Introduction
A classification model is a fundamental concept in the field of machine learning. It serves as a predictive tool that categorizes data points into predefined classes or groups based on their features or attributes. By analyzing and learning from a training dataset that contains labeled examples, a classification model can make predictions or classifications on new, unseen data.
The primary goal of a classification model is to find patterns or relationships within the data that can differentiate one class from another. These patterns are represented by decision boundaries that separate the different classes in the feature space. Classification models are widely used in various domains, from predicting customer churn in business to detecting diseases in medical research.
Classification models play a crucial role in machine learning and have gained significant attention due to their ability to automate decision-making processes. They are also a key component of many real-world applications, including spam email detection, sentiment analysis, fraud detection, image recognition, and recommendation systems.
With the advancement of technology and the availability of vast amounts of data, the demand for accurate and efficient classification models has increased. This has led to the development of various algorithms and techniques to build and evaluate classification models.
In this article, we will explore the definition, working principles, common uses, types, evaluation metrics, and the process of building classification models. We will also highlight some of the challenges and limitations that practitioners may encounter when using classification models.
Let’s dive deeper into the fascinating world of classification models and understand how they can help us in solving complex problems and making informed decisions.
Definition of Classification Model
A classification model, in the context of machine learning, is a predictive model that assigns data points to predefined classes or categories based on their features or attributes. It is a supervised learning technique that involves training the model on a labeled dataset and then using it to predict the class of unseen instances.
The primary objective of a classification model is to learn the underlying patterns or relationships in the training data, allowing it to accurately classify new, unseen data instances. This is achieved by creating decision boundaries or decision surfaces that separate the different classes in the feature space.
Classification models are designed to handle both binary classification problems, where the data needs to be classified into two distinct classes, and multiclass classification problems, where the data can be classified into more than two classes.
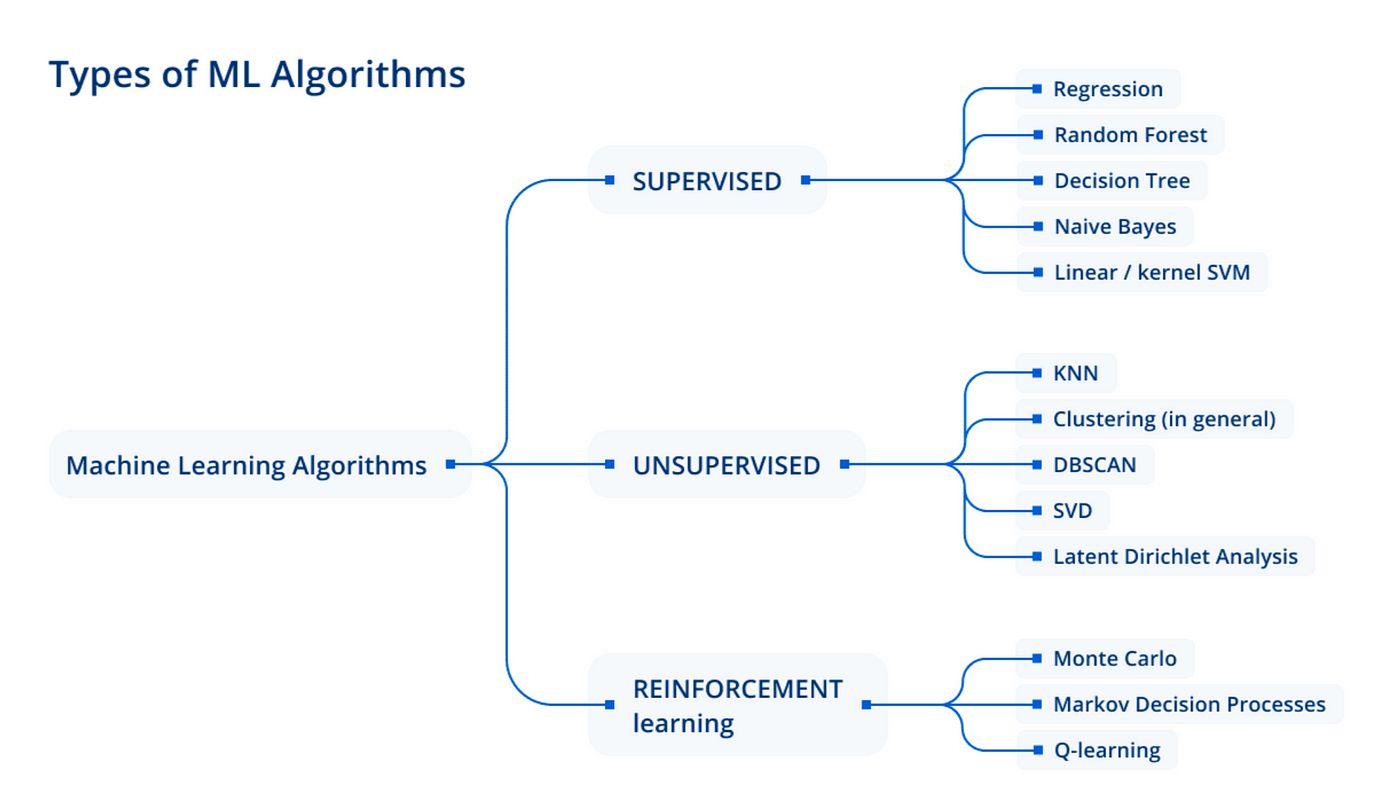
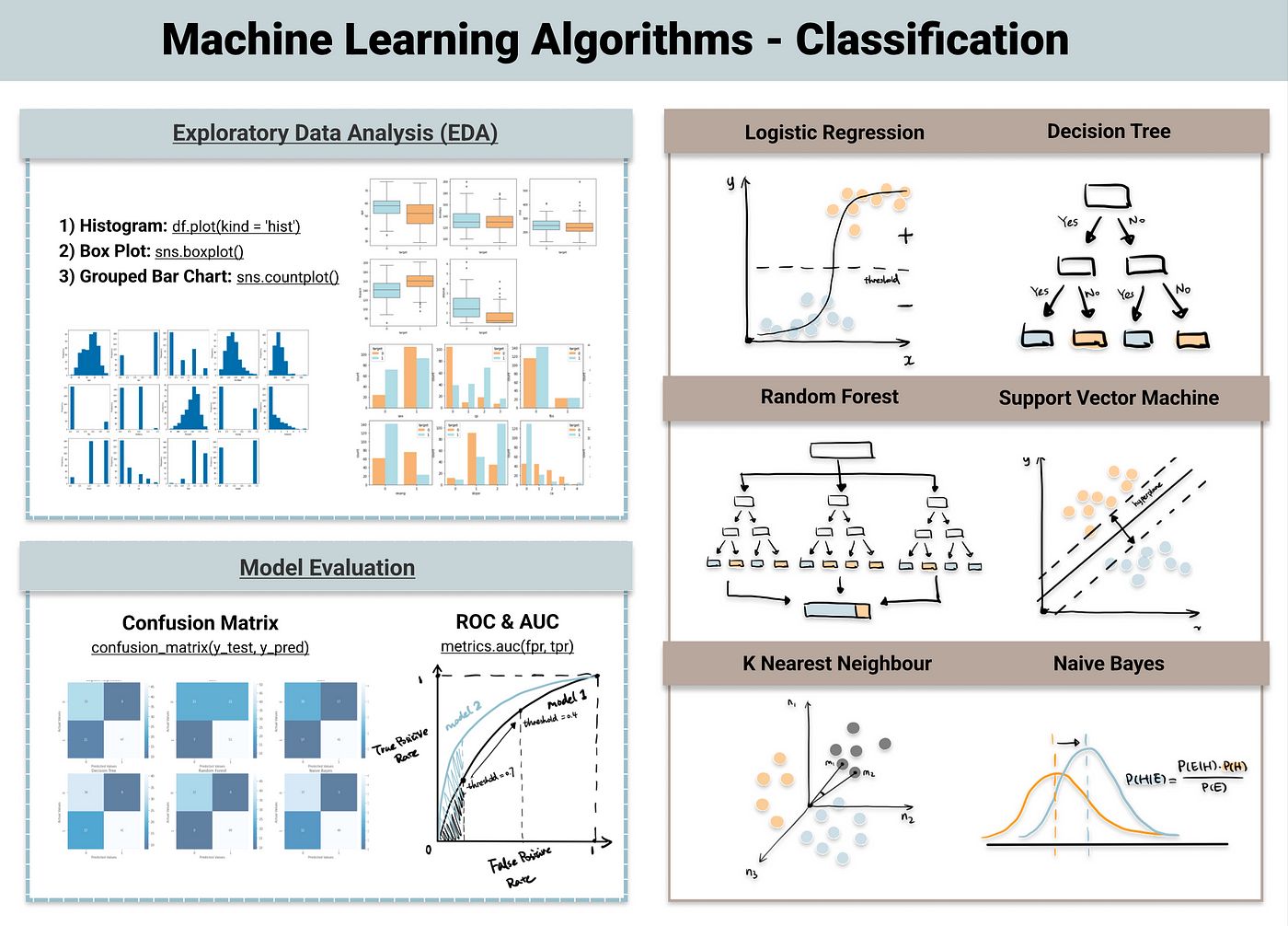
There are various algorithms and techniques used to build classification models, including decision trees, support vector machines (SVM), logistic regression, naive Bayes, k-nearest neighbors (KNN), and random forests.
