Introduction
Welcome to the world of machine learning models! These sophisticated algorithms have revolutionized various industries, from healthcare to finance, by enabling businesses to make data-driven decisions. However, it’s important to acknowledge that machine learning models are not static entities. They require regular updates and retraining to continue delivering accurate and reliable results.
Retraining your machine learning models is crucial because the world is constantly changing. New data is generated, consumer preferences evolve, and market dynamics shift. Failing to update your models can lead to diminishing accuracy and outdated insights, ultimately impacting your business’s performance.
But how often should you retrain your machine learning model? This is a question that doesn’t have a one-size-fits-all answer. The frequency of retraining depends on several factors, including the type of model, available resources, and desired accuracy.
In this article, we will delve into the various aspects that need to be considered when deciding how often to retrain your machine learning models. We will explore the concepts of data drift and concept drift, discuss the importance of monitoring model performance, and examine how resource constraints and accuracy goals come into play. By the end, you will have a solid understanding of how to find the optimal retraining schedule for your models.
The Importance of Retraining
Retraining your machine learning model is vital to ensure its effectiveness and relevance in a continually evolving world. As mentioned earlier, data is constantly being generated, and the patterns and trends it contains can change over time. By retraining your model regularly, you can adapt to these changes and maintain the accuracy of your predictions.
One of the main reasons why retraining is essential is the phenomenon known as data drift. Data drift occurs when the statistical properties of the input data change over time. This can happen due to various factors, such as a shift in customer behavior, changes in the market, or fluctuations in external events. If your model was trained on data that no longer represents the current reality, its performance will suffer. By retraining with fresh data, you can capture the new patterns and dynamics, thus improving the accuracy of your predictions.
In addition to data drift, concept drift is another factor that necessitates retraining. Concept drift refers to the situation where the underlying concept being modeled changes. For example, in a sentiment analysis model, the sentiment of a word or phrase may change over time due to evolving cultural or societal factors. By regularly retraining your model, you can incorporate these changes and ensure that it stays up to date.
Moreover, retraining is crucial for adapting to changing business goals and objectives. As your business grows and evolves, it’s likely that your data requirements and decision-making processes will change as well. By regularly retraining your models, you can align them with your current business needs and ensure that they continue to provide relevant insights.
By neglecting to retrain your machine learning models, you run the risk of relying on outdated information and inaccurate predictions. This can have serious consequences for your business, including missed opportunities, poor decision-making, and loss of competitive advantage. Investing the time and resources into proper retraining is a proactive approach that ensures the continued efficiency and effectiveness of your machine learning models.
Factors to Consider When Deciding How Often to Retrain
Determining the optimal retraining frequency for your machine learning models involves considering several key factors. By carefully evaluating these factors, you can strike the right balance between staying up to date and utilizing your resources efficiently. Here are some important considerations:
1. Type of Model: The type of machine learning model you are working with plays a significant role in determining the retraining frequency. For instance, models that are built using deep learning techniques or complex neural networks may require more frequent retraining due to their higher sensitivity to changing data patterns. On the other hand, simpler models like decision trees or linear regression models may be more robust and require less frequent retraining.
2. Data Drift Rate: The rate at which data drift occurs in your domain is another critical factor. If your industry experiences frequent changes in customer preferences, market dynamics, or regulatory conditions, retraining more frequently may be necessary to capture those changes. Conversely, in domains with slower data drift rates, less frequent retraining may be sufficient.
3. Available Data: The quantity and quality of available data are important considerations. If you have access to ample amounts of labeled and relevant data, it becomes easier to update your models regularly. However, if data collection is costly or time-consuming, you may need to balance retraining frequency with the resources available.
4. Resource Constraints: The availability of computational resources, including processing power and storage capacity, is another consideration. Retraining complex models with large datasets can be resource-intensive and may not be feasible with limited resources. It’s important to assess the resources you have and determine the retraining frequency that optimizes the efficiency and effectiveness of your models.
