Introduction
Big data has become a buzzword in today’s digital age, as organizations across various industries strive to harness the power of vast amounts of information. But what exactly is big data, and why is it so crucial? Simply put, big data refers to the massive volume of structured and unstructured data that organizations collect and analyze to gain insights, make informed decisions, and drive business growth. With the advancements in technology, the amount of data being generated continues to grow exponentially.
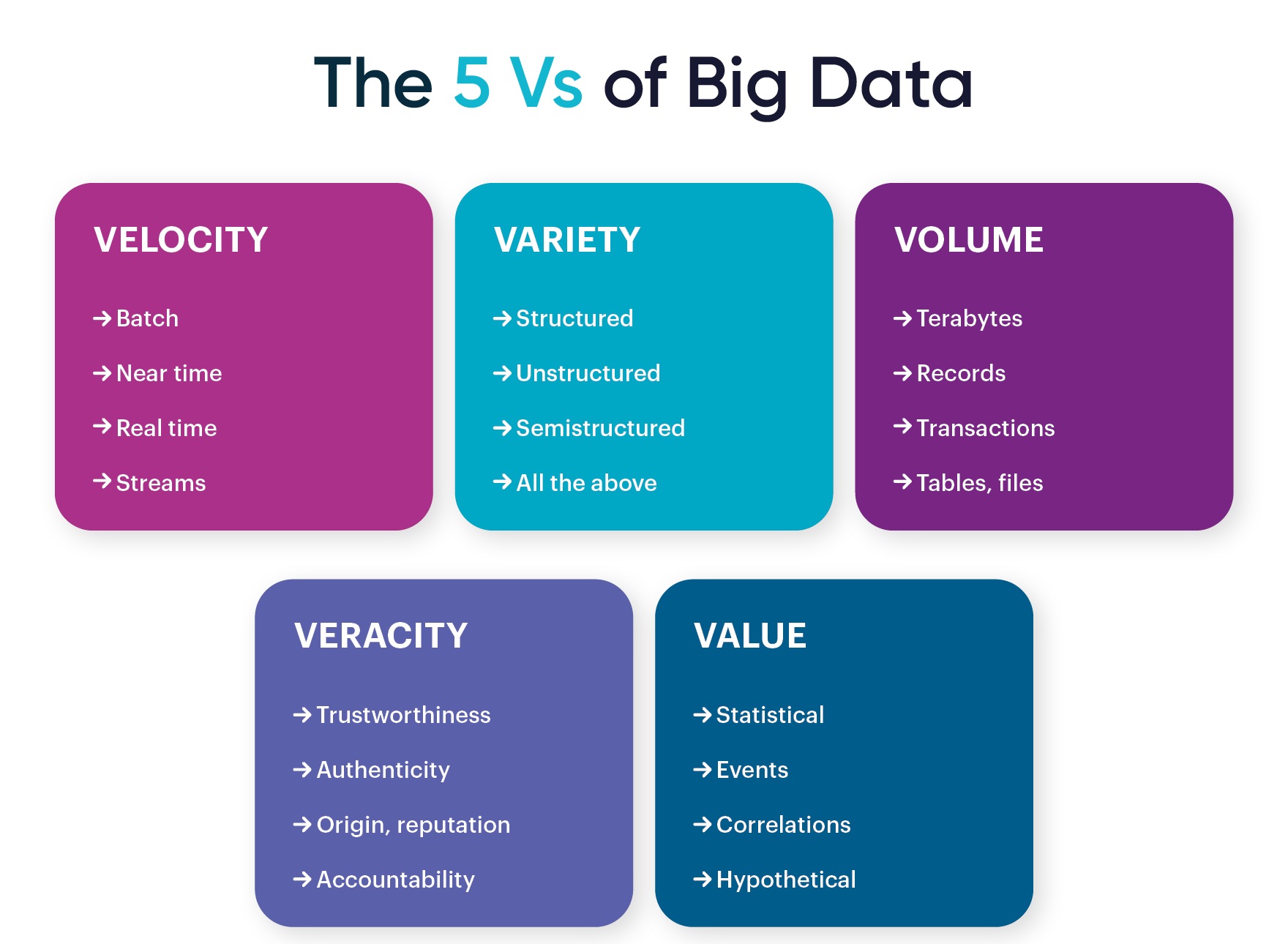
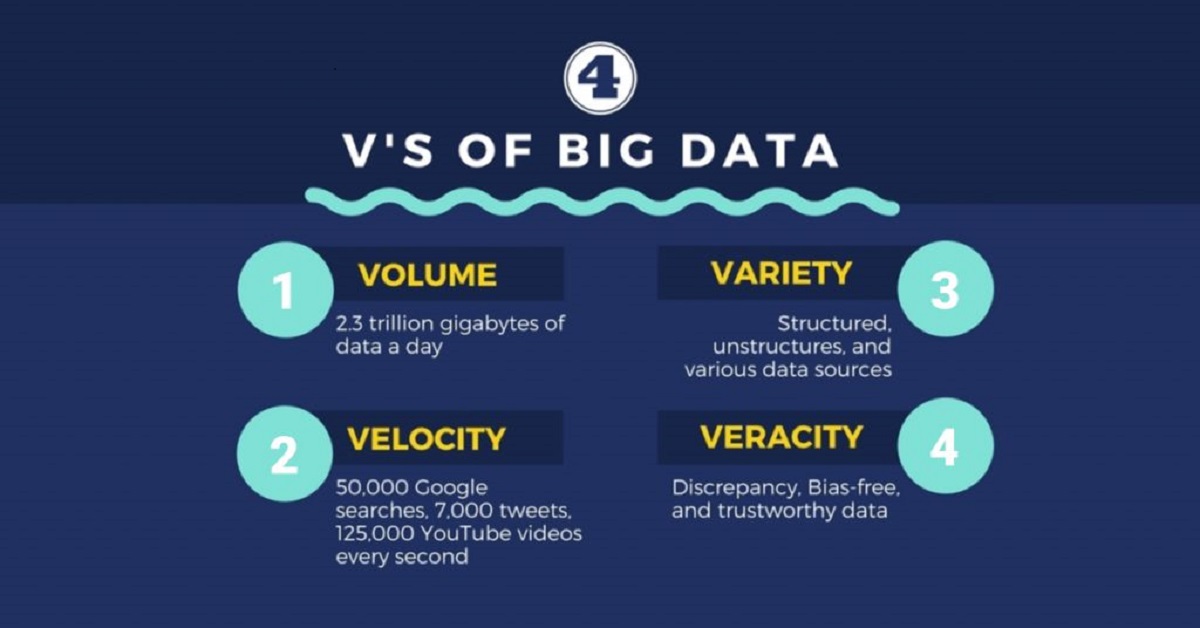
The 4 V’s of big data – volume, velocity, variety, and veracity – represent unique challenges and opportunities that organizations face when dealing with such massive data sets. By understanding and effectively managing these 4 V’s, businesses can unlock valuable insights that can drive innovation, enhance operational efficiency, and deliver better customer experiences.
Throughout this article, we will explore each of the 4 V’s in detail and understand their significance in the realm of big data analytics.
Volume
The first V of big data is volume, which refers to the sheer amount of data generated and collected. With the rapid advancements in technology and the proliferation of digital devices, data is being generated at an unprecedented rate. From customer transactions and social media interactions to sensor data and log files, organizations deal with enormous volumes of data on a daily basis.
The challenge lies in effectively storing, processing, and analyzing these massive datasets. Traditional database management systems are often ill-equipped to handle the volume of data involved in big data analytics. Therefore, innovative solutions such as distributed file systems and cloud-based storage platforms have emerged to tackle this challenge head-on.
By leveraging technologies like Hadoop and Apache Spark, organizations can efficiently store and process large volumes of data in a distributed and parallel manner. This enables faster data processing, real-time analytics, and the ability to uncover valuable insights from this wealth of information.
The volume of data presents both opportunities and challenges for organizations. On one hand, the abundance of data provides a rich source of information that can be harnessed to gain a comprehensive understanding of customer behavior, market trends, and business performance.
