Introduction
When it comes to managing a computer’s resources efficiently, CPU scheduling plays a vital role. In the world of operating systems, CPU scheduling is the process of determining which tasks or processes should be executed by the CPU at a given time. As the CPU is the heart of a computer system, effective CPU scheduling algorithms are crucial for optimizing performance, improving responsiveness, and ensuring fairness in sharing resources.
CPU scheduling becomes even more critical in multi-user systems, where multiple processes are vying for CPU time. The goal of CPU scheduling algorithms is to minimize the average response time, maximize throughput, and maintain fairness among processes.
Understanding the intricacies of CPU scheduling is important for system administrators, software developers, and computer science enthusiasts alike. It provides insights into how computer systems manage and allocate resources to deliver a smooth and efficient computing experience.
In this article, we will delve into the concept of CPU scheduling, explore its importance, and discuss various CPU scheduling algorithms used in modern operating systems. By the end of this article, you will have a comprehensive understanding of CPU scheduling and its significance in optimizing system performance.
What is CPU Scheduling?
CPU scheduling is a fundamental component of modern operating systems and is the mechanism that determines which tasks or processes get access to the CPU’s processing time. In simpler terms, it is the algorithmic strategy used to schedule the execution of processes in a computer system.
When a computer system has multiple processes competing for CPU resources, it becomes crucial to allocate CPU time efficiently to maximize overall system performance. CPU scheduling algorithms consider factors like process priority, burst time, waiting time, and resource dependencies to make informed decisions on which process should be executed next.
At its core, CPU scheduling aims to achieve several objectives, including:
- Fairness: Ensuring that each process gets a fair share of the CPU’s processing time.
- Efficiency: Maximizing CPU utilization and minimizing idle time.
- Responsiveness: Providing quick response times to user requests and interactive tasks.
- Throughput: Maximizing the number of processes completed within a given time frame.
It’s important to note that different CPU scheduling algorithms can be employed based on the specific needs and characteristics of the system. The choice of algorithm can significantly impact system performance and responsiveness.
Nowadays, multi-core processors are common, meaning there are multiple CPUs available for executing processes concurrently. On these systems, the task of CPU scheduling extends to distributing processes across multiple cores efficiently.
In the next section, we will explore why CPU scheduling is of utmost importance in operating systems and how it contributes to the overall system performance and user experience.
Why is CPU Scheduling important?
CPU scheduling is a critical aspect of operating systems as it directly impacts system performance, responsiveness, and resource utilization. Let’s delve into why CPU scheduling is so important:
1. Optimizing CPU Utilization: Efficient CPU scheduling ensures that the CPU remains busy, executing processes as much as possible. By minimizing idle time and maximizing CPU utilization, CPU scheduling allows the system to handle more tasks and achieve higher throughput.
2. Improving Responsiveness: In interactive systems, such as desktops or servers that handle user requests, responsiveness is key. By employing appropriate CPU scheduling algorithms, the operating system can provide quick response times to user actions, making the system feel more snappy and responsive.
3. Enhancing System Performance: CPU scheduling algorithms play a crucial role in optimizing system performance. By making intelligent decisions on task priorities and execution order, CPU scheduling can minimize the average response time, reduce process waiting time, and deliver faster task completion.
4. Enabling Fair Resource Allocation: CPU scheduling ensures fairness by allocating CPU time fairly among competing processes. It prevents any single process from monopolizing the CPU for an extended period, thus creating a balanced resource distribution among running processes.
5. Supporting Real-Time Systems: In real-time systems, where strict timing requirements must be met, such as in aviation or industrial control systems, CPU scheduling plays a vital role in meeting deadlines. Real-time scheduling algorithms ensure that critical tasks are executed on time, guaranteeing system reliability.
6. Minimizing Bottlenecks: CPU scheduling helps in identifying and resolving potential bottlenecks within the system. By analyzing the performance of different processes and their resource requirements, CPU scheduling algorithms can allocate resources more effectively, preventing resource contention and enhancing overall system performance.
