Introduction
Segmentation is a fundamental concept in the field of machine learning, specifically in tasks involving image recognition and analysis. It refers to the process of dividing or partitioning a given image into multiple meaningful and distinct regions or segments. Each segment represents a specific object or entity present in the image, such as a person, a car, or a background element. This segmentation technique plays a crucial role in extracting relevant information from images and enables machines to understand and interpret visual data more accurately.
In recent years, the advancements in machine learning and computer vision have led to significant breakthroughs in segmentation algorithms, enabling machines to achieve state-of-the-art results in tasks such as object detection, image segmentation, and even medical imaging. Segmentation has become an indispensable tool for various applications, including autonomous driving, surveillance systems, medical diagnosis, and multimedia content analysis.
One of the main reasons segmentation is essential in machine learning is its ability to enable more precise object recognition by dividing an image into smaller, meaningful parts. This, in turn, helps machines to better discern between different objects within an image and accurately classify them. For example, in autonomous driving, segmenting objects like pedestrians, vehicles, and traffic signs provides crucial information for decision-making and navigation.
Furthermore, segmentation has proven to be invaluable in medical imaging, where it plays a vital role in identifying and localizing tumors, anatomical structures, or pathological regions. By segmenting these areas, healthcare professionals can gain insights for diagnosis and treatment planning.
There are various types of segmentation techniques used in machine learning, including supervised, unsupervised, and semi-supervised approaches. Each technique has its own advantages and use cases, depending on the availability of labeled data and the complexity of the segmentation task. The choice of the segmentation method depends on the specific application, desired accuracy, and available resources.
In the following sections, we will delve deeper into the different types of segmentation techniques, their applications, challenges in segmentation, and the importance they hold in the field of machine learning.
Definition of Segmentation
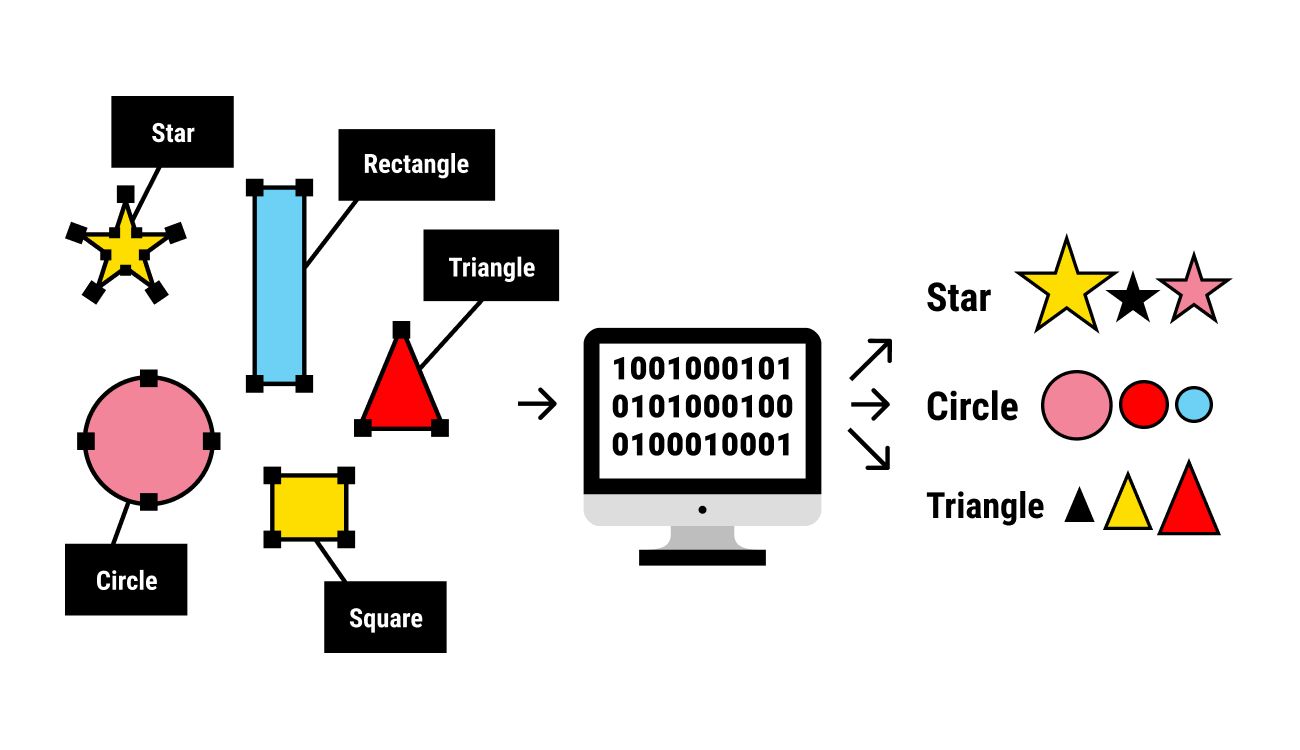
Segmentation, in the context of machine learning, refers to the process of dividing or partitioning a given image into multiple distinct and meaningful regions or segments. It aims to separate different objects or entities present in the image based on their characteristics, such as color, texture, shape, or intensity. The goal of segmentation is to extract relevant information and identify distinct regions within an image that can be further analyzed or classified.
