Introduction
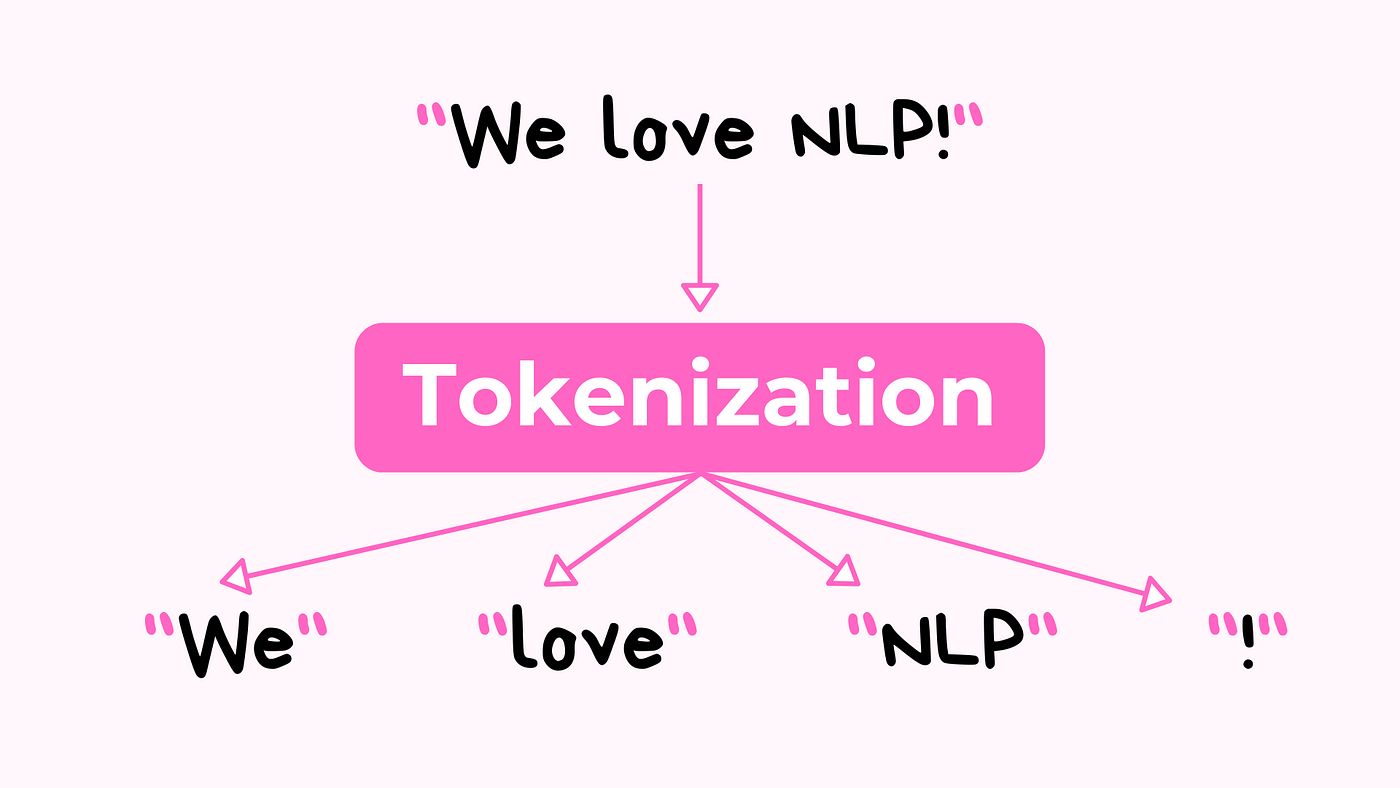
When it comes to managing and processing large amounts of textual data, text tokenization plays a crucial role. Text tokenization is the process of breaking down a chunk of text into smaller, meaningful units called tokens. These tokens can be individual words, phrases, or even sentences, depending on the level of granularity required for analysis or processing. This technique is widely used in natural language processing (NLP), information retrieval, and other text-centric applications.
Text tokenization is essential for various tasks, such as word frequency analysis, sentiment analysis, machine translation, and text classification. By breaking text into tokens, it becomes easier for machines to analyze and understand the underlying meaning in the text. Additionally, tokenization helps in removing unnecessary noise from the text and focusing on the most important elements.
