Introduction
Welcome to the world of machine learning! As technology advances, the ability to derive insights, make predictions, and automate processes using data has become increasingly essential. Machine learning, a subfield of artificial intelligence, offers powerful tools and techniques to analyze and extract valuable information from datasets. However, before we can delve into the realm of machine learning algorithms, it is crucial to properly prepare and preprocess the data to ensure accurate and reliable results.
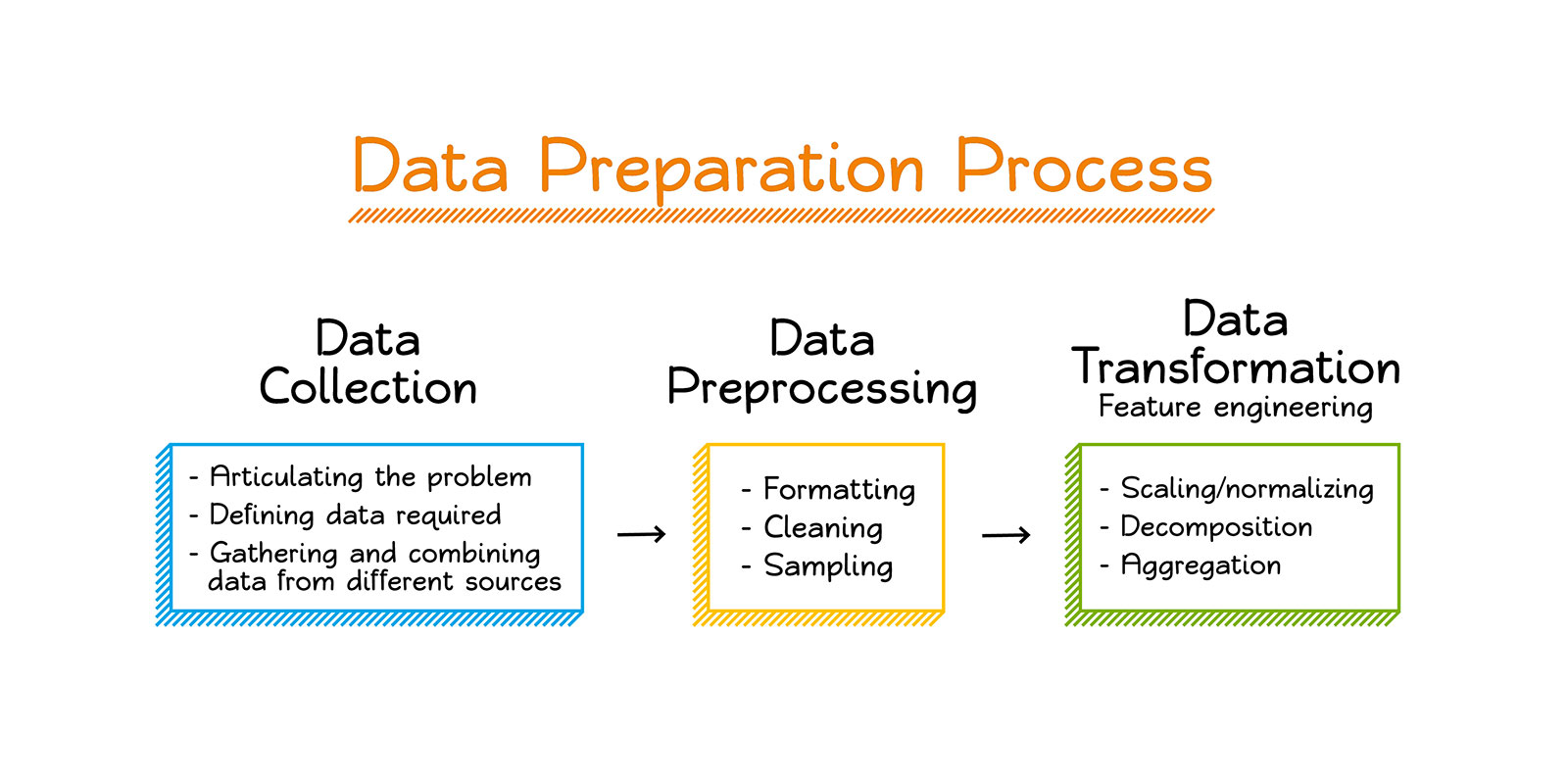
In this article, we will explore the various steps involved in preparing data for machine learning. From collecting and cleaning the data to handling missing values and outliers, we will cover the essential tasks that lay the foundation for successful machine learning models. Additionally, we will discuss exploratory data analysis, feature selection and engineering, categorical variable encoding, and splitting the data into training and testing sets.
