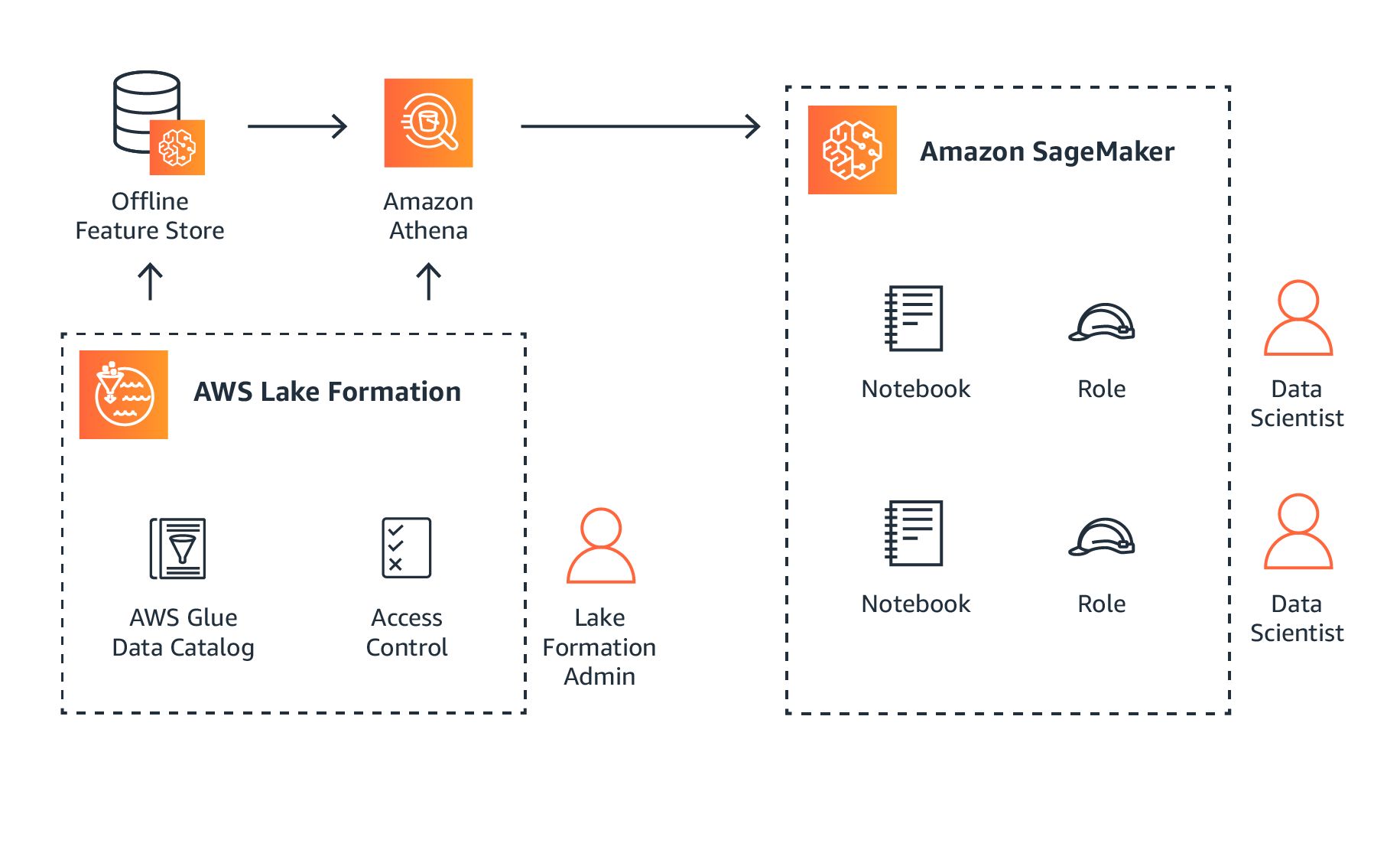
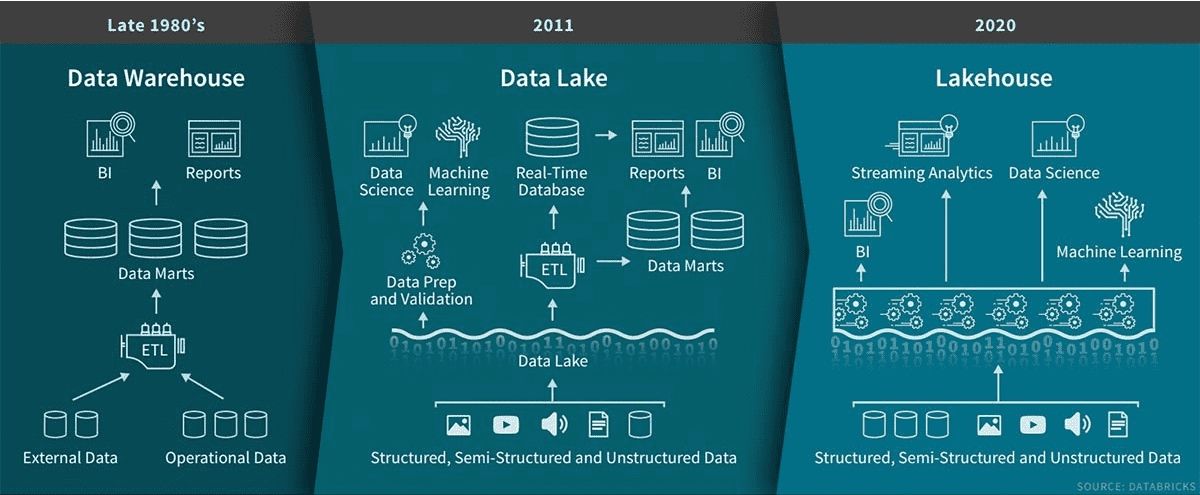
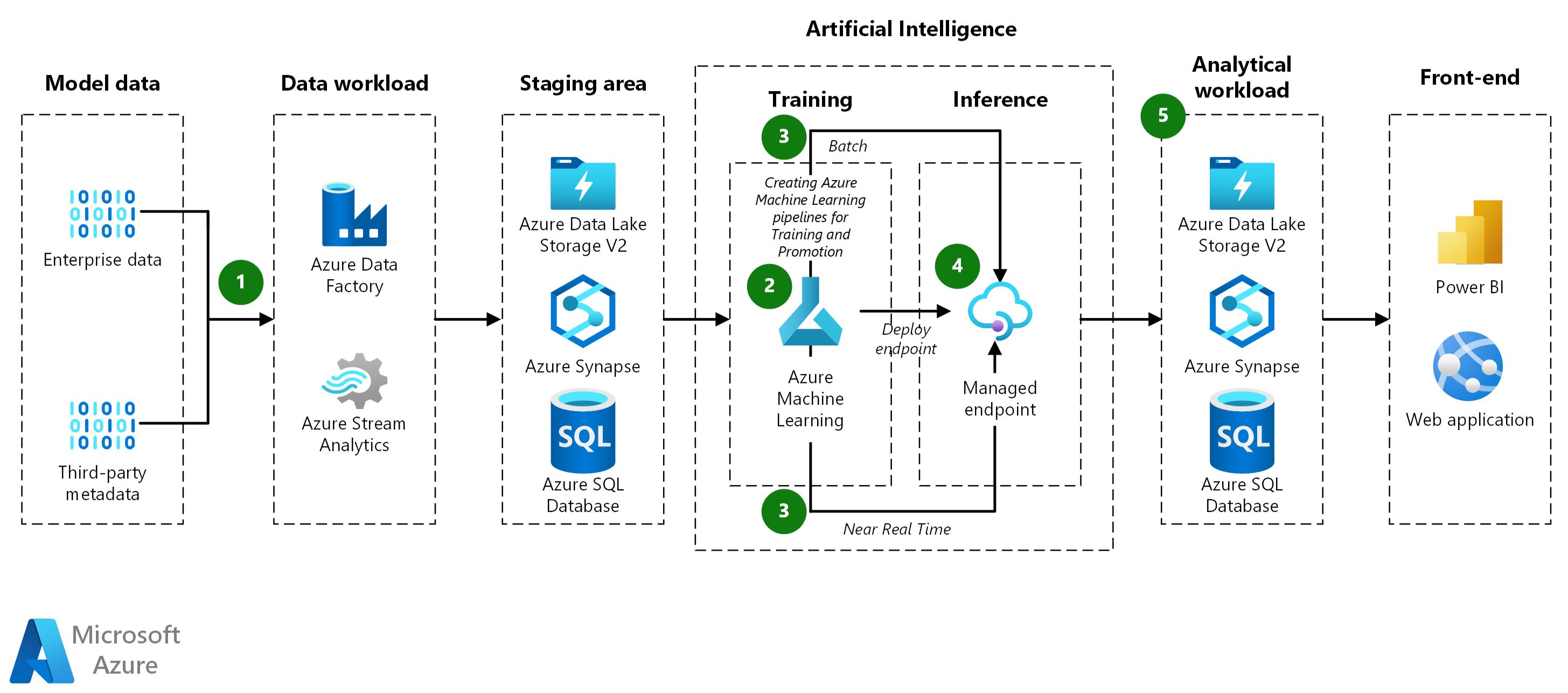
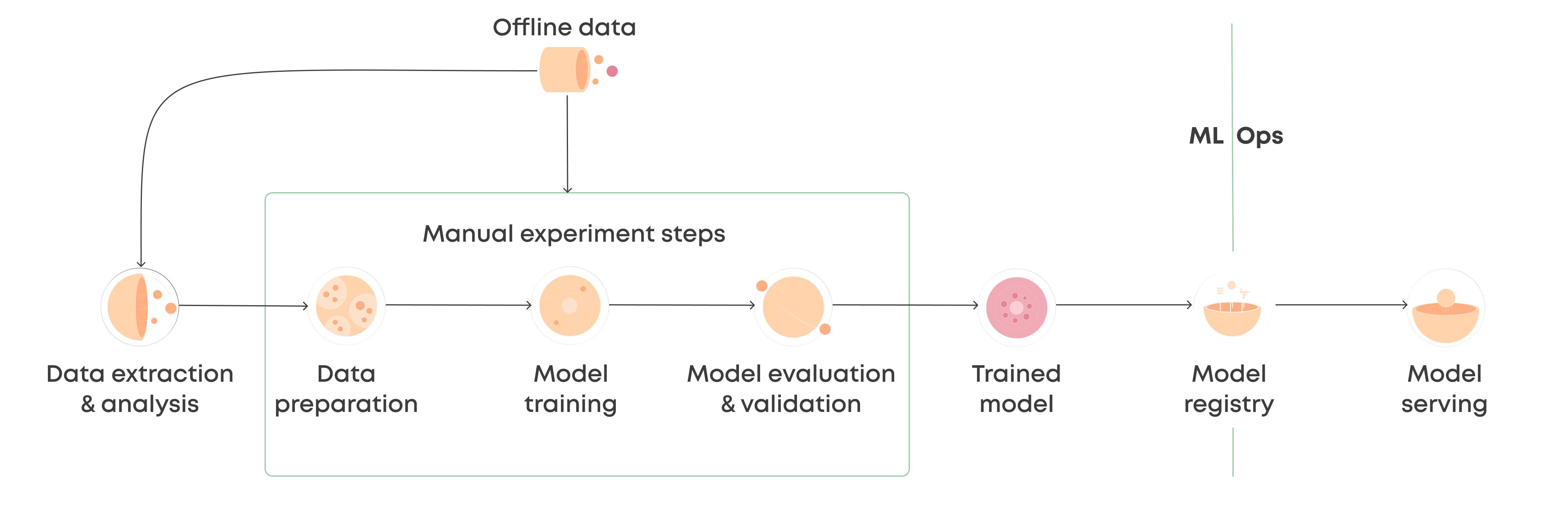
What Is Deployment in Machine Learning
Deployment in machine learning refers to the process of taking a trained machine learning model and making it available for use in real-world applications. It involves integrating the model into a production environment where it can receive input data, make predictions or perform tasks, and generate output. This is a crucial step in the machine learning workflow, as it allows organizations to derive value from their models and achieve tangible results.
During deployment, the model is implemented in a way that enables it to handle new data and make predictions in real-time. This can involve deploying the model on a cloud platform, embedding it into a web application, or integrating it into an existing software system. The ultimate goal of deployment is to make the model accessible and usable by end-users, whether they are customers, employees, or other stakeholders.
Deployment is a key milestone in the machine learning process because it enables organizations to leverage the insights and predictions generated by their models to drive decision-making and improve operational efficiency. It allows companies to automate tasks, streamline processes, and gain a competitive edge by harnessing the power of data-driven intelligence.
Deployed machine learning models can be used in a wide range of applications, including fraud detection, recommendation systems, image recognition, natural language processing, and more. They can provide valuable insights, automate repetitive tasks, and solve complex problems that would otherwise be time-consuming or impossible for humans to handle.
However, deploying machine learning models is not without its challenges. It requires careful planning and consideration of factors such as scalability, infrastructure management, version control, and ongoing monitoring and maintenance. These challenges must be addressed to ensure the successful integration and continuous operation of the deployed model.
In the following sections, we will explore the importance of deployment in machine learning, the steps involved in the deployment process, the challenges organizations may face, and best practices to ensure successful deployment.
Introduction
Machine learning has revolutionized the way organizations extract insights and make predictions from their data. By leveraging complex algorithms, statistical models, and large datasets, machine learning allows computers to learn from past experiences and improve their performance over time. However, the true value of machine learning lies in its application to real-world scenarios, where models can be deployed and put into practical use.
This article explores the concept of deployment in machine learning and its significance in leveraging the power of trained models. Deployment refers to the process of taking a machine learning model and making it available for use in production environments. It involves integrating the model into existing systems or applications, allowing it to receive input data, make predictions, and generate actionable insights.
Deployed machine learning models have the potential to drive business value by automating tasks, enhancing decision-making processes, and improving operational efficiency. They can be applied to a wide range of domains, such as finance, healthcare, marketing, and manufacturing, to solve complex problems that would be difficult or time-consuming for humans to tackle.
