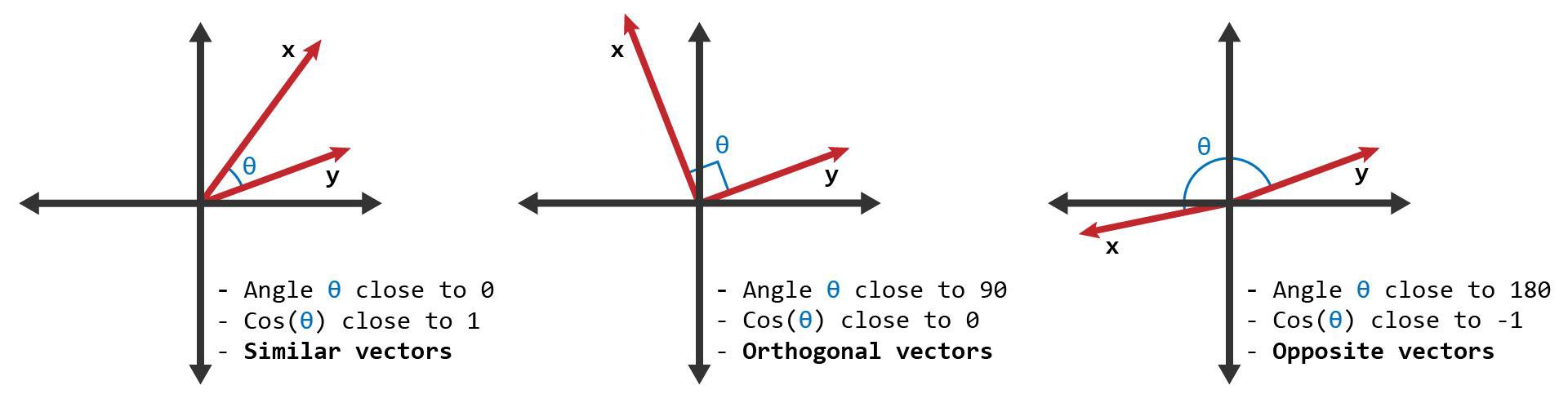
What is Machine Learning?
Machine learning is a subset of artificial intelligence that focuses on the development of algorithms and models that enable computer systems to learn and make predictions or decisions without being explicitly programmed. It is based on the idea that machines can learn from and adapt to data, just like humans do.
Machine learning algorithms use statistical techniques to recognize patterns and relationships within vast amounts of data. These algorithms then use these patterns to make predictions or take actions in response to new inputs or situations.
One of the key features of machine learning is its ability to improve its performance through experience. The more data a machine learning model is exposed to, the better it becomes at making accurate predictions or decisions.
Machine learning is being used in various fields and industries, from healthcare to finance to marketing. In healthcare, machine learning models are used to diagnose diseases, predict patient outcomes, and analyze large amounts of medical data. In finance, machine learning models help detect fraudulent transactions, make investment predictions, and optimize trading strategies. In marketing, machine learning is used to personalize customer experiences, recommend products, and identify patterns in consumer behavior.
There are different types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning. Each type has its own unique characteristics and applications.
Supervised learning uses labeled datasets to train models. The algorithm learns from the labeled data and then makes predictions or classifies new, unseen data based on what it has learned. This type of learning is commonly used in tasks such as image recognition, speech recognition, and sentiment analysis.
Unsupervised learning, on the other hand, does not require labeled data. It focuses on finding patterns, relationships, and structures in unlabeled data. Clustering, anomaly detection, and dimensionality reduction are some examples of unsupervised learning tasks.
Reinforcement learning involves an agent interacting with an environment and learning from the feedback or rewards it receives. The agent explores the environment, takes actions, and learns to maximize its rewards or minimize its penalties. This type of learning is often used in applications such as robotics, gaming, and autonomous vehicles.
In summary, machine learning is a powerful tool that enables computers to learn from data and make intelligent decisions or predictions. Its applications span across industries and continue to evolve as more data becomes available and algorithms improve.