The process of text tokenization involves several steps. Initially, the text is divided into sentences or paragraphs, known as text segmentation. Next, each segment is further broken down into tokens by considering factors such as whitespace, punctuation marks, or specific language rules. These tokens are then used as individual units for analysis or processing.
There are various approaches to text tokenization, such as rule-based tokenization, statistical tokenization, and hybrid tokenization. Rule-based tokenization relies on predefined rules to determine how text is split into tokens. Statistical tokenization, on the other hand, utilizes statistical models to make informed decisions about token boundaries. Hybrid tokenization combines both rule-based and statistical methods for more accurate results.
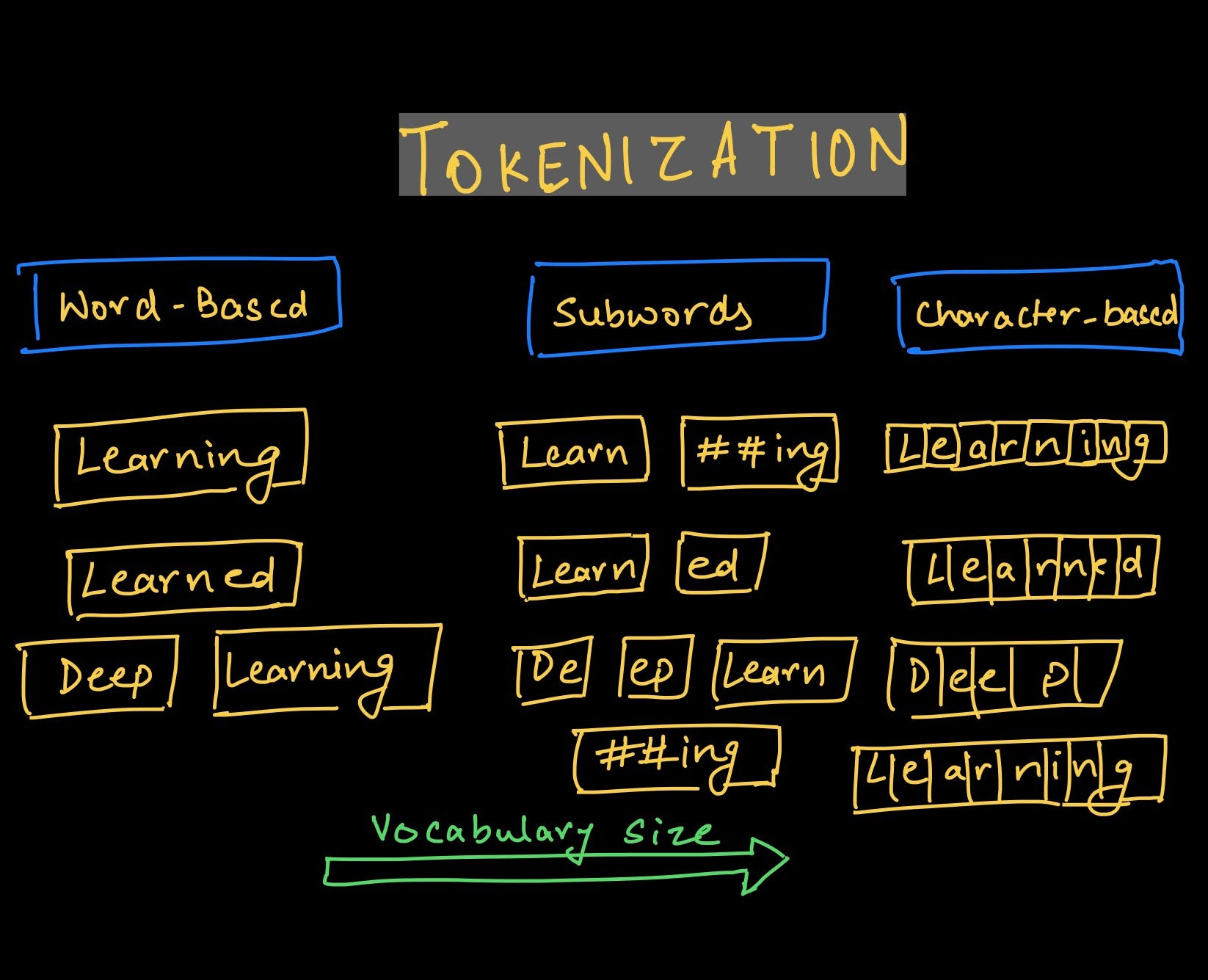
Common methods used during text tokenization include word tokenization, sentence tokenization, and character tokenization. Word tokenization breaks the text into individual words, while sentence tokenization splits it into sentences. Character tokenization, on the other hand, breaks the text down into individual characters. The choice of method depends on the specific requirements of the analysis or processing task.