Throughout this article, we will delve into the steps involved in the deployment process, the challenges organizations may face, and best practices for successful deployment. We will explore how organizations can overcome scalability issues, effectively manage infrastructure, implement version control strategies, and establish monitoring and maintenance procedures.
By understanding the importance of deployment in machine learning and adopting best practices, organizations can fully leverage their models’ capabilities and maximize the return on their investment in data-driven insights. Whether it’s predicting customer churn, optimizing supply chain operations, or personalizing user experiences, deployment enables organizations to turn their machine learning models into valuable assets that drive business growth and competitive advantage.
Definition of Deployment
In the context of machine learning, deployment refers to the process of taking a trained machine learning model and making it accessible and usable in real-world applications. It involves integrating the model into a production environment, where it can receive new data inputs, make predictions or perform tasks, and generate output.
When a machine learning model is deployed, it is implemented in a way that allows it to handle real-time data and make accurate predictions. This can involve various techniques, such as embedding the model into an application, deploying it on a cloud platform, or integrating it into existing software systems.
During the deployment process, the model should be optimized for performance, scalability, and reliability. It should be able to handle large volumes of data and efficiently make predictions or perform tasks in a timely manner. Additionally, the model should be robust enough to handle different types of inputs and adapt to changing conditions or new data patterns.
The deployment of a machine learning model involves several components, including the model itself, the infrastructure on which it runs, and the user interface or application through which it interacts with end-users. It requires coordination and collaboration between data scientists, software engineers, and system administrators to ensure a smooth and successful deployment.
Once deployed, the machine learning model becomes a valuable asset for organizations. It can automate tasks, provide insights and predictions, improve decision-making processes, and enhance overall operational efficiency. Whether it’s predicting customer behavior, detecting anomalies in a manufacturing process, or analyzing medical images, deployed machine learning models have the potential to drive significant value for businesses.
It is important to note that deployment is not the final stage in the machine learning workflow. Models deployed in production environments require continuous monitoring, evaluation, and maintenance. Regular updates and improvements may be necessary to ensure the model remains accurate and effective over time.
Overall, deployment is a critical step in the machine learning process. It bridges the gap between the development and real-world application of machine learning models, enabling organizations to leverage the power of data-driven insights and drive meaningful impact in their respective domains.
Why is Deployment Important in Machine Learning?
Deployment in machine learning is a crucial step in leveraging the power of trained models and turning insights into actionable outcomes. It plays a vital role in bridging the gap between model development and real-world application. Here are some key reasons why deployment is important in machine learning:
1. Turning Insights into Action: During the development phase, machine learning models are trained on historical data to gain insights and make predictions. However, these insights are of limited use if they remain limited to the development environment. Deployment allows organizations to apply these insights in real-world scenarios, enabling them to make informed decisions, automate tasks, and drive operational efficiency.
2. Enhancing Decision-Making Processes: Deployed machine learning models provide organizations with the ability to make data-driven decisions quickly and accurately. By automating complex analyses and predictions, these models can process vast amounts of data and generate insights that humans may overlook. This can lead to improved decision-making across various domains, such as fraud detection, customer churn prediction, demand forecasting, and more.
3. Automating Repetitive Tasks: Machine learning models can automate time-consuming and repetitive tasks, freeing up human resources to focus on more strategic and creative endeavors. For example, models can automatically classify and categorize incoming support tickets, route emails to the appropriate departments, or generate personalized recommendations for customers. By automating these tasks, organizations can improve efficiency and allocate resources more effectively.
4. Solving Complex Problems: Deployed machine learning models have the potential to tackle complex problems that may be difficult for humans to solve. Whether it’s image recognition, natural language processing, or anomaly detection, these models can process vast amounts of data and identify patterns or anomalies that may not be obvious to human analysts. This enables organizations to address complex challenges and uncover valuable insights that may have been overlooked.
5. Enabling Continuous Learning: Deployed models can continually learn and improve over time. By collecting real-time data and continuously updating the model, organizations can ensure that predictions and insights remain relevant and accurate. This allows models to adapt to changing conditions, evolving trends, and new data patterns, ensuring their ongoing effectiveness.
In essence, deployment is important in machine learning because it enables organizations to put their models to practical use and derive value from the insights and predictions they generate. By integrating these models into production environments, organizations can streamline processes, improve decision-making, automate tasks, and solve complex problems.
Steps in the Deployment Process
The deployment process in machine learning involves several steps to ensure the successful integration and operation of trained models in real-world applications. While the exact steps may vary depending on the specific requirements and technologies involved, the following outlines a general framework for the deployment process:
1. Data Preprocessing: Before deploying a machine learning model, it is crucial to preprocess and clean the data. This involves removing outliers, handling missing values, normalizing or standardizing features, and encoding categorical variables. Data preprocessing ensures that the model receives high-quality input data, thus improving the accuracy and performance of predictions or tasks.
2. Model Selection and Training: The next step is to select the appropriate machine learning model for the specific task at hand. This involves considering factors such as the type of problem (classification, regression, etc.) and the characteristics of the data. Once the model is selected, it needs to be trained using labeled or historical data. This involves fitting the model to the training data, adjusting parameters, and optimizing performance.
3. Model Evaluation: After training, the performance of the model needs to be evaluated on a separate validation or test dataset to assess its accuracy and generalization. Various metrics, such as accuracy, precision, recall, or mean squared error, can be used to measure the model’s performance. The evaluation process helps identify potential issues and guides model improvement or selection of alternative models.
4. Model Deployment: Once the model is deemed satisfactory, it is ready for deployment. This involves integrating it into a production environment, which may include software systems, web applications, or cloud platforms. The deployment process requires careful consideration of the infrastructure requirements, scalability, security measures, and integration with existing systems or APIs.
5. Testing and Validation: Before releasing the deployed model to end-users, it is crucial to thoroughly test and validate its performance in a real-world setting. This involves simulating various inputs and evaluating the output to ensure accurate predictions and reliable performance. Robust testing and validation help identify any issues or bugs that may affect the model’s performance or cause unexpected behaviors.
6. Monitoring and Maintenance: After deployment, the model needs to be continuously monitored and maintained to ensure its ongoing effectiveness. This includes monitoring input data quality, tracking model performance, and addressing issues as they arise. Regular updates and improvements may be necessary to accommodate changes in data patterns, technology upgrades, or evolving requirements.
By following these steps, organizations can ensure a smooth and successful deployment of their machine learning models. Each step plays a crucial role in preparing the model, assessing its performance, integrating it into production, and maintaining its reliability in real-world applications.
Data Preprocessing
Data preprocessing is a crucial step in the deployment process of machine learning models. It involves preparing and cleaning the data to ensure that the model receives high-quality input for accurate predictions or tasks. Data preprocessing encompasses several operations, including handling missing values, outlier detection and removal, feature scaling, and encoding categorical variables.
One common preprocessing step is handling missing values. Missing data can negatively impact the performance of a machine learning model. Depending on the nature and extent of missingness, different strategies can be employed, such as removing rows with missing values, filling in missing values using statistical measures (mean, median, mode), or using more advanced techniques like imputation algorithms.
