Introduction
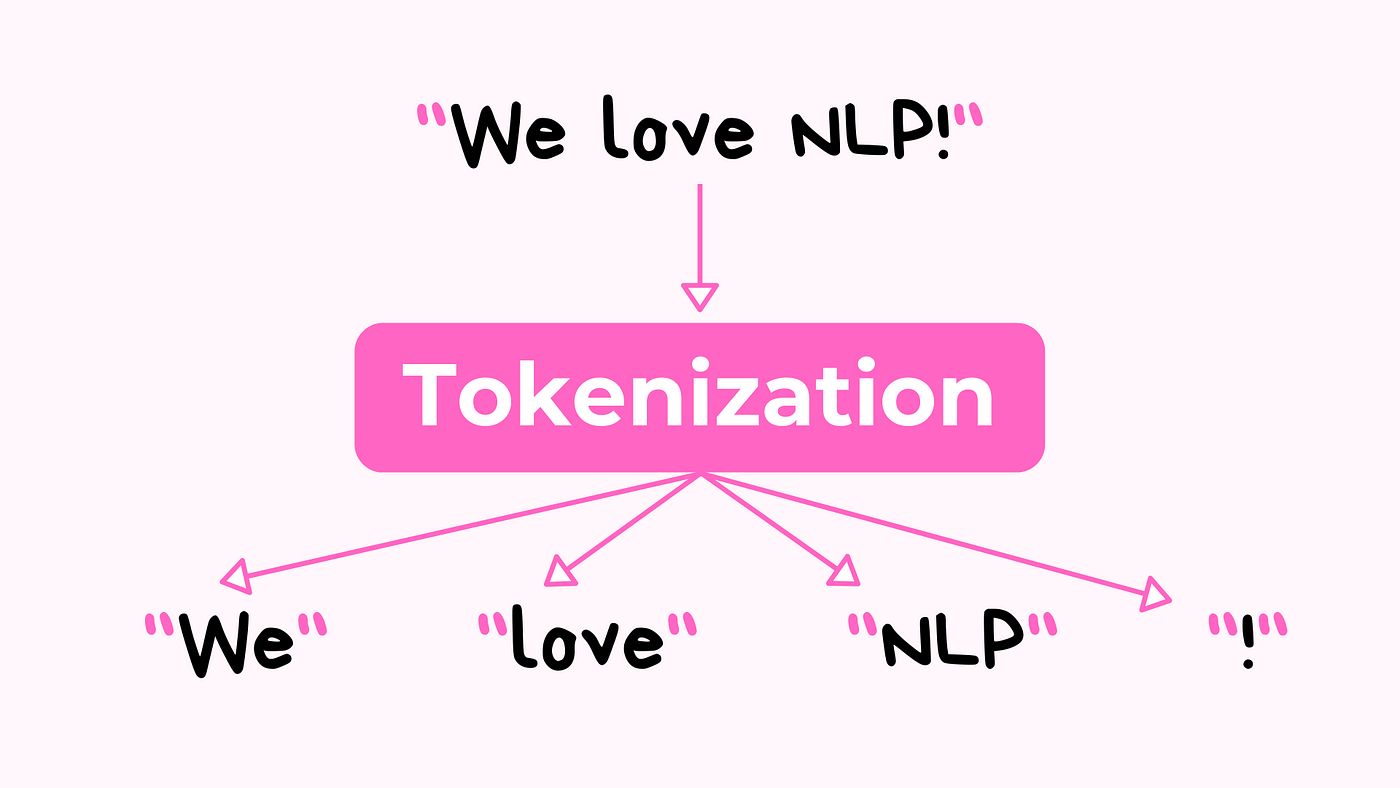
Welcome to this guide on how to import text files in order to use them for tokenization in R. Tokenization is a key step in natural language processing (NLP) tasks, such as text analysis, sentiment analysis, and machine learning. By breaking down text into smaller units, or tokens, we can gain insights and perform various operations on textual data.
In this tutorial, we will explore the process of importing text files and preparing them for tokenization in R. We will cover the necessary steps, including installing the required packages, importing the text files using the readLines() function, pre-processing the data, and finally tokenizing the text using the textTokenize() function. Additionally, we will analyze the tokenized data to gain meaningful information from it.
