Introduction
Welcome to the world of recommendation systems in machine learning! In today’s digital era, we are surrounded by an overwhelming amount of information, products, and services. From online shopping to video streaming platforms, the options are endless. But how do we navigate through this vast landscape and find what we truly need or enjoy? This is where recommendation systems come into play.
A recommendation system is a powerful tool that helps users discover relevant items, whether it be products, movies, music, or even news articles. It is a technology that uses machine learning algorithms to analyze user preferences and behavior, and then generates personalized recommendations based on that analysis.
The main goal of a recommendation system is to provide users with a tailored experience, delivering suggestions that align with their unique interests and preferences. By leveraging the power of data analysis and machine learning, these systems can save users time and effort, and enhance their overall experience.
As you might imagine, recommendation systems have become an integral part of many popular platforms. E-commerce giants like Amazon and Netflix, for example, rely heavily on recommendation systems to drive sales and increase user engagement. These systems not only help users discover new products or movies they might like, but they also have a significant impact on the platform’s revenue and customer satisfaction.
In this article, we will delve into the workings of recommendation systems, exploring the different types, how they function, and the challenges they face. We will also touch upon the importance of data collection and preprocessing, feature extraction and representation, similarity calculation, and recommendation generation. Additionally, we will discuss evaluation metrics for recommendation systems and address privacy and ethical considerations.
By the end of this article, you will have a solid understanding of what recommendation systems are, how they work, and their significance in the digital landscape. So, let’s start our journey into the fascinating world of recommendation systems and uncover the secrets behind their recommendations.
What Is a Recommendation System?
A recommendation system, also known as a recommender system, is a machine learning technology that suggests relevant items to users based on their preferences, behavior, and historical data. These systems utilize algorithms to analyze vast amounts of data, such as user interactions, purchase history, and item attributes, in order to generate personalized recommendations.
The objective of a recommendation system is to assist users in finding items that align with their interests and needs. Whether it’s suggesting a new book to read, a movie to watch, or a product to purchase, recommendation systems aim to enhance user experience by presenting options that are most likely to be of interest or value to the user.
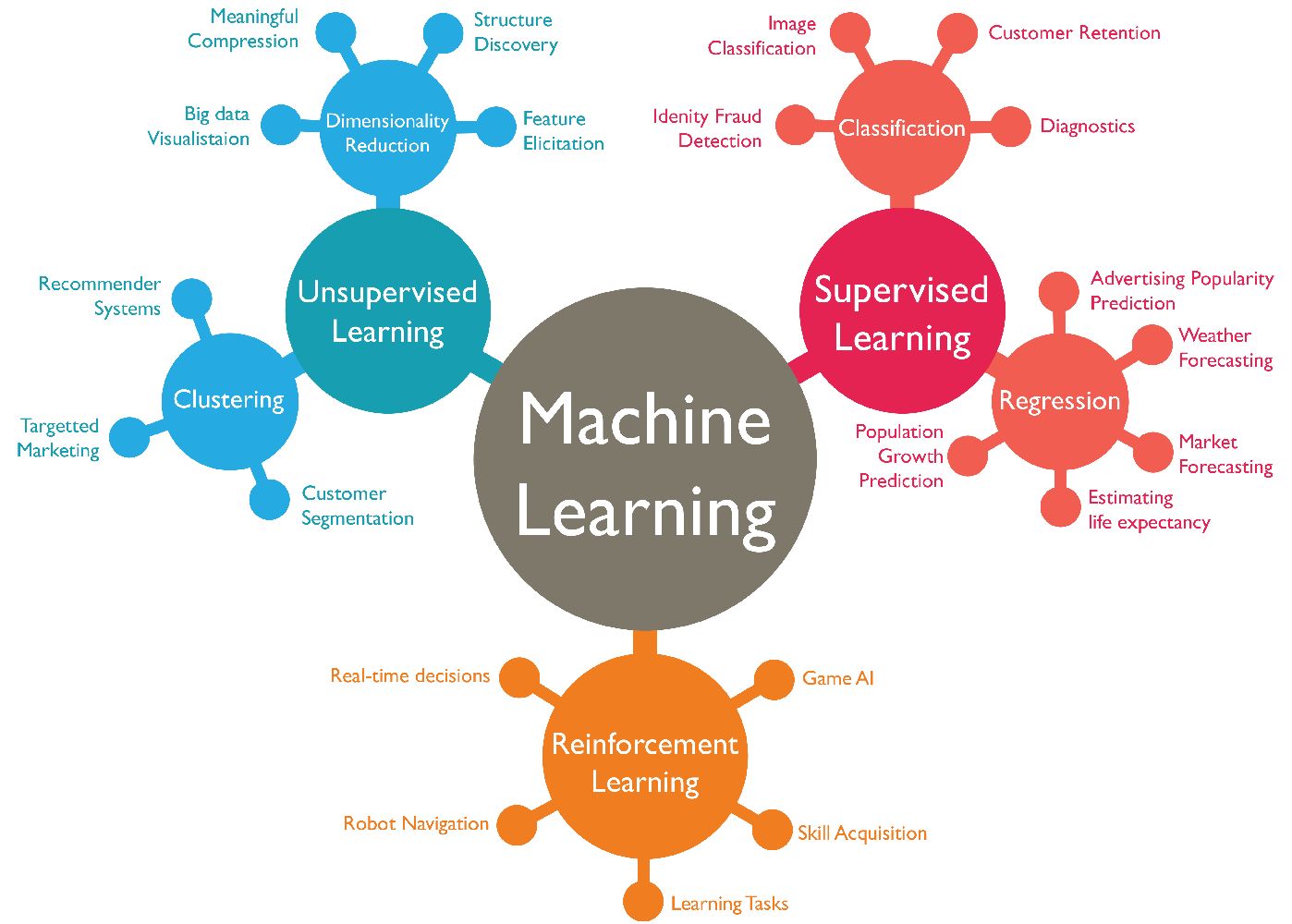
There are various types of recommendation systems, each utilizing different techniques and data sources to generate recommendations. The two main categories of recommendation systems are:
- Content-based Recommendation Systems: This approach analyzes the characteristics and attributes of items or content that a user has interacted with or shown an interest in. By understanding the features of items, such as genre, actors, or keywords, the system can recommend similar content to the user. For example, if a user enjoys watching action movies, the content-based recommendation system may suggest other action-packed films that match their preferences.
- Collaborative Filtering Recommendation Systems: Instead of relying on item attributes, collaborative filtering focuses on user behavior and preferences. By analyzing the historical data of multiple users and finding patterns or similarities in their interests, the system can recommend items that users with similar tastes have enjoyed. Collaborative filtering can be further divided into two subtypes: user-based collaborative filtering and item-based collaborative filtering.
Additionally, there are hybrid recommendation systems that combine elements of both content-based and collaborative filtering approaches. These systems aim to leverage the strengths of both techniques to provide more accurate and diverse recommendations.
