Introduction
Welcome to the world of machine learning, where algorithms can learn and make predictions without being explicitly programmed. Machine learning has revolutionized industries across the globe, from healthcare to finance, by enabling computers to analyze vast amounts of data and extract meaningful insights. But with so many different machine learning models available, how do you decide which one to use for your specific task? In this article, we will explore the factors to consider when choosing a model and provide an overview of some popular machine learning models in different categories.
When it comes to choosing a machine learning model, there is no one-size-fits-all solution. The right model depends on various factors, such as the nature of the data, the type of problem you’re trying to solve, and the resources available to you.
Before diving into the specifics of each model, it’s essential to understand the different types of machine learning approaches. There are four main categories:
- Supervised Learning Models: These models are trained on labeled data, where the input features (the independent variables) are mapped to their respective output labels (the dependent variable). The goal is to learn the mapping function that can predict the labels for new, unseen data.
- Unsupervised Learning Models: These models are used when you have unlabeled data, and the goal is to find patterns, relationships, or structures within the data without any predefined outcome variable.
- Semi-Supervised Learning Models: As the name suggests, these models lie between supervised and unsupervised learning. They are used when you have a limited amount of labeled data and a large pool of unlabeled data.
- Reinforcement Learning Models: These models learn through interaction with an environment, receiving feedback in the form of rewards or punishments. The goal is to maximize the cumulative reward over time by making optimal actions based on the learned policies.
Each category has its own set of models, each with its strengths and weaknesses. In the following sections, we will delve into some popular models and explore their applications in different scenarios. By understanding these models, you will be better equipped to choose the most suitable one for your specific machine learning task.
Understanding Machine Learning Models
Before we jump into the specifics of different machine learning models, let’s first gain a general understanding of how these models work. At their core, machine learning models are mathematical algorithms that learn from data and make predictions or decisions based on that learned information.
Machine learning models learn patterns and relationships in the data through a process called training. During the training phase, the model is exposed to a set of input data along with corresponding output labels (in the case of supervised learning) or unlabeled data (in the case of unsupervised learning). The model analyzes the data and adjusts its internal parameters to optimize its performance in making accurate predictions or capturing the underlying structure of the data.
Once the model is trained, it can be used to make predictions or decisions on new, unseen data. This is called the testing or inference phase. The model takes the input data and applies the knowledge gained during training to generate an output, which can be a predicted label, a probability, or a representation of the data’s structure.
It’s important to note that no model is perfect, and there is always some level of error in predicting or representing the data. The goal is to minimize this error by selecting the most appropriate model for the task at hand and optimizing its parameters and hyperparameters.
When choosing a machine learning model, several factors should be considered:
- Accuracy: The model should have a high level of accuracy in predicting or representing the data.
- Interpretability: Some models offer better interpretability, allowing users to understand the reasoning behind the model’s predictions.
- Scalability: The model should be able to handle large datasets and be efficient in terms of computation and memory usage.
- Robustness: The model should be able to handle noisy or missing data and be resistant to overfitting or underfitting.
- Flexibility: The model should be able to handle different types of data, such as numerical, categorical, or text-based data.
- Resource Requirements: Consider the computational requirements, memory usage, and training time needed for the model.
By considering these factors and understanding the underlying principles of machine learning models, you can make an informed decision on which model to use for your specific task. In the following sections, we will explore different categories of machine learning models and their applications, helping you gain a deeper understanding of the options available to you.
Factors to Consider When Choosing a Model
Choosing the right machine learning model for your task can be a challenging decision. To help guide your selection process, there are several key factors you should consider. These factors can make a significant impact on the performance and effectiveness of your model. Let’s explore some of the crucial considerations:
- Accuracy: The primary goal of a machine learning model is to make accurate predictions or capture the underlying patterns in the data. Therefore, it’s essential to evaluate the accuracy of the model and choose one that performs well on your specific problem.
