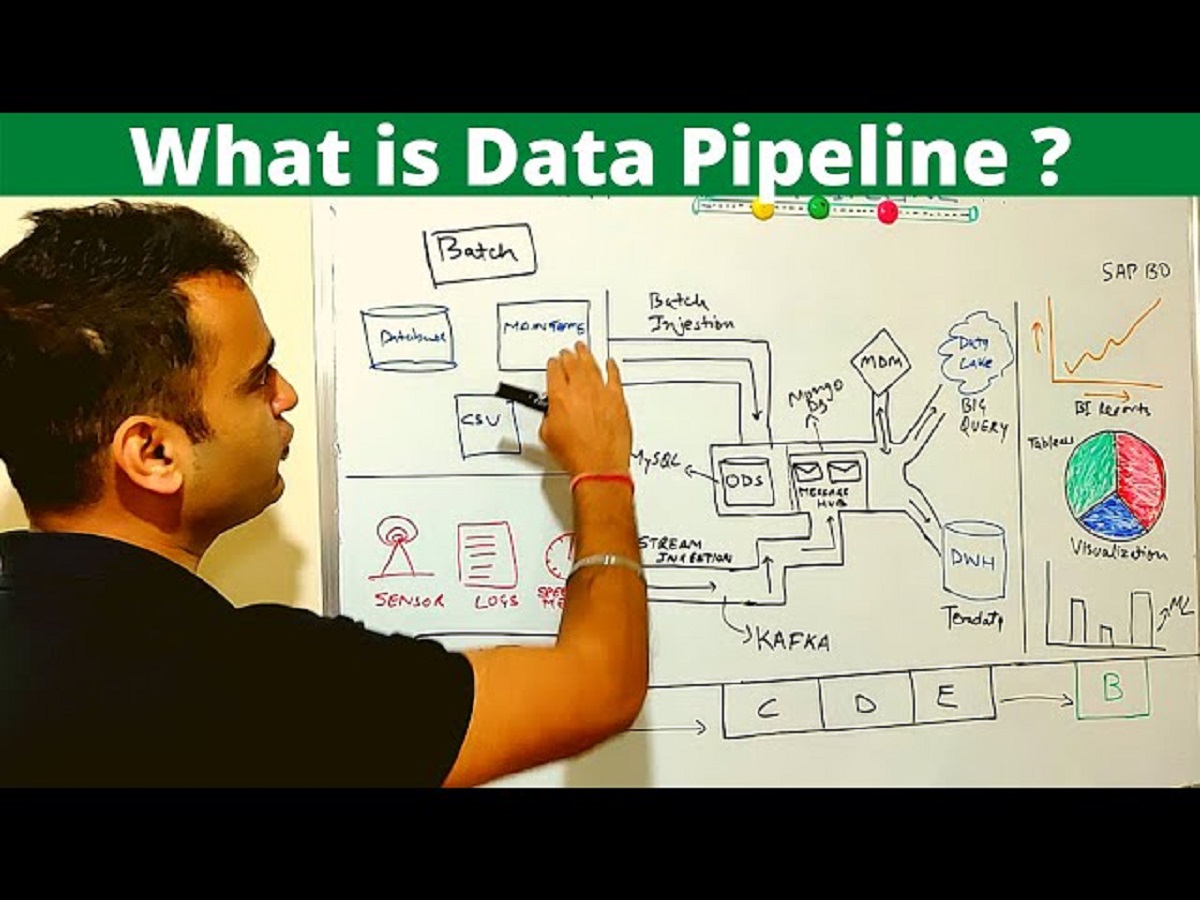
Introduction
Data ingestion is a fundamental process in the world of big data. With the exponential growth of data generated from various sources, organizations need efficient methods to collect, process, and store this data for analysis and decision-making purposes. Data ingestion involves the process of collecting and importing data from multiple sources into a central location or data storage system, such as a data warehouse, data lake, or database.
In today’s fast-paced digital landscape, data ingestion plays a crucial role in enabling organizations to unlock the true potential of big data. It allows enterprises to gain valuable insights, identify trends, and make data-driven decisions that can drive business growth and innovation.
