Introduction
Welcome to the world of machine learning! As technology continues to advance, the field of machine learning has gained significant popularity and is being utilized in various industries. One of the key aspects of machine learning is the ability to make accurate predictions using statistical models. To evaluate the performance and accuracy of such models, we rely on various evaluation metrics. One such metric is the Mean Absolute Error (MAE).
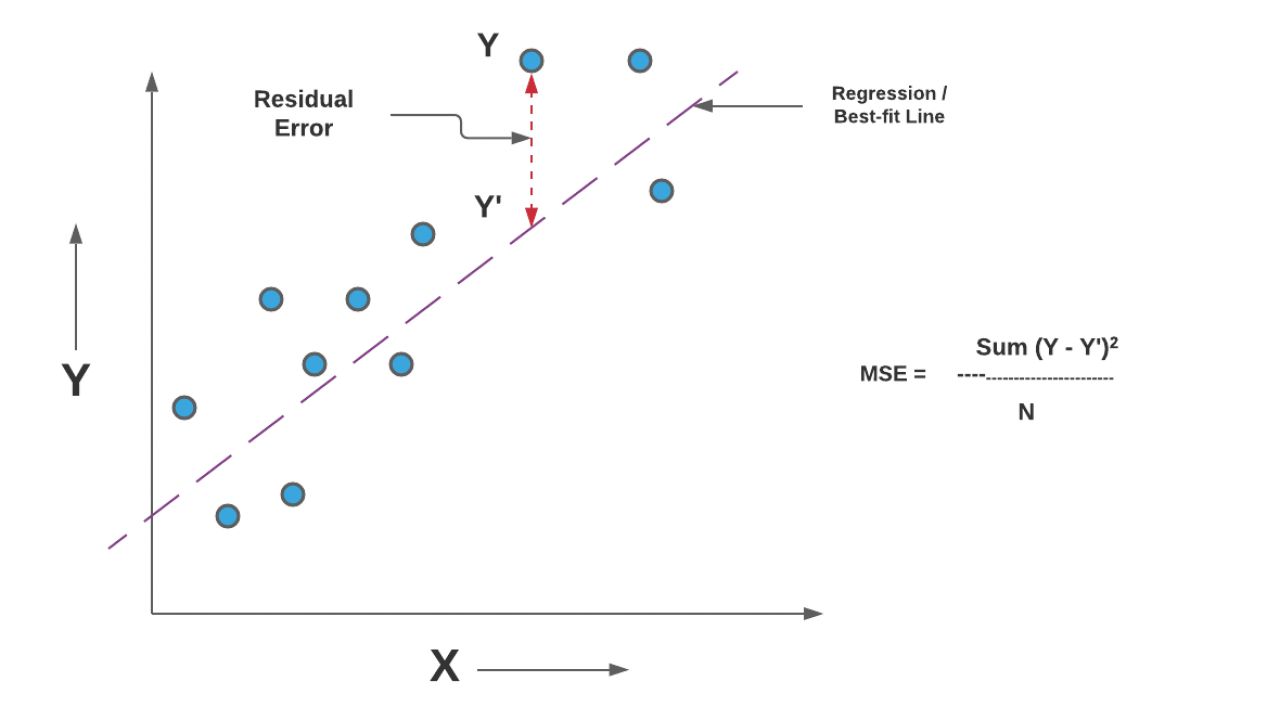
Mean Absolute Error is a commonly used evaluation metric in machine learning to measure the average magnitude of errors between predicted and actual values. It provides a valuable understanding of how well a predictive model is performing by quantifying the average discrepancy between the predicted and real values.
MAE is especially useful when dealing with continuous variables, such as temperature, stock prices, or sales figures. By determining the average error magnitude, it helps us assess the quality of the model’s predictions and make necessary adjustments if needed.
Throughout this article, we will delve into the concept of Mean Absolute Error, understand its calculation formula, explore its interpretation, and analyze its advantages and disadvantages. We will also explore the applications of MAE in various fields of machine learning and provide examples to illustrate its practical implementation. By the end of this article, you will have a solid understanding of the significance and usage of Mean Absolute Error in the field of machine learning.
Definition of Mean Absolute Error
Mean Absolute Error (MAE) is a metric used in machine learning to measure the average magnitude of errors between predicted and actual values. It provides a reliable measure of how far the predicted values deviate from the true values in a dataset. Unlike other metrics that consider the squared differences of errors, MAE focuses on the absolute differences.
Mathematically, the Mean Absolute Error is calculated by taking the average of the absolute differences between the predicted values (represented as ^y) and the actual values (represented as y) in a dataset. It can be expressed as:
MAE = (1/n) * Σ|^y – y|
Where:
- MAE is the Mean Absolute Error
- n is the number of data points in the dataset
- Σ represents the sum of all absolute differences between predicted and actual values
- ^y is the predicted value
- y is the true value
The calculated MAE value represents the average magnitude of the errors in the predicted values. It is important to note that the MAE value is always non-negative, as it considers the absolute differences between predicted and actual values. The closer the MAE value is to zero, the better the model’s performance, indicating a smaller average error magnitude and a higher level of accuracy.