Whether you are a beginner or an experienced programmer, this guide will provide you with a step-by-step approach to importing text files and utilizing them for tokenization in R. So, let’s dive in and learn how to effectively import and process text data for your NLP projects.
Prerequisites: To follow along with this tutorial, you should have a basic understanding of R programming and have R and RStudio installed on your computer. Additionally, you will need the following packages installed: “tm,” “stringr,” and “qdap.” If you haven’t installed these packages yet, don’t worry – we will cover the installation process in the next step.
Step 1: Installing the necessary packages
The first step in importing text files for tokenization in R is to ensure that the required packages are installed. In this guide, we will be using three main packages: “tm,” “stringr,” and “qdap.” These packages provide various functions and tools for text processing and analysis.
To install these packages, follow these steps:
- Launch RStudio or open an R console.
- Install the “tm” package by running the following command:
install.packages("tm")
- Install the “stringr” package by running the following command:
install.packages("stringr")
- Install the “qdap” package by running the following command:
install.packages("qdap")
Once the packages are installed, you can load them into your R session using the library() function. For example:
library(tm) library(stringr) library(qdap)
By installing and loading these packages, you will have access to functions and utilities that will facilitate the import and processing of text files for tokenization in R.
Note: It is a good practice to regularly update your packages to ensure you have the latest versions with bug fixes and additional features. To update a package, you can use the update.packages() function followed by the package name. For example:
update.packages("tm")
With the necessary packages installed, we can now move on to the next step, which is importing the text files using the readLines() function.
Step 2: Importing text files using readLines()
Once you have the required packages installed, the next step is to import the text files that you want to use for tokenization. In R, the “readLines()” function allows you to read the contents of a text file and store it as a character vector.
To import a text file using the “readLines()” function, follow these steps:
- Ensure that your text file is saved in the appropriate directory or provide the full path to the file.
- Use the “readLines()” function and pass the path to your text file as an argument. For example:
text_data <- readLines("path/to/your/textfile.txt")
The "readLines()" function will read the contents of the text file and store it in the "text_data" variable as a character vector, where each element represents a line of text from the file.
Note: It is important to ensure that the path to your text file is correct. A common mistake is not specifying the correct directory or providing an incorrect file name or extension.
Once you have imported the text file, you can verify the contents by printing the "text_data" variable:
print(text_data)
This will display the lines of text from the file in your R console.
Importing text files using the "readLines()" function is a straightforward process. However, it is important to keep in mind that this function reads the entire file into memory. Therefore, for very large text files, it may not be the most efficient method. In such cases, you may need to consider alternative approaches, such as reading the file in chunks or using specialized functions for handling large text files.
Now that you have imported your text files, we can proceed to the next step: pre-processing the text data to prepare it for tokenization.
Step 3: Pre-processing the text data
Before we can tokenize the text data, it is essential to pre-process it to remove any irrelevant or unwanted elements and standardize the text. This step helps in improving the accuracy and efficiency of the tokenization process.
In this section, we will cover some common pre-processing steps that you can perform on your text data:
- Convert to lowercase: It is a good practice to convert all the text to lowercase. This step helps in avoiding case sensitivity issues and ensures consistent tokenization. You can use the "tolower()" function in R to achieve this:
text_data <- tolower(text_data)
- Remove punctuation: Punctuation marks do not contribute much to the semantic meaning of the text and can be safely removed. You can use the "gsub()" function in conjunction with regular expressions to remove punctuation marks:
text_data <- gsub("[[:punct:]]", "", text_data)
- Remove numbers: If the numbers in your text data are not relevant to your analysis, you can remove them using the "gsub()" function:
text_data <- gsub("[[:digit:]]", "", text_data)
- Remove extra white spaces: Sometimes, text data may contain extra spaces or multiple consecutive spaces. These spaces can be removed using regular expressions:
text_data <- gsub("\\s+", " ", text_data)
These pre-processing steps are just a starting point and can be customized based on your specific requirements. Depending on the nature of your text data, you may need to perform additional pre-processing steps such as removing stopwords, stemming, or handling special characters.
Once you have pre-processed your text data, it is ready for tokenization. In the next step, we will explore how to tokenize the text data using the "textTokenize()" function.
Step 4: Tokenizing the text data using textTokenize()
Now that we have pre-processed our text data, we can move on to the next step, which is tokenization. Tokenization is the process of breaking down text into smaller units called tokens, which could be words, phrases, or even individual characters. In R, we can use the "textTokenize()" function from the "qdap" package to perform tokenization.