The Basics of Machine Learning
Machine learning is a complex field, but it is rooted in some fundamental concepts. Understanding these basics is crucial for grasping the essence of machine learning and its applications.
At its core, machine learning revolves around the idea of training a model to learn from data and make predictions or decisions. The model is built using algorithms that analyze the patterns and relationships within the data.
One of the key components of machine learning is the training dataset. This dataset consists of labeled examples that the model uses to learn. Each example in the dataset consists of input variables, also known as features, and an associated output variable, also known as the target variable. The model learns the patterns in the data by adjusting its internal parameters to minimize the error between the predicted outputs and the actual outputs.
Once the model is trained, it can then be used to make predictions or decisions on new, unseen data. This is known as the prediction or inference phase. The accuracy and reliability of the model’s predictions are assessed by evaluating its performance on a separate set of data, called the test dataset.
Machine learning algorithms can be categorized into two main types: supervised learning and unsupervised learning. In supervised learning, the training dataset is labeled, meaning that the desired outputs for each example are known. The model learns to map the input variables to the correct output variables. Classification and regression are common tasks in supervised learning.
Unsupervised learning, on the other hand, deals with unlabeled data. The model’s objective is to find patterns or structures in the data. Clustering and dimensionality reduction are some of the tasks performed in unsupervised learning. Reinforcement learning is another type of machine learning, where an agent learns to interact with an environment and make decisions based on the feedback it receives.
Data preprocessing is a crucial step in machine learning. It involves cleaning the data, handling missing values, scaling features, and transforming variables to make them suitable for the model. This step ensures the quality and reliability of the data before training the model.
Feature selection or extraction is another important aspect of machine learning. It involves choosing the most relevant features from the dataset or transforming the existing features to create new ones. This helps in improving the model’s performance and reducing computational complexity.
Regularization techniques are used to prevent overfitting, where the model becomes too complex and performs poorly on new data. Cross-validation is a popular technique for assessing the generalization ability of the model and selecting the optimal hyperparameters.
In summary, the basics of machine learning involve training a model using data, making predictions or decisions based on the learned patterns, and assessing the model’s performance. Understanding the fundamentals of supervised learning, unsupervised learning, data preprocessing, and regularization is essential for building effective machine learning models.
The Role of Data in Machine Learning
Data plays a crucial role in machine learning. It serves as the foundation for training the models, evaluating their performance, and making accurate predictions or decisions. The quality, quantity, and relevance of the data significantly impact the effectiveness of machine learning algorithms.
Machine learning models rely on data to identify patterns, learn from examples, and make predictions. The more diverse and representative the data, the better the model can capture the underlying relationships and generalize to new, unseen instances.
One of the key considerations in machine learning is the availability of labeled data. In supervised learning, where the model learns from labeled examples, having high-quality labeled data is essential. This data serves as a reference for the model to learn the correct associations between the input variables and the output variables.
In many cases, obtaining labeled data can be costly or time-consuming. In such scenarios, techniques like transfer learning or semi-supervised learning can be used to leverage existing labeled data or utilize a smaller subset of labeled data combined with a larger amount of unlabeled data.
The quality of the data is equally important. Data preprocessing steps, such as handling missing values, removing outliers, and balancing the dataset, are crucial for training a reliable machine learning model. Cleaning the data ensures that the model does not learn from noise or irrelevant information, leading to more accurate predictions.
Another aspect to consider is the dimensionality of the data. High-dimensional datasets with a large number of features can pose challenges, including computational complexity and the curse of dimensionality. Feature selection or extraction techniques can be applied to reduce the dimensionality and improve the model’s performance.
Data diversity and representativeness are crucial for enabling the model to generalize well to new instances. Biased or skewed data can lead to biased models and inaccurate predictions. Therefore, it is important to ensure that the data used for training is representative of the target population and covers a wide range of scenarios and variations.
In addition to the training data, having a separate test dataset is essential for evaluating the model’s performance. This allows for an unbiased assessment of how well the model generalizes to new, unseen data. The test dataset should be carefully selected to reflect real-world scenarios and should not be used for model training to avoid overfitting.