Overall, CPU scheduling is a crucial component of any operating system, and its effective implementation is essential for achieving optimal system performance, responsiveness, and resource utilization.
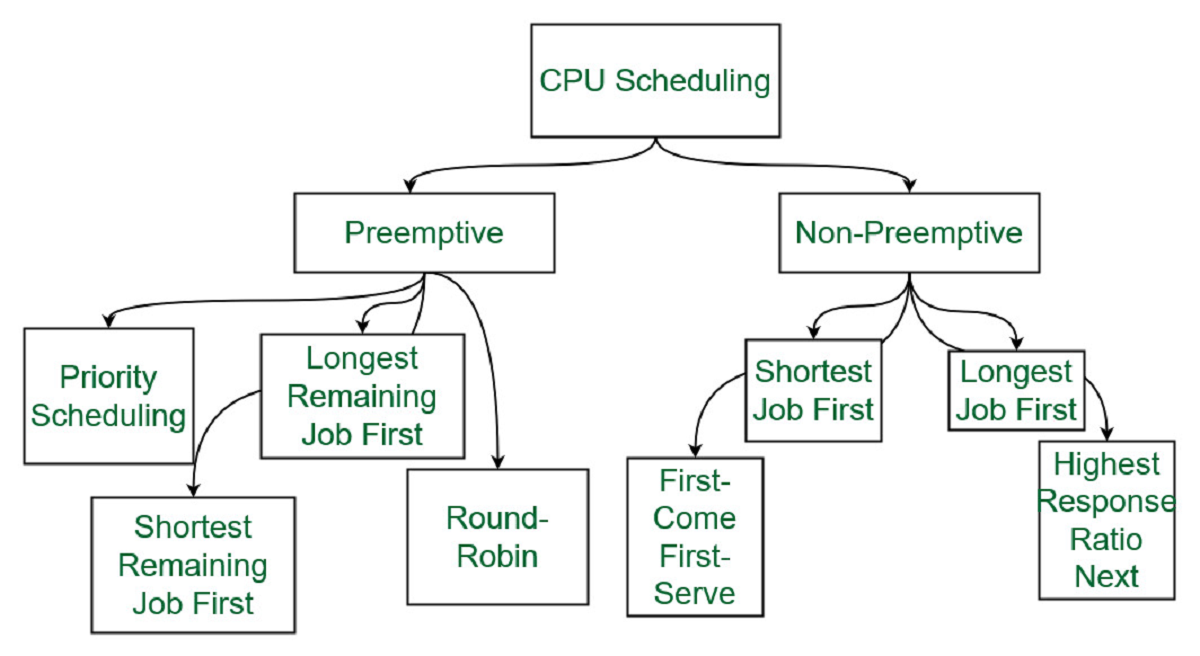
Different CPU Scheduling Algorithms
Several CPU scheduling algorithms have been developed over the years, each with its unique characteristics and suitability for specific scenarios. Let’s explore some of the commonly used CPU scheduling algorithms:
1. First-Come, First-Served (FCFS) Scheduling: This is a non-preemptive scheduling algorithm where processes are executed in the order they arrive. The CPU is allocated to the first process in the queue, and it continues execution until completion or when it voluntarily relinquishes control. FCFS provides fairness but may suffer from poor responsiveness when long-running processes block others from executing.
2. Shortest Job Next (SJN) Scheduling: Also known as Shortest Job First (SJF), this algorithm selects the process with the shortest burst time to execute first. SJN can minimize average waiting time and turnaround time, but it requires knowledge of the burst time beforehand, which is often unrealistic in practice.
3. Round Robin (RR) Scheduling: In this algorithm, processes are executed in a cyclic fashion, with each process receiving a fixed time slice or quantum of CPU time. If a process does not complete execution within the time slice, it is preempted and moved to the back of the queue. RR provides fairness and responsiveness, but can suffer from high context switch overhead and may not be suitable for long-running tasks.
