Introduction
Big data is revolutionizing the way businesses operate and make decisions. As the volume, velocity, and variety of data continue to grow exponentially, there is an increasing demand for skilled professionals who can extract valuable insights from this vast amount of information. This is where the role of a Big Data Scientist comes into play.
A Big Data Scientist is a professional who possesses the technical expertise and analytical skills required to identify patterns, trends, and correlations within large and complex datasets. They use advanced statistical techniques and machine learning algorithms to analyze data and develop models that can predict future outcomes or provide valuable insights for decision-making.
As a Big Data Scientist, your role goes beyond just analyzing data. You will also be responsible for cleaning and preprocessing data to ensure its quality and reliability. Additionally, you will need to possess strong programming skills to manipulate and process data efficiently.
This article will outline the necessary education and skills required to become a successful Big Data Scientist. We will also delve into the key aspects of understanding big data, the programming languages and tools commonly used in this field, as well as the importance of machine learning, statistical analysis, data visualization, and data cleaning in the day-to-day tasks of a Big Data Scientist.
Furthermore, we will explore the process of building and evaluating models to extract meaningful insights from data, and discuss the ethical considerations that Big Data Scientists must be aware of.
This article will serve as a comprehensive guide for anyone interested in pursuing a career as a Big Data Scientist, providing valuable insights into the essential skills and knowledge required to thrive in this exciting and evolving field.
Education and Skills Required
To become a Big Data Scientist, a strong educational foundation and a diverse set of skills are essential. Here are the key requirements:
Educational Background: A minimum of a bachelor’s degree in a relevant field such as computer science, mathematics, statistics, or data science is typically required. Some organizations may even prefer candidates with a master’s or doctoral degree in these fields.
Mathematical and Statistical Knowledge: A solid understanding of mathematics and statistics is crucial for analyzing and interpreting complex data. Proficiency in linear algebra, calculus, probability theory, and statistical modeling is highly beneficial for a Big Data Scientist.
Programming Skills: Expertise in programming languages such as Python, R, and Java is essential for manipulating and processing large datasets. Strong coding skills are necessary for developing algorithms, implementing machine learning models, and automating data processes.
SQL and Database Management: Knowledge of Structured Query Language (SQL) is important for working with relational databases and retrieving data efficiently. Understanding database management concepts, such as normalization and indexing, is also advantageous.
Machine Learning and Data Analysis: Familiarity with machine learning algorithms, such as linear regression, decision trees, and neural networks, is crucial for developing predictive models and extracting insights from data. Proficiency in data analysis techniques, such as clustering, classification, and regression, is also necessary.
Data Visualization: The ability to communicate findings effectively through data visualization is a valuable skill for a Big Data Scientist. Knowledge of visualization libraries, such as Matplotlib, ggplot, or Tableau, and experience in creating visually appealing and informative charts, graphs, and dashboards is highly desirable.
Problem-Solving and Analytical Thinking: Big Data Scientists need to be excellent problem solvers, capable of formulating research questions, designing experiments, and analyzing results. Strong analytical thinking skills are critical for identifying patterns and trends within complex datasets.
Ethical Awareness: As a Big Data Scientist, you will be working with sensitive and potentially personal data. Understanding ethical principles, such as data privacy, consent, and fairness, is essential. It is crucial to adhere to ethical guidelines and protect the privacy and rights of individuals.
Continuous Learning: The field of big data is constantly evolving, with new tools, technologies, and techniques emerging regularly. Being open to continuous learning and staying updated with the latest advancements is crucial for a successful Big Data Scientist.
Communication and Collaboration: Effective communication and collaboration skills are essential for working as part of a multidisciplinary team. Big Data Scientists need to be able to convey complex concepts and findings to non-technical stakeholders in a clear and concise manner.
Gaining practical experience through internships, research projects, or industry collaborations can further enhance your skills and make you a competitive candidate in the field of big data.
Understanding Big Data
Big data refers to the massive volume of structured, semi-structured, and unstructured data that is generated at an unprecedented rate from various sources. This data is characterized by its volume, velocity, and variety, posing significant challenges for traditional data processing methods.
Volume: Big data is typically characterized by its massive volume. Traditional data processing systems are often unable to handle such large amounts of data effectively. As a Big Data Scientist, you will need to work with tools and technologies that can process and analyze data on a massive scale.
Velocity: The velocity of big data refers to the high speed at which data is generated and needs to be processed. Streaming data from social media feeds, sensors, or IoT devices requires real-time or near-real-time analysis. As a Big Data Scientist, you must be adept at handling and processing data in real-time or near-real-time scenarios.
