Introduction
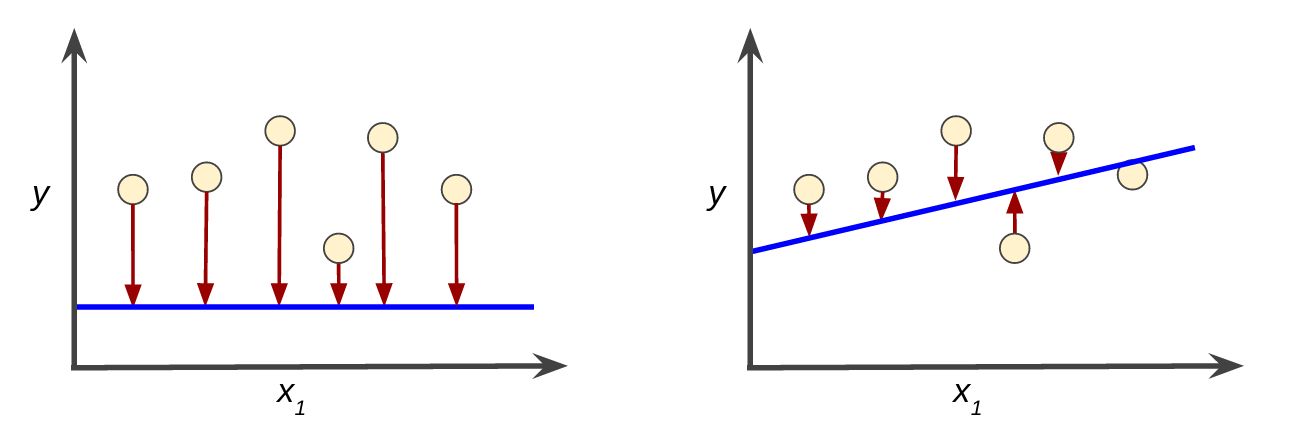
Welcome to the world of machine learning, where algorithms and models are trained to make predictions and learn from data. In this fascinating field, one of the key concepts that plays a crucial role in model training is loss. Loss, also known as cost or error, quantifies the dissimilarity between predicted and actual values. By minimizing the loss, machine learning models can become more accurate and make better predictions.
Loss functions are an essential component of machine learning algorithms as they define the objective to be minimized during training. They act as a guidance system, steering the model towards finding the best possible set of parameters that minimize the difference between predictions and ground truth.
In this article, we will explore the concept of loss in machine learning in more detail. We will discuss its definition, the types of loss functions used, and their impact on model training. Additionally, we will delve into popular loss functions and provide insights into selecting the most appropriate loss function for different types of machine learning problems.
Understanding loss functions is critical for machine learning practitioners, as it directly affects the performance and accuracy of models. By gaining a deeper understanding of loss, you will be better equipped to train models effectively and achieve optimal results in your machine learning projects.
Definition of Loss in Machine Learning
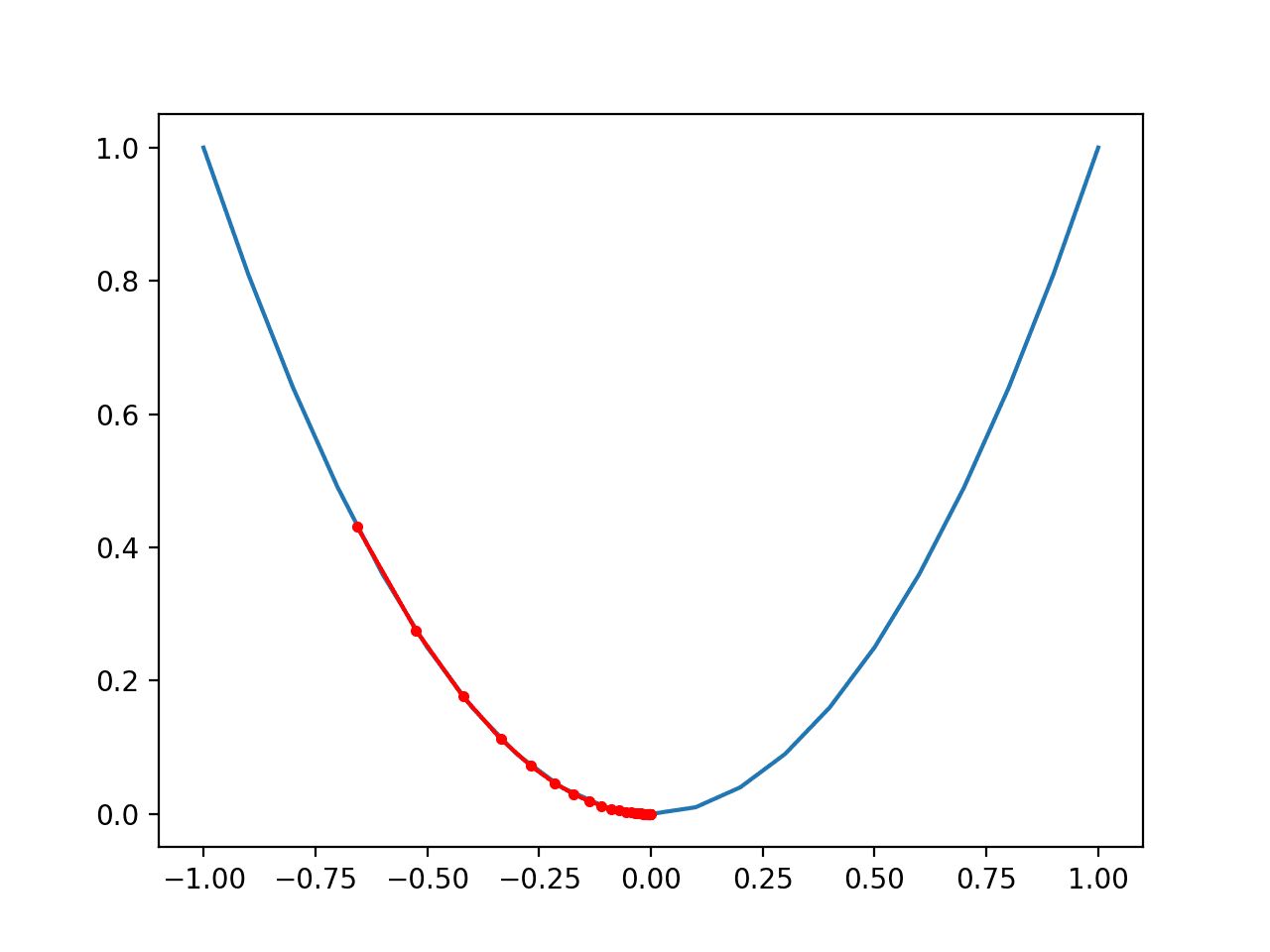
In the context of machine learning, loss refers to a metric that quantifies the discrepancy between the predicted values of a model and the true values of the target variable. It is a measure of how well the model is performing in terms of its ability to make accurate predictions.
