





Introduction
In today’s technology-driven world, the demand for faster and more efficient computing power is constantly increasing. Central Processing Units (CPUs) have long been the primary workhorses of computing, handling a wide range of tasks from running operating systems to executing complex algorithms. However, Graphics Processing Units (GPUs) are emerging as a powerful alternative that offers significant advantages in certain applications.
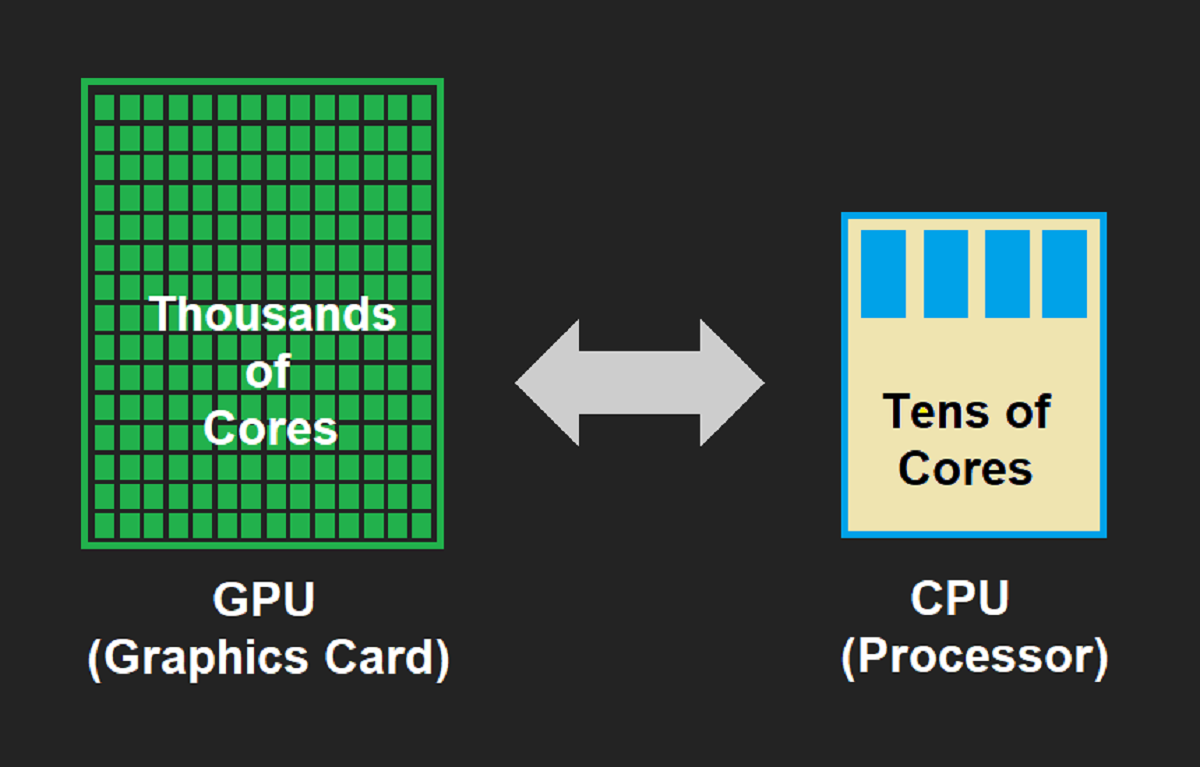
In order to understand why GPUs are faster than CPUs in certain scenarios, it is important to delve into their respective architectures and functionalities. While CPUs are designed for general-purpose computing and possess a few processor cores, GPUs are specialized processors primarily designed for rendering graphics and handling highly parallel tasks.
By harnessing the power of parallel processing and their unique architectural design, GPUs excel in applications that require massive computational power, such as scientific simulations, machine learning, and cryptocurrency mining. GPU manufacturers have been continuously improving their designs to cater to the growing demand for high-performance computing.
In this article, we will explore the architectural differences between CPUs and GPUs and analyze the factors that contribute to the superior speed and efficiency of GPUs. By delving into concepts like parallel processing power, specialized functions, and memory bandwidth, we will uncover the reasons behind the exceptional performance of GPUs in specific computing tasks.