Overall, recommendation systems play a crucial role in today’s digital landscape by helping users navigate through the overwhelming amount of available options. By understanding user preferences and analyzing vast troves of data, recommendation systems provide tailored suggestions that can save time, enhance discovery, and ultimately improve user satisfaction.
Types of Recommendation Systems
Recommendation systems come in various types, each employing different techniques and data sources to generate personalized recommendations for users. The two primary categories of recommendation systems are content-based recommendation systems and collaborative filtering recommendation systems. Let’s explore these categories in more detail:
Content-Based Recommendation Systems
A content-based recommendation system analyzes the characteristics and attributes of items or content that a user has interacted with or shown an interest in. By understanding the features of items, such as genre, actors, or keywords, the system can recommend similar content to the user. This approach offers recommendations based on the content itself, without relying on other users’ preferences.
For example, consider a user who frequently watches action movies. A content-based recommendation system can analyze the genre, actors, and other attributes of the action movies the user has enjoyed and suggest similar action-packed films that match their preferences. By focusing on item attributes, this type of recommendation system is particularly useful for users with specific tastes or preferences.
Collaborative Filtering Recommendation Systems
Collaborative filtering recommendation systems, on the other hand, focus on user behavior and preferences. These systems analyze the historical data of multiple users to find patterns or similarities in their interests and recommend items that users with similar tastes have enjoyed. Collaborative filtering can be further categorized into user-based collaborative filtering and item-based collaborative filtering.
User-based collaborative filtering focuses on similarities between users to generate recommendations. It identifies users who have shown similar preferences or interests in the past and suggests items that have been enjoyed by those similar users. For instance, if User A and User B have both rated and liked several action movies, user-based collaborative filtering can recommend action movies to User A that have been highly rated by User B.
Item-based collaborative filtering, on the other hand, focuses on similarities between items. The system identifies items that are frequently consumed or rated by the same users and recommends items that are similar to the ones the user has already shown interest in. For example, if a user frequently watches romantic comedies, item-based collaborative filtering can suggest other romantic comedies that have been popular among users who enjoy similar films.
Hybrid Recommendation Systems
In addition to the above categories, hybrid recommendation systems combine elements of both content-based and collaborative filtering approaches. These systems aim to leverage the strengths of both techniques to provide more accurate and diverse recommendations.
By incorporating both user preferences and item attributes, hybrid recommendation systems can overcome the limitations of using a single approach. They can offer personalized recommendations that take into account the user’s interests and preferences while considering the inherent characteristics and similarities of the items being recommended.
Although content-based recommendation systems, collaborative filtering recommendation systems, and hybrid recommendation systems are the main categories, there are other subcategories and variations depending on the specific algorithms and techniques used.
Understanding the different types of recommendation systems is crucial for businesses and platforms looking to provide personalized recommendations to their users. By employing the most suitable approach, organizations can enhance user satisfaction, increase engagement, and drive revenue by connecting users with the items or content that resonate with their preferences.
