Introduction
Machine learning is a rapidly evolving field that encompasses various techniques to enable computers to learn from data and make intelligent decisions. One key aspect of machine learning is the representation of data, as the quality and format of data can greatly influence the performance of machine learning models.
Embedding is a powerful technique used in machine learning to represent categorical or discrete data in a continuous, numerical form. It aims to capture the underlying relationships and semantic meanings of the data, facilitating various downstream tasks such as classification, recommendation systems, and natural language processing.
By transforming categorical variables into dense vector representations, embedding allows machine learning models to effectively leverage the information contained within the data. This not only improves the efficiency of learning algorithms but also enables the models to generalize better when inferring from unseen data.
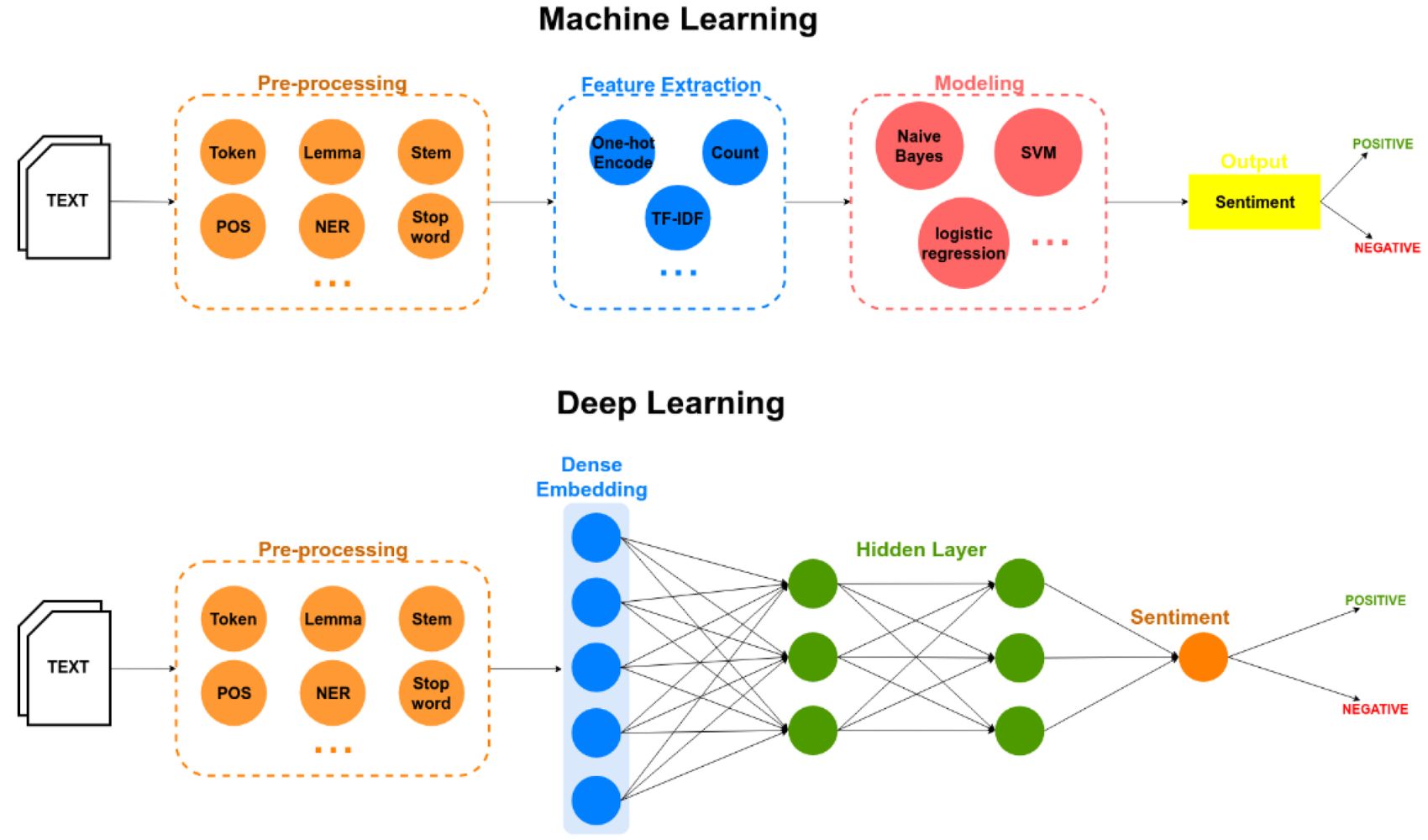
Embedding has gained tremendous popularity in recent years, particularly with the advent of deep learning. Deep neural networks are capable of learning complex and non-linear relationships, making them well-suited for capturing the intricate patterns and dependencies present in the data.