5. Accuracy Requirements: The desired accuracy of your model’s predictions is another factor to consider. If your application requires high precision and accuracy, more frequent retraining may be necessary to maintain performance. On the other hand, for applications where a slight decline in accuracy is acceptable, less frequent retraining may suffice.
6. Return on Investment: Evaluating the potential benefits and costs associated with retraining can help guide your decision. Assess the impact of improved accuracy and updated insights against the time, effort, and resources required for retraining. Finding the right balance ensures that you derive the maximum value from your models.
By carefully considering these factors, you can determine how often to retrain your machine learning models. Remember, there is no one-size-fits-all approach, and the optimal retraining frequency may vary depending on your specific circumstances. Regular evaluation and fine-tuning of your retraining schedule will help you keep your models at their best performance.
Data Drift and Concept Drift
Data drift and concept drift are two critical concepts that impact the performance and accuracy of machine learning models. Understanding these phenomena is essential when determining how often to retrain your models.
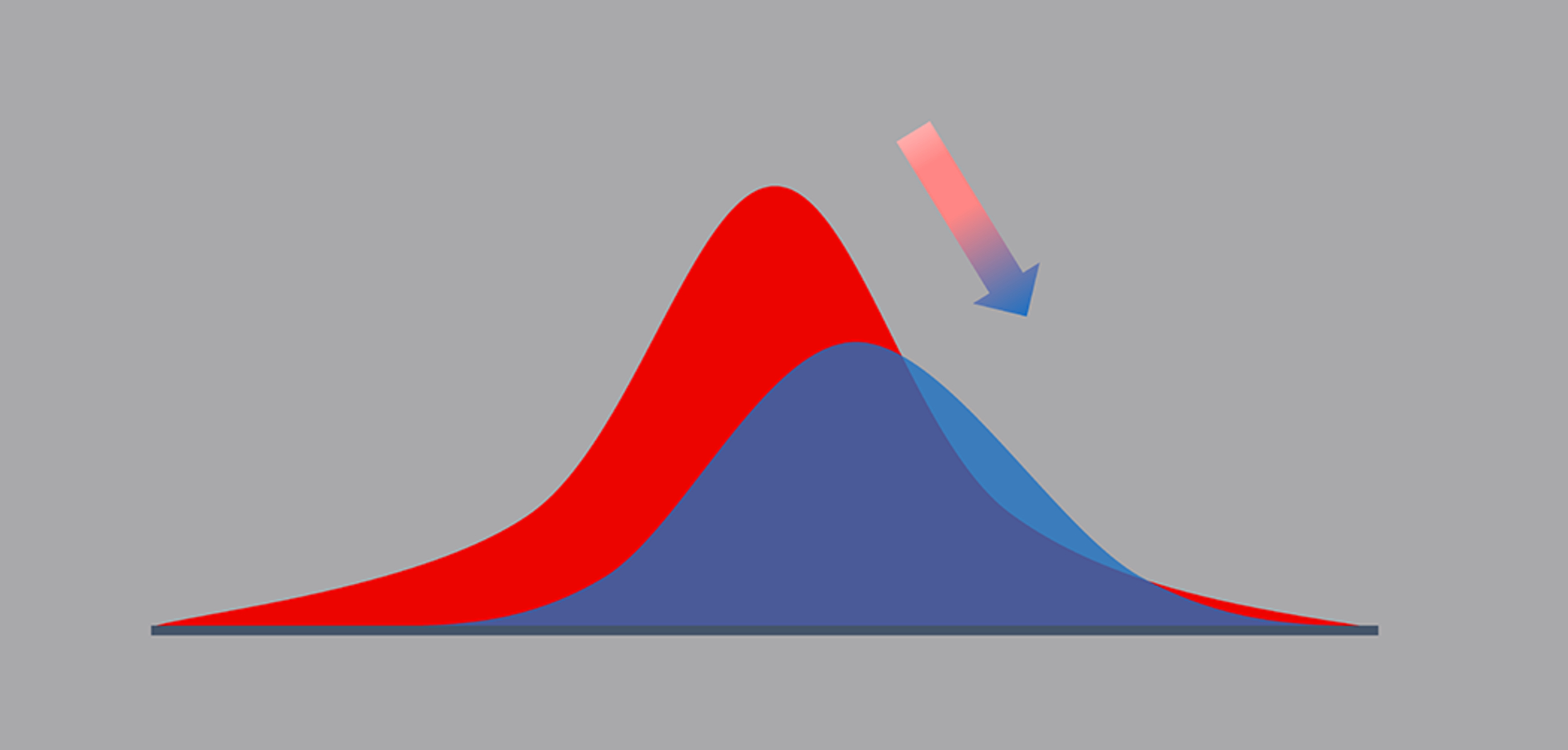
Data drift refers to the continuous change in the statistical properties of the input data. As time goes by, the distribution of the data can shift, leading to a mismatch between the training data and the real-world data that the model encounters during deployment. This can result in a decrease in prediction accuracy. Data drift can occur due to various factors, such as changing customer behavior, new trends, or shifts in market dynamics.
For example, let’s say you have a model that predicts customer churn for a subscription-based service. If the characteristics and patterns of customer behavior change over time, your model trained on older data may struggle to accurately predict churn for new customers.
Concept drift, on the other hand, refers to changes in the underlying concept being modeled. It occurs when the relationship between the input features and the target variable changes over time. Unlike data drift, concept drift is not solely driven by statistical changes in the data but rather by changes in the phenomenon being studied.
For instance, consider a sentiment analysis model that classifies customer reviews as positive or negative. If the sentiment associated with certain words or phrases evolves due to changes in cultural or societal factors, the model needs to be updated to understand the new context accurately.
