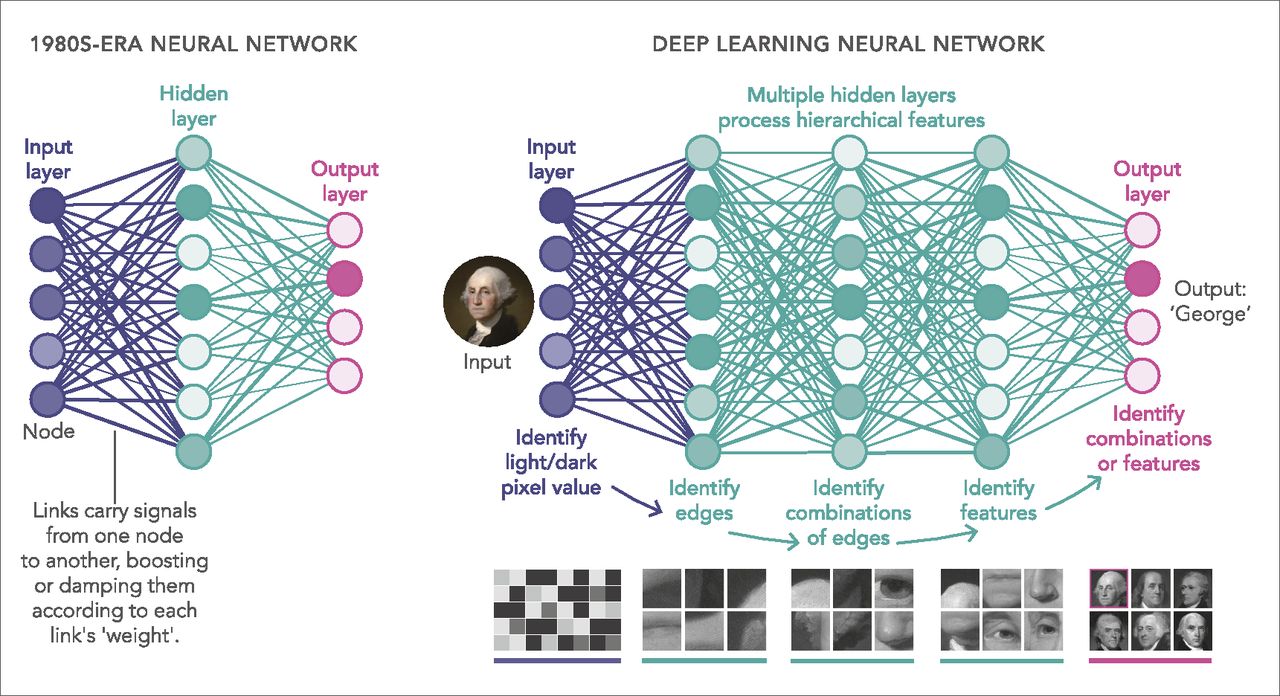
Introduction
Adversarial machine learning is a rapidly evolving field that poses significant challenges to the security and integrity of machine learning models. As machine learning algorithms become more prevalent in various applications, such as autonomous vehicles, facial recognition systems, and fraud detection, they are also susceptible to attacks that can manipulate their behavior or exploit vulnerabilities.
Adversarial machine learning is concerned with understanding and mitigating these attacks to improve the robustness and reliability of these models. In this article, we will explore the concept of adversarial machine learning, the different types of attacks, and the techniques used to defend against them.
