Introduction
Machine learning is a rapidly evolving field that has revolutionized several industries. One of the key techniques used in machine learning is the decision tree algorithm. Decision trees are powerful tools for making predictions and solving complex problems by dividing data into smaller and more manageable subsets. Understanding decision tree machine learning can provide valuable insights for both data scientists and business professionals.
In this article, we will explore the concepts of machine learning and decision trees. We will delve into how decision trees work, the advantages and disadvantages of using them, different types of decision tree algorithms, and how to build and evaluate a decision tree model. Additionally, we will uncover various applications of decision tree machine learning across different domains.
The field of machine learning focuses on developing algorithms that can learn and make predictions or decisions without being explicitly programmed. It involves training a model with a large dataset to identify patterns and make accurate predictions or decisions based on previously unseen data. Machine learning has applications in various sectors such as finance, healthcare, marketing, and cybersecurity, where it can provide valuable insights and enable more efficient decision-making processes.
The decision tree algorithm is a popular and intuitive approach within machine learning. It is a flowchart-like structure where each internal node represents a feature or attribute, each branch represents a decision rule, and each leaf node represents an outcome or prediction. Decision trees are constructed using the training data and can be used for both classification and regression tasks.
By understanding how decision trees work and the various techniques used in building and evaluating them, data scientists can improve the accuracy of their predictions and gain a deeper understanding of the underlying patterns within their data. Business professionals can also benefit from decision tree machine learning by utilizing it in tasks such as customer segmentation, risk assessment, and demand forecasting.
In the next sections, we will dive deeper into the intricacies of decision trees, explore the advantages and disadvantages of using them, and discuss different types of decision tree algorithms. So, let’s begin our journey into the fascinating world of decision tree machine learning.
What is Machine Learning?
Machine learning is a subfield of artificial intelligence that focuses on developing algorithms and models that can learn from data and make predictions or decisions automatically, without being explicitly programmed. It is based on the idea of teaching machines to learn from experience and improve their performance over time.
At its core, machine learning relies on statistical techniques and computational models to analyze and interpret large datasets, extract meaningful patterns and insights, and develop predictive models. These models can then be used to make accurate predictions or decisions on new, unseen data.
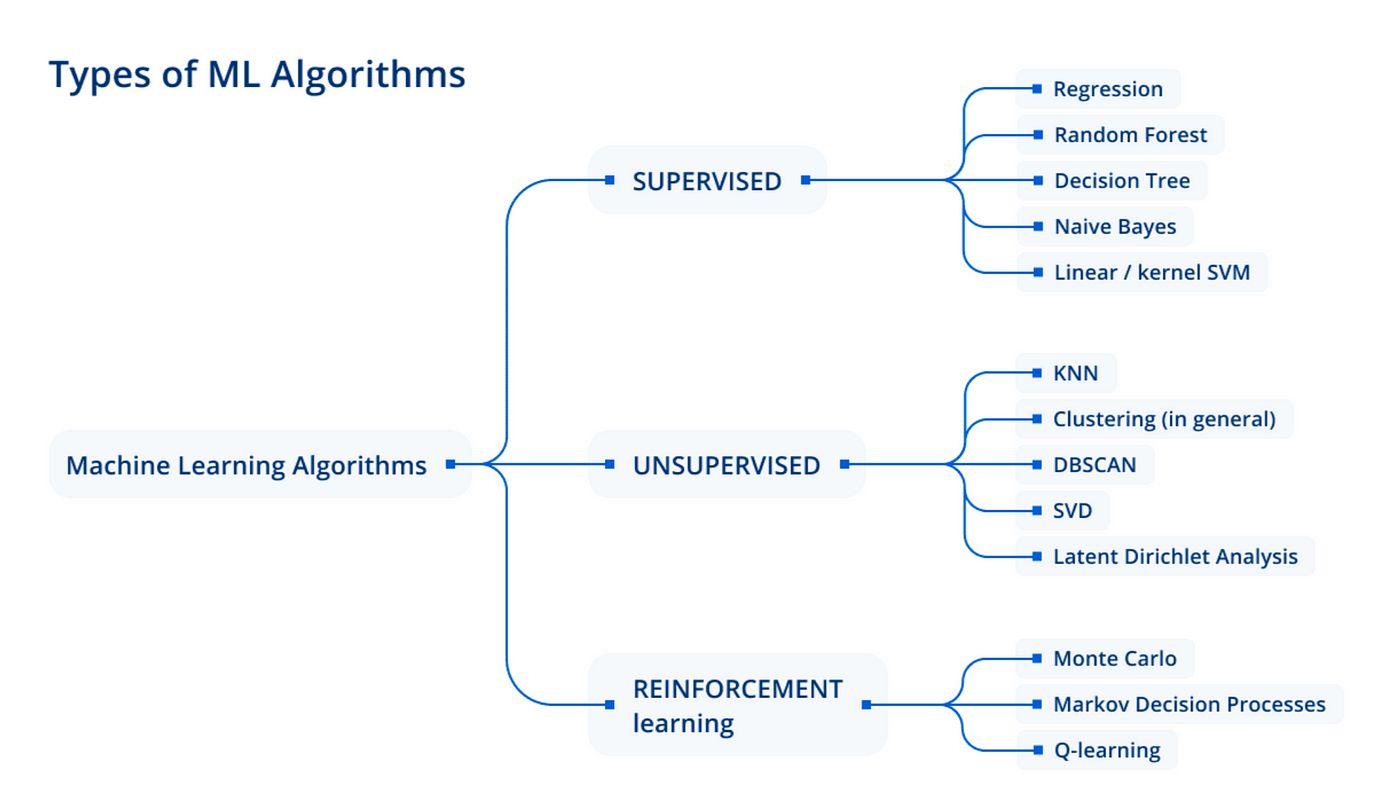
There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the model is trained on labeled data, meaning the input data is accompanied by the correct output or target variable. The goal is to learn a mapping from the input variables to the output variable. This type of learning is commonly used for tasks such as classification and regression.