Content-based Recommendation Systems
Content-based recommendation systems are a type of recommendation system that analyzes the characteristics and attributes of items or content that a user has interacted with or shown an interest in. This approach focuses on the content itself, without relying on other users’ preferences. By understanding the features of items, such as genre, actors, keywords, or item descriptions, content-based recommendation systems can recommend similar items to the user.
The key idea behind content-based recommendation systems is that if a user enjoys certain types of content, they are likely to enjoy similar content that possesses similar attributes or features. For example, if a user has watched and rated several action movies, a content-based recommendation system can analyze the specific attributes of those action movies, such as high-intensity action sequences, a particular actor, or a specific genre. Based on these attributes, the system can then suggest other action-packed films that match the user’s preferences.
One of the main advantages of content-based recommendation systems is their ability to offer personalized recommendations even for niche or less popular items. Since these systems focus on item attributes and characteristics, they can recommend items based on specific details that may not be as evident or noticeable to other users.
To build an effective content-based recommendation system, several steps are involved:
- Data Collection and Preprocessing: The system gathers data about items and the attributes that describe them. This data can be obtained from various sources, such as metadata, user interactions, or user feedback.
- Feature Extraction and Representation: The next step is to extract relevant features from the collected data. For example, in the case of movies, features might include the genre, director, cast members, summary, or keywords. These features help to describe the unique qualities of each item.
- Similarity Calculation: Once the features are extracted, the system calculates the similarity between items. This is done by comparing the features of one item to those of other items. Various techniques, such as cosine similarity or Jaccard similarity, can be used for this purpose.
- Recommendation Generation: Based on the calculated similarities, the system then generates recommendations by selecting items that are most similar to the ones the user has shown interest in. The highest-rated or most relevant items are typically recommended to the user.
While content-based recommendation systems have proven to be effective in many scenarios, they also have certain limitations. One limitation is the potential for overfitting, where the system recommends only similar items and fails to introduce diversity or novelty into the recommendations. Additionally, content-based recommendation systems typically rely on accurate and detailed item attributes, which may not always be available or accurately represented in the data.
Despite these limitations, content-based recommendation systems play a significant role in providing personalized recommendations to users. By leveraging the attributes and characteristics of items, these systems can offer tailored suggestions that resonate with the unique interests and preferences of individual users.
Collaborative Filtering Recommendation Systems
Collaborative filtering recommendation systems are a type of recommendation system that focuses on user behavior and preferences. These systems analyze the historical data of multiple users to find patterns or similarities in their interests and recommend items based on those similarities. Collaborative filtering does not rely on attributes or features of the items themselves, but rather on the collective wisdom of users.
The fundamental idea behind collaborative filtering is that users who have shown similar preferences or behaviors in the past are likely to have similar tastes in the future. Based on this assumption, collaborative filtering recommendation systems can generate recommendations by identifying users with similar interests and suggesting items that these similar users have enjoyed.
Collaborative filtering can be further categorized into user-based collaborative filtering and item-based collaborative filtering:
User-based Collaborative Filtering:
User-based collaborative filtering focuses on similarities between users to generate recommendations. It starts by identifying users who have exhibited similar behaviors or preferences in the past. For example, if User A and User B have both rated and liked several action movies, user-based collaborative filtering can recommend action movies to User A that have been highly rated and enjoyed by User B.
To achieve this, the system calculates the similarity between users by measuring the overlap or similarity of their item ratings. Various techniques, such as cosine similarity or Pearson correlation coefficient, can be used to determine the similarity between users. Once the similarities are calculated, the system can generate recommendations by selecting items that are highly rated by similar users but have not been rated by the target user.
Item-based Collaborative Filtering:
Item-based collaborative filtering, in contrast, focuses on similarities between items. Instead of analyzing user similarities, this approach identifies items that are frequently consumed or rated by the same users. By examining the patterns of user interactions, the system can recommend items that are similar to the ones the user has already shown interest in. For example, if a user frequently watches romantic comedies, item-based collaborative filtering can suggest other romantic comedies that have been popular among users who enjoy similar films.
Similar to user-based collaborative filtering, item-based collaborative filtering calculates the similarity between items using techniques such as cosine similarity or Jaccard similarity. Once the similarities are determined, the system can generate recommendations by selecting items that are similar to the ones the user has interacted with or rated highly.
Collaborative filtering recommendation systems are known for their ability to provide personalized recommendations even for users with unique or niche interests. By leveraging the collective intelligence of users, these systems can offer suggestions that align with the preferences and behaviors of individual users, even without detailed information about item attributes or content.
However, collaborative filtering systems also face challenges such as the cold start problem, where recommendations for new users or items may be limited, and the sparsity problem when the amount of available user-item interaction data is insufficient. Nonetheless, collaborative filtering remains a widely used and effective approach in generating personalized recommendations in various domains.
