Introduction
A classifier is a fundamental component of machine learning, a branch of artificial intelligence that enables computers to identify patterns and make predictions based on data. In simple terms, a classifier is like an algorithmic model that learns from past data to classify or categorize new data points into predefined classes or categories. This enables computers to recognize and classify various objects, events, or phenomena, based on their characteristics and features.
Classifiers play a crucial role in many real-world applications, ranging from email spam filtering to medical diagnosis and fraud detection. They are widely used in industries such as finance, healthcare, marketing, and cybersecurity, to name a few. By leveraging the power of machine learning, classifiers enable businesses and organizations to automate decision-making processes and gain valuable insights from data.
At its core, a classifier analyzes patterns and relationships within a dataset to assign new data points to relevant categories or labels. It uses a set of predefined features or attributes to make predictions and distinguish between different classes. These features can include numerical values, textual data, or even images and audio signals, depending on the nature of the problem and the type of classifier being used.
Machine learning classifiers can be trained using various algorithms, such as decision trees, support vector machines (SVM), k-nearest neighbors (KNN), and neural networks. Each algorithm has its strengths and weaknesses, and selecting the most appropriate one depends on the specific problem and the available data.
One of the key factors in building an effective classifier is feature selection. By carefully choosing the most relevant and informative features, a classifier can achieve higher accuracy and performance. Additionally, classifiers can be trained using labeled data (supervised learning) or without labeled data (unsupervised learning), depending on the availability of training samples.
Overall, classifiers are a vital tool in machine learning, enabling computers to make sense of vast amounts of data and make accurate predictions. They provide valuable insights, automate decision-making processes, and drive innovation across diverse industries. As the field of machine learning continues to advance, classifiers will continue to play a crucial role in transforming the way we interact with data and make informed decisions.
Definition of a Classifier
A classifier is a fundamental concept in machine learning that refers to an algorithm or a model capable of determining the class or category of an input based on its characteristics and features. In other words, it is a tool that enables computers to learn from existing data and classify new data into predefined classes or categories.
The process of classification involves training a classifier with a labeled dataset, where each data point is associated with a known class or category. The classifier analyzes the patterns and relationships in the data and builds a model that can then be used to predict the class of new, unseen data.
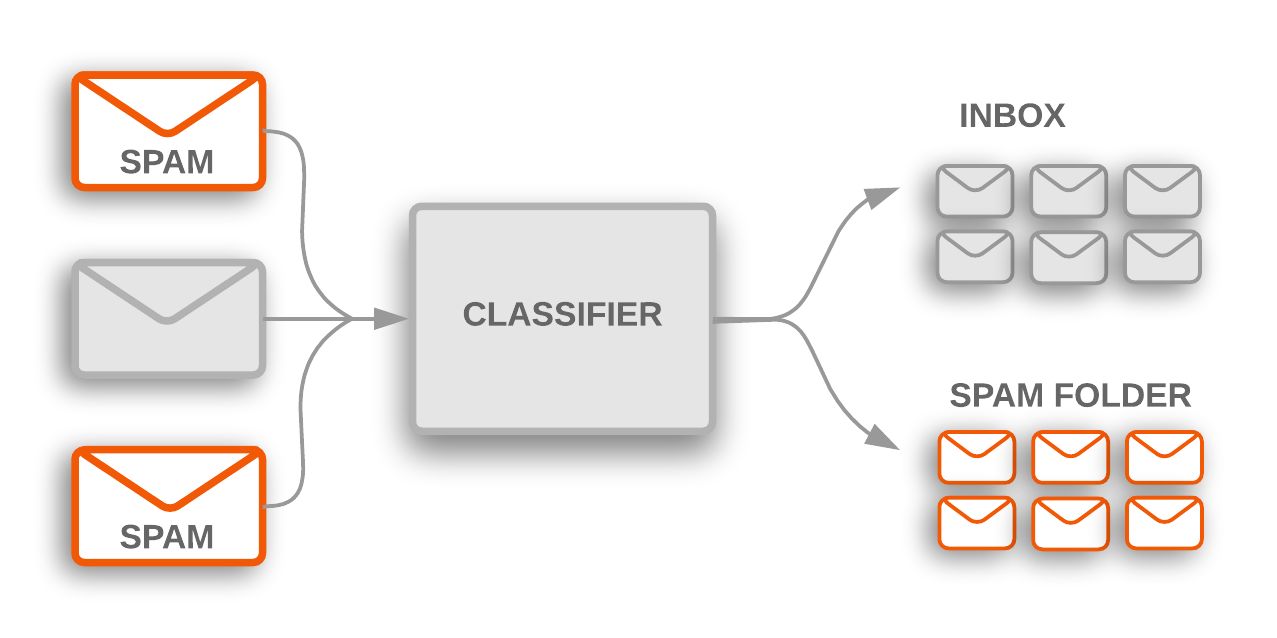
To understand this concept better, let’s consider an example. Suppose we have a dataset of emails, some of which are spam and others are legitimate. By training a classifier with this labeled data, the algorithm can learn to distinguish between spam and non-spam emails based on various features, such as the presence of certain keywords, the structure of the email, or the sender’s information. Once trained, the classifier can be used to predict whether a new email is spam or not.