Unsupervised learning, on the other hand, involves training the model on unlabeled data, where no specific output or target variable is provided. The goal is to uncover hidden patterns or structures in the data without any prior knowledge. Clustering and dimensionality reduction are common examples of unsupervised learning.
Reinforcement learning is a type of learning where an agent learns to interact with an environment and maximize its rewards through trial and error. The agent receives feedback in the form of rewards or punishments based on its actions, and it continuously adjusts its behavior to achieve optimal performance.
Machine learning has numerous applications across various industries. In healthcare, it can be used for disease diagnosis, drug discovery, and personalized medicine. In finance, it can aid in fraud detection, algorithmic trading, and credit risk assessment. In marketing, it can help in customer segmentation, recommendation systems, and campaign optimization. The possibilities are vast, and machine learning continues to advance and drive innovation in many fields.
In the next section, we will explore the concept of decision trees, which are a powerful technique used in machine learning to make predictions and solve complex problems.
What is a Decision Tree?
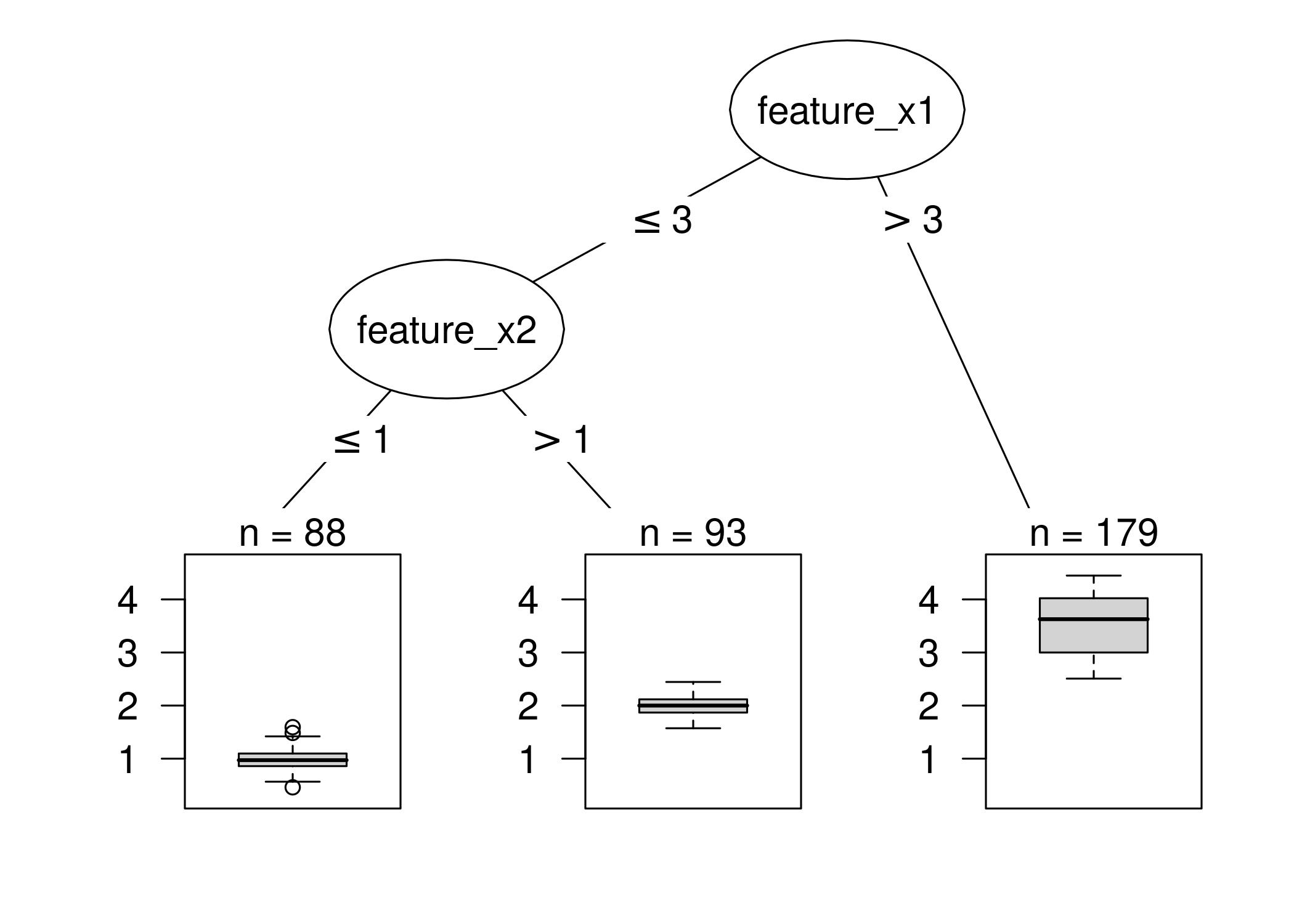
A decision tree is a supervised machine learning algorithm that uses a tree-like structure to model decisions and their potential consequences. It is a flowchart-like structure where each internal node represents a feature or attribute, each branch represents a decision rule, and each leaf node represents an outcome or prediction.