- Interpretability: Depending on your application, interpretability may be crucial. Some models, like decision trees or linear regression, provide easy-to-understand explanations for their predictions. On the other hand, more complex models like neural networks or deep learning models may lack interpretability but offer excellent predictive power.
- Scalability: Consider the scalability of the model, especially if you anticipate working with large datasets. Some models, such as support vector machines (SVM) or random forests, can handle large-scale data efficiently, while others may struggle with computational or memory limitations.
- Robustness: Robustness refers to a model’s ability to handle noisy or missing data and be resistant to overfitting or underfitting. Models with regularization techniques, like Lasso or Ridge regression, are known to be robust in such scenarios.
- Flexibility: Different models are suited for different types of data. For example, if you have text data, models like Naive Bayes or recurrent neural networks (RNNs) may be more appropriate. Consider the specific data characteristics and choose a model that can effectively handle them.
- Resource Requirements: Assess the computational requirements, memory usage, and training time of the model. Deep learning models, such as convolutional neural networks (CNNs) or recurrent neural networks (RNNs), are notoriously resource-intensive, whereas simpler models like linear regression or decision trees have lower resource requirements.
While these factors can guide your decision-making process, it’s important to strike a balance between model complexity and performance. Sometimes, simpler models may outperform more complex ones due to their ability to generalize well on the given task.
Additionally, it’s worth considering the availability of resources and expertise. Some models require specialized knowledge and skills for training and fine-tuning, while others have user-friendly libraries or pre-trained models readily available.
By carefully considering these factors, you can make an informed decision when choosing a machine learning model. In the following sections, we will explore popular models in different categories, providing you with a deeper understanding of their strengths and applications.
Supervised Learning Models
Supervised learning models are widely used when you have labeled data, meaning each data point has associated input features and a corresponding output label. These models learn from these labeled examples and make predictions on new, unseen data. Here are some popular supervised learning models:
- Linear Regression: Linear regression is used for regression tasks, where the output variable is a continuous value. It models the relationship between the input features and the output label using a linear equation.
- Logistic Regression: Logistic regression is used for classification tasks, where the output variable is a categorical value. It estimates the probability of an input belonging to a particular class using the logistic function.
- Decision Trees: Decision trees are versatile models that can handle both regression and classification tasks. They partition the feature space into smaller regions based on a series of binary decisions and make predictions based on the majority class or average value in each region.
- Random Forests: Random forests are an ensemble of decision trees. They combine multiple decision trees through a voting mechanism to generate more accurate predictions. Random forests also provide insights into feature importance.
- Support Vector Machines (SVM): SVMs are powerful models for both regression and classification tasks. They find the optimal hyperplane that separates the data points with the largest margin between two classes, maximizing the decision boundary’s robustness.
- Naive Bayes: Naive Bayes is a probabilistic model that is particularly effective for text classification tasks. It uses Bayes’ theorem and assumes feature independence to estimate the probability of a class given the input features.
- K-Nearest Neighbors (KNN): KNN is a non-parametric model that makes predictions based on the similarity of the input data to its k nearest neighbors. It is commonly used for classification tasks, but can also be adapted for regression.
These are just a few examples of supervised learning models, each with its own strengths and applications. The choice of model depends on the nature of your data and the problem you’re trying to solve. Evaluating model performance through metrics like accuracy, precision, recall, and F1 score can help you select the most suitable model.
Remember that supervised learning models require labeled data for training, which may not always be readily available. In such cases, you may need to explore other learning paradigms like unsupervised learning or semi-supervised learning. Let’s dive into these types of models in the next sections to expand your understanding of machine learning options.
