine learning models involves evaluating their performance, identifying potential issues, and fine-tuning their parameters to optimize their effectiveness. It also helps determine if the models are overfitting or underfitting the data—two commonly encountered problems in machine learning. Testing is essential to ensure that the models can handle new and unseen data, and that they are robust and reliable.
This article provides a comprehensive guide on how to test machine learning models. We will explore various aspects of testing, including data preparation, cross-validation techniques, evaluation metrics, feature selection, hyperparameter tuning, handling class imbalance, testing for robustness and generalization, and considering ethical considerations.
By following the best practices outlined in this guide, you can ensure that your machine learning models are accurate, reliable, and capable of delivering high-quality predictions or decisions. So let’s dive in and discover the various testing techniques and considerations that will help you achieve optimal performance with your machine learning models.
Understanding Machine Learning Models
Before diving into testing machine learning models, it’s important to have a clear understanding of what these models are and how they work. Machine learning models are algorithms that learn from data to make predictions, identify patterns, or classify new instances without being explicitly programmed.
There are two main types of machine learning models: supervised learning and unsupervised learning. In supervised learning, the model is trained using labeled data, where each instance has a corresponding label or target variable. The model learns from this labeled data to make predictions on new, unseen data.
On the other hand, unsupervised learning models are trained on unlabeled data, where the model learns to identify patterns or group similar instances without any predefined labels. Unsupervised learning is useful for tasks like clustering and anomaly detection.
Machine learning models are typically represented as mathematical functions that map the input variables (features) to the target variable or prediction. These models can be linear (such as linear regression), nonlinear (such as decision trees or neural networks), or probabilistic (such as naive Bayes or support vector machines).
During the training process, the machine learning model adjusts its parameters to minimize the difference between its predicted output and the actual output from the training data. This is done through an optimization process called gradient descent or other optimization algorithms.
Understanding the underlying concepts and algorithms of machine learning models is crucial for effective testing. It allows you to identify potential limitations, biases, and assumptions of the model. It also helps you select appropriate testing techniques, evaluation metrics, and interpret the results correctly.
Now that we have a solid foundation in understanding machine learning models, let’s explore the process of testing these models and ensuring their performance and reliability.
Overview of Testing Machine Learning Models
Testing machine learning models is a critical step in the development process to assess their performance, accuracy, and generalizability. This process involves evaluating how well the models perform on unseen data and understanding their limitations and potential pitfalls.
There are several key aspects to consider when testing machine learning models:
- Data Preparation: Before testing a machine learning model, it is important to properly prepare the data. This involves cleaning the data, handling missing values, and transforming the features into a suitable format for the model. Data preparation ensures that the model receives high-quality and relevant data for testing.
- Cross-Validation Techniques: Cross-validation is a popular technique used to assess a model’s performance by splitting the data into multiple subsets (or folds). The model is trained on a subset of the data and tested on the remaining fold. This process is repeated multiple times to get a more reliable estimate of the model’s performance.
- Evaluation Metrics: Evaluation metrics quantify the performance of the machine learning model. Common evaluation metrics include accuracy, precision, recall, F1 score, and area under the receiver operating characteristic (ROC) curve. Choosing the appropriate evaluation metrics depends on the specific problem and the nature of the data.
- Overfitting and Underfitting: Overfitting occurs when a machine learning model performs well on the training data but fails to generalize to new, unseen data. Underfitting, on the other hand, occurs when the model is too simplistic and fails to capture the underlying patterns in the data. Proper testing helps identify and address these issues to improve model performance.
- Feature Selection: Feature selection techniques are used to identify the most relevant and informative features for the model. By selecting the right set of features, the model can achieve better performance and reduce complexity. Testing different feature subsets can help in identifying the most important features for the model.
- Hyperparameter Tuning: Machine learning models have hyperparameters, which are adjustable settings that control the learning process. Testing different combinations of hyperparameters helps optimize the model’s performance. Techniques like grid search or random search can be used to find the best hyperparameter values.
- Class Imbalance: In many machine learning applications, the dataset may have imbalanced classes, where one class dominates the other. Testing with imbalanced data can lead to biased performance metrics. Techniques such as upsampling, downsampling, or using weighted metrics can help address this issue.
