Introduction
Welcome to the world of sentiment analysis and machine learning. In today’s digital age, where opinions and emotions are constantly expressed online, analyzing and understanding the sentiment behind text data has become increasingly important. Sentiment analysis, also known as opinion mining, is the process of determining the sentiment or emotional tone of a piece of text, such as a social media post, customer review, or news article.
The ability to accurately analyze sentiment has numerous applications across various fields. From analyzing customer feedback to monitoring brand reputation, sentiment analysis provides valuable insights into public opinion and allows businesses and organizations to make informed decisions based on the sentiment expressed by their target audience.
Machine learning, a subfield of artificial intelligence, plays a significant role in sentiment analysis. Machine learning algorithms learn from data and are capable of identifying patterns and making predictions. In the context of sentiment analysis, machine learning models are trained on labeled datasets that contain examples of text along with their corresponding sentiment. These models learn to classify new, unseen text based on the patterns and relationships they have learned from the training data.
In this article, we will explore the process of sentiment analysis using machine learning. We will discuss the various steps involved, starting from text preprocessing to training and evaluating the sentiment classification models. We will also delve into some examples of real-world applications of sentiment analysis.
So, whether you are interested in understanding the basics of sentiment analysis, looking to implement it in your own projects, or simply curious about how machine learning can be applied to analyze emotions in text data, this article is for you. Let’s dive in and explore the fascinating world of sentiment analysis and machine learning.
What is Sentiment Analysis?
Sentiment analysis, also known as opinion mining, is a branch of natural language processing (NLP) that focuses on understanding and interpreting the sentiment or emotional tone expressed in a piece of text. The goal of sentiment analysis is to determine whether a given text expresses a positive, negative, or neutral sentiment towards a particular topic, product, or event.
Text data can be sourced from various platforms, including social media posts, customer reviews, news articles, surveys, and more. Sentiment analysis techniques aim to extract subjective information from these texts and transform it into objective data that can be quantified and analyzed.
The primary challenge in sentiment analysis lies in interpreting the nuances of human language. Since human expressions can be complex and subjective, accurately determining sentiment is not always straightforward. Sentences may contain sarcasm, irony, figurative language, or mixed sentiments, which can complicate the analysis process.
Sentiment analysis can provide valuable insights across a wide range of applications. In the business world, sentiment analysis can help companies monitor brand reputation, customer satisfaction, and identify emerging trends or issues. By analyzing social media posts and customer reviews, businesses can understand the sentiment towards their products or services and make data-driven decisions to improve customer experience.
In the field of market research, sentiment analysis can be used to analyze public opinion about a particular product, service, or even a political candidate. This information is crucial for companies and organizations to understand how their brand is perceived in the market and to tailor their marketing strategies accordingly.
News organizations can also benefit from sentiment analysis by understanding the sentiment towards certain events or news topics. By analyzing public sentiment, news outlets can gauge the impact of their reporting and make adjustments if necessary.
Overall, sentiment analysis provides a powerful tool for understanding and analyzing the sentiment expressed in text data. By extracting subjective information and converting it into objective data, sentiment analysis enables businesses, organizations, and researchers to gain insights into public opinion and make informed decisions based on the sentiment expressed by their target audience.
Why is Sentiment Analysis Important?
Sentiment analysis plays a crucial role in today’s data-driven world. Here are some reasons why sentiment analysis is important:
1. Customer Insights: Businesses can gain valuable insights into customer opinions, preferences, and needs by analyzing sentiment in customer feedback. By understanding customer sentiment, companies can identify areas of improvement, optimize their products and services, and enhance customer satisfaction.
2. Brand Reputation Management: Monitoring sentiment helps businesses track and manage their brand reputation. By analyzing social media mentions, customer reviews, and other online content, companies can respond to negative sentiment promptly, defuse crises, and protect their brand image.
3. Competitive Analysis: Sentiment analysis allows businesses to compare their brand sentiment with that of their competitors. By understanding the sentiment around competing products or services, companies can identify areas where they excel or areas where they need improvement, helping them to stay ahead in the market.