The process of segmentation involves assigning a unique label or identifier to each pixel or region in the image. These labels indicate the membership or association of that pixel or region with a specific object or background in the image. By segmenting an image, we can isolate and extract individual objects or regions, which enables more accurate analysis, interpretation, and manipulation of visual data.
Segmentation can be performed at different levels of granularity, depending on the specific task and requirements. For instance, in a simple segmentation task, the goal might be to separate an object of interest from the rest of the image background. In more complex scenarios, such as semantic segmentation, the objective is to assign a specific label to each pixel, providing a detailed understanding of the object boundaries and their semantic meaning.
There are several approaches and algorithms employed in segmentation, ranging from traditional methods to more recent deep learning-based techniques. Traditional segmentation algorithms include thresholding, edge detection, region growing, and watershed transformation, which rely on predefined rules and heuristics to partition an image. On the other hand, deep learning-based techniques leverage artificial neural networks to automatically learn and infer segmentation patterns from a large amount of labeled training data.
Segmentation is a crucial step in many computer vision tasks, such as object recognition, scene understanding, image annotation, and image editing. By accurately segmenting an image, machines can better analyze and interpret visual data, leading to improved performance in various applications.
Next, let’s explore the importance of segmentation in machine learning and its significance in solving complex recognition and analysis problems.
Importance of Segmentation in Machine Learning
Segmentation plays a crucial role in machine learning, especially in tasks involving image recognition and analysis. Here are some key reasons why segmentation is important in this field:
1. Precise Object Recognition: One of the main advantages of segmentation is its ability to enable more accurate and precise object recognition. By dividing an image into smaller, meaningful segments, machines can better discern between different objects and accurately classify them. This is particularly beneficial in scenarios where objects overlap or have complex boundaries.
2. Improved Understanding of Visual Data: Segmenting an image helps machines gain a deeper understanding of the visual data. By isolating individual objects or regions, machines can analyze and interpret them more effectively. This leads to better feature extraction, allowing the model to capture more specific and relevant characteristics of the objects, thereby improving overall performance.
3. Extraction of Relevant Information: Segmentation techniques enable the extraction of specific and relevant information from images. By identifying and separating different objects or regions, machines can focus on the areas of interest and extract meaningful features. This information can then be used for further analysis, decision-making, and understanding complex visual scenes.
4. Contextual Understanding: Segmenting an image provides contextual information about the relationships between objects and their surroundings. By analyzing the spatial distribution and interactions between different segments, machines can better comprehend the scene and infer higher-level semantic meaning. This contextual understanding is essential in tasks such as scene understanding, autonomous navigation, and object tracking.
5. Localization and Boundary Detection: Segmentation helps in localizing objects within an image and accurately detecting their boundaries. This localization is vital in various applications, such as medical imaging, where segmenting and localizing tumors or pathology regions can aid in diagnosis and treatment planning.
6. Enhanced Image Editing and Manipulation: Segmenting an image into different regions allows for more targeted and precise image editing and manipulation. By isolating specific objects or regions, machines can apply specific effects, enhancements, or modifications to those areas without affecting the rest of the image. This is particularly useful in areas like graphic design, image editing software, and augmented reality applications.