By using MAE as an evaluation metric, we can objectively assess the predictive power of our model and compare it to other models or baseline performance. It allows us to understand how well the model predicts the target variable and aids in the selection and optimization of machine learning algorithms.
Formula for Mean Absolute Error
The Mean Absolute Error (MAE) is calculated using a simple formula that involves finding the average of the absolute differences between the predicted values and the actual values in a dataset. The formula is as follows:
MAE = (1/n) * Σ|^y – y|
In this formula:
- MAE represents the Mean Absolute Error.
- n denotes the number of data points in the dataset.
- ^y signifies the predicted value.
- y represents the actual value.
- Σ represents the summation symbol, indicating that we need to sum up the absolute differences for all data points.
Let’s illustrate the formula with an example:
Suppose we have a dataset with 5 data points as follows:
| Actual Value (y) | Predicted Value (^y) | Absolute Difference (|^y – y|) |
|---|---|---|
| 10 | 8 | 2 |
| 5 | 7 | 2 |
| 8 | 9 | 1 |
| 12 | 11 | 1 |
| 7 | 6 | 1 |
To calculate the MAE, we need to sum up the absolute differences and divide it by the number of data points:
MAE = (1/5) * (2 + 2 + 1 + 1 + 1) = 0.7
Therefore, the Mean Absolute Error for this dataset is 0.7.
The MAE value essentially represents the average magnitude of the errors in the predicted values. A lower MAE value indicates a higher level of accuracy, as it means that the predicted values are closer to the actual values. Conversely, a higher MAE value suggests that the model’s predictions deviate significantly from the true values.
By utilizing this simple formula, we can quantitatively evaluate the performance of machine learning models and make informed decisions regarding their accuracy and reliability.
Interpretation of Mean Absolute Error
The Mean Absolute Error (MAE) is a valuable metric for evaluating the performance and accuracy of machine learning models. When interpreting the MAE value, several key points should be considered.
Firstly, the MAE value indicates the average magnitude of errors in the predicted values. It represents how far, on average, the predicted values deviate from the true values in the dataset. A lower MAE value suggests that the model’s predictions are closer to the actual values, indicating a higher level of accuracy. Conversely, a higher MAE value indicates larger errors, indicating less accurate predictions.
Another aspect to consider is the context of the problem being solved. The interpretation of the MAE value depends on the specific domain and the units of the target variable. For example, in a regression problem where the target variable represents sales revenue in dollars, an MAE value of $1000 might be acceptable if the average sales revenue is in the millions. However, the same MAE value would be considered poor if the average sales revenue is in the thousands. Understanding the scale and context of the problem is crucial in interpreting the significance of the MAE value.
Furthermore, the MAE value is an absolute measure, meaning it does not provide information about the direction of the errors. It only considers the magnitude of the errors. This can be both an advantage and a disadvantage. On one hand, it allows us to assess the overall accuracy of the model without being influenced by the direction of the errors. On the other hand, it may not reflect the impact of outliers or extreme errors that could significantly affect the model’s performance. Therefore, it is important to consider other evaluation metrics in conjunction with MAE to get a comprehensive understanding of the model’s performance.
Lastly, comparing the MAE values of different models or variations of the same model can provide insights into their relative performance. If one model has a significantly lower MAE value than another, it generally indicates that the former model is making more accurate predictions.
In summary, the interpretation of the Mean Absolute Error involves considering the average magnitude of errors, understanding the context of the problem, recognizing its absolute nature, and comparing it to other models or baselines. By doing so, we can gain valuable insights into the accuracy and performance of machine learning models and make informed decisions in model selection and optimization.
Advantages and Disadvantages of Mean Absolute Error
The Mean Absolute Error (MAE) is a widely used evaluation metric in machine learning with various advantages and disadvantages. Understanding these can help guide the selection and interpretation of MAE in different scenarios.
Advantages:
- Easy to understand: MAE has a straightforward interpretation as it represents the average magnitude of errors. It provides a simple and intuitive measure of how well a model’s predictions align with the true values.
- Robust to outliers: MAE is not affected by extreme values or outliers, as it considers the absolute differences between predicted and actual values. This makes it a suitable metric when the focus is on the overall performance and not specifically on individual outliers.
- Resistant to skewed distributions: MAE performs well even when the target variable has non-normal or skewed distributions. It is not influenced by the shape of the distribution and provides a reliable measure of error estimation.
Disadvantages:
- Insensitive to variations in error magnitude: MAE treats all errors equally, regardless of their magnitude. It does not differentiate between small errors and large errors. As a result, it may not capture the impact of significant errors that could be highly influential in certain applications.
- Does not consider error direction: MAE is an absolute measure that only focuses on the magnitude of errors. It does not take into account whether the predictions are consistently overestimating or underestimating the true values. This limitation can be critical in certain scenarios, where the direction of error matters.