Overall, data is the fuel that powers machine learning. The availability of high-quality, diverse, and representative data is crucial for training accurate and reliable models. Proper data preprocessing, handling of missing values, dimensionality reduction, and maintaining data integrity are key considerations in machine learning projects.
The Different Types of Machine Learning Algorithms
Machine learning algorithms can be categorized into several types, each with its own characteristics and applications. The choice of algorithm depends on the nature of the data and the specific problem at hand.
1. Supervised Learning: This type of learning involves training a model on labeled data, where the desired outputs are known. It learns to map the input variables to the correct output variables. Classification algorithms, such as logistic regression, decision trees, and support vector machines, are used for predicting discrete labels. Regression algorithms, such as linear regression and random forest regression, are used for predicting continuous values.
2. Unsupervised Learning: In unsupervised learning, the training data is unlabeled, and the model discovers patterns and relationships within the data. Clustering algorithms, like k-means and hierarchical clustering, group similar instances together based on their features. Dimensionality reduction techniques, such as principal component analysis (PCA) and t-SNE, reduce the number of features while preserving important information. Anomaly detection algorithms identify outliers or anomalies within the data.
3. Reinforcement Learning: This type of learning involves an agent interacting with an environment and learning from the feedback it receives. The agent takes actions, and based on the rewards or penalties it receives, it learns to optimize its decisions to receive maximum rewards. Reinforcement learning algorithms are commonly used in robotics, gaming, and optimization problems.
4. Semi-Supervised Learning: This type of learning utilizes a combination of labeled and unlabeled data for training. It leverages the small amount of labeled data to guide the learning process while taking advantage of the larger amount of unlabeled data. Semi-supervised learning algorithms can be especially useful when labeling large datasets is expensive or time-consuming.
5. Transfer Learning: Transfer learning involves leveraging knowledge from one domain or problem to another. In this approach, a model pre-trained on a large dataset for a specific task is used as a starting point for a new, related task. By transferring the learned features and knowledge, the model can be trained with a smaller dataset and achieve better performance.
6. Deep Learning: Deep learning algorithms, specifically neural networks, are designed to simulate the complex workings of the human brain. They consist of multiple layers of interconnected nodes (neurons) and are capable of learning hierarchical representations of data. Deep learning has achieved remarkable success in computer vision, natural language processing, and speech recognition tasks.
Each type of machine learning algorithm has its own strengths and weaknesses, and the choice depends on the problem domain, available data, and desired outcomes. A thorough understanding of these algorithms and their capabilities is crucial for effectively applying machine learning techniques.
Data Preprocessing in Machine Learning
Data preprocessing is a crucial step in machine learning that involves transforming raw data into a clean, consistent, and reliable format. This process helps prepare the data for training machine learning models and ensures the accuracy and quality of the results.
Here are some common techniques used in data preprocessing:
1. Data Cleaning: This step involves handling missing values, which are often represented as NaN or null in the dataset. Missing values can be imputed by replacing them with a suitable value, such as the mean or median of the feature, or by using advanced techniques like regression imputation or multiple imputation. Outliers, or extreme values that deviate from the overall pattern, can also be identified and handled through techniques like z-score or percentile analysis.
2. Data Transformation: Sometimes, the distribution of the data may not be suitable for the machine learning algorithm. In such cases, feature scaling techniques like normalization or standardization can be applied. Normalization scales the data to a specific range, such as between 0 and 1, while standardization transforms the data to have zero mean and unit variance. Another transformation technique is log transformation, which can be useful for handling skewed data.
3. Encoding Categorical Variables: Many machine learning algorithms require numerical inputs, but categorical variables often contain non-numeric labels. One way to handle this is by one-hot encoding, where each category is encoded as a binary vector. Another approach is label encoding, where each category is assigned a unique numerical value. The choice between these techniques depends on the nature of the data and the algorithm being used.