Unsupervised Learning Models
Unsupervised learning models are used when you have unlabeled data. These models aim to find patterns, relationships, or structures within the data without any predefined outcome variable. Here are some popular unsupervised learning models:
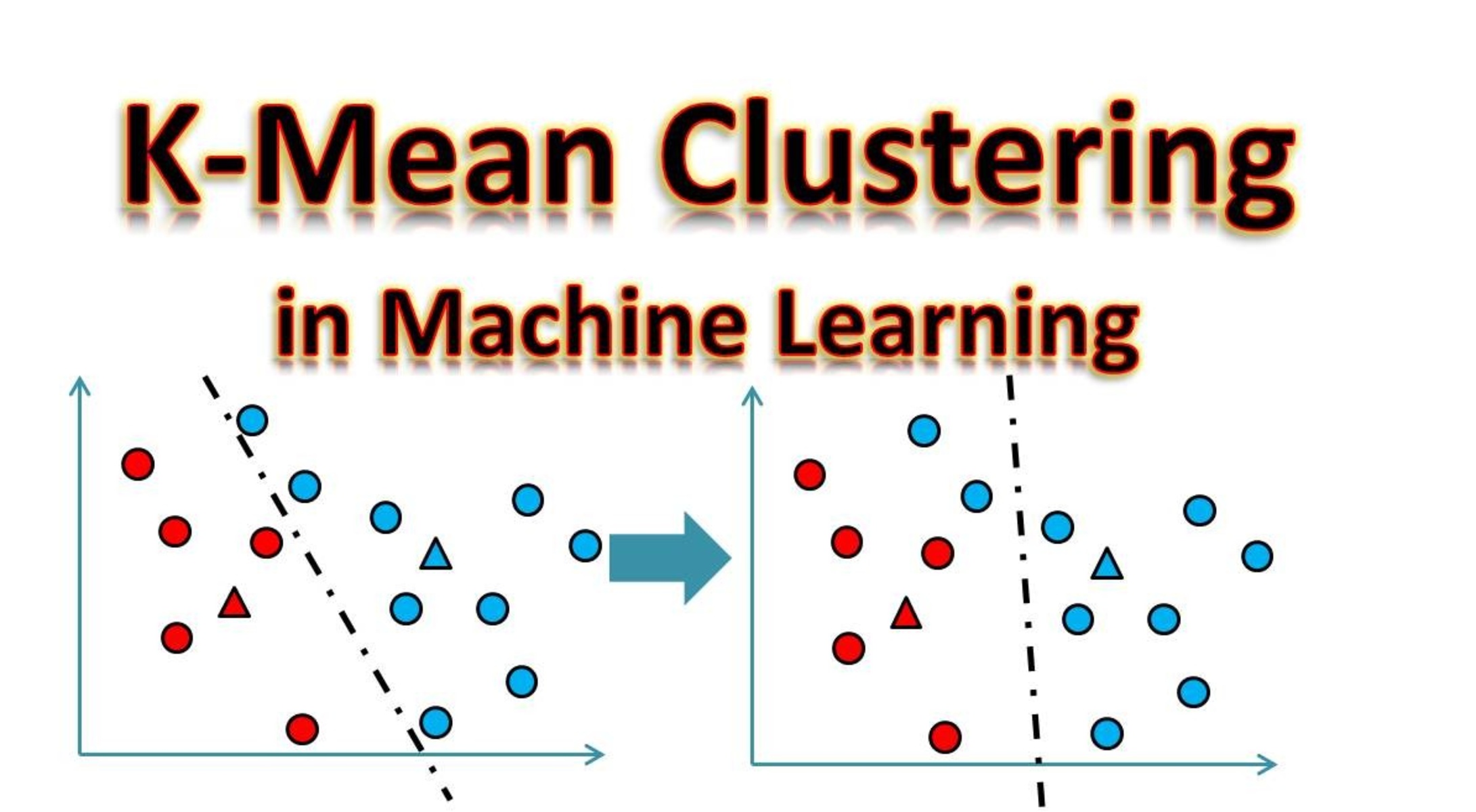
- K-Means Clustering: K-means clustering is a widely used clustering algorithm that partitions the data into k clusters based on the similarity of the data points. It aims to minimize the within-cluster sum of squares.
