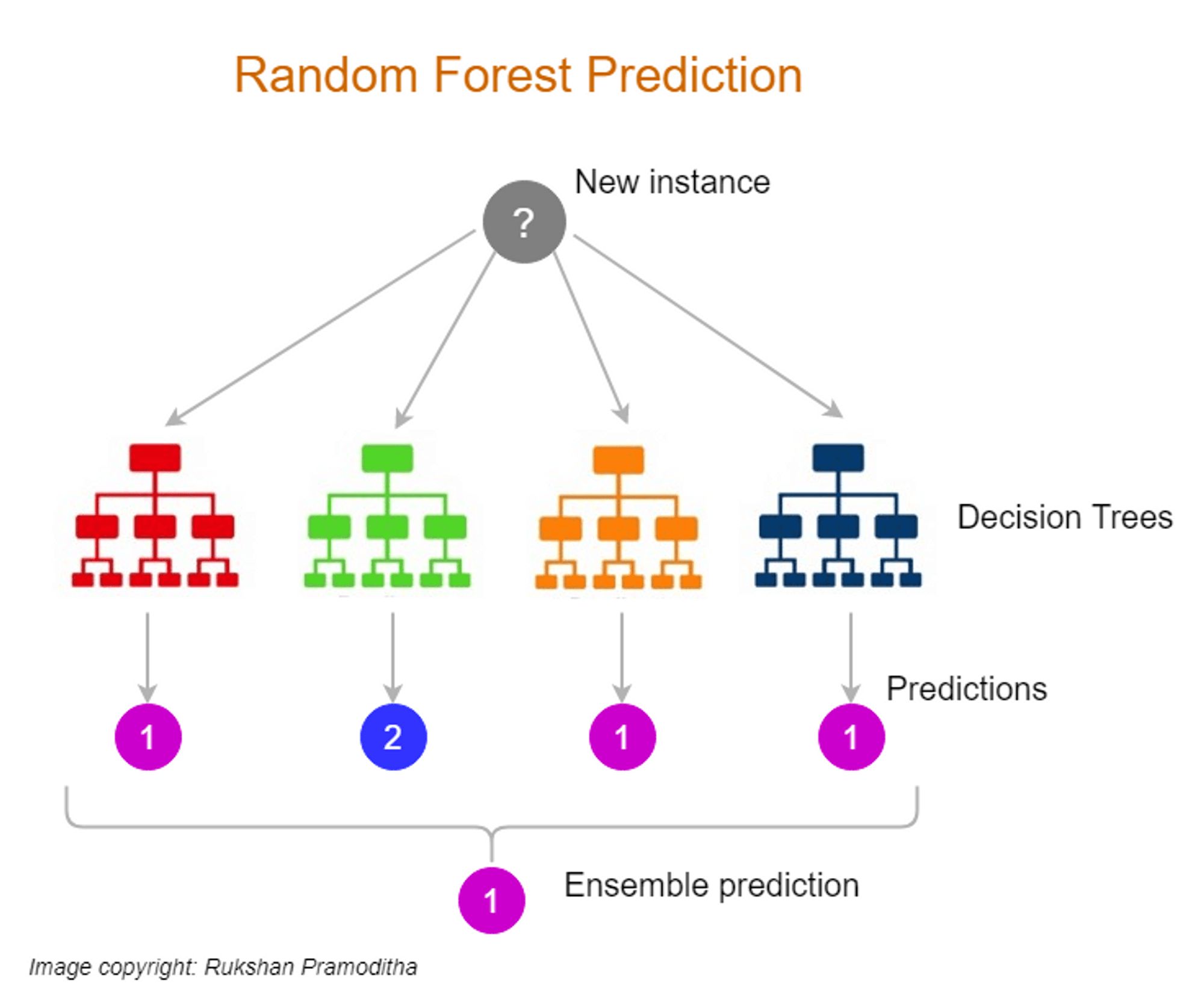
Introduction
Missing data is a common occurrence in the field of machine learning and can pose challenges for data analysts and researchers. When working with real-world datasets, it is not uncommon to encounter variables or observations with missing values. These missing values can arise due to a variety of reasons, such as human error, faulty data collection methods, or technical issues.
The presence of missing data can have a significant impact on the accuracy and reliability of machine learning models. Ignoring or mishandling missing data can lead to biased and unreliable results, compromising the validity of the analysis. Therefore, it is crucial to have a robust strategy in place for handling missing data in machine learning projects.