Embedding can be used in a wide range of applications, including text analysis, image recognition, recommendation systems, and more. In this article, we will explore the fundamentals of embedding, how it works, and its various applications in machine learning. We will also discuss the different approaches to creating embeddings, such as using pre-trained embeddings or training them from scratch.
Whether you are a machine learning enthusiast or a data scientist looking to enhance your models, understanding embedding is crucial for effectively representing and analyzing your data. So, let’s dive into the world of embedding and discover its power in transforming categorical data into meaningful representations for machine learning.
What is Embedding?
Embedding, in the context of machine learning, refers to the process of representing categorical or discrete data in a continuous, numerical form. It is a way to transform raw data into a format that machine learning models can effectively understand and utilize.
When dealing with traditional machine learning algorithms, such as decision trees or logistic regression, it is often necessary to convert categorical variables into numerical ones. This is typically done using one-hot encoding, where each category is assigned a binary value. However, one-hot encoding can lead to high-dimensional and sparse representations, as the number of possible categories increases. This can be computationally expensive and may result in the curse of dimensionality.
Embedding addresses this issue by representing categorical variables as dense vector representations, also known as embeddings. These embeddings capture the inherent relationships and semantic meanings of the data, allowing machine learning models to learn and generalize better.
Embeddings are derived from the idea that similar categories should have similar representations. By placing similar categories closer together in the embedding space, models can effectively measure the similarity or dissimilarity between different categories.
For example, consider a dataset of movie genres. By using embeddings, we can represent each genre as a numerical vector with multiple dimensions. Genres that are closely related or share similar characteristics, such as action and adventure, will have embeddings that are close to each other in the embedding space. This proximity allows the model to understand the underlying similarities between different genres and make more accurate predictions.
Embedding can be understood as a dimensionality reduction technique, where high-dimensional categorical data is transformed into a lower-dimensional continuous space. This not only reduces the computational complexity but also enables the model to capture complex patterns and dependencies within the data.
Overall, embedding provides a powerful mechanism to represent categorical data in a format that is suitable for machine learning models. By capturing the relationships and semantic meanings of the data, embedding allows models to extract valuable insights, make accurate predictions, and drive intelligent decision-making.
How Embedding Works
Embedding works by mapping categorical or discrete variables to dense vector representations in a continuous space. This is accomplished through a process of learning the optimal representations that capture the important features and relationships of the data.
At a high level, the process of embedding involves the following steps:
- Defining the Embedding Space: Before creating embeddings, we first need to define the space in which the embeddings will live. This involves specifying the dimensionality of the embedding space. The choice of dimensionality will depend on the specific problem and the complexity of the data.
- Initializing the Embeddings: Once the embedding space is defined, the embeddings are initialized with random values. These initial values act as starting points for the learning process.
- Training the Embeddings: The embeddings are then trained using machine learning algorithms or neural networks. The goal is to learn the optimal embeddings that minimize the loss function and capture the underlying relationships and semantics of the data.
- Updating the Embeddings: During the training process, the embeddings are continuously updated in order to improve their quality and effectiveness. This is achieved through the process of gradient descent, where the gradients of the loss function with respect to the embeddings are computed and used to update their values.
- Evaluating the Embeddings: Once the embeddings have been trained, they can be evaluated to measure their performance in capturing the important features of the data. This can be done through various evaluation metrics, such as accuracy, precision, recall, or by visualizing the embeddings to identify clusters or patterns.