Outlier detection and removal is another important preprocessing task. Outliers are data points that deviate significantly from the majority of the data. These outliers can distort the learning process of the model, leading to inaccurate predictions. Various statistical methods, such as the z-score or the interquartile range, can be used to identify and remove outliers from the dataset.
Feature scaling is often necessary to ensure that the input features have a similar scale or range. This is important because many machine learning algorithms rely on the assumption that features are on a similar scale. Common scaling techniques include normalization, which scales the features to a specific range (e.g., between 0 and 1), and standardization, which transforms the features to have a mean of 0 and a standard deviation of 1.
Another important aspect of data preprocessing is encoding categorical variables. Machine learning models typically require numeric input, which means categorical variables need to be encoded as numbers. This can be done using techniques like one-hot encoding, which creates binary columns for each category, or label encoding, where categories are assigned numerical labels. The choice of encoding method depends on the nature of the categorical variable and the specific requirements of the model.
Data preprocessing is essential because it ensures that the machine learning model receives clean, standardized, and meaningful input data. Preprocessing helps to remove noise, handle missing values, and ensure that features are appropriately scaled and encoded. It enhances the model’s ability to generate accurate predictions or perform tasks in real-world scenarios.
It is worth noting that data preprocessing is an iterative process. As models are deployed and new data becomes available, the preprocessing steps may need to be revisited and updated. Regularly evaluating and preprocessing the data helps to maintain the model’s accuracy and reliability over time.
Model Selection and Training
Once the data has been preprocessed, the next step in the deployment process is selecting an appropriate machine learning model and training it using the prepared dataset. Model selection plays a crucial role in the success of the deployment as it determines the model’s ability to accurately make predictions or perform tasks in real-world scenarios.
Model selection involves considering the specific problem at hand, the characteristics of the data, and the desired outcome. Depending on the problem type, such as classification, regression, or clustering, different models can be considered. Each model has its own strengths and weaknesses, and its performance may vary based on the nature of the data and the problem being addressed.
Once a model is selected, it is trained using the preprocessed data. During the training phase, the model learns patterns and relationships within the data to make accurate predictions or perform tasks. This is typically achieved by adjusting the model’s internal parameters through an optimization process.
Training a machine learning model involves splitting the preprocessed data into two sets: the training set and the validation set. The training set is used to update the model’s parameters, while the validation set is used to evaluate the model’s performance and tune its hyperparameters.
The training process involves iteratively feeding batches of training data into the model and updating its parameters to minimize the difference between the predicted output and the actual target values. This process continues until the model reaches a satisfactory level of accuracy or some predefined convergence criteria are met.
Model evaluation is an integral part of the model selection and training process. It helps in assessing the model’s performance on unseen data and ensures that it generalizes well to make accurate predictions in real-world scenarios. Various evaluation metrics, such as accuracy, precision, recall, F1 score, or mean squared error, can be used depending on the problem type.
In addition to traditional machine learning models, deep learning models, such as neural networks, are gaining popularity due to their ability to learn complex patterns and extract high-level features from data. However, these models often require larger datasets and more computational resources for training.
Choosing an appropriate model and effectively training it are critical to the success of a deployed machine learning system. Model selection involves considering the problem type and data characteristics, while training requires diligent parameter tuning and evaluation. These steps ensure that the deployed model can make accurate predictions or perform tasks with high levels of precision and reliability in real-world applications.
Model Evaluation
Model evaluation is a critical step in the deployment process of machine learning models. It assesses the performance and effectiveness of the trained model on unseen data and helps determine its accuracy and reliability in real-world scenarios.
During model evaluation, the performance of the trained model is measured using various evaluation metrics that are appropriate for the problem at hand. The choice of metrics depends on the specific task, such as classification, regression, or clustering. For classification tasks, metrics like accuracy, precision, recall, and F1 score are commonly used. In regression tasks, metrics like mean squared error (MSE), mean absolute error (MAE), and R-squared are often used.
The evaluation process typically involves splitting the dataset into a training set and a separate validation or test set. The validation or test set represents unseen data that the model has not been exposed to during training. This separation helps assess the model’s ability to generalize and make accurate predictions on new, unseen data.
The trained model is then used to make predictions or perform tasks on the validation or test set. The predicted outputs are compared to the ground truth labels or target values to measure the model’s performance using the chosen evaluation metrics.
Model evaluation provides insights into the model’s strengths and weaknesses, helping identify potential issues and areas for improvement. If the model’s evaluation metrics fall below the desired thresholds, further refinement and adjustments may be necessary. This may involve revisiting the model’s architecture, hyperparameters, or even considering alternative models.
It is important to note that model evaluation should be conducted in a fair and unbiased manner. To ensure that the evaluation results are reliable and representative, cross-validation techniques like k-fold cross-validation can be employed. This involves randomly dividing the data into k subsets or folds and performing multiple iterations, each time using a different fold for validation while using the remaining folds for training. The results from these iterations are then averaged to obtain a more robust evaluation.
Model evaluation is an ongoing process that continues even after deployment. As new data becomes available, the model’s performance should be regularly assessed and monitored. This helps identify any degradation in performance, potential concept drift, or the need for retraining or reevaluation.
Effective model evaluation ensures that the deployed machine learning model is accurate and reliable in making predictions or performing tasks in real-world scenarios. By measuring its performance using appropriate evaluation metrics and ensuring ongoing monitoring, organizations can maintain the model’s effectiveness and adapt it to evolving data patterns and requirements.
Model Deployment
Model deployment is the process of integrating a trained machine learning model into a production environment where it can receive input data, make predictions, perform tasks, and generate output. The goal of model deployment is to make the model accessible and usable by end-users, enabling organizations to leverage its insights and predictions in real-world applications.
There are several considerations and steps involved in the model deployment process. These include:
Infrastructure and Environment: Deploying a model requires setting up the necessary infrastructure and environment to support its operation. This may involve configuring servers, cloud platforms, or other computing resources to handle the model’s computational requirements. It is important to ensure that the infrastructure can scale to accommodate increasing demands and provide efficient and reliable performance.
Integration: Integrating the model into existing systems or applications is a crucial step in deployment. This may involve embedding the model as part of a web application, integrating it with an API, or incorporating it into an existing software system. The integration process should be carefully planned to ensure smooth communication between the model and other components of the system.
Scalability: Deployed models need to be designed to handle increasing volumes of data and user demands. This requires considering scalability challenges and implementing strategies to accommodate more significant workloads. Scaling may involve horizontal scaling by distributing the model across multiple servers or vertical scaling by upgrading hardware resources.
Security: Model deployment also requires addressing security concerns to protect sensitive data and maintain the integrity of the system. This may include implementing access controls, encryption mechanisms, and ensuring that the deployment environment meets compliance requirements.
Testing and Validation: Before deploying the model to end-users, thorough testing and validation should be conducted. This ensures that the model performs as expected, produces accurate results, and handles different scenarios and edge cases effectively. Testing and validation help identify any issues or bugs that may affect the model’s performance or cause unexpected behaviors.