- Robustness and Generalization: A well-tested machine learning model should demonstrate robustness and generalization capabilities. Robustness refers to how well the model performs under varying conditions or perturbations in the data. Generalization refers to the model’s ability to perform well on new, unseen data.
- Ethical Considerations: Testing machine learning models should also consider ethical dimensions such as fairness, privacy, and potential biases. It is important to ensure that the models do not perpetuate discriminatory practices or violate user privacy.
By thoroughly testing machine learning models and addressing these key aspects, developers can build more robust and reliable models that deliver accurate predictions or decisions. In the following sections, we will delve deeper into each aspect of testing and explore best practices and techniques.
Data Preparation for Testing
Data preparation is a crucial step in testing machine learning models as it ensures that the data used for testing is of high quality and is appropriately formatted for the model’s inputs. Proper data preparation helps improve the accuracy and reliability of the model’s performance evaluation.
Here are some important considerations for data preparation when testing machine learning models:
- Cleaning the Data: This step involves identifying and handling missing values, outliers, and inconsistencies in the dataset. Missing values can be treated by imputation techniques such as mean, median, or mode imputation, or by removing instances with missing values entirely if it doesn’t significantly impact the dataset size.
- Feature Scaling: It is essential to scale the features to a similar range to prevent certain features from dominating the model’s learning process. Common scaling techniques include standardization (subtracting the mean and dividing by the standard deviation) or normalization (scaling to a specific range, e.g., [0, 1]).
- Encoding Categorical Variables: If the dataset includes categorical variables, they need to be encoded into numerical values. One-hot encoding is a popular technique where each category is represented by a binary feature column. Another approach is label encoding, which assigns an integer value to each category. Care should be taken to apply the appropriate encoding based on the nature of the categorical variable.
- Feature Engineering: Feature engineering involves creating new informative features from the existing ones. This can include mathematical transformations, interaction terms, or creating new features based on domain knowledge. Feature engineering enables the model to capture more complex relationships and improve its performance.
- Handling Imbalanced Classes: If the dataset has imbalanced classes, where one class is significantly more prevalent than the others, it can lead to biased model evaluation. Techniques such as upsampling the minority class, downsampling the majority class, or using weighted evaluation metrics can help address this issue.
- Splitting the Data: Before testing the machine learning model, the dataset should be split into training and testing sets. The training set is used to train the model, while the testing set is used to evaluate its performance. It is important to ensure that the data is split randomly to avoid any inherent biases in the ordering of the instances.
Proper data preparation ensures that the machine learning model is tested on reliable and representative data. It helps identify any issues or inconsistencies that may affect the model’s performance. By following best practices in data preparation, you can enhance the accuracy and reliability of the model’s testing process.
Cross-Validation Techniques
Cross-validation is a crucial technique in testing machine learning models that allows for a more reliable assessment of their performance. It involves splitting the dataset into multiple subsets, or folds, and training and testing the model on different combinations of these folds. Cross-validation helps to mitigate the impact of randomness and provides a more robust estimate of the model’s performance.
Here are some common cross-validation techniques used in testing machine learning models:
- K-Fold Cross-Validation: In K-fold cross-validation, the dataset is divided into K equal-sized folds. The model is trained on K-1 folds combined and tested on the remaining fold. This process is repeated K times with each fold serving as the test set once. The performance measures from each iteration are then averaged to obtain a more reliable estimate of the model’s performance.
- Stratified K-Fold Cross-Validation: Stratified K-fold cross-validation is especially useful when dealing with imbalanced datasets, where the distribution of classes is unequal. It ensures that each fold maintains the proportion of classes similar to the whole dataset, thus reducing biases in performance evaluation.
- Leave-One-Out Cross-Validation: In leave-one-out cross-validation, each instance in the dataset is used as a test set, and the model is trained on the remaining instances. This process is repeated for all instances. Leave-one-out cross-validation provides a more rigorous evaluation but can be computationally expensive for large datasets.
- Time Series Cross-Validation: When working with time series data, it is important to consider the temporal aspect in cross-validation. Time series cross-validation involves splitting the data chronologically, ensuring that the training set contains data from earlier time periods, and the test set contains data from later time periods. This helps evaluate the model’s ability to generalize to future data.