4. Priority Scheduling: Each process is assigned a priority value, and the CPU is allocated to the process with the highest priority at any given time. Priority can be static or dynamic, with static priority assigned based on process characteristics and dynamic priority adjusted during runtime. Priority scheduling is flexible but requires careful management to prevent starvation and ensure fair resource allocation.
5. Multilevel Queue Scheduling: This algorithm divides processes into multiple queues based on priority or other attributes. Each queue has its own scheduling algorithm, allowing different classes of processes to be managed separately. For example, interactive tasks could be assigned to a high-priority queue for quick response, while background tasks are placed in a lower-priority queue.
These are just a few examples of CPU scheduling algorithms, and there are many variations and hybrid approaches that have been developed to address different system requirements and constraints.
CPU scheduling algorithms are a crucial aspect of designing and implementing efficient operating systems. The choice of algorithm depends on factors such as system workload, task characteristics, and performance goals. By understanding these different algorithms, system administrators and developers can make informed decisions to enhance system performance and responsiveness.
First-Come, First-Served (FCFS) Scheduling
First-Come, First-Served (FCFS) Scheduling is one of the simplest and most straightforward CPU scheduling algorithms. In FCFS, the processes that arrive first are executed first. The CPU is allocated to the first process in the ready queue, and it continues executing until completion or when it voluntarily relinquishes control, such as when it requests an I/O operation.
FCFS is a non-preemptive scheduling algorithm, which means that once a process starts executing, it holds the CPU until it completes or requests an I/O operation. Only then will the CPU be allocated to the next process in the queue.
While FCFS provides fairness in terms of executing processes in the order they arrive, it may suffer from poor responsiveness, especially if there are long-running processes that block others from executing. This is known as the “convoy effect,” where a single long process causes other shorter processes to wait, leading to increased waiting time and reduced system performance.
One advantage of FCFS is its simplicity in implementation. Its non-preemptive nature avoids issues like race conditions and synchronization problems that can occur in preemptive scheduling algorithms. Additionally, FCFS does not require knowledge of burst times in advance, making it easier to use in practice.
However, FCFS has limitations, and its performance may not be optimal in all scenarios. For example, if a CPU-bound process arrives first and continues to execute for a long time, it could significantly delay the execution of other processes, especially interactive or time-sensitive tasks.
In summary, FCFS is a simple and fair CPU scheduling algorithm. While it provides straightforward implementation and avoids certain complexities of preemptive algorithms, it may suffer from poor responsiveness and delay other tasks. As such, understanding the characteristics and trade-offs of FCFS is important for designing efficient CPU scheduling strategies in operating systems.
Shortest Job Next (SJN) Scheduling
Shortest Job Next (SJN) Scheduling, also known as Shortest Job First (SJF) Scheduling, is a CPU scheduling algorithm that selects the process with the shortest burst time to be executed next. The idea behind SJN is to minimize the average waiting time and turnaround time of processes.
In SJN scheduling, the CPU is allocated to the process that has the smallest total execution time or burst time. The assumption is that shorter processes tend to complete more quickly, resulting in faster turnaround times and improved system performance.
One challenge in implementing SJN is the difficulty of accurately predicting the burst time of each process before it starts execution. In practical scenarios, burst times are often unknown, making it challenging to determine which process is actually the shortest. Therefore, in most cases, an estimate or approximation of burst time is used to make scheduling decisions.
SJN can be implemented in both preemptive and non-preemptive variants. In the non-preemptive version, once a process starts executing, it continues until it completes or voluntarily releases the CPU. This leads to a longer overall waiting time for longer processes, known as the “starvation” problem.
In contrast, the preemptive version of SJN allows the currently executing process to be preempted when a shorter job arrives. In this case, the shorter job gets priority, leading to reduced waiting times and improved fairness. However, preemptive SJN scheduling introduces additional overhead due to frequent context switches.
The SJN algorithm is particularly effective for minimizing the average waiting time if the burst times are known accurately. However, in practical scenarios, burst times are often estimated based on historical data or assumptions, which can introduce errors and impact the efficiency of scheduling decisions.