Documentation and Version Control: Proper documentation and version control are essential during model deployment. Documenting the deployment process, including the specific versions of the model, libraries, and dependencies used, helps with maintaining consistency and reproducibility. Version control enables tracking changes to the model and facilitates collaboration among team members.
Once the model is successfully deployed, continuous monitoring and maintenance are crucial to ensure its ongoing effectiveness. Monitoring involves tracking key performance indicators, detecting anomalies, and identifying potential degradation in the model’s performance. Maintenance may involve regular updates to address issues, enhance performance, or adapt to changing data patterns.
Model deployment is a critical step in realizing the value of machine learning models. By carefully considering infrastructure requirements, integrating with existing systems, ensuring scalability and security, and conducting rigorous testing, organizations can successfully deploy models that provide valuable insights and predictions in real-world applications.
Challenges in Machine Learning Deployment
Deploying machine learning models in real-world applications brings forth various challenges that organizations must address to ensure successful and effective deployment. Understanding these challenges is crucial for mitigating potential risks and maximizing the value derived from deployed models. Some key challenges in machine learning deployment include:
1. Scalability: Scaling up the deployment of machine learning models to handle increasing volumes of data and user demands can be challenging. As the number of users and data inputs grows, the infrastructure and resources must be able to handle the increased workload without compromising performance. Efficient scaling strategies, such as distributed computing or cloud-based solutions, need to be considered and implemented.
2. Infrastructure Management: Managing the infrastructure required for deploying and running machine learning models can be complex. This involves setting up and maintaining the necessary computational resources, storage, and networking infrastructure to support the models. Effective infrastructure management ensures high availability, performance, and reliability of the deployed models.
3. Version Control: Managing different versions of machine learning models can become challenging, especially when multiple iterations or improvements are made over time. Version control helps ensure proper tracking of model versions, dependencies, and modifications, facilitating reproducibility and collaborative development. Implementing robust version control practices is essential to manage and maintain the consistency and integrity of the deployed models.
4. Monitoring and Maintenance: Deployed machine learning models require continuous monitoring to track their performance, detect anomalies, and identify potential issues. Monitoring allows organizations to ensure that the models are producing accurate and reliable predictions or tasks. Additionally, regular maintenance procedures, such as updates, bug fixes, and retraining, are necessary to keep the models up-to-date and effective in tackling new challenges and evolving data patterns.
Successfully overcoming these challenges can lead to effective deployment and utilization of machine learning models in real-world applications. Organizations must actively address scalability concerns, effectively manage the infrastructure, implement robust version control mechanisms, and establish monitoring and maintenance procedures. By doing so, they can ensure that their deployed models consistently deliver accurate predictions, improve decision-making processes, and generate meaningful insights.
Scalability
Scalability is a significant challenge in the deployment of machine learning models. As the volume of data and user demands increase, organizations must ensure that their deployed models can handle the growing workload without compromising performance. Scalability plays a crucial role in enabling models to efficiently process large amounts of data and provide timely predictions or perform tasks.
There are several key considerations when addressing scalability in machine learning deployment:
Infrastructure: To achieve scalability, organizations need to consider the infrastructure that supports the deployment of machine learning models. This includes having sufficient computational resources, storage capacity, and network bandwidth to handle the increasing workload. Scalable infrastructures, such as distributed computing systems or cloud platforms, provide the flexibility to scale resources up or down based on demand.
Parallelization: One technique for improving scalability is parallelizing the model’s computations. By distributing the workload across multiple computing resources, such as multiple servers or GPU clusters, processing time can be significantly reduced. Parallelization techniques include data parallelism, where different subsets of the data are processed simultaneously, and model parallelism, where different parts of the model are processed on separate resources.
Batch Processing: Another approach to scalability is batch processing, where multiple data inputs are processed together as a batch. This reduces the overall processing time by minimizing the overhead associated with loading and unloading data for each individual input. Batch processing can improve efficiency and help accommodate larger workloads by optimizing the use of computational resources.
Distributed Computing: Leveraging distributed computing frameworks, such as Apache Spark or Hadoop, can enable scalability in machine learning deployment. These frameworks allow for distributed processing of large datasets across multiple nodes or clusters, effectively distributing the computational load and improving performance.
Streaming Algorithms: In scenarios where real-time or near real-time processing is required, streaming algorithms can be employed to handle continuous data streams. These algorithms process data as it arrives in a streaming fashion, enabling models to make predictions or perform tasks in real-time or with minimal latency. Streaming algorithms are designed to efficiently process data on-the-fly, ensuring scalability and responsiveness in high-velocity environments.
Addressing scalability concerns in machine learning deployment is crucial to ensure that models can handle the increasing volume of data and user demands. By considering the right infrastructure, implementing parallelization techniques, leveraging distributed computing frameworks, and utilizing streaming algorithms when necessary, organizations can achieve efficient and scalable deployment of machine learning models. This allows models to process data in a timely manner, deliver accurate predictions, and support the growing needs of the business.
Infrastructure Management
Effective infrastructure management is essential for successful deployment of machine learning models. It involves setting up and maintaining the necessary computational resources, storage, and networking infrastructure to support the deployed models. Proper infrastructure management ensures high availability, performance, and reliability of the deployed models in real-world applications.
Here are some key considerations for managing the infrastructure in machine learning deployment:
Resource Provisioning: Provisioning the appropriate computational resources is crucial for efficient deployment. Organizations need to ensure that the infrastructure has sufficient processing power, memory, and storage to handle the computational requirements of the deployed models. Scalability should be a key consideration, allowing the infrastructure to be easily scaled up or down as the demand fluctuates.
Storage Management: Managing data storage is essential for effective deployment. Organizations must consider how and where the data required for the models will be stored. This includes deciding between on-premises storage or cloud-based storage solutions. Additionally, considering data replication, backup, and disaster recovery mechanisms is crucial to maintain data integrity and availability.
Networking: Seamless communication between the deployed models and other components of the system is essential. Organizations need to ensure that the infrastructure provides robust networking capabilities, including reliable and high-speed connections. Networking considerations may include load balancing, firewalls, and network security measures to protect data and ensure smooth operation.
Performance Monitoring: Monitoring the performance of the infrastructure is essential to identify and address any issues. This includes tracking resource utilization, analyzing performance metrics, and proactively identifying bottlenecks or areas for optimization. Performance monitoring helps ensure that the infrastructure can handle the increasing workload and provides the necessary reliability and responsiveness for the deployed models.
Automation and Orchestration: Automating infrastructure management tasks ensures efficient and consistent deployment of models. Automating resource provisioning, monitoring, scaling, and maintenance tasks can save time and reduce the risk of human errors. Orchestration tools and frameworks can be used to automate the deployment pipeline, enabling smoother integration and continuous delivery of machine learning models.
Scalability and Resilience: Infrastructure management should focus on ensuring scalability and resilience in the face of growing demands and potential failures. Implementing strategies such as load balancing, fault tolerance, and redundancy architecture helps ensure smooth and uninterrupted operation of the deployed models. Organizations should regularly assess scalability requirements and plan for future growth to avoid performance bottlenecks.