Variety: Big data comes in various formats and types. It includes structured data from databases, semi-structured data like JSON or XML, and unstructured data such as text documents, images, or videos. Being able to deal with different data formats and extract meaningful insights from them is crucial for a Big Data Scientist.
Importance: Big data holds immense value for organizations across industries. It can provide insights into customer behavior, market trends, operational efficiencies, and fraud detection, among other things. By analyzing and understanding big data, organizations can make data-driven decisions and gain a competitive edge.
Challenges: While big data presents significant opportunities, it also brings challenges. Some of the key challenges include data quality and reliability, data privacy and security, data integration from multiple sources, and the need for scalable and cost-effective storage and processing solutions.
Tools and Technologies: To analyze and process big data effectively, Big Data Scientists rely on various tools and technologies. This includes distributed storage and processing frameworks like Hadoop and Apache Spark, data querying tools like Apache Hive and Apache Drill, and data streaming platforms like Apache Kafka and Apache Flink. Familiarity with these tools is crucial for handling big data efficiently.
Data Governance: Big Data Scientists must also be aware of data governance practices. This involves ensuring data quality, data privacy, compliance with regulations, and establishing clear data ownership and accountability.
By understanding the nature of big data, its challenges, and the tools and technologies available, Big Data Scientists can effectively harness the power of data and derive meaningful insights for organizations.
Programming Languages and Tools
As a Big Data Scientist, proficiency in programming languages and tools is crucial for data manipulation, analysis, and model development. Here are some of the key programming languages and tools commonly used in the field:
Python: Python is a popular programming language among Big Data Scientists due to its simplicity, versatility, and a vast ecosystem of libraries and frameworks. It offers extensive support for data analysis and machine learning through libraries such as NumPy, Pandas, and scikit-learn.
R: R is another widely used language in the field of data science. It provides powerful statistical analysis capabilities and a range of specialized packages for data manipulation, visualization, and machine learning. R is particularly favored for its statistical modeling and data visualization capabilities.
Java: Java is a general-purpose programming language that is known for its scalability and performance. It is commonly used for developing distributed applications and working with large-scale data processing frameworks like Apache Hadoop. Java is also used in the development of enterprise-level solutions for data analysis.
SQL: Structured Query Language (SQL) is essential for working with relational databases. SQL enables querying, manipulating, and managing structured data efficiently. Knowledge of SQL is crucial for data retrieval, data cleaning, and data integration tasks.
Hadoop: Apache Hadoop is a widely used open-source framework for distributed storage and processing of large-scale data. It allows for the distributed processing of data across clusters of computers, enabling scalability and fault tolerance. The Hadoop ecosystem includes tools like Hadoop Distributed File System (HDFS) and MapReduce for data storage and processing.
Apache Spark: Apache Spark is a fast and distributed computing system that provides an alternative to MapReduce for big data processing. It offers in-memory processing capabilities, making it well-suited for iterative algorithms and real-time analytics. Spark has APIs for Java, Scala, Python, and R, making it accessible to Big Data Scientists using different programming languages.
Apache Kafka: Kafka is a distributed streaming platform used for real-time data streaming and processing. It is commonly used for building data pipelines and handling high-volume, real-time data streams. Kafka offers fault tolerance and scalability, making it an important component in streaming data analytics.
Visualization Tools: Data visualization is a critical aspect of a Big Data Scientist’s work. Tools like Tableau, Matplotlib, ggplot, and D3.js enable the creation of visually appealing charts, graphs, and dashboards for communicating insights effectively.
Jupyter Notebooks: Jupyter Notebooks provide an interactive and flexible environment for data exploration, analysis, and model development. They combine code execution, visualization, and documentation in a single interface, making it easier to develop and share reproducible data science workflows.
Keep in mind that the choice of programming language and tools may vary depending on the specific needs and requirements of the project and organization. It is important to stay updated with the latest developments in programming languages and tools and adapt to emerging technologies in the field of big data.
Machine Learning and Statistical Analysis
Machine learning and statistical analysis are at the core of a Big Data Scientist’s toolkit. These techniques enable the extraction of valuable insights and the development of predictive models from large and complex datasets. Let’s explore the importance of machine learning and statistical analysis in the field of big data:
Machine Learning: Machine learning involves the development of algorithms that can learn from data and make predictions or take actions without being explicitly programmed. Big Data Scientists utilize machine learning techniques to identify patterns, trends, and relationships within datasets and build models for prediction and classification tasks. Machine learning algorithms such as linear regression, decision trees, support vector machines, and neural networks are commonly used in big data analysis.