The loss function serves as a guide for the learning algorithm, providing feedback on the performance of the model and helping it to adjust its parameters in order to minimize the error. The ultimate goal is to find the set of parameters that results in the lowest possible loss value.
The concept of loss is closely related to the notion of error. Loss can be seen as a mathematical representation of the error made by the model in its predictions. It measures the extent to which the model’s output deviates from the actual values. By minimizing the loss, the model aims to reduce the error and improve its predictive capabilities.
The choice of the specific loss function depends on the nature of the problem being tackled. Different machine learning tasks, such as regression, classification, or sequence generation, require different types of loss functions. These functions are designed to capture the specific characteristics and objectives of each task.
Loss functions can be formulated in various ways. They can be simple mathematical expressions, such as the mean squared error (MSE), or more complex functions that involve a combination of mathematical operations and logical rules. The selection of a suitable loss function is crucial, as it directly affects the behavior of the learning algorithm and the performance of the model.
Overall, the definition of loss in machine learning revolves around the idea of quantifying the error or discrepancy between predicted and actual values. It plays a fundamental role in guiding the learning process and improving the performance of machine learning models.
Types of Loss Functions
Loss functions come in various forms, each tailored to address different types of machine learning problems. Although there are numerous loss functions available, they can generally be classified into several broad categories.