- Repeated Cross-Validation: Repeated cross-validation is performed by repeating the cross-validation process multiple times with different random splits of the data. This helps reduce the impact of any particular random split and provides a more robust estimate of the model’s performance.
Cross-validation techniques help assess how well the machine learning model will perform on unseen data. By training and testing the model on different subsets of the data, cross-validation provides a more reliable estimate of the model’s performance and helps identify any biases or overfitting issues.
Choosing the appropriate cross-validation technique depends on the nature of the dataset, the problem at hand, and the available computational resources. By incorporating cross-validation into the testing process, you can obtain more accurate and trustworthy assessments of your machine learning models.
Evaluation Metrics for Model Performance
Evaluation metrics are essential in testing machine learning models to quantify their performance and assess their predictive capabilities. These metrics provide insights into how well the model is able to make accurate predictions and classify instances correctly. The choice of evaluation metrics depends on the specific problem at hand and the nature of the data.
Here are some commonly used evaluation metrics for assessing the performance of machine learning models:
- Accuracy: Accuracy measures the proportion of correctly classified instances out of the total number of instances. It provides a general measure of how well the model predicts the correct class. However, accuracy can be misleading when dealing with imbalanced datasets, where the class distribution is uneven.
- Precision: Precision measures the proportion of correctly predicted positive instances out of the total instances predicted as positive. It focuses on the accuracy of positive predictions. Precision is useful when the cost of false positives is high, such as in medical diagnosis or fraud detection scenarios.
- Recall (Sensitivity / True Positive Rate): Recall measures the proportion of correctly predicted positive instances out of the total actual positive instances. It focuses on how well the model captures all positive instances. Recall is important when the cost of false negatives (missed positive instances) is high, such as in disease detection or spam email filtering.
- F1 Score: F1 score is the harmonic mean of precision and recall. It provides a balanced measure of a model’s performance by considering both precision and recall. F1 score is particularly useful in situations where there is an uneven class distribution and an equal emphasis on precision and recall is desired.
- Area Under the ROC Curve (AUC-ROC): AUC-ROC is a performance metric used in binary classification problems. It measures the model’s ability to discriminate between positive and negative instances across different threshold values. A higher AUC-ROC value indicates better model performance.
- Mean Squared Error (MSE): MSE is a commonly used metric for regression problems. It measures the average squared difference between the predicted and actual values. Lower MSE values indicate better model performance.
- R-squared (Coefficient of Determination): R-squared measures the proportion of the variance in the target variable that is explained by the model. It ranges from 0 to 1, with higher values indicating a better fit of the model to the data.
These evaluation metrics provide insights into different aspects of the model’s performance. Depending on the specific problem and goals, one or more of these metrics can be selected to assess and compare different machine learning models.
It’s important to keep in mind that evaluation metrics need to be interpreted in the context of the problem and that no single metric can provide a complete picture of a model’s performance. Evaluating multiple metrics and considering domain knowledge helps to make informed decisions and select the most appropriate model for deployment.
Testing for Overfitting and Underfitting
Overfitting and underfitting are common challenges in machine learning models that can adversely affect their performance and generalizability. Testing for overfitting and underfitting helps identify these issues and allows for appropriate adjustments to improve model performance.
Overfitting: Overfitting occurs when a machine learning model performs exceptionally well on the training data but fails to generalize to new, unseen data. In such cases, the model becomes too complex and starts memorizing the patterns and noise in the training data, rather than learning the underlying patterns. As a result, it does not perform well on real-world instances.
Testing for overfitting involves evaluating the model’s performance on a separate testing set or using techniques like cross-validation. If the model demonstrates significantly better performance on the training data compared to the testing data, it indicates overfitting. Common signs of overfitting include high training accuracy but low testing accuracy or a large difference between the training and testing performance.
To address overfitting, several techniques can be adopted, such as:
- Reducing model complexity by using simpler algorithms or reducing the number of features.
- Increasing the amount of training data to capture more diverse patterns.
- Applying regularization techniques to penalize complex models or features.
- Using ensemble methods such as bagging or boosting to combine multiple models.
Underfitting: Underfitting, in contrast, occurs when the machine learning model is too simple to capture the underlying patterns in the data. It generally leads to poor performance on both the training and testing data. An underfit model may have low accuracy, low precision, or low recall, indicating that it fails to learn from the data effectively.