As organizations collect data from diverse sources like databases, streaming platforms, social media, IoT devices, and more, data ingestion becomes a critical step to ensure that the data is properly captured and transformed into a suitable format for analysis. By efficiently managing the process of data ingestion, companies can extract maximum value from their data and drive competitive advantages.
Data ingestion is not just about transferring data from one place to another; it also includes data validation, transformation, filtering, and enrichment. The data collected can be structured, semi-structured, or unstructured, and the ingestion process needs to handle this variety of data efficiently.
Furthermore, data ingestion needs to be scalable and adaptable to accommodate the ever-growing volume and velocity of data. With the rise of real-time data generation and streaming analytics, organizations require robust data ingestion methods to continuously collect and process data in near real-time.
In this article, we will explore the concept of data ingestion in big data, its importance, the challenges associated with it, different data ingestion methods, popular tools and platforms, and best practices to ensure a successful data ingestion process.
What is Data Ingestion?
Data ingestion is the process of collecting and importing data from various sources into a central repository or data storage system. It involves capturing, transforming, and loading data from different sources, such as databases, streaming platforms, files, APIs, and more.
During the data ingestion process, the data is validated, cleaned, and transformed to ensure its quality and compatibility with the target storage system. This step is crucial as it determines the accuracy and reliability of the data for subsequent analysis and decision-making.
Data ingestion is not a one-time event but rather an ongoing process to continuously collect and update data as new information becomes available. With the increasing volume, variety, and velocity of data in the era of big data and IoT, the need for efficient data ingestion methods has become essential.
Effective data ingestion involves understanding the source systems, their formats, APIs, and protocols. It requires designing appropriate data pipelines to extract data from the sources, transform it into a standardized format or schema, and load it into the target storage system. Companies often employ various tools, technologies, and frameworks to streamline the data ingestion process and ensure its scalability and reliability.
Data ingestion serves as the first step in the data processing pipeline, contributing to the success of subsequent data analysis, modeling, and visualization. It lays the foundation for advanced analytics, machine learning, and AI applications. By ingesting data from multiple sources, organizations can gain a comprehensive view of their operations, customers, and market trends, leading to data-driven insights and informed decision-making.
Moreover, data ingestion plays a crucial role in data integration efforts. It allows organizations to consolidate data from disparate sources, creating a centralized data repository that can be accessed and analyzed more efficiently. This integration enables cross-functional analysis, data sharing, and collaboration among different teams within the organization.
In summary, data ingestion is the process of collecting, transforming, and loading data from various sources into a central repository. It is a crucial step in the data processing pipeline, enabling organizations to harness the power of big data and drive valuable insights for their business operations and decision-making processes.
Importance of Data Ingestion in Big Data
Data ingestion plays a vital role in the world of big data by enabling organizations to effectively manage and utilize the vast amounts of data available to them. Here are some key reasons why data ingestion is important in the context of big data:
1. Data Centralization: Data ingestion allows organizations to centralize their data from various sources into a single repository. This centralization facilitates better data management, data integration, and data governance. It enables businesses to have a holistic view of their data, leading to better decision-making and improved operational efficiency.
2. Real-time or Near Real-time Analytics: With the increasing velocity of data generation, real-time or near real-time analytics has become crucial for businesses. Data ingestion enables the continuous collection and processing of streaming data, allowing organizations to gain actionable insights and make timely decisions. By ingesting data in real-time, companies can identify emerging trends, monitor KPIs, and respond quickly to changing market conditions.
3. Improved Data Quality: Data ingestion involves data validation, cleaning, and transformation, which helps improve data quality. By enforcing data quality checks during the ingestion process, organizations can identify and rectify any issues or inconsistencies in the data. This ensures that the data used for analysis and decision-making is accurate, reliable, and consistent, leading to more reliable insights and outcomes.
4. Data Integration and Transformation: Data ingestion allows businesses to integrate data from different sources and formats. It provides the opportunity to transform and standardize data, making it compatible for analysis and reporting. By ingesting and integrating data from multiple sources, organizations can gain a comprehensive and unified view of their data, leading to better cross-functional analysis and insights.
5. Scalability and Flexibility: As the volume of data continues to grow rapidly, scalability and flexibility in data ingestion are crucial. Organizations need to be able to handle large volumes of data efficiently and adapt to changing data requirements. Data ingestion processes and tools that can scale and easily accommodate new data sources and formats are essential for handling big data efficiently.