4. Handling Imbalanced Data: Imbalanced datasets occur when the distribution of classes is skewed, with one class having a significantly larger number of instances than the others. This can lead to biased models that perform poorly on minority classes. Techniques like undersampling (removing instances from the majority class), oversampling (duplicating instances from the minority class), or the use of advanced methods like SMOTE (Synthetic Minority Over-sampling Technique) can be employed to address class imbalance.
5. Feature Selection: Not all features in a dataset may contribute equally to the performance of the model. Irrelevant or redundant features can introduce noise and increase computational complexity. Feature selection techniques, such as correlation analysis, forward or backward selection, or L1 regularization, help identify the most relevant features and discard the unnecessary ones.
6. Data Split: Before training a model, the dataset is typically split into training and testing sets. The training set is used to train the model, while the testing set evaluates its performance on unseen data. Care should be taken to ensure that the split is representative and avoids leakage of information between the training and testing sets.
Data preprocessing is a vital step in machine learning that ensures the quality and integrity of the data used for training the models. By applying appropriate techniques to handle missing values, transform data distributions, encode categorical variables, address class imbalance, select relevant features, and split the data, we can set a solid foundation for building accurate and reliable machine learning models.
Training and Testing Split
The training and testing split is a critical step in machine learning that involves dividing the dataset into two parts: a training set and a testing set. The training set is used to train the machine learning model, while the testing set is used to evaluate its performance on unseen data.
The purpose of this split is to assess how well the model generalizes to new, unseen instances. By evaluating the model on a separate testing set, we can get an unbiased estimate of its performance and ensure that it is not overfitting to the training data.
Here are the key factors to consider when performing the training and testing split:
1. Dataset Size: The size of the dataset plays a crucial role in determining the split ratio. Generally, the larger the dataset, the smaller the proportion assigned to the testing set. A common practice is to use a 70-30 or 80-20 split, where 70% or 80% of the data is used for training and the remaining 30% or 20% is reserved for testing.
2. Randomization: To ensure the fairness of the split, it is important to randomize the order of the data instances before splitting. By shuffling the dataset, we can prevent any potential biases or patterns in the data from influencing the split.
3. Stratified Split: In classification tasks with imbalanced class distributions, it is advisable to perform a stratified split. This means that the proportion of each class in the training and testing sets is representative of the overall class distribution. This helps ensure that the model is trained and tested on a diverse range of instances from each class.
4. Train-Validation Split: In addition to the training and testing split, it is common to further split the training set into training and validation subsets. The training set is used to train the model, while the validation set is used to tune hyperparameters and assess the model’s performance during the training process. This helps prevent overfitting and allows for early stopping based on the performance on the validation set.
5. Cross-Validation: Cross-validation is a technique that involves splitting the dataset into multiple folds, performing the training and testing process multiple times, and averaging the results. This helps provide a more robust assessment of the model’s performance and reduces the dependency on a single train-test split. Cross-validation is especially useful when the dataset is limited in size.
The training and testing split is a fundamental step in machine learning that helps gauge the performance and generalization of the model. By carefully considering the dataset size, randomization, stratification, train-validation split, and cross-validation, we can ensure a reliable evaluation of the model’s capabilities and make informed decisions for model selection and parameter tuning.
How Does a Machine Learning Model Learn?
A machine learning model learns by analyzing data and identifying patterns and relationships within it. The learning process involves adjusting the model’s internal parameters to minimize the error between the predicted outputs and the actual outputs. Let’s explore the steps involved in how a machine learning model learns:
1. Data Input: The learning process begins with feeding input data into the model. This data contains features or attributes that serve as the input variables for the model.
2. Model Initialization: Initially, the model’s internal parameters are randomly initialized. These parameters represent the weights and biases that define the relationship between the input features and the predicted outputs.
3. Forward Propagation: The model processes the input data through a series of mathematical operations to produce an output prediction. This process is known as forward propagation. The model takes the input features, applies the learned parameters, and generates a predicted output.
4. Error Calculation: After the forward propagation step, the model compares its predicted output with the actual output from the training data. This comparison results in an error or a loss value, which quantifies the discrepancy between the predicted and actual values.