Testing for underfitting involves evaluating the model’s performance on the training and testing data. If both the training and testing accuracy are low and similar, it suggests underfitting. Underfitting can also be indicated by a high bias error and a large difference between the training and testing performance.
To address underfitting, some techniques that can be applied include:
- Using more complex models or algorithms that can capture the complexity of the data.
- Increasing the number of features to include more relevant information.
- Collecting more data to provide a richer representation of the underlying patterns.
- Experimenting with different preprocessing techniques or transformations to enhance the information in the features.
Testing for overfitting and underfitting helps identify and address model performance issues. It is imperative to strike a balance between model complexity and generalization, ensuring that the model can perform well on unseen data and deliver accurate predictions in real-world scenarios.
Techniques for Feature Selection
Feature selection is a vital step in testing machine learning models, as it helps identify the most relevant and informative features for the predictive task. Selecting the right set of features can improve model performance, reduce complexity, and prevent overfitting. There are several techniques available for feature selection, each with its own advantages and considerations.
Here are some common techniques for feature selection:
- Filter Methods: Filter methods assess the relevance of features based on statistical characteristics of the data, such as correlation, variance, or mutual information. Features are ranked or assigned scores, and a threshold is set to select the top-ranked features. Common filter methods include Pearson’s correlation coefficient, chi-square test, or information gain.
- Wrapper Methods: Wrapper methods evaluate feature subsets by training and testing the model on different combinations of features. It involves an iterative process of feature selection, typically using algorithms like forward selection, backward elimination, or recursive feature elimination. Wrapper methods provide a more accurate assessment of feature subsets but can be computationally expensive.
- Embedded Methods: Embedded methods incorporate feature selection within the model training process. Some machine learning algorithms, like Lasso regression or decision trees with feature importance measures, inherently perform feature selection as part of their learning process. These methods consider the relevance of features during model training, reducing the need for separate feature selection.
- Dimensionality Reduction: Dimensionality reduction techniques, such as principal component analysis (PCA) or singular value decomposition (SVD), transform the original features into a lower-dimensional space while preserving the most important information. These techniques help reduce the complexity and redundancy in the data and can enhance model performance.
When selecting features, it’s important to strike a balance between the number of features and the model’s performance. Too many irrelevant or redundant features can lead to overfitting, while too few relevant features may result in underfitting. Moreover, domain knowledge and understanding of the problem can guide the selection process by identifying the most informative features.
It’s essential to evaluate the performance of the model with different subsets of features using appropriate evaluation metrics. This helps identify the optimal set of features that yields the best model performance.
By employing effective feature selection techniques, you can improve the model’s accuracy, reduce computational complexity, and enhance interpretability. It also ensures that the model focuses on the most relevant information for making accurate predictions or decisions.
Hyperparameter Tuning
Hyperparameter tuning is a crucial step in testing machine learning models to optimize their performance. Hyperparameters are adjustable settings that control the learning process of the model and cannot be learned from the data. Tuning these hyperparameters helps fine-tune the model, improve its performance, and enhance its ability to capture the underlying patterns in the data.
Here are some techniques commonly used for hyperparameter tuning:
- Grid Search: Grid search involves defining a grid of possible hyperparameter values and systematically evaluating the model’s performance for each combination. This approach exhaustively searches through all possible combinations, making it more time-consuming but thorough.
- Random Search: Random search randomly selects hyperparameter values from predefined ranges and evaluates the model’s performance for each combination. This approach is less computationally intensive compared to grid search but still provides a good exploration of the hyperparameter space.
- Bayesian Optimization: Bayesian optimization is an efficient technique that builds a probability model of the hyperparameter space and selects hyperparameters with the highest expected improvement. It uses prior information and an acquisition function to guide the search towards the most promising regions of the hyperparameter space for better performance.
- Gradient-based Optimization: Gradient-based optimization techniques, such as gradient descent or stochastic gradient descent, can be used to optimize hyperparameters. These techniques iteratively update the hyperparameters based on the gradients of the performance metric with respect to the hyperparameters.