On the other hand, managing and processing such massive datasets requires robust infrastructure and data management practices. It is essential for organizations to invest in scalable storage solutions, data compression techniques, and data governance frameworks to ensure the smooth functioning of their big data analytics initiatives.
Furthermore, with the advent of the Internet of Things (IoT) and connected devices, the volume of data being generated is expected to skyrocket in the coming years. Businesses need to prepare themselves to handle this exponential growth in data by adopting scalable and agile data infrastructure.
Velocity
The second V of big data is velocity, which refers to the speed at which data is generated, processed, and analyzed. In today’s fast-paced digital world, data is constantly being created and updated in real-time. From social media feeds and online transactions to sensor readings and website clicks, data streams in from various sources at an unprecedented rate.
This velocity of data poses a significant challenge for organizations as they strive to extract meaningful insights from it. Traditional data processing methods are often incapable of handling the high velocity of data. Therefore, specialized tools and technologies have emerged to tackle this challenge, such as stream processing frameworks.
Stream processing allows organizations to analyze and act upon data as it is generated in real-time. This enables them to make timely decisions, identify patterns, and respond to events quickly. For example, in the finance industry, stream processing can be used to monitor stock prices, detect fraud, and execute high-frequency trading.
Moreover, the velocity of data is closely linked to the concept of data latency. Organizations need to ensure that the data they analyze and act upon is as up-to-date as possible. Real-time data processing and analytics play a crucial role in enabling organizations to stay agile and make informed decisions in a rapidly changing environment.
However, dealing with high-velocity data requires organizations to have the right infrastructure and tools in place. This includes efficient data ingestion mechanisms, scalable processing frameworks, and powerful analytics platforms. By investing in these technologies, organizations can effectively capture, process, and analyze data in real-time, enabling them to gain a competitive advantage and drive innovation.
