Introduction
Data plays a crucial role in machine learning. It serves as the foundation upon which models are built, trained, and evaluated. However, not all data is created equal. In many cases, the input data for machine learning algorithms can be messy, inconsistent, and even incompatible with the desired outcome.
To overcome these challenges, data standardization is implemented. Data standardization refers to the process of transforming data into a consistent and uniform format that can be easily understood and processed by machine learning algorithms. By applying standardization techniques, data is normalized and organized, making it suitable for analysis and modeling.
Data standardization is a fundamental step in the machine learning pipeline as it has a significant impact on the accuracy and performance of the models. It ensures that the data is prepared and preprocessed in a way that eliminates biases, reduces noise, and improves the overall quality.
This article aims to explore the importance of data standardization in machine learning and highlight its benefits. We will also delve into the techniques for data standardization, and discuss the key considerations when applying these techniques.
By the end of this article, you will have a clear understanding of why data standardization is an essential aspect of machine learning and how it contributes to the success of predictive models. So, let’s dive in and explore the world of data standardization in machine learning.
What is data standardization?
Data standardization, also known as data normalization, is the process of transforming data into a consistent and uniform format. It involves reorganizing and restructuring the data to ensure that it adheres to a predefined set of rules or specifications. The goal of data standardization is to make the data more manageable, comparable, and suitable for analysis and modeling.
In the context of machine learning, data standardization involves transforming the input data into a common scale or range. This normalization process brings all the features or variables within the dataset to a similar magnitude, enabling the algorithms to make accurate and meaningful comparisons.
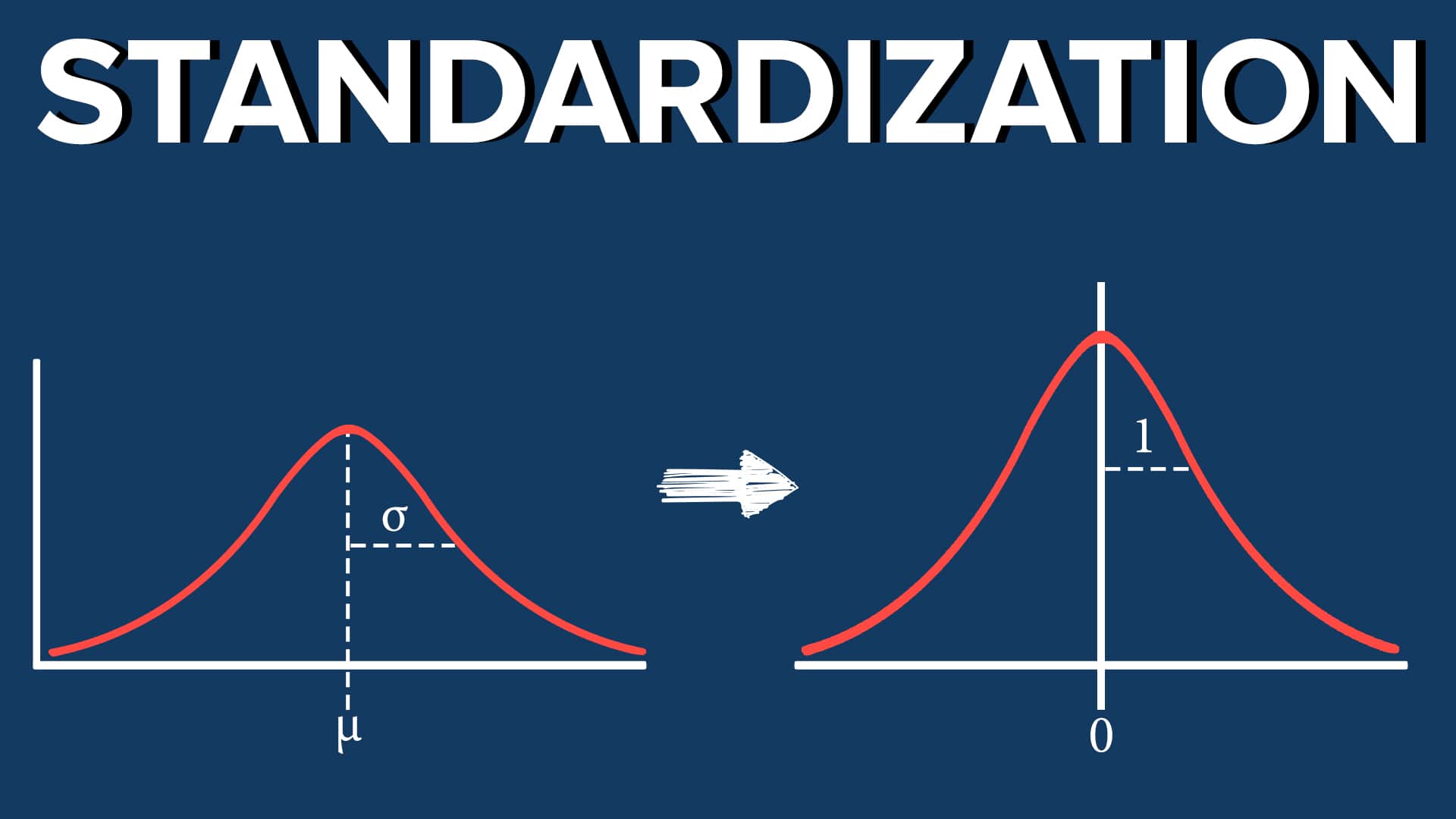