The decision tree algorithm is based on the concept of recursive partitioning, which involves splitting the data into smaller and more manageable subsets based on different attributes or features. These splits are made at each internal node of the tree until a stopping criterion is met. The stopping criterion could be a maximum tree depth, a minimum number of samples per leaf node, or other user-defined conditions.
Decision trees are versatile and can be used for both classification and regression tasks. In classification, the goal is to assign a class or label to a given input based on the features or attributes. The decision tree algorithm creates a set of rules that divide the data into different classes or categories. In regression, on the other hand, the decision tree predicts a continuous value as the output variable.
The construction of a decision tree involves selecting the most informative features to make optimal splits at each internal node. Different algorithms use various criteria to measure the quality of these splits, such as information gain, Gini impurity, or reduction in variance. By making the best possible splits, decision trees can effectively separate the data and produce accurate predictions.
Decision trees are often preferred over other machine learning algorithms due to their interpretability and simplicity. The resulting tree structure is easy to understand and visualize, making it an excellent tool for both technical and non-technical stakeholders. Decision trees can uncover complex relationships between variables and provide insights into the decision-making process.
However, decision trees are prone to overfitting, especially when the tree becomes too deep or complex. Overfitting occurs when the model learns the training data too well and fails to generalize well to unseen data. To mitigate this, techniques such as pruning, setting appropriate stopping criteria, or using ensemble methods like random forests are employed.
In the next section, we will explore how decision trees work and the process of making decisions using a decision tree algorithm. We will unravel the inner workings of this powerful machine learning technique.
How Does a Decision Tree Work?
A decision tree works by recursively partitioning the data based on features or attributes to make decisions and predictions. The algorithm starts with the entire dataset and selects the most informative feature to create the root node of the tree. It then splits the data into subsets based on different attribute values. This process continues until a stopping criterion is met, resulting in a tree-like structure where each leaf node represents an outcome or prediction.
The selection of the most informative feature at each internal node is crucial in decision tree construction. Various criteria can be used to measure the quality of a split, such as information gain, Gini impurity, or reduction in variance. The goal is to find the feature that helps the tree make the most accurate predictions.
Once the tree is constructed, making predictions using a decision tree involves traversing the tree from the root node to a leaf node. At each internal node, the algorithm evaluates the attribute value of the data point and follows the corresponding branch based on the decision rule. The process continues until a leaf node is reached, which represents the final prediction or outcome.
For example, let’s consider a decision tree for classifying emails into spam or non-spam. The root node might use the feature “number of suspicious words” and split the data into two subsets: emails with a high number of suspicious words and emails with a low number of suspicious words. Each subset is further split based on different attributes until the final predictions are made at the leaf nodes.
Decision trees can handle both categorical and numerical features. For categorical features, each possible value of the feature forms a different branch in the tree. For numerical features, the algorithm determines an optimal threshold to split the data.
Decision trees are interpretable and allow us to gain insights into the decision-making process. We can trace the path from the root node to a leaf node to understand the criteria and rules used to make a particular prediction. Decision trees are also robust to missing values in the dataset, as they can handle missing values by assigning them to the most probable branch based on the available information.
However, decision trees are prone to overfitting if they become too deep or complex. Overfitting occurs when the tree learns the training data too well and fails to generalize to unseen data. To address this, techniques like pruning and setting appropriate stopping criteria can be used to limit the tree’s depth or complexity.
In the next section, we will delve into the advantages of using decision tree machine learning and explore the benefits it offers in various applications.
Advantages of Decision Tree Machine Learning
Decision tree machine learning offers several advantages that make it a popular choice in various domains. Let’s explore the key advantages of using decision trees for predictive modeling and problem-solving:
1. Interpretability: Decision trees provide a clear and interpretable representation of the decision-making process. The tree structure allows us to trace the path from the root node to a leaf node, understanding the rules and criteria used at each step. This makes decision trees more intuitive and easily understandable compared to other complex machine learning models.
2. Handling Nonlinear Relationships: Decision trees can capture nonlinear relationships between features and the target variable. They can effectively handle interaction effects and complex patterns that may not be easily captured by traditional statistical models. This makes decision trees more flexible and adaptable to a wide range of problems.