Overall, segmentation plays a crucial role in enhancing machine learning algorithms’ performance in various image recognition and analysis tasks. It enables more accurate object recognition, improves understanding and extraction of relevant information, and provides contextual understanding of visual scenes. With the continuous advancements in segmentation techniques, the capabilities of machine learning models are expanding, leading to better performance in numerous applications.
Different Types of Segmentation Techniques
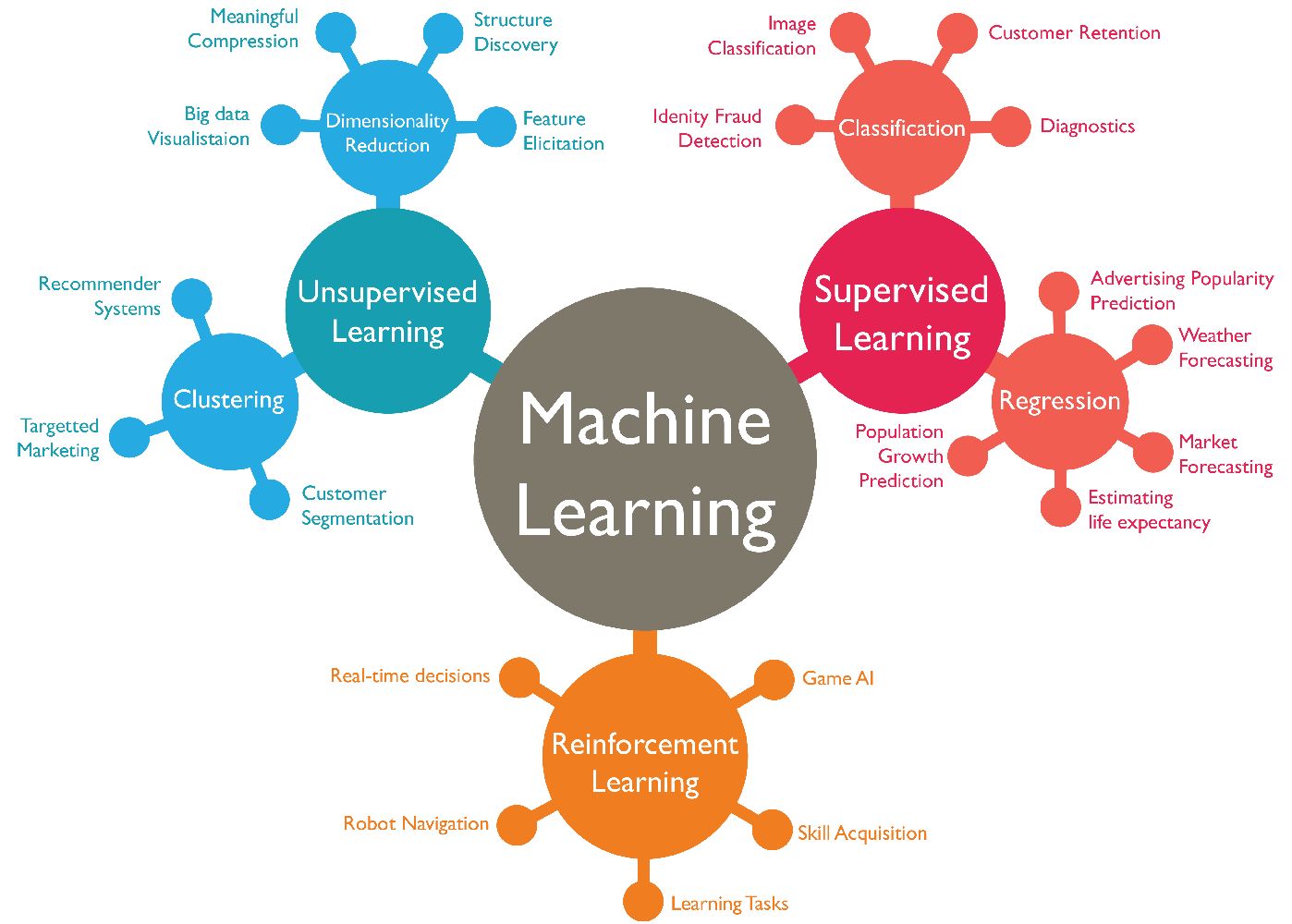
In the field of machine learning, various segmentation techniques are employed to extract meaningful and distinct regions from images. These techniques can be broadly categorized into three main types: supervised segmentation, unsupervised segmentation, and semi-supervised segmentation. Each type has its own characteristics, advantages, and use cases.