4. Market Research: Sentiment analysis is a valuable tool for market research. It helps researchers understand public opinion about specific products, services, or industry trends. This information can be used to make informed decisions about product development, marketing strategies, and targeting specific customer segments.
5. Social Media Monitoring: Social media platforms are full of user-generated content that can provide valuable insights. Sentiment analysis allows businesses to monitor social media discussions, track brand mentions, and identify influencers who can help amplify positive sentiment.
6. Customer Service Improvement: By analyzing sentiment in customer service interactions, businesses can uncover areas for improvement and provide personalized responses to customer concerns. Sentiment analysis helps to gauge customer satisfaction levels and identify recurring issues that need to be addressed.
7. Public Opinion Analysis: Sentiment analysis can be used to analyze public sentiment towards political candidates, social issues, or current events. This information aids policymakers, journalists, and organizations in understanding public sentiment and tailoring their communication strategies accordingly.
8. Product Launch and Campaign Evaluation: Sentiment analysis provides valuable insights during product launches and marketing campaigns. By analyzing sentiment during pre-launch or post-campaign periods, businesses can evaluate the effectiveness of their strategies and make data-driven decisions for future campaigns.
Overall, sentiment analysis is important because it helps businesses make informed decisions, understand customers, manage brand reputation, evaluate competition, and stay ahead in the market. By harnessing the power of sentiment analysis, companies can unlock valuable insights hidden within text data and drive their success.
Machine Learning in Sentiment Analysis
Machine learning plays a crucial role in sentiment analysis, enabling the automated analysis and classification of sentiment in text data. Traditional rule-based approaches often struggle to handle the complexity and intricacies of human language. Machine learning algorithms, on the other hand, have the ability to learn from data and identify patterns, making them well-suited for sentiment analysis tasks.
In sentiment analysis, machine learning models are trained on labeled datasets that contain examples of text along with their corresponding sentiment labels, such as positive, negative, or neutral. These models then use the patterns and relationships they have learned from the training data to classify new, unseen text based on its sentiment.
The process of using machine learning in sentiment analysis consists of multiple stages:
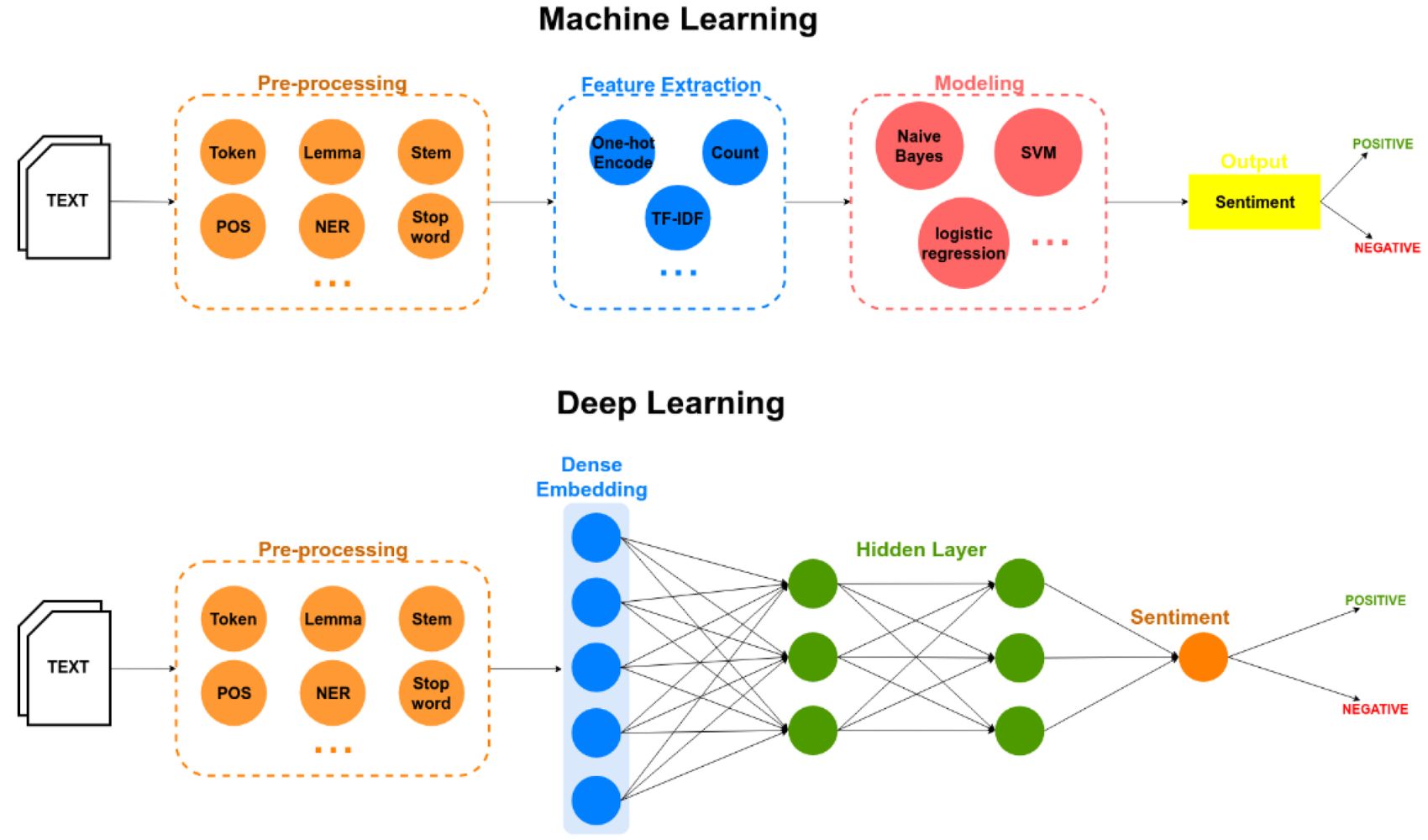
1. Text Preprocessing: Before feeding text data to a machine learning model, it must be preprocessed to remove noise, normalize the text, and transform it into a suitable format. Text preprocessing techniques may include tokenization, removing stop words, stemming or lemmatization, and handling special characters or emoticons.