One popular approach for training embeddings is through the use of neural networks, specifically through the technique known as Word2Vec. Word2Vec is a shallow neural network that learns word embeddings by predicting the context of words in a large corpus of text.
Another commonly used technique for embedding is called GloVe (Global Vectors for Word Representation). GloVe leverages co-occurrence statistics to learn word embeddings that capture both semantic and syntactic relationships between words.
Regardless of the specific training algorithm or technique used, the key idea behind embedding is to create meaningful representations that capture the essential features and relationships of the data. These embeddings enable machine learning models to leverage the information contained within the categorical variables and make accurate predictions or decisions based on that information.
Pre-trained Embeddings
Pre-trained embeddings are pre-computed and pre-trained representations of categorical variables that are readily available for use in machine learning tasks. These embeddings are usually trained on large, external datasets using advanced language models or techniques.
There are several advantages to using pre-trained embeddings:
- Transfer Learning: Pre-trained embeddings enable transfer learning, where knowledge gained from one task is transferred to improve performance on another related task. By leveraging pre-trained embeddings, models can benefit from the wealth of information learned on massive datasets without needing to train from scratch.
- Improved Performance: Pre-trained embeddings are often trained on large and diverse datasets, allowing them to capture nuanced relationships and semantic meanings. Models that use pre-trained embeddings tend to demonstrate better performance and generalization compared to models trained solely on limited data.
- Time and Resource Savings: Training embeddings from scratch can be time-consuming and computationally expensive, especially when dealing with large datasets. By using pre-trained embeddings, the need for extensive training can be reduced or eliminated altogether, resulting in significant time and resource savings.
One of the most widely used pre-trained embeddings is Word2Vec, which captures word relationships and semantics based on their co-occurrence in text. Word2Vec embeddings have been trained on extensive corpora, such as Wikipedia or news articles, allowing them to capture rich semantic information.
GloVe embeddings are another popular option, trained on large amounts of text data to capture both semantic and syntactic relationships between words. GloVe embeddings have been pre-trained on massive corpora, such as Common Crawl or Wikipedia, and are available in various dimensions to suit different tasks and models.
These pre-trained embeddings can be easily integrated into machine learning pipelines using existing libraries and frameworks. They can be fine-tuned or used as fixed features depending on the specific task and the size of the available dataset.
It’s important to note that while pre-trained embeddings offer many benefits, they may not always capture the specific context or domain knowledge required for a particular task. In such cases, it may be necessary to fine-tune or train embeddings from scratch to ensure optimal performance.
Overall, pre-trained embeddings provide a valuable resource for machine learning tasks by offering transferable knowledge, improved performance, and time savings. They serve as a powerful tool for leveraging the collective knowledge learned from vast amounts of data, ultimately enhancing the performance and efficiency of machine learning models.
Training Embeddings from Scratch
Training embeddings from scratch involves the process of learning embeddings directly from the available data, without utilizing pre-existing embeddings. This approach allows the embeddings to be tailored to the specific task or domain at hand.
There are several reasons why training embeddings from scratch can be beneficial:
- Domain-Specific Knowledge: By training embeddings from scratch, it is possible to capture the unique nuances and characteristics of the specific dataset or domain. This can lead to improved performance as the embeddings are finely tuned to the task at hand.
- Overcoming Data Limitations: In some cases, pre-trained embeddings may not be available or may not adequately capture the necessary information for the specific task. By training embeddings from scratch, models can learn to extract the relevant features directly from the available data, even when dealing with limited or domain-specific datasets.
- Flexibility and Customization: Training embeddings from scratch provides greater flexibility in terms of architecture design and hyperparameter tuning. Models can be customized to the specific requirements and constraints of the task, potentially leading to improved performance and interpretability.