Statistical Analysis: Statistical analysis plays a vital role in understanding the underlying patterns and relationships within data. Big Data Scientists use statistical techniques to summarize data, perform hypothesis testing, and uncover meaningful insights. Descriptive statistics, inferential statistics, correlation analysis, and regression analysis are among the key statistical methods employed in the analysis of big data.
Feature Selection and Engineering: A crucial step in machine learning is identifying the relevant features or variables that contribute most to the prediction or classification task. Big Data Scientists employ techniques such as statistical tests, dimensionality reduction algorithms, and domain knowledge to select and engineer meaningful features from the available data, improving the accuracy and interpretability of the models.
Model Evaluation and Validation: Evaluating and validating machine learning models is essential to ensure their effectiveness and generalizability. Big Data Scientists employ techniques such as cross-validation, confusion matrices, precision-recall curves, and ROC curves to assess model performance and identify potential issues like overfitting or underfitting.
Ensemble Methods: Ensemble methods combine multiple models or predictions to achieve better overall performance. Techniques such as bagging, boosting, stacking, and random forests are commonly used by Big Data Scientists to improve the accuracy and robustness of their models.
Unsupervised Learning: In addition to supervised learning, unsupervised learning techniques are employed by Big Data Scientists to explore and discover underlying patterns in data. Clustering algorithms, such as k-means or hierarchical clustering, are used to group similar data points, while dimensionality reduction techniques, such as principal component analysis (PCA) or t-SNE, help visualize and understand complex datasets.
Deep Learning: Deep learning, a subset of machine learning, focuses on the development and training of neural networks with multiple hidden layers to learn complex representations and make accurate predictions. Deep learning is particularly effective in the analysis of unstructured data such as images, audio, or text.
Interpretability and Explainability: While machine learning models can provide accurate predictions, it is essential to understand and explain the factors driving those predictions. Big Data Scientists employ techniques such as feature importance analysis, model visualization, or surrogate models to gain insights into the decision-making process of complex models.
By combining machine learning and statistical analysis techniques, Big Data Scientists can unearth valuable insights, make informed decisions, and build accurate predictive models, leading to improved business outcomes and driving innovation in various industries.
Data Visualization
Data visualization is a crucial aspect of a Big Data Scientist’s work. It involves representing complex data in a visual format, such as charts, graphs, and dashboards, to communicate insights effectively. Here’s why data visualization is so important in the field of big data:
Understanding Complex Data: Big data often consists of large and complex datasets that can be overwhelming to comprehend. Data visualization techniques help simplify and distill the information, making it easier for Big Data Scientists and stakeholders to understand patterns, trends, and relationships within the data. Visual representations enable a quick overview and provide a deeper understanding of the underlying data.
Identifying Patterns and Anomalies: Visualizing data can reveal hidden patterns, correlations, and anomalies that may not be apparent through numerical analysis alone. Heatmaps, scatter plots, and histograms can highlight outliers or indicate clusters within the data. By visually exploring the data, Big Data Scientists can gain valuable insights that drive further analysis and decision-making.
Conveying Insights Effectively: Data visualization is a powerful tool for storytelling. By presenting data in a visual and compelling way, Big Data Scientists can effectively communicate their findings to stakeholders, regardless of their technical background. Well-designed visualizations can convey complex concepts, trends, and comparisons in a simple and intuitive manner, making it easier for decision-makers to grasp the significance of the data.
Enhancing Data-Driven Decision-Making: Visualizations help decision-makers understand the implications of the data and make informed business decisions. By visualizing data trends, performance metrics, or customer behavior, Big Data Scientists can support evidence-based decision-making processes. Interactive dashboards and real-time visualizations enable stakeholders to explore and analyze the data themselves, empowering them to make timely and data-driven choices.
Spotting Data Quality Issues: Data visualization can aid in identifying data quality issues, such as missing values, outliers, or inconsistencies. By visualizing the data, Big Data Scientists can quickly detect discrepancies or anomalies that need further investigation. This allows for data cleaning and preprocessing to ensure accurate and reliable analysis.
Selecting the Right Visualization: With a wide range of visualization techniques available, Big Data Scientists must choose the most suitable format for presenting their data. Bar charts, line graphs, pie charts, and scatter plots are just a few examples of the visualization tools at their disposal. The choice depends on the type of data, the message to be conveyed, and the target audience. Selecting the right visualization ensures the information is presented in the most meaningful and impactful way.