1. Supervised Segmentation: Supervised segmentation involves training a model using labeled data, where each image is manually annotated with pixel-level segmentation labels. This labeled data serves as a ground truth, enabling the model to learn the correlation between image features and corresponding segmentation labels. Supervised segmentation algorithms utilize machine learning techniques such as convolutional neural networks (CNNs) to learn and generalize from the labeled training data. The trained model can then segment new, unseen images based on the learned patterns. Supervised segmentation is effective when there is a substantial amount of high-quality labeled data available.
2. Unsupervised Segmentation: Unlike supervised segmentation, unsupervised segmentation does not require any prior knowledge or labeled data for training. Instead, it relies on inherent properties and patterns in the image data to identify distinct regions. Unsupervised segmentation algorithms use clustering techniques, such as k-means clustering or mean-shift clustering, to group pixels with similar characteristics together. These algorithms aim to find natural boundaries or regions within the image based on pixel similarity. Unsupervised segmentation is useful when there is limited or no labeled data available and when the goal is to explore and discover unknown patterns or structures in the image.
3. Semi-supervised Segmentation: Semi-supervised segmentation combines both supervised and unsupervised approaches. It leverages a small amount of labeled data and a larger amount of unlabeled data. In this technique, the labeled data help guide the unsupervised segmentation process, allowing the model to learn from both the labeled and unlabeled data. Semi-supervised segmentation algorithms use techniques like self-training or co-training to iteratively refine the segmentation performance. This approach is useful when there is a limited amount of labeled data available, but leveraging unlabeled data can still improve segmentation accuracy and generalization.
Additionally, in recent years, deep learning techniques, particularly convolutional neural networks (CNNs), have revolutionized image segmentation. Deep learning-based segmentation models, such as U-Net or Mask R-CNN, can learn complex representations of images and generate pixel-level segmentations with remarkable accuracy.
Each segmentation technique has its own strengths and weaknesses, and the choice of technique depends on factors such as the availability of labeled data, the complexity of the segmentation task, and the desired level of accuracy. Understanding the different types of segmentation techniques helps in selecting the most appropriate method for a particular application and achieving optimal results.
Supervised Segmentation
Supervised segmentation is a type of segmentation technique that relies on labeled data for training a model. In this approach, each image in the training dataset is annotated with pixel-level segmentation labels, indicating the class or region to which each pixel belongs. The labeled data serves as ground truth, enabling the model to learn the correlation between image features and corresponding segmentation labels.
To perform supervised segmentation, machine learning techniques such as convolutional neural networks (CNNs) are commonly used. CNNs are well-suited for image segmentation tasks as they can capture local spatial dependencies and learn hierarchical representations from the input images.
The process of supervised segmentation typically involves the following steps:
1. Data Preparation: The training dataset is prepared by gathering a set of images, along with their corresponding pixel-level segmentation labels. These labels can be obtained through manual annotation or using specialized annotation tools. It is crucial to ensure the accuracy and quality of the labeled data as it directly affects the model’s performance and generalization capability.
2. Model Training: The labeled training data is used to train the segmentation model. CNN architectures, such as U-Net or FCN (Fully Convolutional Network), are commonly employed for supervised segmentation. The model learns to map the input image to its corresponding segmentation map by optimizing the network parameters using techniques like backpropagation and gradient descent. The training process involves iteratively adjusting the model’s parameters to minimize the difference between the predicted segmentation and the ground truth labels.
3. Testing and Inference: Once the model is trained, it can be used to perform segmentation on new, unseen images. The trained model takes an input image and generates a pixel-level segmentation map, where each pixel is assigned a label representing the class or region it belongs to. This segmentation map can be further analyzed, processed, or used for downstream tasks such as object detection or semantic understanding.
Supervised segmentation offers several advantages. Firstly, it allows for precise and accurate segmentation by leveraging the knowledge provided by the labeled data. The model can learn specific patterns and feature representations of different objects or regions, leading to more reliable segmentation results. Secondly, supervised segmentation is well-suited for tasks where a clear definition of classes or regions is available. It enables the identification of specific categories within an image, facilitating subsequent analysis and decision-making processes.