Once a classification model is trained on a labeled dataset, it can be applied to new, unseen data for which the class labels are unknown. The model uses the learned patterns and relationships to predict or classify the instances into their respective classes.
Classification models are widely used in a variety of fields and industries. They enable businesses to automate decision-making processes, make accurate predictions, and gain valuable insights from their data. For example, in e-commerce, classification models can be used to predict customer preferences and recommend personalized products, improving the overall customer experience.
In summary, a classification model is a valuable tool in machine learning that allows us to categorize data into predefined classes or categories based on their attributes or features. It provides a powerful way to automate decision-making tasks and extract meaningful insights from data.
How Does a Classification Model Work?
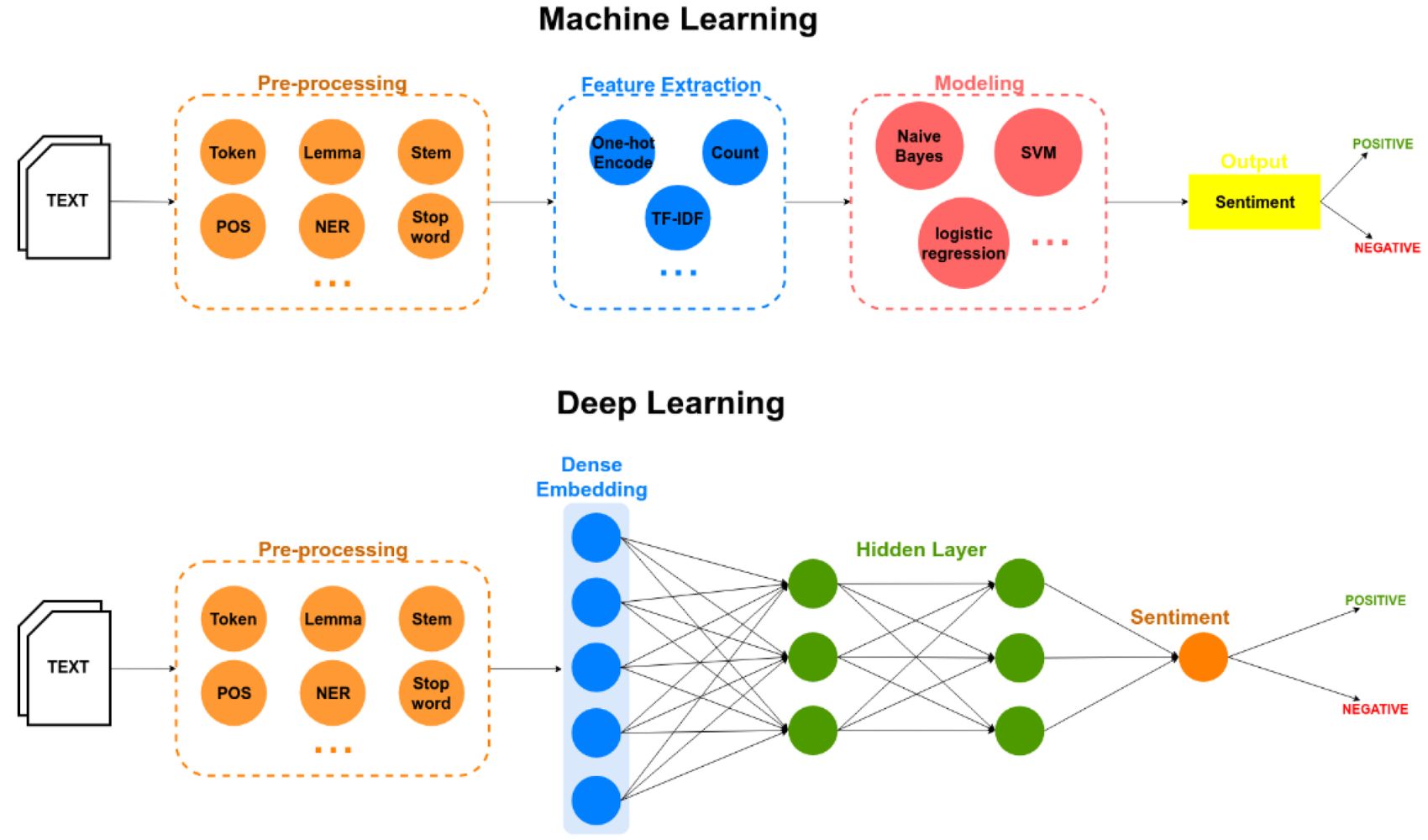
A classification model works by learning patterns and relationships in the training data and using that knowledge to predict the class or category of new, unseen data instances. The process involves several steps, including data preprocessing, feature extraction, model training, and prediction.