Gathering high-quality and relevant data is vital to the success of any machine learning project. This involves identifying the data sources and collecting the necessary information. Once the data is gathered, the next step is to clean it. Data cleaning entails removing any inconsistencies, errors, or outliers that may skew the results during the training process. By ensuring the data is accurate and reliable, we can increase the effectiveness of our machine learning models.
One common challenge in working with data is dealing with missing values. Missing values can occur for various reasons, such as data collection errors or incomplete records. Handling missing values effectively is crucial to prevent biased or inaccurate analysis. We will discuss different techniques to impute or remove missing values, depending on the nature and significance of the missing data.
Duplicate data can also pose challenges in machine learning. Duplicate records can introduce biases and affect the performance of models. It is essential to identify and handle duplicate data appropriately to obtain reliable results. We will explore methodologies to detect and remove duplicates, ensuring the data remains clean and representative.
Outliers, or extreme values, can significantly impact the performance of machine learning models. Outliers can distort statistical measures and lead to inaccurate predictions. Detecting and handling outliers properly is essential to effectively analyze and model the data. We will discuss different approaches to identifying and managing outliers, ensuring robust and reliable machine learning outcomes.
Exploratory data analysis plays a critical role in understanding the data and gaining valuable insights. Exploratory data analysis involves visualizing, summarizing, and extracting patterns from the data. By exploring the data, we can identify trends, relationships, and potential areas for feature engineering.
Feature selection is the process of identifying the most relevant and informative features for model training. Not all features may contribute equally to the predictive power of the model. By selecting the most relevant features, we can reduce dimensionality and improve model performance. We will discuss various feature selection techniques to aid in this process.
Feature scaling is necessary when the features have different scales or units of measurement. Scaling the features to a common range helps prevent one feature from dominating the others during model training. We will explore different scaling techniques, such as normalization and standardization, to ensure meaningful comparisons between features.
Feature engineering involves creating new features from existing ones to improve the performance of the machine learning models. This process requires a deep understanding of the data and domain knowledge. We will discuss feature engineering techniques, such as polynomial features, interaction terms, and domain-specific transformations, to enhance the model’s predictive power.
Categorical variables, such as gender or product categories, need to be encoded into numerical values before they can be used in machine learning algorithms. Various encoding techniques, such as one-hot encoding and label encoding, are used to represent categorical variables effectively. We will explore these techniques and their implementation.
Finally, we will discuss the importance of splitting the data into training and testing sets. The training set is used to train the machine learning models, while the testing set is used to evaluate their performance. By splitting the data, we ensure that the model’s performance is assessed on unseen data, providing a more reliable measure of its predictive ability.
Preparing data for machine learning is a crucial step in the data science workflow. It lays the foundation for accurate and robust predictions. By following the steps discussed in this article, you will be well-equipped to handle various data preprocessing tasks and optimize the performance of your machine learning models.
Gathering Data
The first step in preparing data for machine learning is gathering the necessary data for your project. Gathering relevant and high-quality data is crucial for the success of any machine learning endeavor. But where can you find this data?
There are numerous sources where you can obtain data for your machine learning project. Some common sources include public datasets, government databases, academic research papers, industry reports, social media platforms, and web scraping. It is essential to carefully select data sources that are reliable, up-to-date, and pertinent to your specific problem or domain.
When gathering data, it is important to consider the data’s quality and relevance. High-quality data should be accurate, complete, and representative of the problem domain. Inaccurate or incomplete data can lead to biased or erroneous analysis and model training.
Another consideration is data privacy and compliance with legal regulations. Ensure that the data you gather adheres to data protection laws and any ethical guidelines related to its use. Anonymize any personally identifiable information (PII) to protect individuals’ privacy and maintain data confidentiality.