Data standardization encompasses various techniques to handle different types of data. For numerical data, the most common technique is known as z-score standardization or standard score. This technique involves subtracting the mean and dividing by the standard deviation, resulting in a distribution with a mean of 0 and a standard deviation of 1.
Another technique for data standardization is min-max scaling. It rescales the data to a specific range, typically between 0 and 1. This method involves subtracting the minimum value and dividing by the range (maximum value minus the minimum value), effectively mapping the data to the desired range.
For categorical data, standardization involves transforming the categories into numerical representations. This can be done through one-hot encoding, where each category is represented by a binary variable. Alternatively, ordinal encoding assigns numerical values to the categories based on their order or importance.
Data standardization is not limited to numerical and categorical data. It can also be applied to textual data through techniques like stemming, lemmatization, and removing stop words. These techniques simplify and normalize text data, making it easier to analyze and model.
Overall, data standardization is a crucial step in machine learning to ensure that the input data is converted into a consistent and uniform format. By standardizing the data, algorithms can effectively process and interpret the information, leading to more accurate and reliable predictions and insights.
In the next section, we will discuss why data standardization is essential in machine learning and the benefits it brings to the modeling process.
Why is data standardization important in machine learning?
Data standardization plays a crucial role in machine learning by ensuring that the input data is in a consistent and uniform format. Here are several reasons why data standardization is important in machine learning:
1. Eliminating biases: Data collected from different sources or systems may contain biases or inconsistencies. Standardizing the data removes these biases, ensuring that the models are trained on a fair and balanced dataset. This leads to more unbiased and accurate predictions.
2. Reducing noise: In real-world datasets, it is common to have outliers or noisy data points that can skew the modeling process. Data standardization techniques, such as z-score normalization, help reduce the impact of outliers and make the data more robust and reliable.