3. Dealing with Missing Values: Decision trees have the capability to handle missing values in the dataset. During the tree construction process, when encountering missing values for a particular attribute, the algorithm can assign the data point to the most probable branch based on the available information. This reduces the need for extensive data preprocessing and imputation of missing values.
4. Variable Selection: Decision trees automatically select the most relevant features or attributes to make decisions, as they are based on the information gain or other splitting criteria. This eliminates the need for manual feature selection techniques, saving time and effort in the modeling process.
5. Handling both Categorical and Numerical Data: Decision trees can handle both categorical and numerical features, without the need for extensive data transformations. They can handle categorical features by creating different branches for each possible value and determine optimal thresholds for splitting numerical features. This flexibility makes decision trees versatile in dealing with various types of data.
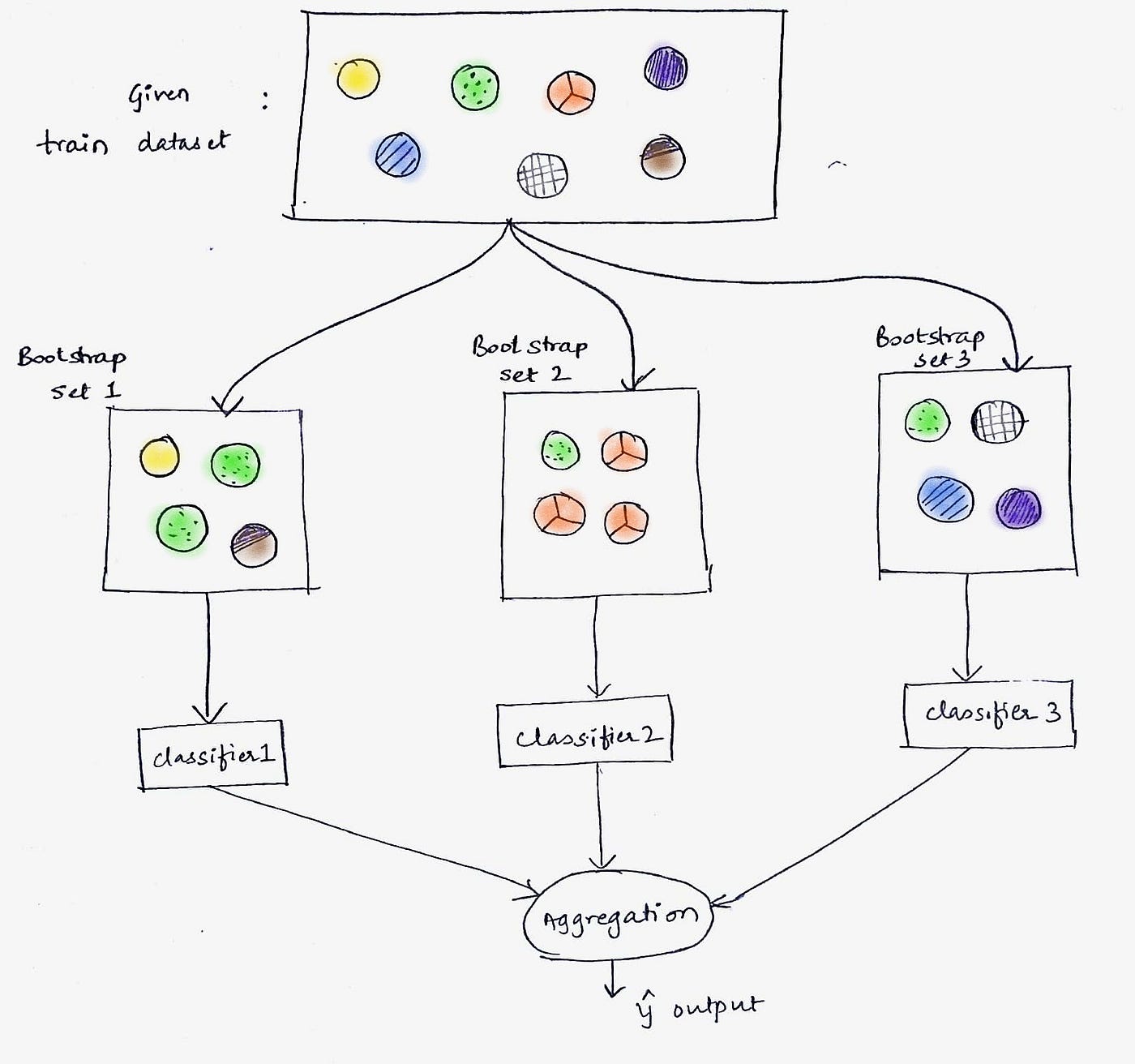
6. Ensemble Methods: Decision trees can be combined using ensemble methods like random forests, boosting, or bagging to improve predictive performance. Ensemble methods combine the strengths of multiple decision trees to produce more accurate and robust predictions. This offers further flexibility in modeling complex problems and dealing with high-dimensional data.
7. Efficiency: Decision tree algorithms are computationally efficient and have a relatively low time complexity compared to other complex machine learning algorithms. They can handle large datasets and provide fast results, making them suitable for real-time or time-constrained applications.