5. Backward Propagation: The next step is to propagate the error backward through the model. The model calculates the gradient of the error with respect to its internal parameters using a technique called backpropagation. This gradient provides information about how the model’s parameters need to be adjusted to minimize the error.
6. Parameter Update: Based on the gradients obtained from the backpropagation process, the model updates its internal parameters using optimization algorithms such as gradient descent. These updates gradually steer the model towards the optimal set of parameters that minimize the error.
7. Iterative Learning: The learning process is iterative, meaning that the model repeats the steps of forward propagation, error calculation, backward propagation, and parameter update multiple times. Each iteration, or epoch, allows the model to adjust its parameters and reduce the error between the predicted and actual outputs.
8. Convergence: The learning process continues until the model reaches a point of convergence, where the error is minimized, and the model’s predictions align closely with the actual values. The convergence point indicates that the model has learned the underlying patterns and relationships in the data.
9. Generalization: Once the model has learned from the training data, it can be tested on new, unseen data to assess its performance and generalization ability. The model’s ability to make accurate predictions on unseen data demonstrates its learning capabilities.
By repeating the iterative learning process, adjusting its internal parameters based on the error, and gradually minimizing the discrepancy between predicted and actual values, a machine learning model learns to make predictions or decisions based on new inputs. Understanding how a model learns is key to effectively building and training machine learning models.
The Process of Training a Machine Learning Model
The process of training a machine learning model involves several steps that enable the model to learn from data and make accurate predictions or decisions. Let’s delve into the key stages of training a machine learning model:
1. Problem Definition: The first step is to clearly define the problem and identify the objective of the model. This includes determining whether it is a classification, regression, or another type of problem that needs to be solved using machine learning.
2. Data Collection: Gathering a suitable and representative dataset is essential for training a model. The data should cover a wide range of scenarios and variations related to the problem at hand. It may involve collecting data from various sources, such as databases, APIs, or online repositories.
3. Data Preprocessing: Before training the model, the data needs to be prepared through various preprocessing techniques. This may include handling missing values, cleaning the data, transforming variables, and encoding categorical features to ensure that the data is in a suitable format for the model.
4. Splitting the Dataset: The dataset is split into training and testing sets. The training set is used to train the model, while the testing set is used to evaluate its performance on unseen data. This split helps assess the model’s ability to generalize and make accurate predictions on new data.
5. Model Selection: Choosing an appropriate machine learning algorithm is crucial for the success of the model. Factors such as the problem type, data characteristics, and computational requirements need to be considered. Different algorithms, such as decision trees, support vector machines, or deep learning models, may be evaluated to identify the most suitable one.
6. Training the Model: The model is trained by feeding the training data into the selected algorithm. During training, the model adjusts its internal parameters based on the input-output pairs in the training set to minimize the error. This process involves multiple iterations or epochs to gradually improve the model’s predictions.
7. Hyperparameter Tuning: Hyperparameters are settings that are not learned from the data but need to be set manually before training. These parameters can have a significant impact on the model’s performance. Techniques such as cross-validation, grid search, or random search can be used to find the optimal combination of hyperparameters.
8. Model Evaluation: Once the model has been trained, it is evaluated using the testing set. The performance metrics, such as accuracy, precision, recall, or mean squared error, are calculated to assess how well the model performs on unseen data. This evaluation provides insight into the model’s ability to generalize and make accurate predictions.
9. Iterative Refinement: Based on the evaluation results, the model may undergo further improvements or refinements. This may involve adjusting hyperparameters, collecting more data, or trying different preprocessing techniques. The process is iterative until a satisfactory level of performance is achieved.
10. Deployment and Monitoring: Once the model has been trained and evaluated, it can be deployed for real-world use. Monitoring and continuous evaluation of the model’s performance are necessary to ensure its accuracy and adaptability as new data becomes available.
By following these steps, the process of training a machine learning model can lead to the development of robust, accurate, and reliable models that can make valuable predictions or decisions based on data.