Text tokenization is not without its challenges. One major challenge is dealing with languages that lack explicit word boundaries, such as Chinese or Thai. Another challenge is handling special cases like compound words, abbreviations, or contractions. Properly identifying and tokenizing these elements can significantly impact the accuracy of subsequent analysis or processing tasks.
Definition of Text Tokenization
Text tokenization is a fundamental process in natural language processing (NLP) and information retrieval, wherein a given text is divided into smaller, meaningful units called tokens. These tokens can be individual words, phrases, or even sentences, depending on the level of granularity required for analysis or processing. By breaking down the text into tokens, it becomes easier for machines to understand and process the information contained in the text.
The primary goal of text tokenization is to extract relevant and meaningful units of text that can be used for various NLP tasks, such as analysis, classification, and information retrieval. Tokens are considered as atomic components of the text and serve as the building blocks for further analysis or processing.
The process of text tokenization generally begins with text segmentation, where the text is divided into segments such as sentences or paragraphs. The purpose of segmentation is to manage the text structure and provide context for further tokenization. Once the text is segmented, the next step is to identify the boundaries of individual tokens within each segment.
There are different approaches to text tokenization, including rule-based, statistical, and hybrid methods. Rule-based tokenization relies on predefined rules, such as whitespace or punctuation marks, to determine token boundaries. Statistical tokenization, on the other hand, uses statistical models to make informed decisions about tokenization based on the probabilities of certain sequences. Hybrid tokenization combines both rule-based and statistical approaches to achieve more accurate results.
Word tokenization is one of the most common forms of text tokenization, where the text is divided into individual words. This method is particularly useful for tasks such as word frequency analysis or text classification. Sentence tokenization, on the other hand, breaks the text into sentences, which is necessary for tasks like sentiment analysis or machine translation. Character tokenization, although less common, splits the text into individual characters and can be useful for certain analysis tasks.
Text tokenization presents several challenges that need to be addressed. For instance, languages that lack explicit word boundaries, such as Chinese or Thai, pose difficulty in identifying and tokenizing words. Additionally, dealing with compound words, abbreviations, or contractions requires special handling to ensure accurate tokenization. Overcoming these challenges is crucial to ensure the accuracy and quality of subsequent analysis or processing tasks.
Importance of Text Tokenization
Text tokenization plays a critical role in various applications that involve processing and analyzing textual data. It provides a foundation for understanding and extracting meaningful information from large volumes of text. Here are some key reasons why text tokenization is important:
- Information Extraction: Text tokenization enables the extraction of useful information from text, such as identifying keywords, entities, or important phrases. By breaking down the text into tokens, it becomes easier to analyze and extract the relevant information needed for tasks like information retrieval or content analysis.
- Natural Language Processing: Text tokenization is a crucial step in natural language processing (NLP) tasks. It helps in processing and understanding human language by dividing it into smaller units that can be easily analyzed and processed by machines. NLP applications like sentiment analysis, machine translation, or text summarization heavily rely on tokenization to derive meaningful insights from textual data.
- Text Classification: Tokenization is essential for text classification tasks, where the goal is to categorize text into specific classes or categories. By breaking down the text into tokens, it becomes possible to analyze the frequency and distribution of different words or phrases, which in turn helps in creating accurate models for text classification.
- Search Engine Optimization: Tokenization is an integral part of search engine optimization (SEO) techniques. Search engines use tokenization to analyze and index web pages, allowing them to retrieve relevant search results based on user queries. By tokenizing web page content, search engines can understand the context and relevance of the information, improving the accuracy and effectiveness of search results.
- Data Preprocessing: Before performing any analysis or processing on textual data, it often requires preprocessing, which includes tokenization. Tokenization removes unnecessary noise from the text, such as punctuation marks or special characters, and focuses on the most important elements. This helps in achieving better accuracy and reliability in subsequent data analysis tasks.