Overall, SJN scheduling aims to optimize system performance by prioritizing the execution of shorter jobs. While it can achieve lower average waiting times, it heavily relies on accurate burst time estimation. The trade-off between estimation accuracy and scheduling performance needs to be carefully considered when implementing SJN in operating systems.
Round Robin (RR) Scheduling
Round Robin (RR) Scheduling is a widely used CPU scheduling algorithm that provides fairness and responsiveness in multitasking operating systems. In RR scheduling, each process is assigned a fixed time slice or quantum of CPU time. The CPU is allocated to the first process in the ready queue and executes for the specified time quantum before being preempted and moved to the back of the queue, allowing the next process in line to execute.
The main idea behind RR scheduling is to provide equal opportunity for each process to execute, ensuring fairness in resource allocation. This fair sharing of the CPU helps prevent a single long-running process from monopolizing the CPU and creating a poor user experience.
One advantage of the RR algorithm is its simplicity and ease of implementation. It ensures that all processes get a chance to execute within a reasonable timeframe, regardless of their execution time requirements.
RR scheduling also provides a degree of responsiveness, especially for interactive tasks. Since each process gets a fixed time quantum, shorter tasks can complete quickly and provide a more interactive experience to users.
However, one drawback of RR scheduling is the potential for high context switch overhead. Context switch occurs when the CPU switches from executing one process to another. With smaller time quantum values, the frequency of context switches increases. This can lead to additional overhead and affect the overall system performance.
Additionally, the choice of time quantum plays a crucial role in the performance of RR scheduling. A short time quantum allows for more frequent process switching, reducing potential delays but increasing the context switch overhead. On the other hand, a long time quantum may lead to longer waiting times for other processes, causing reduced responsiveness.
Overall, Round Robin scheduling is a popular CPU scheduling algorithm due to its fairness and responsiveness. By providing equal opportunity to all processes and preventing a single process from dominating the CPU, RR scheduling ensures a balanced sharing of resources. However, the choice of the time quantum and management of context switch overhead are important considerations in implementing RR scheduling effectively in operating systems.
Priority Scheduling
Priority Scheduling is a widely used CPU scheduling algorithm in operating systems that assigns a priority value to each process. The CPU is allocated to the process with the highest priority at any given time. Priority can be defined based on various factors, such as process importance, user-defined priorities, or process characteristics.
In priority scheduling, each process is associated with a priority value, and the CPU is allocated to the process with the highest priority. If multiple processes have the same priority, they are usually scheduled in a first-come, first-served manner (FCFS) within that priority level.
Priority scheduling allows for fine-grained control over resource allocation, as processes can be assigned different priorities based on their importance or time-criticality. For example, critical system tasks or real-time applications can be assigned high priorities to ensure their timely execution.
There are two common variations of priority scheduling: static priority scheduling and dynamic priority scheduling.
In static priority scheduling, the priority of a process remains constant throughout its life cycle. The priorities are usually assigned based on process characteristics or predetermined rules. This approach provides a stable and predictable scheduling pattern but may not adapt well to changing system conditions.
In dynamic priority scheduling, the priority of a process can change during runtime based on factors such as process behavior, resource usage, or time spent in the system. This adaptive approach helps in managing resource allocation based on changing demands and can enhance system performance and responsiveness.
Priority scheduling, however, presents challenges in preventing starvation, where lower priority processes may not get sufficient CPU time. To address this, some implementations of priority scheduling include aging mechanisms, where the priority of waiting processes gradually increases over time, ensuring a fair distribution of CPU time and preventing starvation.
While priority scheduling provides flexibility and enables the execution of critical processes efficiently, it can also lead to situations where higher priority processes dominate the CPU at the expense of lower priority processes. It is crucial to strike a balance between fairness and responsiveness when setting priorities.