6. Compliance and Data Security: Data ingestion processes can be designed to incorporate data privacy and security measures. By ensuring that data is encrypted, anonymized, or masked during the ingestion process, organizations can maintain compliance with data protection regulations and safeguard sensitive information. Thus, data ingestion contributes to maintaining data security and privacy standards.
Overall, data ingestion is of utmost importance in the world of big data as it enables organizations to centralize, analyze, and utilize data effectively. It provides the foundation for data-driven decision-making, real-time analytics, data integration, and scalability, ultimately leading to improved operational efficiency and competitive advantage.
Challenges in Data Ingestion
While data ingestion is crucial for managing and utilizing big data, it also comes with its own set of challenges. Here are some common challenges faced in the data ingestion process:
1. Data Variety and Complexity: Ingesting data from various sources means dealing with different data formats, structures, and systems. Each source may have its own unique challenges, such as data inconsistencies, missing values, or incompatible schemas. Extracting and transforming data from diverse sources to ensure consistency and compatibility can be a complex and time-consuming task.
2. Data Volume and Velocity: The sheer volume and velocity at which data is generated can pose challenges in data ingestion. Organizations need to design ingestion processes that can handle large volumes of data in a timely manner. Ingesting streaming data or real-time data adds further complexity, requiring robust infrastructure and technologies to handle the high throughput of data.
3. Data Quality and Integrity: Maintaining data quality throughout the ingestion process is critical. Inaccurate or inconsistent data can lead to flawed analysis and decision-making. Data cleansing and validation steps need to be implemented to identify and address any data quality issues. Ensuring data integrity, such as avoiding duplicates or data corruption during ingestion, is also essential.
4. Scalability and Performance: As data volumes grow, scalability becomes a challenge for data ingestion. Ingestion processes need to be able to scale up or down efficiently to handle increasing data demands while maintaining optimal performance. This requires robust architecture, distributed processing, and efficient resource utilization.
5. Real-time Data Ingestion: Ingesting real-time or streaming data adds complexity due to its continuous and fast-paced nature. Organizations need to employ technologies that can handle low latency, high throughput data ingestion. Ensuring data consistency, capturing all events, and maintaining data order are additional challenges faced in real-time data ingestion scenarios.
6. Data Security and Compliance: Ingesting and storing data requires addressing data security concerns. Protecting sensitive information, ensuring encryption, and complying with data privacy regulations are challenges organizations must navigate during ingestion. Proper access controls, data anonymization techniques, and data protection measures need to be implemented to maintain data security and compliance.
7. System Integration: Ingesting data from various sources often involves integrating with different systems, databases, and platforms. Ensuring compatibility, establishing suitable connectors, and managing dependencies can be challenging, especially when dealing with legacy systems or complex data architectures.
Despite these challenges, organizations can overcome them by adopting intelligent data ingestion approaches, utilizing data integration tools, implementing data quality checks, and leveraging scalable and flexible infrastructure. By addressing these challenges, organizations can improve the quality, accuracy, and reliability of their ingested data, enabling better insights and decision-making.
Data Ingestion Methods
There are several methods and approaches for data ingestion, each suited for different data sources and requirements. Organizations can choose the most appropriate method based on factors such as data volume, velocity, and integration complexity. Here are some commonly used data ingestion methods:
1. Extract, Transform, Load (ETL): ETL is a widely used data ingestion method that involves three main steps. First, data is extracted from various sources, including databases, files, or APIs. Then, the extracted data is transformed to a standardized format or schema, ensuring consistency and compatibility. Finally, the transformed data is loaded into the target storage system, such as a data warehouse or data lake. ETL processes are typically executed in batch or scheduled intervals, making them suitable for scenarios where near real-time ingestion is not required.
2. Change Data Capture (CDC): CDC is a method that captures and transfers only the changed data from source systems to the target system. It tracks and replicates data changes, such as updates, inserts, or deletes, in near real-time or real-time. CDC minimizes the amount of data transferred, reducing processing time and network bandwidth usage. It is commonly used for databases where real-time data replication is crucial, such as for continuous analytics or data warehousing.