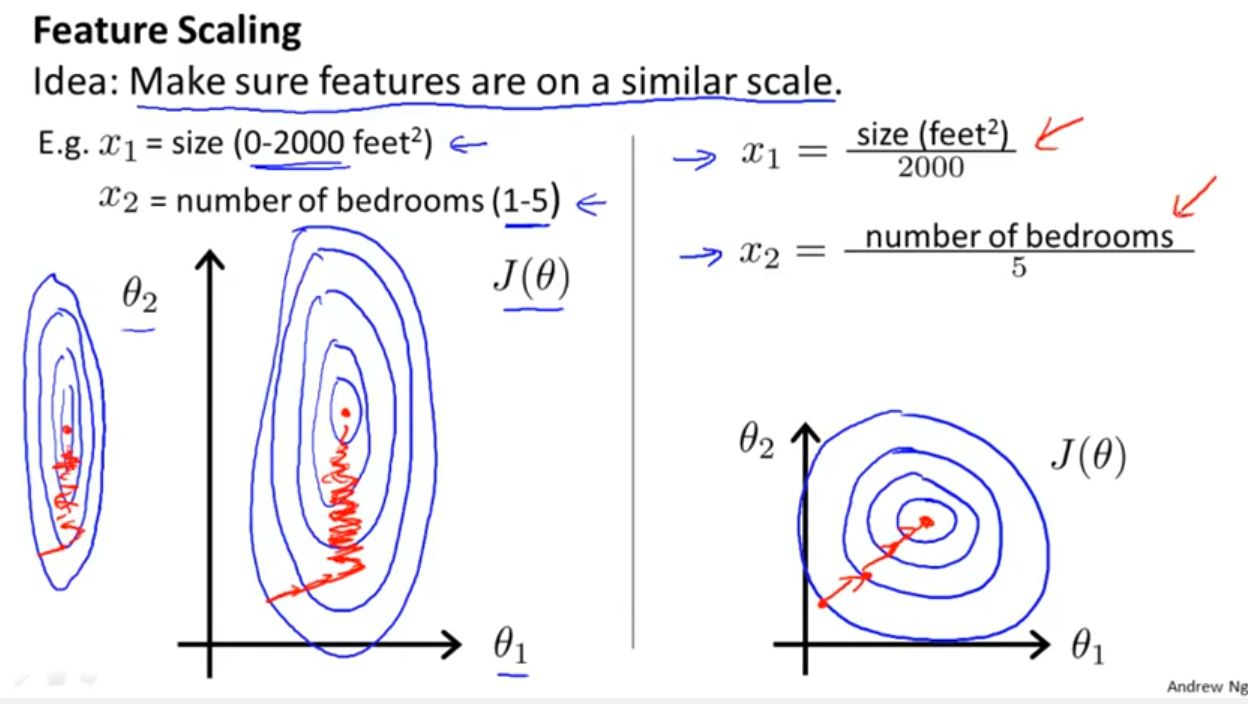
3. Improving comparability: When working with multiple features or variables, data standardization brings them to a similar scale or range. This makes it easier to compare and analyze the impact of different features on the model’s output. Without standardization, the features with larger scales may dominate the modeling process, leading to biased results.
4. Easing model convergence: Many machine learning algorithms, such as neural networks, rely on numerical optimization techniques to converge to an optimal solution. Non-standardized data with varying scales can make the convergence process slower or even prevent it. By standardizing the data, the algorithms can converge faster and achieve better performance.
5. Improving model interpretability: Standardized data makes it easier to interpret the model’s coefficients or weights. With all features on the same scale, it becomes simpler to identify which features have a stronger or weaker impact on the model’s predictions. This enhances the interpretability and understanding of the model’s inner workings.
6. Enhancing generalization: Models trained on standardized data tend to generalize better to unseen or future data. Standardization reduces the dependence on the specific scale or distribution of the training data, allowing the model to adapt and perform well on new data instances.
In summary, data standardization is important in machine learning to eliminate biases, reduce noise, improve comparability, ease model convergence, enhance interpretability, and enhance generalization. By ensuring that the input data is consistent and uniform, data standardization contributes to the overall accuracy and performance of machine learning models.
Next, we will explore the specific benefits of implementing data standardization in the modeling process.
Benefits of data standardization
Data standardization brings several benefits to the machine learning process. By transforming the input data into a consistent and uniform format, data standardization enhances the accuracy, robustness, and interpretability of the models. Let’s explore the specific benefits in more detail:
1. Improved accuracy: Standardized data ensures that all features or variables are on a similar scale, which helps prevent any single feature from dominating the modeling process. This balance allows the algorithm to make accurate comparisons and weigh the importance of different features appropriately, leading to more accurate predictions.
2. Enhanced model robustness: Data standardization reduces the impact of outliers and noise in the dataset. By scaling the data or removing extreme values, the models become more robust and less sensitive to irregularities in the data. This enhances the model’s ability to handle unexpected or noisy inputs, resulting in more reliable predictions.
3. Streamlined feature selection: Standardized data makes it easier to compare the importance or contribution of different features in the modeling process. This facilitates feature selection and helps identify the most relevant variables for the models. By eliminating irrelevant or redundant features, the models become simpler, more interpretable, and less prone to overfitting.