- Ensemble Methods: Ensemble methods, like random forests or gradient boosting, can be utilized for hyperparameter tuning. By training multiple models with different hyperparameter settings and combining their predictions, ensemble methods help to find optimal combinations of hyperparameters and improve the overall performance.
During hyperparameter tuning, it is essential to split the data into training, validation, and testing sets. The training set is used to train the model, the validation set is used to evaluate different hyperparameter combinations, and the testing set is reserved for the final evaluation of the fully trained model.
Hyperparameter tuning aims to strike a balance between underfitting and overfitting and find the optimal configuration for the model. It requires careful consideration and experimentation with various hyperparameter values to identify the combination that yields the best performance on the validation set.
By employing effective hyperparameter tuning techniques, you can optimize the model’s performance, improve its accuracy, and ensure that it is tailored specifically to the dataset at hand. This iterative process of tuning plays a crucial role in building high-performing machine learning models.
Handling Class Imbalance in Testing
Class imbalance occurs when the distribution of classes in a dataset is significantly skewed, with one class being more prevalent than the others. This poses a challenge in testing machine learning models, as they can become biased towards the majority class and perform poorly on minority classes. Hence, special attention is required to handle class imbalance effectively during testing.
Here are some techniques that can be employed to address class imbalance in testing:
- Upsampling: Upsampling involves randomly duplicating instances from the minority class to increase its representation in the dataset. This helps in balancing the class distribution and provides the model with more examples to learn from. However, care should be taken to avoid overfitting and introducing noise by indiscriminately oversampling the minority class.
- Downsampling: Downsampling involves randomly removing instances from the majority class to reduce its dominance in the dataset. This can be an effective way to balance the class distribution. However, downsampling may result in the loss of potentially valuable information, and important patterns from the majority class may be underrepresented.
- Using Synthetic Samples: Synthetic sample generation techniques, such as SMOTE (Synthetic Minority Over-sampling Technique), can be employed to create new instances for the minority class by interpolating between existing instances. This helps in generating a balanced dataset and can improve the model’s ability to learn the minority class.
- Weighted Metrics: Instead of using traditional evaluation metrics, weighted metrics can be utilized to account for class imbalance. Weighted metrics give more importance to minority class performance, ensuring that the model’s evaluation is not biased towards the majority class.
- Cost-Sensitive Learning: Cost-sensitive learning assigns higher misclassification costs to the minority class to encourage the model to prioritize correct predictions for the minority class. This approach focuses on minimizing the overall cost rather than just optimizing accuracy.
When handling class imbalance, it is essential to ensure that the testing set reflects the original class distribution present in real-world scenarios. Thus, the selection of the testing set should consider the relative proportions of the classes to evaluate the model’s performance accurately.
It is important to note that the choice of technique for handling class imbalance should be based on the characteristics of the dataset, the objectives of the machine learning task, and the available resources. Experimentation and careful evaluation of different approaches can help determine the most suitable technique for addressing class imbalance in testing.
By appropriately handling class imbalance in testing, machine learning models can provide more accurate predictions for all classes and avoid the bias towards the majority class. This enhances the reliability and fairness of the model’s performance evaluation in real-world scenarios.
Testing for Robustness and Generalization
Testing machine learning models for robustness and generalization is essential to ensure that they can perform reliably and accurately in real-world scenarios. Robustness refers to a model’s ability to maintain its performance under varying conditions or perturbations in the data, while generalization measures how well the model can apply its learned knowledge to new, unseen data.
Here are some considerations for testing the robustness and generalization of machine learning models:
- Varying Test Data: Testing a model with varying test data is crucial to assess its robustness. By introducing different distributions, noise, or outliers in the test data, you can evaluate how well the model can handle different scenarios and if its performance remains consistent.
- Cross-Domain Testing: Cross-domain testing involves evaluating the model’s performance on data from different sources or domains. This helps determine if the model can generalize its learned knowledge to new data that might have different characteristics.
- Out-of-Domain Detection: Testing for out-of-domain detection involves assessing the model’s ability to recognize instances that fall outside the domain it was trained on. This helps identify cases where the model may struggle or provide unreliable predictions.
- Temporal Testing: If working with time series data, it is important to conduct temporal testing to evaluate the model’s performance on new, future data. This helps gauge the model’s ability to generalize and make accurate predictions for upcoming instances.