2. Feature Extraction: In order to represent text data in a numerical format that can be understood by machine learning algorithms, feature extraction is performed. Common feature extraction techniques for sentiment analysis include bag-of-words, n-grams, and word embeddings like Word2Vec or GloVe. These techniques capture information about the frequency and context of words in the text.
3. Sentiment Classification Models: Various machine learning models can be used for sentiment classification, including Naive Bayes, Support Vector Machines (SVM), Decision Trees, Random Forests, and deep learning models such as Recurrent Neural Networks (RNN) or Convolutional Neural Networks (CNN). These models learn to classify text based on the patterns and relationships observed in the training data.
4. Training and Testing the Model: The labeled dataset is divided into a training set and a testing set. The machine learning model is trained on the training set, and its performance is evaluated on the testing set. This allows us to assess how well the model generalizes to new, unseen data.
5. Evaluating the Model: The performance of the sentiment classification model is evaluated using various evaluation metrics such as accuracy, precision, recall, and F1-score. These metrics provide insights into how well the model is predicting sentiment and help in fine-tuning the model if necessary.
Machine learning in sentiment analysis offers numerous advantages. It allows for the handling of large volumes of data, the ability to learn from examples, and the potential to improve accuracy with more data and model optimization. Additionally, machine learning models can adapt and improve over time as more data becomes available.
Overall, machine learning has revolutionized sentiment analysis, enabling the automated analysis and classification of sentiment in text data. By leveraging machine learning techniques, businesses and organizations can gain valuable insights into customer sentiment, market trends, and brand perception. The application of machine learning algorithms in sentiment analysis continues to evolve, promising more accurate and efficient sentiment analysis in the future.
The Process of Sentiment Analysis
The process of sentiment analysis involves several steps that transform raw text data into actionable insights. While the specific implementation may vary depending on the tools and techniques used, the overall sentiment analysis process can be summarized as follows:
1. Text Preprocessing: The first step is to preprocess the text data. This includes removing any unnecessary characters, such as punctuation or special symbols, and converting the text to lowercase. Additionally, techniques like tokenization, removing stop words, and handling emoticons or slang may be employed to prepare the text for further analysis.