- Hierarchical Clustering: Hierarchical clustering creates a hierarchy of clusters by merging or splitting clusters based on their similarities. It can be represented as a dendrogram to visualize the clustering structure.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): DBSCAN is a density-based clustering algorithm that groups together data points based on their density. It is particularly robust in handling clusters of different shapes and detecting outliers.
- PCA (Principal Component Analysis): PCA is a dimensionality reduction technique that finds a lower-dimensional representation of the data while preserving its important characteristics. It can be used to reduce the complexity of high-dimensional data.
- Association Rules: Association rule mining is used to discover interesting relationships between variables in a dataset. It identifies frequent itemsets and generates rules that describe the associations between items.
- Anomaly Detection: Anomaly detection models aim to identify unusual or suspicious data points that deviate significantly from the majority of the data. They are useful for detecting fraud, network intrusions, or any abnormal behavior.
Unsupervised learning models are valuable for exploratory data analysis, pattern discovery, and segmentation. They can uncover hidden insights and provide a deeper understanding of the data without the need for labeled examples.
It’s worth noting that unsupervised learning models can also be used in combination with supervised learning. For example, clustering can be used as a pre-processing step to create groups or segments that can inform the feature engineering process for a subsequent supervised learning task.
Understanding and applying unsupervised learning models can provide you with a comprehensive toolkit for various data analysis tasks. However, it’s important to evaluate the performance of these models using appropriate metrics, such as silhouette coefficient or within-cluster sum of squares, to ensure their effectiveness for your specific problem.
Next, let’s explore semi-supervised learning models, which bridge the gap between supervised and unsupervised learning approaches.
Semi-Supervised Learning Models
Semi-supervised learning models are used when you have a limited amount of labeled data and a large pool of unlabeled data. These models leverage the available labeled data along with the unlabeled data to make predictions or capture the underlying structure of the data. Here are some popular semi-supervised learning models:
- Self-Training: Self-training is a straightforward approach where a supervised learning model is trained on the labeled data and then used to predict labels for the unlabeled data. These predicted labels are then combined with the labeled data to retrain the model.
- Co-Training: Co-training involves training multiple models on different subsets of features or views of the data. Each model is then used to make predictions on the unlabeled data, and the instances with high agreement between the models are labeled and added to the training set.
- Transductive Learning: Transductive learning is a semi-supervised learning approach where the model learns to label the unlabeled data points while considering the specific test instances. It aims to leverage the similarity between the unlabeled data and the labeled data to improve predictions.
- Generative Models: Generative models, such as Gaussian Mixture Models (GMM) or Hidden Markov Models (HMM), can be used in a semi-supervised setting. These models learn the underlying probability distribution of the data, which can be used to generate labels for the unlabeled data.
- Graph-based Methods: Graph-based semi-supervised learning methods leverage the connections or relationships between the data points to propagate labels from the labeled to the unlabeled data. Examples include Label Propagation and Graph Convolutional Networks.
Semi-supervised learning models are beneficial when obtaining labeled data is expensive or time-consuming, as they enable you to utilize the abundance of unlabeled data to improve the model’s performance.
It’s important to note that the performance of semi-supervised learning models heavily relies on the quality and reliability of the predicted labels for the unlabeled data. Therefore, it’s crucial to carefully tune and evaluate these models to ensure their effectiveness.
Now that we have explored supervised, unsupervised, and semi-supervised learning models, let’s move on to the realm of reinforcement learning models in the next section.
Reinforcement Learning Models
Reinforcement learning models are designed to learn through interaction with an environment. In these models, an agent takes actions in a given state and receives feedback in the form of rewards or punishments. The goal is to learn optimal policies that maximize the cumulative reward over time. Here are some popular reinforcement learning models:
- Q-Learning: Q-learning is a model-free reinforcement learning algorithm that uses a value function to estimate the expected cumulative future reward for each state-action pair. It iteratively updates the values based on the reward signals received.