Once you have identified the data sources, the next step is to retrieve the data. Many datasets are readily available for download, either in CSV, JSON, or other common formats. These datasets can be directly imported into your preferred data analysis or machine learning tools.
For data sources that do not provide ready-to-use datasets, you may need to perform web scraping, which involves extracting data from websites. Web scraping tools and libraries can help automate this process, allowing you to collect data from various web pages efficiently. However, be respectful of website terms of service and utilize web scraping responsibly.
It is worth noting that data gathering can consume a significant amount of time and resources. Depending on the complexity and scale of your project, it may be necessary to allocate sufficient resources for data collection. Consider factors such as data availability, data accessibility, and any legal or ethical issues that may arise.
Additionally, be prepared to handle missing or incomplete data. It is common for datasets to have missing values or incomplete records. Dealing with missing data will be addressed in subsequent sections of this article.
In summary, gathering data is the initial step in preparing data for machine learning. Selecting reliable and relevant data sources, ensuring data quality, and addressing legal and ethical considerations are vital. Whether obtaining data from public sources, government databases, or utilizing web scraping techniques, the data gathering process is critical to the success of your machine learning project.
Cleaning Data
Once the data has been gathered, the next step in preparing it for machine learning is cleaning the data. Cleaning involves eliminating any inconsistencies, errors, or outliers that may affect the analysis or model training process.
One common task in data cleaning is handling missing values. Missing values can occur due to various reasons, such as data collection errors or incomplete records. It is essential to address missing values appropriately as they can impact the validity and accuracy of your analysis.
There are several approaches to dealing with missing values. One method is to impute the missing values, where you estimate or fill in the missing data based on other available information. This can be done by using statistical measures such as mean, median, or mode. Another option is to remove instances or variables with missing values, but this should be done cautiously to ensure that valuable information is not discarded.
In addition to missing values, data cleaning involves identifying and addressing data inconsistencies. Inconsistencies might include inconsistent formatting, duplicate records, or incorrect data entries. These inconsistencies can lead to biased analysis or models that are inaccurate or unreliable.
Removing duplicate records is an essential step in cleaning data. Duplicate records can introduce biases, affect statistical measures, and hinder the performance of machine learning models. Identifying and removing duplicates ensures that the data remains accurate and representative of the underlying problem.
Outliers are another aspect of data cleaning. Outliers are data points that deviate significantly from the normal distribution or other data points. They can skew statistical measures and affect the performance of machine learning models. Identifying and handling outliers is crucial to obtain reliable and robust results in your analysis.
There are several techniques to detect and handle outliers. One common approach is to use statistical methods such as the Z-score or the modified Z-score. These methods identify data points that are a certain number of standard deviations away from the mean. Outliers can be removed or transformed to reduce their impact on the analysis or model training.
Furthermore, it is important to ensure that the data is in the correct format and meets the required data types for machine learning algorithms. This includes converting categorical variables into numerical representations (encoding), converting continuous variables into discrete categories (binning), and checking for data consistency across different attributes.
Cleaning the data is a critical step in the data preparation process. It ensures that the data is accurate, consistent, and free from outliers or missing values that could impact the analysis or model performance. By addressing these issues, you can confidently move forward with the next stage of preparing your data for machine learning.
Handling Missing Values
Dealing with missing values is a crucial task in data preparation for machine learning. Missing values can arise due to various reasons, such as data collection errors, malfunctioning sensors, or respondents choosing not to answer certain questions. Regardless of the cause, it is important to handle missing values appropriately to ensure accurate and reliable analysis.
There are several approaches to handling missing values in your dataset. One common method is imputation, where missing values are estimated or filled in based on other available information. One simple imputation technique is to use the mean, median, or mode of the variable to fill in missing values. This approach assumes that the missing values are missing at random and that the imputed values do not significantly alter the overall distribution of the variable.
Another imputation approach is regression imputation, which involves using a regression model to predict the missing values based on other variables. This method takes into account the relationships between the missing variable and other variables in the dataset. It can provide more accurate imputations, especially when there is a strong relationship between the missing variable and the other variables.