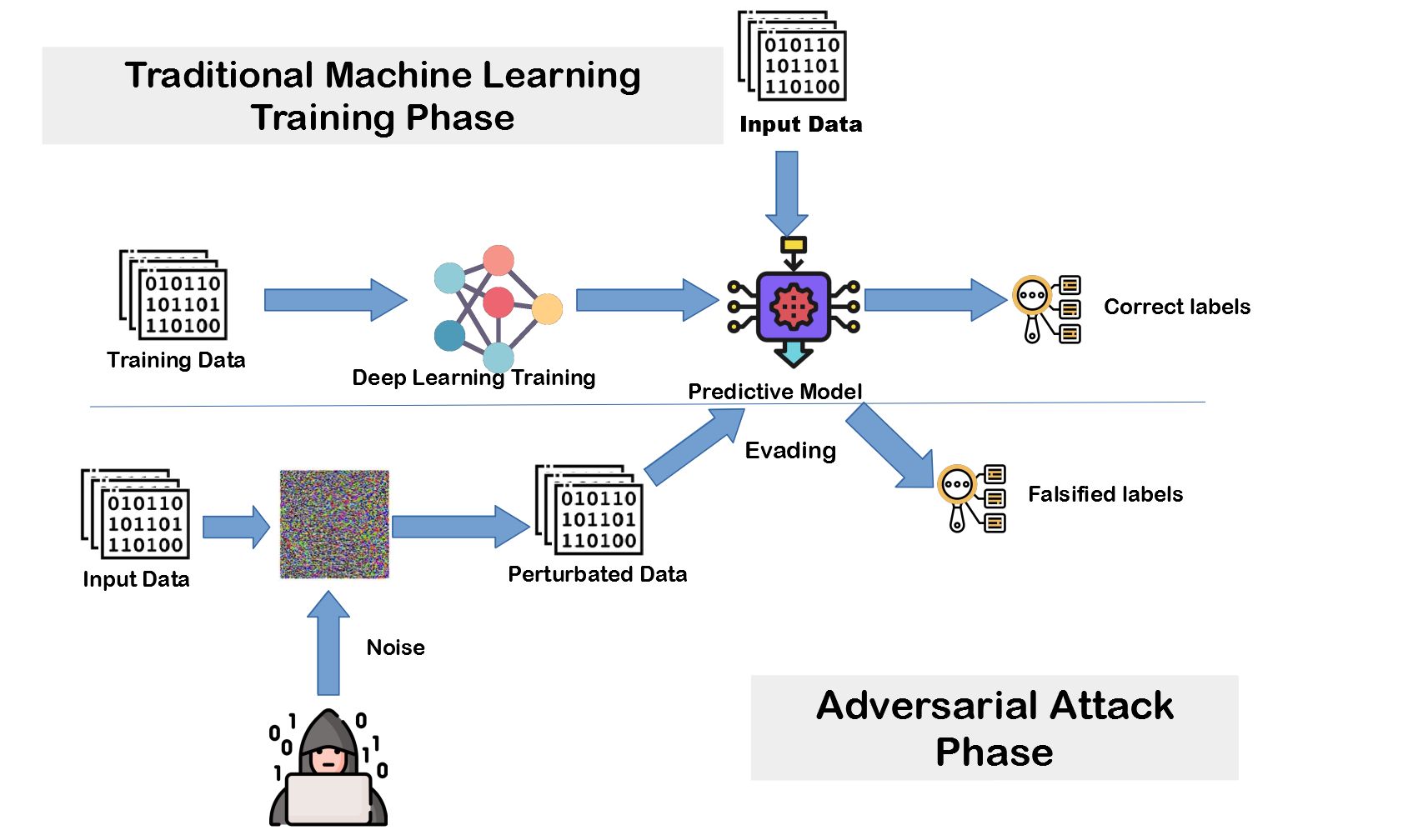
Adversarial attacks in machine learning involve introducing carefully crafted inputs, known as adversarial examples, to deceive or manipulate the model’s predictions. These inputs are designed to exploit vulnerabilities in the model’s decision-making process, often resulting in incorrect predictions or misclassification.
The consequences of successful adversarial attacks can be severe. For instance, in the context of autonomous vehicles, an attacker could introduce adversarial inputs that make the vehicle misclassify a stop sign as a speed limit sign, leading to potentially dangerous situations. Similarly, in the context of facial recognition systems, an attacker could manipulate an image to fool the system into misidentifying individuals.
To mitigate these attacks, researchers have developed various techniques known as adversarial training. Adversarial training involves augmenting the training process with adversarial examples to improve the model’s resilience to such attacks. These techniques seek to make the model more robust by exposing it to potential adversarial inputs during training, enabling it to learn to recognize and reject them.
While adversarial training techniques have proven effective to some extent, the problem of adversarial attacks in machine learning is far from being solved. The cat-and-mouse game between attackers and defenders continues, with attackers constantly finding new ways to undermine and exploit machine learning models, requiring researchers and practitioners to develop more sophisticated defense mechanisms.
In this article, we will explore the different types of adversarial attacks, including evasion attacks and poisoning attacks, and the implications they have on the security and trustworthiness of machine learning models. We will also delve into the current research and future directions of adversarial machine learning, highlighting the ongoing efforts to develop more robust defense techniques and the challenges that lie ahead.