2. Feature Extraction: The next step is to extract relevant features from the preprocessed text. This involves representing the text in a numerical format that machine learning algorithms can understand. Common techniques include creating a bag-of-words representation, which counts the frequency of each word in the text, or using word embeddings like Word2Vec or GloVe to capture semantic information.
3. Sentiment Classification Models: Once the features are extracted, a sentiment classification model is built. Machine learning models, such as Naive Bayes, Support Vector Machines (SVM), or deep learning models like Recurrent Neural Networks (RNN) or Convolutional Neural Networks (CNN), can be trained on labeled data to classify text into positive, negative, or neutral sentiment categories. The choice of model depends on the dataset, computational resources, and specific requirements of the sentiment analysis task.
4. Training and Testing the Model: To evaluate the performance of the sentiment classification model, it is trained on a labeled dataset. The dataset is divided into two parts: a training set used to train the model and a testing set used to assess its accuracy and generalization. The model learns to classify text based on the training data and is then evaluated on the testing data to measure its performance.
5. Evaluating the Model: The performance of the sentiment classification model is assessed using various evaluation metrics, such as accuracy, precision, recall, and F1-score. These metrics provide insights into how well the model predicts sentiment. The model can be refined and optimized based on these evaluation metrics.
6. Sentiment Analysis Output: Once the model is trained and evaluated, it can be used to perform sentiment analysis on new, unseen text data. The sentiment analysis output typically includes sentiment scores or labels that indicate the sentiment expressed in the text. These scores or labels can be used to generate insights, make data-driven decisions, or trigger specific actions based on the sentiment detected.
The process of sentiment analysis is iterative and may involve fine-tuning the models, updating the training data, and re-evaluating the model’s performance to improve accuracy. Continuous monitoring and adaptation are necessary to ensure the sentiment analysis system performs optimally as language and sentiment trends evolve.
By following this process, sentiment analysis enables businesses, organizations, and researchers to gain valuable insights into the sentiment expressed in text data. These insights can inform decision-making, help understand customer sentiment, and drive improvements in products, services, and overall brand reputation.
Text Preprocessing
Text preprocessing is a crucial step in sentiment analysis that involves cleaning and transforming raw text data before it can be effectively analyzed. The purpose of text preprocessing is to remove noise, normalize the text, and prepare it for further analysis. Several techniques and steps are involved in text preprocessing:
1. Removing Punctuation and Special Characters: The first step is to remove punctuation marks, special symbols, and any non-alphabetic characters from the text. These characters do not contribute to sentiment analysis and can be safely discarded.
2. Converting to Lowercase: Converting all text to lowercase is important to remove any inconsistencies in capitalization. It ensures that words with the same letters but different capitalization are treated as the same, preventing duplication of features during feature extraction.
3. Tokenization: Tokenization involves breaking down the text into individual words or tokens. This step is important for feature extraction and allows the sentiment analysis model to process each word as a separate unit. Tokenization can be done using various techniques, such as splitting the text by spaces or using advanced tokenizer libraries.
4. Removing Stop Words: Stop words are commonly used words that do not add much meaning to the text, such as “and,” “the,” or “is.” These words are removed during text preprocessing as they do not contribute to sentiment analysis and can introduce noise into the data.
5. Handling Emoticons and Slang: Emoticons, acronyms, and slang words often carry sentiment and meaning. To preserve this information, sentiment analysis systems may treat emoticons or slang words differently, mapping them to their respective sentiment or transforming them into their expanded forms.
6. Lemmatization or Stemming: Lemmatization and stemming are techniques used to reduce words to their base or root form. This helps in reducing the vocabulary size and treating related words as the same. For example, “running,” “runs,” and “ran” can all be stemmed or lemmatized to “run.”
7. Handling Spelling Errors: Text data may contain spelling errors, which can affect the accuracy of sentiment analysis. Techniques such as spell checking or using language models can help correct common spelling mistakes and improve the quality of the text data.