Alternatively, rather than imputing missing values, you may choose to remove instances or variables with missing values from the dataset. This is known as listwise deletion or complete case analysis. It involves discarding any instances that have missing values in any of the variables. While this approach can be straightforward, it may result in a loss of valuable data, especially if the missing values are not randomly distributed.
A variation of listwise deletion is pairwise deletion, where only instances with missing values in specific variables are excluded from analysis involving those variables. Pairwise deletion preserves more data but can lead to biased estimates if the missing values are not missing completely at random.
In some cases, missing values may carry valuable information or have a specific meaning. In such scenarios, it is important to handle missing values as a separate category or create an additional indicator variable that captures the presence or absence of a missing value. This approach ensures that any patterns or relationships associated with missing values are captured in the analysis.
When deciding how to handle missing values, it is important to consider the nature and quantity of missing values, as well as the impact their presence or absence may have on the overall analysis. Moreover, it is crucial to be transparent about how missing values are handled in the final analysis to ensure the validity and interpretability of the results.
In summary, addressing missing values is a critical step in the data preparation process for machine learning. By carefully imputing missing data or removing instances with missing values, you can ensure the accuracy and completeness of your dataset, thereby improving the validity and reliability of your machine learning models.
Handling Duplicate Data
Duplicate data can significantly impact the integrity and accuracy of your dataset, making it crucial to handle duplicates effectively during the data preparation process for machine learning. Duplicate records can arise due to various reasons, such as data entry errors, merging errors, or multiple data sources. Detecting and addressing duplicate data ensures that your dataset is accurate, unbiased, and representative of the underlying problem.
The first step in handling duplicate data is identifying duplicate records. This can be done by comparing the values in each attribute across the dataset and identifying instances where all attributes have identical values. Depending on the size of your dataset, this comparison can be achieved manually or through automated methods, such as using hashing algorithms or dedicated duplicate detection libraries.
After identifying duplicates, you have several options for handling them. One common approach is to remove duplicate records, keeping only one instance of each unique record. This process is known as deduplication or deduping and ensures that no bias or undue influence is introduced into the analysis or model training by duplicate records.
When deciding which duplicate records to remove, it is important to consider factors such as the significance and relevance of the duplicated information. For example, if duplicates only differ in one or two attributes that are not critical to the analysis, you may choose to remove them. On the other hand, if duplicates contain different information in important attributes, you may need to carefully evaluate and determine which record to retain.
In some cases, duplicates may contain valuable information that needs to be merged or consolidated. This is common when dealing with multiple data sources or when information is captured over time. In such cases, you can merge the information from duplicate records into a single representative record. This process may involve data aggregation, applying specific rules for merging conflicting values, or selecting the most recent or complete information.
Handling duplicate data ensures that your analysis and machine learning models are based on accurate and non-redundant information. However, it is important to note that removing or consolidating duplicates may impact the size and structure of your dataset. Be aware of the potential consequences and consider the trade-offs between preserving as much information as possible and maintaining data integrity.
Additionally, it is worth noting that duplicate data may not always be explicitly marked as duplicates in the dataset. It is common for duplicates to have subtle variations, such as variations in spelling, formatting, or capitalization. Preprocessing techniques such as data standardization, normalization, or fuzzy matching can be used to identify and handle such cases.
In summary, handling duplicate data is an important step in the data preparation process for machine learning. By identifying and removing duplicates or consolidating duplicate information, you can ensure the accuracy, integrity, and non-redundancy of your dataset, leading to more reliable and unbiased machine learning outcomes.
Handling Outliers
Outliers are data points that deviate significantly from the normal distribution or the general pattern observed in the dataset. These extreme values can have a disproportionate impact on statistical measures, analysis results, and the performance of machine learning models. Therefore, it is crucial to handle outliers effectively during the data preparation process.
The first step in handling outliers is to identify them. Outliers can be detected using various statistical techniques, including methods based on the distribution of the data, such as the Z-score or the modified Z-score. These techniques measure how many standard deviations a data point is away from the mean. Values that fall outside a certain threshold can be classified as outliers.
Once outliers are identified, there are several approaches to handling them. One common approach is to remove the outliers from the dataset entirely. However, this should be done with caution, as removing outliers can potentially remove valuable information, especially if the outliers represent legitimate or significant observations.