What is a CPU?
A Central Processing Unit (CPU) is one of the essential components of a computer system. It is responsible for executing instructions and coordinating the operations of all the hardware and software components. CPUs are often referred to as the “brain” of a computer because they perform a wide range of tasks required for the system’s operation.
CPU architecture usually consists of a few processor cores, each capable of executing multiple instructions sequentially. These cores handle tasks such as running the operating system, executing applications, and performing arithmetic and logical operations. CPUs are designed to be versatile, which allows them to handle various types of computing tasks effectively.
The key characteristics of a CPU are its clock speed, the number of cores it has, and the cache memory it possesses. The clock speed determines how many instructions a CPU can execute per second, while the number of cores determines how many tasks it can handle simultaneously. Cache memory assists in speeding up data access by storing frequently used information closer to the processor.
CPUs are designed to be flexible and capable of efficiently executing a wide range of tasks, such as running complex software, browsing the internet, and handling everyday computing needs. They excel in tasks that require strong single-threaded performance, where the execution of instructions is done in a sequential manner.
However, CPUs may struggle with highly parallel tasks that require executing multiple instructions simultaneously. This is where Graphics Processing Units (GPUs) come into play, as they are specifically designed to handle such tasks. In the next section, we will delve into the functionality and architecture of GPUs to understand why they outperform CPUs in certain scenarios.
What is a GPU?
A Graphics Processing Unit (GPU) is a specialized processor primarily designed for rendering and manipulating graphics. While CPUs are versatile and handle a wide range of computing tasks, GPUs are specifically optimized for parallel processing and excel in tasks that require massive computational power.
The architecture of a GPU is different from that of a CPU. While CPUs typically have a few cores, GPUs have hundreds or even thousands of smaller cores. These cores work together in parallel, allowing the GPU to process a large number of tasks simultaneously.
Originally, GPUs were developed to accelerate graphics rendering for video games and other visual applications. However, their powerful parallel processing capabilities made them suitable for other computationally intensive tasks as well. This led to the emergence of General-Purpose GPU (GPGPU) computing, where GPUs are used for non-graphics related tasks such as scientific simulations, machine learning, and data analytics.
One of the key features that differentiate GPUs from CPUs is their memory architecture. GPUs have high memory bandwidth, which enables them to quickly access and process large amounts of data. This is particularly advantageous in applications that involve working with large data sets or performing complex calculations.
Furthermore, GPUs have specialized functions and frameworks, such as CUDA (Compute Unified Device Architecture) and OpenCL (Open Computing Language), which allow developers to harness their parallel processing capabilities. These frameworks provide a programming interface that enables developers to efficiently distribute tasks across the GPU cores, optimizing the use of available resources.
It is important to note that while GPUs are highly efficient for parallel tasks, they may not perform as well as CPUs in tasks that require strong single-threaded performance. The architectural design of GPUs sacrifices some sequential processing power in favor of parallelism.
In the next sections, we will delve deeper into the architectural differences between CPUs and GPUs and explore the factors that contribute to the superior speed and efficiency of GPUs in certain computing scenarios.
Architecture Differences
The architecture of CPUs and GPUs differs significantly, reflecting their intended purposes and priorities. CPUs are designed for general-purpose computing, while GPUs are optimized for parallel processing and graphics rendering.
CPUs typically have a few cores, usually ranging from two to eight, with each core capable of executing multiple instructions sequentially. This sequential execution allows CPUs to handle a wide variety of tasks efficiently. CPUs also include complex cache hierarchies, which improve data access speed and reduce memory latency.
On the other hand, GPUs have a multitude of smaller cores, numbering in the hundreds or even thousands. These cores are designed to work together in parallel, making GPUs highly efficient in tasks that can be divided into multiple subtasks. This parallelism enables the GPU to process a massive amount of data simultaneously, resulting in significant speed and performance gains.
The architectural differences between CPUs and GPUs can be visualized as a trade-off between single-threaded performance and parallel processing power. CPUs excel at running tasks that require strong single-threaded performance, where instructions need to be executed in a sequential manner.