Tools for Data Visualization: Various tools and libraries are available to assist Big Data Scientists in creating visually appealing and interactive data visualizations. Tableau, Matplotlib, ggplot, D3.js, and Power BI are examples of popular tools used to develop advanced visualizations. Data visualization tools provide a user-friendly interface and enable customization, allowing Big Data Scientists to fine-tune their visualizations to suit their specific needs.
Data visualization is not just about presenting data; it is about telling a story, extracting insights, and enabling data-driven decision-making. By leveraging effective data visualization techniques, Big Data Scientists can transform complex data into meaningful and actionable insights that drive innovation and business success.
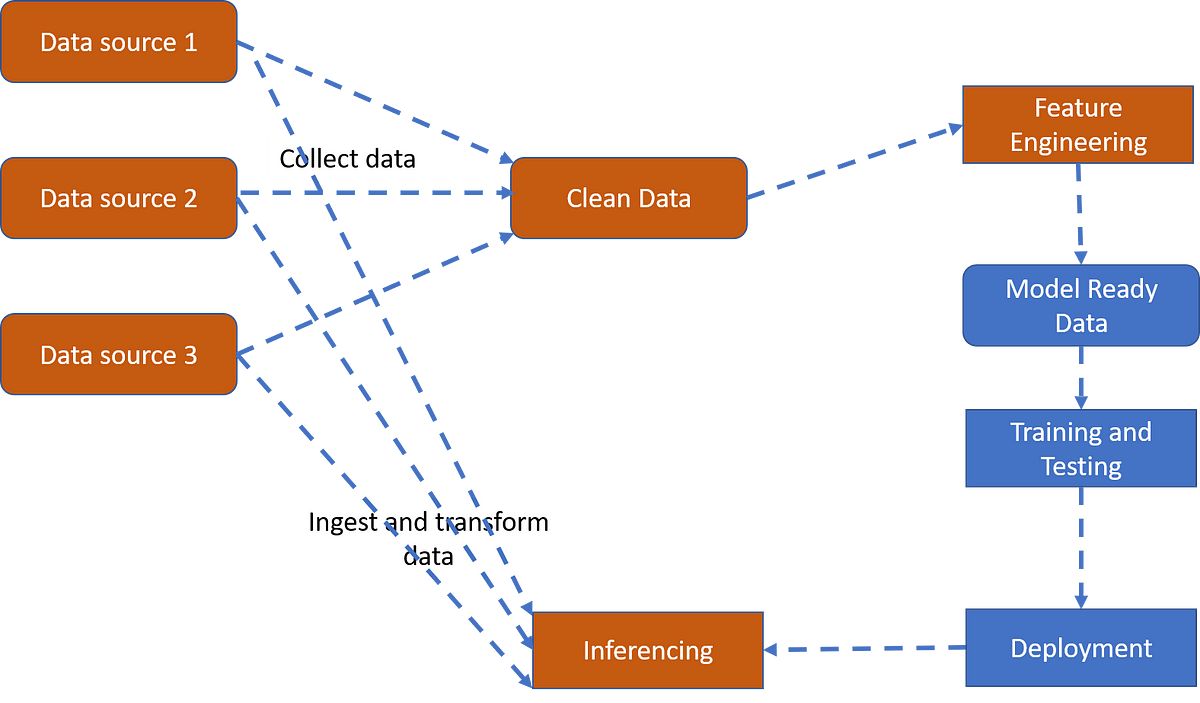
Data Cleaning and Preprocessing
Data cleaning and preprocessing are essential steps in the data analysis process for Big Data Scientists. They involve transforming raw and often messy data into a clean and structured format suitable for analysis. Here’s why data cleaning and preprocessing are crucial in the field of big data:
Data Quality Assurance: Big data often comes from various sources and may contain errors, missing values, or inconsistencies. Data cleaning ensures data quality by identifying and rectifying these issues. Missing data can be imputed, errors can be corrected, and inconsistent data can be standardized. This ensures that the data is accurate and reliable for analysis.
Data Integration: It is common for big data to be collected from multiple sources, each with its own structure and format. Data preprocessing involves integrating this disparate data into a unified format. This allows Big Data Scientists to combine and analyze data from various sources, gaining comprehensive insights that would not be possible with separate datasets.