By effectively managing the infrastructure, organizations can ensure the reliability and performance of deployed machine learning models. Proper resource provisioning, storage management, networking, performance monitoring, and automation will contribute to the smooth operation of the models in real-world applications. Infrastructure management is crucial to support the scalability, resilience, and efficiency required for successful machine learning deployment.
Version Control
Version control is a critical aspect of machine learning deployment, ensuring the management, traceability, and reproducibility of models over time. It involves tracking and controlling different versions of models, libraries, dependencies, and configurations to facilitate collaboration, maintain consistency, and enable reproducibility in the deployment process.
Here are some key considerations for version control in machine learning deployment:
Model Versions: Version control allows organizations to track different versions of machine learning models. This includes saving snapshots of models at different stages of development, modifications, or improvements, and associating them with specific features or datasets. Proper version control ensures that changes made to the models can be traced, rolled back if necessary, and compared for performance evaluation.
Code and Configuration: Version control goes beyond tracking models; it also includes tracking the code used to train and deploy the models. This involves versioning the machine learning codebase, preprocessing scripts, configuration files, and any other code associated with the model’s pipeline. Versioning the code and configurations ensures that all the components required to reproduce the model are properly controlled and managed.
Dependencies and Libraries: Machine learning models rely on various libraries, frameworks, and dependencies. It is crucial to keep track of the specific versions used during model development and deployment. Maintaining a well-documented list of dependencies facilitates reproducibility and ensures that the models can be retrained or redeployed in the future, even as libraries and dependencies evolve.
Collaboration: Version control enables collaboration among team members working on machine learning deployment. It allows multiple developers, data scientists, and engineers to work in parallel on different branches, experiment with different techniques, and merge their contributions. Version control systems provide mechanisms for resolving conflicts, reviewing changes, and ensuring a smooth collaborative workflow.
Reproducibility: Version control ensures that machine learning models can be reproduced reliably. By explicitly tracking all the code, configurations, and dependencies used during model training and deployment, it becomes possible to recreate the exact environment and conditions for training and predicting with the model. This is crucial for maintaining consistency and facilitating model evaluation, validation, and auditing.
Documentation: Version control allows for the documentation of changes, enhancements, and bug fixes made to the models. It provides an audit trail that can be useful for future reference and understanding the evolution of the models over time. Documentation of version history assists in maintaining a clear and comprehensive record of the model’s development and deployment.
Implementing robust version control practices ensures that machine learning models can be effectively managed and maintained in the deployment process. By versioning models, code, configurations, and dependencies, organizations can maintain consistency, enable collaboration, and achieve reproducibility. Proper version control contributes to the traceability and reliability of machine learning deployment, enabling more efficient development, deployment, and maintenance of models.
Monitoring and Maintenance
Monitoring and maintenance are vital aspects of machine learning deployment, ensuring the ongoing performance, reliability, and accuracy of deployed models. Continuous monitoring and timely maintenance allow organizations to identify and address any issues, adapt to changing data patterns, and ensure that the deployed models continue to provide accurate predictions or perform tasks effectively.
Monitoring: Monitoring the deployed models involves tracking key performance metrics and collecting relevant data to assess their performance. This includes monitoring the inputs, outputs, and intermediate data at various stages of the model pipeline. By monitoring these metrics, organizations can identify potential issues, detect anomalies, and evaluate the models’ effectiveness in real-world scenarios.
Performance Metrics: Monitoring often involves tracking specific performance metrics based on the nature of the problem or task. For instance, accuracy, precision, recall, or F1 score can be used for classification tasks, while mean squared error or mean absolute error can be used for regression tasks. Monitoring performance metrics provides insights into how well the models are performing and helps identify areas where improvements may be needed.
Anomaly Detection: Anomaly detection is a crucial aspect of monitoring. By comparing the model’s predictions or task outputs with expected results, organizations can detect anomalies and take appropriate actions. Anomalies could signify issues like data quality problems, changes in data patterns, or model degradation. Implementing anomaly detection techniques ensures the early detection and resolution of any issues affecting the performance of the deployed models.
Maintenance: Regular maintenance is essential to ensure that deployed models continue to function accurately and effectively. Maintenance tasks may include updating the models, retraining on new data, addressing bug fixes, or improving the model’s performance based on new requirements. Maintenance also involves keeping the dependencies and libraries up to date, ensuring compatibility and security patches.
Ongoing Training: As new data becomes available, retraining the models periodically is necessary to maintain their accuracy and relevance. This may involve incorporating new labeled data or using techniques like transfer learning to leverage pre-trained models. Ongoing training helps the models adapt to changes, evolving trends, and new data patterns, ensuring their continued effectiveness in real-world scenarios.
Error and Issue Resolution: Timely diagnosing and resolving errors and issues is critical in maintenance. When errors or issues arise, organizations need to actively investigate the root cause, whether it be data-related issues, code bugs, or infrastructure problems. Proper logging and error tracking mechanisms can help identify and address these issues promptly.
Version Control and Documentation: Maintaining proper version control and documentation of changes made to the models, code, configurations, and dependencies is essential. Version control ensures traceability, making it easier to identify which version caused a particular issue and to roll back if necessary. Documentation helps in understanding the model’s evolution, facilitating maintenance, and knowledge sharing among team members.
By actively monitoring and maintaining deployed machine learning models, organizations can ensure ongoing accuracy, performance, and reliability. Monitoring allows for the detection of anomalies and performance issues, while maintenance ensures continuous improvement, adaptation to changing data, and resolution of errors. Timely monitoring and maintenance contribute to the longevity and effectiveness of deployed models in real-world applications.
Best Practices for Deployment
Deploying machine learning models requires careful planning and execution to ensure success and maximize the value derived from the models. Following best practices during the deployment process is crucial for efficient integration, scalability, maintainability, and effective utilization of the models in real-world applications.
Here are some best practices to consider when deploying machine learning models:
Plan for Scalability: Design the deployment infrastructure with scalability in mind. Anticipate future growth and ensure that the infrastructure can handle the increasing volume of data and user demands. Utilize scalable cloud platforms or distributed computing systems to accommodate growing workloads and maintain performance as demand increases.
Automate the Deployment Process: Automating the deployment process helps ensure consistency, reproducibility, and efficiency. Use tools and frameworks to automate infrastructure provisioning, model training, testing, and deployment pipelines. This minimizes the risk of human error and streamlines the process, making it faster and more reliable.
Implement Version Control: Utilize a version control system to track the different versions of models, code, configurations, and dependencies. This facilitates collaboration among team members, enables easy rollback to previous versions if necessary, and ensures reproducibility. Proper version control also helps maintain documentation and a clear record of changes made during the deployment process.
Set Up Monitoring and Maintenance Procedures: Establish robust monitoring mechanisms to track the performance of the deployed models in real-world scenarios. Monitor key metrics and set up alerts to detect anomalies or performance degradation. Implement regular maintenance procedures to address issues, update models and dependencies, and retrain models on new data. Continuous monitoring and maintenance ensure that the models remain accurate, reliable, and effective over time.