Monitoring data drift and concept drift is crucial to assess when retraining is necessary. Continually monitoring the performance of your model against new incoming data can give you insights into whether the model’s accuracy is declining due to drift. If accuracy drops significantly, it’s an indication that the model needs retraining to adapt to the new data or concept.
There are several techniques for detecting data drift and concept drift, such as statistical methods, monitoring key performance metrics, or employing specialized algorithms. By regularly monitoring and detecting drift, you can plan your retraining schedule more effectively and ensure that your models stay accurate and up to date with the dynamic nature of your data.
Addressing data drift and concept drift is crucial for maintaining the performance of your machine learning models. By retraining your models frequently and adapting them to changing data patterns and underlying concepts, you can ensure that your models continue to provide accurate predictions and valuable insights.
Monitoring Model Performance
Monitoring the performance of your machine learning model is essential to ensure its accuracy and detect any issues or deterioration over time. By regularly assessing model performance, you can identify when retraining is necessary and take proactive measures to maintain optimal results.
There are several key metrics that can be used to monitor model performance. These include metrics such as accuracy, precision, recall, F1 score, and area under the receiver operating characteristic curve (AUC-ROC). These metrics provide insights into how well your model is performing and how it is handling different classes or prediction thresholds.
Regularly tracking these metrics allows you to identify if there is a decline in model performance. A significant drop in accuracy or other performance metrics may indicate that the model is no longer accurately capturing the patterns in the data. This can be an indication of data drift or concept drift, suggesting that retraining is necessary.
Another technique for monitoring model performance is to set up alerts or thresholds. By defining thresholds for key performance metrics, you can receive notifications or warnings when the model’s performance falls below the predefined standards. This helps you take immediate action and initiate the retraining process.
It’s important to establish a robust monitoring system that tracks model performance on an ongoing basis. This ensures that you can quickly identify any deterioration in performance and respond accordingly. With real-time monitoring, you can anticipate and address issues before they impact the accuracy and reliability of your predictions.