Another technique for handling outliers is data transformation. Data can be transformed using mathematical functions, such as logarithmic or power transformations, to reduce the impact of extreme values. These transformations can help normalize the distribution of the data and alleviate the influence of outliers on statistical measures.
Alternatively, outliers can be winsorized or truncated. Winsorization involves replacing extreme values with less extreme values, such as the nearest threshold values. Truncation, on the other hand, involves setting the extreme values to a predetermined threshold. These techniques prevent outliers from having an undue influence on the analysis or model training while still preserving some information about their presence in the data.
In certain cases, it may be necessary to treat outliers as a separate category or consider the possibility that they represent meaningful or anomalous observations. Instead of removing or transforming the outliers, they can be assigned a specific label or treated as special cases in the analysis. This approach allows for further investigation into the underlying reasons behind these extreme values.
When deciding how to handle outliers, it is important to consider the domain knowledge and context of the data. Some outliers may be valid and representative of rare events or crucial observations. In such cases, removing or treating them as noise may lead to biased or incomplete analysis. It is best to consult domain experts or subject matter specialists to determine the most appropriate approach for handling outliers in your specific context.
In summary, handling outliers is a critical step in the data preparation process for machine learning. By identifying and addressing outliers, you can reduce their impact on statistical measures and the performance of machine learning models. Whether through outlier removal, data transformation, or treating outliers as a separate category, careful handling of outliers ensures more accurate and robust analysis results.
Exploratory Data Analysis
Exploratory Data Analysis (EDA) is a crucial step in the data preparation process for machine learning. It involves visualizing, summarizing, and extracting meaningful insights from the dataset. EDA helps us better understand the data, identify patterns and relationships, and make informed decisions about data preprocessing and feature engineering.
One of the primary aims of EDA is to visualize the data through various graphical techniques. Histograms, scatter plots, box plots, and bar charts are commonly used to visualize the distribution, relationships, and anomalies within the data. Visualizations provide a visual representation of the dataset, making it easier to identify trends, clusters, or outliers.
Statistical measures such as mean, median, variance, and standard deviation can also be employed to summarize the dataset and understand its central tendency and spread. Summary statistics provide a concise overview of the data and can help identify any significant deviations or peculiarities.
EDA allows us to detect and investigate any patterns or relationships within the dataset. Correlation analysis can determine the degree of association between variables, whether positive or negative. Heatmaps or correlation matrices can visually represent these relationships, aiding in feature selection and identifying potentially redundant features.
Through EDA, we can identify missing values, outliers, or inconsistencies in the data. These anomalies can be addressed through imputation, data cleaning, or outlier treatment techniques, as discussed in earlier sections. By identifying and understanding these issues, we can improve the quality and reliability of the dataset.
Domain-specific visualizations or custom features can also be explored during EDA. Depending on the problem domain, industry-specific visualizations or domain knowledge can shed light on important trends or insights. Building on existing research or theories related to the dataset can further enhance the analysis process and provide valuable insights for feature engineering or modeling.
EDA is an iterative process that should be conducted with an open mind and a willingness to explore different angles of the data. By visualizing, summarizing, and exploring the dataset in depth, we can gain valuable insights, generate hypotheses, and make informed decisions about the subsequent steps in the data preparation process.
Furthermore, EDA helps to communicate and present the findings to stakeholders or collaborators effectively. Visualizations and summary statistics can be used to convey complex information in a clear and concise manner, facilitating better decision-making and understanding.
In summary, exploratory data analysis plays a pivotal role in the data preparation process for machine learning. It helps us understand the dataset, detect anomalies, identify relationships, and make informed decisions about data preprocessing and feature engineering. By leveraging visualizations, statistical measures, and domain knowledge, we can uncover valuable insights that will ultimately enhance the performance and accuracy of our machine learning models.
Feature Selection
Feature selection is a crucial step in the data preparation process for machine learning. It involves choosing a subset of the most relevant features from the dataset to train the machine learning model. Feature selection helps to improve model performance, reduce dimensionality, and mitigate the risk of overfitting.