4. Better interpretability: Standardized data simplifies the interpretation of model coefficients or weights. When all features are on the same scale, it becomes easier to determine the relative impact of each feature on the model’s predictions. This enhances the understanding of the model’s behavior and improves its interpretability, which is crucial for applications where transparency is required.
5. Increased model convergence: Non-standardized data with varying scales can hinder the convergence of machine learning algorithms, particularly those that rely on optimization techniques. By standardizing the data, the algorithms can converge faster and more consistently towards an optimal solution. This leads to improved model performance and training efficiency.
6. Generalization to new data: Standardization reduces the dependence on the specific scale or distribution of the training data. Models trained on standardized data tend to generalize better to unseen or future data. This adaptability allows the models to perform well on real-world data instances, even if they have different scales or distributions than the training data.
In summary, data standardization brings benefits such as improved accuracy, enhanced model robustness, streamlined feature selection, better interpretability, increased model convergence, and improved generalization to new data. These benefits highlight the importance of implementing data standardization techniques in the machine learning pipeline.
Next, let’s explore the specific techniques used for data standardization and their differences from data normalization.
Techniques for data standardization
Data standardization involves the application of various techniques to transform the input data into a consistent and uniform format. Here are some commonly used techniques for data standardization:
1. Z-score standardization: This technique, also known as standard score standardization, transforms the data to have a mean of 0 and a standard deviation of 1. It involves subtracting the mean from each data point and then dividing by the standard deviation. This method is well-suited for numerical data and helps in comparing the relative values of different features.
2. Min-max scaling: Min-max scaling rescales the data to a specific range, typically between 0 and 1. It involves subtracting the minimum value and then dividing by the range (maximum value minus the minimum value). This technique preserves the original distribution of the data and is useful when the absolute values are not as important as the relative values.
3. Normalization: Normalization is a broader term that encompasses various techniques to transform data into a normalized range. It ensures that the data falls within a specific range, such as [0, 1] or [-1, 1]. Normalization can be achieved through techniques like min-max scaling, decimal scaling, or logarithmic scaling, depending on the characteristics of the data.
4. One-hot encoding: One-hot encoding is used for categorical data, where each category is represented by a binary variable. It creates additional columns for each unique category and assigns 1 or 0 as values to indicate the presence or absence of the category in each data point. One-hot encoding allows categorical variables to be used in mathematical models.
5. Ordinal encoding: Ordinal encoding assigns numerical values to categorical variables based on their order or importance. For example, if the categories represent education levels (e.g., “High School,” “Bachelor’s degree,” “Master’s degree”), they can be assigned values like 1, 2, and 3, respectively. This preserves the ordinal relationship between categories.
6. Text data preprocessing: Standardization techniques are also applicable to text data. Preprocessing steps like stemming, lemmatization, and removing stop words can be performed to normalize the text. Stemming reduces words to their base or root form, while lemmatization maps words to their dictionary form. Removing stop words eliminates common words that do not carry significant meaning.
It’s important to note that the choice of technique for data standardization depends on the characteristics of the data and the specific requirements of the problem at hand. Experimentation and analysis of the data distribution are crucial for selecting the most appropriate technique.
Next, we will discuss the key differences between data standardization and normalization, as they are often used interchangeably but have distinct meanings in the context of machine learning.