Text preprocessing is a critical step in sentiment analysis as it helps in reducing noise, standardizing the text, and ensuring consistency in representation. By applying these techniques, the text data is cleaned and transformed into a format that can be effectively analyzed by sentiment classification models.
It is important to note that the specific steps and techniques used in text preprocessing may vary depending on the specific requirements of the sentiment analysis task and the nature of the text data. Different domains or languages may require modifications to the preprocessing steps to ensure accurate sentiment analysis results.
By performing text preprocessing, sentiment analysis systems can uncover valuable insights hidden within the text data and deliver more accurate sentiment analysis results. It sets the foundation for subsequent steps such as feature extraction and model training, enabling businesses, organizations, and researchers to gain a deeper understanding of sentiment in textual data.
Feature Extraction
Feature extraction is a vital step in sentiment analysis that involves representing text data in a numerical format that can be understood by machine learning algorithms. The purpose of feature extraction is to capture the relevant information from the text and transform it into features that can be used to train models for sentiment classification. Several techniques can be employed for feature extraction:
1. Bag-of-Words: The bag-of-words approach treats each document or text as a collection of unique words, disregarding the order or structure of the text. A vocabulary is created by tokenizing the text into individual words, and then a vector representation is generated for each document, with each position corresponding to a word in the vocabulary. The value in each position indicates the frequency or presence of the word in the document, capturing the importance of the word in sentiment analysis.
2. N-grams: N-grams are contiguous sequences of n items, usually words, in a text. By considering not only individual words but also the context in which they appear, n-grams capture some of the semantic meaning and syntactic structure of the text. Commonly used n-grams include unigrams (individual words), bigrams (pairs of words), and trigrams (triplets of words).
3. Word Embeddings: Word embeddings are dense vector representations of words that capture semantic meaning and relationships between words. Techniques like Word2Vec or GloVe learn word embeddings by training on large text corpora. These word embeddings can be used to represent text documents by averaging or concatenating the embeddings of the words in the document.
4. Term Frequency-Inverse Document Frequency (TF-IDF): TF-IDF is a statistical measure used to evaluate the importance of a word in a document within a corpus. It considers both the frequency of the word in the document (term frequency) and the rarity of the word in the corpus (inverse document frequency). TF-IDF assigns higher weights to words that are more relevant in distinguishing one document from another, making it useful for sentiment analysis.
5. Neural Network-based Models: Deep learning models, such as Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs), can be used for feature extraction. These models can learn expressive representations of the text by incorporating sequential or convolutional layers, capturing the contextual information and local patterns present in the text.
The choice of feature extraction technique depends on the nature of the text data and the specific requirements of the sentiment analysis task. Different techniques have their strengths and weaknesses. For instance, bag-of-words and n-grams can be simpler to implement, while word embeddings and deep learning models tend to capture more nuanced semantic information.
After feature extraction, the transformed numerical representation of the text data can be fed into machine learning algorithms for training and prediction. These features capture the relevant information from the text required for sentiment analysis and allow sentiment classification models to learn patterns and relationships between words and sentiment labels.
Feature extraction is a crucial step in sentiment analysis as it enables the translation of text data into a format that can be processed and analyzed by machine learning algorithms. By effectively representing the text as features, sentiment analysis models can achieve better accuracy and performance, helping businesses, organizations, and researchers gain valuable insights into sentiment expressed in textual data.
Sentiment Classification Models
Sentiment classification models are machine learning algorithms that are trained to classify text into different sentiment categories, such as positive, negative, or neutral. These models play a crucial role in sentiment analysis by automatically assigning sentiment labels to text data, based on patterns and relationships learned from training data. Various machine learning algorithms and techniques can be used for sentiment classification:
1. Naive Bayes: Naive Bayes is a probabilistic classification algorithm commonly used in sentiment analysis. It assumes that the presence of a particular feature in a class is independent of the presence of other features. Despite its simplicity, Naive Bayes can perform well in sentiment analysis tasks and is computationally efficient.