Classifiers are designed to work with different types of data, depending on the problem at hand. They can handle numerical data, such as the age or income of a person, as well as categorical data, such as the type of car or the color of a dress. Furthermore, classifiers can also process textual data, images, audio signals, and other forms of data, making them versatile tools in the field of machine learning.
It’s important to note that the effectiveness of a classifier depends on the quality and relevance of the features used for classification. Selecting the right features is crucial for achieving accurate predictions. Additionally, the choice of the classifier algorithm itself plays a significant role in the performance of the model. Different algorithms have different strengths and weaknesses, and selecting the most appropriate one depends on the nature of the problem and the available data.
In summary, a classifier is an algorithm or model that utilizes machine learning techniques to classify new data into predefined categories or classes based on its characteristics and features. By training the classifier with labeled data, it can learn to recognize patterns and make accurate predictions. Classifiers are powerful tools that enable computers to automate decision-making processes and handle vast amounts of data across various domains.
How Does a Classifier Work?
A classifier works by learning patterns and relationships within a dataset and using that knowledge to make predictions or classify new, unseen data. The process of classification involves several steps and can vary depending on the specific classifier algorithm being used. However, the general workflow of a classifier can be summarized as follows:
- Data Collection and Preprocessing: The first step is to gather a dataset that contains both the input data and the corresponding labels or categories. This dataset is split into two parts: the training set, used to train the classifier, and the test set, used to evaluate its performance. The collected data may need to be preprocessed to remove noise, handle missing values, or normalize the features.
- Feature Extraction and Selection: Once the data is preprocessed, the next step is to extract or select relevant features that can effectively represent the input data. Feature extraction involves transforming the input data into a format that is easier for the classifier to work with. Feature selection, on the other hand, involves choosing the most informative features that contribute to the classification task.
- Training the Classifier: With the preprocessed training data and the selected features, the classifier is trained using a specific algorithm. The algorithm analyzes the patterns and relationships in the training data to build a model that can make predictions. The training process may involve adjusting internal parameters or weights to optimize the performance of the classifier.
- Evaluation and Validation: Once the classifier is trained, it is tested using the test set to evaluate its accuracy and performance. Various evaluation metrics, such as precision, recall, and accuracy, can be used to measure the classifier’s effectiveness. If the performance is satisfactory, the classifier is considered ready for deployment. If not, adjustments can be made to improve its performance, such as refining the feature selection process or trying different algorithms.
- Classification of New Data: After the classifier is trained and validated, it can be used to classify new, unseen data. The input data is processed using the same feature extraction techniques applied during training, and the classifier uses its learned model to predict the corresponding class or category. The output of the classifier can be a single class prediction or a probability distribution over multiple classes.
It’s important to note that the accuracy and performance of a classifier depend on various factors such as the quality and relevance of the training data, the selection of features, the choice of the algorithm, and the degree of complexity of the classification problem. Therefore, it’s crucial to carefully design and train the classifier to achieve optimal results in real-world applications.
Types of Classifiers
There are various types of classifiers, each employing different algorithms and techniques to accomplish the task of classification. The choice of classifier depends on the nature of the problem, the available data, and the desired outcome. Here are some commonly used types of classifiers:
- Decision Trees: Decision trees are popular classifiers that make decisions based on a series of if-else conditions in a hierarchical structure. Each internal node represents a decision based on a feature, and each leaf node represents a class or category. Decision trees are easily interpretable and can handle both numerical and categorical data.
- Support Vector Machines (SVM): SVM is a powerful classifier that finds a hyperplane in a feature space to separate different classes. It aims to maximize the margin between the nearest data points of different classes. SVM is effective in handling complex datasets and has a strong theoretical foundation.