To tokenize the text data using the "textTokenize()" function, follow these steps:
- Load the "qdap" package if you haven't already:
library(qdap)
- Use the "textTokenize()" function and pass the pre-processed text data as an argument:
tokens <- textTokenize(text_data)
The "textTokenize()" function will tokenize the text data and store the resultant tokens in the "tokens" variable.
Note that the "textTokenize()" function has various options and parameters that allow you to customize the tokenization process. For example, you can specify whether the tokens should be words, phrases, or n-grams, and you can also define the minimum and maximum lengths of the tokens.
After tokenization, you can explore the tokens by printing the "tokens" variable:
print(tokens)
This will display the tokens in your R console.
Tokenization is a crucial step in many natural language processing tasks, as it forms the foundation for further analysis and processing of textual data. By breaking down the text into tokens, we can perform tasks such as frequency analysis, sentiment analysis, and text classification.
In the next step, we will dive into analyzing the tokenized data to gain insights and information from it.
Step 5: Analyzing the tokenized data
After tokenizing the text data, the next step is to analyze the tokens to gain insights and extract meaningful information from the text. This analysis can help us understand patterns, frequencies, and relationships within the text data.
In this step, we will explore some common techniques for analyzing the tokenized data:
- Counting token frequencies: One of the simplest analyses we can perform is to count the frequency of each token in the text data. This gives us an idea of the most common words or phrases in the text. The "table()" function in R can be used to calculate the frequency of each token:
token_freq <- table(tokens) print(token_freq)
- Visualizing token frequencies: To gain a more visual understanding of token frequencies, we can create word clouds or bar charts. The "wordcloud()" function from the "wordcloud" package or the "barplot()" function in R can be used for this purpose:
library(wordcloud) wordcloud(token_freq) # or barplot(token_freq)
- Finding unique tokens: We may want to identify the unique tokens in our text data. The "unique()" function in R can help us achieve this:
unique_tokens <- unique(tokens) print(unique_tokens)
- Calculating token lengths: Another interesting analysis is to determine the lengths of the tokens. This can be useful in identifying short or long words in the text data. The "nchar()" function in R can be used to calculate the lengths of the tokens:
token_lengths <- nchar(tokens) print(token_lengths)
These are just a few examples of the analysis that can be performed on tokenized data. Depending on your specific project goals, you may employ more sophisticated techniques such as sentiment analysis, topic modeling, or text classification.
By analyzing the tokenized data, we can gain valuable insights into our text data and make informed decisions based on the findings. It is through this analysis that we can unlock the true potential of our text data.
Now that we have covered the process of analyzing tokenized data, we can conclude the tutorial.
Conclusion
In this tutorial, we have explored the process of importing text files and using them for tokenization in R. By following the steps outlined in this guide, you can efficiently import text data, preprocess it, tokenize it, and analyze the resulting tokens to gain insights and information.
We started by installing the necessary packages: "tm," "stringr," and "qdap." These packages provide the essential functions and tools for working with text data in R. Afterward, we used the "readLines()" function to import the text files and stored them as character vectors for further processing.
Next, we preprocessed the text data to ensure consistency and remove any irrelevant elements. This involved converting the text to lowercase, removing punctuation and numbers, and dealing with extra white spaces. These pre-processing steps help in improving the accuracy and efficiency of the tokenization process.
Once our text data was preprocessed, we used the "textTokenize()" function from the "qdap" package to tokenize the text. This step involved breaking down the text into smaller units, such as words, phrases, or individual characters. Tokenization is a fundamental step in many natural language processing tasks, as it enables further analysis and processing of textual data.
Finally, we explored various techniques for analyzing the tokenized data, such as counting token frequencies, visualizing token frequencies, finding unique tokens, and calculating token lengths. These analyses help us gain insights into the text data and make informed decisions based on the findings.
By following this guide, you now have a solid understanding of how to import text files, preprocess them, tokenize them, and analyze the resulting tokens in R. You can apply these techniques to various applications, including text analysis, sentiment analysis, text classification, and more.
Remember, the process of working with text data is both an art and a science. It requires creativity, domain knowledge, and a thorough understanding of the tools and techniques available. With continuous practice and exploration, you can become proficient in working with text data and harness its potential to drive meaningful insights and valuable outcomes.