- Error Analysis: Performing an error analysis helps uncover patterns and understand the reasons behind the model’s mistakes. This can help identify areas where the model may need improvement and guide further adjustments or feature engineering.
- Model Monitoring: Continuously monitoring the model’s performance in a production environment is essential to ensure its ongoing robustness and generalization. Regular testing and evaluation help identify any drift or degradation in performance, prompting necessary updates or retraining.
Robustness and generalization testing should reflect real-world conditions and potential challenges that the model may encounter. It is important to consider a variety of scenarios and test the model on diverse datasets to evaluate its performance across different contexts and distributions.
By conducting rigorous testing for robustness and generalization, machine learning models can demonstrate the ability to perform reliably, handle variations in the data, and generalize well to unseen instances. This ensures their effectiveness and utility in real-world applications and improves their overall performance and reliability.
Ethical Considerations in Testing Machine Learning Models
While testing machine learning models, it is crucial to consider ethical implications to ensure fairness, privacy, and avoid potential biases. Ethical considerations play a significant role in building responsible and accountable models that align with societal values. Here are some important ethical considerations in testing machine learning models:
- Fairness and Bias: Testing for fairness involves evaluating whether the model’s predictions or decisions are unbiased and do not discriminate against particular individuals or groups. It is important to monitor and mitigate biases that may arise from the training data or the model’s learning process to avoid perpetuating discrimination or unfair treatment.
- Privacy Protection: Testing machine learning models requires handling sensitive data. It is essential to ensure that privacy protection measures are in place to safeguard the confidentiality and privacy of individuals’ information. This includes practices such as data anonymization, secure data storage, and strict access controls.
- Transparency and Explainability: Machine learning models should be transparent and provide explanations for their predictions or decisions, especially in domains where transparency and interpretability are crucial, such as healthcare or finance. Testing for model explainability helps ensure transparency, accountability, and user trust.
- Model Governance: Establishing governance processes during testing is necessary to manage potential risks and ensure responsible use of machine learning models. This includes defining guidelines, regularly auditing the model’s performance, and having mechanisms in place to address biases, privacy concerns, or adverse impacts that may arise during testing.
- Data Bias and Representativeness: Testing should focus on evaluating the performance of the model across different demographic groups to identify potential biases or disparities in predictions. It is important to ensure that the training data is representative of the target population to avoid biased models and ensure equitable outcomes.
- Fair Use and Responsible Deployment: Testing should consider the intended use of the model and evaluate whether it aligns with legal and ethical standards. Assessing potential harms, unintended consequences, and societal impacts helps identify any issues that may arise from deploying the model in real-world scenarios.
Ethical considerations in testing machine learning models require a comprehensive and holistic approach. It involves carefully examining the potential risks, biases, and societal impact associated with the model’s predictions or decisions. By addressing these ethical considerations, we can develop models that are fair, unbiased, transparent, and respectful of privacy.
It is important to involve diverse stakeholders, including ethicists, domain experts, and impacted communities, in the testing process to ensure a broad perspective and incorporate ethical principles into the design, evaluation, and deployment of machine learning models.
Conclusion
Testing machine learning models is a critical step in their development to ensure their performance, reliability, and generalizability. By following best practices and incorporating various testing techniques, developers can build models that are accurate, robust, and capable of handling real-world scenarios.
The testing process involves understanding the model, preparing the data, selecting appropriate evaluation metrics, and addressing common challenges such as overfitting, underfitting, and class imbalance. Techniques like cross-validation, hyperparameter tuning, and feature selection help improve model performance and ensure optimal results.
Additionally, ethical considerations play a crucial role in testing machine learning models. By addressing issues such as fairness, privacy, transparency, and responsible deployment, developers can ensure that the models align with societal values and avoid biases or discriminatory outcomes.
It is important to approach testing with an open mind and be willing to iterate and refine the model based on the insights gained. Regular monitoring of model performance and continuous evaluation in real-world settings help maintain robustness and performance over time.
In conclusion, the testing of machine learning models is a comprehensive and iterative process that requires careful consideration of various factors. By incorporating best practices, addressing challenges, and considering ethical implications, developers can build models that provide accurate predictions, handle uncertainties, and contribute positively to society.