Understanding adversarial machine learning and the associated techniques for defending against attacks is crucial in today’s digital landscape where machine learning models play an increasingly critical role. By shedding light on this fascinating field, we hope to raise awareness about the vulnerabilities of machine learning models and ultimately contribute to the development of more secure and reliable systems.
What is Adversarial Machine Learning?
Adversarial machine learning is a subfield of machine learning that deals with understanding and countering attacks on machine learning models. It explores the vulnerabilities and exploits in these models by taking into account the adversarial nature of potential attackers.
In traditional machine learning, the assumption is that the training and test data are drawn from the same distribution. However, in adversarial machine learning, this assumption is challenged by adversaries who aim to manipulate the model’s behavior by injecting carefully crafted inputs, called adversarial examples.
Adversarial examples are specifically designed to deceive or mislead the machine learning model into making incorrect predictions. These examples can be as subtle as adding imperceptible perturbations to an image to make an object unrecognizable to the model, or as impactful as altering the features of an input to trick the model into misclassifying it.
The main goal of adversarial machine learning is to study and develop techniques that can make machine learning models more robust and secure in the face of such attacks. This involves analyzing the vulnerabilities of the models, understanding the adversarial strategies employed by attackers, and developing effective defense mechanisms.
Adversarial machine learning is not limited to specific domains or types of machine learning models. It can be applied to various areas, including computer vision, natural language processing, voice recognition, and more. The insights gained from studying adversarial attacks in one domain can often be transferred to another domain to improve the robustness of machine learning models across different applications.
One of the key challenges in adversarial machine learning is the trade-off between model accuracy and robustness. A model that is highly accurate in normal circumstances may be highly susceptible to adversarial attacks. Balancing these two objectives requires striking a delicate equilibrium by employing defenses that can tolerate some level of adversarial perturbations without sacrificing overall model performance.
Researchers in adversarial machine learning have developed various techniques to tackle these challenges. Adversarial training, for example, involves augmenting the training process with adversarial examples to expose the model to potential attack scenarios during training, enhancing its ability to recognize and reject adversarial inputs. Other techniques include defensive distillation, which introduces an extra layer of protection by making it harder for an attacker to understand the inner workings of the model.
Overall, adversarial machine learning is a crucial field for ensuring the reliability and security of machine learning models. By continuously analyzing and refining our defense mechanisms against such attacks, we can contribute to a more trustworthy and resilient machine learning ecosystem.
Types of Adversarial Attacks in Machine Learning
Adversarial attacks in machine learning come in various forms, exploiting different weaknesses and vulnerabilities in the models. By understanding the different types of attacks, we can better appreciate the diversity and complexity of the adversarial landscape.
1. Evasion Attacks: Evasion attacks, also known as perturbation attacks, aim to manipulate the model’s behavior by introducing perturbations into the input data. These perturbations are carefully crafted to “fool” the model without significantly altering the input’s perceptual or semantic meaning. Evasion attacks are particularly challenging because the adversarial examples need to be resilient to scrutiny by both humans and the model itself.
2. Poisoning Attacks: In poisoning attacks, the attacker manipulates the training data used to train the machine learning model. By injecting malicious samples or modifying existing samples in the training set, the attacker aims to compromise the training process and bias the model’s learned decision boundaries. Poisoning attacks can be highly effective, as even a small number of manipulations in the training data can have a significant impact on the model’s behavior.
3. Model Inversion Attacks: Model inversion attacks focus on compromising the privacy of the training data rather than manipulating the model’s predictions. By exploiting information leakage in the model’s output, an attacker can reverse-engineer parts of the training data used to train the model, potentially exposing sensitive information or breaching privacy concerns.
4. Model Stealing Attacks: Model stealing attacks involve extracting or replicating a target model by querying it and creating a surrogate model based on the obtained information. The attacker can then use the surrogate model for various malevolent purposes, such as reverse-engineering proprietary models or exploiting vulnerabilities in the stolen model.
5. Black Box Attacks: Black box attacks occur when the attacker has limited or no access to the inner workings of the model. In these scenarios, the attacker can only query the model for predictions and has to rely on various techniques, such as genetic algorithms or reinforcement learning, to generate adversarial examples. Black box attacks pose a significant challenge as the attacker must make the most of limited information about the model’s behavior.