- k-Nearest Neighbors (KNN): KNN is a non-parametric classifier that classifies a new data point based on the majority vote of its k nearest neighbors in the feature space. KNN does not require training as it simply stores all the training data. It is simple to implement and works well with small to medium-sized datasets.
- Naive Bayes: Naive Bayes is a probabilistic classifier based on Bayes’ theorem. It assumes that all features are independent of each other, hence the “naive” assumption. Despite this simplification, Naive Bayes can produce good results and is particularly effective for text categorization tasks.
- Random Forest: Random Forest is an ensemble classifier that combines multiple decision trees to make predictions. Each tree is trained on a random subset of the data, and the final prediction is based on the majority vote of all the trees. Random Forest is robust against overfitting and can handle both categorical and numerical data.
- Neural Networks: Neural networks are a versatile class of classifiers commonly used for complex pattern recognition tasks. They consist of interconnected layers of artificial neurons that learn to map input data to output predictions through a process called training. Neural networks can handle large amounts of data and capture intricate relationships.
These are just a few examples of classifiers, and there are many other types and variations available. Each classifier has its own advantages and limitations, and the choice of classifier depends on the specific problem and the characteristics of the data. It’s important to explore different classifiers and select the one that fits the requirements of the task at hand.
Accuracy and Performance of a Classifier
The accuracy and performance of a classifier are crucial factors to consider when evaluating its effectiveness in solving a classification problem. Assessing a classifier’s performance involves measuring its ability to correctly classify data and estimating its predictive accuracy. Several metrics are commonly used to evaluate the accuracy and performance of a classifier:
- Accuracy: Accuracy is the most straightforward metric and represents the percentage of correctly classified instances in relation to the total number of instances. While accuracy is a useful measure, it may not provide a complete picture, especially when dealing with imbalanced datasets where one class dominates the others.
- Precision and Recall: Precision and recall are two important metrics used in binary classification. Precision calculates the percentage of correctly predicted positive instances among all instances predicted as positive, while recall calculates the percentage of correctly predicted positive instances among all actual positive instances. These metrics are particularly useful when the cost of false positive and false negative predictions is significantly different.
- F1 Score: The F1 score is the harmonic mean of precision and recall and provides a single value that represents the overall performance of a classifier in binary classification tasks. It balances the importance of precision and recall and is especially helpful when there is an uneven distribution of classes or when there is a need for one metric to summarize the classifier’s performance.
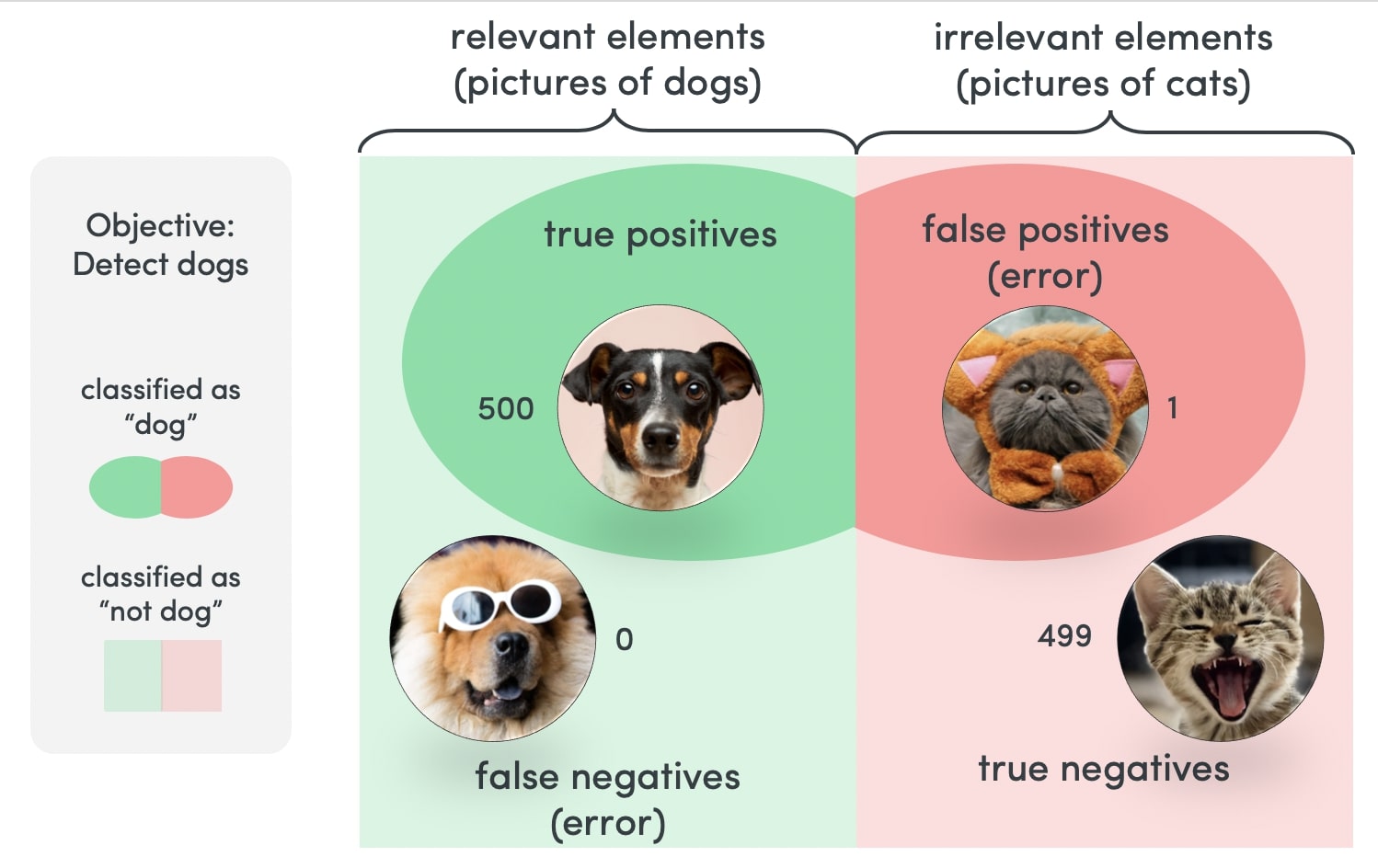
- Confusion Matrix: A confusion matrix presents a detailed view of a classifier’s performance by showing the number of true positive, true negative, false positive, and false negative classifications. It provides insights into the specific types of errors made by the classifier, helping to identify areas for improvement.