The first step in building a classification model is data preprocessing. This involves cleaning and preparing the dataset by handling missing values, outliers, and irrelevant features. The data is then split into a training set and a test set. The training set is used to train the model, while the test set is used to evaluate its performance.
Next, feature extraction is performed to extract meaningful features from the data. This step involves selecting or transforming the input variables (features) that are most relevant to the classification task. It helps to reduce dimensionality and improve the model’s performance by focusing on informative features.
Once the data is preprocessed and the relevant features are extracted, the model training begins. Various classification algorithms can be used for this purpose, such as decision trees, logistic regression, or support vector machines. The model is presented with the training data, which consists of labeled examples, where each instance is associated with a known class label.
During training, the model learns the relationships between the input features and the corresponding class labels. It adjusts its internal parameters or weights based on these relationships to minimize the prediction error. The training process involves iteratively fitting the model to the training data until it achieves an acceptable level of accuracy.
After the model is trained, it can be used to make predictions on new, unseen data instances. The model takes the input features of these instances and applies the learned patterns and relationships to classify them into one of the predefined classes. The accuracy of the predictions can be measured using evaluation metrics such as accuracy, precision, recall, and F1 score.
To improve the performance of a classification model, various techniques can be applied, such as feature engineering, ensemble methods, and hyperparameter tuning. Feature engineering involves creating new features from the existing ones or transforming them to better represent the underlying patterns in the data. Ensemble methods combine the predictions of multiple models to improve overall accuracy. Hyperparameter tuning involves finding the optimal values for the model’s parameters to improve its performance.
In summary, a classification model learns patterns and relationships in the training data to predict the class or category of new, unseen instances. It involves data preprocessing, feature extraction, model training, and prediction. By understanding how classification models work, we can effectively build and utilize them for various applications.
Common Uses of Classification Models
Classification models have a wide range of applications across various industries and domains. They are powerful tools for automating decision-making processes and extracting meaningful insights from data. Here are some common uses of classification models:
- Spam Email Detection: Classification models can be used to distinguish between spam and non-spam emails. By analyzing the email content, subject line, sender information, and other features, the model can accurately classify incoming emails as either spam or legitimate.
- Sentiment Analysis: Classification models can be used to analyze text data, such as customer reviews or social media posts, and determine the sentiment expressed. This is valuable for businesses to understand customer opinions and sentiment towards their products or services.
- Fraud Detection: Classification models can be used to identify fraudulent transactions or activities. By analyzing historical transaction data and detecting patterns indicative of fraud, the model can flag suspicious transactions in real-time, helping to prevent financial losses.
- Medical Diagnosis: Classification models can aid in the diagnosis of diseases. By analyzing patient data, symptoms, and medical test results, the model can classify patients into different disease categories, assisting healthcare professionals in making accurate and timely diagnoses.
- Customer Churn Prediction: Classification models can predict customer churn, enabling businesses to retain valuable customers. By analyzing customer behavior, purchase history, and demographic data, the model can identify customers who are likely to churn and allow businesses to take proactive measures to retain them.