Consider Security and Privacy: Pay attention to security and privacy measures when deploying machine learning models. Ensure that sensitive data is handled securely and that access controls and encryption mechanisms are in place. Implement measures to protect against unauthorized access, data breaches, and adversarial attacks. Consider compliance requirements and industry best practices related to security and privacy.
Document the Deployment Process: Maintain proper documentation throughout the deployment process. Document the steps followed, decisions made, and the reasoning behind them. This aids in reproducing the deployment and helps future team members or stakeholders understand the process. Documentation should encompass the model pipeline, data preprocessing, infrastructure details, performance metrics, and any unique considerations specific to the deployment.
Continuously Evaluate and Improve: Regularly evaluate the performance and impact of the deployed models. Analyze the model’s effectiveness, predictive accuracy, and alignment with the intended business objectives. Collect feedback from end-users to identify areas for improvement or additional features. Continuously update the models, infrastructure, and processes to ensure they remain responsive and aligned with evolving requirements.
By following these best practices, organizations can ensure a smooth and successful deployment of machine learning models. Planning for scalability, automating the deployment process, implementing version control, setting up monitoring and maintenance procedures, considering security and privacy, documenting the process, and continuously evaluating and improving are key factors for achieving highly performant, reliable, and effective machine learning deployment.
Plan for Scalability
Effective scalability planning is crucial for ensuring the successful deployment of machine learning models. Scalability refers to an organization’s ability to handle increasing volumes of data, user demands, and computational requirements without compromising performance. Planning for scalability is essential from the early stages of deployment to accommodate growing workloads and ensure the models can handle higher traffic and larger datasets.
Here are some key considerations for planning scalability in machine learning deployment:
Assess Future Needs: Anticipate future growth and assess the potential scalability requirements of your machine learning models. Consider factors such as increasing data volumes, user demands, concurrent requests, and computational resources needed to handle the workload. Evaluate the potential impact on response times, throughput, and latency to determine the necessary scalability measures.
Infrastructure Scaling: Choose an infrastructure that can easily scale to meet growing demands. Cloud platforms, such as Amazon Web Services (AWS) or Google Cloud Platform (GCP), offer scalability features that allow you to provision additional computational resources on-demand. Auto-scaling capabilities enable automatic scaling of resources based on predefined thresholds, ensuring your infrastructure can handle peak loads without overprovisioning.
Design for Distributed Computing: Consider using distributed computing techniques when deploying machine learning models. Distributed computing frameworks, like Apache Spark or Hadoop, enable processing of large datasets across multiple nodes or clusters, thereby distributing the computational load and improving performance. This allows you to scale horizontally by adding more machines to the cluster as data volumes increase.
Use Parallel Computing: Leverage parallel computing techniques to speed up the processing of machine learning models. Parallelization involves breaking down the computational workload into smaller tasks that are processed simultaneously on separate resources, such as GPUs or clusters. Implementing parallel computing techniques like data parallelism or model parallelism can improve processing time and enable the scalability of models.
Efficient Resource Management: Optimize resource allocation and usage to maximize scalability. This includes effectively utilizing computational resources, minimizing resource contention, and optimizing task scheduling. Monitoring resource usage, identifying bottlenecks, and implementing strategies like workload balancing or task prioritization helps ensure efficient resource management in the context of scalability.
Testing and Benchmarking: Conduct extensive performance testing and benchmarking to assess the scalability of deployed models. Simulate various workload scenarios, including high-traffic periods, to measure the response times, throughput, and resource utilization under different conditions. This helps identify potential scalability limitations and allows for optimization and adjustments to be made in advance.
Monitoring and Capacity Planning: Implement robust monitoring mechanisms to track the performance of deployed models and anticipate capacity needs. Monitor key metrics, such as response times, throughput, resource utilization, and error rates, and set up alerts for potential issues or anomalies. Regularly evaluate and analyze monitoring data to forecast future capacity requirements and plan for additional resources or infrastructure upgrades.
By proactively planning for scalability, organizations can ensure that their machine learning models can handle increasing workloads, larger datasets, and concurrent user demands. Considering infrastructure scaling, distributed computing, parallel computing, efficient resource management, testing and benchmarking, monitoring, and capacity planning enables the seamless scaling of deployed models, ensuring optimal performance and an enhanced user experience.
Automate the Deployment Process
Automating the deployment process is crucial for streamlining the deployment of machine learning models, ensuring consistency, reproducibility, and efficiency. Manual deployment processes can be error-prone, time-consuming, and difficult to replicate. Automating the deployment process reduces human error, accelerates deployment timelines, and facilitates seamless integration of models into production environments.
Here are some key considerations for automating the deployment process of machine learning models:
Infrastructure Provisioning: Automate the provisioning of the required infrastructure to support the deployment of machine learning models. Infrastructure provisioning automation can involve utilizing infrastructure-as-code tools, such as Terraform or AWS CloudFormation, to define and manage the infrastructure resources needed for the deployment. This ensures consistent and reproducible infrastructure setup for each deployment.
Continuous Integration and Delivery (CI/CD): Implement CI/CD pipelines to automate the integration, testing, and deployment of machine learning models. CI/CD pipelines allow for automation of model training and evaluation steps, ensuring that the models are regularly updated and deployed. Automating the processes for building, testing, and deploying models as part of the CI/CD pipeline increases efficiency and reduces the time from development to deployment.
Version Control and Collaboration: Integrate version control systems, such as Git, into the deployment process to manage model versions, code, and configurations. Version control enables collaboration among team members, streamlines code reviews, facilitates reproducibility, and simplifies rollback to previous versions if necessary. Leveraging branching strategies and pull requests supports parallel development and ensures that updates are managed efficiently.
Containerization: Containerize the machine learning models using tools like Docker or Kubernetes to package the models, dependencies, and configurations into portable containers. Containerization provides several benefits, including easy deployment across different environments, isolation of dependencies, and the ability to manage resources efficiently. Containerization makes it easier to replicate and deploy models consistently, irrespective of the underlying infrastructure.
Deployment Orchestration: Use deployment orchestration tools and frameworks, such as Kubernetes, to automate the deployment and management of containerized machine learning models. These tools enable efficient scaling, load balancing, and fault tolerance, ensuring high availability and reliability of the deployed models. Orchestration simplifies the management of complex deployments and allows for seamless scaling as demand increases.
Testing and Validation: Automate testing and validation procedures to ensure the accuracy and reliability of the deployed models. This can involve the integration of automated unit tests, integration tests, and model validation steps into the deployment pipeline. Automated testing ensures that the deployed models meet the required performance metrics and functional expectations before being released to end-users.
Monitoring and Alerting: Implement automated monitoring and alerting systems to track the performance and health of deployed models. This involves setting up monitoring metrics, logs, and dashboards to collect real-time data and evaluate the performance of models in production. Alerting systems can be configured to trigger notifications when performance metrics deviate from expected values or when anomalies occur.
By automating the deployment process, organizations can experience numerous benefits. Automation minimizes human error, accelerates deployment timelines, ensures consistency, improves reproducibility, and provides a solid foundation for scalable and efficient deployment of machine learning models. Adopting automation practices facilitates collaboration, agility, and reliability, enabling organizations to effectively deploy and maintain their deployed models in real-world applications.