However, supervised segmentation also has limitations. It relies heavily on the availability of high-quality labeled data, which can be time-consuming and expensive to obtain. Additionally, supervised segmentation may struggle when faced with unseen or outlier data that deviates from the training distribution. Overfitting is also a common challenge, where the model may perform well on the training set but fail to generalize to unseen data.
In summary, supervised segmentation is a powerful technique that leverages labeled data to achieve accurate and precise image segmentation. By training a model using pixel-level annotations, supervised segmentation enables machines to understand and interpret visual data more effectively, leading to improved performance across various applications.
Unsupervised Segmentation
Unsupervised segmentation is a segmentation technique that does not rely on pre-labeled data for training. Instead, it aims to discover structures and patterns in the image data without any prior knowledge of the object classes or regions. Unsupervised segmentation algorithms use clustering techniques to group pixels with similar characteristics together, aiming to find natural boundaries or regions within the image based on pixel similarity.
In unsupervised segmentation, the process can be summarized in the following steps:
1. Feature Extraction: The first step in unsupervised segmentation is extracting meaningful features from the input image. These features capture various aspects of the image, such as color, texture, or intensity. Commonly used techniques for feature extraction include histogram-based methods, edge detection, or texture analysis.
2. Clustering: Once the features are extracted, clustering algorithms are used to group pixels with similar characteristics together. The goal is to identify distinct regions or clusters based on the similarities in their feature representations. Clustering algorithms like k-means, mean-shift, or spectral clustering are frequently employed in unsupervised segmentation.
3. Region Merging or Splitting: After clustering, additional steps might be performed to refine and improve the segmentation results. These steps include region merging or splitting, where neighboring regions are combined or divided based on certain criteria. This helps to eliminate noise, fill in gaps, and create more coherent and meaningful segmentations.
Unsupervised segmentation offers several advantages and use cases. Firstly, it is particularly useful in scenarios where there is a lack of labeled data or where the number of object classes or regions is unknown. Unsupervised segmentation allows for exploration and discovery of patterns or structures in the image data without any prior assumptions.
Secondly, unsupervised segmentation supports unsupervised learning, which is important in scenarios where the relationship between the features and the segmentation labels is not well-defined or understood. It can be used to gain insights and understanding from unlabeled data, helping to refine or discover new classes or categories within the image.
However, unsupervised segmentation also has some limitations. It relies heavily on the quality and appropriateness of the chosen clustering algorithm and the selected features. If the features do not capture the relevant information, or if the clustering algorithm fails to separate the desired regions properly, the segmentation results may not be accurate or meaningful.
Additionally, unsupervised segmentation might not be able to handle complex or ambiguous scenarios where objects overlap or have similar characteristics. It may struggle to distinguish between subtle differences or handle scenarios where knowledge of individual classes or semantic meaning is necessary.
In summary, unsupervised segmentation is a powerful technique that can uncover meaningful structures and relationships within image data without the need for labeled training data. By leveraging clustering algorithms and feature extraction, unsupervised segmentation provides valuable insights and understanding in scenarios where labeled data is scarce or unknown. It is especially useful in exploratory analysis, data mining, or when discovering hidden patterns within the image data.
Semi-supervised Segmentation
Semi-supervised segmentation is a segmentation technique that combines both supervised and unsupervised approaches. It leverages a small amount of labeled data along with a larger amount of unlabeled data to perform image segmentation. This hybrid approach aims to benefit from the advantages of both supervised and unsupervised methods, allowing the model to learn from the labeled data while also leveraging the unlabeled data to improve segmentation accuracy and generalization.
In semi-supervised segmentation, the process can be described as follows:
1. Labeled Data Preparation: The first step in semi-supervised segmentation involves gathering a small amount of labeled data where each image is annotated with pixel-level segmentation labels. This labeled data serves as the initial training set, providing a foundation for the supervised learning aspect of the approach.
2. Unlabeled Data Preparation: Alongside the labeled data, a larger set of unlabeled data is collected. This unlabeled data does not have any pixel-level segmentation labels and is used to leverage the unsupervised learning aspect of the approach. It provides additional information to guide the segmentation process.
3. Model Training: Using the labeled data, a segmentation model is trained using supervised learning techniques. The model learns to map the input image to its corresponding segmentation map, using the labeled data as ground truth. This training step focuses on capturing the specific patterns and relationships between the features and segmentation labels found in the labeled data.