These advantages make decision tree machine learning a popular and widely used technique in various domains, from finance and healthcare to marketing and beyond. It provides a powerful and interpretable tool for predictive modeling and decision-making processes.
In the next section, we will discuss the potential disadvantages and limitations of decision tree machine learning.
Disadvantages of Decision Tree Machine Learning
While decision tree machine learning offers many advantages, it also has some limitations and potential drawbacks. It’s important to be aware of these disadvantages when using decision trees for predictive modeling and problem-solving. Let’s explore some of the main disadvantages:
1. Overfitting: Decision trees are prone to overfitting, especially when the tree becomes too deep or complex. Overfitting occurs when the model learns the training data too well and fails to generalize well to unseen data. This can lead to poor performance on new data and inaccurate predictions. Techniques like pruning and setting appropriate stopping criteria can help mitigate this issue.
2. High Variance: Decision trees are highly variable and sensitive to small changes in the training data. Different splits or variations in the training set can lead to different tree structures and predictions. This can make decision trees less stable compared to other machine learning models, such as linear regression or support vector machines.
3. Bias towards Features with More Levels: Decision trees have a bias towards features with more levels or categories. They tend to prioritize features with more choices for splitting, which can result in a biased and imbalanced tree structure. This can impact the accuracy and fairness of the predictions, especially when dealing with imbalanced datasets.
4. Limited Linear Modeling: Decision trees are not well-suited for capturing linear relationships or patterns in the data. They are more effective in handling nonlinear relationships and interactions between features. If the relationship between the features and the target variable is primarily linear, other models like linear regression may provide better results.
5. Difficulty in Handling Continuous Variables: While decision trees can handle numerical features, they may struggle with the inherent nature of continuous variables. Decision trees make binary decisions at each split, which can lead to loss of information in continuous variables. Techniques like discretization or binning can be used to transform continuous variables into categorical ones for decision tree modeling.
6. Data Instability: Decision tree structures can be affected by small changes in the training data, resulting in different splits and predictions. This instability can be a challenge when working with datasets that are prone to noise or have high variability. Ensemble methods like random forests can help mitigate this issue by combining multiple decision trees.
7. Complexity for Large Datasets: Decision tree algorithms can become computationally expensive and memory-intensive for large datasets with numerous features and observations. As the number of features and data points increases, the complexity of the tree grows, leading to longer training times and increased memory requirements. This can be a limitation for real-time or resource-constrained applications.
Understanding these limitations and potential disadvantages is crucial for effectively using decision tree machine learning. By being aware of these challenges, data scientists can make informed decisions and employ strategies to address these limitations.
In the next section, we will explore different types of decision tree algorithms that are commonly used in machine learning.
Types of Decision Tree Algorithms
There are several different types of decision tree algorithms that can be used in machine learning. Each algorithm has its own characteristics and advantages. Let’s explore some of the most commonly used decision tree algorithms:
1. ID3 (Iterative Dichotomiser 3): ID3 is one of the earliest and most basic decision tree algorithms. It uses the concept of information gain to determine the best attribute for splitting the data at each node. ID3 is primarily used for categorical data and can handle both binary and multi-class classification problems.
2. C4.5: C4.5 is an extension of the ID3 algorithm that improves upon its limitations. It can handle both categorical and numerical data, using attribute selection measures like information gain ratio. C4.5 also introduces the concept of handling missing values in the dataset, further enhancing its capabilities.
3. CART (Classification and Regression Trees): CART is a versatile decision tree algorithm that can be used for both classification and regression tasks. It uses the Gini impurity measure to evaluate the quality of splits for categorical variables and the reduction in variance for continuous variables. CART constructs binary decision trees, where each internal node has two branches.