- Deep Q-Networks (DQN): DQN is a deep learning approach to reinforcement learning. It uses neural networks to approximate the Q-function and combines it with experience replay for more stable updates.
- Policy Gradient Methods: Policy gradient methods directly optimize the agent’s policy by estimating the gradient of the expected cumulative reward. They perform updates based on observed rewards and use methods like REINFORCE or Proximal Policy Optimization.
- Actor-Critic Methods: Actor-Critic methods combine the advantages of both value-based and policy-based methods. They have an actor that suggests actions and learns from the environment’s feedback, and a critic that estimates the value function to guide the learning process.
- Monte Carlo Tree Search (MCTS): MCTS is a search algorithm commonly used in reinforcement learning models, especially in games. It builds a search tree by simulating possible future states and selects actions based on the tree exploration and exploitation.
Reinforcement learning models are well-suited for problems where the optimal action needs to be learned through trial and error. They have been successful in various domains, including game playing, robotics, and autonomous decision-making.
It’s important to note that training reinforcement learning models can be time-consuming and computationally intensive, as they require a significant number of interactions with the environment. Careful exploration and exploitation strategies, reward shaping, and model architectures are crucial for training efficient and effective reinforcement learning models.
Now that we have covered the different categories of machine learning models, let’s explore some specific models within each category to gain a deeper understanding of their applications and strengths.
Decision Trees and Random Forests
Decision trees and random forests are versatile supervised learning models that can be used for both regression and classification tasks. Decision trees make predictions by recursively partitioning the feature space based on a series of binary decisions, while random forests combine multiple decision trees to produce more accurate and robust predictions.
A decision tree is a flowchart-like structure where each internal node represents a feature or attribute, each branch represents a decision rule, and each leaf node represents the outcome or class label. The tree structure allows for easy interpretation and understanding of the decision-making process.
Random forests are an ensemble of decision trees. They work by creating a set of decision trees where each tree is randomly trained on a subset of the original data and a subset of the available features. The predictions from all the trees are then combined through a voting mechanism to produce the final prediction.
One of the key advantages of decision trees and random forests is their ability to handle both numerical and categorical input features. They can also handle missing values and automatically select important features, making them robust models in various domains.
Decision trees and random forests have applications in diverse fields, such as finance, healthcare, and image classification. They are especially useful when interpretability and feature importance are important considerations. Decision trees allow you to understand the decision-making process by visualizing the tree structure, while random forests provide insights into feature importance based on their contribution to the overall model performance.
However, one potential limitation of decision trees is their tendency to overfit the training data. They can become overly complex and perform poorly on unseen data. Random forests help mitigate this issue by aggregating predictions from multiple trees and reducing overfitting.
When using decision trees and random forests, it’s important to tune the hyperparameters such as the maximum depth, minimum samples per leaf, and the number of trees in the forest to achieve the best performance. Additionally, feature engineering and selecting relevant features can greatly impact the model’s performance.
In summary, decision trees and random forests are powerful machine learning models that offer interpretability, handle different types of features, and provide robust predictions. They are versatile tools suitable for a wide range of regression and classification tasks.
Support Vector Machines
Support Vector Machines (SVM) are powerful and versatile supervised learning models that can be used for both regression and classification tasks. SVMs find an optimal hyperplane that separates the data points with the largest margin between two classes, maximizing the decision boundary’s robustness.
The key idea behind SVMs is to transform the input data into a higher-dimensional feature space using a kernel function. In this transformed space, SVMs aim to find the hyperplane that best separates the data points of different classes. SVMs use support vectors, which are the data points closest to the decision boundary, to calculate the optimal hyperplane.
One of the advantages of SVMs is their ability to handle high-dimensional and nonlinear data. By using different kernel functions such as linear, polynomial, or radial basis function, SVMs can capture complex relationships between the input features and the output labels.