Furthermore, the rise of the Internet of Things (IoT) and connected devices has amplified the velocity of data generation. With billions of devices generating data streams, organizations need to be equipped to handle this high-velocity data influx. Implementing robust data pipelines and data streaming architectures becomes crucial in ensuring the timely and efficient processing of data.
Variety
The third V of big data is variety, which refers to the diverse types and formats of data that organizations deal with. In addition to traditional structured data, such as those found in databases and spreadsheets, there is an increasing influx of unstructured and semi-structured data.
Unstructured data includes text documents, emails, social media posts, images, videos, and audio files. It is estimated that unstructured data accounts for around 80% of the data generated today. Semi-structured data, on the other hand, includes data that has a partial structure or is tagged with metadata, such as XML files and log files.
The challenge lies in effectively managing and extracting insights from these diverse data types. Traditional relational database management systems are designed to handle structured data, and they struggle with the complexity and variability of unstructured and semi-structured data.
In order to overcome this challenge, organizations need to leverage advanced data integration and analytics tools. Technologies such as data lakes and data warehouses provide a centralized repository for storing diverse data types. Meanwhile, natural language processing (NLP), image recognition, and machine learning algorithms enable organizations to extract valuable insights from unstructured data.
Having the capability to analyze a variety of data types is essential for organizations to gain a holistic view of their operations, customer behavior, and market trends. By incorporating unstructured and semi-structured data into their analytics initiatives, businesses can uncover hidden patterns, sentiments, and trends that traditional data sources may not capture.
Furthermore, the variety of data extends beyond just the data types but also includes data sources. Organizations today have access to data from a multitude of sources, both internal and external. This includes data from social media platforms, sensors, third-party APIs, and more. The ability to effectively integrate and analyze data from these diverse sources provides organizations with a more comprehensive understanding of their business landscape.
Embracing the variety of data requires organizations to adopt flexible and scalable data architectures. By implementing agile data integration practices, leveraging advanced analytics techniques, and embracing data interoperability standards, organizations can unlock the full potential of the variety of data and drive innovation.
Veracity
The fourth V of big data is veracity, which refers to the accuracy, reliability, and trustworthiness of the data being analyzed. With the increasing variety and volume of data, organizations face the challenge of ensuring data quality and veracity.
Data can come from various sources, and not all data is reliable or accurate. Incomplete, inconsistent, or erroneous data can lead to incorrect insights and decisions. Organizations must have rigorous data quality processes in place to verify the veracity of the data they collect and analyze.
One of the key aspects of ensuring data veracity is data governance. Data governance involves establishing policies, procedures, and controls for data management. It includes data validation, data cleansing, data profiling, and data monitoring to ensure the accuracy and reliability of data.
Data veracity also requires organizations to be transparent and accountable in their data practices. This includes clearly documenting data sources, data transformations, and data processing methodologies to ensure traceability and reproducibility. It is essential to maintain an audit trail of data lineage to enable data quality assurance and to address any concerns or issues that arise.
Technological advancements, such as blockchain, can play a role in ensuring data veracity by providing a decentralized and immutable ledger for recording transactions and data provenance. This allows organizations to establish trust and validate the authenticity of the data they analyze.
Moreover, data veracity is closely linked to data privacy and security. Organizations must ensure that sensitive data is protected and handled in compliance with relevant regulations, such as GDPR or CCPA. By implementing robust data security measures, organizations can safeguard data integrity and maintain trust with their customers.
Addressing the veracity of data requires organizations to establish a culture of data quality and data literacy. Employees need to be trained in data management practices and understand the importance of data quality in decision-making processes.
By placing a strong emphasis on data veracity, organizations can ensure the reliability and accuracy of their insights. This, in turn, leads to more confident decision-making, improved operational efficiency, and a competitive advantage in the market.
Conclusion
Understanding and effectively managing the 4 V’s of big data – volume, velocity, variety, and veracity – are crucial for organizations looking to harness the power of data analytics. The sheer volume of data being generated and collected requires scalable storage and processing solutions. The high velocity of data necessitates real-time analytics capabilities to extract actionable insights. The variety of data types and sources calls for flexible integration and advanced analytical techniques. Finally, ensuring the veracity of data through strong data governance and quality practices is essential for accurate decision-making.
By successfully addressing these challenges, organizations can unlock the potential of big data analytics to drive innovation, improve operational efficiency, and deliver enhanced customer experiences. They can gain a comprehensive understanding of their business landscape, uncover insights that were previously unseen, and make informed decisions in a rapidly changing environment.
However, it is important to remember that tackling the 4 V’s of big data is an ongoing process. The advancements in technology and the evolving data landscape will continue to present new challenges and opportunities. Organizations must stay agile, continuously adapt their data strategies, and invest in the right tools and technologies to stay ahead in the data-driven world.
Ultimately, the effective management of the 4 V’s of big data positions organizations to thrive in the digital age. By embracing the volume, velocity, variety, and veracity of data, businesses can unlock valuable insights, drive competitive advantage, and stay at the forefront of their industries.