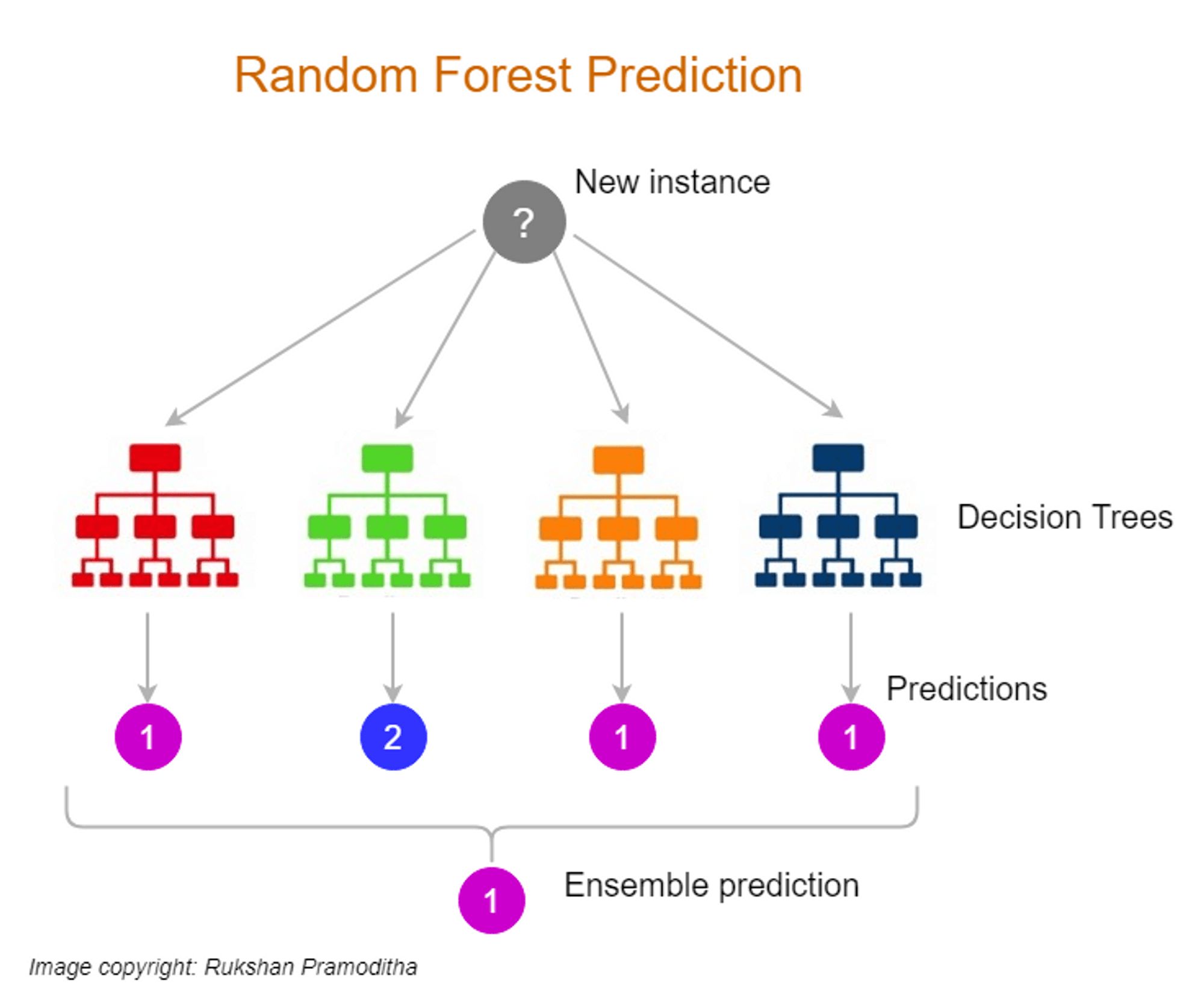
4. Random Forest: Random forest is an ensemble method that combines multiple decision trees to make predictions. It creates a collection of decision trees, each trained on a random subset of the original data. The final prediction is made by aggregating the predictions of individual trees. Random forest can improve accuracy and handle high-dimensional datasets.
5. Gradient Boosting Machines (GBM): GBM is another ensemble method that combines decision trees sequentially. It learns from the mistakes made by previous trees and focuses on improving those areas. GBM can handle both regression and classification tasks and is known for its high predictive performance.
6. AdaBoost: AdaBoost is a boosting algorithm that combines weak learners, typically decision trees, to create a strong predictive model. It assigns weights to the training samples based on their performance and focuses on the misclassified samples in subsequent iterations. AdaBoost is widely used for binary classification problems.
7. XGBoost: XGBoost is an optimized implementation of gradient boosting that provides superior performance and scalability. It incorporates regularization techniques and parallel processing to handle large datasets efficiently. XGBoost is widely used in various machine learning competitions and has gained popularity in both academic and industry settings.
These are just a few examples of the different types of decision tree algorithms used in machine learning. Each algorithm has its own strengths and weaknesses, and the choice of algorithm depends on the specific problem and dataset. It is important to explore and experiment with different algorithms to find the one that best suits the task at hand.
In the next section, we will delve into the process of building a decision tree model and the steps involved in its construction.
Building a Decision Tree Model
Building a decision tree model involves several key steps to construct an accurate and effective tree-based predictive model. Let’s explore the process of building a decision tree model:
1. Data Preprocessing: The first step is to prepare and preprocess the data. This includes handling missing values, removing duplicates and irrelevant features, and encoding categorical variables.
2. Data Split: The dataset is typically divided into training and testing sets. The training set is used to build the decision tree model, while the testing set is used to evaluate its performance on unseen data.
3. Selecting the Splitting Criterion: The next step is to choose the appropriate splitting criterion for the decision tree algorithm. This could be information gain, Gini impurity, or another measure depending on the algorithm being used and the nature of the problem.
4. Constructing the Tree: The decision tree is constructed by recursively partitioning the data based on the selected splitting criterion. The algorithm determines the best attribute to split on at each internal node and continues splitting until a stopping criterion is met, such as reaching a maximum tree depth or a minimum number of samples per leaf node.
5. Handling Overfitting: Decision trees are prone to overfitting, so it’s important to employ strategies to mitigate this issue. Techniques like pruning or setting appropriate stopping criteria can prevent the tree from becoming too deep or complex, improving its generalization ability.
6. Tree Evaluation: Once the decision tree is constructed, it needs to be evaluated to ensure its performance. This involves assessing its accuracy, precision, recall, and other evaluation metrics. Cross-validation techniques like k-fold cross-validation can be used to obtain more robust estimates of the model’s performance.