In summary, text tokenization is crucial for extracting meaningful information, enabling natural language processing, improving text classification, optimizing search engine results, and preprocessing textual data. Its significance lies in its ability to break down text into smaller units that can be easily analyzed, processed, and understood by machines. Without text tokenization, extracting insights from textual data and performing various NLP tasks would be significantly more challenging and time-consuming.
Process of Text Tokenization
The process of text tokenization involves several steps to break down a given text into smaller, meaningful units called tokens. These tokens serve as the building blocks for analysis, processing, or understanding of the text. Here is an overview of the typical process of text tokenization:
- Text Segmentation: The first step in text tokenization is text segmentation, where the text is divided into segments such as sentences or paragraphs. This segmentation helps in managing the text structure and provides context for further tokenization.
- Token Boundary Identification: Once the text is segmented, the next step is to identify the boundaries of individual tokens within each segment. This is done by considering factors such as whitespace, punctuation marks, or specific language rules. Token boundary identification may vary depending on the specific requirements of the analysis or processing task.
- Tokenization Method: There are various approaches to text tokenization, including rule-based, statistical, and hybrid methods. Rule-based tokenization relies on predefined rules, such as whitespace or punctuation marks, to determine token boundaries. Statistical tokenization utilizes statistical models to make informed decisions about tokenization based on the probabilities of certain sequences. Hybrid tokenization combines both rule-based and statistical approaches to achieve more accurate results. The choice of tokenization method depends on the nature of the text and the specific requirements of the task.
- Token Generation: Once the boundaries of tokens are identified, the text is further divided into individual tokens. This can be done at the word level, where the text is divided into individual words, or at the sentence level, where the text is split into sentences. Alternatively, in character tokenization, the text is broken down into individual characters. The choice of tokenization level depends on the specific requirements of the task at hand.
- Token Representation: Tokens can be represented in various ways, depending on the specific needs of the analysis or processing. They can be represented as strings, integers, or other data structures, depending on the underlying system or algorithm. Token representation is crucial for subsequent analysis or processing tasks that rely on the extracted tokens.
The process of text tokenization is iterative and dynamic, as it may involve multiple iterations and adjustments to achieve the desired tokenization results. It requires careful consideration of the text’s structure, language, and specific requirements of the task at hand. By breaking down the text into tokens, text tokenization enables more effective analysis, processing, and understanding of textual data.
Different Approaches to Text Tokenization
Text tokenization can be approached in various ways, depending on the specific requirements of the task and the nature of the text being processed. Different approaches to text tokenization have their own advantages and limitations. Here are three common approaches to text tokenization:
- Rule-based Tokenization: Rule-based tokenization relies on predefined rules to determine how the text should be split into tokens. These rules can be based on patterns, such as whitespace or specific punctuation marks, to identify token boundaries. Rule-based tokenization is useful when working with languages that have explicit word boundaries, as well as for tasks where specific tokenization rules need to be enforced. However, it may struggle with irregular cases like compound words, abbreviations, or contractions, where the simple rules may not apply.
- Statistical Tokenization: Statistical tokenization utilizes statistical models to make informed decisions about token boundaries. These models analyze the text and calculate probabilities to determine where tokens should be split. Statistical tokenization is useful when dealing with languages or texts that lack explicit word boundaries, such as Chinese or Thai. It can adapt to different contexts and is more flexible than rule-based tokenization. However, statistical tokenizers require training data and may be sensitive to variations in the training corpus, making them less ideal for specialized domains or rare languages.
- Hybrid Tokenization: Hybrid tokenization combines rule-based and statistical approaches to achieve more accurate results. This approach leverages the advantages of both methods by using rules as a starting point and then refining the token boundaries using statistical models. Hybrid tokenization is often employed to improve rule-based tokenization by handling irregular cases and exceptions. It provides a more flexible and adaptable tokenization process that can handle various linguistic complexities. However, hybrid tokenization requires additional complexity in terms of rule development and model integration.
The choice of tokenization approach depends on various factors, including the nature of the text, the specific requirements of the task, and the available resources. Rule-based tokenization is often employed for tasks that require strict adherence to predefined rules, while statistical tokenization is more suitable for languages or domains with ambiguous word boundaries. Hybrid tokenization offers a balance between accuracy and flexibility, making it a popular choice in many applications.