- Image Recognition: Classification models can be used for image recognition tasks, such as object detection or facial recognition. By training the model on a large dataset of labeled images, it can learn to accurately classify and identify objects or faces in new images.
- Document Classification: Classification models can be used to categorize documents into different classes based on their content. This is useful for organizing large amounts of textual data, such as news articles or legal documents, and extracting relevant information.
These are just a few examples of the common uses of classification models. In reality, the applications are vast and can be customized to suit specific business needs and problems. By leveraging classification models, organizations can automate decision-making processes, improve efficiency, and gain valuable insights from their data.
Types of Classification Models
There are various types of classification models, each with its own specific characteristics and algorithms. The choice of classification model depends on the nature of the data and the problem at hand. Here are some common types of classification models:
- Decision Trees: Decision trees are hierarchical structures that represent a sequence of decisions or questions leading to a class prediction. Each internal node in the tree represents a decision based on a specific feature, while each leaf node represents a class label. Decision trees are easy to understand and interpret, making them suitable for both binary and multiclass classification problems.
- Support Vector Machines (SVM): SVM is a powerful classification algorithm that separates data points by finding an optimal hyperplane in the feature space. It aims to maximize the margin between the classes to achieve the best separation. SVM can handle both linear and non-linear classification tasks and is effective in situations with high-dimensional feature spaces.
- Logistic Regression: Logistic regression is a statistical model that predicts the probability of an instance belonging to a particular class. It is widely used for binary classification problems and can be extended to handle multiclass classification tasks. Logistic regression models the relationship between the input features and the class label using a logistic function.
- Naive Bayes: Naive Bayes is a probabilistic classifier that assumes that the presence of a particular feature is independent of other features. Despite this assumption, Naive Bayes performs well in many real-world applications. It is efficient and works well with high-dimensional data.
- K-Nearest Neighbors (KNN): KNN is a lazy learning algorithm that classifies instances based on their nearest neighbors in the feature space. It selects the class label based on the majority vote of its k closest neighbors. KNN is effective for both binary and multiclass classification tasks but can be computationally expensive for large datasets.
- Random Forests: Random forests combine multiple decision trees to make predictions. Each tree is trained on a random subset of the data and features and then aggregated to produce a final prediction. Random forests are robust and can handle high-dimensional data with complex relationships.
These are some commonly used types of classification models, but there are many more variations and algorithms available. The choice of the model depends on factors such as the type and size of the data, the complexity of the problem, and the desired interpretability of the model. It is important to experiment with different models and compare their performance to select the most suitable one.
Evaluation Metrics for Classification Models
Evaluation metrics are essential for assessing the performance and effectiveness of classification models. These metrics provide quantitative measures that help in comparing different models and understanding their predictive capabilities. Here are some common evaluation metrics used for classification models:
- Accuracy: Accuracy is the most basic evaluation metric and measures the percentage of correctly classified instances out of the total number of instances. It provides an overall measure of how well the model performs in terms of correct predictions.
- Precision: Precision focuses on the instances that the model classified as positive (true positive), measuring the proportion of true positive predictions out of all positive predictions. It is a useful metric when the cost of false positives is high, and we want to minimize the number of false positive predictions.
- Recall: Recall, also known as sensitivity or true positive rate, measures the proportion of true positive predictions out of all actual positive instances. It is a useful metric when the cost of false negatives is high, and we want to minimize the number of false negative predictions.