Aside from performance metrics, it is also valuable to monitor other indicators, such as feedback from end-users or domain experts. Their insights and feedback can provide valuable information about the model’s performance in real-world scenarios. Considering their input can help identify potential issues or opportunities for improvement that might not be captured by the performance metrics alone.
Monitoring model performance is an iterative process that requires regular attention and analysis. By being proactive and responsive to changes in performance, you can ensure that your machine learning models remain effective and accurate. Regularly monitoring performance, considering feedback, and leveraging relevant metrics will enable you to make informed decisions about retraining and continuously improve your models.
Available Resources and Constraints
When deciding how often to retrain your machine learning models, it’s important to consider the resources and constraints that are available to you. Retraining models can be a resource-intensive task, so finding the right balance between frequency and resource utilization is crucial.
The availability of computational resources is one key consideration. Retraining models often requires significant processing power and memory, especially when dealing with large datasets or complex models. Evaluate the computing resources, such as CPU or GPU, that you have at your disposal and consider the time and effort required for each retraining iteration. This will help you determine a feasible retraining frequency.
In addition to computing resources, the availability of data is another constraint to take into account. Data collection and labeling can be time-consuming and expensive processes. If gathering the required data for retraining is a challenge, you may need to adopt a less frequent retraining schedule. It’s important to strike a balance between the quality and quantity of data available and the retraining frequency that can be realistically achieved within your resource constraints.
Budgetary constraints are another aspect to consider. Retraining models can incur costs related to computing resources, data storage, and potentially hiring skilled personnel. Assess your budget limitations and allocate resources accordingly to ensure that retraining is sustainable in the long run. It may be necessary to adjust the retraining frequency based on the available budget and prioritize the most critical models or those with the highest impact on your business.
Time constraints are also important to consider. Retraining models can be a time-consuming process, especially for large-scale models and datasets. Assess the time available and the urgency of having up-to-date models. If time is a constraint, you may need to prioritize certain models or focus on key aspects of retraining that can have the most significant impact on performance.
By carefully evaluating the available resources and constraints, you can determine a retraining frequency that is both practical and efficient. It’s important to find the right balance that allows you to maintain model accuracy while optimizing resource utilization. Prioritize your efforts and allocate resources wisely to ensure effective retraining within the limitations of your organization.
Balancing Accuracy and Efficiency
When determining how often to retrain your machine learning models, striking the right balance between accuracy and efficiency is crucial. Retraining too frequently can be time-consuming and resource-intensive, while retraining too infrequently can lead to outdated models and diminished performance. Finding the optimal balance ensures that your models are accurate and up to date without sacrificing efficiency.
Accuracy is a critical factor to consider. The more frequently you retrain your model, the more accurately it can adapt to changes in data patterns and underlying concepts. Regular retraining allows your model to capture recent trends, evolving customer preferences, and shifting market dynamics. However, it’s important to remember that increasing frequency alone doesn’t guarantee better accuracy. The quality and relevancy of the data used for retraining are equally important.
Efficiency is another consideration in determining retraining frequency. Retraining models can be a time-consuming and computationally expensive process, especially for complex models or large datasets. The resources required for frequent retraining can be a constraint, with implications for cost and operational efficiency.
To balance accuracy and efficiency, consider the rate of change in your domain and the importance of staying up to date. If your industry experiences rapid shifts and data rapidly becomes outdated, more frequent retraining may be necessary to maintain accuracy. In contrast, if the rate of change is slower, less frequent retraining may be sufficient.
Furthermore, you can optimize efficiency by leveraging techniques such as incremental learning or transfer learning. Incremental learning allows you to update your model incrementally using new data points, reducing the need for complete retraining. Transfer learning, on the other hand, enables you to leverage knowledge learned from a related task or dataset, saving both time and computational resources.