Hybrid Recommendation Systems
Hybrid recommendation systems are a type of recommendation system that combines elements of both content-based and collaborative filtering approaches. By leveraging the strengths of both techniques, hybrid systems aim to provide more accurate and diverse recommendations that cater to the unique preferences and needs of individual users.
While content-based recommendation systems focus on item attributes and characteristics, collaborative filtering recommendation systems analyze user behavior and preferences. By combining these two approaches, hybrid recommendation systems can overcome their individual limitations and enhance the quality of recommendations.
The key idea behind hybrid recommendation systems is to utilize the content-based approach to provide personalized recommendations based on item attributes and then integrate collaborative filtering techniques to enhance the relevance and diversity of the recommendations.
There are various ways in which content-based and collaborative filtering techniques can be combined in a hybrid recommendation system:
- Weighted Hybrid: In a weighted hybrid approach, the recommendations from the content-based and collaborative filtering systems are assigned different weights. These weights are used to balance the influence of each system on the final recommendation. For example, if the system determines that the user’s preferences are better captured by collaborative filtering, the collaborative filtering recommendations may be given a higher weight.
- Switching Hybrid: A switching hybrid approach involves utilizing either the content-based or collaborative filtering system based on certain conditions or user contexts. For example, the system may switch to collaborative filtering when there is not enough content information available for a new user or item. This approach allows for flexibility and adaptation depending on the availability and quality of data.
- Feature Combination: In this approach, the features extracted from the content-based system are combined with user-item interaction data from the collaborative filtering system. By incorporating both types of information, the hybrid system can generate recommendations that consider both item attributes and user preferences.
- Meta-level Hybrid: In a meta-level hybrid approach, the recommendations generated by the content-based and collaborative filtering systems are treated as inputs to a higher-level recommendation model. This model then utilizes the strengths and preferences of the individual systems to generate a final recommendation. Meta-level hybrid models can help address the limitations of individual systems by capturing a more comprehensive understanding of user preferences.
By combining content-based and collaborative filtering techniques, hybrid recommendation systems can offer more accurate and diverse recommendations. They can leverage the benefits of content-based systems, such as dealing with the cold-start problem and providing personalized recommendations, while also incorporating collaborative filtering to capture the collective wisdom of users and introduce serendipity into recommendations.
Hybrid recommendation systems are widely used in real-world applications, particularly in e-commerce and entertainment platforms, where providing relevant and personalized recommendations is crucial for user engagement and satisfaction. These systems continue to evolve and incorporate other techniques, such as deep learning or reinforcement learning, to further improve the accuracy and effectiveness of recommendations.
How Do Recommendation Systems Work?
Recommendation systems work by utilizing complex algorithms and techniques to analyze user data, item attributes, and user-item interactions in order to generate personalized recommendations. The process of how recommendation systems work can be broken down into several key steps:
Data Collection and Preprocessing:
The first step in building a recommendation system is to collect and preprocess the necessary data. This data can include user profiles, item attributes, and historical user-item interactions. The data is then organized and transformed into a suitable format for further analysis.
Feature Extraction and Representation:
Once the data is collected, the next step is to extract relevant features from the collected data. These features can vary depending on the type of recommendation system and the domain it operates in. For example, in a movie recommendation system, the features might include genre, actors, director, and user ratings.
The extracted features are then represented in a structured format that can be easily processed by machine learning algorithms. This representation helps in capturing the distinguishing attributes and characteristics of items and users.
Similarity Calculation:
After feature extraction, the recommendation system calculates the similarity between items or users. Various similarity measures, such as cosine similarity, Euclidean distance, or Jaccard index, can be used to determine the similarity.
For content-based recommendation systems, the similarity is calculated based on the attributes or features of items. Items with similar attributes or characteristics are considered to be more similar. In collaborative filtering recommendation systems, the similarity is calculated based on the overlap or similarity of user-item interactions. Users who have similar preferences or behaviors are considered to be more similar.
Recommendation Generation:
Based on the calculated similarities, the recommendation system generates recommendations. The specific algorithm or technique used for generating recommendations varies depending on the type of recommendation system.
In content-based recommendation systems, the system recommends items that are similar to the ones the user has shown interest in. For example, if a user has watched and liked several action movies, the system might recommend other action films with similar attributes.
In collaborative filtering recommendation systems, the system recommends items that have been enjoyed by users with similar preferences. It identifies users who have shown similar behaviors or have similar taste and suggests items that these similar users have enjoyed. For example, if User A has rated and liked similar items as User B, the system might recommend other items highly rated by User B to User A.
Feedback and Adaptation:
Recommendation systems also incorporate feedback from users to further refine the recommendations. User feedback, such as explicit ratings or implicit feedback like purchases or clicks, is collected and used to improve the system’s understanding of the user’s preferences and to adjust the recommendations accordingly.
Additionally, recommendation systems often employ techniques such as reinforcement learning or bandit algorithms to continually learn and adapt based on the users’ responses and interactions with the recommendations.