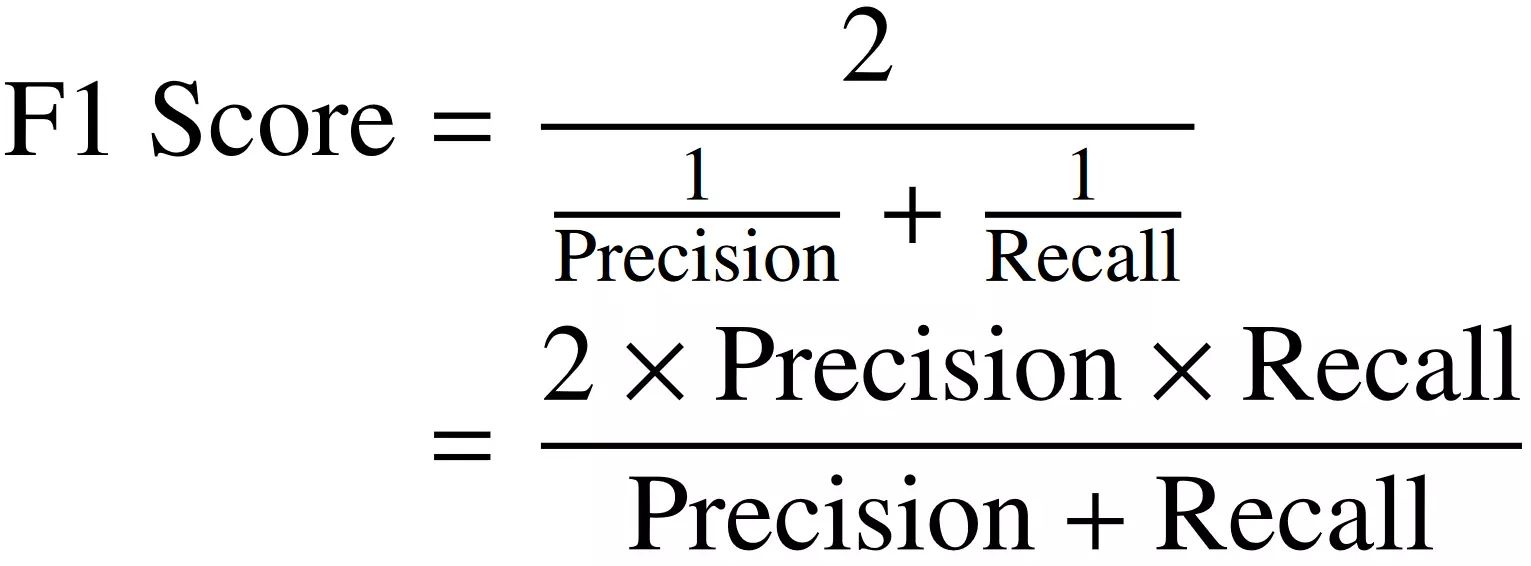
- F1 Score: The F1 score is the harmonic mean of precision and recall, providing a balanced evaluation metric. It accounts for both precision and recall and is particularly useful when the data is imbalanced.
- Confusion Matrix: A confusion matrix is a table that summarizes the performance of a classification model. It displays the number of true positives, true negatives, false positives, and false negatives. It is a useful tool for visualizing the performance of a model and understanding the types of errors it makes.
- Receiver Operating Characteristic (ROC) curve: The ROC curve is a graphical representation that shows the performance of a binary classifier at different classification thresholds. It plots the true positive rate against the false positive rate. The area under the ROC curve (AUC-ROC) is a common metric used to compare different models, with a higher value indicating better performance.
- Precision-Recall curve: The precision-recall curve is another graphical representation that shows the trade-off between precision and recall at different classification thresholds. It helps in evaluating the performance of a model when the data is imbalanced.
These evaluation metrics provide insights into the performance of the classification model, helping practitioners understand its strengths and weaknesses. It is important to consider multiple evaluation metrics to obtain a comprehensive understanding of the model’s performance and choose the most suitable model for the given problem and dataset.
How to Build a Classification Model
Building a classification model involves several steps, from data preparation to model training and evaluation. Here is a general outline of the process:
- Data Collection: Gather the relevant data that will be used to train and test the classification model. The data should be representative and cover a wide range of instances and classes.
- Data Preprocessing: Clean and preprocess the data to handle missing values, outliers, and inconsistencies. This step may also involve transforming and normalizing the data to ensure compatibility and improve model performance.
- Feature Selection/Engineering: Select the most relevant features for the classification task or engineer new features from the existing ones. Feature selection helps to reduce dimensionality and focus on informative features, while feature engineering creates new variables that capture important information from the data.
- Data Split: Split the data into a training set and a test set. The training set is used to train the classification model, while the test set is used to evaluate its performance. It is important to ensure that the split is representative of the overall data and maintains the class distribution.
- Model Selection: Choose an appropriate classification algorithm based on the nature of the problem, data characteristics, and model assumptions. Consider factors such as interpretability, complexity, and performance requirements when selecting the model.
- Model Training: Train the selected classification model using the labeled training data. The model learns the underlying patterns and relationships between the input features and the class labels through an iterative optimization process. It adjusts its internal parameters or weights to minimize the prediction error.