To train embeddings from scratch, various techniques can be employed depending on the nature of the data and the specific machine learning architecture used. For text-based data, popular algorithms such as Word2Vec, Skip-gram or Continuous Bag of Words (CBOW), can be utilized to learn word embeddings by predicting the surrounding context words or the target word based on context window words. These algorithms leverage the co-occurrence patterns in the data to capture semantic and syntactic relationships between words.
For other types of data, such as images or sequential data, deep learning architectures like convolutional neural networks (CNNs) or recurrent neural networks (RNNs) can be employed to learn the embeddings. Depending on the task at hand, different model architectures and training strategies may be explored to achieve optimal performance.
It’s important to note that training embeddings from scratch requires sufficient data to learn robust representations. If the dataset is limited or noisy, the performance of the trained embeddings may be compromised. In such cases, it may be beneficial to consider transfer learning with pre-trained embeddings, or other techniques like data augmentation, to overcome data limitations.
Overall, training embeddings from scratch offers the advantage of domain-specific knowledge, flexibility, and customization. It allows for the fine-tuning of embeddings specifically tailored to the task or domain, potentially leading to improved performance and better capture of the unique characteristics of the data.
Applications of Embedding in Machine Learning
Embedding has a wide range of applications in machine learning across various domains. Its ability to transform categorical or discrete data into meaningful representations opens up numerous possibilities for leveraging the power of machine learning algorithms. Here are some prominent applications of embedding:
- Natural Language Processing (NLP): Embedding is extensively used in NLP tasks, such as text classification, sentiment analysis, machine translation, and named entity recognition. By representing words or sentences as dense vectors, embedding allows models to capture semantic meaning, context, and similarity between words, enabling more accurate and context-aware language understanding.
- Recommendation Systems: Embedding plays a crucial role in recommendation systems, where it is used to represent user preferences, item features, and interactions. By mapping users and items to latent vector representations using embedding, recommendation models can effectively capture user-item similarities and make personalized recommendations.
- Image Analysis: Embedding enables powerful image analysis techniques such as image classification, object detection, and image retrieval. By transforming images into dense vector representations, embedding allows models to capture visual features, similarities, and relationships between images, facilitating effective image analysis and understanding.
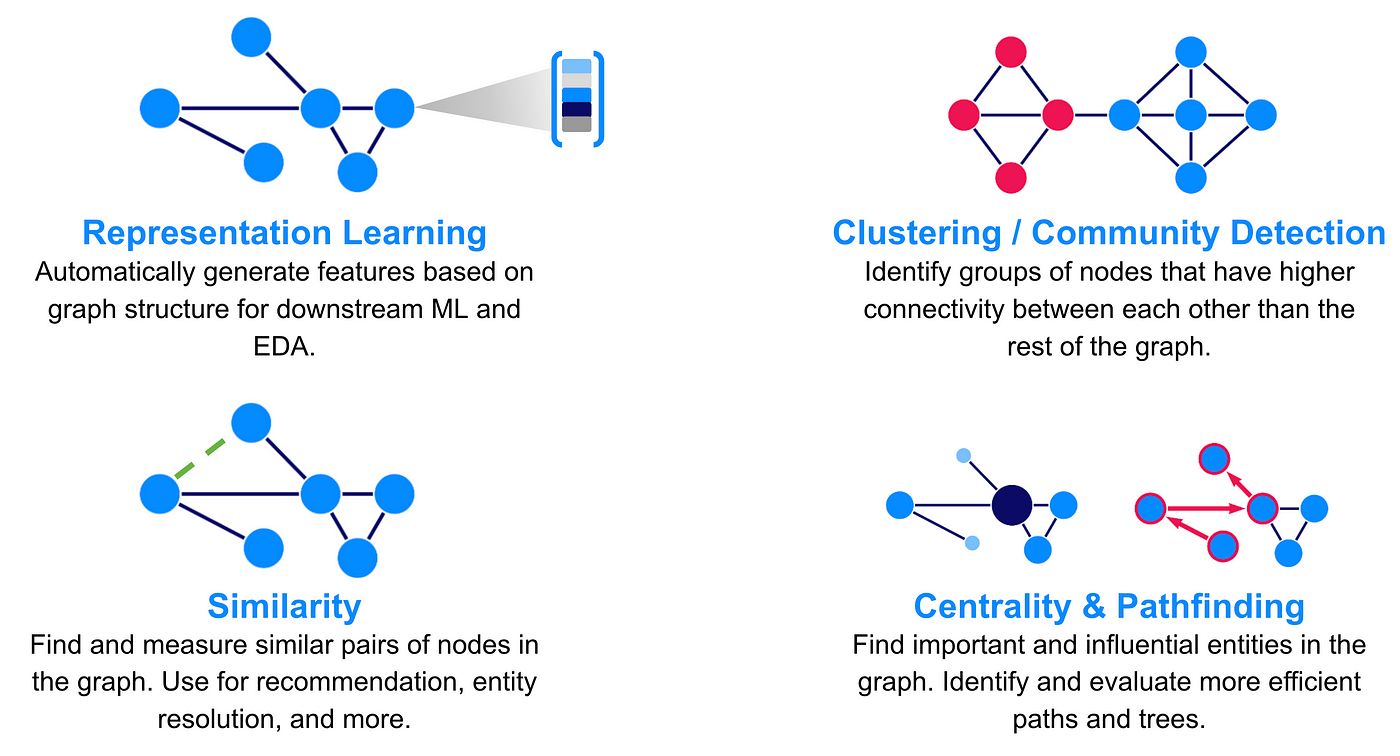
- Graph Analysis: Embedding is employed in graph analysis tasks such as link prediction, node classification, and graph clustering. By embedding nodes or edges of a graph into a continuous vector space, graph embeddings capture structural and semantic relationships between entities, enabling efficient graph analysis and mining.