- Equally weighted across all data points: MAE treats all data points equally, regardless of their importance or contribution to the overall performance of the model. This can be problematic when certain data points have more significance or carry more weight in the analysis.
Despite its drawbacks, the MAE metric is widely used and provides valuable insights into the performance of machine learning models. Its simplicity, robustness to outliers, and resistance to skewed distributions make it a reliable choice in many applications. However, it is important to consider the specific characteristics of the problem and desired outcomes before solely relying on MAE as the sole evaluation metric. In some cases, a combination of different metrics may be necessary to thoroughly evaluate the accuracy and effectiveness of the models.
Applications of Mean Absolute Error in Machine Learning
The Mean Absolute Error (MAE) metric has a wide range of applications in the field of machine learning. Its simplicity and robustness make it a popular choice for evaluating models and measuring their predictive performance. Here are some key applications of MAE in machine learning:
- Regression tasks: MAE is commonly used in regression tasks where the goal is to predict a continuous target variable. It provides a quantitative measure of the average error magnitude between the predicted and actual values, allowing us to assess the accuracy and reliability of the regression models.
- Feature selection: MAE can be employed in feature selection processes to identify the most significant features in a dataset. By evaluating the impact of individual features on the model’s performance using MAE, we can determine which features are most relevant and informative in driving accurate predictions.
- Model comparison: MAE is an effective metric for comparing the performance of different models on the same dataset. By calculating the MAE values for each model, we can assess and identify the model that consistently produces more accurate predictions.
- Model monitoring: MAE can also be utilized for ongoing model monitoring in production systems. By tracking the MAE values over time, we can detect any significant changes in the model’s performance, identifying if it requires retraining or adjustments to maintain its predictive accuracy.
- Anomaly detection: MAE can be useful in detecting anomalies or outliers in datasets. By calculating the MAE for each data point, we can identify instances where the predicted value significantly deviates from the actual value, indicating potential anomalies or errors in the dataset.
Additionally, MAE can be combined with other evaluation metrics to provide a comprehensive understanding of model performance. For example, it can be used in conjunction with Mean Squared Error (MSE) to assess accuracy and precision simultaneously.
Overall, the applications of MAE in machine learning are diverse and versatile. Its applicability across various tasks, simplicity, and robustness make it a valuable evaluation metric for assessing model performance, feature selection, and model monitoring. By utilizing MAE effectively, we can make informed decisions in model selection, optimization, and problem-solving in the field of machine learning.
Examples of Calculating Mean Absolute Error
To better understand how the Mean Absolute Error (MAE) is calculated, let’s consider a couple of examples.
Example 1:
Suppose we have a dataset with actual and predicted values for a regression task as follows:
| Actual Value (y) | Predicted Value (^y) | Absolute Difference (|^y – y|) |
|---|---|---|
| 8 | 7 | 1 |
| 12 | 10 | 2 |
| 9 | 9 | 0 |
To calculate the MAE, we sum up the absolute differences and divide it by the number of data points:
MAE = (1/3) * (1 + 2 + 0) = 1
In this example, the MAE value is 1, indicating that, on average, the predicted values deviate from the actual values by 1 unit.
Example 2:
Consider a scenario where we have a larger dataset with actual and predicted values:
| Actual Value (y) | Predicted Value (^y) | Absolute Difference (|^y – y|) |
|---|---|---|
| 15 | 10 | 5 |
| 20 | 25 | 5 |
| 18 | 18 | 0 |
| 12 | 14 | 2 |
| 25 | 30 | 5 |
Calculating the MAE, we sum the absolute differences and divide it by the number of data points:
MAE = (1/5) * (5 + 5 + 0 + 2 + 5) = 3.4
In this example, the MAE value is 3.4, indicating that, on average, the predicted values deviate from the actual values by 3.4 units.
These examples demonstrate how the MAE metric provides an understanding of the average error magnitude between the predicted and actual values. By calculating the MAE, we can quantitatively assess the performance and accuracy of machine learning models, aiding in the selection, optimization, and comparison of different models.
Conclusion
Mean Absolute Error (MAE) is a valuable evaluation metric in machine learning that allows us to measure the average magnitude of errors between predicted and actual values. It provides insights into the accuracy and performance of regression models and aids in the selection, optimization, and comparison of different models.
In this article, we have explored the concept of MAE, its calculation formula, and its interpretation. We have seen that MAE is easy to understand and robust to outliers and skewed distributions. However, it has limitations such as being insensitive to error direction and equally weighting all data points.
Despite its limitations, MAE finds applications in various domains of machine learning. It is commonly used in regression tasks, feature selection, model comparison, model monitoring, and anomaly detection. By utilizing MAE effectively, we can make data-driven decisions, improve the accuracy of machine learning models, and enhance the performance of our predictions.
In conclusion, Mean Absolute Error provides a valuable measure of error estimation and helps us understand the average discrepancy between predicted and actual values in a dataset. By considering its advantages, disadvantages, and applications, we can utilize MAE as a powerful tool in the field of machine learning to enhance our models and make better predictions.