Evaluating a Machine Learning Model
Evaluating a machine learning model is crucial to assess its performance, measure its effectiveness, and ensure its reliability in making accurate predictions or decisions. The evaluation process involves using various metrics and techniques to quantify the model’s performance on unseen data. Let’s explore the key aspects of evaluating a machine learning model:
1. Performance Metrics: Performance metrics provide quantitative measures of how well the model is performing. The choice of metrics depends on the type of problem being solved. For classification tasks, metrics such as accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC) are commonly used. For regression tasks, mean squared error (MSE), root mean squared error (RMSE), mean absolute error (MAE), and R-squared are commonly used.
2. Confusion Matrix: A confusion matrix is a tabular representation that summarizes the performance of a classification model. It displays the number of correctly classified instances (true positives and true negatives) and the number of incorrectly classified instances (false positives and false negatives). From the confusion matrix, metrics such as precision, recall, and F1-score can be calculated.
3. Cross-Validation: Cross-validation is a technique used to assess the generalization ability of the model and reduce dependency on a single train-test split. It involves dividing the dataset into multiple folds, training the model on different combinations of these folds, and evaluating its performance on the remaining fold. This helps provide a more robust estimate of the model’s performance by averaging the results from multiple train-test splits.
4. Overfitting and Underfitting: Overfitting occurs when a model performs well on the training data but poorly on the testing data. This usually happens when the model becomes too complex and starts to memorize the training examples instead of learning the underlying patterns. Underfitting, on the other hand, occurs when the model is too simple to capture the complexities in the data. Evaluating a model helps identify whether it is suffering from overfitting or underfitting.
5. Validation Set: During the training process, a separate validation set can be used to fine-tune the model’s hyperparameters and assess its performance. This allows for an early indication of how the model will perform on unseen data and helps with model selection and parameter tuning.
6. Bias and Variance: Evaluating a model helps identify the trade-off between bias and variance. Bias refers to the model’s ability to capture the underlying patterns and relationships in the data, while variance refers to the model’s sensitivity to fluctuations in the training data. A high-bias model may underperform, while a high-variance model may overfit. Balancing bias and variance is crucial for achieving a well-performing, generalizable model.
7. Domain-Specific Evaluation: In some cases, domain-specific evaluation measures may be necessary to assess the model’s performance. This can involve metrics specific to the industry or field in which the model is being applied. For example, in medical diagnosis, evaluation may involve metrics such as sensitivity, specificity, or positive predictive value.
Evaluating a machine learning model is an iterative process. By assessing its performance using appropriate metrics, identifying potential issues like overfitting or underfitting, and fine-tuning hyperparameters, we can ensure that the model is reliable, accurate, and capable of making informed decisions or predictions on unseen data.
Common Challenges in Machine Learning
Machine learning is a complex field with its share of challenges and obstacles. Understanding and addressing these challenges is crucial for building effective and reliable machine learning models. Let’s explore some of the common challenges encountered in machine learning:
1. Insufficient or Poor Quality Data: The quality, quantity, and relevance of the data have a significant impact on the performance of machine learning models. Insufficient or biased data can lead to inaccurate predictions or biased models. Cleaning the data, handling missing values, and ensuring data diversity are necessary steps to overcome this challenge.
2. Overfitting and Underfitting: Overfitting occurs when a model performs exceptionally well on the training data but fails to generalize to new, unseen data. Underfitting, on the other hand, occurs when the model is not able to capture the underlying patterns in the data. Balancing bias and variance, optimizing the model’s complexity, and using techniques like regularization are key to address these challenges.
3. Feature Selection and Dimensionality: Selecting relevant features from the data and handling high-dimensional datasets can be challenging. Including irrelevant or redundant features can lead to noisy models and increased computational complexity. Feature selection techniques, such as correlation analysis or penalty-based methods, and dimensionality reduction techniques, like principal component analysis (PCA), can help mitigate these challenges.
4. Class Imbalance: In classification tasks, when the classes are imbalanced, meaning one class has significantly more instances than others, models may classify the majority class accurately while neglecting the minority classes. Techniques such as undersampling, oversampling, or generating synthetic samples can address class imbalance issues and ensure fair and accurate predictions for all classes.