2. Support Vector Machines (SVM): SVMs are powerful machine learning models that are widely used in sentiment analysis. SVMs aim to find an optimal hyperplane that separates different sentiment classes in a high-dimensional feature space. SVMs with different kernels, such as linear, polynomial, or radial basis function (RBF), can be employed for sentiment classification.
3. Decision Trees: Decision trees are simple yet powerful models that use a hierarchical structure of decision nodes and branches to classify data. Decision trees are easy to interpret and can capture non-linear relationships between features and sentiment classes. However, they can suffer from overfitting if not properly tuned.
4. Random Forests: Random forests are ensemble learning models that combine multiple decision trees to improve the accuracy and robustness of the sentiment classification. By aggregating the predictions of individual decision trees, random forests can reduce overfitting and handle a larger variety of features.
5. Deep Learning Models: Deep learning models, especially recurrent neural networks (RNNs) and convolutional neural networks (CNNs), have been widely used in sentiment analysis due to their ability to capture complex patterns and relationships in text data. RNNs are effective in modeling sequential information, while CNNs excel at capturing local patterns and the compositionality of words.
The choice of sentiment classification model depends on factors such as the size of the dataset, the level of interpretability required, computational resources, and the specific requirements of the sentiment analysis task. Each model has its own advantages and limitations, and experimentation and evaluation are crucial to determine the most suitable model for a given application.
Once the sentiment classification model is trained using labeled data, it can be used to predict sentiment on new, unseen text data. The model analyzes the features extracted from the text and assigns a sentiment label or sentiment score to the input. The output of the sentiment classification model provides valuable insights into the sentiment expressed in the text, enabling businesses, organizations, and researchers to make data-driven decisions based on customer opinions and market trends.
It’s important to note that sentiment classification models may require fine-tuning and hyperparameter optimization to achieve optimal performance. Regular model evaluation and refinement are essential to maintain accuracy and adapt the model to changing sentiment patterns and language use over time.
By utilizing sentiment classification models, sentiment analysis systems can effectively classify text data into sentiment categories, providing valuable insights into the sentiment expressed in textual data. These models form the backbone of sentiment analysis, enabling businesses and organizations to understand customer opinions, monitor brand reputation, and make informed decisions based on sentiment analysis results.
Training and Testing the Model
Training and testing the model is a crucial step in sentiment analysis, where the sentiment classification model is trained on labeled data and evaluated for its performance. This process involves splitting the labeled dataset into separate training and testing sets, training the model on the training set, and evaluating its performance on the testing set. The steps involved in training and testing the model are as follows:
1. Dividing the Dataset: The labeled dataset is divided into two parts: the training set and the testing set. The training set is used to train the sentiment classification model, while the testing set is used to evaluate the model’s performance on unseen data. The division is typically done randomly, ensuring that each set represents the diversity of the data.
2. Training the Model: The training set is used to train the sentiment classification model. The model learns the patterns and relationships between the text features and their corresponding sentiment labels present in the training data. The training process involves feeding the features extracted from the text data into the model and adjusting the model’s parameters to minimize the error or loss function.
3. Evaluating the Model: After training, the performance of the sentiment classification model is evaluated using the testing set. The testing set contains labeled data that the model has not seen during the training process. The model predicts the sentiment labels for the text data in the testing set, and these predictions are compared to the actual labels to assess the model’s accuracy and generalization.
4. Performance Metrics: Various evaluation metrics can be used to measure the performance of the sentiment classification model. Common metrics include accuracy, precision, recall, and F1-score. Accuracy measures the overall correctness of the model’s predictions. Precision focuses on the model’s ability to correctly identify positive or negative sentiment. Recall measures the model’s ability to identify all relevant positive or negative sentiment. F1-score is the harmonic mean of precision and recall, providing an overall assessment of the model’s performance.
5. Optimizing the Model: Based on the evaluation results, the sentiment classification model can be further optimized. This may involve adjusting hyperparameters, modifying the model architecture, or increasing the training data size. Regular model evaluation and refinement are important to improve the model’s performance and enhance its ability to accurately classify sentiment.