Standardization vs normalization
In the context of machine learning, the terms “standardization” and “normalization” are often used interchangeably, but they have distinct meanings and implications. Let’s explore the differences between standardization and normalization:
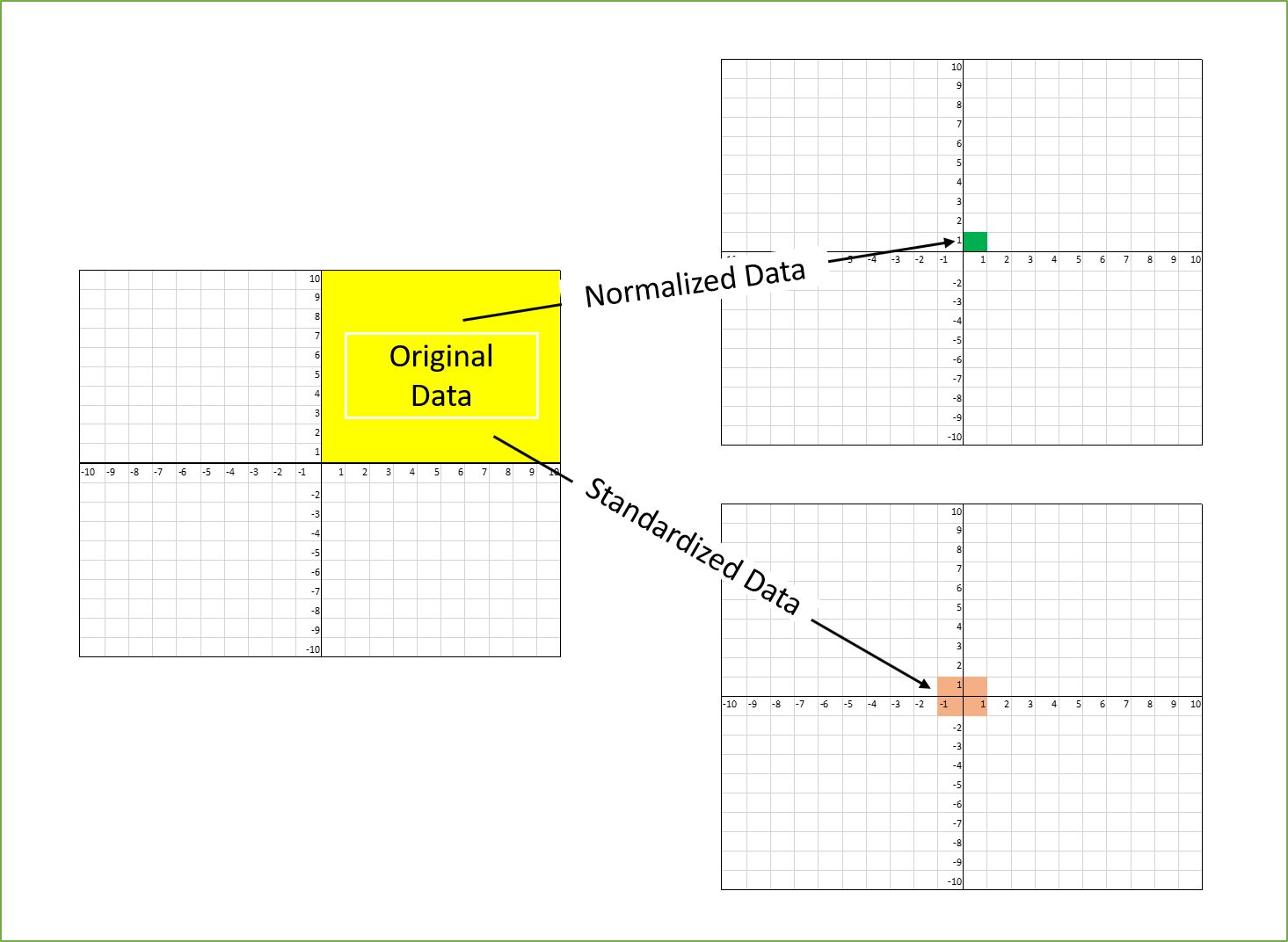
Standardization: Standardization is a technique to transform data into a consistent and uniform format. It aims to bring the features or variables onto a common scale, typically with a mean of 0 and a standard deviation of 1. The z-score standardization is a commonly used method for standardizing data. It subtracts the mean from each data point and then divides by the standard deviation. Standardization preserves the distribution shape of the data while making it easier to compare and analyze the relative values of different features.
Normalization: Normalization, on the other hand, is a broader concept that refers to the process of rescaling data to a specific range. The range can be [0, 1], [-1, 1], or any other desired interval. Normalization techniques, such as min-max scaling, decimal scaling, or logarithmic scaling, are used to transform the data to fit within the defined range. Normalization maintains the relationship between the original values and ensures that all data points fall within the chosen range.
The key difference between standardization and normalization lies in the goal and interpretation of the transformed data. Standardization focuses on making the data comparable by bringing it onto a common scale with a mean of 0 and a standard deviation of 1. This technique is particularly useful when the absolute values and distribution shape of the data are important for analysis and modeling.