It’s important to note that there is no one-size-fits-all solution for text tokenization, and the choice of approach should be made based on careful analysis and consideration of the specific context and requirements. Combining multiple approaches or fine-tuning existing ones can also lead to improved results in certain cases. Regardless of the approach chosen, text tokenization is a critical step in information retrieval, natural language processing, and various other applications where understanding and processing textual data is crucial.
Common Methods of Tokenization
Text tokenization can be performed using different methods, depending on the specific requirements of the task and the nature of the text being processed. Here are three common methods of tokenization:
- Word Tokenization: Word tokenization, also known as word segmentation, is the process of breaking the text into individual words. This method is widely used in various natural language processing (NLP) tasks, such as sentiment analysis, machine translation, and text classification. Word tokenization is typically performed by splitting the text based on whitespace or specific punctuation marks. However, it can be more challenging for languages with agglutinative or morphologically rich structures, where there might not be clear boundaries between words.
- Sentence Tokenization: Sentence tokenization involves breaking the text into sentences. This method is essential for tasks that require analyzing or processing text at the sentence level, such as text summarization, sentiment analysis, or machine translation. Sentence tokenization is typically performed using punctuation marks like periods, exclamation points, and question marks as indicators of sentence boundaries. However, sentence tokenization can be challenging in cases where punctuation marks are used differently, or there are abbreviations or numeric expressions that resemble sentence-ending punctuation.
- Character Tokenization: Character tokenization breaks down the text into individual characters. This method is less common and is typically used in specific cases where analyzing or processing individual characters is necessary, such as handwriting recognition or certain linguistic analysis tasks. Character tokenization can be relatively straightforward, as each character is considered a token. However, it can lead to a significant increase in the number of tokens and may not be suitable for tasks that require higher-level units, such as words or sentences.
The choice of tokenization method depends on the specific requirements of the task and the nature of the text being processed. For instance, word tokenization is commonly used in tasks that focus on word-level analysis or processing, such as language modeling or part-of-speech tagging. Sentence tokenization, on the other hand, is crucial for tasks that require understanding or processing text at the sentence level. Meanwhile, character tokenization is employed in tasks that deal with individual character-level information.
It’s important to note that these methods can be combined or modified based on the specific linguistic characteristics of the text or the requirements of the task. For example, a combination of word and sentence tokenization might be used to break the text into both words and sentences simultaneously. Additionally, specialized tokenization methods might be developed for specific domains, languages, or text types to cater to their unique characteristics and requirements.
Overall, the selection of a suitable tokenization method is critical for the accurate analysis, processing, and understanding of textual data. The choice should consider the specific task, the linguistic characteristics of the text, and the desired level of granularity for analysis or processing. By adopting the appropriate tokenization method, researchers and practitioners can unlock valuable insights and improve the overall performance of their text-based applications.
Challenges in Text Tokenization
While text tokenization is a fundamental process in natural language processing (NLP) and information retrieval, it comes with several challenges that need to be addressed. These challenges arise due to the complexities and variations present in languages and texts. Here are some common challenges in text tokenization:
- Word Boundary Ambiguity: One of the major challenges in tokenization is word boundary ambiguity. Many languages don’t have explicit word boundaries or use different conventions, making it difficult to determine where one word ends and another begins. This is especially true for languages like Chinese or Thai, which are written without spaces between words. Resolving word boundary ambiguity requires sophisticated techniques and linguistic knowledge.
- Compound Words: Compound words pose another challenge in tokenization. These are words that are formed by combining two or more individual words, such as “blackboard” or “website.” Determining where to divide compound words into separate tokens can be challenging, as the division can affect the meaning and interpretation of the text. Proper identification and tokenization of compound words are important for accurate analysis and understanding of the text.
- Abbreviations and Contractions: Abbreviations and contractions are commonly used in written language, and they present challenges for tokenization. Abbreviations, such as “Mr.” or “U.S.A.,” may need to be treated as separate tokens or as part of a larger word. Similarly, contractions like “can’t” or “I’m” can be challenging to tokenize, as they involve merging multiple words into a single token. Accurate handling of abbreviations and contractions is crucial for preserving the intended meaning of the text.
- Special Characters and Symbols: Texts often contain special characters, symbols, or emojis that may need to be considered as separate tokens. However, identifying and tokenizing these special characters correctly can be challenging, as they can have various meanings or functions based on the context. Tokenization methods need to account for these special characters and symbols to avoid distorting the meaning or semantic content of the text.