Outlier Detection and Handling: Outliers can significantly impact the analysis and modeling process. Data preprocessing involves detecting and handling outliers, either by removing them or imputing them with suitable values. This ensures that the outliers do not skew the analysis or lead to biased results.
Normalization and Standardization: Data often needs to be normalized or standardized to ensure comparability and eliminate scale-related biases. Normalization adjusts the data to a common scale, while standardization transforms the data to have a mean of zero and a standard deviation of one. These techniques make the data suitable for certain analysis methods, such as clustering or classification algorithms.
Feature Extraction and Engineering: Data preprocessing involves identifying relevant features and transforming them into a suitable format for analysis. This may involve feature extraction, where new features are derived from existing ones, or feature engineering, where features are created based on domain knowledge. Proper feature extraction and engineering enhance the performance and interpretability of machine learning models.
Data Reduction: Big data can be voluminous, making analysis challenging. Data preprocessing includes techniques for data reduction, such as feature selection or dimensionality reduction. Feature selection identifies the most relevant features, discarding unnecessary ones, while dimensionality reduction techniques like Principal Component Analysis (PCA) or t-SNE reduce the dataset’s dimensionality while retaining as much relevant information as possible.
Data Imputation: Missing data is a common issue in big datasets. Data preprocessing involves imputing missing values using various techniques, such as mean imputation, regression imputation, or k-nearest neighbors imputation. This ensures that the missing data does not negatively impact the analysis or introduce biases.
Data Transformation: Data preprocessing may include transforming variables to improve their distribution or address specific assumptions. This can include log transformations, power transformations, or categorical variable encoding. Such transformations ensure that the data meets the assumptions required for certain statistical or machine learning techniques.
Data validation: Preprocessed data is validated to ensure it meets the requirements for further analysis. This involves checking for data integrity, verifying the accuracy of preprocessing techniques, and ensuring that transformed data aligns with the intended goals of analysis.
By performing data cleaning and preprocessing, Big Data Scientists can ensure that their analyses are accurate, reliable, and meaningful. These steps lay the foundation for deriving valuable insights and making data-driven decisions in the field of big data analysis.
Building and Evaluating Models
Building and evaluating models is a fundamental aspect of being a Big Data Scientist. This involves using machine learning and statistical techniques to develop predictive models based on the available data. Let’s explore the importance of building and evaluating models in the field of big data:
Model Building: Building models is the process of training machine learning algorithms on historical data to learn patterns and relationships. Big Data Scientists choose appropriate algorithms based on the nature of the problem, the available data, and the desired outcome. This step involves feature selection, hyperparameter tuning, and training the models using techniques like cross-validation.
Types of Models: Big Data Scientists can build a wide range of models depending on the problem at hand. Regression models are used to predict continuous outcomes, while classification models classify data into different categories or classes. Other models include clustering models for grouping similar data points, recommendation systems for personalized suggestions, and time series models for forecasting future trends.
Model Evaluation: Evaluating models is crucial for assessing their performance and determining their suitability for the problem being solved. Big Data Scientists use various evaluation metrics such as accuracy, precision, recall, F1-score, and area under the receiver operating characteristic (ROC) curve. Evaluation involves splitting the data into training and testing sets to measure how well the model generalizes to unseen data.
Overfitting and Underfitting: Overfitting occurs when a model performs well on the training data but fails to generalize to new data. Underfitting, on the other hand, occurs when a model is too simple and fails to capture the underlying patterns in the data. Big Data Scientists employ techniques such as regularization, cross-validation, and ensemble methods to mitigate overfitting and underfitting issues.
Model Interpretability: Understanding and interpreting models is crucial for extracting insights and making informed decisions. Big Data Scientists use techniques such as feature importance analysis, partial dependence plots, and model visualization to understand the factors driving predictions. Interpretability is particularly important in fields where accountability and transparency are critical, such as finance or healthcare.
Model Optimization: Big Data Scientists continuously strive to improve the performance of their models by optimizing hyperparameters, selecting appropriate algorithms, and incorporating domain knowledge. Techniques such as grid search, random search, or Bayesian optimization are used to find the optimal combination of hyperparameters.
Model Validation: Validating models involves assessing their performance on unseen data that was not used during model training. This helps ensure that the model performs well in real-world scenarios. Techniques such as k-fold cross-validation or holdout validation are used to validate models and estimate their performance on unseen data.
Model Deployment: Once a model is deemed reliable and effective, it can be deployed to make predictions on new data. This can include integrating the model into a production environment, creating an API for real-time predictions, or incorporating the model into a larger software system.