On the other hand, normalization emphasizes rescaling the data to fit within a specific range, irrespective of the distribution shape. Normalization is often applied when the absolute values are not as critical as the relative values or when the scaled data is required for algorithms that are sensitive to the scale of the variables.
While standardization and normalization have different interpretations, both techniques aim to preprocess the data to improve the accuracy and efficiency of machine learning models. The choice between these techniques depends on the nature of the data, the requirements of the problem, and the specific algorithm being used.
In the next section, we will discuss some important considerations when applying data standardization techniques in the machine learning pipeline.
Considerations for data standardization
While data standardization is an essential step in the machine learning pipeline, it is important to consider several factors to ensure its effectiveness and avoid potential pitfalls. Here are some considerations to keep in mind when applying data standardization techniques:
1. Domain knowledge: Having a deep understanding of the data and the problem domain is crucial. Consider the characteristics, distributions, and scales of the variables involved. Certain features may require specific transformation techniques. For example, variables with extremely skewed distributions may benefit from non-linear transformations like logarithmic scaling.
2. Outliers: Outliers, which are extreme values in the dataset, can have a significant impact on standardization. It is important to identify and handle outliers appropriately. Consider using robust techniques that are less affected by outliers, such as percentiles or median-based approaches, if the data contains extreme values that may disrupt the standardization process.
3. Missing data: Data standardization can be affected by missing values, as calculating the mean or standard deviation may be challenging with incomplete data. Decide on the appropriate strategy to handle missing values, such as imputation techniques or removing incomplete data points. The choice should be based on the percentage of missing data and the impact it may have on the overall analysis.
4. Variable types: Different variable types (numeric, categorical, textual) require specific standardization techniques. Ensure that the chosen technique is appropriate for the variable type. For instance, one-hot encoding is mainly used for categorical variables, while z-score standardization is suitable for numeric variables. Mixing variable types without appropriate transformations may yield inaccurate and misleading results.
5. Data leakage: Data standardization should be performed on the training data alone and then applied consistently to the test or validation data. The calculated mean and standard deviation should not include any information from the test or validation sets, as this can lead to data leakage. Leakage can unfairly improve model performance during evaluation due to unintended information leakage from the test set.
6. Impact on interpretability: While standardization enhances the accuracy and performance of models, it can potentially affect the interpretability of the results. Consider the trade-off between improved model performance and the need for interpretability. In some cases, preserving the original scale or providing domain-specific interpretations may be more important than standardizing the data.
By taking these considerations into account, you can ensure that the data standardization process is appropriate and effective for your specific machine learning task. Properly standardized data improves the accuracy and reliability of models, leading to more robust and meaningful analysis and predictions.
In the next section, we will summarize the key points discussed in this article and emphasize the importance of data standardization in machine learning.
Conclusion
Data standardization is a crucial aspect of the machine learning pipeline. It involves transforming data into a consistent and uniform format, making it suitable for analysis and modeling. By standardizing the data, biases are eliminated, noise is reduced, comparability is improved, and model interpretability is enhanced.
The benefits of data standardization in machine learning are numerous. It improves the accuracy, robustness, and generalization of models. Standardization facilitates feature selection, model convergence, and the interpretation of model coefficients. It ensures that models are trained on fair, balanced, and normalized data, leading to more reliable predictions and insights.
When applying data standardization techniques, several considerations should be taken into account. Prior domain knowledge, handling outliers and missing data, appropriate transformations for different variable types, preventing data leakage, and balancing interpretability with improved model performance are all important factors to consider.
In summary, data standardization is an integral part of the machine learning process. It transforms data into a consistent and uniform format, ensuring that models are trained on normalized and comparable data. By implementing data standardization techniques effectively, machine learning models can achieve higher accuracy, robustness, and interpretability, leading to more reliable and meaningful results.
As the field of machine learning continues to advance, it is essential for practitioners to understand and apply proper data standardization techniques. By doing so, they can unlock the full potential of their models and leverage the power of high-quality, standardized data for successful predictions and insights.
Remember, data standardization sets the stage for accurate and reliable machine learning models. So, embrace this important step and unleash the true potential of your data in the exciting world of machine learning.