This article will explore the concept of missing data and provide an overview of various techniques that can be used to handle it effectively. By understanding the types of missing data and learning about common techniques for handling it, data analysts and machine learning practitioners can make informed decisions about the most suitable approach for their specific projects.
By ensuring that missing data is properly addressed, we can improve the quality and reliability of our machine learning models, leading to more accurate predictions and actionable insights.
Understanding Missing Data
Missing data refers to the absence or lack of values in a dataset for one or more variables. The presence of missing data can impact the analysis and interpretation of data, as well as the performance of machine learning models.
There are various reasons why data can be missing. It can occur due to human error during data collection or entry, where certain fields are left blank or not recorded accurately. Missing data can also arise from technical issues, such as sensor failures or data corruption during transmission. Additionally, participants in surveys or studies may choose not to answer specific questions, resulting in missing data points.
Missing data can disrupt the integrity of a dataset and affect the statistical properties of the variables. It can lead to biased estimates, distorted relationships, and reduced accuracy in predictive models. Therefore, understanding the nature and extent of missing data is crucial for appropriate data analysis.
Exploring the patterns of missing data can provide insights into its causes and potential implications. Some datasets may exhibit patterns of missingness, such as missing data occurring more frequently for certain variables or in specific subgroups. This information can help in designing appropriate strategies for handling missing data.
It is important to distinguish between different types of missing data, as the appropriate handling technique may depend on the specific type. Missing data can be categorized into three types:
- Missing Completely at Random (MCAR): In this case, the probability of missing data is unrelated to any observed or unobserved variables in the dataset. The missing values occur randomly, and there is no systematic relationship between the missingness and the values of other variables.
- Missing at Random (MAR): In MAR, the probability of missing data is dependent on other observed variables in the dataset, but not on the missing variable itself. For example, in a survey, the probability of missing income data may depend on variables like age or education level.
- Missing Not at Random (MNAR): MNAR occurs when the probability of missing data is related to the unobserved value of the missing variable. In this case, the missingness may be driven by factors that are unknown or unmeasured. For instance, in a survey about personal income, high-income individuals may be less likely to disclose their earnings.
The type of missing data can influence the selection of appropriate techniques for handling it. Understanding the underlying mechanisms of missing data is essential to make informed decisions regarding the handling strategies that will minimize bias and maintain the integrity of the analysis.
Types of Missing Data
When dealing with missing data, it is essential to understand the different types of missingness to determine the most suitable approach for handling it. Missing data can be classified into three main types:
- Missing Completely at Random (MCAR): In this type, the missingness is unrelated to any variables, observed or unobserved. The missing values occur randomly throughout the dataset, and there is no systematic pattern or reason behind their absence. This is often considered the most straightforward type of missingness since it does not introduce any bias into the analysis. Handling MCAR missing data involves simple techniques that do not rely on the values in the dataset.
- Missing at Random (MAR): MAR occurs when the probability of missingness depends only on observed variables in the dataset. In other words, the missingness is related to the values of other variables in the dataset but not the missing variable itself. MAR can be thought of as missingness that is predictable based on the available information. Handling MAR missing data often involves techniques that account for the relationships between the missing variable and other observed variables.
- Missing Not at Random (MNAR): MNAR is the most challenging and problematic type of missingness. It occurs when the probability of missing data depends on the unobserved value of the missing variable. MNAR introduces potential bias into the analysis, as the missingness is influenced by unmeasured factors. Handling MNAR missing data requires more complex techniques that account for the potential underlying factors driving the missingness.
Understanding the types of missing data is crucial because it guides the selection of appropriate handling techniques. For MCAR missing data, techniques such as listwise deletion or imputation methods can be used. With MAR missing data, techniques like maximum likelihood estimation or multiple imputation can be employed. Dealing with MNAR missing data is more challenging, as it requires advanced techniques like pattern-mixture models or selection models to properly handle the missing values.
It is worth noting that determining the type of missing data can be challenging in practice, as it often involves making assumptions about the underlying mechanism driving the missingness. Therefore, it is important to assess and analyze the missing data carefully and consider the potential implications of the missingness on the validity and generalizability of the analysis.
Common Techniques for Handling Missing Data
When it comes to dealing with missing data, several techniques can be employed to minimize the impact of missing values on the analysis. The choice of technique depends on the type of missing data, the characteristics of the dataset, and the objectives of the analysis. Here are some commonly used techniques:
- Removing Rows or Columns with Missing Data: In some cases, if the missing data is minimal and does not significantly affect the analysis, the simplest approach is to remove the rows or columns containing missing values. This technique is known as complete case analysis or listwise deletion. While it may be convenient, it can lead to a loss of valuable information and potentially biased results if the missingness is not random.