- Model Evaluation: Evaluate the performance of the trained classification model using the test set. Calculate the relevant evaluation metrics such as accuracy, precision, recall, and F1 score to assess the model’s effectiveness and generalization ability.
- Model Tuning: If necessary, fine-tune the model by adjusting hyperparameters or applying techniques such as cross-validation or ensemble methods to improve its performance. This step involves experimenting with different parameter settings and evaluating their impact on the model’s performance.
- Model Deployment: Once the classification model has been trained and evaluated, it can be deployed to make predictions on new, unseen data. The model should be integrated with the appropriate systems or applications to ensure seamless and efficient usage.
It’s important to iterate through this process, continuously refining and improving the model by incorporating feedback, adjusting the feature set, and exploring different algorithms. Building a classification model requires a combination of domain knowledge, data understanding, and analytical skills to create an effective and reliable solution.
Challenges and Limitations of Classification Models
While classification models are powerful tools for automated decision-making, they also have inherent challenges and limitations that need to be considered. Here are some common challenges and limitations of classification models:
- Imbalanced Data: Classification models may struggle when the dataset is imbalanced, meaning that one class has significantly more instances than the others. This can lead to biased predictions and inaccurate performance evaluation. Techniques like oversampling, undersampling, or using specialized algorithms can help overcome this challenge.
- Overfitting: Overfitting occurs when a classification model performs very well on the training data but fails to generalize to new, unseen data. This can happen when the model becomes too complex or when there is noise or outliers in the data. Regularization techniques and proper model selection can help mitigate overfitting.
- High-Dimensional Data: Classification models can struggle with high-dimensional data, where the number of features is large compared to the number of instances. This can lead to the curse of dimensionality, increased computational complexity, and potential overfitting. Feature selection, dimensionality reduction techniques, and algorithms designed for high-dimensional data can address this challenge.
- Missing Data and Outliers: Classification models may not handle missing data or outliers well. Data preprocessing techniques such as imputation or outlier detection can help address these issues, but they can affect the performance and reliability of the model.
- Assumptions and Linearity: Certain classification algorithms, like logistic regression, make assumptions about the linearity or independence of the features. Violating these assumptions can impact the accuracy and generalizability of the model. Choosing the appropriate algorithm based on the data characteristics is crucial.
- Interpretability vs. Performance Trade-off: Some classification models, like decision trees or naive Bayes, are highly interpretable and allow for easy understanding of the underlying decision-making process. However, these models may sacrifice performance compared to more complex models like neural networks. Striking the right balance between interpretability and performance is a crucial consideration.
Understanding the challenges and limitations of classification models is important to make informed decisions and achieve reliable results. It is essential to consider appropriate techniques, preprocessing methods, and algorithm selection based on the specific characteristics of the data and the problem at hand. Continuous monitoring, evaluation, and improvement of the classification model can help mitigate these challenges and ensure its effectiveness in real-world applications.
Conclusion
Classification models are powerful tools in machine learning that enable us to categorize data into predefined classes based on their attributes or features. They have a wide range of applications across various industries and domains, including spam email detection, sentiment analysis, fraud detection, medical diagnosis, and image recognition.
In this article, we explored the definition of classification models and discussed how they work. We delved into common uses of classification models and highlighted the different types of algorithms used, such as decision trees, support vector machines, logistic regression, naive Bayes, k-nearest neighbors, and random forests.
We also covered the important evaluation metrics for assessing the performance of classification models, including accuracy, precision, recall, F1 score, confusion matrix, ROC curve, and precision-recall curve. These metrics help us understand the strengths and weaknesses of the models and guide us in selecting the most suitable one for our needs.
Building a classification model involves several steps, from data preprocessing and feature selection to model training and evaluation. It requires careful consideration of data characteristics, model assumptions, and performance requirements. It’s also important to address common challenges such as imbalanced data, overfitting, high-dimensional data, missing data, and outliers.
By understanding the challenges and limitations of classification models, we can make informed decisions and overcome these obstacles. Continuous monitoring, fine-tuning, and improvement of the models are essential to achieve reliable and accurate predictions.
In conclusion, classification models offer a powerful approach to automate decision-making processes, make accurate predictions, and gain valuable insights from data. Through proper model selection, diligent data preprocessing, and thoughtful evaluation, we can leverage the potential of classification models to achieve our goals and solve complex problems in various domains.