SVMs have a number of important parameters that should be tuned to achieve the best performance. These include the kernel type, the regularization parameter, and the kernel-specific hyperparameters. Proper tuning is critical to prevent overfitting or underfitting.
SVMs have been successfully used in various domains, including text classification, image recognition, and bioinformatics. They are particularly effective in tasks where the number of features is larger than the number of samples, or when there is a clear separation between classes in the feature space.
However, SVMs may not be well-suited for large datasets or computationally intensive problems due to their training complexity. Additionally, SVMs may struggle when the data is imbalanced or contains overlapping classes.
It’s important to pre-process the input data when using SVMs. Data standardization, feature scaling, and handling missing values can greatly impact the model’s performance. Additionally, feature selection or dimensionality reduction techniques can help improve the SVM’s efficiency and generalization ability.
In summary, Support Vector Machines are powerful models that offer versatility, ability to handle high-dimensional data, and robust decision boundaries. With proper parameter tuning and data preparation, SVMs can be effective tools for various regression and classification tasks.
Naive Bayes
Naive Bayes is a simple yet powerful probabilistic model that is often used for classification tasks, particularly in text classification. Despite its simplicity, Naive Bayes has shown excellent performance in various domains, such as spam detection, sentiment analysis, and document classification.
The key idea behind Naive Bayes is Bayes’ theorem, which provides a way to calculate the probability of a certain event given prior knowledge. Naive Bayes assumes that the features are conditionally independent of each other, meaning that the presence or absence of one feature does not affect the presence or absence of other features. This assumption simplifies the calculations and allows for efficient and fast training and prediction.
Naive Bayes calculates the probabilities of each class given the observed features and selects the class with the highest probability as the predicted class. It relies on counting the occurrence of each feature in the training data and estimating the likelihood of each feature belonging to a specific class.
One of the advantages of Naive Bayes is its efficiency and scalability. It can handle large datasets with high-dimensional input features. Naive Bayes also handles continuous and discrete features well, making it suitable for a wide range of applications.
However, Naive Bayes may struggle with rare events or features that have not been observed in the training data. This is known as the “zero-frequency problem.” To mitigate this, techniques like Laplace smoothing or add-one smoothing can be applied to adjust the probability estimates.
Naive Bayes models are relatively easy to interpret and understand. They can provide insights into the importance of different features for classification, as each feature’s contribution can be quantified through the calculated probabilities.
When using Naive Bayes, it’s important to consider the assumptions of feature independence. While this assumption may not hold in many real-world scenarios, Naive Bayes can still yield good results in practice.
In summary, Naive Bayes is a fast and efficient probabilistic classifier that has proven to be effective in various text classification and other classification tasks. It is particularly useful when dealing with large datasets, high-dimensional features, and time constraints.
K-Nearest Neighbors
K-Nearest Neighbors (KNN) is a popular and versatile classification and regression algorithm. It is a non-parametric model that makes predictions based on the similarity of a new data point to its k nearest neighbors in the training data.
The key idea behind KNN is that similar instances tend to have similar class labels or target values. KNN determines the class of a data point by majority voting among its k nearest neighbors in the feature space. For regression tasks, KNN predicts the average target value of its k nearest neighbors.
K is an important parameter in KNN and needs to be carefully chosen. A smaller value of k may result in a more flexible and complex decision boundary, while a larger k value may lead to a smoother decision boundary but with the risk of introducing more noise.
KNN does not make any assumptions about the underlying data distribution, making it a robust and flexible model. It can handle multi-class classification, non-linear decision boundaries, and various types of data. However, KNN can be sensitive to irrelevant features and the choice of distance metric.
One consideration when using KNN is the efficient storage and retrieval of training data. As the number of data points increases, the search for neighbors becomes more computationally intensive. Techniques like KD-trees or ball trees can be used to accelerate this process.
KNN is often used in recommendation systems, image recognition, and similarity-based tasks. It can also be useful in imputation of missing values, where the missing feature values are estimated based on the values of the nearest neighbors.