- Imputation Techniques: Imputation is a technique where missing values are replaced with estimated values. This approach enables retaining the complete dataset without discarding any observations. There are various imputation methods available, including mean imputation, median imputation, mode imputation, and regression imputation. Imputation methods strive to preserve the statistical properties of the variable while filling in the missing values, but they can introduce some level of bias.
- Using Mean, Median, or Mode: One simple approach for imputing missing values is to substitute them with the mean, median, or mode of the variable. This technique is suitable for numerical variables or categorical variables with few categories. However, it can lead to the loss of variability and introduce bias if the missingness is related to other variables.
- Using Regression Models: Another approach is to use regression models to predict the missing values based on other variables. This technique is called regression imputation. It leverages the relationships between the missing variable and other variables to estimate the missing values. Regression imputation can be more accurate than simple imputation methods, but it assumes that the relationship between the missing variable and the other variables is linear.
- Using Machine Learning Algorithms: Machine learning algorithms, such as k-nearest neighbors (KNN), random forests, or support vector machines (SVM), can also be utilized to fill in missing values. These algorithms use the available data to predict and impute the missing values. Machine learning-based imputation can capture non-linear relationships and interactions between variables, but it can be computationally expensive and may introduce complexity into the analysis.
It is important to evaluate the performance and impact of the chosen technique on the analysis. Researchers should assess the quality of the imputed values, measure the impact on statistical measures and predictive models, and consider the assumptions and limitations associated with each technique. It is worth noting that no single technique is universally applicable, and the decision of which approach to use depends on the specific characteristics and requirements of the dataset and analysis.
Removing Rows or Columns with Missing Data
One common approach for handling missing data is to simply remove the rows or columns that contain missing values. This technique is known as complete case analysis or listwise deletion. When the missing data is minimal and does not significantly affect the analysis, removing the incomplete cases can be a convenient and straightforward method.
By removing the rows with missing values, the remaining dataset is considered “complete,” and the analysis can proceed without dealing with missing data. This technique ensures that no imputation or estimation is necessary, simplifying the analysis process. Additionally, removing incomplete cases can reduce the risk of introducing biased results or erroneous interpretations.
However, complete case analysis does come with some potential drawbacks. It may result in a loss of valuable information, especially if the proportion of missing values is substantial. Removing observations with missing data reduces the sample size, which could decrease the statistical power and precision of the analysis. Moreover, if the missingness is not random and is related to other variables, removing incomplete cases can introduce bias into the results.
Another consideration is the removal of entire variables or features that contain missing values. If the missingness is concentrated in one or a few variables, removing those variables entirely may be a viable option. However, this approach should be carefully considered, as it could eliminate valuable predictors or confounding variables that are crucial for the analysis.
Complete case analysis is best suited for situations where the missingness is minimal and truly random (MCAR). This technique can be useful when the integrity or validity of the analysis would not be compromised by removing the incomplete cases.
It is important to note that the decision to remove rows or columns with missing values should be made based on a careful evaluation of the impact on the analysis and the goals of the study. Researchers should consider the proportion of missing data, the potential bias introduced, and the implications for the statistical power and interpretation of the results.
Imputation Techniques
Imputation is a widely used technique for handling missing data by replacing the missing values with estimated values based on the available information. This approach allows for the retention of the complete dataset without discarding any observations, ensuring the preservation of valuable information.
There are several imputation methods available, and the choice depends on the characteristics of the data and the assumptions made about the missingness. Some common imputation techniques include mean imputation, median imputation, mode imputation, and regression imputation.
Mean imputation: In this technique, the missing values are replaced with the mean value of the variable. Mean imputation is suitable for numerical variables and assumes that the missing values are similar to the overall average or central tendency of the variable. However, mean imputation can lead to a reduction in variability and potential bias if the missingness is related to other variables.
Median imputation: Similar to mean imputation, median imputation replaces the missing values with the median value of the variable. Median imputation is robust to outliers and may be preferred when the variable is not normally distributed or contains extreme values.
Mode imputation: Mode imputation is used for categorical variables and replaces the missing values with the mode, or most frequent value, of the variable. This technique assumes that the missing values are likely to belong to the most common category in the dataset.
Regression imputation: Regression imputation involves using regression models to predict the missing values based on other variables in the dataset. This technique assumes a linear relationship between the missing variable and the other observed variables. By fitting a regression model using the complete cases, the missing values can be estimated based on the relationships observed in the data.