- Linguistic Complexity: The linguistic complexity of different languages and dialects can pose challenges in tokenization. Languages with rich morphological structures or complex grammar rules may require more sophisticated tokenization algorithms. Additionally, dialectal variations, slang, or informal language can complicate the tokenization process, as they may deviate from standard language rules. Adaptability and flexibility are necessary to handle different linguistic complexities effectively.
Overcoming these challenges in text tokenization requires a combination of linguistic knowledge, domain expertise, and technical approaches. Researchers and practitioners continue to develop advanced tokenization algorithms and techniques to handle the complexities of different languages and text types. Proper handling of these challenges is crucial for ensuring the accuracy and reliability of subsequent analysis, understanding, and processing of textual data.
Applications of Text Tokenization
Text tokenization is an essential process with a wide range of applications in various fields that involve processing and analyzing textual data. Here are some key applications where text tokenization plays a crucial role:
- Information Retrieval: Text tokenization is fundamental to information retrieval systems. By breaking down the text into tokens, search engines can analyze and index documents more effectively, allowing for efficient retrieval of relevant information based on user queries. Tokenization helps in organizing and representing textual data in a structured manner, improving the accuracy and speed of information retrieval systems.
- Natural Language Processing (NLP): NLP tasks heavily rely on text tokenization. Tokenization allows machines to understand and process natural language by breaking it down into meaningful units for further analysis. NLP applications such as sentiment analysis, machine translation, text classification, and named entity recognition all require accurate tokenization to extract and analyze meaningful information. Tokenization provides the foundation for various higher-level NLP tasks.
- Text Analysis and Mining: Text tokenization is essential for text analysis and mining tasks, where the goal is to extract insights and patterns from large volumes of textual data. Tokenization plays a key role in tasks such as text summarization, topic modeling, sentiment analysis, and keyword extraction. By breaking the text into tokens, it becomes possible to analyze the frequency, distribution, and relationships of different words or phrases, enabling more accurate and meaningful analysis of textual data.
- Text Classification: Tokenization forms the basis for text classification tasks. Text is tokenized into units such as words, sentences, or phrases, which are then used as features for training classification models. By representing text as tokens, it becomes possible to analyze the frequency and distribution of different words or phrases within specific classes or categories, improving the accuracy and efficiency of text classification models. Text tokenization is crucial in applications like spam detection, sentiment analysis, and topic classification.
- Search Engine Optimization (SEO): Tokenization plays a vital role in search engine optimization. Search engines use tokenization to analyze and understand web page content, enabling them to provide relevant search results. By tokenizing web page text, search engines can identify keywords, phrases, and other important elements that influence search result rankings. Tokenization contributes to better indexing, retrieval, and ranking of web pages, enhancing the visibility and discoverability of content on the web.
These are just a few examples of the wide range of applications where text tokenization is crucial. Virtually any task that involves processing, analyzing, or understanding textual data can benefit from accurate and effective text tokenization. The ability to break down text into meaningful units enables machines to extract insights, understand language, and make informed decisions based on textual information. As technologies advance and new applications emerge, the importance of text tokenization continues to grow in the realm of text-centric fields.
Conclusion
Text tokenization is a foundational process in natural language processing (NLP), information retrieval, and various other text-centric applications. By breaking down a chunk of text into smaller, meaningful units called tokens, text tokenization enables machines to analyze, process, and understand textual data more effectively.
We explored the definition, importance, process, different approaches, common methods, challenges, and applications of text tokenization. This process is crucial for tasks such as information retrieval, NLP, text analysis and mining, text classification, and search engine optimization.
During text tokenization, the choice of approach and method is influenced by factors such as the nature of the text, the specific requirements of the task, and the linguistic complexities involved. Rule-based tokenization, statistical tokenization, and hybrid tokenization are the main approaches, and word tokenization, sentence tokenization, and character tokenization are the common methods employed.
However, text tokenization comes with challenges such as word boundary ambiguity, compound word handling, abbreviation and contraction identification, special character recognition, and linguistic complexity. Overcoming these challenges requires specialized techniques and a comprehensive understanding of the text being processed.
In conclusion, text tokenization is a crucial step in dealing with textual data. It enables machines to extract meaningful information, understand language, perform accurate analysis, and improve information retrieval. As technologies continue to advance and new applications emerge, the importance of accurate and effective text tokenization will only grow, contributing to more nuanced and insightful analyses of textual data in various domains.