3. Event-driven or Streaming Data Ingestion: Event-driven or streaming data ingestion involves capturing and processing data as it is generated in real-time. This method is commonly used for streaming platforms like Apache Kafka or Apache Flink. It allows for the continuous ingestion and analysis of high-velocity and high-volume data streams, enabling real-time analytics, alerting, and automation.
4. Batch Processing Data Ingestion: Batch processing involves ingesting large volumes of data in scheduled batches. Data is collected and processed in predefined intervals, making it suitable for scenarios where near real-time ingestion is not necessary. This method is commonly used for historical data analysis, reporting, and data warehousing, where data can be ingested overnight or during off-peak hours.
5. Real-time Data Ingestion: Real-time data ingestion is focused on capturing and processing data as soon as it is generated, without any delay. It is commonly used for IoT devices, sensors, social media streams, or mobile applications, where immediate data processing and analytics are required. Real-time ingestion ensures timely insights and enables rapid decision-making.
Organizations can also combine multiple data ingestion methods to meet their specific needs. For example, they can employ CDC for real-time database replication and ETL for batch ingestion from other sources. The choice of data ingestion method depends on the nature of the data, the desired latency, scalability requirements, and the processing capabilities of the target systems.
By selecting the appropriate data ingestion method, organizations can ensure efficient data collection, integration, and processing, thereby maximizing the value and usability of their data assets.
Extract, Transform, Load (ETL)
Extract, Transform, Load (ETL) is a widely used method for data ingestion, particularly in batch processing scenarios. It involves three main steps: extraction, transformation, and loading into a target data storage system. ETL is designed to handle large volumes of data and ensure its quality and compatibility for analysis and reporting purposes.
1. Extraction: In the extraction phase of ETL, data is collected and extracted from various sources, such as databases, files, or APIs. This involves querying databases, retrieving files, or pulling data from external sources. The goal is to gather the required data for further processing and analysis.
2. Transformation: Once the data is extracted, it goes through the transformation phase. During this step, the data is standardized, cleansed, and enriched to ensure its consistency and compatibility. Data transformation may involve tasks such as data validation, data cleansing to remove inconsistencies or duplicates, data aggregation, data normalization, or data enrichment through calculations or derivations.
Transformation also includes applying business rules, data validations, and data quality checks to ensure that the data meets specific requirements. Complex data transformations can be implemented to harmonize different data sources and create a unified view of the data.
3. Loading: After the data is transformed, it is loaded into the target data storage system, such as a data warehouse, data lake, or a database. The loading process involves mapping the transformed data to the target schema or structure and inserting it into the storage system. The loading phase may also involve partitioning the data, indexing it, or creating relational connections between tables based on the target system’s requirements.
ETL processes are typically executed in batches, where data is collected and processed periodically, such as daily, hourly, or in other predefined intervals. This batching process makes ETL suitable for scenarios where near real-time ingestion is not required, and data can be processed in regular intervals without compromising the overall data quality or accuracy.
ETL tools and frameworks provide features and functionalities to automate and streamline the extraction, transformation, and loading process. These tools help simplify complex data workflows, provide connectors to various data sources, offer visual interfaces for data mapping and transformation, and support scheduling and monitoring of the ETL pipelines.
While ETL is traditionally associated with batch processing, modern ETL approaches may incorporate real-time or near real-time capabilities to handle streaming data or have hybrid capabilities to combine both batch and real-time processing.
Overall, ETL is a powerful data ingestion method that enables organizations to efficiently extract, transform, and load data from various sources into a centralized storage system. By following the ETL process, businesses can ensure data consistency, integrity, and quality, making their data ready for analysis and decision-making.
Change Data Capture (CDC)
Change Data Capture (CDC) is a data ingestion method that focuses on capturing and transferring only the changed data from source systems to a target system in near real-time or real-time. CDC is commonly used for scenarios where continuous data replication or synchronization is required, such as database replication, data warehousing, or real-time analytics.
1. Capture: The first step in CDC is capturing the changes that occur in the source system. This involves monitoring and tracking any modifications, additions, or deletions made to the data. CDC can leverage the transaction logs or change logs maintained by the source system to detect and extract the changed data.