1. Regression Loss Functions: These loss functions are primarily used in regression tasks, where the goal is to predict a continuous value. Popular regression loss functions include Mean Squared Error (MSE), Mean Absolute Error (MAE), and Huber Loss. The MSE measures the average squared difference between the predicted and actual values, while MAE computes the absolute difference. Huber Loss combines the best aspects of MSE and MAE, offering robustness to outliers.
2. Classification Loss Functions: Classification tasks involve assigning input data to specific classes or categories. Binary classification loss functions, such as Binary Cross-Entropy and Hinge Loss, are commonly used when there are only two classes. For multi-class classification, Cross-Entropy and Softmax loss functions are applied to estimate the probability distribution over the classes.
3. Ranking Loss Functions: In certain machine learning applications, the goal is to learn a ranking order among a set of items or instances. Ranking loss functions, such as the Pairwise and Listwise loss, are designed to optimize the order of the predicted results based on a scoring system.
4. Reconstruction Loss Functions: Reconstruction loss functions are used in tasks such as autoencoders and generative models, where the objective is to reconstruct the input data from an encoded representation. Common reconstruction loss functions include Mean Squared Error (MSE) and Binary Cross-Entropy (BCE).
5. Custom Loss Functions: In some cases, predefined loss functions may not be suitable for a specific task. In such situations, custom loss functions can be designed to address the specific requirements of the problem at hand. These loss functions are crafted based on domain knowledge and problem-specific constraints.
The selection of the appropriate loss function depends on the nature of the problem, data distribution, and desired model behavior. It’s important to understand the characteristics of different loss functions and their impact on the learning process and model performance.
By employing the right loss function, machine learning models can be trained more effectively, leading to improved predictions and higher overall performance.
Popular Loss Functions
When it comes to machine learning, certain loss functions have gained popularity due to their effectiveness in various tasks. Let’s explore some of the most commonly used loss functions:
1. Mean Squared Error (MSE): MSE is a regression loss function that measures the average squared difference between the predicted and true values. It penalizes larger errors more heavily, making it sensitive to outliers. MSE is widely used due to its simplicity and differentiability, making it suitable for many regression tasks.
2. Mean Absolute Error (MAE): MAE is another regression loss function that measures the average absolute difference between the predicted and true values. Unlike MSE, MAE is not as sensitive to outliers and provides a more robust measure of error. MAE is commonly used when outliers are present or when equal weight is given to all error values.
3. Binary Cross-Entropy (BCE): BCE is a classification loss function used in binary classification tasks. It measures the dissimilarity between the predicted probabilities and the true binary labels. BCE is effective when dealing with imbalanced datasets and is often used in tasks such as spam detection or sentiment analysis.
4. Categorical Cross-Entropy (CCE): CCE is a classification loss function used in multi-class classification tasks. It calculates the cross-entropy loss between the predicted class probabilities and the true one-hot encoded labels. CCE is popular in tasks such as image classification or natural language processing, where multiple classes need to be assigned.
5. Hinge Loss: Hinge loss is commonly used in linear SVM (Support Vector Machines) and binary classification tasks. It measures the margin between the predicted scores and the true labels. Hinge loss encourages correct classification and penalizes predictions that are too confident or on the wrong side of the margin.
These are just a few examples of popular loss functions in machine learning. It’s important to note that the choice of a specific loss function depends on the problem domain, the nature of the task, and the underlying data. Experimenting with different loss functions can help fine-tune the model’s performance and achieve better results.
Understanding the characteristics and properties of these widely used loss functions is crucial for a data scientist or machine learning practitioner aiming to build efficient and accurate models.
How Loss Functions Affect Model Training
Loss functions play a vital role in model training, influencing the learning process and the final performance of the model. Let’s delve into how loss functions affect the training of machine learning models:
1. Optimization: Loss functions serve as the objective to be optimized during training. The learning algorithm aims to find the set of model parameters that minimizes the loss function. By minimizing the loss, the model learns to make more accurate predictions.
2. Model Behavior: Different loss functions yield different model behaviors. For example, using Mean Squared Error as a loss function in regression tasks encourages the model to produce continuous predictions. On the other hand, using Binary Cross-Entropy as a loss function in binary classification tasks encourages the model to output probabilities that favor one class over the other.