Imputation techniques strive to retain the statistical properties of the variable while filling in missing values. However, it is important to be aware of the limitations and assumptions associated with each method. Imputation assumes that the missing data are Missing at Random (MAR) or Missing Completely at Random (MCAR). If the missingness is not random and is related to unobserved factors (Missing Not at Random – MNAR), imputation may introduce bias and affect the validity of the analysis.
Evaluating the performance and impact of imputation techniques is crucial. Researchers should assess the quality of the imputed values, examine any changes in the statistical properties of the variable, and consider the assumptions and limitations associated with each method to ensure the reliability and validity of the results.
Using Mean, Median, or Mode
When dealing with missing data, one common approach is to impute the missing values using summary statistics such as the mean, median, or mode of the variable. This technique is straightforward and can be applied to both numerical and categorical variables.
Mean imputation: Mean imputation involves replacing the missing values with the mean value of the variable. This technique assumes that the missing values are similar to the average or central tendency of the variable. Mean imputation is often used when the missingness is MCAR or when the variable follows a normal distribution. However, it should be used with caution as it can reduce variability and potentially introduce bias if the missingness is related to other variables.
Median imputation: Median imputation replaces missing values with the median value of the variable. This approach is robust to outliers and can be useful when dealing with variables that are not normally distributed or contain extreme values. Median imputation is also appropriate when the missingness is MCAR or when the variable is skewed.
Mode imputation: Mode imputation is used for categorical variables and replaces missing values with the mode, which is the most frequent value of the variable. It assumes that the missing values are likely to belong to the most common category in the dataset. Mode imputation can be employed when the missingness is MCAR or when dealing with categorical variables that have a clear majority category.
Using mean, median, or mode for imputing missing values is a simple and quick solution. It allows for the completion of the dataset without the need for more complex techniques or additional data. However, it is important to note that these methods do not account for relationships or interactions between variables, which can impact the accuracy of the imputed values.
Furthermore, mean, median, or mode imputation assumes that the missingness is MCAR or MAR. If the missingness is MNAR, where the missing values are related to unobserved factors, using summary statistics for imputation may introduce bias and compromise the validity of the analysis.
When employing mean, median, or mode imputation, it is crucial to evaluate the impact on the statistical measures, assess any changes in the distribution of the variable, and consider the assumptions and limitations associated with each technique. Researchers should be mindful of the potential drawbacks and exercise caution when applying these methods in their data analysis.
Using Regression Models
Regression imputation is a technique used to handle missing data by utilizing regression models to predict the missing values based on other variables in the dataset. This approach assumes a linear relationship between the missing variable and the observed variables.
The process of regression imputation involves two main steps. First, a regression model is fitted using the complete cases in the dataset, where the missing variable acts as the dependent variable, and the other variables serve as independent variables. Once the regression model is established, it can be used to predict the missing values for the corresponding observations.
Regression imputation offers several advantages over simple imputation methods like mean or median imputation. It takes into account the relationships between variables and can generate more accurate imputed values based on the observed patterns in the data. Using regression models allows for capturing more complex relationships and interactions, which can lead to improved imputation accuracy.
However, it is essential to consider that regression imputation assumes linearity between the missing variable and the observed variables. It may not be appropriate if the relationship is non-linear or if there are complex interactions among the variables. In such cases, other non-linear regression models or machine learning algorithms may be more suitable for imputation.
Addtionally, it is important to note that regression imputation assumes that the missingness is MCAR or MAR, where the probability of missing data depends only on observed variables. If the missingness is related to unobserved factors (MNAR), applying regression imputation may introduce bias into the imputed values.
Evaluating the performance of regression imputation is crucial. Researchers should assess the quality of the imputed values by comparing them to the available observed data and consider any changes in the statistical properties of the variable. It is also important to validate the assumptions of linear relationships between variables and assess the potential impact of missingness patterns on the validity of the analysis.
When employing regression imputation, researchers should exercise caution and consider the suitability of this technique based on the specific characteristics of their data. It is recommended to perform sensitivity analyses and explore alternative imputation methods to ensure robustness and reliability in the imputed values.
Using Machine Learning Algorithms
Handling missing data using machine learning algorithms has gained popularity due to their ability to capture complex patterns and relationships in the data. By leveraging the power of machine learning, missing values can be imputed based on the available information in the dataset.
Machine learning algorithms, such as k-nearest neighbors (KNN), random forests, or support vector machines (SVM), can be employed for imputing missing values. These algorithms utilize the existing data to build models and make predictions for the missing values. The imputation process involves training the model on the complete cases, then using it to impute the missing values based on the relationships observed in the data.