6. Cross-Validation: In addition to a simple train-test split, cross-validation techniques can be used to further evaluate the model’s performance. Cross-validation involves splitting the dataset into multiple folds and performing multiple iterations of training and testing on different combinations of the folds. This helps to obtain a more robust evaluation of the model’s performance by validating it on different subsets of the data.
By training and testing the sentiment classification model, businesses, organizations, and researchers can assess the model’s accuracy, understand its generalization capabilities, and fine-tune it for optimal performance. It is important to note that the model’s performance on the testing set serves as an estimate of its performance on new, unseen data. Continuous evaluation and refinement are necessary as language and sentiment patterns evolve over time.
Through the training and testing process, sentiment analysis models become better equipped to analyze and classify sentiment in text data, providing valuable insights into the sentiment expressed by customers, users, or the general public. This information can guide decision-making processes, help tailor marketing strategies, and optimize products and services for improved customer satisfaction.
Evaluating the Model
Evaluating the model is a critical step in sentiment analysis that assesses the performance and effectiveness of the sentiment classification model. By evaluating the model, businesses, organizations, and researchers can gain insights into how well the model predicts sentiment and make informed decisions based on its performance. Several evaluation metrics are commonly used to assess the model’s effectiveness:
1. Accuracy: Accuracy measures the overall correctness of the model’s predictions. It is calculated as the ratio of correctly classified instances to the total number of instances. While accuracy provides a general measure of the model’s performance, it can be misleading if the dataset is imbalanced.
2. Precision: Precision focuses on the model’s ability to correctly identify instances of positive or negative sentiment. It is calculated as the ratio of true positives (correctly identified instances of a particular sentiment) to the sum of true positives and false positives (instances wrongly classified as a particular sentiment).
3. Recall: Recall, also known as sensitivity or true positive rate, measures the model’s ability to identify all relevant instances of a particular sentiment. It is calculated as the ratio of true positives to the sum of true positives and false negatives (instances wrongly classified as a different sentiment).
4. F1-Score: F1-score is the harmonic mean of precision and recall, providing a balance between the two metrics. It combines precision and recall into a single evaluation metric, providing an overall assessment of the model’s performance.
5. Confusion Matrix: The confusion matrix provides a detailed and comprehensive view of the model’s performance by showing the number of true positives, false positives, true negatives, and false negatives. It helps in identifying which sentiments are most frequently misclassified and provides insights into the model’s strengths and weaknesses.
6. Cross-Validation: Cross-validation techniques, such as k-fold cross-validation, can be employed to evaluate the model’s performance more robustly. This involves dividing the dataset into multiple folds and performing multiple iterations of training and testing on different combinations of the folds. Cross-validation provides a more accurate estimate of the model’s performance by validating it on different subsets of the data.
In addition to these evaluation metrics, researchers and practitioners may also consider other domain-specific measures or metrics tailored to specific sentiment analysis tasks or goals.
During the evaluation process, it is important to interpret and analyze the evaluation metrics in the context of the specific task and the dataset’s characteristics. A high accuracy, for example, does not necessarily indicate a good sentiment analysis model if the dataset is imbalanced or contains biases. Additionally, evaluation should involve comparing the model’s performance against baseline models or previous iterations to assess any improvements.
Evaluation does not end with a single assessment; it should be an ongoing process to monitor the model’s performance and identify opportunities for improvement. Continuous evaluation and refinement of sentiment analysis models are necessary to adapt to evolving language use, sentiment patterns, and the dynamics of the domain.
By effectively evaluating sentiment analysis models, businesses, organizations, and researchers can understand the reliability and predictive power of the models, make informed decisions based on sentiment insights, and optimize their strategies and actions accordingly.
Examples of Sentiment Analysis Applications
Sentiment analysis has a wide range of applications across various industries and domains. The ability to understand and analyze sentiment in text data provides valuable insights into people’s opinions, emotions, and attitudes. Here are some examples of how sentiment analysis is applied in real-world scenarios:
1. Brand Monitoring and Reputation Management: Companies use sentiment analysis to monitor social media platforms, customer reviews, and online forums to understand public sentiment towards their brand. By tracking and analyzing sentiment, businesses can identify brand advocates, address negative sentiment promptly, and manage their online reputation effectively.