Overall, recommendation systems rely on advanced machine learning and data analysis techniques to analyze user data, item attributes, and user-item interactions. By understanding the similarities between items or users, recommendation systems can generate personalized recommendations that match the unique preferences and needs of individual users.
Data Collection and Preprocessing
Data collection and preprocessing are vital steps in building a recommendation system. These steps involve gathering relevant data and transforming it into a suitable format for further analysis. The data used in recommendation systems can be categorized into user data, item data, and user-item interactions.
User Data: User data includes information about the users of the recommendation system. This data can consist of user profiles, demographic information, preferences, and past user interactions. User data helps provide a personalized experience by understanding each user’s unique tastes and preferences.
Item Data: Item data refers to information about the items or products being recommended. This data can include attributes such as genre, actors, directors, authors, release dates, or item descriptions. Item data plays a crucial role in content-based recommendation systems, where recommendations are based on the characteristics and attributes of items.
User-Item Interactions: User-item interaction data encompasses the historical interactions between users and items in the recommendation system. This data reflects the preferences and behaviors of users, including ratings, reviews, purchases, clicks, or views. User-item interaction data is particularly important in collaborative filtering recommendation systems, where similarities between users or items are determined based on past interactions.
Once the necessary data is collected, the next step is preprocessing the data. Preprocessing involves cleaning, transforming, and organizing the data to make it ready for analysis. The following steps are typically involved in data preprocessing for recommendation systems:
- Data Cleaning: Data cleaning involves removing any irrelevant, duplicate, or noisy data from the dataset. Outliers or inconsistent data points are also handled during this stage.
- Feature Selection: In this step, the most relevant features for recommendation are selected from the collected data. The selected features should be informative and capture the distinguishing characteristics of items or users.
- Data Transformation: Data transformation involves converting data into a suitable format for analysis. This can include scaling numerical features, encoding categorical variables, or normalizing data distributions.
- Merging and Integration: In some cases, data from multiple sources may need to be merged or integrated to create a comprehensive dataset. This step ensures that all relevant data is combined and ready for analysis.
- Data Split: To evaluate the performance of a recommendation system, the dataset is often split into training and testing sets. The training set is used to train the recommendation system, while the testing set is used to evaluate its performance and measure the accuracy of recommendations.
Data collection and preprocessing are critical steps in building a robust and accurate recommendation system. The quality and relevance of the data directly impact the effectiveness of the recommendations generated. Proper preprocessing ensures that the data is clean, organized, and appropriate for subsequent analysis, enabling recommendation systems to provide meaningful and personalized recommendations to users.
Feature Extraction and Representation
Feature extraction and representation are essential steps in building a recommendation system. These steps involve extracting relevant features from the collected data and representing them in a suitable format for further analysis. The extracted features help describe the unique qualities and characteristics of items or users, enabling the recommendation system to understand their preferences and make accurate recommendations.
Item Features: For content-based recommendation systems, extracting item features is a crucial aspect. Item features can include attributes such as genre, actors, directors, release dates, item descriptions, or even textual data like keywords or tags. These features capture the distinctive qualities of the items being recommended. For example, in a movie recommendation system, the genre, actors, and director can be important features that define the content of a movie.
User Features: Understanding the characteristics of users is equally important in recommendation systems. User features can include demographic information, preferences, past ratings, or behavioral traits. By extracting user features, the recommendation system gains insights into each user’s unique tastes and preferences. For example, user features like age, gender, or location might play a role in influencing the recommended items.
Once the relevant features are identified, they need to be represented in a suitable format that can be processed by machine learning algorithms. Common techniques for feature representation include:
- Vectorization: Vectorization is a popular method for representing features in recommendation systems. Each item or user is represented as a vector, where each dimension of the vector corresponds to a specific feature. The values in the vector reflect the presence or absence of a particular feature or can be numerical values representing attributes. Vectorization allows for efficient computation and similarity calculations between items or users.
- One-Hot Encoding: One-hot encoding is a technique used to represent categorical features. Each category is represented by a binary value, where a 1 indicates the presence of that category and a 0 indicates its absence. For example, in a movie recommendation system, the genre feature can be represented using one-hot encoding, where each genre is represented as a binary value in the item vector.
- Embeddings: Embeddings are dense, low-dimensional representations of features that capture the semantic relationships between items or users. Through techniques like word embeddings or matrix factorization, embeddings can be generated that provide a more nuanced and contextual understanding of item or user characteristics. Embeddings are widely used in recommendation systems to capture complex and subtle relationships between features.
The choice of feature representation technique depends on the nature of the data and the specific requirements of the recommendation system. Different techniques may be employed for different types of features within the same recommendation system.
By extracting and representing relevant features, recommendation systems are able to capture the distinguishing attributes of items or users. These features serve as inputs to machine learning algorithms, enabling the system to understand user preferences, identify similar items or users, and ultimately generate personalized recommendations that align with each user’s unique tastes and needs.