2. Transfer: Once the changes are captured, they are transferred to the target system. The changed data can be transported using various methods, such as message queues, streaming platforms, or replication protocols. The idea is to efficiently transmit the minimum amount of data required to keep the target system up-to-date with the changes happening in the source system.
3. Apply: In the target system, the captured changes are applied to the corresponding data structures. This process ensures that the data in the target system reflects the latest updates from the source system. The changes may involve updates to existing records, addition of new records, or removal of obsolete records.
CDC allows organizations to replicate and synchronize their data in near real-time, ensuring that the target system has the most up-to-date data. It enables several use cases:
Data Replication: CDC is commonly used for replicating databases in real-time across multiple locations. By capturing and transferring only the changes made to the data, CDC minimizes the network bandwidth usage and processing time required for data replication.
Data Warehousing: CDC can be employed to continuously capture and load data from transactional databases into a data warehouse. It ensures that the data warehouse has the latest updates from the source system, enabling timely and accurate reporting and analysis.
Real-time Analytics: CDC enables real-time analytics by capturing and delivering the changes as they occur in the source system. This allows for continuous monitoring, analysis, and visualization of the changing data, facilitating timely decision-making and proactive actions.
Implementing CDC involves establishing connectors or interfaces with the source systems to capture the changes efficiently. It requires understanding the source system’s transaction logs or change logs and configuring appropriate mechanisms to identify and extract the relevant changes.
Modern CDC solutions often provide additional capabilities, such as data transformation, filtering, and routing, allowing organizations to tailor the captured data based on their specific needs. These solutions also offer monitoring and auditing features to track the progress and ensure the integrity of the CDC process.
CDC enables organizations to keep their target systems up-to-date with the changing data, providing real-time or near real-time access to critical information. By capturing only the changes, CDC optimizes data ingestion by reducing network bandwidth, processing time, and storage requirements, making it a valuable method for real-time data replication and synchronization.
Event-driven or Streaming Data Ingestion
Event-driven or streaming data ingestion is a method that focuses on capturing and processing data as it is generated in real-time. This approach is particularly useful for scenarios where organizations need to ingest and analyze high-velocity and high-volume data streams, such as IoT device data, social media feeds, financial market data, or application logs.
1. Event Capture: In event-driven data ingestion, events are captured as they occur. An event can represent a data record, an update, a log entry, or any other piece of data generated at a specific time. The events can be sent by various sources, including sensors, applications, or systems, often using protocols like MQTT or Apache Kafka.
2. Stream Processing: Once the events are captured, they can be processed in real-time through stream processing frameworks or technologies. Stream processors allow organizations to transform, filter, aggregate, and analyze the streaming data as it flows. This enables real-time decision-making, anomaly detection, pattern identification, and other real-time analytics use cases.
3. Continuous Processing: The essence of event-driven ingestion is the continuous and near real-time processing of the streaming data. Rather than waiting for batches or predefined intervals, event-driven ingestion processes data in a continuous manner, often within milliseconds of its generation. This makes it suitable for use cases that require immediate insights, rapid response, or near real-time monitoring.
4. Scalability and Efficiency: Event-driven ingestion is designed to scale with the high-velocity and high-volume nature of streaming data. Stream processors leverage distributed computing, parallelism, and fault-tolerant mechanisms to handle the continuous flow of data. This ensures that the ingestion system can handle the spikes in data volume and velocity without sacrificing performance or reliability.
5. Event-driven Architectures: Event-driven data ingestion aligns well with event-driven architectures, where various components or microservices communicate through events. In such architectures, data ingestion becomes an integral part, enabling different systems to react and respond to events in real-time.
6. Complex Event Processing: Event-driven ingestion often involves complex event processing (CEP), where events are analyzed for patterns, correlations, or anomalies in near real-time. CEP allows organizations to capture meaningful insights from the streaming data and trigger actions or alerts based on specific event patterns or conditions.
Event-driven or streaming data ingestion is supported by various technologies and frameworks such as Apache Kafka, Apache Flink, and Amazon Kinesis. These technologies provide scalable, fault-tolerant, and distributed processing capabilities, enabling organizations to handle high-velocity streaming data effectively.