7. Model Optimization: Depending on the evaluation results, the decision tree model may need to be optimized. This can involve adjusting hyperparameters, such as the maximum tree depth, the minimum number of samples per leaf node, or other parameters specific to the algorithm being used. This iterative process of optimization helps improve the model’s performance.
8. Prediction and Deployment: Finally, the trained decision tree model can be used to make predictions on new, unseen data. The model can be deployed as part of a larger application or integrated into business processes to aid in decision-making or predictive tasks.
It’s important to note that the process of building a decision tree model involves iterative steps and experimentation. Fine-tuning the model and exploring different configuration options can lead to a more accurate and robust predictive model.
In the next section, we will discuss the evaluation of a decision tree model and the metrics used to assess its performance.
Evaluating the Decision Tree Model
Evaluating the performance of a decision tree model is crucial to determine its accuracy and effectiveness in making predictions. Several evaluation metrics can be used to assess the model’s performance and compare it against alternative models. Let’s explore the key aspects of evaluating a decision tree model:
1. Accuracy: Accuracy is a commonly used metric to evaluate the overall performance of a classification model. It measures the proportion of correct predictions made by the model on the test dataset. However, accuracy alone may not be sufficient in cases of imbalanced datasets, where the class distribution is skewed.
2. Precision and Recall: Precision and recall are evaluation metrics that provide insights into the model’s performance on individual classes. Precision measures the proportion of correctly predicted positive instances out of all instances predicted as positive. Recall, also known as sensitivity or true positive rate, measures the proportion of correctly predicted positive instances out of all true positive instances.
3. F1 Score: The F1 score is the harmonic mean of precision and recall and provides a balanced assessment of the model’s performance. It combines the strengths of precision and recall into a single metric. F1 score is useful when there is an imbalance between the number of positive and negative instances in the dataset.
4. Confusion Matrix: A confusion matrix provides a detailed view of the model’s performance by showing the number of correct and incorrect predictions for each class. It helps identify the types of errors made by the model, such as false positives and false negatives, and provides insights into specific areas for improvement.
5. Receiver Operating Characteristic (ROC) Curve: The ROC curve is a graphical representation of the model’s performance at various classification thresholds. It plots the true positive rate (recall) against the false positive rate (1-specificity) for different threshold values. The area under the ROC curve (AUC) is a commonly used metric to assess the model’s performance, with a higher AUC indicating better predictive ability.
6. Cross-Validation: Cross-validation is a widely used technique to evaluate the performance of a decision tree model. It involves splitting the dataset into multiple subsets or folds, training the model on a subset, and evaluating it on the remaining fold. This helps assess the model’s performance on different subsets of data and provides a more robust estimate of its performance.
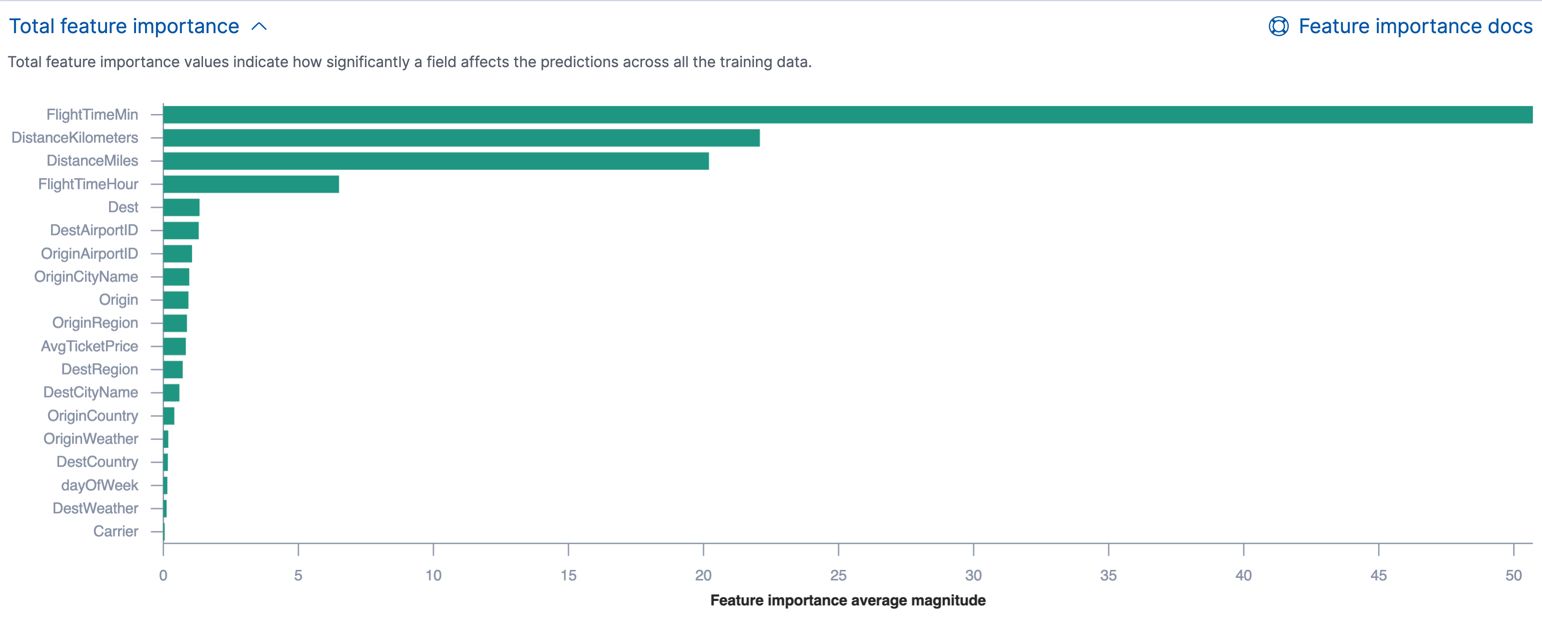
7. Feature Importance: Decision trees provide insights into the importance of features in predicting the target variable. This information can be used to identify the most influential features and understand their impact on the model’s predictions. Feature importance can aid in feature selection, dimensionality reduction, and identifying areas for further investigation.