3. Sensitivity to Errors: Loss functions can have varying levels of sensitivity to errors. Some loss functions, like Mean Squared Error, penalize larger errors more heavily. This can make the model more sensitive to outliers in the data. Other loss functions, like Mean Absolute Error, treat all errors equally, providing a more robust measure of performance.
4. Training Speed and Convergence: The choice of loss function can impact the speed and convergence of the training process. Some loss functions have smooth and convex surfaces, making it easier for optimization algorithms to find the global minimum. Other loss functions may have non-convex surfaces, leading to slower convergence or the possibility of getting stuck in local minima.
5. Special Considerations: Certain loss functions have special considerations depending on the problem at hand. For instance, in imbalanced classification tasks, using a loss function like Binary Cross-Entropy can help address the issue of class imbalance by assigning different weights to the positive and negative classes.
It is important to carefully select a loss function that aligns with the problem’s objective, data characteristics, and desired model behavior. Understanding how different loss functions affect the training process helps machine learning practitioners make informed decisions and achieve optimal model performance.
Selecting the Right Loss Function
Choosing the appropriate loss function is a critical step in the model development process. The right choice can greatly impact the model’s performance and effectiveness. Here are some considerations to keep in mind when selecting a loss function:
1. Understand the Task: Gain a clear understanding of the specific task at hand. Is it a regression, classification, ranking, or reconstruction problem? Different tasks require different types of loss functions that are specifically designed to address their unique characteristics and objectives.
2. Data Distribution: Examine the distribution of your data. Are there class imbalances, outliers, or noisy data points? Certain loss functions are more suitable for handling these scenarios. For example, Binary Cross-Entropy loss can mitigate the impact of class imbalance, while robust loss functions like Huber Loss can handle outliers effectively.
3. Model Behavior: Consider the desired behavior of your model. Do you want it to output probabilities, continuous values, or rankings? Different loss functions encourage different behaviors, so choose one that aligns with your intended outcomes.
4. Performance Metrics: Evaluate the effectiveness of the loss function based on the performance metrics that are important for your task. Some loss functions may be more aligned with specific evaluation metrics such as accuracy, precision, recall, or F1 score. Make sure the chosen loss function aligns with the metrics that matter most to you.
5. Experimentation: It is often helpful to experiment with different loss functions to determine which one performs best for your problem. Consider trying out multiple loss functions and comparing their performance on a validation set. This iterative process can provide insights into the strengths and weaknesses of different loss functions.
6. Customization: In some cases, predefined loss functions may not fully capture the requirements of your problem. In such situations, custom loss functions can be created to address specific constraints or objectives. Customization allows for fine-tuning the loss function to better suit your unique problem domain.
By carefully considering these factors and experimenting with different loss functions, you can select the most appropriate one for your machine learning task. Remember that the right choice of loss function can significantly impact the accuracy, robustness, and overall performance of your trained models.
Conclusion
Loss functions are fundamental components of machine learning algorithms that play a critical role in model training and optimization. They quantify the dissimilarity between predicted and true values, guiding the learning process to improve the accuracy and performance of the models.
In this article, we explored the definition of loss in machine learning and discussed different types of loss functions commonly used in various tasks, such as regression, classification, ranking, and reconstruction. We also highlighted some popular loss functions, including Mean Squared Error (MSE), Mean Absolute Error (MAE), Binary Cross-Entropy (BCE), and Hinge Loss.
We learned that the choice of the right loss function significantly impacts the behavior, sensitivity to errors, and training speed of machine learning models. Understanding the characteristics and implications of different loss functions helps in selecting the most suitable one for a particular task, considering factors such as the nature of the problem, data distribution, and desired model behavior.
It is important to note that the choice of loss function is not fixed and may require iterations and experimentation to find the best fit. Additionally, in some cases, custom loss functions may be necessary to address specific requirements or constraints in the problem at hand.
Overall, loss functions are crucial tools in machine learning, enabling models to learn from data and make accurate predictions. By gaining a deep understanding of the different types of loss functions and their impact on training, machine learning practitioners can create more effective and efficient models and drive advancements in the field.