Organizations can use event-driven ingestion to power real-time analytics, dynamic dashboarding, proactive monitoring, fraud detection, predictive maintenance, and other use cases that require immediate insights from streaming data sources. By ingesting and processing streaming data in real-time, organizations can gain timely and valuable insights, enabling them to make data-driven decisions and take actions swiftly.
Batch Processing Data Ingestion
Batch processing data ingestion is a method that involves ingesting and processing large volumes of data in scheduled batches. It is commonly used for scenarios where near real-time data ingestion is not required, and the data can be processed in predefined intervals or during off-peak hours.
1. Data Collection: In batch processing, data is collected from various sources, such as databases, files, or APIs, during a specific time interval or based on a predefined schedule. The collected data is stored or staged in a temporary location before further processing.
2. Data Transformation: Once the data is collected, it undergoes transformation to ensure consistency and compatibility. Data transformation may involve tasks such as data validation, cleansing, standardization, aggregation, or enrichment. Data is processed to meet the requirements of the target system, such as formatting data into a specific schema or performing calculations or derivations.
3. Data Loading: After the data is transformed, it is loaded into the target storage system, such as a data warehouse, a data lake, or a database. The loading process involves inserting the processed and formatted data into the appropriate tables or structures of the target system.
4. Scheduled Execution: Batch processing data ingestion is typically performed on a scheduled basis, such as daily, hourly, or in other predefined intervals. The ingestion process can be automated using batch scheduling tools or scripts, ensuring the regular and consistent collection, transformation, and loading of data.
5. Resource Optimization: Batch processing allows organizations to optimize resource utilization by performing data ingestion tasks during off-peak hours when system and network resources are less utilized. This helps ensure smooth operation and minimal impact on the performance of the source or target systems during peak business hours.
6. Incremental Updates: In batch processing, organizations can implement incremental updates to process only the new or modified data since the last batch execution. This minimizes redundant processing, reduces computational overhead, and enables faster data ingestion by focusing on the delta or changes in the data.
The batch processing data ingestion approach is commonly employed for historical data analysis, reporting, periodic data updates, or scenarios where the processing time is less critical than real-time requirements. It allows organizations to efficiently process and ingest large volumes of data in manageable chunks, ensuring data consistency, accuracy, and quality.
Batch processing data ingestion is supported by various tools and technologies, including ETL (Extract, Transform, Load) tools, batch processing frameworks (such as Apache Spark or Apache Hadoop), and job scheduling tools (such as Apache Airflow or Cron). These tools enable organizations to automate, schedule, and execute the batch ingestion process reliably and efficiently.
Organizations can leverage the benefits of batch processing data ingestion for various use cases, including historical data analysis, data warehousing, periodic reporting, regulatory compliance, and batch-based data integration from multiple sources. By processing data in batches, organizations can optimize resource utilization, ensure data quality, and meet their data processing and analysis requirements within a predefined schedule.
Real-time Data Ingestion
Real-time data ingestion is a method that focuses on capturing and processing data as soon as it is generated, without any delay. This approach is suitable for scenarios where immediate data processing and analysis are required to enable timely decision-making, real-time monitoring, or rapid responses to events.
1. Continuous Data Capture: Real-time data ingestion involves continuously capturing data as it is generated by various sources such as IoT devices, sensors, social media feeds, or application logs. The data capture process often involves leveraging technologies like message queues, event-driven architectures, or streaming platforms such as Apache Kafka, Amazon Kinesis, or Apache Flink.
2. Low-latency Processing: Once the data is captured, it undergoes immediate or near real-time processing. This involves analyzing, transforming, and aggregating the data as it arrives. Low-latency processing techniques and technologies, such as stream processing frameworks, allow organizations to process and analyze the data in real-time, enabling quick insights and actionable outcomes.
3. Real-time Analytics: Real-time data ingestion enables organizations to perform real-time analytics and monitoring. By processing and analyzing the data as it arrives, organizations can identify patterns, detect anomalies, calculate metrics, and generate alerts or notifications in real-time. Real-time analytics allows for proactive decision-making, rapid response to incidents, and timely identification of emerging trends.
4. Data Enrichment: Real-time data ingestion facilitates data enrichment by injecting additional context, metadata, or derived data into the incoming stream. This can involve enriching the data with external data sources, applying machine learning models, or enriching with reference data, enabling more comprehensive real-time analysis and insights.