By evaluating the decision tree model using these metrics, data scientists can gain an understanding of its predictive performance, identify areas for improvement, and compare results with other models. It is important to choose the appropriate evaluation metrics based on the specific problem and the objectives of the analysis.
In the next section, we will explore the diverse applications of decision tree machine learning across various domains.
Applications of Decision Tree Machine Learning
Decision tree machine learning has a wide range of applications across various domains, thanks to its versatility and interpretability. Let’s explore some of the diverse applications of decision tree machine learning:
1. Finance and Credit Risk Assessment: Decision trees are commonly used in finance for credit risk assessment. They can analyze customer data, financial records, and credit history to predict the likelihood of default or the creditworthiness of borrowers. Decision trees enable financial institutions to make informed lending decisions and assess the potential risk associated with different borrowers.
2. Healthcare and Medical Diagnosis: Decision trees find applications in healthcare for medical diagnosis and disease prediction. They can analyze patient data, symptoms, and medical history to identify potential diseases or conditions. Decision trees help doctors and healthcare professionals in making accurate diagnoses and recommending appropriate treatments or interventions.
3. Marketing and Customer Segmentation: Decision trees are widely used in marketing for customer segmentation and targeting. They help businesses identify distinct groups of customers based on their demographics, behaviors, or preferences. Decision trees enable marketers to tailor their marketing strategies and campaigns to specific customer segments, enhancing their effectiveness and ROI.
4. Fraud Detection: Decision trees are effective in fraud detection and prevention. They can analyze financial transaction data and identify patterns indicative of fraudulent activities. Decision trees help financial institutions, insurance companies, and e-commerce platforms detect fraud in real-time, minimizing loss and enhancing security.
5. Supply Chain Management: Decision trees are employed in supply chain management to optimize decision-making processes. They can analyze various factors such as demand patterns, inventory levels, transportation costs, and production capabilities. Decision trees aid in making informed decisions on inventory management, demand forecasting, and logistics planning.
6. Environmental Monitoring and Resource Management: Decision trees find applications in environmental monitoring and resource management. They can analyze data on climate, pollution levels, and resource consumption to make predictions and recommendations. Decision trees assist in sustainable resource management, conservation efforts, and environmental decision-making.
7. Human Resources and Employee Decision-Making: Decision trees can be utilized in human resources for various tasks, such as employee recruitment, performance evaluation, and employee churn prediction. They help in identifying the key factors influencing employee decisions and making data-driven HR decisions.
These are just a few examples of the diverse applications of decision tree machine learning. Decision trees’ simplicity, interpretability, and ability to handle both categorical and numerical data make them valuable tools in solving complex problems and making informed decisions across different domains.
In the concluding section, we will summarize the key points discussed in this article and highlight the significance of decision tree machine learning in the field of data science.
Conclusion
Decision tree machine learning is a powerful technique that offers numerous advantages in predictive modeling and problem-solving. It provides a clear and interpretable representation of the decision-making process, making it accessible to both technical and non-technical stakeholders. Decision trees can handle both categorical and numerical data, making them versatile in analyzing diverse datasets.
Despite their advantages, decision tree machine learning also has some limitations. Overfitting and high variance can be challenges, but techniques like pruning and ensemble methods can help mitigate these issues. The choice of an appropriate decision tree algorithm depends on the specific problem and dataset, and experimentation is often needed to find the most suitable algorithm.
Decision trees find applications in various domains, including finance, healthcare, marketing, and supply chain management. They are used for tasks such as credit risk assessment, medical diagnosis, customer segmentation, fraud detection, and resource management. Decision trees enable data-driven decision-making, improve efficiency, and enhance the accuracy of predictions in these domains.
In conclusion, decision tree machine learning is a valuable tool in the field of data science. It provides a transparent and interpretable approach to problem-solving, capturing complex relationships between variables. By understanding the concepts and techniques behind decision tree machine learning, data scientists and business professionals can harness its power for accurate predictions, valuable insights, and efficient decision-making processes.