Consider the trade-off between accuracy and efficiency based on the unique requirements and constraints of your business. Consider the costs associated with retraining, the computational resources available, and the desired level of accuracy for your specific use case. Set realistic goals and evaluate the impact of accuracy improvements against the effort and resources required for retraining.
Regularly evaluate and reassess the balance between accuracy and efficiency. Monitor the performance of your models and keep track of the accuracy gains achieved through retraining. By striking the right balance, you can ensure that your machine learning models deliver accurate results while optimizing the use of your resources.
Choosing the Right Retraining Schedule
Choosing the right retraining schedule for your machine learning models is crucial for maintaining accuracy and staying up to date. After considering factors such as data drift, concept drift, available resources, and the balance between accuracy and efficiency, it’s time to determine the specific retraining schedule that suits your needs. Here are some considerations to help you make an informed decision:
1. Regular Evaluation: Develop a process for regularly evaluating the performance of your models and monitoring data and concept drift. This will help you identify when retraining is necessary and guide the frequency of retraining. Set up monitoring systems and define thresholds to trigger retraining when performance drops below acceptable levels.
2. Data Availability: Consider the availability and accessibility of new data. If you have access to a steady stream of fresh, relevant, and high-quality training data, more frequent retraining may be beneficial. However, if new data is scarce or difficult to obtain, less frequent retraining may be necessary to balance the available resources and retraining costs.
3. Adaptability Requirements: Assess the adaptability requirements of your models. Models that need to respond quickly to changing real-world conditions, such as fraud detection or customer behavior prediction, may require more frequent retraining. On the other hand, models that are less affected by real-time changes, such as long-term trend analysis, may require less frequent retraining.
4. Resource Constraints: Take into account the computational resources and budget available for retraining. Consider the time and cost involved in retraining and find a schedule that optimizes resource utilization. If resources are limited, you may need to prioritize retraining based on the criticality of the models or allocate resources strategically to those models that have the highest impact on business goals.
5. Iterative Improvement: Embrace an iterative approach to retraining. Start with an initial retraining schedule and monitor the performance of your models. Based on the feedback and insights gained, fine-tune the retraining schedule over time. This iterative process allows you to continuously improve the accuracy of your models while refining the retraining strategy.
6. Domain Expertise: Seek input from domain experts who understand the nuances and dynamics of your industry. They can provide valuable insights on the rate of change, data availability, and the need for retraining. Their expertise can help you make informed decisions on the retraining schedule that aligns with the specific needs and challenges of your domain.
Remember, the optimal retraining schedule is not a one-time decision but an ongoing evaluation and adjustment process. Stay vigilant, regularly assess model performance, and reassess your retraining schedule as needed. By finding the right balance, you can ensure that your machine learning models stay accurate, relevant, and effective in providing valuable insights for your business.
Conclusion
Retraining your machine learning models is a critical aspect of maintaining their accuracy and relevance in a rapidly evolving world. By considering factors such as data drift, concept drift, available resources, and the balance between accuracy and efficiency, you can determine the optimal retraining schedule for your models.
Data and concept drift are inevitable, and monitoring model performance is crucial to identify when retraining is necessary. Regular evaluation and monitoring of key metrics help ensure that your models adapt to changing patterns and deliver accurate predictions.
Available resources and constraints play a significant role in determining retraining frequency. Consider the computational resources, budget limitations, and data availability when establishing a retraining schedule that strikes the right balance for your organization.
Finding the optimal retraining schedule requires an iterative approach. Regularly assess model performance, gather feedback from domain experts, and fine-tune the schedule based on insights gained. Continuously reevaluating and adjusting the retraining strategy ensures that your models remain accurate and aligned with your business goals.
In conclusion, the decision on how often to retrain your machine learning models is not a one-size-fits-all approach. It requires careful consideration of various factors, including the type of model, data drift, concept drift, available resources, and efficiency requirements. By finding the right balance and establishing an effective retraining schedule, you can ensure that your models stay robust, accurate, and deliver valuable insights to drive your business forward.