Overall, priority scheduling is a versatile CPU scheduling algorithm that allows for resource allocation based on process importance. By assigning priorities, the algorithm enables the execution of critical tasks and improves system responsiveness. However, careful management of priorities and dealing with potential starvation scenarios are important considerations when implementing priority scheduling in operating systems.
Multilevel Queue Scheduling
Multilevel Queue Scheduling is a CPU scheduling algorithm that divides processes into multiple queues, each with its own priority level or characteristics. Each queue can have its own scheduling algorithm, allowing different classes of processes to be managed separately based on their priority, type, or other properties.
The primary goal of multilevel queue scheduling is to provide differentiated treatment to different categories of processes based on their importance or requirements. By dividing processes into separate queues, system administrators can assign different priorities to different classes of processes, ensuring that critical processes or time-sensitive tasks receive preferential treatment.
The multilevel queue scheduling algorithm allows for efficient handling of different types of processes, such as interactive tasks, batch jobs, or real-time applications, each with their own scheduling requirements. For example, interactive tasks that require quick response times can be assigned to a high-priority queue, while background processes or low-priority tasks can be placed in a separate queue with lower priority.
Each queue can be scheduled using a different scheduling algorithm based on the requirements of the processes in that particular queue. Common scheduling algorithms used within each queue include First-Come, First-Served (FCFS), Round Robin (RR), or Priority Scheduling.
Processes are typically assigned to queues based on predetermined criteria or during the process creation phase. Some systems allow for dynamic movement of processes between queues based on their behavior, priorities, or resource usage during runtime.
One key consideration when implementing multilevel queue scheduling is the order in which the different queues are serviced. This order is usually based on the priority of the queues themselves. For example, high-priority queues may be scheduled before lower-priority queues.
In some multilevel queue scheduling implementations, there may be additional restrictions on the movement of processes between queues. For example, once a process is assigned to a particular queue, it may not be able to move to a higher-priority queue. These restrictions help maintain fairness and prevent lower-priority processes from being starved by higher-priority processes.
In summary, multilevel queue scheduling is a versatile CPU scheduling algorithm that allows for differentiated treatment of processes based on their characteristics and priority. By dividing processes into separate queues and applying different scheduling algorithms, system performance and fairness can be improved. However, careful consideration of queue assignment, scheduling order, and potential restrictions on process movement is necessary to achieve optimal results.
Conclusion
CPU scheduling algorithms are fundamental in managing the allocation of CPU resources in operating systems. They play a crucial role in optimizing system performance, improving responsiveness, and ensuring fair resource allocation among processes. Throughout this article, we have explored various CPU scheduling algorithms and their characteristics, including First-Come, First-Served (FCFS) Scheduling, Shortest Job Next (SJN) Scheduling, Round Robin (RR) Scheduling, Priority Scheduling, and Multilevel Queue Scheduling.
Each CPU scheduling algorithm has its advantages and trade-offs. FCFS provides fairness but may suffer from poor responsiveness. SJN aims to minimize waiting time but relies heavily on accurate burst time estimation. RR provides fairness and responsiveness but may incur high context switch overhead. Priority scheduling allows for fine-grained control over resource allocation but requires careful management to prevent starvation. Multilevel queue scheduling enables differentiated treatment based on priority levels or characteristics of processes.
Choosing the appropriate CPU scheduling algorithm depends on various factors such as system workload, task characteristics, and performance goals. Understanding the strengths and limitations of each algorithm is crucial for designing efficient scheduling strategies in operating systems.
CPU scheduling algorithms continue to evolve as operating systems become more complex and diverse. Innovative approaches and hybrid models are being developed to address specific requirements and optimize system performance. As technology advances, new challenges related to multi-core processors, real-time systems, and dynamic workloads arise, necessitating further advancements in CPU scheduling techniques.
In conclusion, CPU scheduling is a critical aspect of operating systems that directly impacts system performance, responsiveness, and resource utilization. By implementing effective CPU scheduling algorithms, system administrators and developers can optimize the usage of CPU resources, enhance user experience, and achieve efficient multitasking in modern computer systems.