6. Physical Attacks: Physical attacks involve manipulating the physical properties of the input data to deceive the machine learning model. For example, an attacker can place stickers on an object to mislead an image recognition system or alter the acoustic properties of a sound to deceive a voice recognition system. Physical attacks pose practical threats in real-world scenarios where adversaries have physical access to the input data.
Understanding these types of adversarial attacks is essential to develop effective defense mechanisms and improve the security and reliability of machine learning models. By analyzing the different attack vectors, researchers can design robust models that are more resilient against known attacks and anticipate potential future threats.
Adversarial Examples and Their Implications
Adversarial examples are carefully crafted inputs that aim to deceive or manipulate machine learning models. These examples exploit vulnerabilities in the model’s decision-making process, leading to incorrect predictions or misclassifications. Adversarial examples have significant implications for the security, trustworthiness, and widespread adoption of machine learning models.
Adversarial examples often arise from imperceptible perturbations in the input data. These perturbations can be as subtle as introducing small alterations to an image or modifying a few words in a sentence. Despite being almost indistinguishable to human perception, these minor changes can lead to significant differences in the model’s output, causing it to make erroneous predictions.
The implications of adversarial examples are far-reaching. From autonomous vehicles to medical diagnosis systems, the impact of misclassification can be catastrophic. For example, an attacker manipulating a stop sign to appear as a speed limit sign could potentially lead to accidents, endangering lives. In the healthcare domain, adversarial attacks on medical image classification models could result in incorrect diagnoses or inappropriate treatments.
Adversarial examples also raise concerns about the transparency and interpretability of machine learning models. As these examples exploit subtle weaknesses, it becomes challenging to understand and explain why the model made a particular prediction. The lack of interpretability not only hampers trust in the model’s decisions but also makes it difficult to detect and mitigate potential adversarial attacks.
Another implication of adversarial examples is the potential for privacy breaches. Adversarial attacks can be used to infer sensitive information about individuals by perturbing inputs and observing the model’s responses. This raises privacy concerns, especially in applications such as voice recognition systems or facial recognition technology, where personal data is involved.
Furthermore, adversarial examples can undermine the deployment and adoption of machine learning models in safety-critical systems. Industries such as aviation, defense, and finance have strict regulations and high stakes, and the presence of vulnerabilities to adversarial attacks can significantly impede the integration of machine learning models into these domains.
Addressing the implications of adversarial examples requires a multi-faceted approach. Developing robust models that are resilient to adversarial attacks is essential. Techniques like adversarial training, defensive distillation, and model regularization can help improve the model’s robustness by considering adversary-induced perturbations during training.
Additionally, investing in research and development of explainable AI and interpretability methods will enable better understanding and detection of adversarial attacks. By shedding light on the decision-making process of the model, researchers can identify vulnerabilities and develop more effective defense mechanisms.
Ultimately, mitigating the implications of adversarial examples requires collaboration between researchers, practitioners, and policymakers. The continued exploration of adversarial machine learning and the development of robust defense strategies are critical to ensure the security, trustworthiness, and widespread adoption of machine learning models in various domains.
Adversarial Training Techniques
Adversarial training is a key technique used to improve the robustness of machine learning models against adversarial attacks. It involves augmenting the training process with adversarial examples, exposing the model to potential attack scenarios during training and enhancing its ability to recognize and reject adversarial inputs.
The basic idea behind adversarial training is to generate adversarial examples by perturbing the training data. These perturbations are carefully calculated to maximize the model’s loss and force it to learn to be more robust against similar attacks. The adversarial examples, along with the original training data, are then used to retrain the model.
There are different variations of adversarial training techniques, each with its own unique approach to generating adversarial examples and training the model:
1. Fast Gradient Sign Method (FGSM): The FGSM is one of the simplest and widely used adversarial training techniques. It involves taking the sign of the gradient of the model’s loss function with respect to the input data and perturbing the input based on that sign. By iteratively applying this perturbation, the model is exposed to a range of adversarial inputs during training.
2. Projected Gradient Descent (PGD): PGD is an iterative optimization-based method that generates adversarial examples by taking multiple small steps in the direction that maximizes the model’s loss. At each step, the adversarial input is projected back onto a feasible region to ensure it remains close to the original input. The iterative nature of PGD helps in finding stronger adversarial examples that are harder for the model to defend against.