Not all features in a dataset contribute equally to the predictive power of a machine learning model. Some features may be irrelevant, redundant, or provide little additional information. Including these features in the model can introduce noise and increase the risk of overfitting, where the model performs well on the training data but fails to generalize to new, unseen data.
There are several approaches to feature selection. One commonly used method is univariate feature selection, which calculates statistical measures, such as chi-square, mutual information, or correlation, to evaluate the relationship between each feature and the target variable. Features that have the highest scores or exhibit the strongest relationships with the target variable are selected for the model.
Another approach is to use model-based feature selection, where a machine learning model is trained on the entire set of features, and the importance or relevance of each feature is determined. Models such as decision trees, random forests, and gradient boosting algorithms provide feature importance scores or rankings, allowing us to select the top-performing features.
Recursive feature elimination (RFE) is another popular technique for feature selection. RFE starts with all features and sequentially removes the least important features based on the model’s performance until a desired number of features is reached. This iterative process helps identify the key features that contribute the most to the model’s predictive power.
Additionally, domain knowledge and expert judgment can be leveraged in the feature selection process. Subject matter experts can provide insights into the relevance and significance of certain features based on their understanding of the problem domain. This can be particularly useful when dealing with domain-specific data or when certain features are known to be highly influential.
Feature selection helps to reduce the complexity and dimensionality of the dataset, resulting in faster model training and improved interpretability. By selecting the most relevant features, we can focus the model’s attention on the most informative attributes, thereby enhancing its predictive performance and generalization ability.
It is worth noting that feature selection is an iterative process, and the selection of features may change depending on the specific machine learning algorithm, dataset, and problem domain. Continual evaluation and refinement of the selected features are necessary to ensure optimal model performance.
In summary, feature selection plays a vital role in the data preparation process for machine learning. By selecting the most relevant features, we can improve model performance, reduce overfitting, and enhance interpretability. Using statistical measures, model-based approaches, and expert judgment, we can identify the subset of features that will maximize the predictive power of our models.
Feature Scaling
Feature scaling is an important step in the data preparation process for machine learning. It involves transforming the features in the dataset to ensure they are on a similar scale or range. Feature scaling is essential because many machine learning algorithms are sensitive to the relative magnitudes of the features, and having features on different scales can impact the model’s performance and convergence.
There are a few common techniques for feature scaling. One popular method is normalization, also known as min-max scaling. Normalization scales the values of a feature to a range between 0 and 1, based on the minimum and maximum values of the feature. This technique is particularly useful when the distribution of the feature is relatively Gaussian or known to be bounded.
Another commonly used technique is standardization, which transforms the feature values to have zero mean and unit variance. Standardization involves subtracting the mean of the feature from each value and then dividing by the standard deviation. Standardization is beneficial when the feature values have a more arbitrary or unknown distribution and when there may be outliers or extreme values in the dataset.
Scaling the features to a similar range or scale helps to prevent one feature from dominating the others during model training. If the features have different scales or units of measurement, the algorithm may give undue importance to the feature with larger values and overlook the significance of features with smaller values.
Feature scaling is crucial for many machine learning algorithms, including gradient-based optimization algorithms such as linear regression, logistic regression, and neural networks. These algorithms often rely on numerical optimization techniques that are sensitive to the scale of the features. By scaling the features, we ensure that the algorithm converges more efficiently and effectively.
Additionally, feature scaling can improve the interpretability of the model. When the features are on a similar scale, it becomes easier to compare the magnitudes of the coefficients or weights assigned to each feature. This makes it simpler to understand the relative importance of different features in the model’s predictions.
It is important to note that feature scaling should be applied after splitting the data into training and testing sets. Scaling should be performed on the training set and then applied consistently to the testing set using the same scaling parameters to avoid data leakage and ensure proper evaluation of the model.
In summary, feature scaling is a critical step in the data preparation process for machine learning. By scaling the features to a similar range, we can prevent scale-related biases, improve model convergence, and enhance interpretability. Whether through normalization or standardization, feature scaling ensures that the algorithm can effectively learn from the data and make accurate predictions.