Similarity Calculation
Similarity calculation is a crucial step in recommendation systems that involves quantifying the similarity between items or users. The similarity measures help determine the degree of relatedness between items or users, which enables the recommendation system to identify similar items for content-based recommendation systems or similar users for collaborative filtering recommendation systems.
There are several techniques and similarity measures used in recommendation systems:
Cosine Similarity: Cosine similarity is a widely used measure for calculating similarity in recommendation systems. It calculates the cosine of the angle between two vectors representing items or users. Since recommendation systems often represent items or users as vectors, cosine similarity provides a measure of how similar their attributes or preferences are. A value close to 1 indicates high similarity, while a value close to 0 indicates low similarity.
Pearson Correlation: Pearson correlation coefficient is another similarity measure used in recommendation systems. It calculates the linear correlation between two sets of data points. In collaborative filtering recommendation systems, Pearson correlation is often used to measure the similarity between users based on their ratings or preferences for different items. A positive value indicates positive correlation, meaning similar preferences, while a negative value indicates negative correlation, suggesting dissimilar preferences.
Jaccard Similarity: Jaccard similarity is commonly used to measure the similarity between sets. It calculates the ratio of the intersection of two sets to the union of the sets. In recommendation systems, Jaccard similarity is used to measure the overlap between sets of items or user preferences. It is particularly beneficial in collaborative filtering recommendation systems to identify similar users based on common item interactions.
Euclidean Distance: Euclidean distance is a distance metric used to measure the dissimilarity between items or users. It calculates the square root of the sum of squared differences between corresponding attributes or preferences. A smaller distance indicates higher similarity, while a larger distance indicates lower similarity. Euclidean distance is useful in content-based recommendation systems for measuring the dissimilarity between item attributes.
These are just a few examples of similarity measures used in recommendation systems, and the choice of measure depends on the specific nature of the data and the requirements of the system.
Once the similarity is calculated, it is used to identify similar items for content-based recommendation systems or similar users for collaborative filtering recommendation systems. For content-based systems, items with higher similarity to a given item indicate a higher likelihood that users who have shown interest in one item may also be interested in the similar item. In collaborative filtering systems, users with higher similarity to a target user indicate similar preferences, and their preferences are used to generate recommendations for the target user.
Similarity calculation is a fundamental step in recommendation systems as it allows for the identification of similar items or users based on their attributes or behavior. By quantifying similarity, recommendation systems can generate accurate and relevant recommendations that match the preferences and needs of individual users.
Recommendation Generation
Recommendation generation is a critical step in the recommendation systems pipeline. After collecting and preprocessing the data, extracting relevant features, and calculating similarity, the recommendation system moves on to generating personalized recommendations for users. At this stage, the system utilizes the calculated similarities and the user’s preferences to identify and present items that are likely to be of interest.
There are several methods and techniques used for recommendation generation:
Content-Based Recommendation: In content-based recommendation systems, recommendations are generated by identifying items that are similar to the ones the user has shown interest in. The system analyzes the user’s historical preferences, ratings, or interactions to understand their preferences and use that information to find similar items with matching attributes or characteristics. For example, if a user has rated and enjoyed several action movies, the system can recommend other action films with similar attributes or themes.
Collaborative Filtering Recommendation: Collaborative filtering recommendation systems generate recommendations by leveraging the preferences of similar users or items. Based on the similarity metrics calculated between users or items, the system identifies users or items with similar tastes and recommends items that those similar users or items have enjoyed. For instance, if User A and User B have similar preferences and User B highly rates a specific movie, collaborative filtering recommends that movie to User A.
Hybrid Recommendation: Hybrid recommendation systems combine multiple approaches and techniques to generate recommendations. They incorporate both content-based and collaborative filtering methods to provide more accurate and diverse recommendations. These systems aim to leverage the strengths of both approaches, considering both item attributes and user preferences in generating recommendations. The final recommendations are often a combination of content-based and collaborative filtering results, either by assigning weights to the results or through a higher-level recommendation model.
Once the recommendation system has identified the items to be recommended, it presents them to the user. The presentation can be in the form of a list, a personalized homepage, or pop-up suggestions, depending on the platform or application where the recommendation system is implemented.
It’s important to note that recommendation generation is an iterative process. Feedback from users, such as explicit ratings or implicit interactions, is collected and used to refine the recommendation system over time. By incorporating user feedback, the system continuously learns and adapts to better understand the user’s preferences and improve the quality of recommendations.
Recommendation generation is the ultimate goal of a recommendation system. By combining the user’s preferences, the calculated similarities, and the available item data, the system generates personalized recommendations that aim to match the user’s interests, increase engagement, and enhance the overall user experience.