When applying KNN, it is essential to preprocess the data by normalizing or standardizing the feature values. This helps avoid biased distances due to differences in feature scales.
In summary, K-Nearest Neighbors is a versatile algorithm that can be used for both classification and regression tasks. It is simple to understand and apply, flexible for different types of data, and can handle non-linear decision boundaries. Careful selection of the k value and preprocessing of the data are important considerations when using KNN.
Neural Networks
Neural networks, often referred to as artificial neural networks or simply “NN,” are powerful machine learning models inspired by the structure and functioning of the human brain. They are known for their ability to learn complex patterns and relationships in data, making them well-suited for a wide range of tasks, including classification, regression, and image recognition.
Neural networks consist of interconnected nodes, called artificial neurons or “units,” organized in layers. The input layer receives the input data, which is then passed through one or more hidden layers that perform complex transformations. The final output is generated by the output layer, which provides the model’s predictions or decisions.
One of the key strengths of neural networks is their ability to automatically learn feature representations from raw data. During training, the network adjusts the weights and biases of the connections between the units to minimize the difference between the predicted and actual outputs. This process, known as backpropagation, allows the model to gradually improve its performance over multiple iterations.
Neural networks can be shallow or deep, depending on the number of hidden layers. Deep neural networks, also known as deep learning models, have gained significant attention due to their ability to learn hierarchical and abstract representations of data.
Deep learning models, such as Convolutional Neural Networks (CNNs) for image recognition and Recurrent Neural Networks (RNNs) for sequential data, have achieved remarkable success in various domains. They have surpassed human-level performance in tasks like object detection, natural language processing, and speech recognition.
One challenge when using neural networks is the potential for overfitting. The complex architecture and large number of parameters make neural networks prone to memorizing noise or irrelevant patterns in the training data. Regularization techniques, such as dropout or L1/L2 regularization, can help reduce overfitting.
Another consideration is the computational resources required for training and inference. Deep learning models can be computationally intensive, requiring powerful hardware like GPUs or specialized hardware accelerators. However, the availability of libraries and frameworks, such as TensorFlow and PyTorch, makes it easier to develop and train neural networks.
In summary, neural networks are versatile models that can learn complex patterns and relationships from data. They have achieved state-of-the-art performance in various machine learning tasks and domains. With careful architecture design, regularization, and sufficient computational resources, neural networks can provide highly accurate and robust predictions.
Deep Learning Models
Deep learning models, a subset of neural networks, have gained significant attention and revolutionized the field of artificial intelligence in recent years. These models are characterized by their ability to learn hierarchical representations of data, enabling them to handle complex tasks and achieve state-of-the-art performance in various domains.
At the heart of deep learning models are architectures with multiple layers of interconnected artificial neurons. The depth of these models allows them to learn and extract intricate features and patterns from raw data. Deep learning models have proven to be particularly effective in tasks like image classification, natural language processing, and speech recognition.
Convolutional Neural Networks (CNNs) are a popular type of deep learning model widely used in computer vision tasks. CNNs employ convolutional layers that can automatically learn spatial hierarchies of features. This makes them well-suited for tasks like object detection, image segmentation, and facial recognition.
Recurrent Neural Networks (RNNs) are another important class of deep learning models that excel in handling sequential data. RNNs have connections that create loops, allowing information to persist and be passed from one step to another. This enables RNNs to capture dependencies and patterns in time series data, making them ideal for tasks like speech recognition, sentiment analysis, and machine translation.
One of the key advantages of deep learning models is their ability to learn feature representations directly from raw data, often eliminating the need for manual feature engineering. This automated feature learning capability reduces the reliance on domain expertise and speeds up the model development process.
However, deep learning models also present some challenges. They can be computationally intensive and require significant amounts of training data. Training deep learning models on large datasets may necessitate powerful hardware, such as GPUs or specialized processors like Tensor Processing Units (TPUs), and can be time-consuming.