5. Hyperparameter Tuning: Models often have hyperparameters that need to be set manually, such as the learning rate, regularization parameters, or the number of hidden layers in a neural network. Selecting appropriate hyperparameters to optimize the model’s performance can be challenging and is typically done through techniques like grid search, random search, or Bayesian optimization.
6. Interpretability and Explainability: Some machine learning models, such as deep learning models, are considered black boxes, meaning it can be challenging to interpret the reasons behind their predictions. In certain applications, interpretability and explainability are crucial, especially in domains where decisions have legal, ethical, or safety implications. Techniques like feature importance analysis, rule-based models, or model-agnostic methods can enhance interpretability.
7. Computational Resources: Training complex models or working with large datasets can require significant computational resources, including processing power and memory. Limited resources can hinder the training process, require compromises in model complexity, or increase the training time. Utilizing cloud-based services or distributed computing frameworks can help overcome these constraints.
8. Ethical Considerations: Machine learning models have the potential to amplify biases or perpetuate discrimination present in the data they are trained on. Ensuring fairness, transparency, privacy, and ethical use of the models is a critical challenge. Regular audits, bias detection and mitigation, diversity in training data, and compliance with legal and ethical guidelines are crucial to address these concerns.
Addressing these challenges in machine learning requires a combination of technical expertise, domain knowledge, and continuous learning. By understanding and proactively addressing these challenges, we can improve the performance and reliability of machine learning models and make better-informed decisions.
The Future of Machine Learning
The field of machine learning has seen significant advancements in recent years, and its future holds immense promise and potential. Here are some key trends and developments that shape the future of machine learning:
1. Deep Learning and Neural Networks: Deep learning, a subset of machine learning, has revolutionized various domains such as computer vision, natural language processing, and speech recognition. The future will witness further advancements in deep learning architectures, training techniques, and model interpretability, enabling even more complex and accurate predictions.
2. Explainable AI: As machine learning becomes more pervasive, the demand for models that are transparent and explainable is increasing. Efforts are being made to develop techniques and algorithms that enable better understanding and interpretation of machine learning models. This will be crucial for applications in sensitive domains like healthcare and finance, where interpretability is paramount.
3. Federated Learning: Federated learning is a distributed machine learning approach that allows models to be trained collaboratively on data from multiple devices while ensuring data privacy. This emerging paradigm paves the way for privacy-preserving machine learning, enabling organizations to leverage collective intelligence while safeguarding user data.
4. AutoML: Automated Machine Learning (AutoML) aims to automate the machine learning pipeline, reducing the need for manual intervention in model selection, hyperparameter tuning, and feature engineering. AutoML tools and frameworks are poised to become more sophisticated, making machine learning more accessible to non-experts and accelerating the development of advanced models.
5. Reinforcement Learning in Real-World Applications: Reinforcement learning, traditionally used in controlled environments like games, is increasingly being applied to real-world problems such as robotics, autonomous vehicles, and resource management. The future will witness more research and development in reinforcement learning algorithms that can handle complex, dynamic environments and real-time decision-making.
6. Interdisciplinary Applications: Machine learning is finding applications across diverse domains, including healthcare, finance, transportation, agriculture, and social sciences. Future advancements will involve more interdisciplinary collaborations, leveraging machine learning in conjunction with domain-specific expertise to address complex challenges and make breakthroughs.
7. Ethical Considerations: As machine learning becomes more prevalent, ethical considerations about bias, fairness, accountability, and transparency need to be addressed. The future of machine learning will involve developing robust frameworks and guidelines to ensure responsible and ethical AI deployment, fostering trust between AI systems and users.
8. Continued Research and Learning: The field of machine learning is dynamic and constantly evolving. Its future will heavily rely on ongoing research, collaboration, and learning. As new algorithms, techniques, and tools emerge, the machine learning community will continue to push the boundaries, driving innovation and addressing new challenges.
The future of machine learning is exciting and holds tremendous potential for transforming industries, improving decision-making, and enhancing various aspects of our lives. With continued progress and advancements, machine learning will become an integral part of our daily lives, empowering us to solve complex problems and make data-driven decisions.