5. Scalability and High Throughput: Real-time data ingestion systems need to handle high data volumes and high-velocity data streams. This requires scalable and high-throughput infrastructure or technologies that can accommodate the continuous flow of data. Horizontal scaling, distributed processing, and optimized resource allocation are key considerations for ensuring the efficiency and reliability of real-time data ingestion.
6. Event-driven Architectures: Real-time data ingestion aligns well with event-driven architectures, where various components or microservices communicate through events. In such architectures, data ingestion becomes an integral part, enabling different systems to react and respond to events in real-time, ensuring a seamless and interconnected ecosystem.
Real-time data ingestion is supported by various technologies and frameworks, such as Apache Kafka, Apache Flink, Amazon Kinesis, or Google Cloud Pub/Sub. These technologies provide the necessary capabilities for handling real-time data capture, processing, and analytics at scale.
Organizations can leverage real-time data ingestion for use cases such as real-time monitoring, fraud detection, network security, predictive maintenance, supply chain optimization, or any scenario where immediate insights or actions are crucial. By ingesting and processing data in real-time, organizations can unlock the potential of their data assets, enabling agility, responsiveness, and data-driven decision-making in dynamic and fast-paced environments.
Data Ingestion Tools and Platforms
Data ingestion tools and platforms play a crucial role in simplifying and streamlining the data ingestion process. These tools provide the necessary functionalities to extract, transform, and load data from various sources into target storage systems. They offer features to handle different data formats, ensure data quality, and support scalability. Here are some popular data ingestion tools and platforms:
1. Apache Kafka: Apache Kafka is a distributed streaming platform that is widely used for real-time data ingestion. It provides high-throughput, fault-tolerant, and scalable messaging infrastructure, enabling organizations to capture and process streaming data in real-time. Kafka is known for its ability to handle high volumes of data and support high-velocity data streams.
2. Apache Nifi: Apache Nifi is an open-source data integration tool that offers a visual interface for designing and managing data flows. It provides a wide range of processors and connectors to handle data ingestion from various sources, such as databases, files, APIs, and streaming platforms. Nifi supports data transformation, routing, and enrichment, making it suitable for complex data ingestion scenarios.
3. AWS Data Pipeline: AWS Data Pipeline is a cloud-based data ingestion and orchestration service offered by Amazon Web Services (AWS). It allows organizations to define and schedule data pipelines for ingesting, transforming, and moving data between different AWS services and on-premises data sources. Data Pipeline supports batch processing and real-time streaming ingestion, making it versatile for various data ingestion needs.
4. Google Cloud Dataflow: Google Cloud Dataflow is a fully managed batch and stream processing service provided by Google Cloud. It offers a unified programming model for both batch and streaming data processing. With Dataflow, organizations can design and execute data pipelines for efficient data ingestion, transformation, and analysis, leveraging the power of Google’s infrastructure.
5. Talend: Talend is an enterprise-grade data integration platform that offers a comprehensive set of tools for data ingestion, transformation, and management. It provides a visual interface for designing and deploying data pipelines and offers a wide range of connectors to various data sources and targets. Talend supports both batch and real-time data ingestion, making it suitable for diverse data integration needs.
6. Informatica PowerCenter: Informatica PowerCenter is a popular data integration platform that offers a broad set of capabilities, including data ingestion. It provides a scalable and high-performance environment for extracting, transforming, and loading data from diverse sources into target systems. PowerCenter supports batch and real-time data ingestion with features such as data profiling, data quality checks, and data transformation.
These are just a few examples of data ingestion tools and platforms available in the market. When selecting a data ingestion tool or platform, organizations should consider factors such as scalability, ease of use, flexibility, data format support, security, and compatibility with existing infrastructure and technologies. Evaluating and choosing the right tool or platform can significantly enhance the efficiency and effectiveness of the data ingestion process.
Data Ingestion Best Practices
Implementing data ingestion best practices is essential for ensuring the accuracy, reliability, and efficiency of the data ingestion process. By following these best practices, organizations can optimize their data ingestion pipelines and maximize the value and usability of their data. Here are some key best practices to consider:
1. Data Validation and Quality Checks: Implement data validation checks during the ingestion process to ensure data accuracy and integrity. Validate data formats, check for missing values or inconsistencies, and enforce data quality rules. Performing data quality checks improves the reliability of the ingested data for analysis and decision-making.