In addition, deep learning models are prone to overfitting due to their large number of parameters. Techniques like dropout, batch normalization, early stopping, and regularization can help mitigate overfitting and enhance generalization performance.
Despite these challenges, the power and versatility of deep learning models have made them a driving force in the advancement of artificial intelligence. Continuous research and innovation in deep learning continue to push the boundaries of what machines can achieve in understanding and interpreting complex data.
Evaluating Model Performance
Evaluating the performance of machine learning models is crucial in ensuring their effectiveness and identifying the best model for a given task. There are several key metrics and techniques used to evaluate model performance, each providing insights into different aspects of the model’s capabilities. Let’s explore some common evaluation methods:
Accuracy: Accuracy is the most basic and widely used metric for classification tasks. It measures the proportion of correctly predicted instances out of the total number of instances.
Precision and Recall: Precision and recall are important metrics, especially when dealing with imbalanced datasets or when the cost of false positives and false negatives varies. Precision measures the proportion of true positives out of the predicted positive instances, while recall measures the proportion of true positives out of the actual positive instances.
F1 Score: The F1 score is the harmonic mean of precision and recall. It provides a balanced measure of a model’s performance by considering both precision and recall simultaneously. The F1 score is useful when you want to find a balance between precision and recall.
ROC and AUC: Receiver Operating Characteristic (ROC) curves and the associated Area Under the Curve (AUC) are commonly used for binary classification tasks. The ROC curve visualizes the trade-off between true positive rate and false positive rate at various threshold settings. AUC summarizes the performance of the model across all possible thresholds.
Mean Squared Error (MSE) and R-squared: For regression tasks, MSE measures the average squared difference between the predicted and actual values. A lower MSE indicates better model performance. R-squared, or the coefficient of determination, measures the proportion of the variance in the target variable that can be explained by the model.
Cross-validation: Cross-validation is a technique used to estimate the performance of a model on unseen data. It involves dividing the data into multiple subsets, training the model on a portion of the data, and evaluating its performance on the remaining subset. This helps assess the model’s generalization ability and reduce the impact of random variations in the data.
In addition to these metrics, it’s important to consider the specific requirements of the task, as different evaluation measures may be appropriate. It’s also crucial to validate the model’s performance on external validation datasets, as a model’s performance on the training data may not fully reflect its performance on new, unseen data.
Finally, it’s essential to remember that evaluation should be an iterative process. Continuously monitoring and assessing model performance allows for model refinement and improvement over time.
Conclusion
Machine learning models provide powerful tools for solving complex problems and extracting valuable insights from data. In this article, we have explored various types of machine learning models, including supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning models.
We discussed the factors to consider when choosing a model, such as accuracy, interpretability, scalability, robustness, flexibility, and resource requirements. Understanding these factors helps in selecting the most suitable model for a specific task.
We delved into specific models within each category, highlighting their strengths, applications, and considerations. Decision trees and random forests offer robust and interpretable predictions, while support vector machines excel in separating classes with maximum margin.
Naive Bayes models provide probabilistic classification, and K-nearest neighbors employ similarity-based predictions. In the realm of neural networks, we explored the power of deep learning models in learning complex patterns and hierarchies from raw data.
We also covered the importance of evaluating model performance using metrics like accuracy, precision, recall, F1 score, AUC-ROC, MSE, and R-squared. Cross-validation ensures the model’s generalization ability and reduces overfitting risks.
In conclusion, choosing the right model depends on various factors, such as the problem at hand, the available data, and the desired performance and interpretability requirements. By understanding the strengths and considerations of different models, one can make informed decisions in selecting and evaluating the best model for the task.
Machine learning continues to evolve with advancements in algorithms, computing power, and data availability. The exploration and application of different machine learning models open up new realms of possibilities for solving complex problems and unearthing valuable insights in various domains.