GPUs, on the other hand, shine in highly parallel tasks. With their multitude of cores, GPUs can tackle computationally intensive workloads by dividing them into smaller subtasks and processing them concurrently. This makes them ideal for applications such as scientific simulations, image and video processing, virtual reality, and machine learning.
To effectively harness the power of GPUs, developers need to design and optimize their applications to take advantage of parallel processing. This involves distributing tasks across the GPU cores, minimizing data dependencies, and utilizing specialized GPU programming frameworks like CUDA and OpenCL.
In the next sections, we will explore other factors that contribute to the superior speed and efficiency of GPUs, including their parallel processing power, specialized functions, and memory bandwidth.
Parallel Processing Power
One of the major advantages of Graphics Processing Units (GPUs) over Central Processing Units (CPUs) is their superior parallel processing power. While CPUs typically have a few cores designed for sequential processing, GPUs feature hundreds or even thousands of smaller cores that can simultaneously execute multiple instructions in parallel.
This parallelism allows GPUs to handle highly parallel tasks more efficiently than CPUs. For example, in graphics rendering, GPUs can process multiple vertices and pixels simultaneously, resulting in faster frame rates and smoother visuals. Similarly, in machine learning algorithms, GPUs can process multiple training examples simultaneously, significantly reducing the time required for training models.
Modern GPUs are built using a concept called Single Instruction Multiple Threads (SIMT), where a single instruction is executed across multiple threads simultaneously. This approach allows for massive parallelism across the GPU cores, resulting in a significant boost in computational throughput.
Furthermore, GPUs also employ techniques such as warp scheduling and thread interleaving to maximize parallel execution. Warps are groups of threads that execute the same instruction but on different data. By executing these threads in parallel, GPUs can achieve high levels of instruction-level parallelism.
The parallel processing power of GPUs also plays a crucial role in scientific simulations and data-intensive applications. Tasks such as climate modeling, fluid dynamics, and molecular dynamics simulations can be executed concurrently across GPU cores, accelerating the calculations and reducing the time required for obtaining results.
However, it is essential to note that not all tasks can benefit from parallel processing to the same extent. Some tasks inherently have dependencies and require sequential processing or have limits to the amount of parallelization possible. In such cases, CPUs may perform better due to their stronger single-threaded performance.
In the following sections, we will explore other factors that contribute to the faster performance of GPUs, including their specialized functions and memory bandwidth.
Specialized Functions
Graphics Processing Units (GPUs) are not only designed for parallel processing but also possess specialized functions that make them highly efficient in certain types of computations. These specialized functions enable GPUs to outperform Central Processing Units (CPUs) in specific applications, especially those that require massive computational power.
One of the specialized functions of GPUs is their ability to perform vector operations efficiently. GPUs are equipped with SIMD (Single Instruction, Multiple Data) instructions, which allow a single instruction to be applied to multiple data elements simultaneously. This is particularly beneficial in tasks involving large datasets, such as image and video processing.
Another key function of GPUs is their support for floating-point arithmetic. GPUs have dedicated hardware units for floating-point operations, which enable them to perform complex calculations with high precision and speed. This makes GPUs ideal for scientific simulations, numerical computations, and financial modeling.
Furthermore, GPUs also offer support for specialized libraries and frameworks that enhance their performance in specific domains. For example, CUDA (Compute Unified Device Architecture) is a programming framework developed by NVIDIA specifically for GPU computing. It provides developers with a high-level programming language and a set of libraries optimized for parallel processing on GPUs.
Other frameworks, such as OpenCL (Open Computing Language), allow developers to write code that can execute across different types of accelerators, including GPUs. These frameworks provide an abstraction layer that allows programmers to utilize the parallel processing capabilities of GPUs without having to worry about the specific hardware architecture.
In addition to their specialized functions, GPUs also benefit from advancements in hardware technologies. Manufacturers are constantly improving the design of GPUs, increasing the number of cores, improving memory bandwidth, and incorporating more advanced features for efficient parallel processing.