2. Incremental Data Updates: Implement incremental data updates to process only the new or modified data since the last ingestion. This reduces redundant processing, improves efficiency, and speeds up the ingestion process. Leveraging change data capture (CDC) or timestamp-based techniques enables the ingestion of only the relevant delta or changes in the data.
3. Scalability and Performance: Design the data ingestion pipeline to be scalable and able to handle increasing data volumes and velocities. Use distributed processing, parallelism, and optimized resource utilization to accommodate the growing demands of data ingestion. Assess and provision the necessary hardware and infrastructure to ensure optimal performance.
4. Data Security and Privacy: Incorporate security measures to protect ingested data. Encrypt sensitive data during transmission and storage, authenticate and authorize access to the data, and implement data masking or anonymization techniques when necessary. Compliance with data privacy regulations, such as GDPR or CCPA, should be considered and adhered to.
5. Error Handling and Monitoring: Establish robust error handling mechanisms to handle data ingestion failures or exceptions. Set up proper logging, alerts, and notifications to identify and address any issues promptly. Monitor the ingestion pipeline performance, data consistency, and data quality to ensure the overall health of the ingestion process.
6. Documentation and Metadata Management: Maintain documentation and metadata about the ingested data sources, transformations, and processing steps. This helps in understanding the data lineage, facilitating troubleshooting, and ensuring the reproducibility of the ingestion process. Documenting the schema and mapping rules improves the understanding of the ingested data and enhances data governance.
7. Data Retention and Archiving: Define data retention policies for the ingested data based on regulatory requirements and business needs. Establish archiving strategies to store historical data for long-term analysis or compliance purposes. Data archiving helps optimize the performance of the ingestion process by reducing the amount of data stored in the active storage system.
8. Testing and Validation: Perform thorough testing and validation of the data ingestion pipeline before deployment. Validate the data transformation rules, check for data integrity, and conduct end-to-end testing to ensure the accuracy and reliability of the ingested data. Consider using sample datasets or simulated data for testing purposes.
9. Continuous Optimization: Regularly evaluate and optimize the data ingestion pipeline based on changing data requirements and business needs. Regularly review the performance metrics, identify bottlenecks, and apply appropriate optimizations, such as parallel processing, indexing, or compression. Continuously monitoring and optimizing the ingestion process helps ensure its efficiency and effectiveness over time.
By adopting these data ingestion best practices, organizations can ensure the accuracy, reliability, and efficiency of their data ingestion pipelines. This, in turn, leads to high-quality ingested data that can drive informed decision-making, improved operational efficiency, and valuable insights from big data.
Conclusion
Data ingestion is a critical process in the world of big data, enabling organizations to collect, transform, and load data from various sources into centralized storage systems. By effectively managing the data ingestion process, organizations can unlock the full potential of their data and derive valuable insights for better decision-making and innovation.
In this article, we explored key concepts related to data ingestion in big data, including its definition, importance, challenges, and various methods. We discussed Extract, Transform, Load (ETL) and Change Data Capture (CDC) as popular data ingestion methods, along with event-driven or streaming data ingestion and batch processing data ingestion. We also highlighted the significance of data ingestion tools and platforms in simplifying and streamlining the ingestion process.
Furthermore, we covered important best practices for data ingestion, including data validation, scalability, security, error handling, and documentation. Implementing these best practices ensures the accuracy, reliability, and efficiency of the data ingestion pipeline, leading to high-quality ingested data for analysis, reporting, and decision-making purposes.
Data ingestion continues to evolve in response to the ever-increasing volume, variety, and velocity of data. Real-time data ingestion and the integration of data from diverse sources remain crucial for organizations seeking to harness the power of big data. By staying abreast of emerging technologies and best practices, organizations can adapt their data ingestion processes to meet evolving business needs.
Ultimately, data ingestion serves as the foundation for successful data analytics, machine learning, AI applications, and data-driven decision-making. By implementing effective data ingestion strategies, organizations can leverage their data assets, gain actionable insights, and drive innovation for a competitive advantage in today’s data-driven landscape.