3. Defensive Distillation: Defensive distillation is a technique that involves training a “teacher” model on the regular training data and using the teacher’s soft predictions as labels to train a “student” model. The student model is trained on a distilled version of the soft predictions, making it more resistant to adversarial attacks. Defensive distillation introduces an extra layer of protection by obfuscating the decision boundaries of the model and making it harder for an attacker to understand the inner workings of the model.
4. Robust Optimization: Robust optimization approaches formulate the training process as a min-max problem, where the model’s parameters are optimized to minimize the loss for adversarial examples while considering a worst-case perturbation within a specified magnitude. This formulation aims to find a model that performs well not only on the regular training data but also under adversarial perturbations.
Adversarial training techniques have demonstrated promising results in improving the robustness of machine learning models against adversarial attacks. However, they are not without limitations. Adversarial training can increase the model’s robustness against known attacks, but it may not generalize well to unseen or more sophisticated attacks. Additionally, adversarial training can come at the cost of decreased accuracy on the regular test data, as the model learns to reject even benign inputs that exhibit characteristics similar to adversarial examples.
Despite these limitations, adversarial training remains a valuable and active area of research in defending against adversarial attacks. Combining adversarial training with other defense mechanisms, such as input preprocessing techniques and anomaly detection, can further enhance the model’s resilience to attacks and promote the development of more secure and trustworthy machine learning systems.
Defending Against Adversarial Attacks
Defending against adversarial attacks is crucial for ensuring the security and reliability of machine learning models. While no defense mechanism can provide absolute protection against all possible attacks, researchers and practitioners have developed various strategies to improve the resilience of models against adversarial attacks.
1. Adversarial Training: As discussed earlier, adversarial training involves augmenting the training process with adversarial examples, allowing the model to learn to recognize and reject such inputs. Adversarial training helps improve the model’s robustness against known attacks and can serve as a fundamental defense mechanism.
2. Input Preprocessing Techniques: Preprocessing techniques can be used to alter the input data in ways that make it more difficult for adversaries to craft effective adversarial examples. This can include techniques such as randomization, adding noise to the inputs, or using denoising filters to remove potential adversarial perturbations. Input preprocessing techniques can add an additional layer of defense by making the model less sensitive to small perturbations and reducing the effectiveness of evasion attacks.
3. Ensemble Methods: Ensemble methods involve training multiple models and combining their predictions. By leveraging the diversity of the models and considering a consensus among them, ensemble methods can make it harder for attackers to craft adversarial examples that fool all models simultaneously.
4. Certified Defenses: Certified defenses aim to provide formal guarantees of a model’s robustness against adversarial attacks. These defenses use mathematical techniques, such as interval analysis or optimization-based methods, to evaluate the worst-case adversarial perturbations that the model can withstand under certain constraints. Certified defenses can provide stronger guarantees compared to empirical defenses but often come with higher computational costs.
5. Architecture Modifications: Modifying the architecture of the machine learning model can make it more resilient to adversarial attacks. For example, incorporating skip connections or using attention mechanisms can enhance the model’s ability to distinguish between important features and potential adversarial perturbations. Additionally, employing techniques like adversarial logit pairing or label smoothing can further improve the model’s ability to generalize and defend against certain attacks.
6. Adversarial Detection: Adversarial detection techniques aim to identify whether an input is benign or adversarial. These techniques use certain properties of adversarial examples, such as their high-confidence predictions or their distinct statistical features, to distinguish them from normal inputs. Adversarial detection can be used to flag potential attacks and trigger additional defense mechanisms or provide warnings for further investigation.
It is important to note that no single defense mechanism can provide a foolproof solution against all possible adversarial attacks. Adversarial attacks are continually evolving, and researchers and attackers engage in a constant cat-and-mouse game. Therefore, a combination of multiple defense techniques, used in conjunction with regular updates and continuous monitoring, is recommended to improve the overall resilience of machine learning models.
The field of defending against adversarial attacks is still an active area of research, with ongoing efforts to develop more robust and effective defense mechanisms. By sharing knowledge, encouraging collaboration, and fostering interdisciplinary approaches, researchers and practitioners can collectively work towards building more secure and trustworthy machine learning systems.
Current Research and Future Directions
The field of adversarial machine learning is continuously evolving, with ongoing research efforts to improve the security and robustness of machine learning models. Here, we discuss some current research trends and future directions in this field.