Evaluation Metrics for Recommendation Systems
Evaluating the performance and effectiveness of recommendation systems is crucial to ensure the generation of accurate and useful recommendations. Various evaluation metrics are used to assess the quality of recommendations and measure how well the system is meeting user needs. These metrics provide insights into the accuracy, relevance, and diversity of the recommendations being generated. Here are some commonly used evaluation metrics for recommendation systems:
Precision: Precision measures the proportion of relevant recommendations among all the recommendations made. It calculates the ratio of the number of correctly recommended items to the total number of recommended items. Precision is often used to evaluate the accuracy of recommendations and is especially important in scenarios where the user’s attention is limited (e.g., top-n recommendations).
Recall: Recall measures the proportion of relevant items that have been recommended. It calculates the ratio of the number of correctly recommended items to the total number of relevant items. Recall is particularly useful when the goal is to ensure that all relevant items are included in the recommendations, such as in comprehensive recommendation scenarios.
F1 Score: The F1 score is the harmonic mean of precision and recall. It provides a single metric that balances both precision and recall. The F1 score is useful when there is a need to consider both precision and recall simultaneously, providing an overall measure of recommendation quality.
Mean Average Precision (MAP): MAP calculates the average precision across multiple users or queries. It takes into account both the relevance of the recommended items and their ranking. MAP is commonly used in information retrieval to evaluate the quality of ranked lists, and it provides a comprehensive measure of recommendation performance across different user scenarios.
Mean Reciprocal Rank (MRR): MRR measures the ranking performance of a recommendation system. It calculates the average reciprocal rank of the first relevant item in the recommendation list. MRR is useful when the order of recommendations is important, such as in cases where the main objective is to provide the most relevant items at the top of the list.
Novelty: Novelty measures how diverse and original the recommended items are. It assesses the system’s ability to introduce fresh and lesser-known items to users, rather than repeatedly recommending popular or well-known items. Evaluating the novelty of recommendations helps ensure that users are exposed to a wider range of items and encourages serendipitous discoveries.
Evaluation metrics can be applied using offline evaluation approaches, where historical data is used to simulate recommendation scenarios, or through online evaluations, where users provide feedback on the quality of recommendations. Using multiple evaluation metrics provides a comprehensive understanding of the performance of a recommendation system, allowing for continuous improvements and iterations.
It’s important to note that the choice of evaluation metrics depends on the specific goals and characteristics of the recommendation system. Different domains and applications may require different evaluation metrics to assess the relevance, accuracy, diversity, or other desired aspects of recommendations.
By employing appropriate evaluation metrics, developers and researchers can assess and optimize the performance of recommendation systems, ensuring that the generated recommendations effectively meet the needs and preferences of users.
Challenges in Recommendation Systems
While recommendation systems have proven to be powerful tools in generating personalized recommendations, they also face several challenges that need to be addressed to ensure their effectiveness and user satisfaction. Understanding and mitigating these challenges is essential for building robust and accurate recommendation systems. Here are some common challenges faced by recommendation systems:
Cold Start Problem: The cold start problem occurs when a recommendation system has limited or no information about a new user or item. In such cases, the system struggles to provide accurate and relevant recommendations due to a lack of data. Overcoming the cold start problem requires mechanisms to gather initial user or item information, such as through explicit user preferences or leveraging metadata and attributes of items.
Data Sparsity: Data sparsity refers to the situation where the available user-item interaction data is insufficient or sparse. When user-item interactions are sparse, it becomes challenging to identify meaningful patterns or similarities between users or items. Techniques like matrix completion, collaborative filtering with regularization, or incorporating side information can help address the data sparsity problem in recommendation systems.
Scalability: Recommendation systems often deal with large-scale datasets and numerous users and items, which poses scalability challenges. Processing and analyzing such vast amounts of data require efficient algorithms and infrastructure. Distributed systems, parallel computing, and data sampling techniques are employed to address scalability challenges in recommendation systems.
Privacy and Ethics: Recommendation systems have access to sensitive user data, which raises concerns regarding privacy and ethical considerations. Protecting user privacy and ensuring ethical use of user data is vital. Techniques like differential privacy, data anonymization, and user control over data sharing can help mitigate these concerns and establish trust with users.
Filter Bubble: The filter bubble is a phenomenon where users are exposed to a limited set of recommendations that align with their existing preferences, resulting in a narrow view of information and potential bias. Over-reliance on personalization can lead to missed opportunities for users to discover diverse perspectives and serendipitous recommendations. Techniques like serendipity-enhancing algorithms, diversity-aware recommendation strategies, and user-controlled filters can help combat the filter bubble challenge.
Dynamic and Evolving Preferences: User preferences are dynamic and change over time. Recommendation systems need to adapt to changing user preferences to provide up-to-date and relevant recommendations. Techniques like sequential recommendation, session-based recommendation, and real-time updating of user profiles can address the challenge of dynamic and evolving preferences.
Addressing these challenges requires continuous research and innovation in recommendation system development. Techniques from machine learning, data mining, natural language processing, and human-computer interaction are applied to tackle these challenges and enhance the performance and usability of recommendation systems.