4. Semi-supervised Learning: After the initial model training using the labeled data, the model is further fine-tuned or trained using the unlabeled data. This step involves utilizing unsupervised learning techniques to leverage the information present in the unlabeled data. The model aims to generalize and extract additional knowledge from the unlabeled data to improve the segmentation performance.
5. Iterative Refinement: The semi-supervised segmentation approach often involves an iterative process of refining and improving the segmentation performance. This process alternates between training the model using the labeled data, fine-tuning using the unlabeled data, and updating the model parameters. This iterative approach helps to enhance the segmentation accuracy and generalization by gradually incorporating the information present in the unlabeled data.
Semi-supervised segmentation offers several benefits. Firstly, it combines the strengths of both supervised and unsupervised approaches. It makes use of the labeled data to provide initial guidance and ensures accuracy in regions where labels are available. Simultaneously, it leverages the unlabeled data to enable the model to learn from a broader range of information and improve its ability to generalize and capture complex segmentation patterns.
Secondly, semi-supervised segmentation is especially useful when obtaining labeled data is expensive, time-consuming, or challenging. It allows for more efficient use of available resources by utilizing both labeled and unlabeled data. This approach can be particularly valuable in scenarios where manual annotation of large datasets is not feasible.
However, semi-supervised segmentation also faces challenges. Balancing the contributions of labeled and unlabeled data requires careful consideration, as the quality and representativeness of the labeled and unlabeled data may vary. Additionally, determining the appropriate amount of labeled data and the optimal training schedule for iterative refinement can be complex.
In summary, semi-supervised segmentation is a hybrid approach that combines supervised and unsupervised techniques. It leverages a small amount of labeled data along with unlabeled data to improve segmentation accuracy and generalization. By striking a balance between labeled and unlabeled data, semi-supervised segmentation offers efficient utilization of resources and improved segmentation performance in scenarios where obtaining fully labeled datasets is challenging.
Applications of Segmentation in Machine Learning
Segmentation techniques play a crucial role in various fields and applications within machine learning. By dividing images into meaningful and distinct regions, segmentation enables machines to understand and interpret visual data more accurately. Here are some key applications where segmentation is commonly used:
1. Object Detection and Recognition: Segmentation is vital in object detection and recognition tasks, where the goal is to locate and identify specific objects within an image. By segmenting the image into regions corresponding to different objects, machines can accurately detect and classify these objects. Segmentation helps to distinguish and understand the boundaries between objects, leading to improved object recognition accuracy.
2. Medical Imaging: Segmentation is of utmost importance in medical imaging applications. It assists in tasks such as tumor detection, organ segmentation, and pathological region identification. By segmenting medical images, healthcare professionals can analyze and interpret specific regions of interest, aiding in diagnosis, treatment planning, and monitoring disease progression.
3. Autonomous Driving: In autonomous driving systems, segmentation plays a critical role in scene understanding and environment perception. By segmenting objects such as pedestrians, vehicles, traffic signs, and road boundaries, autonomous vehicles can make informed decisions and navigate safely. Segmentation helps distinguish between different objects and assists in recognizing and predicting their behavior on the road.
4. Image Annotation and Understanding: Segmenting images is essential in annotation tasks, where objects or regions of interest need to be labeled to create training datasets for various machine learning tasks. Segmentation helps in precisely delineating the boundaries of objects and enables accurate annotation. Furthermore, segmenting images aids in understanding the contents of visual data, enabling machines to retrieve and comprehend specific objects or regions within images.
5. Multimedia Content Analysis: Segmentation is valuable in multimedia content analysis, which involves understanding and analyzing large collections of images or videos. By segmenting images or video frames, the content can be classified, organized, and searched more efficiently. Segmentation facilitates content-based retrieval and enables the extraction of meaningful features from visual data.
6. Image Editing and Augmented Reality: Segmentation techniques are used extensively in image editing software and augmented reality applications. By segmenting an image into different regions, specific enhancements or modifications can be applied to individual objects or regions without affecting the entire image. This enables advanced editing capabilities, such as background removal, object replacement, or applying realistic virtual objects in augmented reality environments.
These are just a few examples of the vast range of applications where segmentation is vital in machine learning. The ability to segment images and extract meaningful information from them is crucial in numerous fields, leading to improved performance, accuracy, and understanding in various tasks and domains.