Evaluating Business Impact: In addition to technical evaluation, Big Data Scientists also assess the business impact of their models. This involves measuring how well the model achieves its intended goals, such as improving customer satisfaction, optimizing operations, or increasing revenue. Regular monitoring and periodic re-evaluation of the model’s performance are essential for ensuring continued success.
Building and evaluating models is a crucial part of a Big Data Scientist’s role. By selecting appropriate models, evaluating their performance accurately, and continuously optimizing them, Big Data Scientists can derive valuable insights, make informed decisions, and drive innovation in various industries.
Ethical Considerations
As Big Data Scientists work with vast amounts of data, it is important to consider the ethical implications of their work. Ethical considerations play a crucial role in ensuring that data is collected, analyzed, and used responsibly and ethically. Here are some key ethical considerations for Big Data Scientists:
Data Privacy: Respecting individuals’ privacy rights is of utmost importance. Big Data Scientists must adhere to privacy regulations and ensure that personal and sensitive information is protected. This includes obtaining explicit consent for data collection and ensuring secure data storage and transmission.
Data Bias and Fairness: Big data can sometimes reflect societal biases and inequalities. It is essential for Big Data Scientists to be aware of and mitigate biases in the data and the models they build. They should strive for fairness and equal treatment to avoid potential discrimination against individuals or groups.
Data Security: Big Data Scientists have a responsibility to protect data from unauthorized access or security breaches. They must follow best practices for data security, including encryption, access controls, and regular security audits.
Data Ownership and Intellectual Property: Understanding the ownership and intellectual property rights surrounding data is critical. Big Data Scientists should respect the legal and ethical boundaries related to data ownership and ensure compliance with intellectual property rights and licensing agreements.
Data Transparency and Explainability: Big Data Scientists should strive for transparency in their work, making their methodologies and algorithms understandable and explainable to stakeholders. This helps build trust and allows individuals impacted by the data analysis to understand how their data is used and how decisions are made based on it.
Consent and Informed Decision-Making: Big Data Scientists must obtain informed consent from individuals whose data is being collected and analyzed. They should clearly communicate the purpose and potential implications of data analysis and ensure that individuals have the right to withdraw consent at any time.
Data Retention and Deletion: When working with data, Big Data Scientists should establish policies for data retention and deletion. They should only retain data for as long as necessary and securely delete or anonymize data when it is no longer needed.
Data Use for Public Good: Big Data Scientists have the opportunity to positively impact society by leveraging data for public good, such as healthcare research or disaster response. However, ethical considerations must still be upheld, ensuring the responsible and ethical use of data even in such contexts.
Continuing Education and Ethical Awareness: Big Data Scientists should stay updated with ethical guidelines, regulations, and best practices in the field. They should continuously educate themselves on emerging issues and be aware of potential ethical dilemmas that may arise in their work.
Responsible Collaboration: Collaboration within multidisciplinary teams is common in big data projects. Big Data Scientists must ensure ethical practices are followed throughout collaborations, including data sharing, consent, and respecting intellectual property rights.
By considering and addressing these ethical considerations in their work, Big Data Scientists can uphold the ethical standards necessary for responsible data analysis and contribute to building a trustworthy and ethical data-driven society.
Conclusion
In conclusion, becoming a successful Big Data Scientist requires a solid educational foundation, a diverse set of skills, and a deep understanding of the field of big data. The ability to analyze, interpret, and extract meaningful insights from large and complex datasets is crucial in today’s data-driven world.
From understanding big data and mastering programming languages and tools to applying machine learning and statistical techniques, Big Data Scientists play a vital role in transforming raw data into valuable insights and predictions. Data cleaning and preprocessing ensure the reliability and accuracy of the data, while data visualization allows for effective communication of findings.
Building and evaluating models empower Big Data Scientists to develop accurate predictive models and make data-driven decisions. It is important to consider ethical considerations, such as data privacy, fairness, and transparency, to ensure responsible and ethical practices in working with data. Continuous learning and staying updated with emerging technologies and ethical guidelines are essential in this rapidly evolving field.
Becoming a skilled Big Data Scientist requires a combination of technical expertise, analytical thinking, and ethical responsibility. By harnessing the power of big data and applying advanced analytical techniques, Big Data Scientists can drive innovation, improve decision-making, and create impactful solutions across various industries.
Are you ready to embark on a journey into the world of big data? Equip yourself with the necessary skills, stay curious, and embrace the challenges and opportunities that come with being a Big Data Scientist.