Feature Engineering
Feature engineering is a crucial step in the data preparation process for machine learning. It involves creating new features or transforming existing ones to enhance the predictive power of the machine learning models. Feature engineering aims to extract more informative and relevant information from the dataset, ultimately improving the model’s performance.
Feature engineering requires a deep understanding of the data and the problem domain. It involves leveraging domain knowledge, expertise, and creativity to identify meaningful relationships, patterns, or transformations that can be applied to the features.
One common technique in feature engineering is creating interaction terms. Interaction terms capture the multiplicative effects or dependencies between different features. For example, in a customer churn prediction model, the interaction between the customer’s usage and their satisfaction level may provide more predictive power than each feature individually.
Polynomial features are another technique for feature engineering. This involves creating higher-order terms of existing features to capture non-linear relationships. By introducing polynomial features, the model can better capture complex patterns within the data. However, it is important to avoid overfitting by carefully selecting the appropriate degree of the polynomial.
Feature engineering can also involve deriving statistical measures from existing features. For example, calculating the mean, standard deviation, or skewness of certain attributes can provide insights into the distribution and variability of the data. These statistical features can serve as valuable indicators or cues for the model.
Domain-specific transformations and scaling techniques can also be applied during feature engineering. For example, in natural language processing (NLP), text data can be transformed into features such as word counts or term frequency-inverse document frequency (TF-IDF) values. In image processing, features can be extracted using techniques like edge detection, blob detection, or color histograms.
Additionally, feature engineering can involve creating derived features from date and time variables. These features can include day of the week, month, season, or time since a specific event. These derived features can help the model capture temporal patterns or seasonality in the data.
In some cases, feature engineering may also involve dimensionality reduction techniques, such as principal component analysis (PCA) or feature selection algorithms. These techniques help identify the most relevant and informative features while reducing the computational complexity and potential overfitting.
It is important to note that feature engineering is an iterative process that requires continual evaluation and refinement. Multiple iterations of feature engineering may be necessary to identify the most effective set of features for the machine learning model.
In summary, feature engineering is a critical step in the data preparation process for machine learning. By creating new features, transforming existing ones, or applying domain-specific knowledge, we can extract valuable information and improve the predictive power of the model. Feature engineering requires a deep understanding of the data and problem domain, as well as creativity and experimentation to extract the most informative features from the dataset.
Encoding Categorical Variables
Categorical variables are non-numeric variables that represent different categories or groups. Machine learning algorithms typically require input data to be in a numerical format, which necessitates the encoding of categorical variables. Encoding categorical variables is a crucial step in the data preparation process for machine learning, as it allows the algorithms to process and utilize these variables effectively.
There are several common techniques for encoding categorical variables. One widely used method is one-hot encoding, also known as dummy encoding. In one-hot encoding, each category within a categorical variable is transformed into a binary vector. For example, if there are three categories A, B, and C, a one-hot encoding scheme would create three binary features: A, B, and C. If a data point belongs to category A, the A feature would be marked as 1, while B and C would be marked as 0.
One limitation of one-hot encoding is that it can lead to the “curse of dimensionality” when dealing with categorical variables with many categories. This occurs when the number of features increases significantly, often resulting in a sparse dataset. Consequently, this can lead to increased computational complexity and potential overfitting. In such cases, techniques like feature extraction or dimensionality reduction may be applied.
Another common technique for encoding categorical variables is label encoding. Label encoding assigns a unique numerical label to each category within a variable. Each category is represented by a different integer value. However, care must be taken when using label encoding, as it may erroneously imply an ordinal relationship between the categories. For example, if a categorical variable represents different car colors (e.g., red, blue, green), label encoding may imply that red is greater than blue, and green is greater than red, which may lead to incorrect interpretations by the model.
Some machine learning algorithms can handle categorical variables directly, without the need for explicit encoding. These algorithms, known as tree-based models, include decision trees, random forests, and gradient boosting methods. These models can implicitly handle categorical variables by selecting appropriate splitting points based on category membership. However, it is important to note that not all tree-based models support this functionality, and explicit encoding may still be required.
When encoding categorical variables, it is crucial to consider the relationship and representation of the categories within the variable. Factors such as imbalance between categories, rare categories, or hierarchical relationships may influence the choice of encoding method. A thorough understanding of the dataset and the specific problem domain is key to making informed decisions regarding categorical variable encoding.