1. Adversarial Example Generation Techniques: Researchers are exploring novel techniques for generating adversarial examples that are more effective and diverse. This includes generative models, reinforcement learning-based approaches, and genetic algorithms. By continuously enhancing our ability to generate sophisticated adversarial examples, we can better understand the vulnerabilities of machine learning models and develop more robust defense strategies.
2. Transferability and Generalization of Attacks: Understanding the transferability of adversarial attacks across different models, domains, and modalities is an active area of research. Researchers are exploring the extent to which adversarial examples can generalize and fool multiple models, expanding the scope of potential attacks. By studying the transferability of attacks, we can develop more comprehensive defense techniques that are robust across a wider range of scenarios.
3. Robustness Verification: Developing techniques to rigorously verify the robustness of machine learning models against adversarial attacks is an important area of research. Formal verification methods are being explored to provide guarantees that a model is robust within certain bounds, enabling certified defenses. Robustness verification can help build more trust in machine learning systems, especially in safety-critical applications.
4. Explainability and Interpretability: Enhancing the interpretability and explainability of machine learning models is crucial for detecting and understanding adversarial attacks. Researchers are developing techniques to provide better insights into the decision-making process of models, aiding in the detection and mitigation of adversarial examples. Explainable AI can also help in building user trust and understanding the limitations of machine learning models.
5. Adversarial Defense Benchmarks: The development of standardized benchmarks and evaluation metrics for adversarial defense techniques is gaining attention. These benchmarks can help compare the effectiveness of different defense methods on a level playing field and drive further advancements in the field. It can also facilitate collaboration among researchers and practitioners in the development and evaluation of robust defense mechanisms.
6. Adversarial Attacks Beyond Classification: While most research has focused on adversarial attacks and defenses in the context of classification tasks, there is increasing interest in exploring adversarial attacks in other domains, such as reinforcement learning, object detection, and natural language processing. Understanding and addressing adversarial vulnerabilities in a broader range of machine learning tasks is becoming more important as these models continue to be integrated into various applications.
As the field of adversarial machine learning progresses, interdisciplinary collaborations between researchers in machine learning, security, and cognitive sciences will be crucial. Combining expertise from these domains can lead to more comprehensive and effective defense strategies against adversarial attacks.
While the battle between attackers and defenders will likely continue, the goal remains to develop robust and secure machine learning models that can withstand adversarial attempts. By adopting a proactive and interdisciplinary approach, we can pave the way for more trustworthy and resilient machine learning systems in the future.
Conclusion
Adversarial machine learning poses significant challenges to the security and reliability of machine learning models. Adversarial attacks continue to evolve, exploiting vulnerabilities in models and raising concerns about the trustworthiness and robustness of these systems. Despite these challenges, researchers and practitioners are actively developing defense mechanisms to improve the resilience of machine learning models against adversarial attacks.
In this article, we explored various aspects of adversarial machine learning, including the different types of attacks, the implications of adversarial examples, and the defense techniques employed to mitigate these attacks. Adversarial training techniques, input preprocessing, ensemble methods, and architecture modifications are among the strategies used to enhance the robustness of models. Additionally, ongoing research focuses on adversarial example generation, verification of model robustness, and improving interpretability and explainability.
It is important to recognize that there is no foolproof solution to defend against adversarial attacks. Adversarial attacks continually evolve, and the development of sophisticated attack strategies requires robust and adaptive defense mechanisms. Therefore, it is crucial to stay abreast of the latest research developments, collaborate across disciplines, and adopt a proactive approach in enhancing the security and reliability of machine learning models.
Ensuring the trustworthiness of machine learning models is not only important for industries and organizations but also for society as a whole. The integration of machine learning models in critical applications, such as healthcare, autonomous vehicles, and financial systems, necessitates the development of robust defense techniques to protect against potential adversarial attacks.
Looking ahead, the field of adversarial machine learning will continue to evolve. Ongoing research efforts will focus on exploring new attack strategies, improving defense mechanisms, developing formal verification methods, and enhancing model interpretability. Collaboration among researchers, practitioners, and policymakers will be crucial to tackle the challenges posed by adversarial machine learning and ensure the development of more secure and trustworthy machine learning systems.
By understanding and addressing the vulnerabilities of machine learning models, we can pave the way for the responsible and safe deployment of these technologies. Adversarial machine learning remains a dynamic and exciting field, ripe with opportunities for innovation and advancements. Through continuous research, collaboration, and vigilance, we can strengthen the security and resilience of machine learning models and foster public trust in these transformative technologies.