Challenges in Segmentation
Despite its significance in machine learning and computer vision, segmentation poses several challenges that researchers and practitioners must overcome. These challenges arise from the complex nature of image data and the inherent difficulties in accurately delineating objects or regions within them. Here are some key challenges in segmentation:
1. Ambiguity and Overlapping: Objects or regions in images often exhibit ambiguity and overlap, making it challenging to precisely delineate their boundaries. The presence of occlusions, similar textures, or closely located objects can cause segmentation algorithms to struggle, leading to inaccurate or imprecise segmentations. Handling these cases requires advanced algorithms that can account for ambiguous scenarios and incorporate contextual information.
2. Scalability and Efficiency: Segmentation algorithms need to perform effectively and efficiently on large datasets or in real-time applications. As image sizes and complexity increase, scalability becomes a significant challenge. Algorithms must be designed to handle such scalability requirements and optimize computational resources while maintaining segmentation accuracy.
3. Variability in Image Appearance: Images can exhibit significant variations in lighting conditions, viewpoint, scale, or background clutter, making segmentation more challenging. Adapting to these variations and ensuring robust segmentations across different image conditions pose a substantial challenge. Techniques such as data augmentation, robust feature extraction, and model generalization play crucial roles in addressing this challenge.
4. Lack of Sufficient Labeled Data: Supervised segmentation techniques heavily rely on labeled data for training. However, obtaining large-scale annotated datasets can be time-consuming, expensive, and in some cases, impractical. The limited availability of labeled data can hinder the development and performance of supervised segmentation algorithms. Techniques such as transfer learning or semi-supervised learning are employed to overcome the scarcity of labeled data and leverage the available resources effectively.
5. Domain-Specific Challenges: Different domains may introduce additional challenges in segmentation. For example, in medical imaging, segmenting complex anatomical structures or tumors can be difficult due to shape and intensity variability. In aerial imagery or satellite images, segmenting objects on varying terrains and with different scales presents unique challenges. Addressing these domain-specific challenges requires tailoring segmentation algorithms to the particular characteristics and requirements of the application domain.
6. Evaluation and Metrics: Evaluating the performance of segmentation algorithms accurately is a challenging task. Choosing appropriate evaluation metrics that capture the quality of segmentations, dealing with ground truth labeling inconsistencies, or comparing results across different segmentation algorithms pose difficulties. The development of standardized evaluation protocols and metrics is essential to ensure consistent evaluation and benchmarking of segmentation algorithms.
These challenges reflect the complex and dynamic nature of segmentation tasks. Researchers and practitioners continuously strive to develop innovative algorithms and techniques that can address these challenges and improve the accuracy and robustness of segmentation algorithms across different applications and scenarios.
Conclusion
Segmentation is a fundamental concept in machine learning that plays a significant role in various image recognition and analysis tasks. By dividing images into meaningful regions or segments, segmentation algorithms enable machines to understand visual data more accurately and extract relevant information for further analysis or decision-making.
In this article, we explored the different types of segmentation techniques, including supervised, unsupervised, and semi-supervised segmentation. Supervised segmentation relies on labeled data to train models and achieve precise object recognition. Unsupervised segmentation discovers structures and patterns in the image data without prior knowledge of object classes or regions. Semi-supervised segmentation combines the strengths of both supervised and unsupervised approaches and leverages labeled and unlabeled data to improve segmentation accuracy and generalization.
We also examined various applications where segmentation is widely used, such as object detection, medical imaging, autonomous driving, image annotation, multimedia content analysis, and image editing. Segmentation plays a vital role in enhancing these applications’ performance, enabling accurate object recognition, precise localization, and advanced image manipulation capabilities.
However, segmentation also presents unique challenges, including ambiguity and overlapping objects, scalability and efficiency requirements, variability in image appearance, scarcity of labeled data, domain-specific challenges, and evaluation complexities. Researchers and practitioners continue to address these challenges through innovative algorithms, data augmentation techniques, and the development of standardized evaluation protocols.
In conclusion, segmentation is a crucial component of machine learning, enabling machines to extract meaningful information from visual data and improving performance in various applications. Advances in segmentation techniques continue to push the boundaries of object recognition, scene understanding, medical diagnosis, and many other fields, paving the way for more accurate and efficient machine learning algorithms in the future.