Implement Version Control
Implementing version control is a critical practice in machine learning deployment to effectively manage the different versions of models, code, configurations, and dependencies. Version control ensures traceability, collaboration, reproducibility, and maintains a clear record of changes made during the deployment process.
Here are some key considerations for implementing version control in machine learning deployment:
Track Model Versions: Version control allows for tracking different versions of machine learning models. This involves saving snapshots of models at different stages, including major milestones, modifications, or improvements. When modifications are made, like changes to the model architecture or new hyperparameter settings, a new version is created and associated with the specific features or datasets.
Code and Configuration Versioning: Version control is not limited to models; it extends to tracking the code used to train and deploy the models. Versioning the codebase, preprocessing scripts, configuration files, and any other code associated with the model’s pipeline enables full reproducibility. This ensures that all components required to reproduce the model’s behavior are properly controlled and managed.
Dependency and Library Management: Machine learning models rely on various libraries, frameworks, and dependencies. It is crucial to keep track of the specific versions used during model development and deployment. Maintaining a well-documented list of dependencies facilitates reproducibility and ensures that the models can be retrained or redeployed in the future, even as libraries and dependencies evolve.
Collaboration Facilitation: Version control enables collaboration among team members working on the deployment process. It allows multiple developers, data scientists, and engineers to work in parallel on different branches, experiment with different techniques or optimizations, and merge their contributions. Version control systems and features, such as branching and pull requests, make collaboration more efficient and streamline the integration of changes.
Reproducibility and Auditability: Version control ensures the reproducibility and auditability of the deployment process. By explicitly tracking all code, configurations, and dependencies used during model training and deployment, it becomes possible to recreate the exact environment and conditions for training and predicting with the model. This is crucial for maintaining consistency and facilitating model evaluation, validation, and auditing.
Documentation and Change History: Version control serves as documentation for the deployment process. It provides a history of changes made to the models, code, configurations, and dependencies. Each commit provides an audit trail that can be useful for future reference and understanding the evolution of the deployment process. Proper documentation of version history assists in maintaining a clear and comprehensive record of the model’s development and deployment.
Implementing version control practices ensures that the different versions of machine learning models, code, configurations, and dependencies are properly managed. It facilitates collaboration, reproducibility, traceability, and documentation in the deployment process. By adopting version control, organizations can effectively manage changes, enable seamless collaboration, and guarantee the replicability and reliability of deployed models.
Set Up Monitoring and Maintenance Procedures
Setting up monitoring and maintenance procedures is crucial for ensuring the ongoing performance, reliability, and accuracy of deployed machine learning models. Continuous monitoring allows organizations to track the models’ performance in real-world scenarios, while maintenance procedures ensure that the models remain effective and up-to-date over time.
Here are some key considerations when setting up monitoring and maintenance procedures for deployed machine learning models:
Monitoring Performance Metrics: Determine the key performance metrics to monitor the deployed models. This could include accuracy, precision, recall, F1 score, or other metrics relevant to the specific problem domain. Monitor these metrics on a regular basis to identify any deviations or anomalies that may affect the performance of the models.
Real-Time Monitoring: Implement real-time monitoring mechanisms to track the performance of deployed models in production environments. This could involve setting up monitoring dashboards, alerts, or logging systems to collect and analyze real-time data on model inputs, outputs, and predictions. Real-time monitoring enables organizations to proactively detect and address any issues or anomalies promptly.
Anomaly Detection: Implement anomaly detection techniques to identify any unusual or unexpected behavior in the deployed models. This involves comparing the models’ predictions or task outputs with expected results and setting up thresholds or algorithms to detect deviations. Anomaly detection helps in quickly identifying performance degradation, data quality issues, or other anomalies that require attention and resolution.
Data Quality Monitoring: Monitor the quality of the data used for model input. Establish data quality checks to identify missing values, outliers, or inconsistencies in the data. By monitoring data quality, organizations can ensure that the deployed models are receiving reliable and accurate inputs, which is essential for maintaining the overall performance and accuracy of the models.
Regular Maintenance: Establish regular maintenance procedures to keep the deployed models up-to-date and effective. This could involve periodic updates to the models based on new data, improving model performance through hyperparameter tuning or architecture modifications, or addressing bug fixes. Regular maintenance ensures that the deployed models continue to perform optimally in changing environments.
Retraining on New Data: Regularly retrain the deployed models on new data to adapt to evolving patterns and ensure ongoing accuracy. This may involve incorporating new labeled data or updating the training pipeline to include more recent data sources. By retraining the models, organizations can ensure that they remain aligned with the changing dynamics of the problem being addressed.
Version Control and Documentation: Employ version control practices to manage changes made to the deployed models, code, configurations, and dependencies. This includes documenting and tracking each update, improvement, or bug fix. Proper version control and documentation facilitate traceability and reproducibility in maintenance processes and allow for seamless collaboration among team members.
Continuous Evaluation: Continuously evaluate the performance and impact of the deployed models. Regularly analyze the effectiveness, predictive accuracy, and alignment with desired business outcomes. Collect feedback from end-users and stakeholders to identify areas for improvement or additional features. Continuous evaluation ensures that the deployed models remain relevant and continue to deliver value over time.
By setting up robust monitoring and maintenance procedures, organizations can ensure the ongoing performance, reliability, and accuracy of their deployed machine learning models. Monitoring allows for early detection and resolution of issues, while maintenance ensures that the models remain effective and up-to-date. With proper monitoring and maintenance, organizations can maximize the value derived from the deployed models in real-world applications.
Conclusion
Deployment is a critical step in the machine learning process, as it allows organizations to put their trained models into practical use and achieve tangible results. Through deployment, organizations can leverage the power of machine learning to drive better decision-making, automate tasks, and solve complex problems in various domains.
In this article, we explored the importance of deployment in machine learning and discussed the steps involved in the deployment process. We highlighted the significance of data preprocessing, model selection and training, model evaluation, and the ultimate deployment of models in real-world applications. We also examined the challenges organizations may face during deployment, such as scalability, infrastructure management, version control, and monitoring and maintenance.
Furthermore, we discussed best practices for successful deployment, including planning for scalability, automating the deployment process, implementing version control, setting up monitoring and maintenance procedures, considering security and privacy, documenting the deployment process, and continuously evaluating and improving the deployed models.
By adopting these best practices and addressing the challenges associated with deployment, organizations can ensure the seamless integration and effective utilization of machine learning models. Proper deployment enables organizations to drive informed decision-making, automate tasks to improve efficiency, and gain a competitive edge in their respective industries.
Machine learning deployment is an ongoing process that requires continuous monitoring, maintenance, and adaptation to changing data patterns and requirements. Organizations should strive to establish robust monitoring mechanisms, set up regular maintenance procedures, and implement version control and documentation practices.
In conclusion, successful deployment of machine learning models enables organizations to unlock the true value of their data. With careful planning, automation, monitoring, and maintenance, deployed models can deliver accurate predictions, automate tasks, and drive significant business impact, ultimately leading to improved operational efficiency and better decision-making in a wide range of applications.