2. Customer Feedback and Satisfaction: Sentiment analysis helps businesses gauge customer satisfaction and gather feedback on products, services, and customer experiences. By analyzing sentiment in customer reviews, surveys, and support interactions, companies can identify areas for improvement, address customer concerns, and enhance overall customer satisfaction.
3. Market Research and Product Development: Sentiment analysis provides insights into public opinions and preferences about products, services, or industry trends. Companies can use sentiment analysis to identify emerging trends, assess market sentiment towards new product launches, and gain a competitive edge by understanding customer needs and preferences.
4. Social Media Monitoring and Influencer Marketing: Sentiment analysis of social media data allows businesses to monitor customer sentiment towards their brand, track brand mentions, and uncover trending topics. This information helps in the identification of key influencers, understanding sentiment patterns, and adapting marketing strategies accordingly.
5. Political Analysis: Sentiment analysis is applied in political campaigns and public opinion analysis to understand public sentiments towards political candidates, parties, or policies. By monitoring sentiment on social media, news articles, and public forums, political organizations can gauge public opinion, tailor their messaging, and make data-driven decisions.
6. Customer Service and Support: Sentiment analysis can be used to analyze customer support interactions, such as emails or chat logs. It helps businesses identify customer sentiment towards their support experience, detect potential issues, and improve the quality of customer service.
7. Financial Market Analysis: Sentiment analysis is extensively used in analyzing financial markets. By analyzing sentiment in news articles, social media discussions, and financial reports, sentiment analysis can help investors and financial institutions gauge market sentiment, make informed trading decisions, and predict market trends.
8. Public Opinion Analysis: Sentiment analysis is applied in analyzing public opinion on social issues, healthcare policies, or environmental topics. Government agencies and policymakers can leverage sentiment analysis to understand public sentiment, receive feedback, and tailor their communication strategies accordingly.
These are just a few examples of how sentiment analysis is applied in various industries and domains. The applications continue to expand as sentiment analysis techniques evolve and new sources of text data emerge. Sentiment analysis provides businesses, organizations, and researchers with valuable insights into public sentiment, helping them make data-driven decisions, drive customer satisfaction, manage their reputation, and stay competitive in today’s digital age.
Conclusion
Sentiment analysis, powered by machine learning, has become an essential tool in understanding and analyzing sentiment in text data. By leveraging various techniques such as text preprocessing, feature extraction, and sentiment classification models, businesses, organizations, and researchers can gain valuable insights into customer opinions, market trends, brand reputation, and public sentiment.
The process of sentiment analysis involves several steps, including text preprocessing to clean and normalize the text, feature extraction to represent the text in a numerical format, training and testing of sentiment classification models, and evaluating the model’s performance using metrics like accuracy, precision, recall, and F1-score.
Real-world applications of sentiment analysis are wide-ranging. From brand reputation management and customer satisfaction analysis to market research and political analysis, sentiment analysis provides actionable insights that drive decision-making, improve customer experiences, and shape business strategies.
However, it is important to note that sentiment analysis is not without its challenges. Human language is complex, and sentiment analysis models need to account for nuances, sarcasm, and figurative language. Continuous evaluation, refinement, and monitoring are necessary to ensure accurate sentiment analysis results and adapt to changing sentiment patterns and language use.
The future of sentiment analysis holds great promise, with advancements in natural language processing and deep learning techniques. As sentiment analysis models become more sophisticated, they will be able to understand context better, detect sentiment shifts, and handle diverse languages and cultural nuances.
In conclusion, sentiment analysis is a powerful tool that provides businesses, organizations, and researchers with valuable insights into sentiment expressed in text data. It enables data-driven decision-making, improves customer experiences, and helps shape marketing strategies. By leveraging the power of sentiment analysis, businesses can stay ahead in a highly competitive market, enhance brand reputation, and build strong customer relationships.