- Receiver Operating Characteristic (ROC) curve and Area Under the Curve (AUC): The ROC curve visualizes the trade-off between true positive rate and false positive rate by varying the classification threshold. The AUC represents the area under the ROC curve and provides a single value that summarizes the classifier’s performance. A higher AUC indicates better overall performance, with a perfect classifier achieving an AUC of 1.
Additionally, the performance of a classifier can be influenced by factors such as the quality and size of the training data, the choice of features, the complexity of the problem, and the specific classifier algorithm used. It’s important to carefully consider these factors and fine-tune the classifier to achieve optimal performance.
Furthermore, it’s worth noting that accuracy and performance can vary across different datasets and tasks. It’s recommended to evaluate the classifier’s performance using cross-validation or on independent test datasets to ensure its generalizability.
Overall, accuracy and performance metrics are essential for assessing the quality and effectiveness of a classifier. By considering these metrics, developers and practitioners can make informed decisions about the suitability of a classifier for a specific problem and optimize its performance to achieve accurate and reliable predictions.
Applications of Classifiers
Classifiers have a wide range of applications across various industries and domains. They enable machines to analyze and classify data, making automated decisions and predictions. Here are some prominent applications of classifiers:
- Email Spam Filtering: One of the most well-known applications of classifiers is email spam filtering. Classifiers can learn patterns and characteristics of spam messages from labeled data and accurately classify incoming emails as spam or legitimate. This helps users focus on important emails and reduces the risk of falling victim to phishing scams or malicious content.
- Disease Diagnosis and Healthcare: Classifiers play a vital role in medical diagnosis, helping doctors and healthcare professionals identify diseases and conditions. By training classifiers with patient data and associated diagnoses, patterns and markers can be learned, enabling accurate predictions and early detection of diseases such as cancer, diabetes, or heart conditions.
- Fraud Detection: Financial institutions and credit card companies use classifiers to detect fraudulent activities. By analyzing transaction data and historical patterns, classifiers can identify suspicious transactions and trigger alerts for further investigation, minimizing financial losses for individuals and organizations.
- Sentiment Analysis: Classifiers are employed in sentiment analysis, which aims to determine the sentiment or emotion expressed in text data. This has applications in social media monitoring, brand reputation management, market research, and customer feedback analysis. Classifiers can categorize sentiment as positive, negative, or neutral, providing valuable insights for organizations.
- Image and Object Recognition: Classifiers are used in computer vision applications for image and object recognition. By training classifiers on labeled images, they can accurately identify and categorize objects in images or even detect and recognize faces. This has applications in facial recognition systems, autonomous vehicles, surveillance, and image search engines.