In summary, encoding categorical variables is an important step in the data preparation process for machine learning. This step enables machine learning algorithms to process and utilize categorical variables effectively. Techniques such as one-hot encoding and label encoding provide ways to transform categorical variables into a numerical format while considering the characteristics of the data and the specific requirements of the machine learning algorithms.
Splitting Data into Training and Testing Sets
Splitting the data into training and testing sets is a crucial step in the data preparation process for machine learning. This step allows us to evaluate and validate the performance of the machine learning models on unseen data, ensuring that the models generalize well beyond the data used for training.
The dataset is typically divided into two subsets: the training set and the testing set. The training set is used to train the machine learning models, where the algorithms learn patterns and relationships from the data. The testing set, on the other hand, is used to evaluate the models’ performance by measuring their accuracy, precision, recall, or other relevant metrics.
The split between the training set and the testing set depends on the size of the dataset and the specific problem at hand. A common practice is to allocate around 70% to 80% of the data to the training set and the remaining 20% to 30% to the testing set. However, these percentages can vary depending on the availability of data and the desired trade-off between training and testing set sizes.
It is important to ensure that the data splitting is done randomly and preserves the distribution of the classes or target variables. This helps prevent bias and ensures that the resulting models are robust and representative of the real-world scenarios they aim to generalize to.
In addition to the training and testing sets, it is recommended to create an additional subset called the validation set. The validation set is used to fine-tune the hyperparameters of the models and make decisions about model selection or feature engineering. It helps to prevent overfitting by providing an additional level of evaluation before testing the models on the unseen testing data.
The validation set is often created by further dividing the training set into smaller subsets. Common techniques include k-fold cross-validation, where the training set is divided into k equal parts, or stratified sampling, which ensures that each class or target variable value is well-represented in the validation set.
By splitting the data into training, testing, and validation sets, we can assess the performance of the machine learning models objectively. This allows us to understand how well the models generalize to unseen data and make informed decisions about model selection, hyperparameter tuning, or any necessary modifications to the data preprocessing steps.
It is essential to note that the splitting should be performed before any data preprocessing steps, such as feature scaling or feature engineering, to avoid data leakage. Scaling or transforming the data should be applied separately to the training, testing, and validation sets while ensuring that the scaling parameters are derived from the training set only.
In summary, splitting the data into training, testing, and validation sets is a critical step in the data preparation process for machine learning. This enables the evaluation of models on unseen data, helps prevent overfitting, and allows for fine-tuning and selecting the best models for deployment. By preserving the distribution and randomizing the splitting process, we can ensure that the resulting models are robust and generalize well to new, unseen data.
Conclusion
The data preparation process is a critical component of any successful machine learning project. Preparing the data involves several key steps, starting with gathering the data from reliable sources and ensuring its quality and relevance. Cleaning the data by handling missing values, dealing with duplicates, and addressing outliers helps to ensure the accuracy and integrity of the dataset.
Exploratory data analysis allows us to gain a deeper understanding of the data, uncover patterns, and identify potential relationships. Feature selection and engineering enable us to select the most relevant features and transform them to enhance the predictive power of our models. Encoding categorical variables ensures that the algorithms can effectively utilize these variables in the analysis.
Lastly, splitting the data into training, testing, and validation sets enables us to evaluate the performance of the machine learning models on unseen data. By preserving the distribution and randomizing the splitting process, we ensure that the models generalize well to new, unseen data.
Through careful and thorough data preparation, we can optimize the performance and accuracy of our machine learning models. The quality of the data and the appropriate preprocessing techniques play a crucial role in the success of the models in real-world applications.
It is worth emphasizing that data preparation is an iterative process that requires continual evaluation and refinement. Different techniques and approaches may be necessary for different types of datasets or problem domains.
In summary, data preparation is a fundamental step in machine learning that sets the foundation for robust and reliable models. By gathering relevant data, cleaning and processing it effectively, and carefully selecting and engineering features, we can create a high-quality dataset that leads to more accurate predictions and valuable insights. The success of any machine learning project heavily relies on the careful execution of the data preparation process.