By understanding and overcoming these challenges, developers and researchers can build recommendation systems that are more accurate, diverse, privacy-aware, and capable of providing meaningful recommendations to users in various domains.
Privacy and Ethical Considerations in Recommendation Systems
Privacy and ethical considerations play a crucial role in the design, development, and deployment of recommendation systems. As recommendation systems rely on user data to generate personalized recommendations, protecting user privacy and ensuring ethical use of data are paramount. Here are some key privacy and ethical considerations in recommendation systems:
User Data Privacy: Recommendation systems often access and analyze sensitive user data, including personal information, browsing history, and purchase behavior. Protecting user data privacy is essential to establish trust between users and recommendation systems. Safeguarding user data through secure storage, data anonymization, and compliance with privacy regulations such as GDPR or CCPA is imperative to maintain user trust and confidentiality.
User Consent and Control: Providing users with control over their data and the ability to provide informed consent is important in recommendation systems. Users should have the option to opt in or opt out of data collection, choose the level of personalization, and be aware of how their data is being used. Transparency in data collection and giving users the ability to manage their data preferences fosters trust and empowers users to make informed decisions.
Fairness and Bias: Recommendation systems should be designed to address biases and promote fairness. Algorithms should not discriminate based on race, gender, religion, or other protected characteristics. Biases present in training data should be identified and addressed to avoid perpetuating biased recommendations. Regular monitoring and evaluation of recommendation algorithms for fairness can help mitigate potential bias and discrimination.
Serendipity and Diversity: Recommendation systems have a responsibility to not only reinforce users’ existing preferences but also expose them to diverse perspectives and novel recommendations. Overemphasizing personalization can create filter bubbles and limit users’ exposure to new ideas. Incorporating techniques that promote serendipity, diversification, and exploration can help ensure that recommendation systems offer a broader range of options to users.
Algorithmic Transparency: Providing transparency about the functioning of recommendation algorithms is essential. Users should have visibility into the factors influencing the recommendations they receive. Explaining the rationale behind recommendations, providing clear disclosure about the use of user data, and offering options for recourse or feedback can foster transparency and accountability.
Evaluation of Recommendation System Impact: Continuous evaluation of the impact of recommendation systems is crucial to identify and address any unintended consequences or negative effects. Monitoring metrics related to user satisfaction, diversity of recommendations, and user feedback can help identify and mitigate algorithmic biases, mitigating the risks of uniformity and limited exposure to new content.
Addressing privacy and ethical considerations in recommendation systems requires ongoing vigilance, stringent data protection practices, and stakeholder collaboration. It is essential for developers and organizations deploying recommendation systems to prioritize user privacy, fairness, transparency, and accountability throughout the entire recommendation process.
By putting privacy and ethics at the forefront, recommendation systems can strive to provide user-centric experiences that respect user autonomy, protect sensitive information, and offer diverse and meaningful recommendations to users.
Conclusion
Recommendation systems have revolutionized the way users discover and engage with content, products, and services. By leveraging machine learning algorithms and analyzing vast amounts of data, these systems provide personalized recommendations that align with users’ preferences and needs. Whether it’s suggesting movies, books, or products, recommendation systems play a pivotal role in enhancing user experience and driving user engagement.
We explored different types of recommendation systems, including content-based, collaborative filtering, and hybrid systems. Content-based recommendation systems analyze item attributes to suggest similar items, while collaborative filtering leverages user behavior and preferences to recommend items favored by similar users. Hybrid systems combine the strengths of both approaches to offer more accurate and diverse recommendations.
Understanding the inner workings of recommendation systems is essential for building effective and robust models. We discussed key steps such as data collection and preprocessing, feature extraction and representation, similarity calculation, and recommendation generation. These steps involve meticulous data processing, extracting relevant features, determining similarities, and generating personalized recommendations that align with user preferences.
Evaluation metrics are used to measure the performance and quality of recommendation systems. Metrics such as precision, recall, F1 score, mean average precision, and mean reciprocal rank help assess accuracy, relevance, and diversity of recommendations. Continual evaluation ensures recommendation systems adapt and improve over time to better suit user needs.
However, recommendation systems also face challenges such as the cold start problem, data sparsity, privacy concerns, filter bubbles, and dynamic user preferences. These challenges require ongoing research and innovation to address issues of privacy protection, fairness, transparency, and serendipity, among others.
Privacy and ethical considerations are of utmost importance in recommendation systems. Protecting user data privacy, obtaining informed consent, ensuring fairness and diversity, promoting algorithmic transparency, and actively evaluating system impact are crucial aspects to uphold trust, user autonomy, and responsible use of data.
In conclusion, recommendation systems have become integral in various domains, guiding users to tailored recommendations and facilitating their exploration. By continuously addressing challenges and incorporating privacy and ethical considerations, recommendation systems can deliver personalized experiences that benefit users and uphold their rights and preferences.