- Recommendation Systems: Classifiers are employed in recommendation systems to personalize recommendations based on user preferences. By analyzing user behavior and historical data, classifiers can predict user interests and make personalized recommendations for products, movies, music, or articles, improving the user experience and engagement.
- Natural Language Processing: Classifiers help in various natural language processing tasks such as document classification, topic modeling, and text categorization. By training classifiers on labeled text data, they can automatically classify documents into predefined categories or identify topics discussed in a collection of documents.
These are just a few examples of how classifiers are applied in real-world scenarios. Virtually any problem that involves classification or prediction can benefit from the use of classifiers. As the field of machine learning advances, new applications and use cases continue to emerge, driving innovation and improving decision-making processes across industries.
Challenges in Using Classifiers
While classifiers provide powerful tools for automated classification and prediction, there are several challenges and considerations that practitioners and developers must address when using classifiers:
- Data Quality and Quantity: Classifiers require high-quality and sufficiently large datasets for effective training. Insufficient or low-quality data can lead to biased or inaccurate results. Additionally, in some domains, acquiring labeled data can be challenging and expensive, limiting the availability of training samples.
- Feature Selection and Engineering: The selection and engineering of relevant features play a crucial role in the performance of classifiers. Identifying the most informative features can be a complex task, requiring domain expertise and experimentation. It’s also important to ensure that the selected features capture the essential characteristics of the problem at hand.
- Overfitting and Underfitting: Overfitting occurs when a classifier learns the training data too well and fails to generalize to new, unseen data. On the other hand, underfitting occurs when the classifier is too simple and fails to capture complex patterns in the data. Balancing the model’s complexity and its ability to generalize is a challenge that requires careful tuning and regularization techniques.
- Imbalanced Datasets: Imbalanced datasets, where one class is more prevalent than others, pose challenges for classifiers. Classifiers tend to predict the majority class more frequently, leading to biased results. Techniques such as resampling, class weighting, or using ensemble methods can help address this issue and improve the performance of classifiers on imbalanced data.
- Computational Complexity: Some classifiers, particularly those based on complex algorithms or neural networks, can be computationally intensive and require significant computational resources to train and deploy. Managing the computational complexity of classifiers can be challenging, especially when dealing with large datasets or real-time applications.
- Interpretability and Explainability: Classifiers based on complex models, such as deep neural networks, can be black boxes, making it difficult to interpret and understand their decisions. In sensitive domains, such as healthcare or finance, the ability to explain and justify the classifier’s predictions is essential. Developing interpretable and explainable classifiers is an ongoing challenge in the field of machine learning.
- Adaptability to Changing Environments: Classifiers trained on past data may struggle to adapt to new and evolving patterns or drifts in the data distribution. As the data changes, the classifier may need to be retrained or may require techniques such as online learning or concept drift detection to maintain its accuracy and performance over time.
Addressing these challenges requires a deep understanding of the problem domain, careful data preparation, model selection, and rigorous evaluation and validation. It’s important to be aware of these challenges and adapt the classifier and the workflow accordingly to maximize its effectiveness and value in real-world applications.
Conclusion
Classifiers are instrumental in the field of machine learning, enabling computers to effectively classify data and make predictions based on learned patterns and relationships. They find applications in a wide range of domains, including spam filtering, healthcare, fraud detection, sentiment analysis, image recognition, and recommendation systems.
Understanding the inner workings of classifiers is crucial for leveraging their potential. From data collection and preprocessing to feature selection, training, and evaluation, classifiers follow a systematic workflow in order to achieve accurate and reliable predictions. Various metrics, such as accuracy, precision, recall, F1 score, and the ROC curve, can be used to assess their performance.
However, using classifiers is not without its challenges. Issues such as data quality and quantity, feature selection, overfitting and underfitting, imbalanced datasets, computational complexity, interpretability, and adaptability to changing environments need to be considered and addressed to ensure the effectiveness and reliability of classifiers.
As the field of machine learning continues to advance, classifiers will play an increasingly vital role in automated decision-making processes across industries. The ongoing research and development in this area focus on overcoming the challenges, improving classifier performance, and addressing ethical considerations associated with their use.
In conclusion, classifiers empower machines to classify and predict data accurately, providing valuable insights, automating decision-making processes, and driving innovation. With continued advancements, classifiers hold tremendous potential to revolutionize various fields, making them an indispensable tool in the age of data-driven decision-making.