- Anomaly Detection: Embedding can be used for anomaly detection tasks in various domains, such as fraud detection, network intrusion detection, or medical diagnosis. By learning representations of normal behavior, embeddings can identify deviations from the expected patterns and detect anomalies in the data.
These are just a few examples of how embedding is used in machine learning applications across different domains. The versatility of embedding allows it to be adapted and applied to a wide range of problems, providing valuable insights and enabling intelligent decision-making.
Furthermore, embedding techniques are continually evolving, with ongoing research focused on enhancing the quality of embeddings, improving training algorithms, and exploring new applications.
By leveraging the power of embedding, machine learning models can effectively capture and utilize the information contained within categorical or discrete variables, resulting in improved accuracy, efficiency, and generalization across various tasks and domains.
Conclusion
Embedding is a powerful technique in machine learning that transforms categorical or discrete data into continuous, meaningful representations. By mapping categorical variables to dense vectors, embedding captures the relationships and semantic meanings of the data, enabling machine learning models to effectively learn and make intelligent decisions.
Throughout this article, we have explored the fundamentals of embedding, how it works, and its various applications in machine learning. We have discussed the benefits of pre-trained embeddings, which offer transferable knowledge, improved performance, and time savings. We have also examined the advantages of training embeddings from scratch, which provide domain-specific knowledge, flexibility, and customization.
Embedding has become a crucial component in various machine learning applications, such as natural language processing, recommendation systems, image analysis, graph analysis, and anomaly detection. It allows models to capture the important features, similarities, and relationships within the data, enabling more accurate predictions and intelligent decision-making.
As the field of machine learning continues to evolve, research and advancements in embedding techniques are ongoing. Further improvements are being made in training algorithms, fine-tuning strategies, and exploring new applications. Embedding provides a powerful tool for unlocking the potential of categorical or discrete data, aiding in the development of more robust and efficient machine learning models.
Whether pre-trained or trained from scratch, embedding offers tremendous value in extracting meaningful information from categorical variables. By leveraging the power of embedding, machine learning practitioners and data scientists can enhance their models, improve accuracy, and uncover valuable insights from their data.
As you explore the world of machine learning and delve into specific tasks and applications, keep in mind the potential of embedding to transform your data and elevate the performance of your models. Embrace the versatility and power of embedding, and let it guide you in your journey towards building smarter, more effective machine learning systems.