It is important to note that while GPUs excel in tasks that leverage their specialized functions, they may not perform as well as CPUs in tasks that do not require parallel processing or involve strong single-threaded performance.
In the next sections, we will explore the role of memory bandwidth in the performance of GPUs and delve deeper into the factors that contribute to their faster performance.
Memory Bandwidth
Memory bandwidth is a crucial factor that contributes to the superior performance of Graphics Processing Units (GPUs) compared to Central Processing Units (CPUs). Memory bandwidth refers to the rate at which data can be read from or written to the memory. GPUs are designed with high memory bandwidth to efficiently handle the vast amount of data processed during graphics rendering and parallel computations.
GPUs utilize GDDR (Graphics Double Data Rate) memory, a specialized type of memory that offers significantly higher bandwidth compared to the DDR (Double Data Rate) memory typically used in CPUs. The high memory bandwidth of GPUs enables them to handle large datasets, perform complex calculations, and process graphics-intensive applications with ease.
Applications that require frequent data access, such as rendering high-resolution graphics or performing complex simulations, can greatly benefit from the high memory bandwidth offered by GPUs. The ability to quickly retrieve data from memory and feed it to the thousands of parallel cores allows GPUs to achieve remarkable speed and efficiency in these tasks.
Additionally, many GPUs employ memory management techniques, such as on-chip caches, to further optimize data access. These caches store frequently accessed data closer to the processor, reducing the need for accessing data from the main memory, and thereby improving the overall performance.
In contrast, CPUs typically have lower memory bandwidth relative to GPUs. However, they compensate for it with other features, such as larger cache sizes and advanced memory management techniques, that optimize performance for general-purpose computing tasks.
While CPUs may excel in tasks that have lower memory requirements or favor strong single-threaded performance, such as web browsing or general office productivity, GPUs shine in applications that heavily rely on memory bandwidth. This includes tasks like video editing, 3D rendering, scientific simulations, and machine learning, where the processing of massive amounts of data is crucial.
As technology advances, advances in memory technology and the architecture of CPUs and GPUs continue to enhance memory bandwidth. This contributes to the overall improvement in performance, allowing both CPUs and GPUs to handle increasingly demanding computational tasks.
In the next sections, we will summarize the key points discussed so far and provide a comprehensive understanding of why GPUs are faster than CPUs in certain scenarios.
Conclusion
In conclusion, Graphics Processing Units (GPUs) outperform Central Processing Units (CPUs) in certain scenarios due to their unique architecture and specialized functions. GPUs are designed for parallel processing, with hundreds or even thousands of smaller cores that can execute multiple instructions simultaneously. This parallelism allows GPUs to handle highly parallel tasks more efficiently, such as graphics rendering, machine learning, and scientific simulations.
The architecture of GPUs sacrifices some sequential processing power in favor of parallelism, which is why CPUs may perform better in tasks that require strong single-threaded performance. GPUs excel in tasks that can be divided into smaller subtasks that can be processed concurrently across their numerous cores.
GPUs also possess specialized functions, such as vector operations and floating-point arithmetic, making them highly efficient for specific computations. They are supported by programming frameworks like CUDA and OpenCL, which enable developers to harness their parallel processing power effectively.
Another advantage of GPUs is their high memory bandwidth, which allows for quick access and processing of large datasets. The ability to efficiently retrieve and process data from memory contributes to the exceptional performance of GPUs in graphics-intensive applications and data-intensive computations.
It is important to note that CPUs and GPUs serve different purposes and excel in different types of tasks. CPUs are versatile and handle a wide range of computing tasks effectively, while GPUs specialize in parallel processing and offer remarkable speed and efficiency in applications that can leverage their architecture and features.
As technology continues to advance, both CPUs and GPUs are experiencing improvements in their architectures, memory technologies, and overall performance. The continuous evolution of these computing components contributes to a better computing experience and allows for more efficient execution of a wide range of computational tasks.
Overall, the choice between using a CPU or GPU depends on the specific requirements of the task at hand. By understanding the architectural differences, specialized functions, and strengths of CPUs and GPUs, developers and users can make informed decisions to optimize performance and enhance overall computing capabilities.
