One of the main advantages of using machine learning algorithms for imputation is their ability to capture non-linear relationships and interactions between variables. They can handle more complex data structures and provide more accurate imputations compared to simple imputation methods. Machine learning-based imputation methods have been shown to outperform traditional techniques, especially when dealing with large and diverse datasets.
However, using machine learning algorithms for imputation may come with certain challenges. These include potential computational complexity, the need for sufficient data to train the algorithms effectively, and the risk of overfitting if the model is overly complex. Moreover, as with any imputation technique, machine learning imputation assumes that the missingness is MCAR or MAR, and the imputed values may still introduce bias if the missingness is related to unobserved factors (MNAR).
It is important to evaluate the performance of the chosen machine learning algorithm for imputation. Researchers should assess how well the algorithm captures the underlying patterns in the data and compare the imputed values to the available observed data. It is also advisable to perform sensitivity analyses and consider alternative imputation methods to ensure the robustness and reliability of the imputed values.
When deciding to use machine learning algorithms for imputation, researchers should carefully consider the complexity of their data, the computational requirements, and the trade-off between accuracy and computational cost. Additionally, it is essential to validate the assumptions made by the algorithm and assess any potential limitations that may arise in the given context.
Evaluating the Impact of Handling Missing Data
Handling missing data is a critical step in data analysis, and it is important to assess the impact of the chosen handling technique on the validity and reliability of the results. Evaluating the impact helps to understand how the handling of missing data influences the outcomes of the analysis and the interpretation of the findings.
There are several key aspects to consider when evaluating the impact of handling missing data:
- Statistical measures: Assess how the handling technique affects key statistical measures such as means, medians, standard deviations, correlations, or regression coefficients. Compare these measures before and after handling missing data to determine if there are significant differences.
- Pattern analysis: Evaluate how the handling technique affects the patterns and relationships observed in the data. Examine if the handling technique introduces bias, distorts the distribution of variables, or affects the strength and direction of associations between variables.
- Model performance: If the analysis involves prediction models or machine learning algorithms, evaluate how the handling technique impacts the model performance. Compare the accuracy, precision, recall, or other relevant metrics before and after handling missing data.
- Sensitivity analyses: Perform sensitivity analyses to assess the robustness of the results to different handling techniques. Consider applying alternative handling methods and compare the results to identify potential variations or inconsistencies resulting from different approaches.
- Subgroup analyses: Explore the impact of handling missing data on different subgroups within the dataset. Examine if the handling technique affects certain groups disproportionately and if it introduces bias or disparities in the analysis across different subgroups.
Evaluating the impact of handling missing data is vital to ensure the reliability and validity of the analysis. It helps to understand the potential biases, limitations, and implications of the handling technique on the results. By carefully evaluating the impact, researchers can make informed decisions about the most appropriate technique and confidently interpret the findings.
It is worth noting that there is no one-size-fits-all approach, and the evaluation of impact should be tailored to the specific dataset, research question, and analysis objectives. Transparency in reporting the handling technique and its impact facilitates the replication of the study and allows for a comprehensive understanding of the data analysis process.
Conclusion
Handling missing data is a crucial step in data analysis, as it has the potential to impact the accuracy, reliability, and interpretability of the results. In this article, we explored different techniques for handling missing data in machine learning projects.
We discussed the importance of understanding missing data, including the types of missingness that can occur, such as Missing Completely at Random (MCAR), Missing at Random (MAR), and Missing Not at Random (MNAR). Recognizing the type of missing data is important as it influences the choice of handling technique.
We then explored various common techniques for handling missing data. These techniques included removing rows or columns with missing data, imputation techniques using mean, median, mode, or regression models, and employing machine learning algorithms for imputation.
To make informed decisions about the appropriate handling technique, it is crucial to evaluate the impact of handling missing data. This evaluation involves considering statistical measures, analyzing patterns and relationships in the data, assessing model performance, conducting sensitivity analyses, and examining subgroup differences.
Ultimately, the choice of handling technique depends on the specific characteristics of the dataset, the objectives of the analysis, and the assumptions made about the missingness. Researchers need to carefully consider the advantages and limitations of each technique and select the most appropriate approach for their particular scenario.
By effectively handling missing data, researchers can improve the quality and reliability of their analyses and enhance the validity and interpretability of their findings. Proper handling of missing data ensures that valuable information is retained and that any potential biases are minimized.
Overall, addressing missing data in machine learning projects is an essential task that requires careful consideration and evaluation. By employing the appropriate techniques and critically assessing their impact, researchers can strengthen their analyses and ensure the validity and reliability of their results.